À propos de la mise en grappe sur les châssis Firepower 4100/9300
Lorsque vous déployez une grappe sur le Châssis Firepower 4100/9300 , elle effectue les opérations suivantes :
-
crée une liaison de commande de grappe (par défaut, le canal de port 48) pour la communication de nœud à nœud.
Pour une grappe isolée des modules de sécurité dans un châssis Firepower 9300, ce lien utilise le fond de panier Firepower 9300 pour les communications de la grappe.
Pour la mise en grappe avec plusieurs châssis, vous devez affecter manuellement une ou plusieurs interfaces physiques à cet EtherChannel pour les communications entre les châssis.
-
Crée la configuration de démarrage de grappe dans l’application.
Lorsque vous déployez la grappe, le superviseur de châssis envoie une configuration de démarrage minimale à chaque unité, qui comprend le nom de la grappe, l’interface de liaison de commande de grappe et d’autres paramètres de la grappe. Certaines parties de la configuration de démarrage peuvent être configurées par l’utilisateur dans l’application si vous souhaitez personnaliser votre environnement de mise en grappe.
-
Affecte des interfaces de données à la grappe en tant qu’interfaces étendues.
Pour une grappe isolée des modules de sécurité dans un châssis Firepower 9300, les interfaces étendues ne se limitent pas aux EtherChannels, comme c’est le cas pour la mise en grappe avec plusieurs châssis. Le superviseur Firepower 9300 utilise la technologie EtherChannel en interne pour équilibrer la charge du trafic vers plusieurs modules sur une interface partagée, de sorte que tout type d’interface de données fonctionne pour le mode étendu. Pour la mise en grappe avec plusieurs châssis, vous devez utiliser des EtherChannels étendus pour toutes les interfaces de données.

Remarque
Les interfaces individuelles ne sont pas prises en charge, à l'exception d'une interface de gestion.
-
Attribue une interface de gestion à toutes les unités de la grappe.
Voir l'une des sections suivantes pour plus d'informations sur la mise en grappe.
Configuration du démarrage
Lorsque vous déployez la grappe, le superviseur de châssis Firepower 4100/9300 envoie une configuration de démarrage minimale à chaque unité, qui comprend le nom de la grappe, l’interface de liaison de commande de grappe et d’autres paramètres de la grappe. Certaines parties de la configuration de démarrage sont configurables par l’utilisateur si vous souhaitez personnaliser votre environnement de mise en grappe.
Membres de la grappe
Les membres de la grappe collaborent pour partager la politique de sécurité et les flux de trafic.
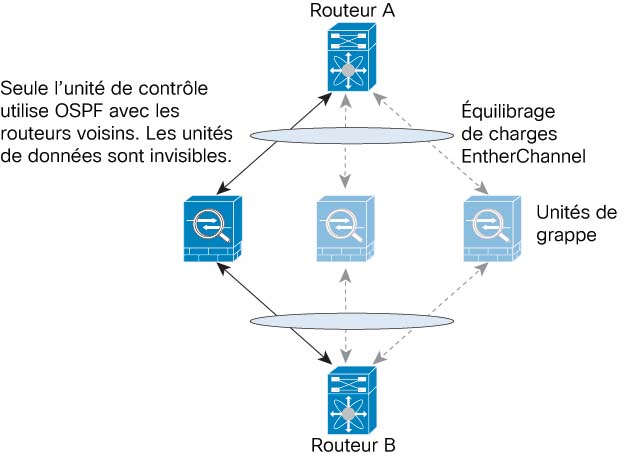
L’unité de contrôle est l’un des membres de la grappe. L'unité de contrôle est déterminée automatiquement. Tous les autres membres sont des unités de données.
Vous devez effectuer toute la configuration sur l’unité de contrôle uniquement; la configuration est ensuite reproduite dans les unités de données.
Certaines fonctionnalités ne sont pas évolutives dans une grappe, et l’unité de contrôle gère tout le trafic pour ces fonctionnalités. Voir Fonctionnalités centralisées pour la mise en grappe.
