
Secure Firewall 3100/4200에 대한 클러스터링 정보
이 섹션에서는 클러스터링 아키텍처 및 이러한 아키텍처의 작동 방식에 대해 설명합니다.
클러스터를 네트워크에 맞게 활용하는 방법
클러스터는 하나의 유닛으로 작동하는 여러 개의 방화벽으로 구성됩니다. 클러스터로 작동하려면 방화벽에는 다음과 같은 인프라가 필요합니다.
-
클러스터 내 커뮤니케이션을 위한 분리된 고속 백플레인 네트워크(또는 클러스터 제어 링크라고 함)
-
구성 및 모니터링을 지원하는 각 방화벽에 대한 관리 액세스
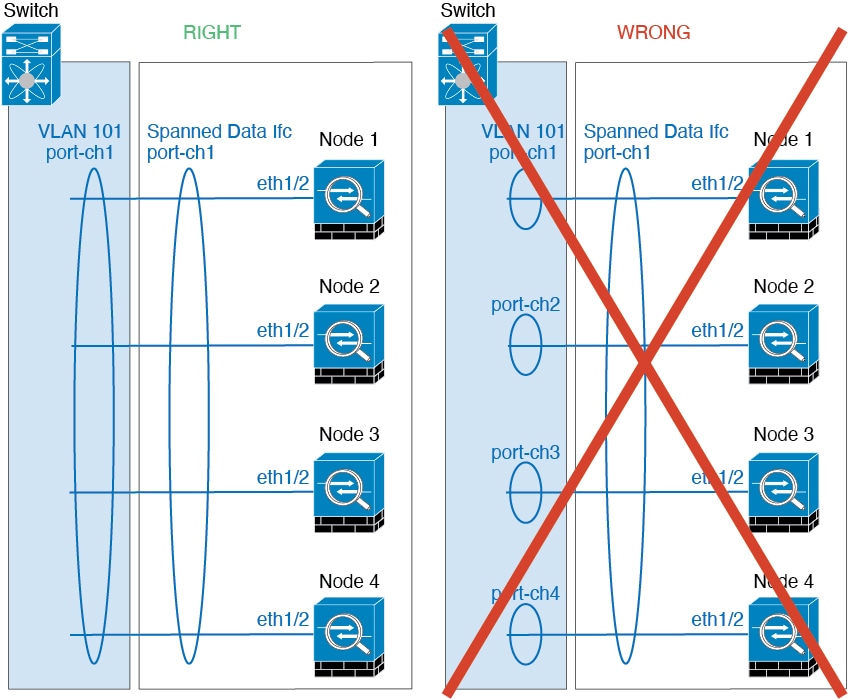
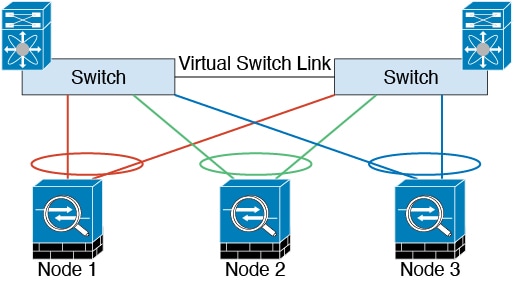
