|
1
|
echo_request
|
echo_request
|
echo_request
|
|
2
|
echo_response
|
echo_response
|
echo_response
|
|
3
|
version_not_supported
|
version_not_supported
|
version_not_supported
|
|
4
|
node_alive_request
|
node_alive_request
|
不适用
|
|
5
|
node_alive_response
|
node_alive_response
|
不适用
|
|
6
|
redirection_request
|
redirection_request
|
不适用
|
|
7
|
redirection_response
|
redirection_response
|
不适用
|
|
16
|
create_pdp_context_request
|
create_pdp_context_request
|
不适用
|
|
17
|
create_pdp_context_response
|
create_pdp_context_response
|
不适用
|
|
18
|
update_pdp_context_request
|
update_pdp_context_request
|
不适用
|
|
19
|
update_pdp_context_response
|
update_pdp_context_response
|
不适用
|
|
20
|
delete_pdp_context_request
|
delete_pdp_context_request
|
不适用
|
|
21
|
delete_pdp_context_response
|
delete_pdp_context_response
|
不适用
|
|
22
|
create_aa_pdp_context_request
|
init_pdp_context_activation_request
|
不适用
|
|
23
|
create_aa_pdp_context_response
|
init_pdp_context_activation_response
|
不适用
|
|
24
|
delete_aa_pdp_context_request
|
不适用
|
不适用
|
|
25
|
delete_aa_pdp_context_response
|
不适用
|
不适用
|
|
26
|
error_indication
|
error_indication
|
不适用
|
|
27
|
pdu_notification_request
|
pdu_notification_request
|
不适用
|
|
28
|
pdu_notification_response
|
pdu_notification_response
|
不适用
|
|
29
|
pdu_notification_reject_request
|
pdu_notification_reject_request
|
不适用
|
|
30
|
pdu_notification_reject_response
|
pdu_notification_reject_response
|
不适用
|
|
31
|
不适用
|
supported_ext_header_notification
|
不适用
|
|
32
|
send_routing_info_request
|
send_routing_info_request
|
create_session_request
|
|
33
|
send_routing_info_response
|
send_routing_info_response
|
create_session_response
|
|
34
|
failure_report_request
|
failure_report_request
|
modify_bearer_request
|
|
35
|
failure_report_response
|
failure_report_response
|
modify_bearer_response
|
|
36
|
note_ms_present_request
|
note_ms_present_request
|
delete_session_request
|
|
37
|
note_ms_present_response
|
note_ms_present_response
|
delete_session_response
|
|
38
|
不适用
|
不适用
|
change_notification_request
|
|
39
|
不适用
|
不适用
|
change_notification_response
|
|
48
|
identification_request
|
identification_request
|
不适用
|
|
49
|
identification_response
|
identification_response
|
不适用
|
|
50
|
sgsn_context_request
|
sgsn_context_request
|
不适用
|
|
51
|
sgsn_context_response
|
sgsn_context_response
|
不适用
|
|
52
|
sgsn_context_ack
|
sgsn_context_ack
|
不适用
|
|
53
|
不适用
|
forward_relocation_request
|
不适用
|
|
54
|
不适用
|
forward_relocation_response
|
不适用
|
|
55
|
不适用
|
forward_relocation_complete
|
不适用
|
|
56
|
不适用
|
relocation_cancel_request
|
不适用
|
|
57
|
不适用
|
relocation_cancel_response
|
不适用
|
|
58
|
不适用
|
forward_srns_contex
|
不适用
|
|
59
|
不适用
|
forward_relocation_complete_ack
|
不适用
|
|
60
|
不适用
|
forward_srns_contex_ack
|
不适用
|
|
64
|
不适用
|
不适用
|
modify_bearer_command
|
|
65
|
不适用
|
不适用
|
modify_bearer_failure_indication
|
|
66
|
不适用
|
不适用
|
delete_bearer_command
|
|
67
|
不适用
|
不适用
|
delete_bearer_failure_indication
|
|
68
|
不适用
|
不适用
|
bearer_resource_command
|
|
69
|
不适用
|
不适用
|
bearer_resource_failure_indication
|
|
70
|
不适用
|
ran_info_relay
|
downlink_failure_indication
|
|
71
|
不适用
|
不适用
|
trace_session_activation
|
|
72
|
不适用
|
不适用
|
trace_session_deactivation
|
|
73
|
不适用
|
不适用
|
stop_paging_indication
|
|
95
|
不适用
|
不适用
|
create_bearer_request
|
|
96
|
不适用
|
mbms_notification_request
|
create_bearer_response
|
|
97
|
不适用
|
mbms_notification_response
|
update_bearer_request
|
|
98
|
不适用
|
