À propos de la mise en grappe d’ASA virtuel dans le nuage public
Cette section décrit l’architecture de mise en grappe et son fonctionnement.
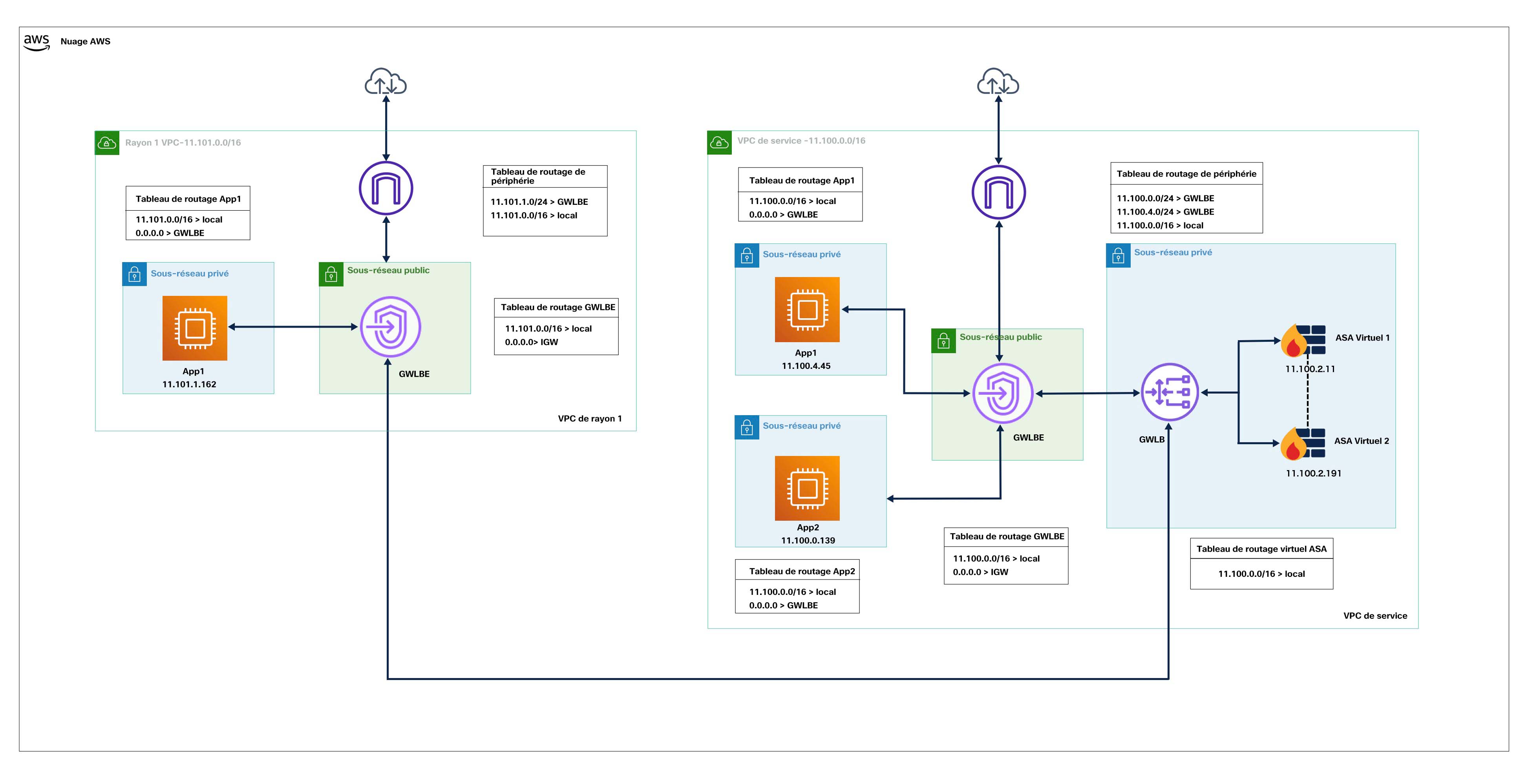
Intégration de la grappe dans votre réseau
La grappe se compose de plusieurs pare-feu agissant comme un seul périphérique. Pour agir comme une grappe, les pare-feu ont besoin de l’infrastructure suivante :
-
Réseau isolé pour la communication intra-grappe, appelé liaison de commande de grappe, qui utilise des interfaces VXLAN. Les VXLAN, qui agissent comme des réseaux virtuels de couche 2 sur des réseaux physiques de couche 3, permettent à la ASA virtuel d’envoyer des messages en diffusion ou en multidiffusion sur la liaison de commande de grappe.
