Firepower 4100/9300 섀시 클러스터링 정보
Firepower 4100/9300 섀시에서 클러스터를 구축할 때는 다음 작업이 수행됩니다.
-
네이티브 인스턴스 클러스터링의 경우: 노드 간 통신에 사용되는 클러스터 제어 링크(기본값: port-channel 48)를 생성합니다.
다중 인스턴스 클러스터링의 경우에는 하나 이상의 클러스터 유형 Etherchannel에서 하위 인터페이스를 사전 구성해야 합니다. 각 인스턴스에는 자체 클러스터 제어 링크가 필요 합니다.
단일 Firepower 9300 섀시 내에서 보안 모듈로 격리된 클러스터의 경우 이 링크는 클러스터 통신에 Firepower 9300 백플레인을 활용합니다.
다중 섀시 클러스터링의 경우, 섀시 간의 통신을 위해 물리적 인터페이스를 이 EtherChannel에 수동으로 할당해야 합니다.
-
애플리케이션 내부에 클러스터 부트스트랩 구성을 생성합니다.
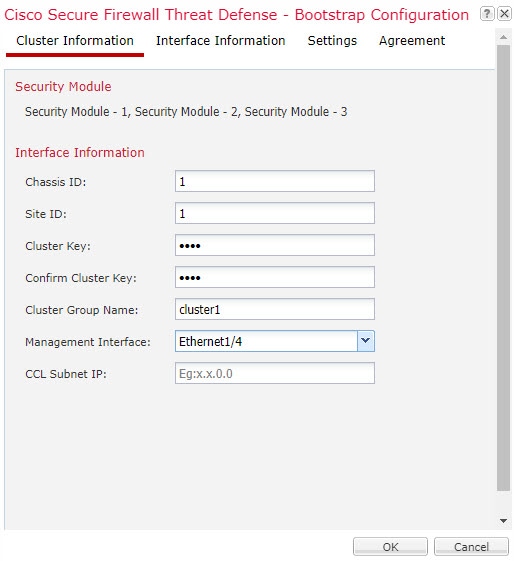
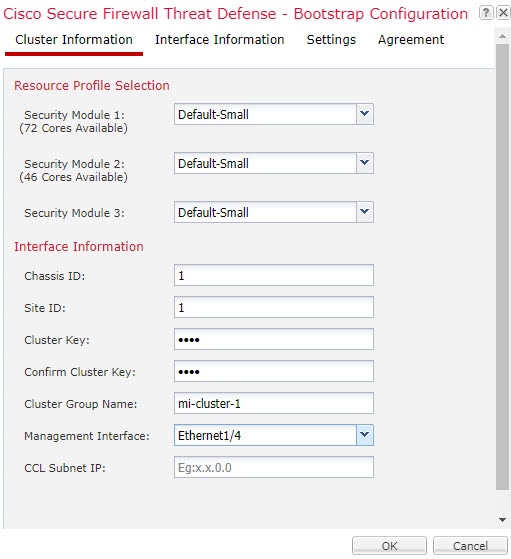
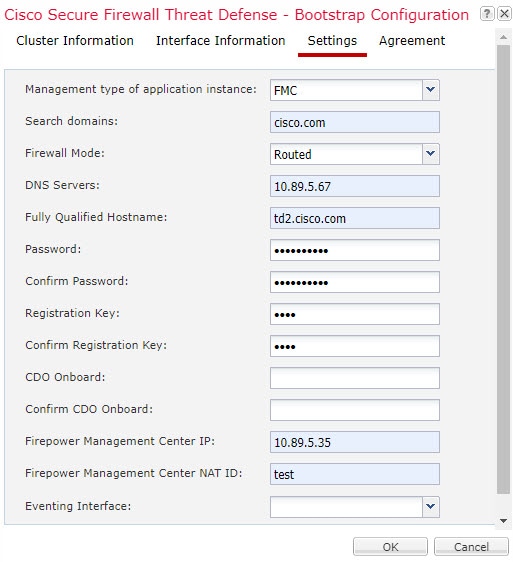
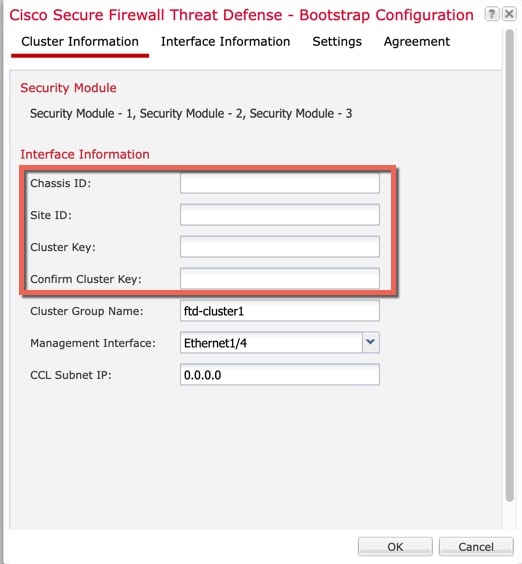
클러스터를 구축할 때, 섀시 수퍼바이저는 클러스터 이름, 클러스터 제어 링크 인터페이스 및 기타 클러스터 설정을 포함하는 각 유닛에 최소한의 부트스트랩 구성을 푸시합니다.