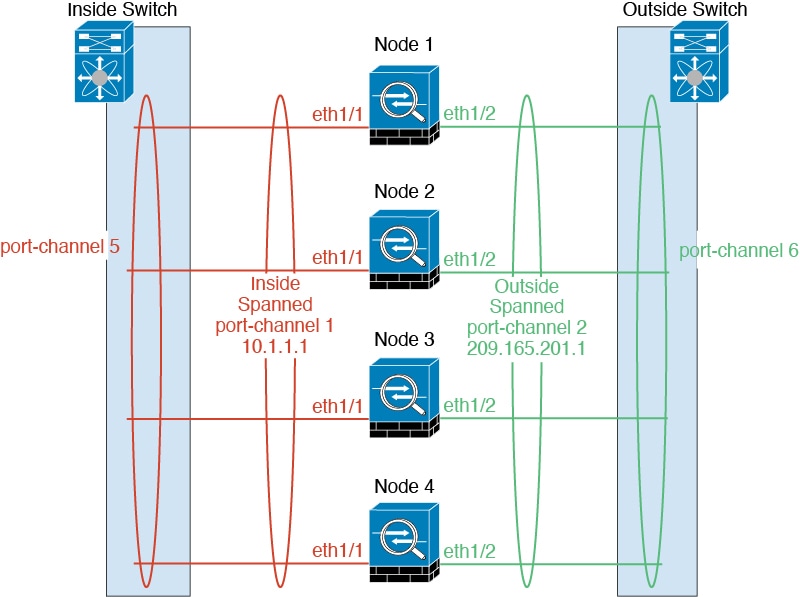
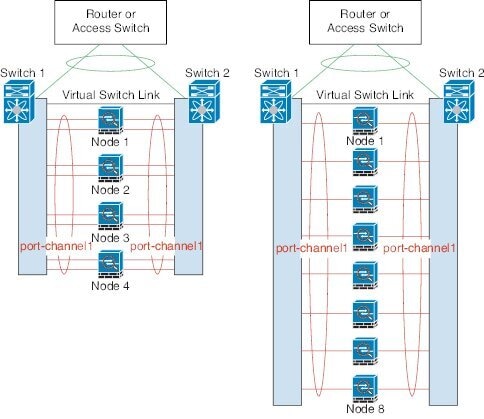
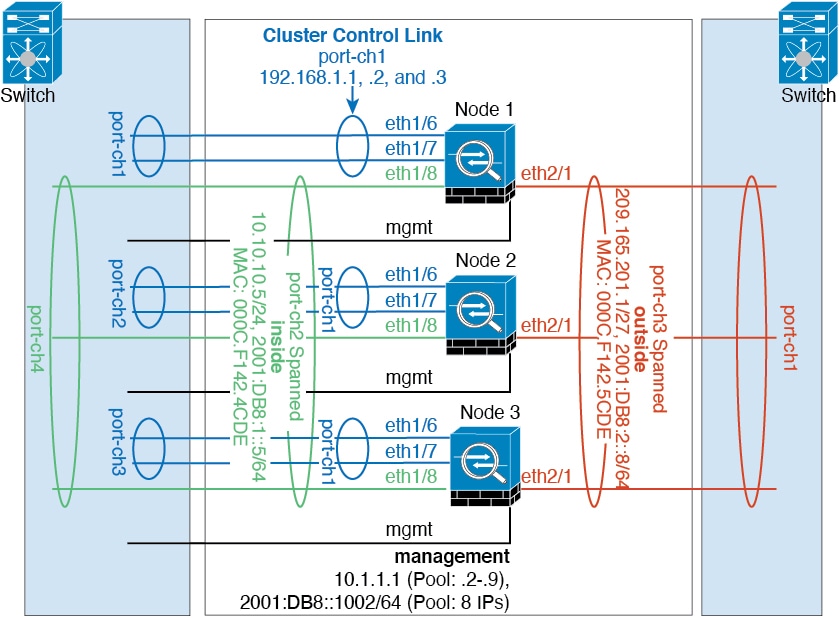
네트워크에 클러스터를 배치할 경우, 업스트림 및 다운스트림 라우터에서는 스팬 EtherChannels 중에서 한 방법을 사용하여 클러스터로 들어오고 나가는 데이터의 로드 밸런싱을 수행할 수 있어야 합니다. 클러스터의 여러 멤버에 대한 인터페이스는 단일 EtherChannel로 그룹화되며, EtherChannel은 유닛 간의 로드 밸런싱을 수행합니다.
