À propos de la haute disponibilité Cisco Secure Firewall Threat Defense
La configuration de la haute disponibilité, également appelée basculement, nécessite deux périphériques défense contre les menaces identiques connectés l’un à l’autre par un lien de basculement dédié et, éventuellement, un lien d’état. défense contre les menaces prend en charge le basculement entre actif/veille, où une unité est l’unité active et transmet le trafic. L’unité secondaire (en veille) ne transmet pas activement le trafic, mais synchronise la configuration et les autres renseignements d’état de l’unité active. Lors d’un basculement, l’unité active est remplacée par l’unité en veille, qui devient alors active.
L’intégrité de l’unité active (matériel, interfaces, logiciels et état environnemental) est surveillée pour déterminer si les conditions spécifiques au basculement sont respectées. Si ces conditions sont remplies, le basculement se produit.
 Remarque |
La haute disponibilité n’est pas prise en charge sur défense contre les menaces virtuelles s’exécutant dans le nuage public. |
Prise en charge de la haute disponibilité sur les périphériques Défense contre les menaces dans un déploiement dans une succursale distante
Dans le déploiement d’une succursale à distance, l’interface de données du périphérique défense contre les menaces est utilisée pour la gestion de Cisco Defense Orchestrator au lieu de l’interface de gestion sur le périphérique. Comme la plupart des succursales distantes ne disposent que d'une seule connexion Internet, l'accès CDO extérieur permet une gestion centralisée.
Vous pouvez utiliser n'importe quelle interface de données pour l'accès àCDO, par exemple, l'interface intérieure si vous avez un CDO interne. Cependant, ce guide aborde principalement l’accès à l’interface externe, car c’est le scénario le plus probable pour les succursales à distance.
CDO fournit une prise en charge de la haute disponibilité sur les périphériques défense contre les menaces qu’il gère par l’interface de données. Cette fonctionnalité est prise en charge sur les périphériques fonctionnant avec la version logicielle 7.2 ou ultérieure.
Pour en savoir plus, consultez Déploiement de Firepower Threat Defense avec un FMC distant dans le Guide de démarrage Cisco Firepower.
Configuration système requise pour High Availability (haute disponibilité)
Cette section décrit les exigences matérielles, logicielles et de licence pour les Défense contre les menaces dans une configuration High Availability (haute disponibilité).
Configuration matérielle requise
Les deux unités dans une configuration High Availability (haute disponibilité) doivent :
-
être du même modèle. En outre, les instances de conteneur doivent utiliser les mêmes attributs de profil de ressource.
Pour la Firepower 9300, la haute disponibilité est uniquement prise en charge entre les modules de même type; toutefois, les deux châssis peuvent inclure des modules mixtes. Par exemple, chaque châssis a un SM-56, SM-48 et SM-40. Vous pouvez créer des paires à haute disponibilité entre les modules SM-56, entre les modules SM-48 et entre les modules SM-40.
Si vous modifiez le profil de ressources après avoir ajouté la paire à haute disponibilité au CDO, mettez à jour l'inventaire de chaque unité dans la boîte de dialogue .
Si vous affectez un profil différent aux instances d’une paire à haute disponibilité établie, ce qui nécessite que le profil soit le même sur les deux unités, vous devez :
-
Rompre la haute disponibilité
-
Attribuer le nouveau profil aux deux unités.
-
Rétablir la haute disponibilité.
-
-
Avoir le même nombre et les mêmes types d'interfaces.
Pour le Châssis Firepower 4100/9300 , toutes les interfaces doivent être préconfigurées en FXOS de manière identique avant d'activer High Availability (haute disponibilité). Si vous modifiez les interfaces après avoir activé High Availability (haute disponibilité), modifiez l'interface dans FXOS sur l'unité en veille, puis apportez les mêmes modifications à l'unité active.
-
Ayez les paramètres suivants dans un déploiement de succursale distante :
-
Ayez la même interface de gestion des données pour gérer le trafic de gestion dans un déploiement à distance.
Par exemple, si vous avez utilisé eth0 dans le périphérique 1, utilisez également la même interface (eth0) dans le périphérique 2.
-
Utilisez l’interface de gestion des données pour la gestion du trafic.
Vous ne pouvez pas gérer une unité à l’aide d’une interface de données et l’autre à l’aide d’une interface de gestion.
-
Si vous utilisez des unités avec des tailles de mémoire flash différentes dans votre configuration High Availability (haute disponibilité), assurez-vous que l’unité dotée de la mémoire flash la plus faible dispose de suffisamment d’espace pour contenir les fichiers d’image logicielle et les fichiers de configuration. Si ce n’est pas le cas, la synchronisation de la configuration de l’unité ayant la plus grande mémoire flash vers l’unité ayant la plus faible mémoire flash échouera.
Configuration logicielle requise
Les deux unités dans une configuration High Availability (haute disponibilité) doivent :
-
: utilisez le même mode de pare-feu (routage ou transparent).
-
Avoir la même version de logiciel;
-
Faire partie du même domaine ou groupe sur centre de gestion.
-
Ont la même configuration NTP. Consultez Configurer la synchronisation de l’heure NTP pour Threat Defense.
-
Être entièrement déployé sur centre de gestion sans modifications non validées.
-
DHCP ou PPPoE n’est configuré dans aucune de leurs interfaces.
-
(Firepower 4100/9300) ont le même mode de déchargement de flux, activé ou désactivé.
Exigences de licence pour les périphériques Défense contre les menaces dans une paire à haute disponibilité
Les deux unités défense contre les menaces d’une configuration à haute disponibilité doivent avoir les mêmes licences.