-
데이터 인터페이스를 Spanned 인터페이스로 클러스터에 할당합니다.
단일 Firepower 9300 섀시 내에서 보안 모듈로 격리된 클러스터의 경우, 다중 섀시 클러스터링과 마찬가지로 Spanned 인터페이스는 EtherChannel로 제한되지 않습니다. Firepower 9300 수퍼바이저는 EtherChannel 기술을 내부에 사용하여 트래픽을 공유 인터페이스의 다중 모듈에 로드 밸런싱하므로 모든 데이터 인터페이스 유형이 Spanned(스팬) 모드에서 작동합니다. 다중 섀시 클러스터링의 경우, 모든 데이터 인터페이스에 Spanned EtherChannel을 사용해야 합니다.

참고
개별 인터페이스는 관리 인터페이스를 제외하고 지원되지 않습니다.
-
관리 인터페이스를 클러스터의 모든 유닛에 할당합니다.
클러스터링에 대한 자세한 내용은 다음 섹션을 참고하십시오.
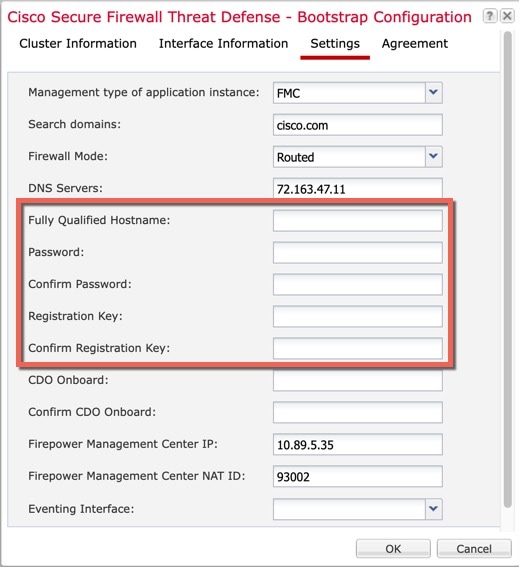
부트스트랩 컨피그레이션
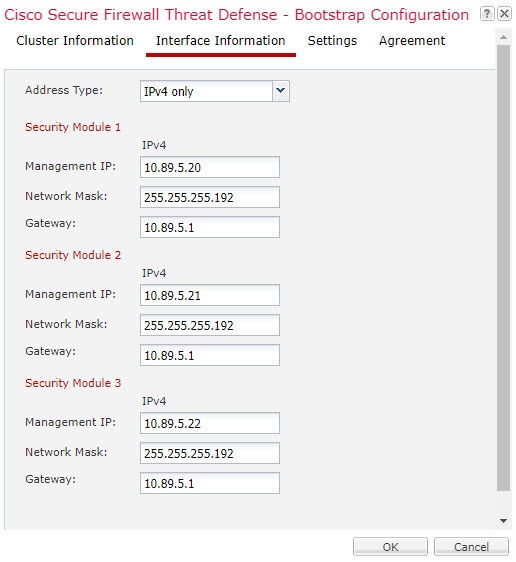
클러스터를 구축할 때, Firepower 4100/9300 섀시 수퍼바이저는 클러스터 이름, 클러스터 제어 링크 인터페이스 및 기타 클러스터 설정을 포함하는 각 유닛에 최소한의 부트스트랩 구성을 푸시합니다.