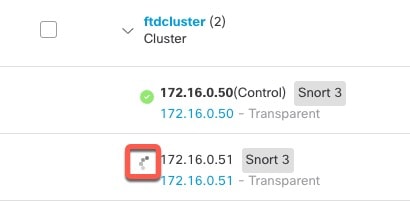
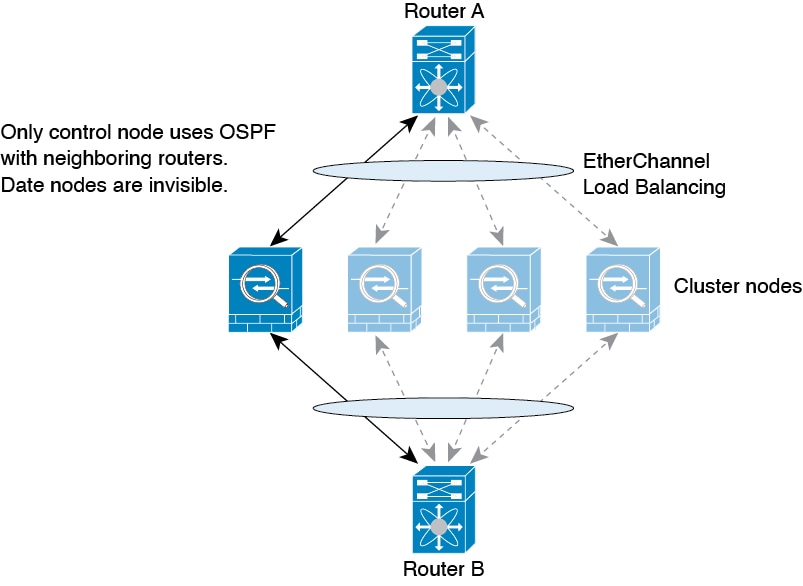
제어 및 데이터 노드 역할
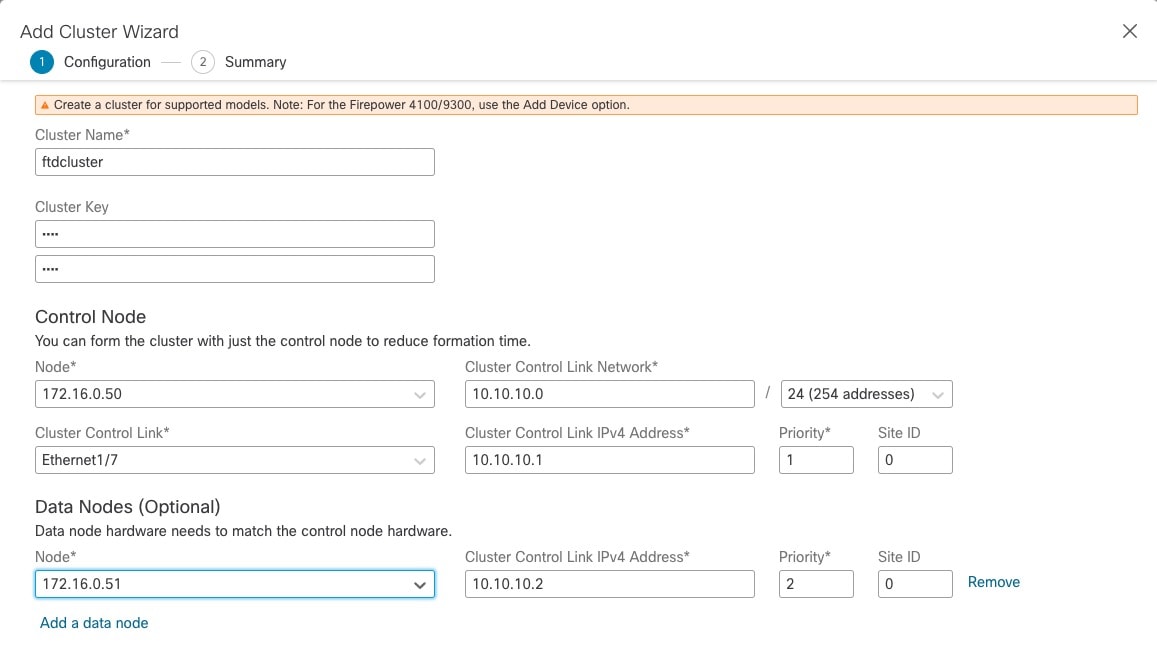
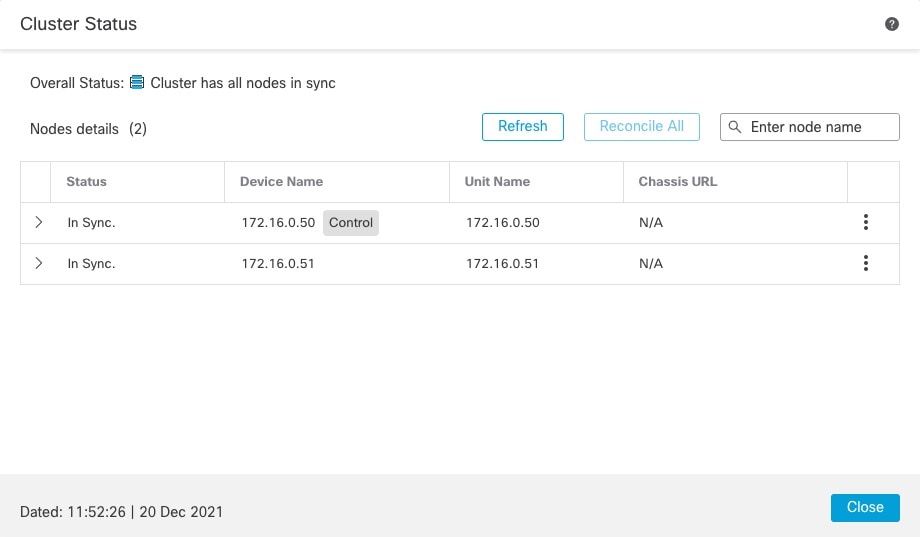
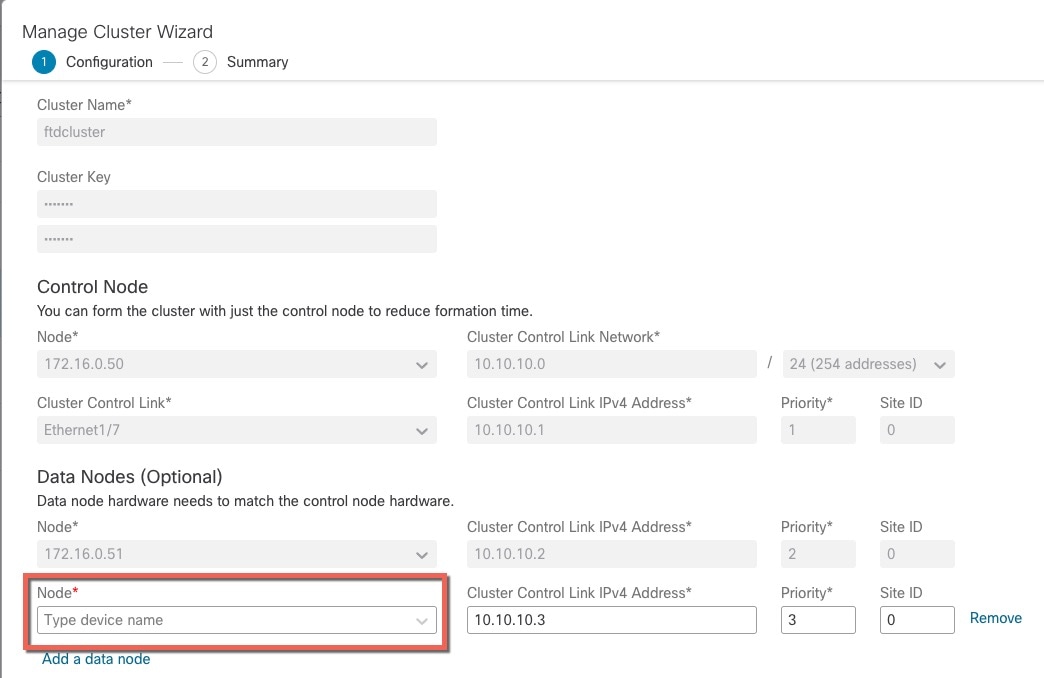
클러스터의 멤버 중 하나는 제어 노드입니다. 여러 클러스터 노드가 동시에 온라인 상태가 되면 의 우선 순위 설정에 따라 제어 노드가 결정됩니다. 우선순위는 1에서 100까지 1이 가장 높은 우선순위입니다. 다른 모든 멤버는 데이터 노드입니다. 클러스터를 처음 생성할 때 제어 노드가 될 노드를 지정하면 클러스터에 추가된 첫 번째 노드이기 때문에 제어 노드가 됩니다.