Les configurations à haute disponibilité nécessitent deux licences Smart; une pour chaque appareil de la paire.
Avant que la haute disponibilité ne soit établie, les licences attribuées au périphérique secondaire ou en veille importent peu. Pendant la configuration à haute disponibilité, centre de gestion libère toutes les licences inutiles attribuées à l’unité de secours et les remplace par des licences identiques attribuées à l’unité principale ou active. Par exemple, si le périphérique actif dispose d’une licence Essentielle et d’une licence IPS et que le périphérique de veille n’a qu’une licence Essentielle , l’unité centre de gestion communique avec Cisco Smart Software Manager pour obtenir une licence IPS disponible pour votre compte, pour l'unité de veille Si votre compte de licences Smart ne comprend pas suffisamment de droits achetés, il devient non conforme jusqu’à ce que vous achetiez le nombre correct de licences.
Liens de basculement et de basculement avec état
Le lien de basculement et le lien de basculement dynamique facultatif sont des connexions dédiées entre les deux unités. Cisco recommande d’utiliser la même interface entre deux périphériques dans une liaison de basculement ou un lien de basculement avec état. Par exemple, dans un lien de basculement, si vous avez utilisé eth0 dans le périphérique 1, utilisez également la même interface (eth0) dans le périphérique 2.
Lien de basculement
Les deux unités d'une paire de basculement communiquent en permanence sur une liaison de basculement pour déterminer l'état de fonctionnement de chaque unité.
Données de la liaison de basculement
Les informations suivantes sont transmises par la liaison de basculement :
-
L’état de l’unité (actif ou en veille)
-
Messages Hello (keep-alives)
-
État de la liaison réseau
-
Échange d’adresses MAC
-
Réplication et synchronisation de la configuration
Interface de la liaison de basculement
Vous pouvez utiliser une interface de données inutilisée (physiqueinterface ou EtherChannel) comme liaison de basculement; cependant, vous ne pouvez pas spécifier une interface actuellement configurée avec un nom. Vous ne pouvez pas utiliser une interface de gestion des données si l’interface est configurée pour la communication avec CDO. Vous ne pouvez pas non plus utiliser une sous-interface, à l’exception d’une sous-interface définie sur le châssis pour le mode multi-instance. L’interface de liaison de basculement n’est pas configurée comme une interface réseau normale; il existe pour la communication de basculement uniquement. Cette interface ne peut être utilisée que pour la liaison de basculement (ainsi que pour le lien d’état).
Le défense contre les menaces ne prend pas en charge les interfaces de partage entre les données de l’utilisateur et le lien de basculement. Vous ne pouvez pas non plus utiliser des sous-interfaces distinctes sur le même parent pour la liaison de basculement et pour les données (sous-interfaces de châssis à instances multiples uniquement). Si vous utilisez une sous-interface de châssis pour le lien de basculement, toutes les sous-interfaces de ce parent, et le parent lui-même, sont restreintes pour utilisation en tant que liaisons de basculement.
Remarque |
Lorsque vous utilisez une comme liaison de basculement ou d’état, vous devez confirmer que la même interface EtherChannel avec les mêmes interfaces membres existe sur les deux périphériques avant d’établir la haute disponibilité. |
Consultez les consignes suivantes concernant la liaison de basculement :
-
Firepower 4100/9300 : Nous vous recommandons d’utiliser une interface de données de 10 Go pour la combinaison de liaison de basculement et de liaison d’état.
-
Tous les autres modèles : l’interface de 1 Go est suffisante pour une combinaison de liaison de basculement et d’état.
La fréquence d’alternance est égale au temps de maintien de l’unité.
Remarque |
Si vous avez une configuration importante et un temps d’attente d’unité faible, l’alternance entre les interfaces membres peut empêcher l’unité secondaire de se joindre ou de se joindre. Dans ce cas, désactivez l’une des interfaces membres jusqu’à ce que l’unité secondaire se soit jointe. |
Pour un EtherChannel utilisé comme liaison de basculement, pour éviter les paquets dans le désordre, une seule interface dans l’EtherChannel est utilisée. Si cette interface échoue, l’interface suivante de l’EtherChannel est utilisée. Vous ne pouvez pas modifier la configuration de l’EtherChannel lorsqu’il est utilisé comme liaison de basculement.
Connexion de la liaison de basculement
Connectez le lien de basculement de l’une des deux manières suivantes :
-
À l'aide d'un commutateur, sans autre périphérique sur le même segment de réseau (domaine de diffusion ou VLAN) que les interfaces de basculement du périphérique.
-
L’utilisation d’un câble Ethernet pour connecter les unités directement, sans avoir besoin d’un commutateur externe.
Si vous n’utilisez pas de commutateur entre les unités, et en cas de défaillance de l’interface, la liaison est interrompue sur les deux homologues. Cette condition peut nuire aux efforts de dépannage, car vous ne pouvez pas facilement déterminer quelle unité a l’interface défaillante qui a entraîné la défaillance du lien.
Lien de basculement dynamique
Pour utiliser le basculement avec état, vous devez configurer un lien de basculement avec état (également appelé lien d’état) pour transmettre les informations sur l’état de la connexion.
Partagé avec la liaison de basculement
Le partage d’un lien de basculement est le meilleur moyen de conserver les interfaces. Cependant, vous devez envisager une interface dédiée pour le lien d’état et le lien de basculement, si votre configuration est importante et que le trafic sur le réseau est élevé.