-
Équilibreur(s) de charges : pour l’équilibrage de charges externe, vous avez les options suivantes :
-
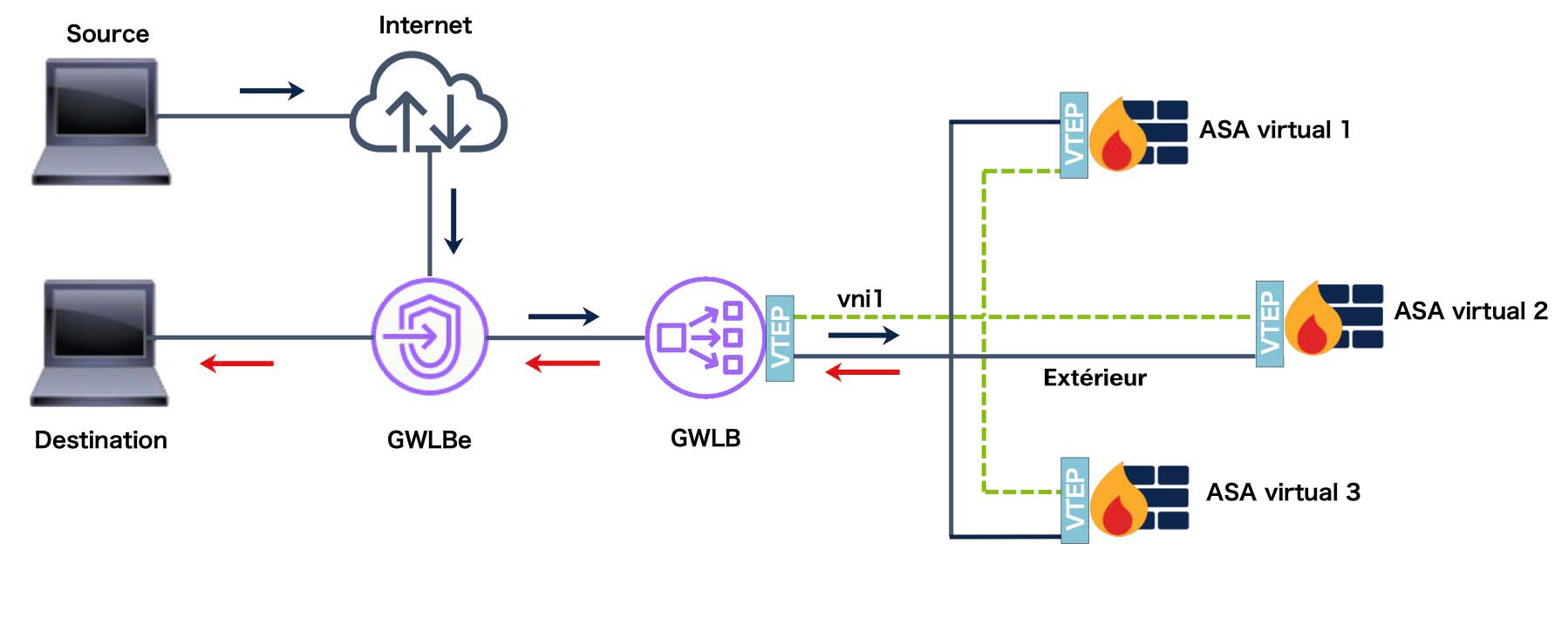
Équilibreur de charge de passerelle AWS
L'équilibreur de charge de passerelle AWS combine une passerelle de réseau transparente et un équilibreur de charge qui répartit le trafic et fait évoluer les périphériques virtuels à la demande. Le ASA virtuel prend en charge le plan de contrôle centralisé de l’équilibreur de charge de passerelle avec un plan de données distribué (point terminal de l’équilibreur de charge de passerelle) à l’aide d’un serveur mandataire à un seul bras d’interface de Geneve.