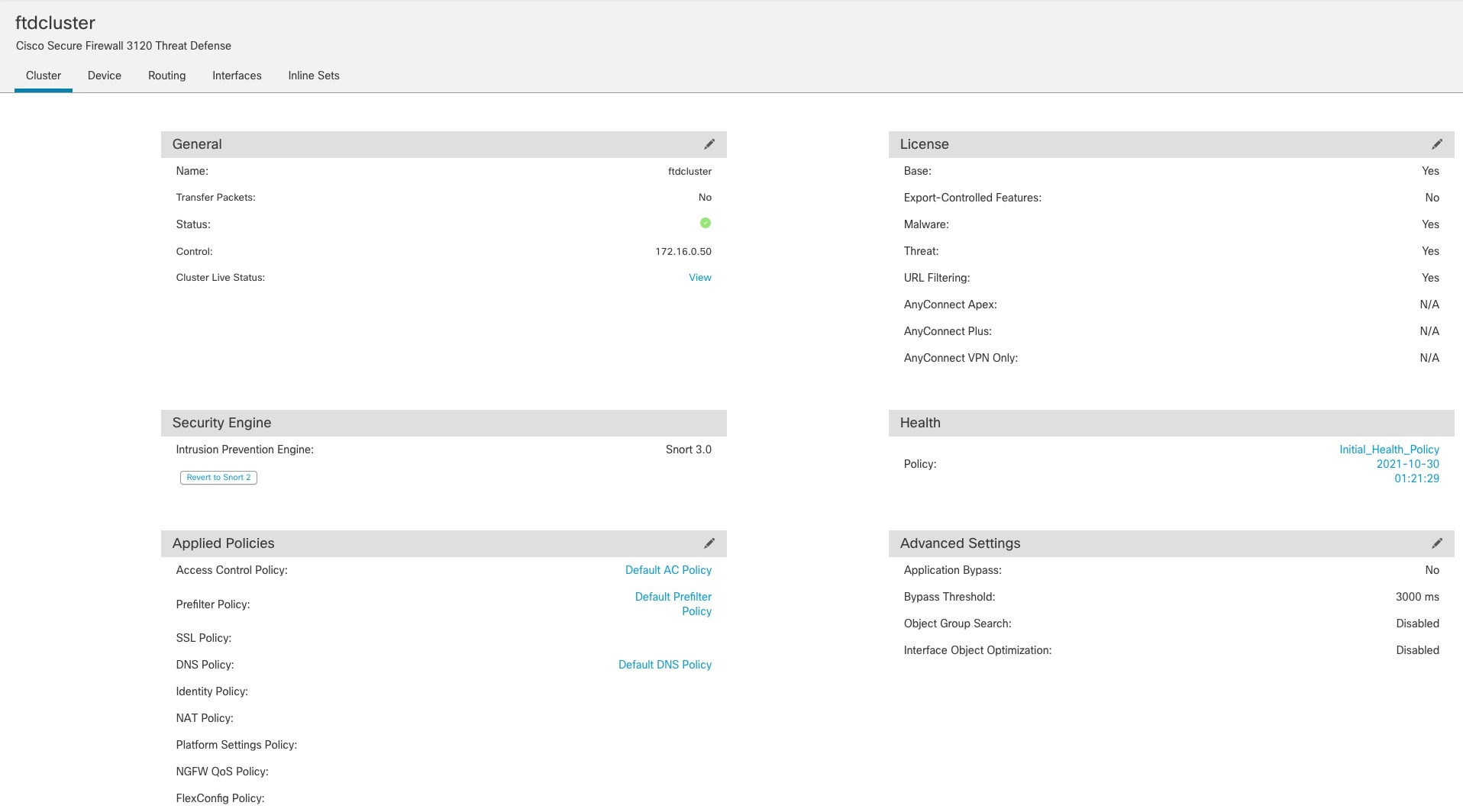
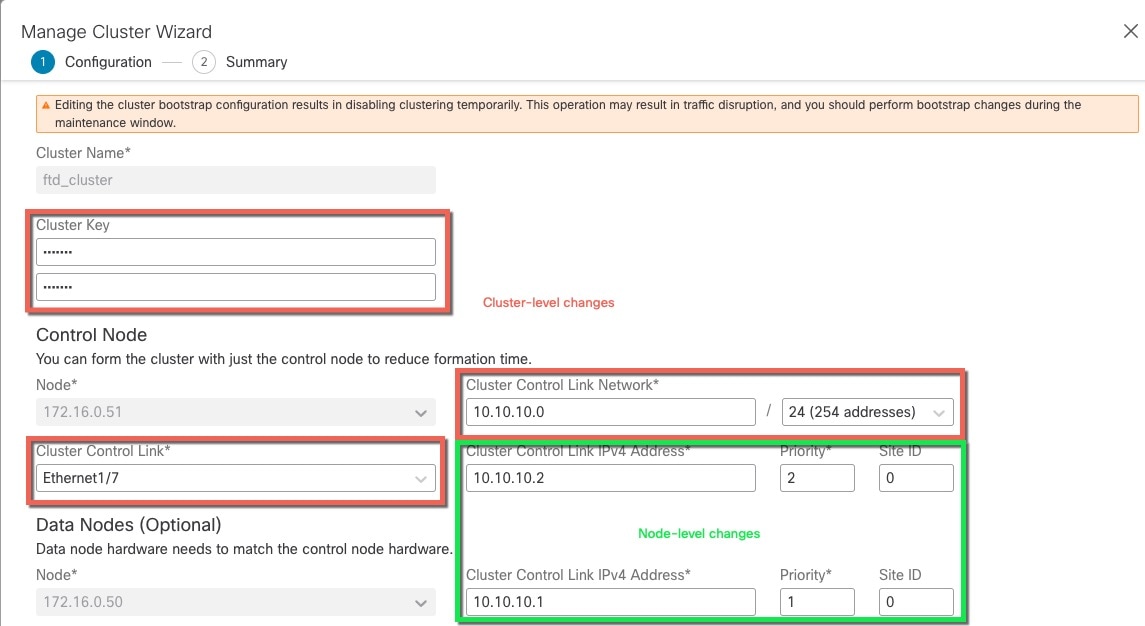
클러스터의 모든 노드에서는 동일한 구성을 공유합니다. 처음에 제어 노드로 지정하는 노드는 클러스터에 참가할 때 데이터 노드의 구성을 덮어쓰므로 클러스터를 구성하기 전에 제어 노드에서 초기 구성만 수행하면 됩니다.