Interface dédiée à la liaison de basculement dynamique
Vous pouvez utiliser une interface de données dédiée (physique ou EtherChannel) pour la liaison d’état. Consultez Interface de la liaison de basculement pour connaître les exigences relatives à une lien liaison d’état dédiée et Connexion de la liaison de basculement pour obtenir des renseignements sur la façon de connecter la liaison d’état.
Pour des performances optimales lors de l’utilisation du basculement longue distance, la latence de la liaison d’état doit être inférieure à 10 millisecondes et non supérieure à 250 millisecondes. Si la latence est supérieure à 10 millisecondes, une certaine dégradation des performances se produit en raison de la retransmission des messages de basculement.
Éviter le basculement interrompu et les liaisons de données
Nous recommandons que les liens de basculement et les interfaces de données empruntent différentes voies pour réduire le risque d’échec de toutes les interfaces en même temps. Si le lien de basculement est arrêté, l’appareil défense contre les menaces peut utiliser les interfaces de données pour déterminer si un basculement est requis. Ensuite, l’opération de basculement est suspendue jusqu’à ce que l’intégrité du lien de basculement soit restaurée.
Consultez les scénarios de connexion suivants pour concevoir un réseau de basculement résilient.
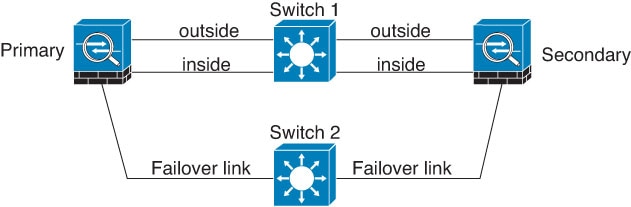
Scénario 1 (non recommandé)
Si un seul commutateur ou un ensemble de commutateurs est utilisé pour connecter les interfaces de basculement et de données entre deux périphériques défense contre les menaces , quand un commutateur ou une liaison inter-commutateurs sont en panne, les deux périphériques deviennent actifs.défense contre les menaces Par conséquent, les deux méthodes de connexion indiquées dans les figures suivantes ne sont pas recommandées.


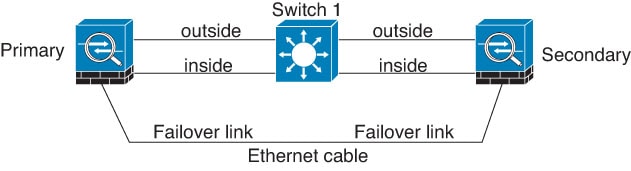
Scénario 2 (recommandé)
Nous recommandons que les liens de basculement n'utilisent pas le même commutateur que les interfaces de données. Au lieu de cela, utilisez un commutateur différent ou utilisez un câble direct pour connecter le lien de basculement, comme le montrent les figures suivantes.
Scénario 3 (recommandé)
Si les interfaces de données défense contre les menaces sont connectées à plusieurs ensembles de commutateurs, un lien de basculement peut être connecté à l’un des commutateurs, de préférence le commutateur du côté sécurisé (interne) du réseau, comme le montre la figure suivante.
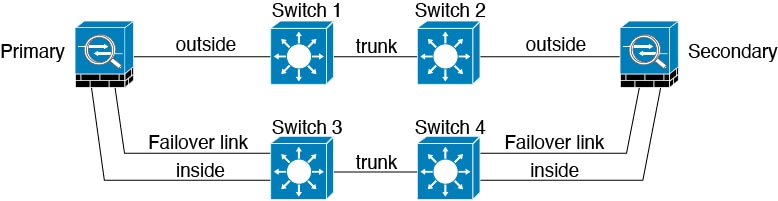
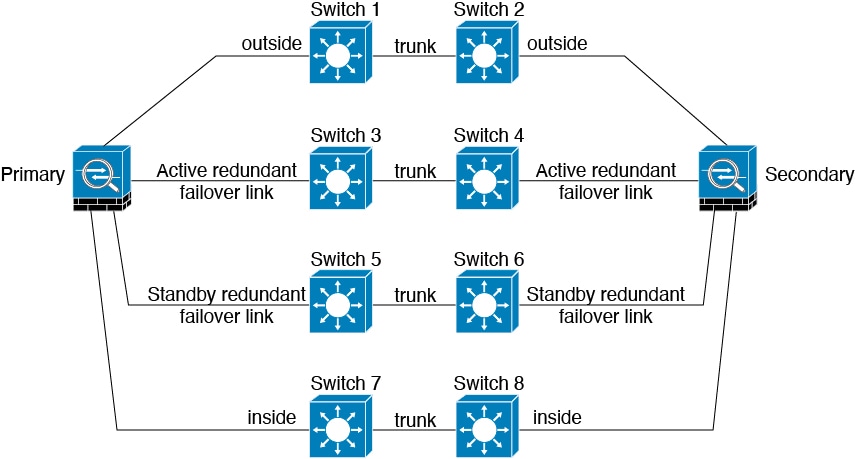
Scénario 4 (recommandé)
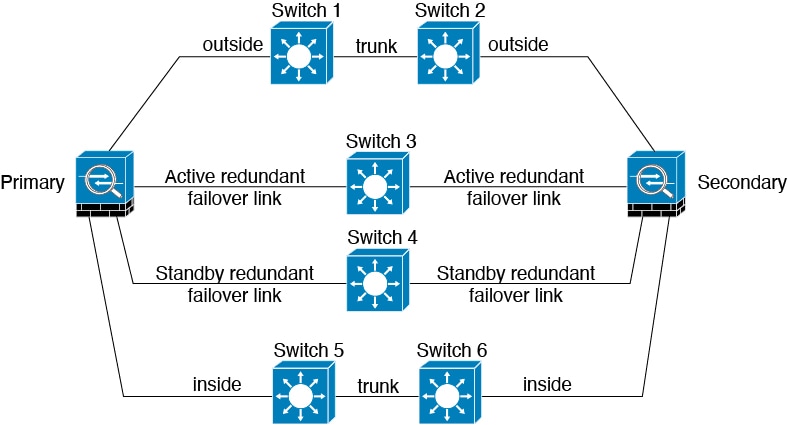
Les configurations de basculement les plus fiables utilisent une interface redondante au niveau du lien de basculement, comme le montrent les figures suivantes.