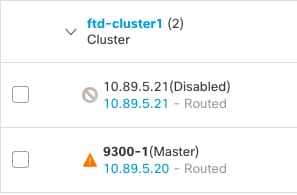
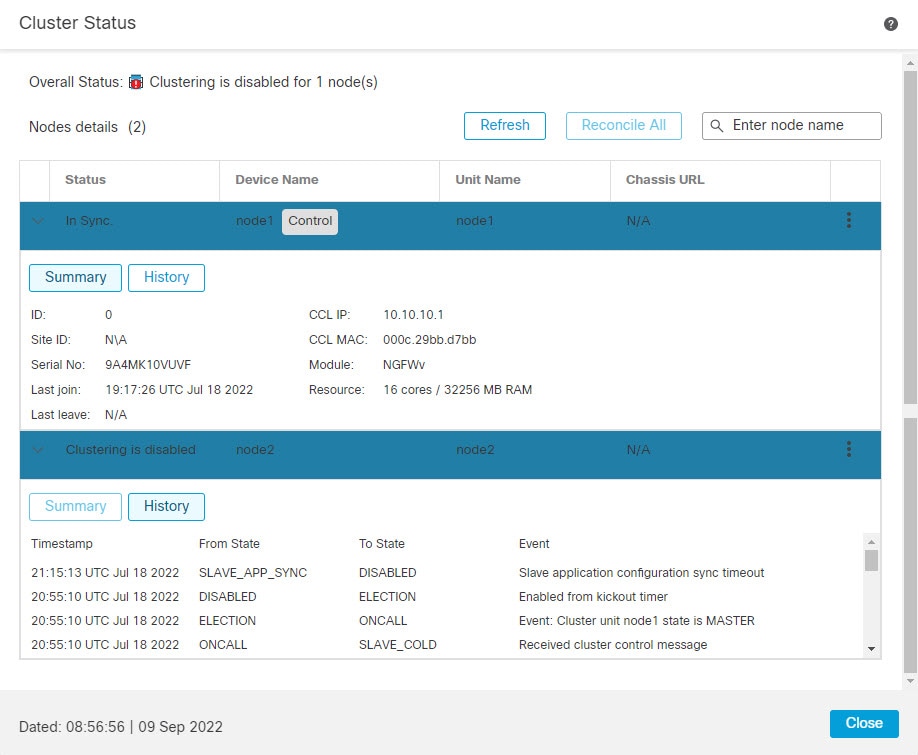
클러스터 멤버
클러스터 멤버는 보안 정책 및 트래픽 흐름을 공유하기 위해 서로 연동됩니다.
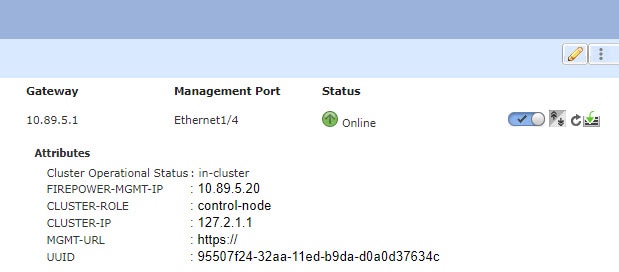
클러스터의 멤버 중 하나는 제어 유닛입니다. 제어 유닛은 자동으로 결정됩니다. 다른 모든 멤버는 데이터 유닛입니다.
모든 설정은 제어 유닛에서만 수행되어야 하며, 이후 설정이 데이터 유닛에 복제됩니다.
일부 기능은 클러스터로 확장되지 않으며, 제어 유닛에서 이러한 기능에 대한 모든 트래픽을 처리합니다. 를 참고하십시오.
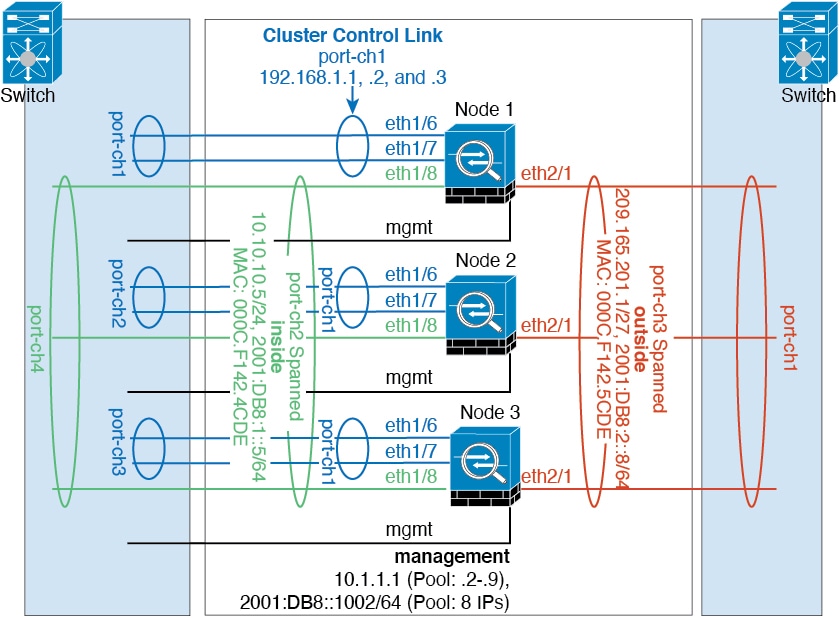
클러스터 제어 링크
네이티브 인스턴스 클러스터링의 경우: 클러스터 제어 링크는 Port-channel 48 인터페이스를 사용하여 자동으로 생성됩니다.
