








Cisco Crosswork: the first closed-loop, mass-scale automation solution that embraces multivendor networks.
Cisco Crosswork
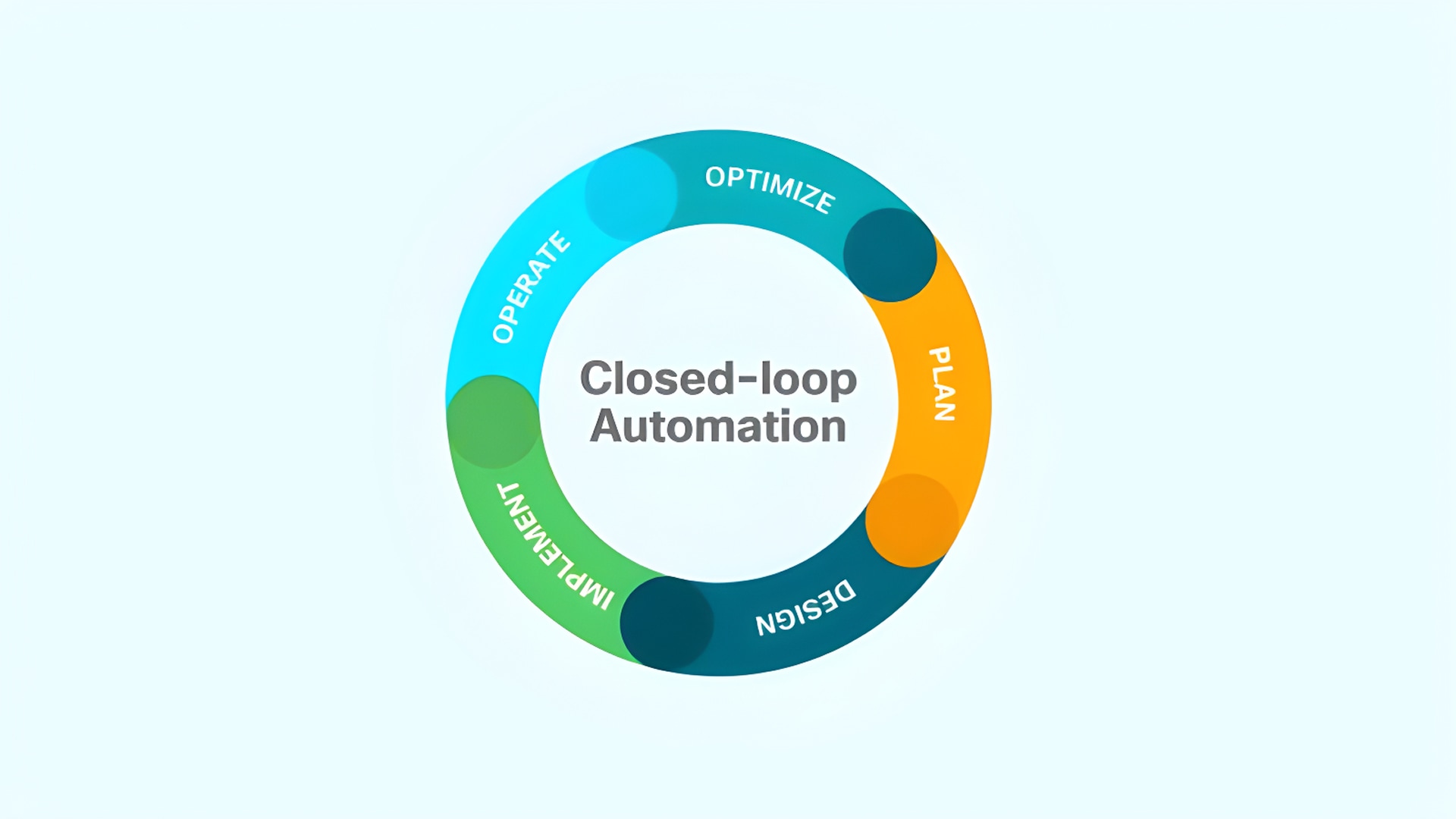
The first closed-loop, mass-scale automation solution that embraces multivendor networks. Built on the proven foundation of open APIs in Cisco Network Service Orchestrator and WAE, Cisco Crosswork now incorporates advanced data consolidation, machine learning, event correlation, and change automation down to the individual network slice and soon even across domains.