Les adresses MAC et les adresses IP en High Availability (haute disponibilité)
Lorsque vous configurez vos interfaces, vous pouvez spécifier une adresse IP active et une adresse IP de secours sur le même réseau. En général, lors d’un basculement, la nouvelle unité active prend en charge les adresses IP et MAC actives. Étant donné que les périphériques réseau ne constatent aucun changement dans l’association d’adresses MAC à l’adresse IP, aucune entrée ARP ne change et n’expire sur le réseau.
Remarque |
Bien que recommandée, l’adresse de secours n’est pas obligatoire. Si vous ne définissez pas l’adresse IP de veille, l’unité active ne peut pas surveiller l’interface de secours en utilisant des tests réseau; elle ne peut que suivre l’état du lien. Vous ne pouvez pas non plus vous connecter à l’unité de secours sur cette interface à des fins de gestion. |
L’adresse IP et l’adresse MAC du lien d’état ne changent pas lors du basculement.
Adresses IP et adresses MAC actives/en attente
Pour le High Availability (haute disponibilité)(actif/veille) consultez les documents suivants pour connaître l'utilisation de l’adresse IP et de l’adresse MAC lors d’un événement de basculement :
-
L’unité active utilise toujours les adresses IP et MAC de l’unité principale.
-
Lorsque l’unité active bascule, l’unité en veille adopte les adresses IP et MAC de l’unité défaillante et commence à transmettre le trafic.
-
Lorsque l’unité défaillante est remise en ligne, elle est maintenant en état de veille et prend le relais des adresses IP et MAC de secours.
Toutefois, si l’unité secondaire démarre sans détecter l’unité principale, l’unité secondaire devient l’unité active et utilise ses propres adresses MAC, car elle ne connaît pas les adresses MAC de l’unité principale. Lorsque l’unité principale devient disponible, les adresses MAC de l’unité secondaire (active) changent pour celles de l’unité principale, ce qui peut entraîner une interruption de votre trafic réseau. De même, si vous remplacez l’unité principale par un nouveau matériel, une nouvelle adresse MAC est utilisée.
Si vous rechargez l’unité de secours avec la configuration de basculement désactivée, l’unité de secours démarre en tant qu’unité active et utilise les adresses IP et MAC de l’unité principale. Cela conduit à des adresses IP en double et entraîne des perturbations du trafic réseau. Utilisez la commande configure high-availability resume pour activer le basculement et restaurer le flux de trafic.
Les adresses MAC virtuelles empêchent cette perturbation, car les adresses MAC actives sont connues de l’unité secondaire au démarrage et restent les mêmes dans le cas du nouveau matériel de l’unité principale. Nous vous recommandons de configurer l’adresse MAC virtuelle sur les unités principale et secondaire pour vous assurer que l’unité secondaire utilise les adresses MAC correctes lorsqu’il s’agit de l’unité active, même si elle est mise en ligne avant l’unité principale. Si vous ne configurez pas d'adresses MAC virtuelles, vous devrez peut-être effacer les tableaux ARP sur les routeurs connectés pour restaurer le flux de trafic. appareil de défense contre les menaces n’envoie pas d’ARP gratuits pour les adresses NAT statiques lorsque l’adresse MAC change, de sorte que les routeurs connectés n’apprennent pas le changement d’adresse MAC pour ces adresses.
Adresses MAC virtuelles
L'appareil de défense contre les menaces comporte plusieurs méthodes pour configurer les adresses MAC virtuelles. Nous vous recommandons d’utiliser une seule méthode. Si vous définissez l’adresse MAC à l’aide de plusieurs méthodes, l’adresse MAC utilisée dépend de nombreuses variables et peut ne pas être prédictible.
Pour la capacité multi-instance, le châssis FXOS génère automatiquement uniquement les adresses MAC principales pour toutes les interfaces. Vous pouvez remplacer l’adresse MAC générée par une adresse MAC virtuelle avec les adresses MAC principale et secondaire, mais la prédéfinition de l’adresse MAC secondaire n’est pas essentielle; la définition de l’adresse MAC secondaire garantit que le trafic de gestion vers le périphérique ne sera pas interrompu dans le cas d’une nouvelle unité secondaire matérielle.
Basculement avec état
pendant le basculement dynamique, l’unité active transmet en permanence des informations sur l’état de la connexion à l’unité en veille. Après un basculement, les mêmes informations de connexion sont disponibles sur la nouvelle unité active. Les applications de l’utilisateur final prises en charge ne sont pas tenues de se reconnecter pour conserver la même session de communication.
Fonctionnalités prises en charge
Pour le basculement avec état, les renseignements d’état suivants sont transmis au appareil de défense contre les menaces de secours :
-
table de traduction NAT
-
Les connexions et les états TCP et UDP, y compris les états des connexions HTTP. Les autres types de protocoles IP et ICMP ne sont pas analysés par l'unité active, car ils sont établis sur la nouvelle unité active à l'arrivée d'un nouveau paquet.