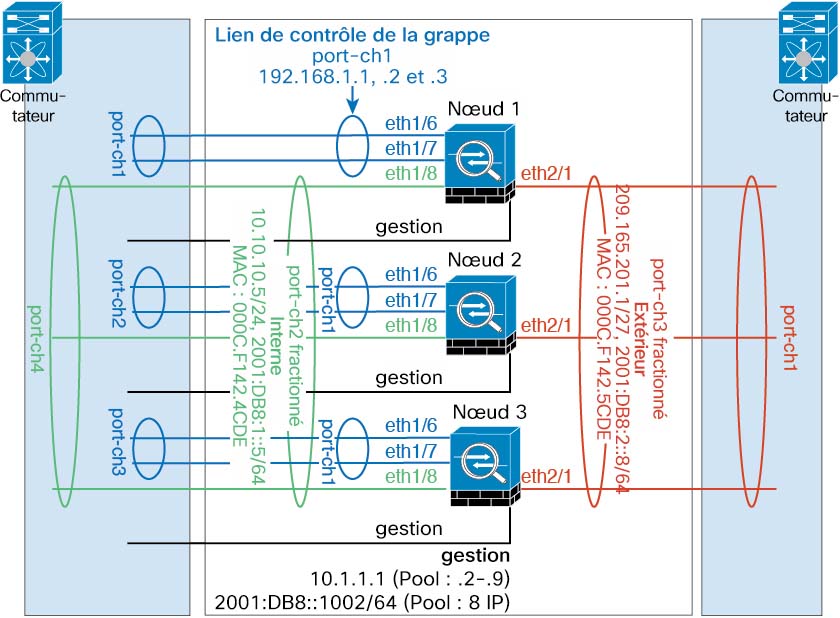
Liaison de commande de grappe
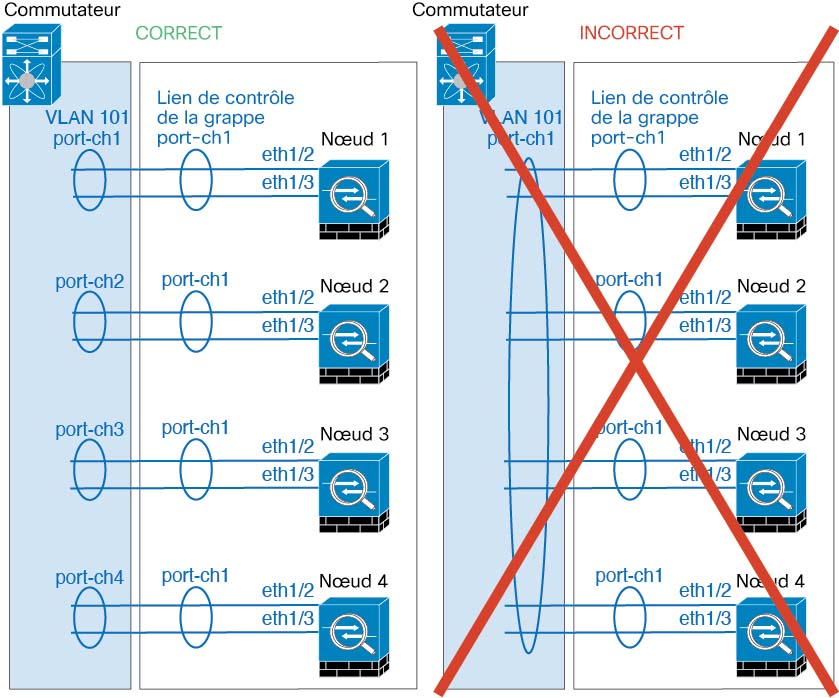
La liaison de commande de grappe est un EtherChannel (canal de port 48) pour la communication d’unité à unité. Pour la mise en grappe intra-châssis, cette liaison utilise le fond de panier Firepower 9300 pour les communications de la grappe. Pour la mise en grappe inter-châssis, vous devez affecter manuellement une ou plusieurs interfaces physiques à cet EtherChannel sur le Châssis Firepower 4100/9300 pour les communications entre les châssis.
Dans le cas d’une grappe inter-châssis à deux châssis, ne connectez pas directement la liaison de commande de grappe d’un châssis à l’autre. Si vous connectez directement les interfaces, lorsqu’une unité tombe en panne, la liaison de commande de grappe tombe en panne, et donc l’unité intègre restante. Si vous connectez la liaison de commande de grappe par l’intermédiaire d’un commutateur, cette dernière reste active pour l’unité intègre.