-
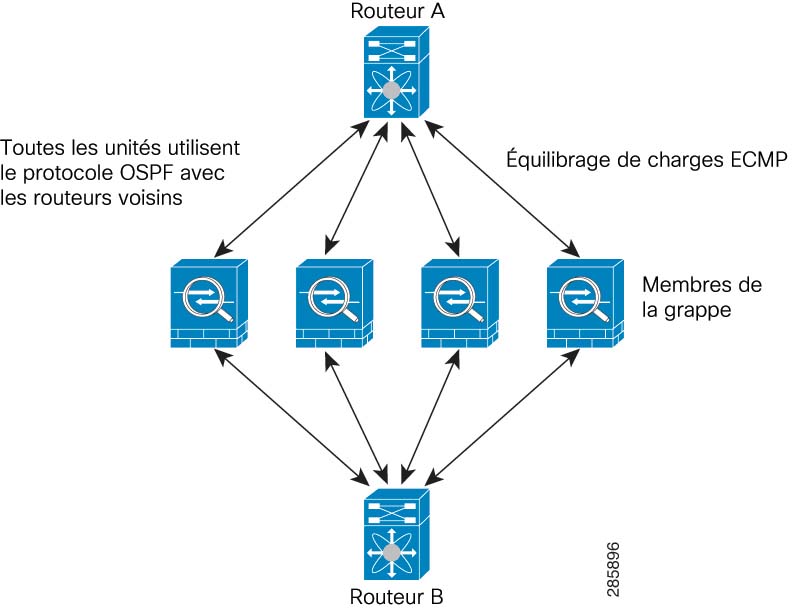
Routage à chemins multiples à coût égal (ECMP) utilisant des routeurs internes et externes comme le routeur des services en nuage de Cisco
Le routage ECMP peut transférer des paquets sur plusieurs « meilleurs chemins » qui se partagent la première place dans la mesure du routage. Comme pour l’EtherChannel, un hachage des adresses IP source et de destination ou des ports source et de destination peut être utilisé pour envoyer un paquet vers l’un des sauts suivants. Si vous utilisez des routes statiques pour le routage ECMP, la défaillance de ASA virtuel peut provoquer des problèmes. le routage continue d’être utilisé et le trafic vers le ASA virtuel défaillant sera perdu. Si vous utilisez des routes statiques, veillez à utiliser une fonctionnalité de surveillance de routage statique telle que le suivi d’objets. Nous recommandons d'utiliser des protocoles de routage dynamique pour ajouter et supprimer des routes, auquel cas vous devez configurer chaque ASA virtuel pour qu'il participe au routage dynamique.

Remarque
Les canaux EtherChannels étendus de couche 2 ne sont pas pris en charge pour l’équilibrage de la charge.
-
Nœuds de la grappe
Les membres du nœud collaborent pour partager la politique de sécurité et les flux de trafic. Cette section décrit la nature du rôle de chaque nœud.
Configuration du démarrage
Sur chaque appareil, vous configurez une configuration de démarrage minimale qui inclut le nom de la grappe, l’interface de la liaison de commande de grappe et les autres paramètres de la grappe. Le premier nœud sur lequel vous activez la mise en grappe devient généralement le nœud de contrôle. Lorsque vous activez la mise en grappe sur les nœuds suivants, ils rejoignent la grappe en tant que nœuds de données.
Rôles des nœuds de contrôle et de données
Un membre de la grappe est le nœud de contrôle. Si plusieurs nœuds de la grappe sont mis en ligne en même temps, le nœud de contrôle est déterminé par le paramètre de priorité dans la configuration de démarrage. la priorité est réglée entre 1 et 100, 1 étant la priorité la plus élevée. Tous les autres membres sont des nœuds de données. En règle générale, lorsque vous créez une grappe pour la première fois, le premier nœud que vous ajoutez devient le nœud de contrôle simplement parce que c’est le seul nœud de la grappe à ce moment-là.
Vous devez effectuer toute la configuration (à l’exception de la configuration de démarrage) sur le nœud de contrôle uniquement; la configuration est ensuite reproduite sur les nœuds de données. Dans le cas de ressources physiques, telles que les interfaces, la configuration du nœud de contrôle est reflétée sur tous les nœuds de données. Par exemple, si vous configurez Ethernet 1/2 comme interface interne et Ethernet 1/1 comme interface externe, ces interfaces sont également utilisées sur les nœuds de données en tant qu’interfaces interne et externe.
Certaines fonctionnalités ne sont pas évolutives en grappe, et le nœud de contrôle gère tout le trafic pour ces fonctionnalités.
Interfaces individuelles
Vous pouvez configurer les interfaces de grappe en tant qu’interfaces individuelles.
Les interfaces individuelles sont des interfaces de routage normales, chacune avec sa propre adresse IP locale. La configuration d’interface doit être configurée uniquement sur le nœud de contrôle et chaque interface utilise DHCP.
Remarque |
Les canaux EtherChannels étendus de couche 2 ne sont pas pris en charge. |
Liaison de commande de grappe
Chaque nœud doit dédier une interface en tant qu’interface VXLAN (VTEP) pour la liaison de commande de grappe. Pour en savoir plus sur VXLAN, consultez Interfaces VXLAN.