다중 인스턴스 클러스터링의 경우에는 하나 이상의 클러스터 유형 Etherchannel에서 하위 인터페이스를 사전 구성해야 합니다. 각 인스턴스에는 자체 클러스터 제어 링크가 필요 합니다.
단일 Firepower 9300 섀시 내에서 보안 모듈로 격리된 클러스터의 경우 이 인터페이스에는 멤버 인터페이스가 없습니다. 이 클러스터 유형 EtherChannel은 클러스터 통신에 Firepower 9300 백플레인을 활용합니다. 다중 섀시 클러스터링의 경우에는 EtherChannel에 인터페이스를 하나 이상 추가해야 합니다.
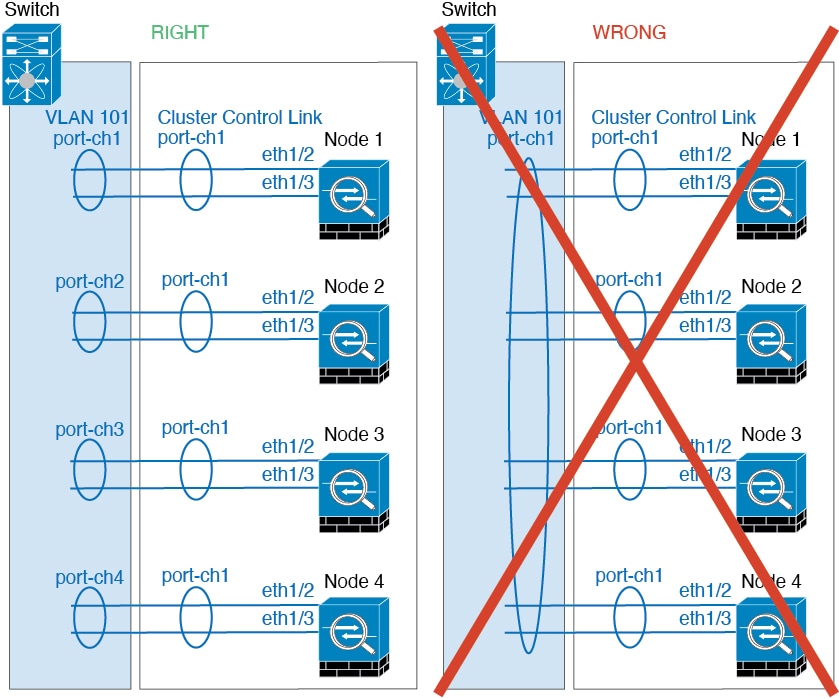
2개 섀시 클러스터의 경우 클러스터 제어 링크를 한 섀시에서 다른 섀시로 직접 연결하지 마십시오. 인터페이스에 직접 연결할 경우, 유닛 하나에 오류가 발생하면 클러스터 제어 링크에도 오류가 발생하므로 나머지 정상 유닛에도 오류가 발생합니다. 스위치를 통해 클러스터 제어 링크를 연결할 경우 클러스터 제어 링크는 가동 상태를 유지하여 정상 유닛을 지원합니다.
클러스터 제어 링크 트래픽에는 제어 및 데이터 트래픽이 모두 포함됩니다.
클러스터 제어 링크 크기 조정
가능한 경우, 각 섀시의 예상 처리량에 맞게 클러스터 제어 링크의 크기를 조정하여 클러스터 제어 링크가 최악의 시나리오를 처리할 수 있게 해야 합니다.