Le trafic de liaison de commande de grappe comprend à la fois un trafic de contrôle et un trafic de données.
Le trafic de contrôle comprend :
-
Choix du nœud de contrôle.
-
Duplication de la configuration.
-
Surveillance de l'intégrité
Le trafic de données comprend :
-
Duplication de l’état.
-
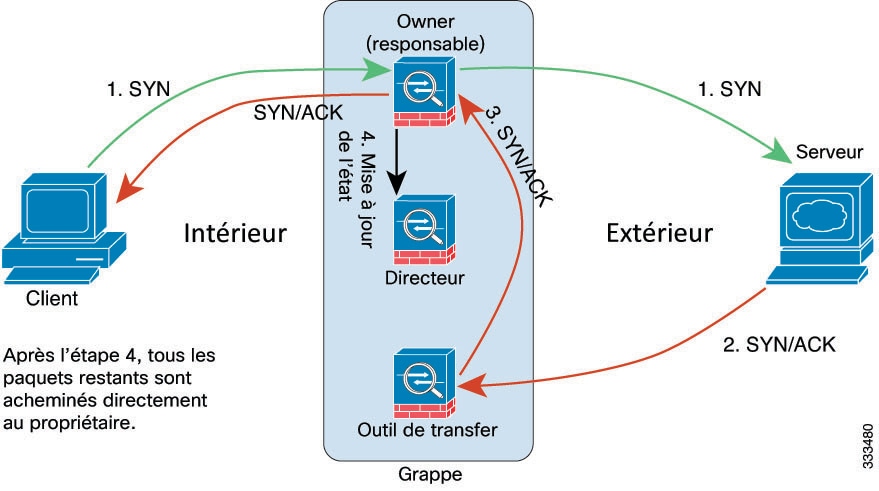
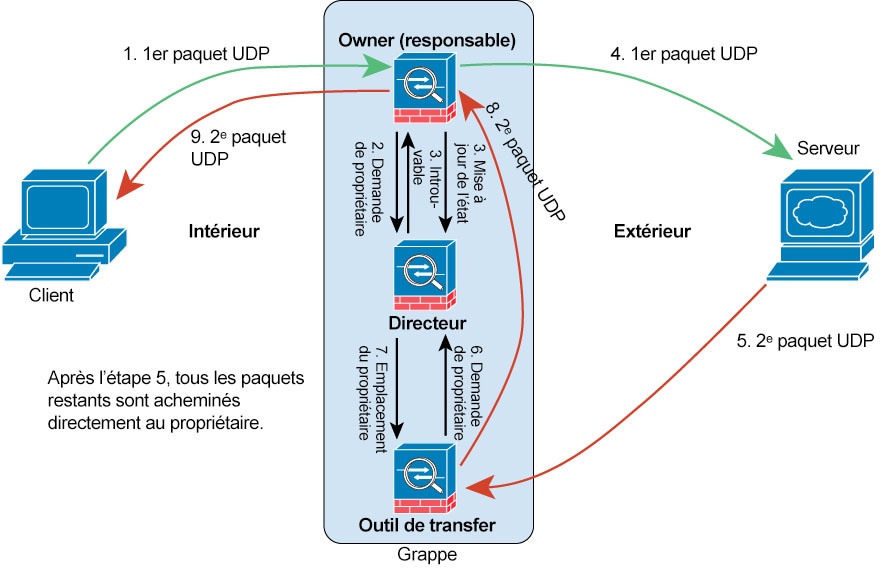
Requêtes de propriété de connexion et transfert de paquets de données.
Consultez les sections suivantes pour en savoir plus sur la liaison de commande de grappe.
Dimensionner la liaison de commande de grappe
Si possible, vous devez dimensionner la liaison de commande de grappe en fonction du débit attendu de chaque châssis afin que la liaison de commande de grappe puisse gérer les scénarios les plus défavorables.
Le trafic de liaison de commande de grappe est principalement composé de mises à jour d’état et de paquets transférés. Le volume de trafic varie à un moment donné sur la liaison de commande de grappe. La quantité de trafic transféré dépend de l’efficacité de l’équilibrage de la charge et de l’importance du trafic pour les fonctionnalités centralisées. Par exemple :
-
La NAT entraîne un mauvais équilibrage de la charge des connexions et la nécessité de rééquilibrer tout le trafic de retour vers les bonnes unités.