일부 기능은 클러스터로 확장되지 않으며, 제어 노드에서 이러한 기능에 대한 모든 트래픽을 처리합니다.
클러스터 인터페이스
데이터 인터페이스를 스팬 EtherChannel. 자세한 내용은 클러스터 인터페이스 정보를 참조하십시오.
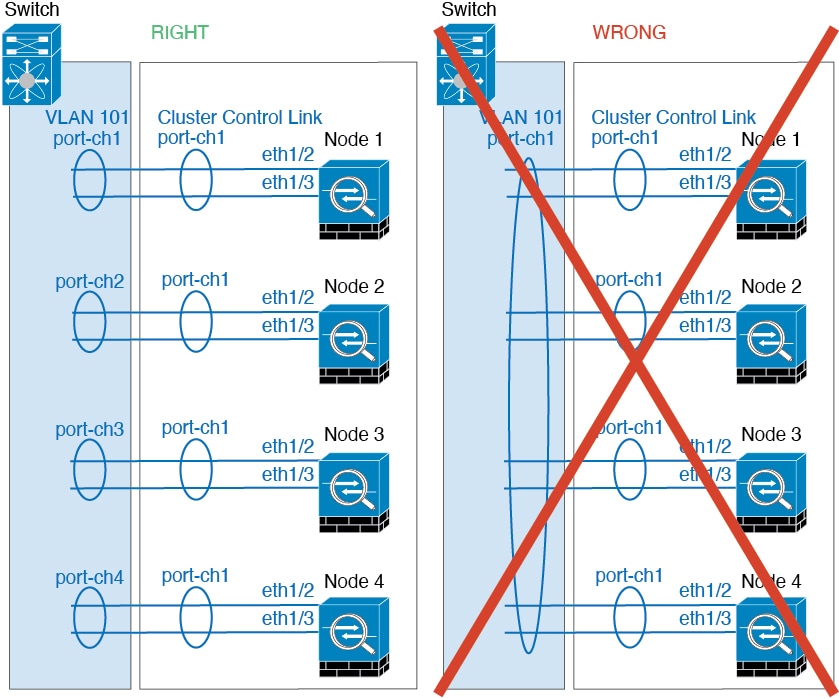
클러스터 제어 링크
각 유닛에서는 최소 1개의 하드웨어 인터페이스를 클러스터 제어 링크로 지정해야 합니다. 자세한 내용은 클러스터 제어 링크를 참조하십시오.
구성 복제
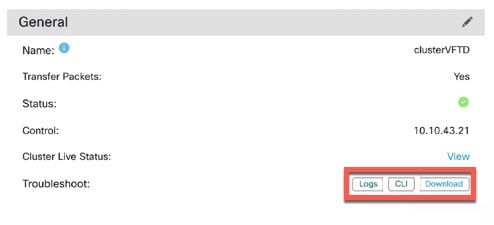
클러스터의 모든 노드에서는 단일 구성을 공유합니다. 제어 노드에서는 구성만 변경할 수 있으며(부트스트랩 구성 예외), 변경 사항은 클러스터의 모든 다른 노드에 자동으로 동기화됩니다.
관리 네트워크
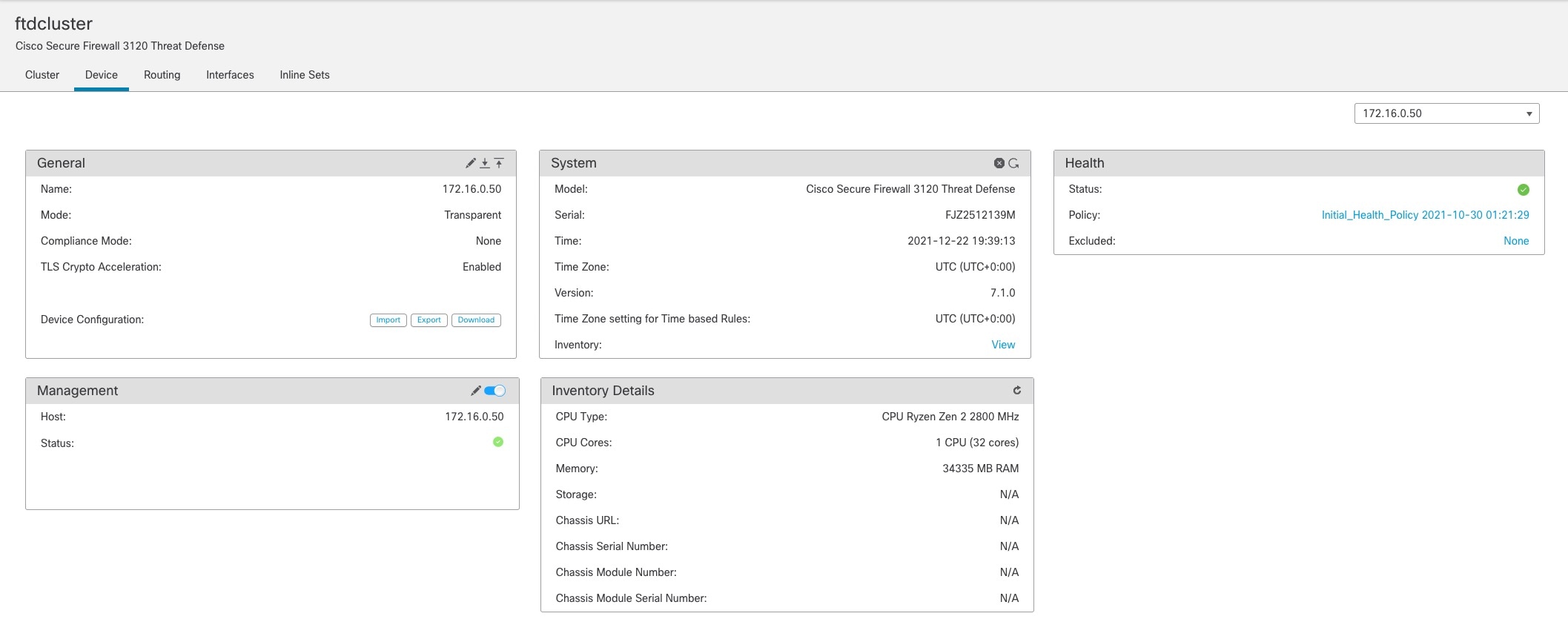
관리 인터페이스를 사용하여 각 노드를 관리해야 합니다. 데이터 인터페이스에서의 관리는 클러스터링에서 지원되지 않습니다.
 )
)
 )
)
 )
)





 )
)

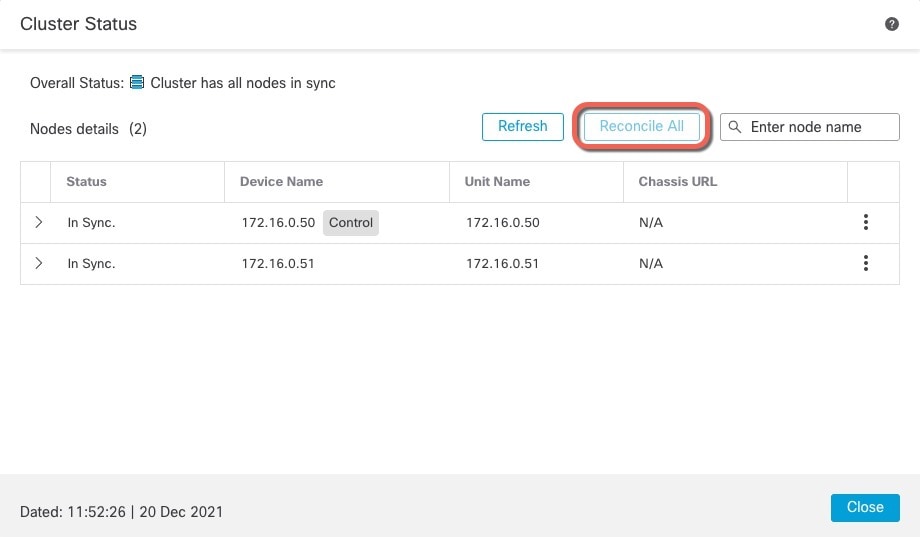
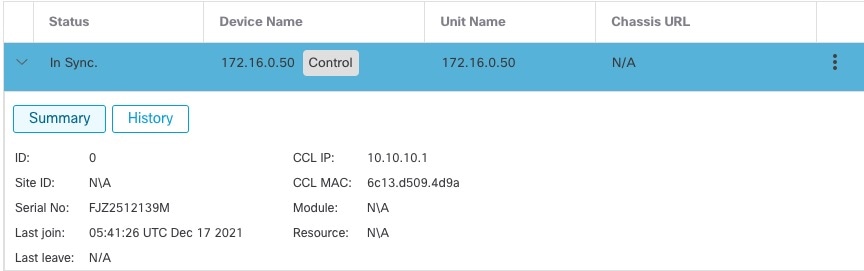
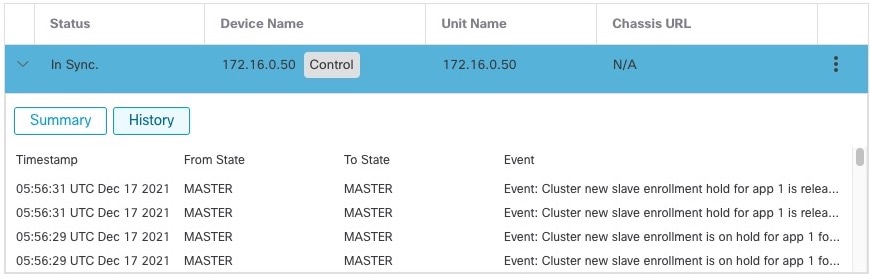
 )
)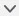 )
)
 피드백
피드백