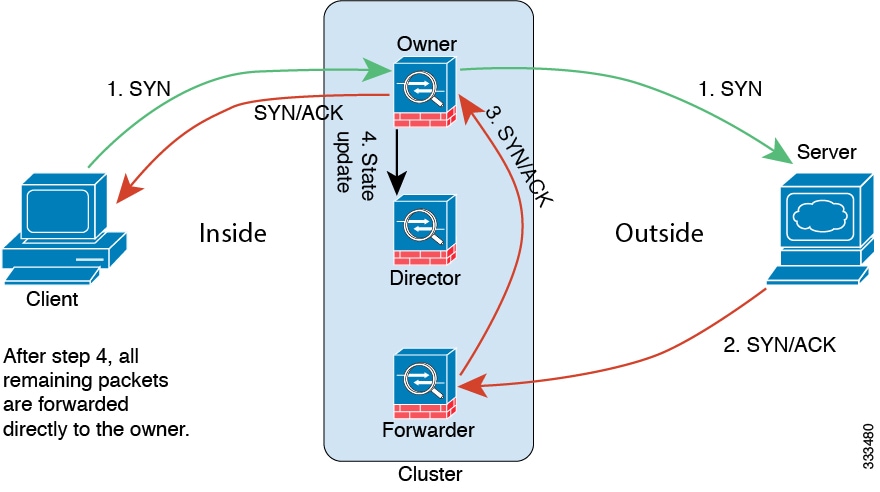
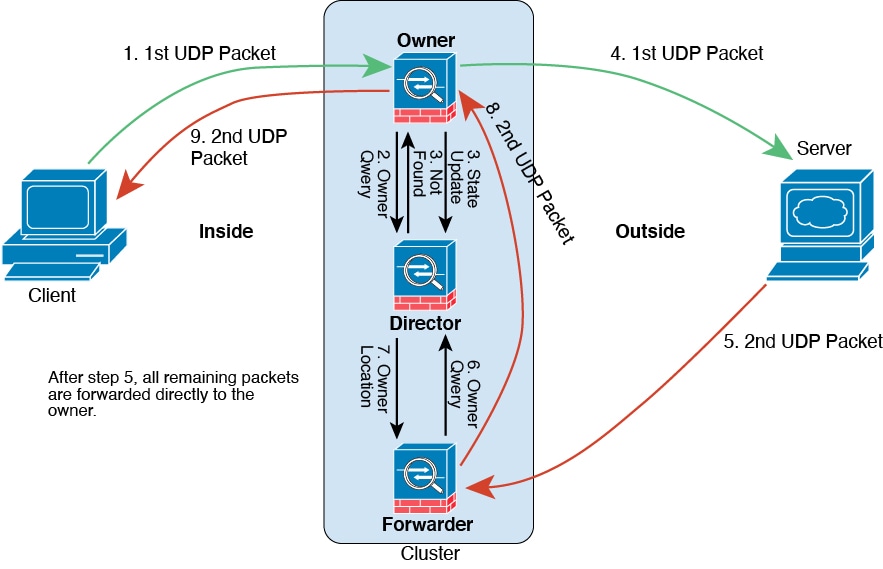
클러스터 제어 링크 트래픽은 주로 상태 업데이트 및 전달된 패킷으로 구성되어 있습니다. 클러스터 제어 링크의 트래픽 양은 언제든지 달라질 수 있습니다. 전달된 트래픽의 양은 로드 밸런싱 효율성 또는 중앙 집중식 기능에 많은 트래픽이 있는지에 따라 좌우됩니다. 예를 들면 다음과 같습니다.
-
NAT의 경우 연결의 로드 밸런싱이 저하되며, 모든 반환 트래픽을 올바른 유닛으로 다시 밸런싱해야 합니다.
-
멤버가 변경된 경우, 클러스터에서는 다량의 연결을 다시 밸런싱해야 하므로 일시적으로 많은 양의 클러스터 제어 링크 대역폭을 사용합니다.
대역폭이 높은 클러스터 제어 링크를 사용하면 멤버가 변경될 경우 클러스터를 더 빠르게 통합할 수 있고 처리량 병목 현상을 방지할 수 있습니다.