-
L’AAA pour l’accès réseau est une fonctionnalité centralisée, de sorte que tout le trafic est acheminé à l’unité de contrôle.
-
Lorsque les membres changent, la grappe doit rééquilibrer un grand nombre de connexions, utilisant ainsi temporairement une grande quantité de bande passante de la liaison de commande de grappe.
Une liaison de commande de grappe à bande passante plus élevée aide la grappe à converger plus rapidement lorsque les membres changent et empêche les goulots d’étranglement.
Remarque |
Si votre grappe génère un trafic asymétrique (rééquilibreur) important, vous devez augmenter la taille du lien de commande de grappe. |
Redondance de la liaison de commande de la grappe
Nous vous recommandons d’utiliser un EtherChannel pour la liaison de commande de la grappe, afin de pouvoir transférer le trafic sur plusieurs liaisons de l’EtherChannel tout en assurant la redondance.
Le diagramme suivant montre comment utiliser un EtherChannel comme liaison de commande de la grappe dans un système de commutation virtuelle (VSS), un canal de port virtuel (vPC), un StackWise ou un environnement StackWise Virtual. Tous les liens de l’EtherChannel sont actifs. Lorsque le commutateur fait partie d’un système redondant, vous pouvez connecter des interfaces de pare-feu dans le même EtherChannel pour séparer les commutateurs du système redondant. Les interfaces des commutateurs sont membres de la même interface de canal de port EtherChannel, car les commutateurs distincts se comportent comme un seul commutateur. Notez qu’il s’agit d’un EtherChannel local au périphérique et non d’un EtherChannel étendu.
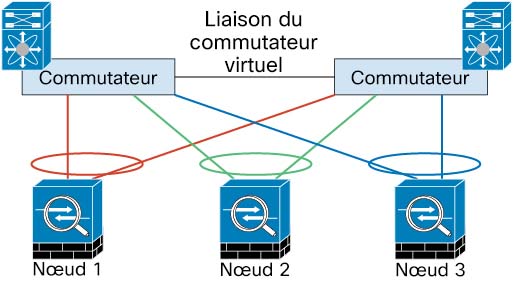
Fiabilité de la liaison de commande de grappe pour la mise en grappe
Pour assurer la fonctionnalité de la liaison de commande de grappe, vérifiez que le temps aller-retour (RTT) entre les unités est inférieur à 20 ms. Cette latence maximale améliore la compatibilité avec les membres de la grappe installés à différents sites géographiques. Pour vérifier votre latence, envoyez un message Ping sur la liaison de commande de grappe entre les unités.
La liaison de commande de grappe doit être fiable, sans paquets en désordre ou abandonnés; par exemple, pour un déploiement intersite, vous devez utiliser un lien dédié.
Réseau de liaison de commande de grappe
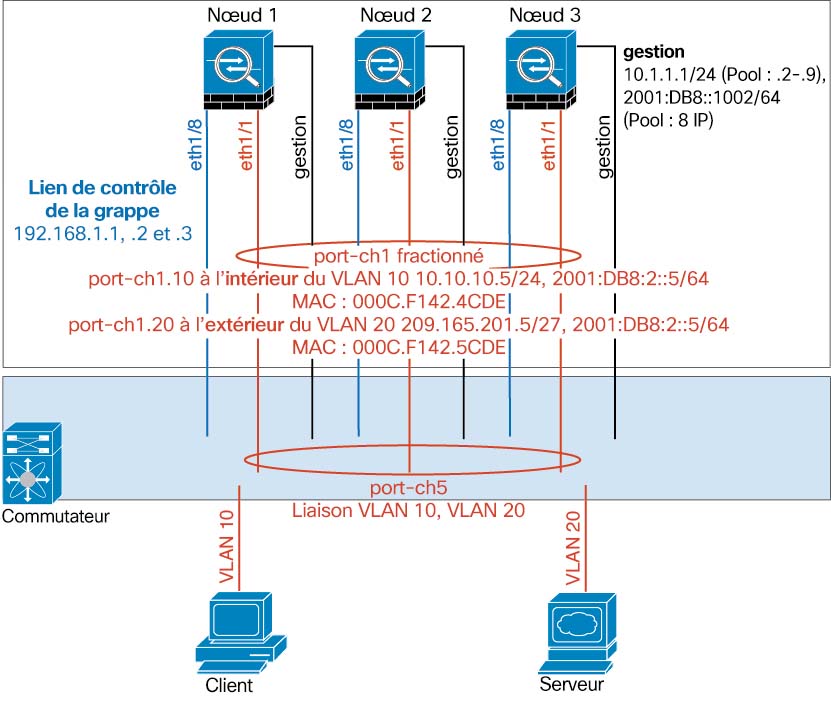
Le Châssis Firepower 4100/9300 génère automatiquement l’adresse IP de l’interface de liaison de commande de grappe pour chaque unité en fonction de l’ID de châssis et de l’ID d’emplacement : 127.2.chassis_id.slot-id.Vous pouvez personnaliser cette adresse IP lorsque vous déployez la grappe. Le réseau de liaison de commande de grappe ne peut pas comprendre de routeurs entre les unités; seule la commutation de couche 2 est autorisée. Pour le trafic intersites, Cisco recommande d’utiliser la virtualisation du transport par superposition (OTV).