-
États de connexion Snort, résultats d’inspection et informations sur les trous d’épingle, y compris une application stricte du protocole TCP.
-
La table ARP
-
La table des ponts de couche 2 (pour les groupes de ponts)
-
La table ISAKMP et IPsec SA
-
La base de données sur les connexions GTP-PDP
-
Sessions de signalisation SIP et trous d'épingle.
-
Tables de routage statiques et dynamiques : le basculement dynamique participe aux protocoles de routage dynamiques, tels que OSPF et EIGRP, de sorte que les itinéraires appris par les protocoles de routage dynamiques sur l'unité active sont conservés dans une table RIB (Routing Information Base) sur l'unité en attente. Lors d’un basculement, les paquets se déplacent normalement avec une perturbation minimale du trafic, car l’unité secondaire active est initialement soumise à des règles qui reflètent l’unité principale. Immédiatement après le basculement, le délai de reconvergence démarre sur l'unité nouvellement active. Ensuite, le numéro de la période pour la table RIB est incrémenté. Pendant la reconvergence, les routes OSPF et EIGRP sont mises à jour avec un nouveau numéro de période. Une fois la minuterie expirée, les entrées de route périmées (déterminées par le numéro de période) sont supprimées du tableau. Le RIB contient ensuite les informations de transfert les plus récentes du protocole de routage sur la nouvelle unité active.
Remarque
Les routages ne sont synchronisés que pour les événements de connexion ou de déconnexion sur une unité active. Si le lien est actif ou inactif sur l’unité de secours, les routages dynamiques envoyés à partir de l’unité active peuvent être perdus. Ce comportement est tout à fait normal et attendu.
-
Serveur DHCP : les baux d’adresses DHCP ne sont pas répliqués. Cependant, un serveur DHCP configuré sur une interface enverra un message ping pour s’assurer qu’une adresse n’est pas utilisée avant d’accorder l’adresse à un client DHCP, donc il n’y a pas d’incidence sur le service. Les informations d’état ne sont pas pertinentes pour le relais DHCP ou DDNS.
-
Décisions relatives à la politique de contrôle d’accès : les décisions relatives à la correspondance du trafic (y compris l’URL, la catégorie d’URL, la géolocalisation, etc.), la détection des intrusions, les programmes malveillants et le type de fichier sont conservées pendant le basculement. Cependant, pour les connexions évaluées au moment du basculement, les mises en garde suivantes doivent être apportées :
-
AVC : Les verdicts d’ID d’application sont répliqués, mais pas les états de détection. Une synchronisation appropriée a lieu tant que les verdicts App-ID sont complets et synchronisés avant le basculement.
-
État de la détection d'intrusion : lors du basculement, une fois que le prélèvement en milieu de flux se produit, de nouvelles inspections sont effectuées, mais les anciens états sont perdus.
-
Blocage des programmes malveillants : l'élimination des fichiers doit être disponible avant le basculement.
-
Détection et blocage du type de fichier : le type de fichier doit être identifié avant le basculement. Si le basculement se produit pendant que le périphérique actif d’origine identifie le fichier, le type de fichier n’est pas synchronisé. Même si votre politique de fichiers bloque ce type de fichier, le nouveau périphérique actif télécharge le fichier.
-
-
Décisions relatives à l'identité de l'utilisateur à partir de la politique d'identité, y compris les correspondances entre l'utilisateur et l'adresse IP recueillies passivement par l'intermédiaire de et de l'annuaire des sessions ISE, ainsi que l'authentification active par le biais du portail captif. Les utilisateurs qui sont en train de s’authentifier activement au moment du basculement peuvent être invités à s’authentifier à nouveau.
-
Network AMP : les recherches au sein du nuage sont indépendantes de chaque périphérique, de sorte que le basculement n’affecte pas cette fonctionnalité en général. Plus précisément :
-
Recherche de signature : si le basculement se produit au milieu d’une transmission de fichier, aucun événement de fichier n’est généré et aucune détection ne se produit.
-
Stockage de fichiers : si le basculement se produit lors du stockage du fichier, il est stocké sur le périphérique actif d’origine. Si le périphérique actif d’origine est tombé en panne pendant le stockage du fichier, le fichier n’est pas stocké.
-
Pré-classification de fichier (analyse locale) : si le basculement se produit au milieu de la pré-classification, la détection échoue.
-
Analyse dynamique de fichier (connectivité au nuage) : en cas de basculement, le système peut transmettre le fichier au nuage.
-
Prise en charge des fichiers d’archive : si le basculement se produit au milieu d’une analyse, le système perd de la visibilité sur le fichier ou l’archive.
-
Blocage personnalisé : en cas de basculement, aucun événement n’est généré.
-
-
Décisions en matière de renseignements sur la sécurité. Cependant, les décisions basées sur le DNS qui sont en cours au moment du basculement ne sont pas prises.
-
VPN d'accès à distance : les utilisateurs finaux du VPN d’accès à distance n’ont pas à s’authentifier ou à reconnecter la session VPN après un basculement. Cependant, les applications fonctionnant sur la connexion VPN pourraient perdre des paquets pendant le processus de basculement et ne pas se rétablir après la perte de paquets.
-
De toutes les connexions, seules celles établies seront répliquées sur l’ASA de secours.
Fonctionnalités non prises en charge
Pour le basculement avec état, les informations d'état suivantes ne sont pas transmises au appareil de défense contre les menaces de secours :
-
Sessions dans des tunnels en texte brut autres que GREv0 et IPv4-en-IP. Les sessions à l’intérieur des tunnels ne sont pas répliquées et le nouveau nœud actif ne pourra pas réutiliser les verdicts d’inspection existants pour faire correspondre les règles de politique correctes.
-
Connexions TLS/SSL déchiffrées : les états de déchiffrement ne sont pas synchronisés et si l’unité active échoue, les connexions déchiffrées seront réinitialisées. De nouvelles connexions devront être établies avec la nouvelle unité active. Les connexions qui ne sont pas déchiffrées (c’est-à-dire celles qui correspondent à une action de règle Ne pas déchiffrer de TLS/SSL) ne sont pas affectées et sont répliquées correctement.
-
Les connexions de contournement d’état TCP
-
Le routage de multidiffusion
Exigences du groupe de ponts pour la haute disponibilité
Il y a des considérations particulières à prendre en matière de haute disponibilité lors de l’utilisation de groupes de ponts.
Lorsque l’unité active bascule sur l’unité en veille, le port du commutateur exécutant le protocole Spanning Tree (STP) peut passer dans un état bloquant pendant 30 à 50 secondes lorsqu’il détecte le changement de topologie. Pour éviter les pertes de trafic sur les interfaces membres du groupe de ponts lorsque le port est dans un état bloquant, vous pouvez configurer l’une des solutions de contournement suivantes :
-
Le port du commutateur est en mode d’accès : activez la fonctionnalité STP PortFast sur le commutateur :
interface interface_id spanning-tree portfastLa fonctionnalité PortFast fait immédiatement passer le port en mode de transfert STP lors de l’établissement de la liaison. Le port participe toujours à STP. Ainsi, si le port doit faire partie de la boucle, le port finit par passer en mode de blocage STP.
-
Si le port de commutation est en mode Trunk, ou si vous ne pouvez pas activer STP PortFast, vous pouvez utiliser l’une des solutions de contournement moins souhaitables suivantes qui a une incidence sur la fonctionnalité de basculement ou la stabilité STP :
-
Désactivez la surveillance sur le groupe de ponts et les interfaces membres.
-
Augmentez le temps d’attente de l’interface dans les critères de basculement à une valeur élevée qui permettra au protocole STP de converger avant que l’unité ne bascule.
-
Réduisez les minuteurs STP sur le commutateur pour permettre au STP de converger plus rapidement que le temps d’attente de l’interface.
-
Surveillance de l'intégrité du basculement
Le périphérique Défense contre les menaces surveille l’intégrité générale et l’intégrité de l’interface de chaque unité. Cette section comprend des informations sur la façon dont lepériphérique Défense contre les menaces effectue les tests pour déterminer l’état de chaque unité.
Surveillance de l'intégrité de l'unité
Le périphérique défense contre les menaces détermine l’intégrité de l’autre unité en surveillant le lien de basculement à l’aide de messages Hello. Lorsqu’une unité ne reçoit pas trois messages Hello consécutifs sur la liaison de basculement, l’unité envoie des messages LANTEST sur chaque interface de données, y compris la liaison de basculement, pour valider si l’homologue réagit ou non. L’action du périphérique défense contre les menaces dépend de la réponse de l’autre unité. Consultez les exemples d’actions suivantes :
-
Si le périphérique défense contre les menaces reçoit une réponse sur le lien de basculement, il ne bascule pas.
-
Si le périphérique défense contre les menaces ne reçoit pas de réponse sur la liaison de basculement, mais qu’il reçoit une réponse sur une interface de données, l’unité ne bascule pas. Le lien de basculement est marqué comme ayant échoué. Vous devez restaurer la liaison de basculement dès que possible, car l’unité ne peut pas basculer sur l’unité de secours lorsque le lien de basculement est inactif.
-
Si le périphérique défense contre les menaces ne reçoit de réponse sur aucune interface, l’unité en veille passe en mode actif et classe l’autre unité comme en panne.
Surveillance d’interfaces
Lorsqu’une unité ne reçoit pas de messages Hello sur une interface surveillée pendant 15 secondes, elle exécute des tests d’interface. Si l’un des tests d’interface échoue pour une interface, mais que cette même interface sur l’autre unité continue de transmettre le trafic avec succès, l’interface est considérée comme ayant échoué et lepériphérique arrête d’exécuter les tests.
Si le seuil que vous avez défini pour le nombre d'interfaces défaillantes est atteint (voir ) et que l'unité active a plus d'interfaces défaillantes que l'unité en attente, un basculement se produit. Si une interface échoue sur les deux unités, les deux interfaces passent à l’état « Inconnu » et ne sont pas prises en compte dans la limite de basculement définie par la politique d’interface de basculement.
Une interface devient de nouveau opérationnelle si elle reçoit du trafic. Un périphérique défaillant passe en mode veille si le seuil de défaillance de l’interface n’est plus atteint.
Si une interface a des adresses IPv4 et IPv6 configurées, le périphérique utilise les adresses IPv4 pour effectuer la surveillance de l’intégrité. Si une interface n’a que des adresses IPv6 configurées, le périphérique utilise la découverte des voisins IPv6 au lieu d’ARP pour effectuer les tests de surveillance de l’intégrité. Pour le test de ping de diffusion, le périphérique utilise l’adresse de tous les nœuds IPv6 (FE02::1).
Tests d’interface
Lepériphérique Défense contre les menaces utilise les tests d’interface suivants. La durée de chaque test est d’environ 1,5 seconde.
-
Test de liaison (Active/En panne) : test de l'état de l'interface. Si le test de liaison active/désactivée indique que l’interface est en panne, lepériphérique la considère comme ayant échoué et les tests s’arrêtent. Si l’état est Activé, lepériphérique effectue le test d’activité réseau.
-
Test d’activité réseau : test d’activité réseau reçu. Au début du test, chaque unité efface son nombre de paquets reçus pour ses interfaces. Dès qu’une unité reçoit des paquets admissibles pendant le test, l’interface est considérée comme opérationnelle. Si les deux unités reçoivent du trafic, les tests s’arrêtent. Si une unité reçoit du trafic et l’autre n’en reçoit pas, l’interface de l’unité qui ne reçoit pas de trafic est considérée comme défaillante et les tests s’arrêtent. Si aucune des unités ne reçoit de trafic, lepériphérique démarre le test ARP.
-
Test ARP : Un test des réponses ARP réussies. Chaque unité envoie une seule requête ARP pour l’adresse IP dans l’entrée la plus récente de son tableau ARP. Si l’unité reçoit une réponse ARP ou un autre trafic réseau pendant le test, l’interface est considérée comme opérationnelle. Si l’unité ne reçoit pas de réponse ARP, lepériphérique envoie une seule requête ARP pour l’adresse IP dans l’entrée suivante du tableau ARP. Si l’unité reçoit une réponse ARP ou un autre trafic réseau pendant le test, l’interface est considérée comme opérationnelle. Si les deux unités reçoivent du trafic, les tests s’arrêtent. Si une unité reçoit du trafic et l’autre n’en reçoit pas, l’interface de l’unité qui ne reçoit pas de trafic est considérée comme défaillante et les tests s’arrêtent. Si aucune des unités ne reçoit de trafic, lepériphérique démarre le test ping de diffusion.
-
Test de ping de diffusion : un test de réponses au ping réussies. Chaque unité envoie un message Ping de diffusion, puis compte tous les paquets reçus. Si l’unité reçoit des paquets pendant le test, l’interface est considérée comme opérationnelle. Si les deux unités reçoivent du trafic, les tests s’arrêtent. Si une unité reçoit du trafic et l’autre n’en reçoit pas, l’interface de l’unité qui ne reçoit pas de trafic est considérée comme défaillante et les tests s’arrêtent. Si aucune des unités ne reçoit de trafic, les tests recommencent avec le test ARP. Si les deux unités continuent de ne recevoir aucun trafic venant des tests ARP et de ping de diffusion, ces tests continueront à se dérouler à l'infini.
État d’interface
Les interfaces surveillées peuvent avoir l’état suivant :
-
Inconnu : état initial. Cet état peut également signifier qu’il ne peut pas être déterminé.
-
Normal : l’interface reçoit du trafic.
-
Normal (en attente) : l’interface est opérationnelle, mais n’a pas encore reçu de paquet Hello de l’interface correspondante sur l’unité homologue.
-
Normal (Non surveillée) : l’interface est opérationnelle, mais n’est pas surveillée par le processus de basculement.
-
En test : les messages Hello ne sont pas entendus sur l’interface pendant cinq cycles d'interrogation.
-
Liaison en panne : l’interface ou le VLAN est administrativement inactif.
-
Liaison en panne (en attente) : l’interface ou le VLAN est en panne administrative et n’a pas encore reçu de paquet Hello de l’interface correspondante sur l’unité homologue.
-
Liaison en panne (non surveillée) : l’interface ou le VLAN est en panne administrative, mais n’est pas surveillée par le processus de basculement.
-
Aucune liaison : le lien physique de l’interface est inactif.
-
Pas de liaison (en attente) : le lien physique de l’interface est inactif et n’a pas encore reçu de paquet Hello de l’interface correspondante sur l’unité homologue.
-
Pas de liaison (non surveillée) : le lien physique de l’interface est inactif, mais n’est pas surveillé par le processus de basculement.
-
Échec : aucun trafic n’est reçu sur l’interface, mais le trafic est diffusé sur l’interface homologue.
Déclencheurs de basculement et heures de
Les événements suivants déclenchent le basculement dans une paire à haute disponibilité Firepower :
-
Plus de 50 % des instances Snort sur l’unité active sont en panne.
-
L’espace disque de l’unité active est plein à plus de 90 %.
-
La commande no failover active est exécutée sur l’unité active ou la commande failover active est exécutée sur l’unité de secours.
-
L’unité active comporte plus d’interfaces défaillantes que l’unité en veille.
-
La défaillance d’interface sur le périphérique actif dépasse le seuil configuré.
Par défaut, la défaillance d’une seule interface entraîne le basculement. Vous pouvez modifier la valeur par défaut en configurant un seuil pour le nombre d’interfaces ou un pourcentage d’interfaces surveillées qui doivent échouer pour que le basculement se produise. Si le seuil est dépassé sur le périphérique actif, le basculement se produit. Si le seuil est dépassé sur le périphérique en veille, l’unité passe à l’état Fail (échec).
Pour modifier les critères de basculement par défaut, saisissez la commande suivante en mode de configuration globale :
Tableau 1. Commande
Objectif
failover interface-policy num [%]
hostname (config)# failover interface-policy 20%Modifie les critères de basculement par défaut.
Lorsque vous spécifiez un nombre spécifique d’interfaces, l’argument num peut être compris entre 1 et 250.
Lors de la spécification d’un pourcentage d’interfaces, l’argument num peut être compris entre 1 et 100.