Point terminal du tunnel VXLAN
Les périphériques de point terminal de tunnel VXLAN (VTEP) effectuent l’encapsulation et la désencapsulation VXLAN. Chaque VTEP comporte deux types d’interface : une ou plusieurs interfaces virtuelles appelées interfaces VNI (VXLAN Network Identifier), et une interface normale appelée interface source du VTEP qui canalise les interfaces VNI entre les VTEP. L’interface source du VTEP est connectée au réseau IP de transport pour la communication de VTEP à VTEP.
Interface de la source VTEP
L’interface source du VTEP est une interface ASA virtuel classique à laquelle vous prévoyez associer l’interface VNI. Vous pouvez configurer une interface source de VTEP pour qu’elle agisse en tant que liaison de commande de grappe. L’interface source est réservée à une utilisation avec la liaison de commande de grappe uniquement. Chaque interface source de VTEP possède une adresse IP sur le même sous-réseau. Ce sous-réseau doit être isolé de tout autre trafic et ne doit inclure que les interfaces de liaison de commande de grappe.
Interface VNI
Une interface VNI est semblable à une interface VLAN : il s’agit d’une interface virtuelle qui sépare le trafic réseau sur une interface physique donnée au moyen de balisage. Vous ne pouvez configurer qu’une seule interface VNI. Chaque interface VNI possède une adresse IP sur le même sous-réseau.
VTEP homologues
Contrairement au VXLAN habituel pour les interfaces de données, qui autorise un seul homologue VTEP, la mise en grappe ASA virtuel vous permet de configurer plusieurs homologues.
Présentation du trafic de liaison de commande de grappe
Le trafic de liaison de commande de grappe comprend à la fois un trafic de contrôle et un trafic de données.
Le trafic de contrôle comprend :
-
Choix du nœud de contrôle.
-
Duplication de la configuration.
-
Surveillance de l'intégrité
Le trafic de données comprend :
-
Duplication de l’état.
-
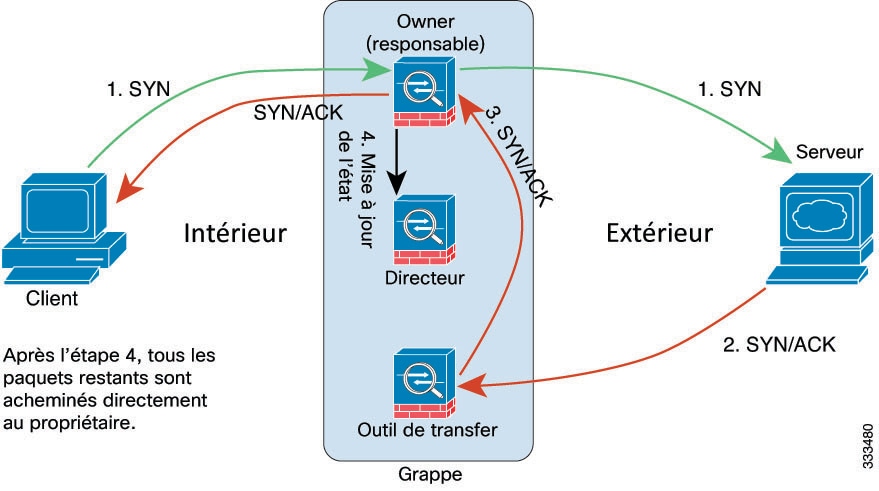
Requêtes de propriété de connexion et transfert de paquets de données.
Échec de la liaison de commande de grappe
Si le protocole de liaison de commande de grappe tombe en panne pour une unité, la mise en grappe est désactivée; les interfaces de données sont fermées. Après avoir corrigé la liaison de commande de grappe, vous devez rejoindre manuellement la grappe en réactivant la mise en grappe.
Remarque |
Lorsque l’ASA virtuel devient inactif, toutes les interfaces de données sont fermées; seule l’interface de gestion uniquement peut envoyer et recevoir du trafic. L’interface de gestion reste active en utilisant l’adresse IP que l’unité a reçue du DHCP ou de l’ensemble d’adresses IP de la grappe. Si vous utilisez un ensemble d’adresses IP de grappe, si vous rechargez et que l’unité est toujours inactive dans la grappe, l’interface de gestion n’est pas accessible (car elle utilise alors l’adresse IP principale, qui est la même que le nœud de contrôle). Vous devez utiliser le port de console (si disponible) pour toute autre configuration. |
Réplication de la configuration
Tous les nœuds de la grappe partagent une configuration unique. Vous pouvez uniquement apporter des modifications à la configuration sur le nœud de contrôle (à l’exception de la configuration de démarrage) et les modifications sont automatiquement synchronisées avec tous les autres nœuds de la grappe.