참고 |
클러스터에 비대칭(다시 밸런싱된) 트래픽이 많은 경우 클러스터 제어 링크 크기를 늘려야 합니다. |
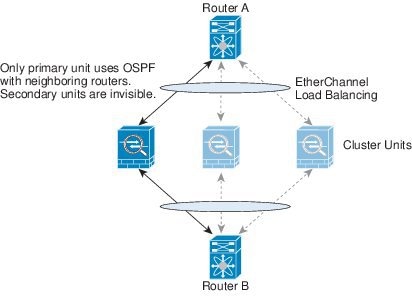
클러스터 제어 링크 이중화
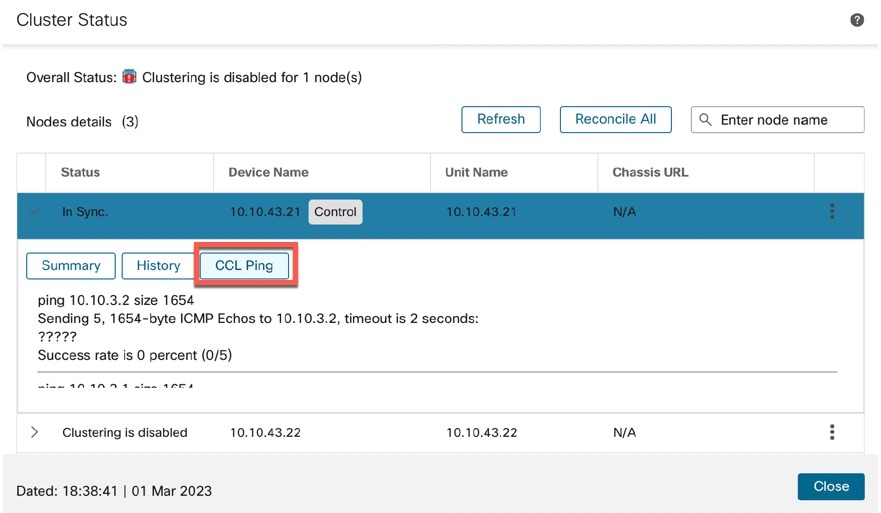
다음 다이어그램은 EtherChannel을 VSS(Virtual Switching System), vPC(Virtual Port Channel), StackWise 또는 StackWise 가상 환경에서 클러스터 제어 링크로 사용하는 방법을 보여줍니다. EtherChannel의 모든 링크가 활성화되어 있습니다. 스위치가 중복 시스템의 일부인 경우 동일한 EtherChannel 내의 방화벽 인터페이스를 중복 시스템의 개별 스위치에 연결할 수 있습니다. 이러한 별도의 스위치는 단일 스위치 역할을 하므로, 스위치 인터페이스는 동일한 EtherChannel 포트 채널 인터페이스의 멤버입니다. 이러한 EtherChannel은 디바이스 로컬이 아닌 스팬 EtherChannel입니다.
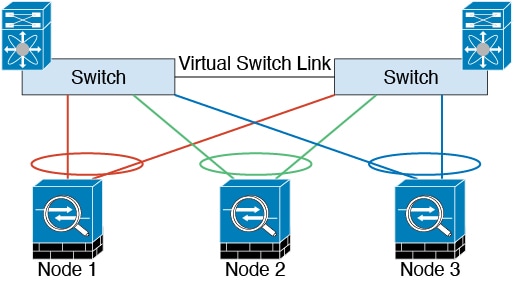
섀시 간 클러스터링을 위한 클러스터 제어 링크 안정성
클러스터 제어 링크 기능을 보장하려면 유닛 간의 RTT(round-trip time)가 20ms 이하여야 합니다. 이러한 최대 레이턴시는 서로 다른 지리적 사이트에 설치된 클러스터 멤버와의 호환성을 개선하는 역할을 합니다. 레이턴시를 확인하려면 유닛 간의 클러스터 제어 링크에서 Ping을 수행합니다.
클러스터 제어 링크는 오류가 나거나 폐기된 패킷이 없는 안정적인 상태여야 합니다. 예를 들어, 사이트 간 구축의 경우 전용 링크를 사용해야 합니다.
클러스터 제어 링크 네트워크
Firepower 4100/9300 섀시에서는 섀시 ID 및 슬롯 ID 127.2.chassis_id.slot_id를 기준으로 하여 각 유닛에 대해 클러스터 제어 링크 인터페이스 IP 주소를 자동 생성합니다. 일반적으로 같은 EtherChannel의 다른 VLAN 하위 인터페이스를 사용하는 다중 인스턴스 클러스터의 경우 VLAN 분리로 인해 서로 다른 클러스터에 같은 IP 주소를 사용할 수 있습니다. 클러스터 제어 링크 네트워크는 유닛 간에 라우터를 포함할 수 없으며 레이어 2 스위칭만 허용됩니다.
관리 네트워크
모든 유닛을 단일한 관리 네트워크에 연결할 것을 권장합니다. 이 네트워크는 클러스터 제어 링크와 분리되어 있습니다.
