This topic explains the disaster recovery solution using a Warm Standby APIC for Cisco APIC clusters, which continuously synchronizes data from active nodes, enabling efficient restoration and rebuilding of the cluster even when database shards are lost.
A Warm Standby APIC is a disaster recovery solution for Cisco APIC clusters that continuously synchronizes all data from active APIC nodes, enabling restoration and rebuilding of the APIC cluster even when some or all database shards are lost.
-
Continuously synchronizes all data from active APIC nodes.
-
Enables restoration and rebuilding of the APIC cluster even when some or all database shards are lost.
-
Allows for faster and more effective replacement of failed APIC nodes compared to Cold Standby APICs.
Disaster Recovery with Warm Standby APIC
Starting from Cisco APIC 6.1(2), Standby APIC can be set up as a Warm Standby APIC as opposed to a Cold Standby APIC. Unlike Cold Standby APIC, which does not contain any data until it’s promoted to active, Warm Standby APIC constantly synchronizes all data from the active APIC nodes while it’s still in the standby role. This enables you to rebuild the APIC cluster by using the Warm Standby APIC when some or all pieces of the database distributed across the APIC cluster are lost forever.
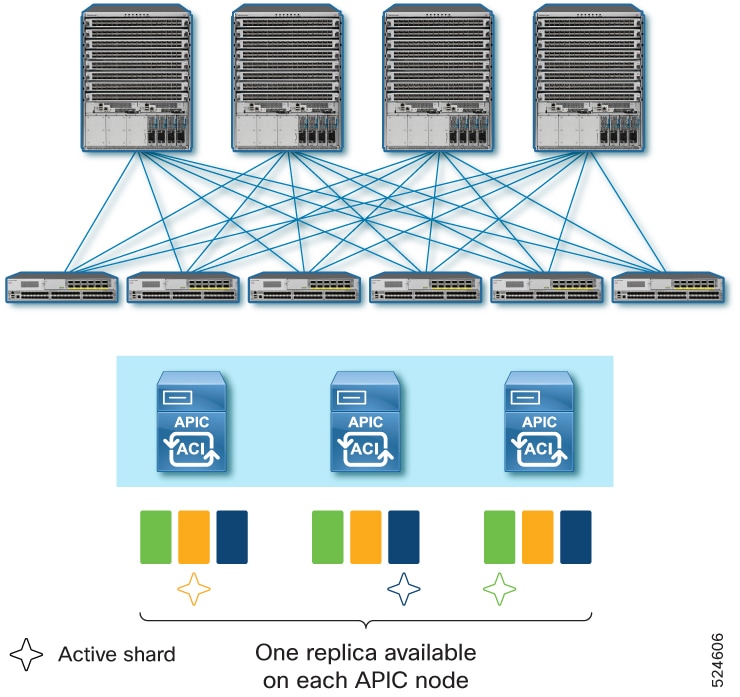
APIC Cluster uses a database technology called sharding and replica. The data of the ACI fabric is divided into smaller, separate parts called shards and distributed across active APIC nodes. Each shard is replicated up to three replicas regardless of the size of your cluster. For instance, if you have a cluster of 5 APIC nodes, one shard is replicated on APIC 1, 2, and 3 while another shard is replicated on APIC 3, 4, and 5. If you lose three or more APIC nodes in the cluster, data for some shard(s) will be completely lost even if you still have some active APIC nodes. In such a case, the Cold Standby APIC cannot replace those lost APIC nodes because the Cold Standby APIC does not contain any data by itself and cannot restore those lost shards from any of the remaining active APIC nodes. Similarly, if you lost all APIC nodes in the cluster, Cold Standby APIC cannot replace them either regardless of the number of APIC nodes you lost.
For these scenarios, a Warm Standby APIC can be used. Some practical examples of such data loss scenarios are as follows:
-
Data loss scenario 1: In a multi-pod deployment where you have APIC 1, 2, and 3 in Pod 1 and APIC 4 and 5 in Pod 2, if Pod 1 goes down because of a disaster, such as flood, fire, earthquake, and so on, three APIC nodes are lost. This means some database shards are completely lost.
-
Data loss scenario 2: In a multi-pod deployment with Pod 1 and 2 in the same location while Pod 3 and 4 in another location where you have APIC 1 and 2 in Pod 1, APIC 3 and 4 in Pod 2, APIC 5 and 6 in Pod 3 and APIC 7 in Pod 4, if the location with Pod 1 and 2 has a disaster, four APICs (APIC 1, 2, 3 and 4) are lost. This means some database shards are completely lost.