mbms_notification_reject_request
|
update_bearer_response
|
|
99
|
不适用
|
mbms_notification_reject_response
|
delete_bearer_request
|
|
100
|
不适用
|
create_mbms_context_request
|
delete_bearer_response
|
|
101
|
不适用
|
create_mbms_context_response
|
delete_pdn_request
|
|
102
|
不适用
|
update_mbms_context_request
|
delete_pdn_response
|
|
103
|
不适用
|
update_mbms_context_response
|
不适用
|
|
104
|
不适用
|
delete_mbms_context_request
|
不适用
|
|
105
|
不适用
|
delete_mbms_context_response
|
不适用
|
|
112
|
不适用
|
mbms_register_request
|
不适用
|
|
113
|
不适用
|
mbms_register_response
|
不适用
|
|
114
|
不适用
|
mbms_deregister_request
|
不适用
|
|
115
|
不适用
|
mbms_deregister_response
|
不适用
|
|
116
|
不适用
|
mbms_session_start_request
|
不适用
|
|
117
|
不适用
|
mbms_session_start_response
|
不适用
|
|
118
|
不适用
|
mbms_session_stop_request
|
不适用
|
|
119
|
不适用
|
mbms_session_stop_response
|
不适用
|
|
120
|
不适用
|
mbms_session_update_request
|
不适用
|
|
121
|
不适用
|
mbms_session_update_response
|
不适用
|
|
128
|
不适用
|
ms_info_change_request
|
identification_request
|
|
129
|
不适用
|
ms_info_change_response
|
identification_response
|
|
130
|
不适用
|
不适用
|
sgsn_context_request
|
|
131
|
不适用
|
不适用
|
sgsn_context_response
|
|
132
|
不适用
|
不适用
|
sgsn_context_ack
|
|
133
|
不适用
|
不适用
|
forward_relocation_request
|
|
134
|
不适用
|
不适用
|
forward_relocation_response
|
|
135
|
不适用
|
不适用
|
forward_relocation_complete
|
|
136
|
不适用
|
不适用
|
forward_relocation_complete_ack
|
|
137
|
不适用
|
不适用
|
forward_access
|
|
138
|
不适用
|
不适用
|
forward_access_ack
|
|
139
|
不适用
|
不适用
|
relocation_cancel_request
|
|
140
|
不适用
|
不适用
|
relocation_cancel_response
|
|
141
|
不适用
|
不适用
|
configuration_transfer_tunnel
|
|
149
|
不适用
|
不适用
|
detach
|
|
150
|
不适用
|
不适用
|
detach_ack
|
|
151
|
不适用
|
不适用
|
cs_paging
|
|
152
|
不适用
|
不适用
|
ran_info_relay
|
|
153
|
不适用
|
不适用
|
alert_mme
|
|
154
|
不适用
|
不适用
|
alert_mme_ack
|
|
155
|
不适用
|
不适用
|
ue_activity
|
|
156
|
不适用
|
不适用
|
ue_activity_ack
|
|
160
|
不适用
|
不适用
|
create_forward_tunnel_request
|
|
161
|
不适用
|
不适用
|
create_forward_tunnel_response
|
|
162
|
不适用
|
不适用
|
suspend
|
|
163
|
不适用
|
不适用
|
suspend_ack
|
|
164
|
不适用
|
不适用
|
继续执行
|
|
165
|
不适用
|
不适用
|
resume_ack
|
|
166
|
不适用
|
不适用
|
create_indirect_forward_tunnel_request
|
|
167
|
不适用
|
不适用
|
create_indirect_forward_tunnel_response
|
|
168
|
不适用
|
不适用
|
delete_indirect_forward_tunnel_request
|
|
169
|
不适用
|
不适用
|
delete_indirect_forward_tunnel_response
|
|
170
|
不适用
|
不适用
|
_access_bearer_request
|
|
171
|
不适用
|
不适用
|
release_access_bearer_response
|
|
176
|
不适用
|
不适用
|
downlink_data
|
|
177
|
不适用
|
不适用
|
downlink_data_ack
|
|
179
|
不适用
|
不适用
|
pgw_restart
|
|
180
|
不适用
|
不适用
|
pgw_restart_ack
|
|
200
|
不适用
|
不适用
|
update_pdn_request
|
|
201
|
不适用
|
不适用
|
update_pdn_response
|
|
211
|
不适用
|
不适用
|
modify_access_bearer_request
|
|
212
|
不适用
|
不适用
|
modify_access_bearer_response
|
|
231
|
不适用
|
不适用
|
mbms_session_start_request
|
|
232
|
不适用
|
不适用
|
mbms_session_start_response
|
|
233
|
不适用
|
不适用
|
mbms_session_update_request
|
|
234
|
不适用
|
不适用
|
mbms_session_update_response
|
|
235
|
不适用
|
不适用
|
mbms_session_stop_request
|
|
236
|
不适用
|
不适用
|
mbms_session_stop_response
|
|
240
|
data_record_transfer_request
|
data_record_transfer_request
|
不适用
|
|
241
|
data_record_transfer_response
|
data_record_transfer_response
|
不适用
|
|
254
|
不适用
|
end_marker
|
不适用
|
|
255
|
pdu
|
pdu
|
不适用
|


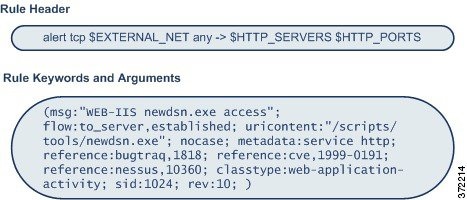
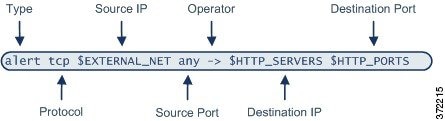




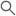
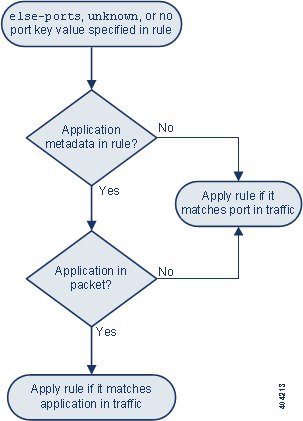
 )
)


 反馈
反馈