Cisco Crosswork is about being proactive, not just in actions, but in vision. It's about enabling networks to ultimately self-heal, self-optimize, and self-protect, by repairing and optimizing infrastructure from the inside – without interruption or human intervention.
Mass awareness
Collecting information from every corner of your network. Across your network, in near real time, at mass scale.
Augmented intelligence
Constantly and excessively evaluating the collected data for you. Finding the outliers—the red flags and soon-to-be red flags—and letting you know.
Proactive control
Staying ahead of things. Becoming more efficient and secure. So you can do one thing at once, for once.
Latest innovations
AIOps
Service-centric approach to AIOps
Machine learning
A deep look at machine learning
Route leaks and route hijacks
How route leaks and route hijacks affect your network
Why Cisco Crosswork Automation?
Cisco Crosswork Network Automation helps service providers proactively manage their end-to-end networks with a suite of machine-learning, intent-based and closed-loop solutions to ensure faster innovation, extraordinary customer experiences and operational excellence.
On-premises solutions provide actionable insights with automated network orchestration, accelerating mean time to value by monetizing agile new services, as well as minimizing mean time to remediation to avoid network degradation and customer issues. Cisco Crosswork Cloud provides multiple SaaS solutions that provide operational insights and validation of network health and security with the agility and scale of the cloud.
Cisco Crosswork Network Automation is ready for service providers of all sizes with broad or narrow use cases. Any device. Anytime. Anywhere. Any format. It is a truly scalable solution for a 5G world.
60
%
Reduction in time to revenue
150,000
+
Labor hours saved
70
%
Improvement in mean time to repair
99
%
Reduction in operational noise
Network Services Orchestrator (NSO)
- Multi-vendor network orchestration
- Northbound and southbound control
Network Insights
- Cloud-based SaaS
- Network routing analysis
- Monitor for route leaks or route hijacking
Trust Insights
- Cloud-based SaaS
- Ensure devices adhere to trusted Known Good Values (KGVs)
- Enhanced chain of trust with Cisco hardware
Situation Manager
- Live alert monitoring
- Noise reduction and alert grouping
Health Insights and Change Automation
- Immediate network health analysis
- Closed-loop and automated remediation
WAE
- Precise network modeling
- Optimize network traffic
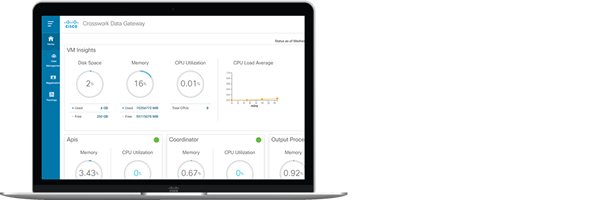
Data Gateway
- Common multi-service data collector
- Integrated data policy controls
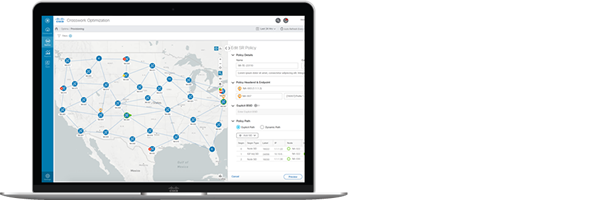
Optimization Engine
- Optimize network paths for efficiency
- Real-time end-to-end transport network visibility
- Closed-loop, intent-driven 5G transport optimization
See Cisco Crosswork in action
See how these companies are transforming
Orange saving time and reducing errors with automation
Using NSO automation, Orange accelerates the deployment of changes and additions to its multi-vendor network while reducing human errors.
Telstra manages change quickly and reliably
Using automation, Telstra and Cisco have partnered to start revolutionizing how networks are managed.
The power of one: Cisco Crosswork Network Automation
Cisco Crosswork Network Automation is a new, one-of-a-kind approach to cohesive network operations. Get true integration in a single automation solution: