プライベートクラウドでの Threat Defense Virtual のクラスタリングについて
ここでは、クラスタリング アーキテクチャとその動作について説明します。
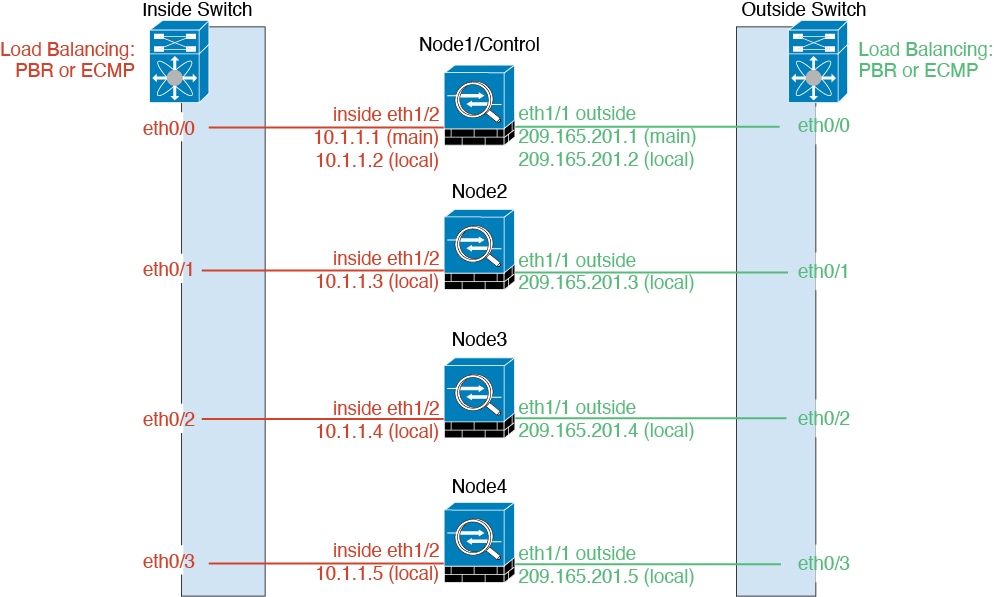
クラスタをネットワークに適合させる方法
クラスタは、複数のファイアウォールで構成され、これらは 1 つのデバイスとして機能します。ファイアウォールをクラスタとして機能させるには、次のインフラストラクチャが必要です。
-
クラスタ内通信用の、隔離されたネットワーク。VXLAN インターフェイスを使用したクラスタ制御リンクと呼ばれます。レイヤ 3 物理ネットワーク上でレイヤ 2 仮想ネットワークとして機能する VXLAN により、Threat Defense Virtual はクラスタ制御リンクを介してブロードキャスト/マルチキャストメッセージを送信できます。
-
各ファイアウォールへの管理アクセス(コンフィギュレーションおよびモニタリングのため)。Threat Defense Virtual 導入には、クラスタノードの管理に使用するManagement 0/0 インターフェイスが含まれています。
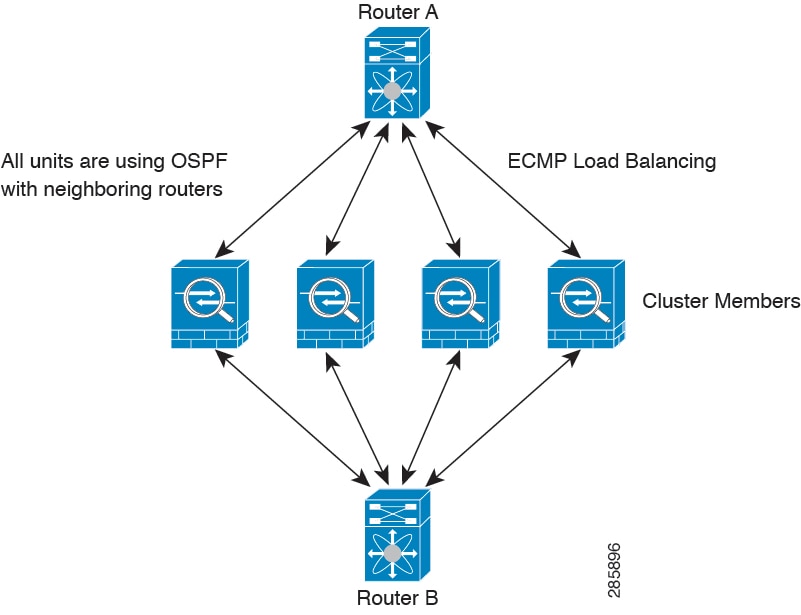
クラスタをネットワーク内に配置するときは、アップストリームおよびダウンストリームのルータは、レイヤ 3 の個別インターフェイスおよび次のいずれかの方法を使用して、クラスタとの間で送受信されるデータをロードバランシングできる必要があります。
-
ポリシーベースルーティング:アップストリームとダウンストリームのルータが、ルート マップと ACL を使用してノード間のロードバランシングを実行します。
-
等コスト マルチパス ルーティング:アップストリームとダウンストリームのルータが、等コストのスタティックまたはダイナミック ルートを使用してノード間のロードバランシングを実行します。
 (注) |
レイヤ 2 スパンド EtherChannels はサポートされません。 |
制御ノードとデータノードの役割
クラスタ内のメンバーの 1 つが制御ノードになります。複数のクラスタノードが同時にオンラインになる場合、制御ノードは、プライオリティ設定によって決まります。プライオリティは 1 ~ 100 の範囲内で設定され、1 が最高のプライオリティです。他のすべてのメンバーはデータノードです。 最初にクラスタを作成するときに、制御ノードにするノードを指定します。これは、クラスタに追加された最初のノードであるため、制御ノードになります。
クラスタ内のすべてのノードは、同一の設定を共有します。最初に制御ノードとして指定したノードは、データノードがクラスタに参加するときにその設定を上書きします。そのため、クラスタを形成する前に制御ノードで初期設定を実行するだけで済みます。
機能によっては、クラスタ内でスケーリングしないものがあり、そのような機能については制御ノードがすべてのトラフィックを処理します。
個々のインターフェイス
個別インターフェイスは通常のルーテッドインターフェイスであり、それぞれが専用のルーティング用ローカル IP アドレスを持ちます。各インターフェイスのメインクラスタ IP アドレスは、固定アドレスであり、常に制御ノードに属します。制御ノードが変更されると、メインクラスタ IP アドレスは新しい制御ノードに移動するので、クラスタの管理をシームレスに続行できます。
IPS 専用インターフェイス(インラインセットとパッシブインターフェイス)は、個別インターフェイスとしてサポートされません。
インターフェイス コンフィギュレーションは制御ノード上だけで行う必要があるため、IP アドレスプールを設定して、このプールのアドレスがクラスタノード(制御ノード用を含む)の特定のインターフェイスに使用されるようにします。
アップストリームスイッチ上でロードバランシングを別途する必要があります。
(注) |
レイヤ 2 スパンド EtherChannels はサポートされません。 |
ポリシーベース ルーティング
個別インターフェイスを使用するときは、各 Threat Defense インターフェイスが専用の IP アドレスと MAC アドレスを維持します。ロード バランシング方法の 1 つが、ポリシーベース ルーティング(PBR)です。
この方法が推奨されるのは、すでに PBR を使用しており、既存のインフラストラクチャを活用したい場合です。
PBR は、ルート マップおよび ACL に基づいて、ルーティングの決定を行います。管理者は、手動でトラフィックをクラスタ内のすべての Threat Defense に分ける必要があります。PBR は静的であるため、常に最適なロード バランシング結果を実現できないこともあります。最高のパフォーマンスを達成するには、PBR ポリシーを設定するときに、同じ接続のフォワードとリターンのパケットが同じ Threat Defense に送信されるように指定することを推奨します。たとえば、Cisco ルータがある場合は、冗長性を実現するには Cisco IOS PBR をオブジェクト トラッキングとともに使用します。Cisco IOS オブジェクト トラッキングは、ICMP ping を使用して各 Threat Defense をモニタします。これで、PBR は、特定の Threat Defense の到達可能性に基づいてルート マップを有効化または無効化できます。詳細については、次の URL を参照してください。
http://www.cisco.com/en/US/products/ps6599/products_white_paper09186a00800a4409.shtml
等コスト マルチパス ルーティング
個別インターフェイスを使用するときは、各 Threat Defense インターフェイスが専用の IP アドレスと MAC アドレスを維持します。ロード バランシング方法の 1 つが、等コスト マルチパス(ECMP)ルーティングです。
この方法が推奨されるのは、すでに ECMP を使用しており、既存のインフラストラクチャを活用したい場合です。
ECMP ルーティングでは、ルーティング メトリックが同値で最高である複数の「最適パス」を介してパケットを転送できます。EtherChannel のように、送信元および宛先の IP アドレスや送信元および宛先のポートのハッシュを使用してネクスト ホップの 1 つにパケットを送信できます。ECMP ルーティングにスタティックルートを使用する場合は、Threat Defense の障害発生時に問題が起きることがあります。ルートは引き続き使用されるため、障害が発生した Threat Defense へのトラフィックが失われるからです。スタティック ルートを使用する場合は必ず、オブジェクト トラッキングなどのスタティック ルート モニタリング機能を使用してください。ダイナミック ルーティング プロトコルを使用してルートの追加と削除を行うことを推奨します。この場合は、ダイナミック ルーティングに参加するように各 Threat Defense を設定する必要があります。
クラスタ制御リンク
ノードごとに 1 つのインターフェイスをクラスタ制御リンク専用の VXLAN(VTEP)インターフェイスにする必要があります。VXLAN の詳細については、「VXLAN インターフェイスの設定」を参照してください。
VXLAN トンネル エンドポイント
VXLAN トンネル エンドポイント(VTEP)デバイスは、VXLAN のカプセル化およびカプセル化解除を実行します。各 VTEP には 2 つのインターフェイスタイプ(VXLAN Network Identifier(VNI)インターフェイスと呼ばれる 1 つ以上の仮想インターフェイスと、 VTEP 間に VNI をトンネリングする VTEP 送信元インターフェイスと呼ばれる通常のインターフェイス)がありますVTEP 送信元インターフェイスは、VTEP 間通信のトランスポート IP ネットワークに接続されます。
VTEP 送信元インターフェイス
VTEP 送信元インターフェイスは、VNI インターフェイスに関連付けられる予定の標準の Threat Defense Virtual インターフェイスです。1 つの VTEP ソースインターフェイスをクラスタ制御リンクとして機能するように設定できます。ソースインターフェイスは、クラスタ制御リンクの使用専用に予約されています。各 VTEP ソースインターフェイスには、同じサブネット上の IP アドレスがあります。このサブネットは、他のすべてのトラフィックからは隔離し、 クラスタ制御リンクインターフェイスだけが含まれるようにしてください。
VNI インターフェイス
VNI インターフェイスは VLAN インターフェイスに似ています。VNI インターフェイスは、タギングを使用して特定の物理インターフェイスでのネットワークトラフィックの分割を維持する仮想インターフェイスです。設定できる VNI インターフェイスは 1 つだけです。各 VNI インターフェイスは、同じサブネット上の IP アドレスを持ちます。
ピア VTEP
単一の VTEP ピアを許可するデータインターフェイス用の通常の VXLAN とは異なり、Threat Defense Virtual クラスタリングでは複数のピアを設定できます。
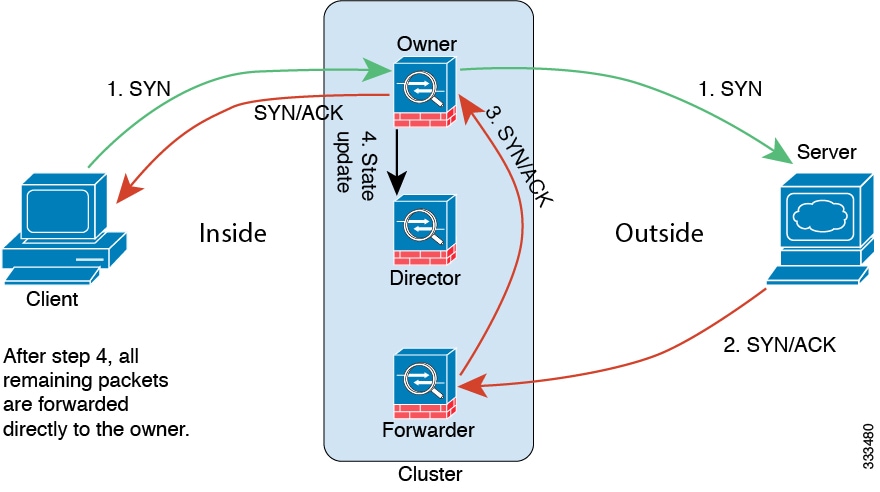
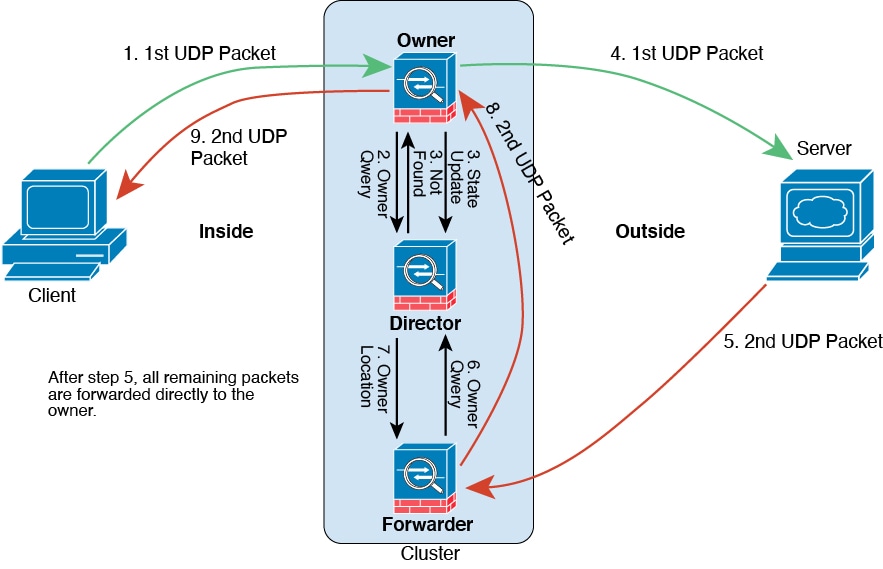
クラスタ制御リンク トラフィックの概要
クラスタ制御リンク トラフィックには、制御とデータの両方のトラフィックが含まれます。
制御トラフィックには次のものが含まれます。
-
制御ノードの選択。
-
設定の複製。
-
ヘルス モニタリング。
データ トラフィックには次のものが含まれます。
-
状態の複製。
-
接続所有権クエリおよびデータ パケット転送。
コンフィギュレーションの複製
クラスタ内のすべてのノードは、単一の設定を共有します。設定の変更は制御ノードでのみ可能(ブートストラップ設定は除く)で、変更はクラスタに含まれる他のすべてのノードに自動的に同期されます。
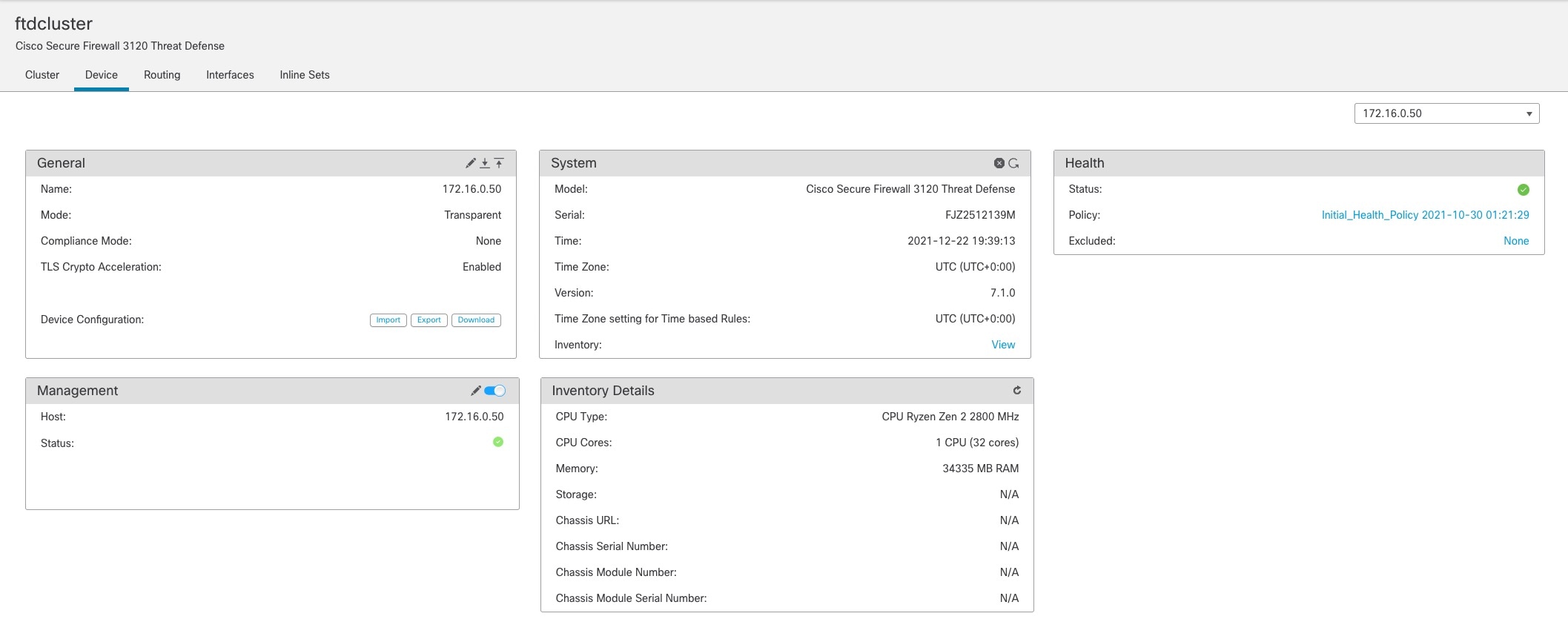
管理ネットワーク
管理インターフェイスを使用して各ノードを管理する必要があります。クラスタリングでは、データインターフェイスからの管理はサポートされていません。

![[クラスタの追加(Add Cluster)] ウィザード](/c/dam/en/us/td/i/400001-500000/460001-470000/464001-465000/464739.jpg)
![[エラー(Error)] アイコン](/c/dam/en/us/td/i/400001-500000/440001-450000/446001-447000/446178.jpg) )
)






![[その他(More)] アイコン](/c/dam/en/us/td/i/400001-500000/440001-450000/448001-449000/448310.jpg) )