관리 인터페이스
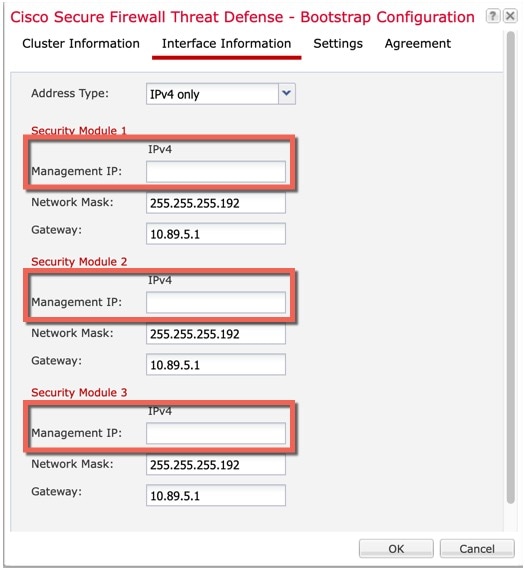
클러스터에 관리 유형 인터페이스를 할당해야 합니다. 이 인터페이스는 Spanned 인터페이스와는 다른 특수 개별 인터페이스입니다. 관리 인터페이스를 사용하면 각 유닛에 직접 연결할 수 있습니다. 논리적 관리 인터페이스는 디바이스에 있는 다른 인터페이스와 분리되어 있습니다. 이 인터페이스는 디바이스를 Secure Firewall Management Center에 설치하고 등록하는 데 사용됩니다. 또한 자체 로컬 인증, IP 주소 및 정적 라우팅을 사용합니다. 각 클러스터 멤버는 부트스트랩 설정의 일부로 설정하는 관리 네트워크에 별도 IP 주소를 사용합니다.
클러스터 인터페이스
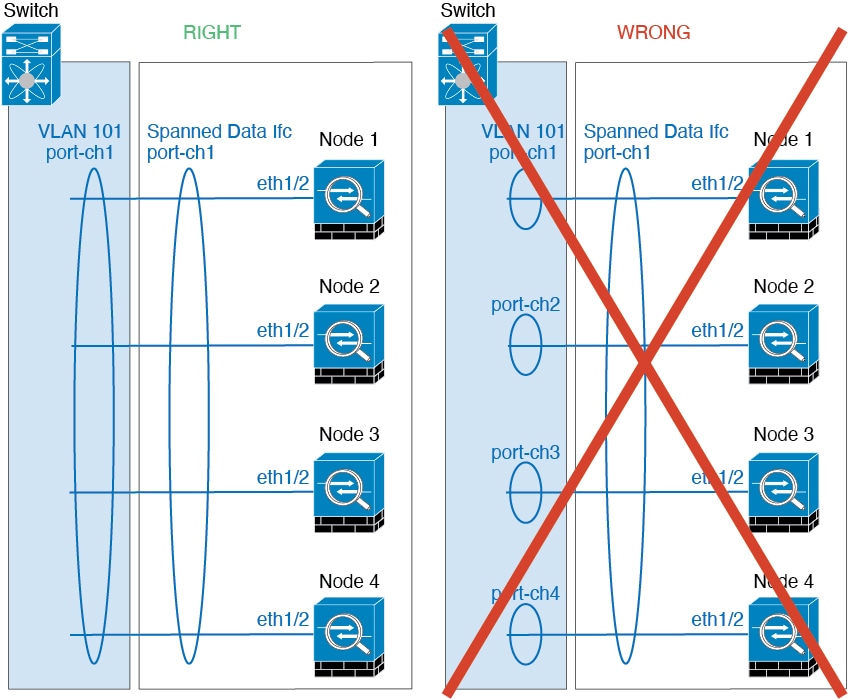
단일 Firepower 섀시 내의 보안 모듈에 격리된 클러스터의 경우, 클러스터에 물리적 인터페이스 또는 Etherchannel(포트 채널)을 할당할 수 있습니다. 클러스터에 할당된 인터페이스는 클러스터의 모든 멤버에 대해 트래픽의 로드 밸런싱을 수행하는 Spanned 인터페이스입니다.
다중 섀시 클러스터링의 경우 클러스터에 데이터 Etherchannel만 할당할 수 있습니다. Spanned EtherChannel은 각 섀시에 동일한 멤버 인터페이스를 포함합니다. 업스트림 스위치에서 모든 인터페이스는 단일 EtherChannel에 포함되므로 스위치는 인터페이스가 여러 디바이스와 연결되었는지 알지 못합니다.
개별 인터페이스는 관리 인터페이스를 제외하고 지원되지 않습니다.
스팬 EtherChannels
섀시당 하나 이상의 인터페이스를 클러스터 내의 모든 섀시를 포괄하는 EtherChannel로 그룹화할 수 있습니다. EtherChannel에서는 채널에서 사용 가능한 모든 활성 인터페이스 전반의 트래픽을 취합합니다. 스팬 EtherChannel은 라우팅 및 투명 방화벽 모드에서 모두 구성할 수 있습니다. 라우팅 모드의 경우 EtherChannel은 단일 IP 주소를 통해 라우팅된 인터페이스로 구성됩니다. 투명 모드의 경우 브리지 그룹 멤버 인터페이스가 아닌 BVI에 IP 주소가 할당됩니다. EtherChannel은 기본적인 작동 시 로드 밸런싱을 함께 제공합니다.
다중 인스턴스 클러스터의 경우 각 클러스터에 전용 데이터 EtherChannel이 필요하며 공유 인터페이스 또는 VLAN 하위 인터페이스를 사용할 수 없습니다.
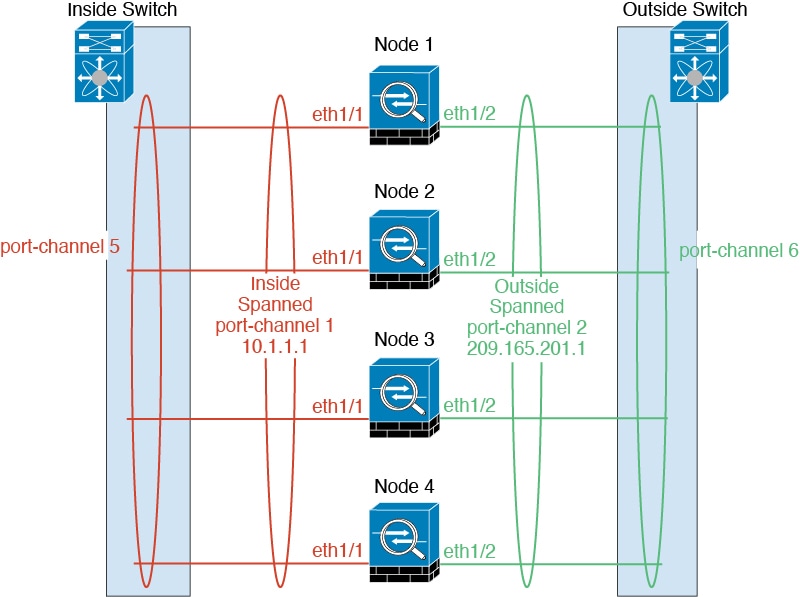
이중화 스위치 시스템에 연결
VSS, vPC, StackWise 또는 StackWise Virtual 시스템과 같은 이중화 스위치 시스템에 EtherChannel을 연결하여 인터페이스에 이중화를 제공하는 것이 좋습니다.
구성 복제
클러스터의 모든 노드에서는 단일 구성을 공유합니다. 제어 노드에서는 구성만 변경할 수 있으며(부트스트랩 구성 예외), 변경 사항은 클러스터의 모든 다른 노드에 자동으로 동기화됩니다.



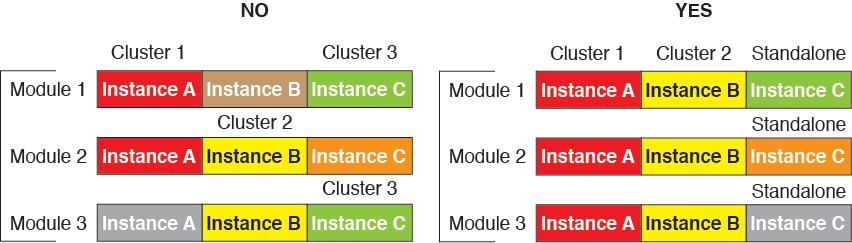
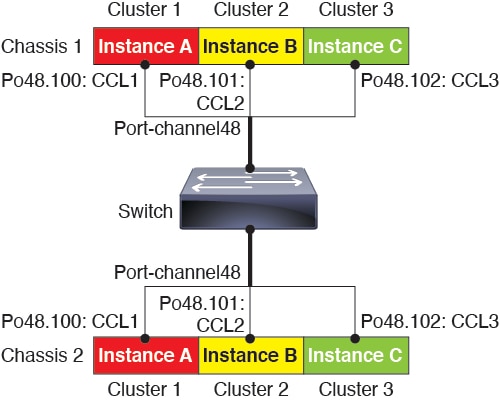
 )
)

 )
)
 )
)


 )
) )
) )
) )
)
 )
)


 )
) )
)
 피드백
피드백