Le tableau suivant présente les événements déclencheurs de basculement et la synchronisation de détection des défaillances. En cas de basculement, vous pouvez afficher la raison du basculement dans le centre de messages, ainsi que les diverses opérations relatives à la paire à haute disponibilité. Vous pouvez configurer ces seuils sur une valeur comprise dans la plage minimale et maximale spécifiée.
|
Événement déclenchant la de basculement |
Minimum |
Par défaut |
Maximum |
|---|---|---|---|
|
L'unité active n'est plus alimentée, le matériel tombe en panne, le logiciel est rechargé ou se bloque. Lorsque l’un de ces événements se produit, les interfaces surveillées ou le lien de basculement ne reçoivent aucun message Hello. |
800 milliseconde |
15 secondes |
45 secondes |
|
Lien physique de l’interface de la unité active en panne. |
500 millisecondes |
5 secondes |
15 secondes |
|
L’interface de l’unité active est active, mais un problème de connexion entraîne des tests d’interface. |
5 secondes |
25 secondes |
75 secondes |
À propos du basculement actif/de secours
Le basculement actif/en veille vous permet d’utiliser un appareil de défense contre les menaces de secours pour reprendre les fonctionnalités d’une unité en panne. Lorsque l’unité active tombe en panne, l’unité en veille devient l’unité active.
Rôles principal/secondaire et état actif/de secours
Lors de la configuration du basculement entre actif/veille, vous configurez une unité comme principale et l’autre comme secondaire. Lors de la configuration, les politiques de l’unité principale sont synchronisées avec celles de l’unité secondaire. À ce stade, les deux unités agissent comme un seul périphérique pour la configuration des périphériques et des politiques. Cependant, pour les événements, les tableaux de bord, les rapports et la surveillance de l’intégrité, ils continuent de s’afficher comme des périphériques distincts.
Les principales différences entre les deux unités d’une paire de basculement dépendent de l’unité active et de l’unité en veille, à savoir les adresses IP à utiliser et l’unité transmettant activement le trafic.
Cependant, il existe quelques différences entre les unités en fonction de l’unité principale (comme spécifié dans la configuration) et de l’unité secondaire :
-
L’unité principale devient toujours l’unité active si les deux unités démarrent en même temps (et ont le même état de fonctionnement opérationnel).
-
Les adresses MAC de l’unité principale sont toujours associées aux adresses IP actives. L’exception à cette règle se produit lorsque l’unité secondaire devient active et ne peut pas obtenir les adresses MAC de l’unité principale sur la liaison de basculement. Dans ce cas, les adresses MAC des unités secondaires sont utilisées.
Détermination de l’unité active au démarrage
L’unité active est déterminée par les éléments suivants :
-
Si une unité démarre et détecte un homologue qui fonctionne déjà comme actif, elle devient l’unité de secours.
-
Si une unité démarre et ne détecte pas d’homologue, elle devient l’unité active.
-
Si les deux unités démarrent simultanément, l’unité principale devient l’unité active et l’unité secondaire devient l’unité de secours.
Événements de basculement
Dans le cas d'un basculement actif/de secours, le basculement se produit de manière unitaire.
Le tableau suivant présente l’action de basculement pour chaque défaillance. Pour chaque défaillance, le tableau indique la politique de basculement (basculement ou absence de basculement), l’action prise par l’unité active, l’action entreprise par l’unité de secours, et toute remarque spéciale sur la condition et les actions de basculement.
|
Défaillance |
Politique |
Action de l’unité active |
Action de l’unité de secours |
Notes |
|---|---|---|---|---|
|
Défaillance de l’unité active (alimentation ou matérielle) |
Basculement |
S.O. |
Devenir active Marquer l'unité active comme défaillante |
Aucun message Hello n’est reçu sur l’interface surveillée ou sur la liaison de basculement. |
|
L’unité précédemment active récupère |
Aucun basculement |
Devient l'unité de secours |
Aucune action |
Aucun. |
|
Défaillance de l’unité de secours (alimentation ou matériel) |
Aucun basculement |
Marquer l'unité de secours come défaillante |
S.O. |
Lorsque l’unité de secours est marquée comme défaillante, l’unité active ne tente pas de basculer, même si le seuil de défaillance de l’interface est dépassé. |
|
Échec du la liaison de basculement pendant l’opération |
Aucun basculement |
Marquer la liaison de basculement comme défaillante |
Marquer la liaison de basculement comme défaillante |
Vous devez restaurer la liaison de basculement dès que possible, car l’unité ne peut pas basculer vers l’unité de secours lorsque la liaison de basculement est inactive. |
|
Échec de la liaison de basculement au démarrage |
Aucun basculement |
Devenir active Marquer la liaison de basculement comme défaillante |
Devenir active Marquer la liaison de basculement comme défaillante |
Si la liaison de basculement est interrompue au démarrage, les deux unités deviennent actives. |
|
Échec du lien avec l’état |
Aucun basculement |
Aucune action |
Aucune action |
Les informations d’état deviennent obsolètes et les sessions sont interrompues en cas de basculement. |
|
Défaillance de l'interface sur l'unité active supérieure au seuil |
Basculement |
Marquer l'unité active comme défaillante |
Devenir active |
Aucun. |
|
Défaillance de l'interface sur l'unité de secours supérieure au seuil |
Aucun basculement |
Aucune action |
Marquer l'unité de secours come défaillante |
Lorsque l’unité de secours est marquée comme en panne, l’unité active ne tente pas de basculer, même si le seuil de défaillance de l’interface est dépassé. |



 )
) )
) Commentaires
Commentaires