-
Data loss scenario 3: In a multi-pod deployment where you have APIC 1 and 2 in Pod 1, APIC 3 in Pod 2 and no active APIC in Pod 3, if Pod 1 and 2 go down because of a disaster, all data of the fabric is lost in the cluster as you lose all active APIC nodes.
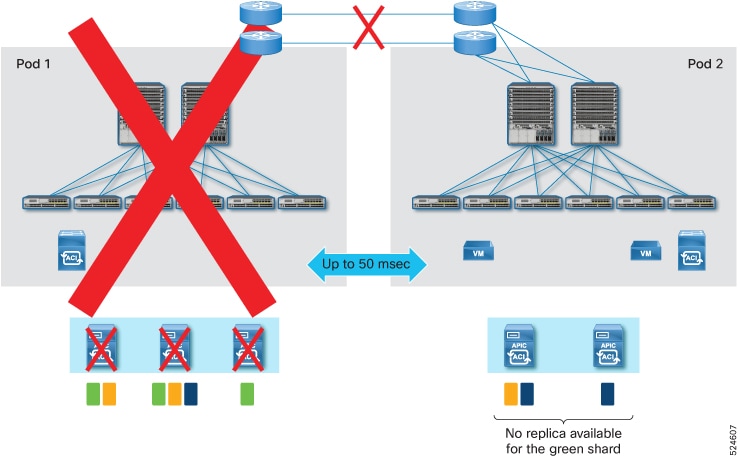
For these scenarios, if you have a Warm Standby APIC in the healthy pod/site, you can restore the lost data shard and restore the fabric because the Warm Standby APIC had all shards synchronized from all the active APIC nodes while they were still operational. This is not possible with the Cold Standby APIC.
These examples are all multi-pod deployments because it’s unlikely for a single pod deployment to lose more than three APIC nodes or all APIC nodes in the cluster while the standby APIC nodes are intact. Nevertheless, a Warm Standby APIC is supported and functions in the same way for both multi-pod and single pod deployments.
As shown with these examples, the new capability introduced with the Warm Standby APIC is disaster recovery where some or all the database shards are lost and the APIC cluster needs to be re-built, in addition to the capability of a faster and easier replacement of an active APIC node which is supported by both Warm and Cold Standby APIC.
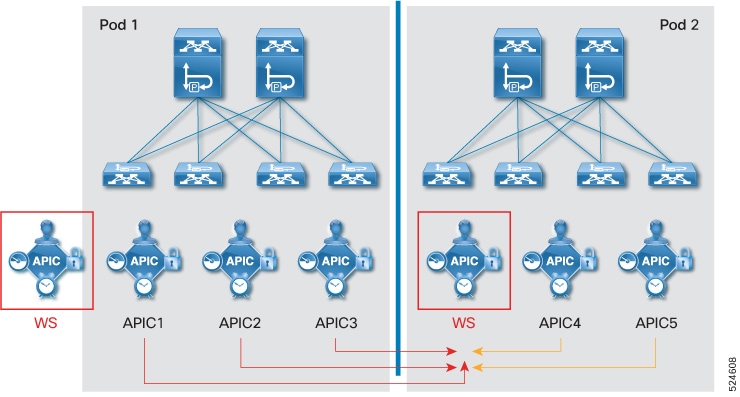
When you need to replace one active APIC node with a Warm or Cold Standby APIC node, the replacement operation is triggered from one of the remaining healthy active APIC nodes. However, the promotion of the Warm Standby APIC to rebuild the cluster in the case of data loss is not performed via the remaining healthy active APIC nodes because there may be no active APIC nodes left. It can be performed via the GUI or REST API on one of the Warm Standby APIC nodes. This always promotes the Warm Standby APIC to APIC 1 such that it can be the starting point of the disaster recovery. See the Recover the APIC cluster using Warm Standby and the GUI section for details.
For Warm Standby APIC to restore the fabric from disastrous events, it is recommended to have one Warm Standby APIC node at a minimum on each failure domain which may be a pod or a geographical site.
Example: Warm Standby APIC in Disaster Recovery
In a multi-pod deployment, if Pod 1 is lost due to a disaster and a Warm Standby APIC is present in another pod, the lost data shards can be restored and the fabric rebuilt using the synchronized data from the Warm Standby APIC.