Gestion des grappes ASA virtuel
L’un des avantages de l’utilisation de la mise en grappe ASA virtuel est la facilité de gestion. Cette section décrit comment gérer la grappe.
Réseau de gestion
Nous vous conseillons de connecter tous les nœuds à un seul réseau de gestion. Ce réseau est distinct de la liaison de commande de grappe.
Interface de gestion
Utilisez l’interface Management 0/0 pour la gestion.
Remarque |
Vous ne pouvez pas activer le routage dynamique pour l’interface de gestion. Vous devez utiliser une route statique. |
Vous pouvez utiliser l’adressage statique ou DHCP pour l’adresse IP de gestion.
Si vous utilisez l’adressage statique, vous pouvez utiliser l’adresse IP de la grappe principale qui est une adresse fixe pour la grappe qui appartient toujours au nœud de contrôle actuel. Pour chaque interface, vous configurez également une plage d’adresses de sorte que chaque nœud, y compris le nœud de contrôle actuel, puisse utiliser une adresse locale de la plage. L’adresse IP de la grappe principale fournit un accès de gestion cohérent à une adresse; lorsqu’un nœud de contrôle change, l’adresse IP de la grappe principale est déplacée vers le nouveau nœud de contrôle, de sorte que la gestion de la grappe se poursuit de façon transparente. L’adresse IP locale est utilisée pour le routage et est également utile pour la résolution de problèmes. Par exemple, vous pouvez gérer la grappe en vous connectant à l’adresse IP de la grappe principale, qui est toujours associée au nœud de contrôle actuel. Pour gérer un membre, vous pouvez vous connecter à l’adresse IP locale. Pour le trafic de gestion sortant tel que TFTP ou le journal système, chaque nœud, y compris le nœud de contrôle, utilise l’adresse IP locale pour se connecter au serveur.
Si vous utilisez DHCP, vous n’utilisez pas un ensemble d’adresses locales ou n’avez pas d’adresse IP de grappe principale.
Remarque |
Le trafic vers la boîte doit être acheminé vers l’adresse IP de gestion du nœud; le trafic vers la boîte n’est pas transféré sur la liaison de commande de grappe vers un autre nœud. |
Gestion de nœud de contrôle vs Gestion de nœud de données
Toutes la gestion et la surveillance peuvent avoir lieu sur le nœud de contrôle. À partir du nœud de contrôle, vous pouvez vérifier les statistiques d’exécution, l’utilisation des ressources ou d’autres informations de surveillance sur tous les nœuds. Vous pouvez également transmettre une commande à tous les nœuds de la grappe et reproduire les messages de console des nœuds de données vers le nœud de contrôle.
Vous pouvez surveiller directement les nœuds de données si vous le souhaitez. Bien que cela soit également disponible à partir du nœud de contrôle, vous pouvez effectuer la gestion de fichiers sur les nœuds de données (y compris la sauvegarde de la configuration et la mise à jour des images). Les fonctions suivantes ne sont pas disponibles à partir du nœud de commande :
-
Surveillance des statistiques propres à la grappe par nœud.
-
Surveillance des journaux système par nœud (sauf pour les journaux système envoyés à la console lorsque la duplication de la console est activée).
-
SNMP
-
NetFlow
duplication de clé de chiffrement
Lorsque vous créez une clé de chiffrement sur le nœud de contrôle, la clé est répliquée sur tous les nœuds de données. Si vous avez une session SSH sur l’adresse IP de la grappe principale, vous serez déconnecté en cas de défaillance du nœud de contrôle. Le nouveau nœud de contrôle utilise la même clé pour les connexions SSH, de sorte que vous n’avez pas besoin de mettre à jour la clé d’hôte SSH mise en cache lorsque vous vous reconnectez au nouveau nœud de contrôle.
Incompatibilité d’adresse IP du certificat de connexion ASDM
Par défaut, un certificat autosigné est utilisé pour la connexion ASDM en fonction de l’adresse IP locale. Si vous vous connectez à l'adresse IP de la grappe principale à l'aide d'ASDM, un message d'avertissement concernant une adresse IP non concordante peut s'afficher, car le certificat utilise l'adresse IP locale, et non l'adresse IP de la grappe principale. Vous pouvez ignorer le message et établir la connexion ASDM. Cependant, pour éviter ce type d'avertissement, vous pouvez inscrire un certificat qui contient l'adresse IP de la grappe principale et toutes les adresses IP locales de l'ensemble d'adresses IP. Vous pouvez ensuite utiliser ce certificat pour chaque membre de la grappe. Consultez https://www.cisco.com/c/en/us/td/docs/security/asdm/identity-cert/cert-install.html pour de plus amples renseignements.

 Commentaires
Commentaires