)
![[クラスタの管理(Manage Cluster)] ウィザード](/c/dam/en/us/td/i/400001-500000/460001-470000/465001-466000/465780.jpg)
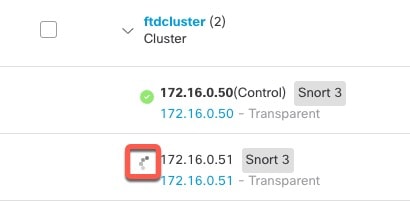
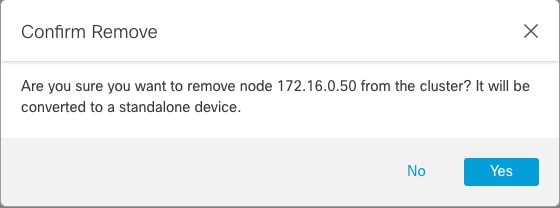
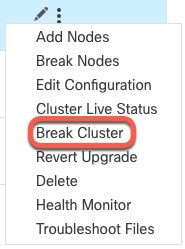
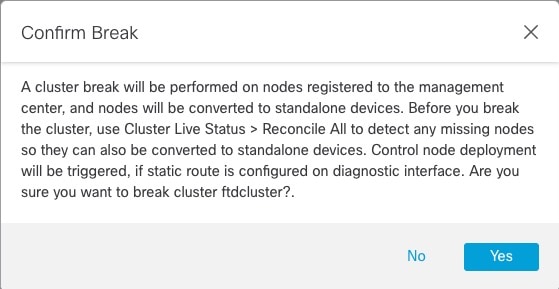
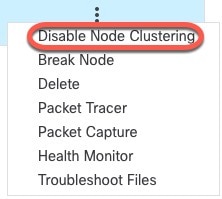

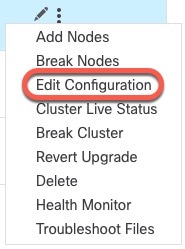
![[クラスタの管理(Manage Cluster)] ウィザード](/c/dam/en/us/td/i/400001-500000/460001-470000/465001-466000/465781.jpg)
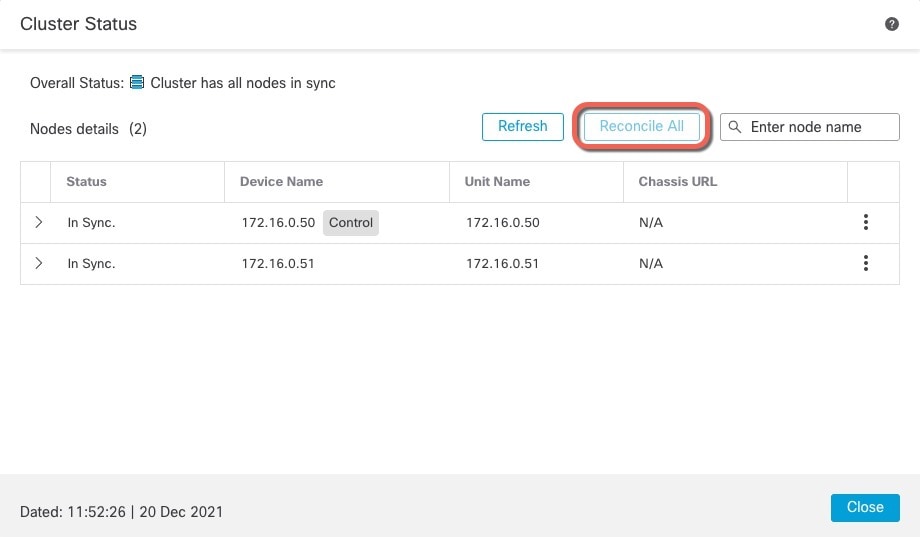
![ノードの [概要(Summary)]](/c/dam/en/us/td/i/400001-500000/450001-460000/459001-460000/459937.jpg)
![ノードの [履歴(History)]](/c/dam/en/us/td/i/400001-500000/450001-460000/459001-460000/459938.jpg)
![[展開(Expand)] アイコン](/c/dam/en/us/td/i/400001-500000/440001-450000/447001-448000/447115.jpg) )
)![[折りたたみ(Collapse)] アイコン](/c/dam/en/us/td/i/400001-500000/440001-450000/447001-448000/447117.jpg) )
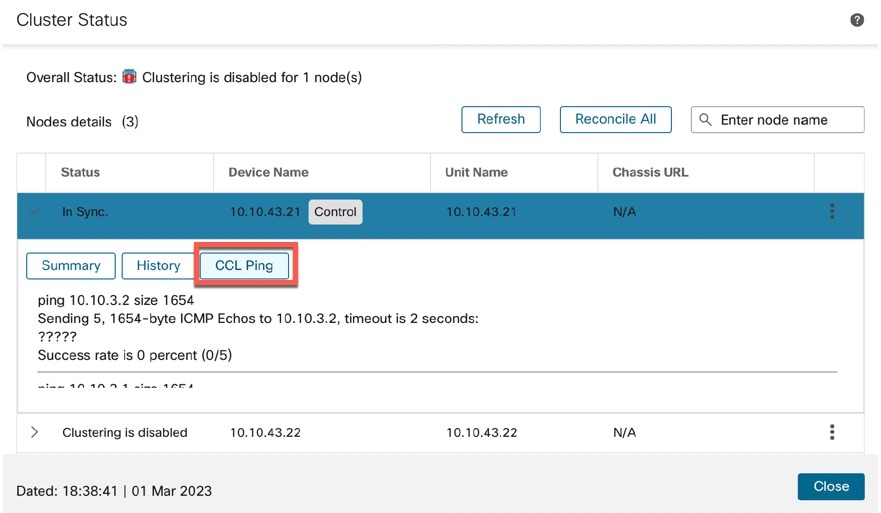
)
 フィードバック
フィードバック