Interfaces de la grappe
Pour une grappe isolée des modules de sécurité dans un châssis Firepower 9300, vous pouvez affecter des interfaces physiques ou des EtherChannels (également appelés canaux de port) à la grappe. Les interfaces affectées à la grappe sont des interfaces étendues qui équilibrent la charge du trafic entre tous les membres de la grappe.
Pour la mise en grappe avec plusieurs châssis, vous pouvez uniquement affecter des EtherChannels de données à la grappe. Ces EtherChannels étendus comprennent les mêmes interfaces membre sur chaque châssis; Sur le commutateur en amont, toutes ces interfaces sont incluses dans un seul EtherChannel, de sorte que le commutateur ne sache pas qu’il est connecté à plusieurs périphériques.
Les interfaces individuelles ne sont pas prises en charge, à l'exception d'une interface de gestion.
Connexion à un système de commutateurs redondants
Nous vous recommandons de connecter les EtherChannels à un système de commutation redondant tel qu’un VSS, vPC, StackWise ou un système virtuel StackWise pour assurer la redondance de vos interfaces.
Réplication de la configuration
Tous les nœuds de la grappe partagent une configuration unique. Vous pouvez uniquement apporter des modifications à la configuration sur le nœud de contrôle (à l’exception de la configuration de démarrage) et les modifications sont automatiquement synchronisées avec tous les autres nœuds de la grappe.
Gestion des grappes Cisco Secure Firewall ASA
L’un des avantages de l’utilisation de la mise en grappe ASA est la facilité de gestion. Cette section décrit comment gérer la grappe.
Réseau de gestion
Nous vous recommandons de connecter toutes les unités à un seul réseau de gestion. Ce réseau est distinct de la liaison de commande de grappe.
Interface de gestion
Vous devez affecter une interface de type gestion à la grappe. Cette interface est une interface individuelle spéciale, par opposition à une interface étendue. L’interface de gestion vous permet de vous connecter directement à chaque unité.
L’adresse IP de la grappe principale est une adresse fixe pour la grappe qui appartient toujours à l’unité de contrôle actuelle. Vous configurez également une plage d’adresses de sorte que chaque unité, y compris l’unité de contrôle actuelle, puisse utiliser une adresse locale de la plage. L’adresse IP de la grappe principale fournit un accès de gestion cohérent à une adresse; lorsqu’une unité de contrôle change, l’adresse IP de la grappe principale est déplacée vers la nouvelle unité de contrôle, de sorte que la gestion de la grappe se poursuit de façon transparente.
Par exemple, vous pouvez gérer la grappe en vous connectant à l’adresse IP de la grappe principale, qui est toujours associée à l’unité de contrôle actuelle. Pour gérer un membre, vous pouvez vous connecter à l’adresse IP locale.
Remarque |
Le trafic vers la boîte doit être acheminé vers l’adresse IP de gestion du nœud; le trafic vers la boîte n’est pas transféré sur la liaison de commande de grappe vers un autre nœud. |
Pour le trafic de gestion sortant tel que TFTP ou syslog, chaque unité, y compris l’unité de contrôle, utilise l’adresse IP locale pour se connecter au serveur.
Gestion de l’unité de contrôle vs Gestion de l’unité de données
Toutes la gestion et la surveillance peuvent avoir lieu sur le nœud de contrôle. À partir du nœud de contrôle, vous pouvez vérifier les statistiques d’exécution, l’utilisation des ressources ou d’autres informations de surveillance sur tous les nœuds. Vous pouvez également transmettre une commande à tous les nœuds de la grappe et reproduire les messages de console des nœuds de données vers le nœud de contrôle.
Vous pouvez surveiller directement les nœuds de données si vous le souhaitez. Bien que cela soit également disponible à partir du nœud de contrôle, vous pouvez effectuer la gestion de fichiers sur les nœuds de données (y compris la sauvegarde de la configuration et la mise à jour des images). Les fonctions suivantes ne sont pas disponibles à partir du nœud de commande :
-
Surveillance des statistiques propres à la grappe par nœud.
-
Surveillance des journaux système par nœud (sauf pour les journaux système envoyés à la console lorsque la duplication de la console est activée).
-
SNMP
-
NetFlow
duplication de clé de chiffrement
Lorsque vous créez une clé de chiffrement sur le nœud de contrôle, la clé est répliquée sur tous les nœuds de données. Si vous avez une session SSH sur l’adresse IP de la grappe principale, vous serez déconnecté en cas de défaillance du nœud de contrôle. Le nouveau nœud de contrôle utilise la même clé pour les connexions SSH, de sorte que vous n’avez pas besoin de mettre à jour la clé d’hôte SSH mise en cache lorsque vous vous reconnectez au nouveau nœud de contrôle.
Incompatibilité d’adresse IP du certificat de connexion ASDM
Par défaut, un certificat autosigné est utilisé pour la connexion ASDM en fonction de l’adresse IP locale. Si vous vous connectez à l'adresse IP de la grappe principale à l'aide d'ASDM, un message d'avertissement concernant une adresse IP non concordante peut s'afficher, car le certificat utilise l'adresse IP locale, et non l'adresse IP de la grappe principale. Vous pouvez ignorer le message et établir la connexion ASDM. Cependant, pour éviter ce type d'avertissement, vous pouvez inscrire un certificat qui contient l'adresse IP de la grappe principale et toutes les adresses IP locales de l'ensemble d'adresses IP. Vous pouvez ensuite utiliser ce certificat pour chaque membre de la grappe. Consultez https://www.cisco.com/c/en/us/td/docs/security/asdm/identity-cert/cert-install.html pour de plus amples renseignements.
EtherChannels étendus (recommandé)
Vous pouvez regrouper une ou plusieurs interfaces par châssis dans un EtherChannel qui s’étend sur tous les châssis de la grappe. L’EtherChannel agrège le trafic sur toutes les interfaces actives disponibles dans le canal.
Un EtherChannel étendu peut être configuré dans les modes de pare-feu avec routage et transparent. En mode routé, l’EtherChannel est configuré comme une interface routée avec une seule adresse IP. En mode transparent, l’adresse IP est attribuée aux BVI, et non à l’interface du membre du groupe de ponts.
L’EtherChannel assure intrinsèquement l’équilibrage de la charge dans le cadre du fonctionnement de base.
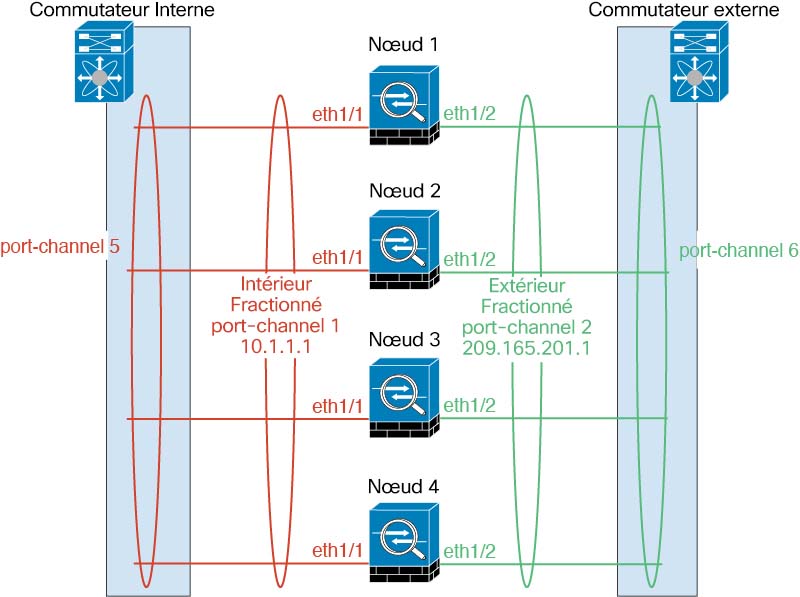
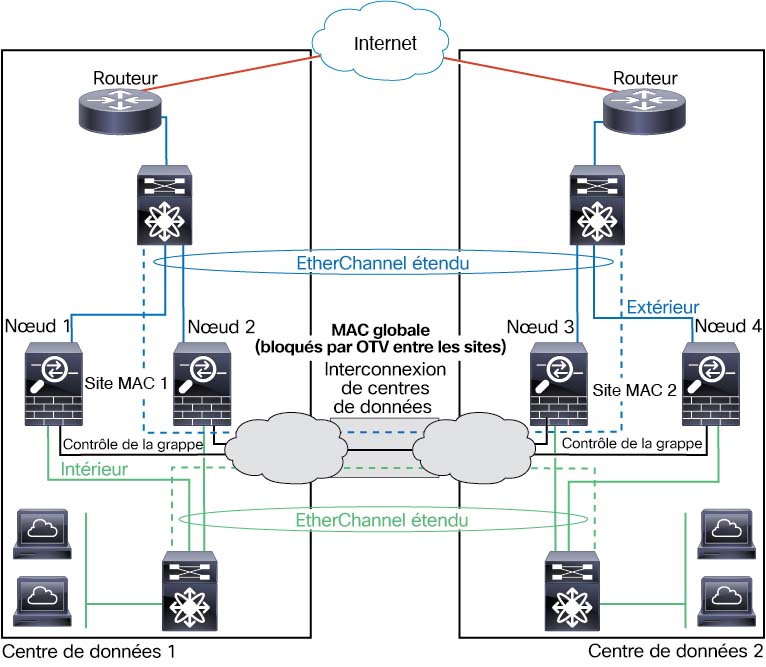
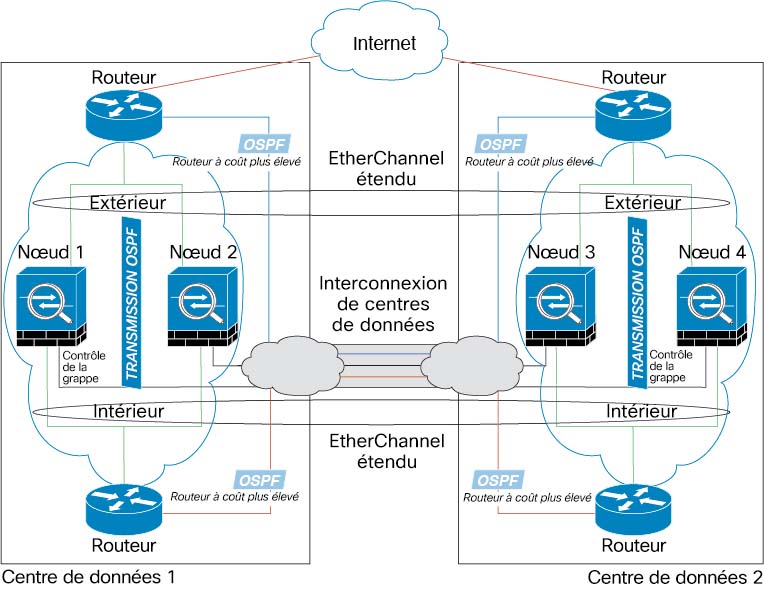
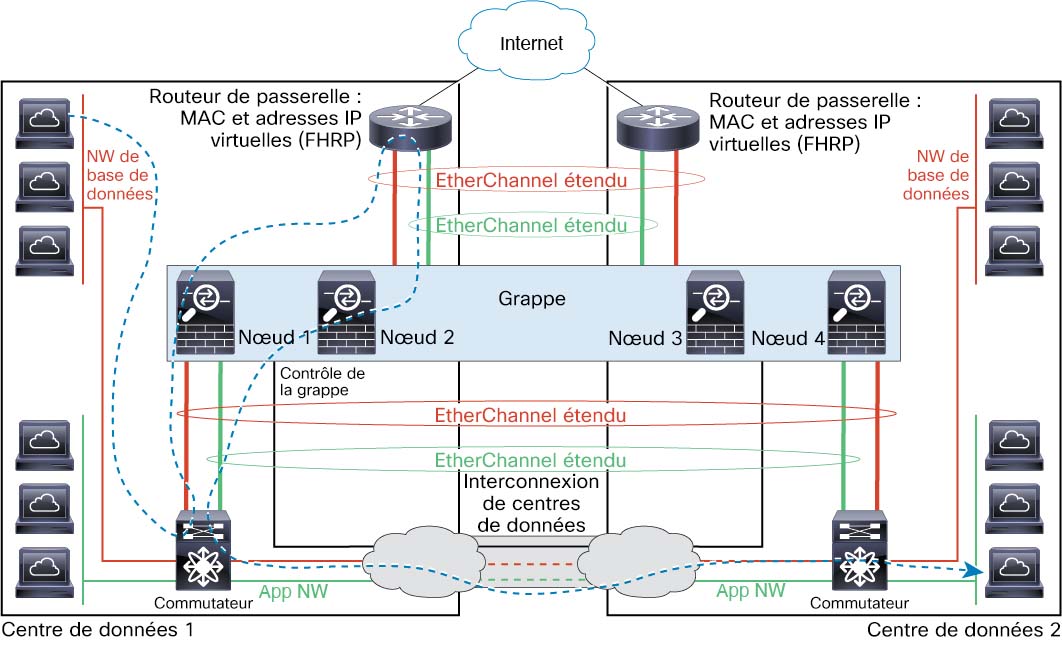
Mise en grappe inter-sites
Pour les installations inter-sites, vous pouvez profiter de la mise en grappe d’ASA tant que vous suivez les lignes directrices recommandées.
Vous pouvez configurer chaque châssis de grappe pour qu’il appartienne à un ID de site distinct.
Les ID de site fonctionnent avec des adresses MAC et des adresses IPspécifiques au site . Les paquets qui sortent de la grappe utilisent une adresse MAC et une adresse IPpropres au site, tandis que les paquets reçus par la grappe utilisent une adresse MAC et une adresse IPglobales. Cette fonctionnalité empêche les commutateurs d’apprendre la même adresse MAC globale à partir des deux sites sur deux ports différents, ce qui entraîne une oscillation MAC; au lieu de cela, ils connaissent uniquement l’adresse MAC du site. Les adresses MAC et les adresses IP spécifiques au site sont prises en charge pour le mode routé qui utilise uniquement les EtherChannels étendus.
Les ID de site sont également utilisés pour permettre la mobilité de flux à l’aide de l’inspection LISP, la localisation du directeur pour améliorer les performances et réduire la latence aller-retour pour la mise en grappe inter-sites pour les centres de données, et la redondance des sites pour les connexions où un propriétaire de secours d’un flux se trouve toujours sur un autre site que celui du propriétaire.
Consultez les sections suivantes pour en savoir plus sur la mise en grappe inter-sites :
-
Dimensionnement de l’interconnexion du centre de données : Exigences et conditions préalables à la mise en grappe sur Châssis Firepower 4100/9300
-
Lignes directrices inter-sites : Lignes directrices et limites de la mise en grappe
-
Configurer la mobilité des flux de grappes : Configurer la mobilité des flux de grappes
-
Activer la localisation du directeur : Activer la localisation du directeur
-
Activer la redondance de site : Activer la localisation du directeur
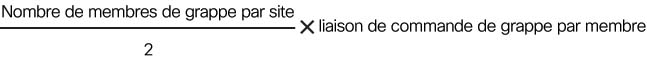


 Commentaires
Commentaires