À propos de la haute disponibilité (basculement)
Une configuration à haute disponibilité ou de basculement joint deux périphériques de sorte que si le périphérique principal tombe en panne, le périphérique secondaire peut prendre le relais. Cela vous aide à garder votre réseau opérationnel en cas de défaillance d’un périphérique.
La configuration de la haute disponibilité nécessite deux périphériques Cisco Firepower Threat Defense identiques connectés l’un à l’autre par un lien de basculement dédié et, éventuellement, un lien d’état. Les deux unités communiquent en permanence sur le lien de basculement pour déterminer l’état de fonctionnement de chacune d’elles et pour synchroniser les modifications de configuration déployées. Le système utilise le lien d’état pour transmettre les informations d’état de connexion au périphérique de secours, de sorte que si un basculement se produit, les connexions des utilisateurs sont conservées.
Les unités forment une paire active/en veille, où l’unité principale est l’unité active et transmet le trafic. L’unité secondaire (en veille) ne transmet pas activement le trafic, mais synchronise la configuration et les autres renseignements d’état de l’unité active.
L’intégrité de l’unité active (matériel, interfaces, logiciels et état environnemental) est surveillée pour déterminer si les conditions spécifiques au basculement sont respectées. Si ces conditions sont remplies, l’unité active bascule vers l’unité en veille, qui devient alors active.
À propos du basculement actif/de secours
Le basculement actif/en veille vous permet d’utiliser un appareil FTD de secours pour reprendre les fonctionnalités d’une unité en panne. Lorsque l’unité active tombe en panne, l’unité en veille devient l’unité active.
Rôles principal/secondaire et état actif/de secours
Les principales différences entre les deux unités d’une paire de basculement dépendent de l’unité active et de l’unité en veille, à savoir les adresses IP à utiliser et l’unité transmettant activement le trafic.
Cependant, il existe quelques différences entre les unités en fonction de l’unité principale (comme spécifié dans la configuration) et de l’unité secondaire :
-
L’unité principale devient toujours l’unité active si les deux unités démarrent en même temps (et ont le même état de fonctionnement opérationnel).
-
Les adresses MAC de l’unité principale sont toujours associées aux adresses IP actives. L’exception à cette règle se produit lorsque l’unité secondaire devient active et ne peut pas obtenir les adresses MAC de l’unité principale sur la liaison de basculement. Dans ce cas, les adresses MAC des unités secondaires sont utilisées.
Détermination de l’unité active au démarrage
L’unité active est déterminée par les éléments suivants :
-
Si une unité démarre et détecte un homologue qui fonctionne déjà comme actif, elle devient l’unité de secours.
-
Si une unité démarre et ne détecte pas d’homologue, elle devient l’unité active.
-
Si les deux unités démarrent simultanément, l’unité principale devient l’unité active et l’unité secondaire devient l’unité de secours.
Événements de basculement
Dans le cas d'un basculement actif/de secours, le basculement se produit de manière unitaire.
Le tableau suivant présente l’action de basculement pour chaque défaillance. Pour chaque défaillance, le tableau indique la politique de basculement (basculement ou absence de basculement), l’action prise par l’unité active, l’action entreprise par l’unité de secours, et toute remarque spéciale sur la condition et les actions de basculement.
|
Défaillance |
Politique |
Action de l’unité active |
Action de l’unité de secours |
Notes |
|---|---|---|---|---|
|
Défaillance de l’unité active (alimentation ou matérielle) |
Basculement |
S.O. |
Devenir active Marquer l'unité active comme défaillante |
Aucun message Hello n’est reçu sur l’interface surveillée ou sur la liaison de basculement. |
|
L’unité précédemment active récupère |
Aucun basculement |
Devient l'unité de secours |
Aucune action |
Aucun. |
|
Défaillance de l’unité de secours (alimentation ou matériel) |
Aucun basculement |
Marquer l'unité de secours come défaillante |
S.O. |
Lorsque l’unité de secours est marquée comme défaillante, l’unité active ne tente pas de basculer, même si le seuil de défaillance de l’interface est dépassé. |
|
Échec du la liaison de basculement pendant l’opération |
Aucun basculement |
Marquer la liaison de basculement comme défaillante |
Marquer la liaison de basculement comme défaillante |
Vous devez restaurer la liaison de basculement dès que possible, car l’unité ne peut pas basculer vers l’unité de secours lorsque la liaison de basculement est inactive. |
|
Échec de la liaison de basculement au démarrage |
Aucun basculement |
Devenir active Marquer la liaison de basculement comme défaillante |
Devenir active Marquer la liaison de basculement comme défaillante |
Si la liaison de basculement est interrompue au démarrage, les deux unités deviennent actives. |
|
Échec du lien avec l’état |
Aucun basculement |
Aucune action |
Aucune action |
Les informations d’état deviennent obsolètes et les sessions sont interrompues en cas de basculement. |
|
Défaillance de l'interface sur l'unité active supérieure au seuil |
Basculement |
Marquer l'unité active comme défaillante |
Devenir active |
Aucun. |
|
Défaillance de l'interface sur l'unité de secours supérieure au seuil |
Aucun basculement |
Aucune action |
Marquer l'unité de secours come défaillante |
Lorsque l’unité de secours est marquée comme en panne, l’unité active ne tente pas de basculer, même si le seuil de défaillance de l’interface est dépassé. |
Liens de basculement et de basculement avec état
Le lien de basculement est une connexion dédiée entre les deux unités. Le lien de basculement avec état est également une connexion dédiée, mais vous pouvez soit utiliser le lien de basculement comme lien de basculement/avec état combiné, soit créer un lien d’état dédié distinct. Si vous utilisez uniquement le lien de basculement, les informations sur l’état passent également par ce lien; vous ne perdez pas la capacité de basculement avec état.
Par défaut, les communications sur les liens de basculement et de basculement avec état sont en texte brut (non chiffré). Vous pouvez chiffrer les communications pour une sécurité renforcée en configurant une clé de chiffrement IPsec.
Les rubriques suivantes expliquent ces interfaces plus en détail et comprennent des recommandations sur la façon de câbler les périphériques pour obtenir les meilleurs résultats.
Lien de basculement
Les deux unités d'une paire de basculement communiquent en permanence sur une liaison de basculement pour déterminer l'état de fonctionnement de chaque unité et synchroniser les modifications de configuration.
Les informations suivantes sont transmises par la liaison de basculement :
-
L’état de l’unité (actif ou en veille).
-
Messages Hello (keep-alives).
-
État de la liaison réseau.
-
Échange d’adresses MAC.
-
Réplication et synchronisation de la configuration
-
Mises à jour des bases de données du système, y compris la VDB et les règles, mais excluant les bases de données de géolocalisation et de Security Intelligence. Chaque système télécharge séparément les mises à jour de géolocalisation et de Security Intelligence. Si vous créez un calendrier de mise à jour, ceux-ci doivent rester synchronisés. Toutefois, si vous effectuez une mise à jour manuelle de géolocalisation ou de Security Intelligence sur le périphérique actif, vous devez également en faire une sur le périphérique en veille.
 Remarque |
Les données d’événements, de rapports et du journal d’audit ne sont pas synchronisées. La visionneuse d’événements et les tableaux de bord affichent uniquement les données liées à l’unité concernée. En outre, l’historique de déploiement, l’historique des tâches et les autres événements du journal d’audit ne sont pas synchronisés. |
Lien de basculement dynamique
Le système utilise la liaison d’état pour transmettre les informations d’état de connexion au périphérique de secours. Ces informations aident l’unité de secours à maintenir les connexions existantes en cas de basculement.
L’utilisation d’une liaison unique pour les liens de basculement et de basculement dynamique est la meilleure façon de conserver les interfaces. Cependant, vous devez envisager une interface dédiée pour le lien d’état et le lien de basculement, si votre configuration est importante et que le trafic sur le réseau est élevé.
Interfaces pour les liens de basculement et d’état
Vous pouvez utiliser une interface de données inutilisée, mais activée (physique ou EtherChannel) comme liaison de basculement ; cependant, vous ne pouvez pas spécifier une interface actuellement configurée avec un nom. L’interface de liaison de basculement n’est pas configurée comme une interface réseau normale; il existe pour la communication de basculement uniquement. Cette interface ne peut être utilisée que pour la liaison de basculement (ainsi que pour le lien d’état). Vous ne pouvez pas utiliser une interface de gestion, sous-interface, une interface VLAN ou un port de commutation pour le basculement.
L’appareil Cisco Firepower Threat Defense ne prend pas en charge le partage des interfaces entre les données utilisateur et le lien de basculement.
Consultez les consignes suivantes concernant la taille de la liaison de basculement et de l’état :
-
Firepower 4100/9300 : nous vous recommandons d’utiliser une interface de données de 10 Go pour la combinaison de liaison de basculement et de liaison d’état.
-
Tous les autres modèles : l’interface de 1 Go est suffisante pour une combinaison de liaison de basculement et d’état.
Lorsque vous utilisez une interface EtherChannel comme liaison de basculement ou d’état, vous devez confirmer que la même interface EtherChannel avec le même ID et les mêmes interfaces membres existe sur les deux appareils avant d’établir la haute disponibilité. S’il y a une incompatibilité EtherChannel, vous devez désactiver la haute disponibilité et corriger la configuration sur l’unité secondaire avant. Pour éviter les paquets dans le désordre, une seule interface dans l’EtherChannel est utilisée. Si cette interface échoue, l’interface suivante de l’EtherChannel est utilisée. Vous ne pouvez pas modifier la configuration de l’EtherChannel lorsqu’il est utilisé comme liaison de basculement.
Connexion des interfaces de basculement et de basculement dynamique
Vous pouvez utiliser toutes les interfaces physiques de données inutilisées comme liaison de basculement et liaison d’état dédiée facultative. Cependant, vous ne pouvez pas sélectionner une interface actuellement configurée avec un nom ou une interface qui comporte des sous-interfaces. Les interfaces de liaison de basculement et de basculement avec état ne sont pas configurées comme des interfaces réseau normales; elles existent uniquement pour la communication de basculement. Ils existent uniquement pour les communications de basculement, et vous ne pouvez pas les utiliser pour le trafic de transit ou l’accès de gestion.
Comme la configuration est synchronisée entre les périphériques, vous devez sélectionner le même numéro de port pour chaque extrémité de liaison. Par exemple, GigabitEthernet1/3 sur les deux appareils pour le lien de basculement.
Connectez le lien de basculement, et le lien d’état dédié si utilisé, de l’une des deux manières suivantes :
-
À l'aide d'un commutateur, sans autre périphérique sur le même segment de réseau (domaine de diffusion ou VLAN) que les interfaces de basculement du périphérique Cisco Firepower Threat Defense. Une liaison d’état dédiée a les mêmes exigences, mais doit se trouver sur un segment de réseau différent de celui de la liaison de basculement.
Remarque
L’intérêt de l’utilisation d’un commutateur est que si l’une des interfaces de l’unité tombe en panne, il est facile de déterminer quelle interface est défaillante. Si vous utilisez une connexion directe par câble, en cas de défaillance d’une interface, la liaison est interrompue sur les deux homologues, ce qui rend difficile de déterminer quel périphérique est défectueux.
-
L’utilisation d’un câble Ethernet pour connecter les unités directement, sans avoir besoin d’un commutateur externe. Le périphérique Cisco Firepower Threat Defense prend en charge Auto-MDI/MDIX sur ses ports Ethernet en cuivre ; vous pouvez donc utiliser un câble croisé ou un câble droit. Si vous utilisez un câble droit, l’interface détecte automatiquement le câble et échange l’une des paires de transmission/réception contre MDIX.
Pour des performances optimales lors de l’utilisation du basculement longue distance, la latence de la liaison d’état doit être inférieure à 10 millisecondes et non supérieure à 250 millisecondes. Si la latence est supérieure à 10 millisecondes, une certaine dégradation des performances se produit en raison de la retransmission des messages de basculement.
Éviter le basculement interrompu et les liaisons de données
Nous recommandons que les liens de basculement et les interfaces de données empruntent différentes voies pour réduire le risque d’échec de toutes les interfaces en même temps. Si le lien de basculement est arrêté, l’appareil Cisco Firepower Threat Defense peut utiliser les interfaces de données pour déterminer si un basculement est requis. Ensuite, l’opération de basculement est suspendue jusqu’à ce que l’intégrité du lien de basculement soit restaurée.
Consultez les scénarios de connexion suivants pour concevoir un réseau de basculement résilient.
Scénario 1 (non recommandé)
Si un seul commutateur ou un ensemble de commutateurs est utilisé pour connecter les interfaces de basculement et de données entre deux périphériques Cisco Firepower Threat Defense, quand un commutateur ou une liaison inter-commutateurs sont en panne, les deux périphériques deviennent actifs.Cisco Firepower Threat Defense Par conséquent, les deux méthodes de connexion indiquées dans les figures suivantes ne sont pas recommandées.


Scénario 2 (recommandé)
Nous recommandons que les liens de basculement n'utilisent pas le même commutateur que les interfaces de données. Au lieu de cela, utilisez un commutateur différent ou utilisez un câble direct pour connecter le lien de basculement, comme le montrent les figures suivantes.
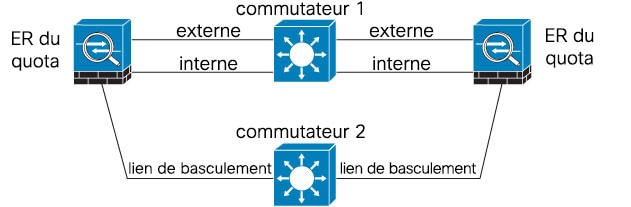
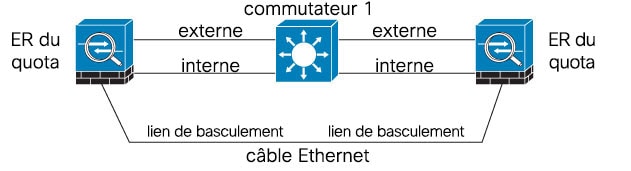
Scénario 3 (recommandé)
Si les interfaces de données Cisco Firepower Threat Defense sont connectées à plusieurs ensembles de commutateurs, un lien de basculement peut être connecté à l’un des commutateurs, de préférence le commutateur du côté sécurisé (interne) du réseau, comme le montre la figure suivante.
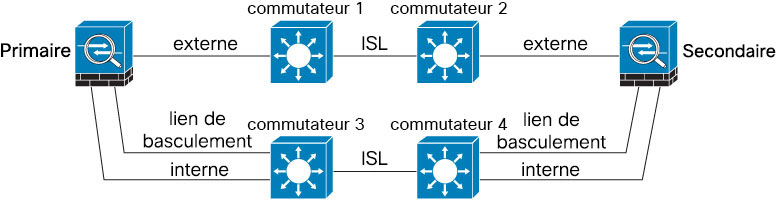
Incidence du basculement dynamique sur les connexions utilisateur
L’unité active partage les informations sur l’état de la connexion avec l’unité de secours. Cela signifie que l’unité de secours peut maintenir certains types de connexions sans nuire à l’utilisateur.
Cependant, il existe certains types de connexions qui ne prennent pas en charge le basculement avec état. Pour ces connexions, l’utilisateur devra rétablir la connexion en cas de basculement. Souvent, cela se produit automatiquement en fonction du comportement du protocole utilisé dans la connexion.
Les rubriques suivantes expliquent quelles fonctionnalités sont prises en charge ou non pour le basculement avec état.
Fonctionnalités prises en charge
Pour le basculement avec état, les renseignements d’état suivants sont transmis au appareil FTD de secours :
-
table de traduction NAT
-
Les connexions et les états TCP et UDP, y compris les états des connexions HTTP. Les autres types de protocoles IP et ICMP ne sont pas analysés par l'unité active, car ils sont établis sur la nouvelle unité active à l'arrivée d'un nouveau paquet.
-
États de connexion Snort, résultats d’inspection et informations sur les trous d’épingle, y compris une application stricte du protocole TCP.
-
La table ARP
-
La table des ponts de couche 2 (pour les groupes de ponts)
-
La table ISAKMP et IPsec SA
-
La base de données sur les connexions GTP-PDP
-
Sessions de signalisation SIP et trous d'épingle.
-
Tables de routage statiques et dynamiques : le basculement dynamique participe aux protocoles de routage dynamiques, tels que OSPF et EIGRP, de sorte que les itinéraires appris par les protocoles de routage dynamiques sur l'unité active sont conservés dans une table RIB (Routing Information Base) sur l'unité en attente. Lors d’un basculement, les paquets se déplacent normalement avec une perturbation minimale du trafic, car l’unité secondaire active est initialement soumise à des règles qui reflètent l’unité principale. Immédiatement après le basculement, le délai de reconvergence démarre sur l'unité nouvellement active. Ensuite, le numéro de la période pour la table RIB est incrémenté. Pendant la reconvergence, les routes OSPF et EIGRP sont mises à jour avec un nouveau numéro de période. Une fois la minuterie expirée, les entrées de route périmées (déterminées par le numéro de période) sont supprimées du tableau. Le RIB contient ensuite les informations de transfert les plus récentes du protocole de routage sur la nouvelle unité active.
Remarque
Les routages ne sont synchronisés que pour les événements de connexion ou de déconnexion sur une unité active. Si le lien est actif ou inactif sur l’unité de secours, les routages dynamiques envoyés à partir de l’unité active peuvent être perdus. Ce comportement est tout à fait normal et attendu.
-
Serveur DHCP : les baux d’adresses DHCP ne sont pas répliqués. Cependant, un serveur DHCP configuré sur une interface enverra un message ping pour s’assurer qu’une adresse n’est pas utilisée avant d’accorder l’adresse à un client DHCP, donc il n’y a pas d’incidence sur le service. Les informations d’état ne sont pas pertinentes pour le relais DHCP ou DDNS.
-
Décisions relatives à la politique de contrôle d’accès : les décisions relatives à la correspondance du trafic (y compris l’URL, la catégorie d’URL, la géolocalisation, etc.), la détection des intrusions, les programmes malveillants et le type de fichier sont conservées pendant le basculement. Cependant, pour les connexions évaluées au moment du basculement, les mises en garde suivantes doivent être apportées :
-
AVC : Les verdicts d’ID d’application sont répliqués, mais pas les états de détection. Une synchronisation appropriée a lieu tant que les verdicts App-ID sont complets et synchronisés avant le basculement.
-
État de la détection d'intrusion : lors du basculement, une fois que le prélèvement en milieu de flux se produit, de nouvelles inspections sont effectuées, mais les anciens états sont perdus.
-
Blocage des programmes malveillants : l'élimination des fichiers doit être disponible avant le basculement.
-
Détection et blocage du type de fichier : le type de fichier doit être identifié avant le basculement. Si le basculement se produit pendant que le périphérique actif d’origine identifie le fichier, le type de fichier n’est pas synchronisé. Même si votre politique de fichiers bloque ce type de fichier, le nouveau périphérique actif télécharge le fichier.
-
-
Décisions relatives à l’identité de l’utilisateur passif de la politique d’identité, mais pas celles recueillies lors de l’authentification active sur un portail captif.
-
Décisions en matière de renseignements sur la sécurité.
-
VPN d'accès à distance : les utilisateurs finaux du VPN d’accès à distance n’ont pas à s’authentifier ou à reconnecter la session VPN après un basculement. Cependant, les applications fonctionnant sur la connexion VPN pourraient perdre des paquets pendant le processus de basculement et ne pas se rétablir après la perte de paquets.
-
De toutes les connexions, seules celles établies seront répliquées sur l’ASA de secours.
Fonctionnalités non prises en charge
Pour le basculement avec état, les informations d'état suivantes ne sont pas transmises au appareil FTD de secours :
-
Sessions dans des tunnels en texte brut comme GRE ou IP-in-IP. Les sessions à l’intérieur des tunnels ne sont pas répliquées et le nouveau nœud actif ne pourra pas réutiliser les verdicts d’inspection existants pour faire correspondre les règles de politique correctes.
-
Connexions TLS/SSL déchiffrées : les états de déchiffrement ne sont pas synchronisés et si l’unité active échoue, les connexions déchiffrées seront réinitialisées. De nouvelles connexions devront être établies avec la nouvelle unité active. Les connexions qui ne sont pas déchiffrées (c’est-à-dire celles qui correspondent à une action de règle Ne pas déchiffrer de TLS/SSL) ne sont pas affectées et sont répliquées correctement.
-
Le routage de multidiffusion
Modifications de configuration et actions autorisées sur une unité de secours
Lorsque vous fonctionnez en mode de haute disponibilité, vous apportez des modifications de configuration à l’unité active uniquement. Lorsque vous déployez la configuration, les nouvelles modifications sont également transmises à l’unité de secours.
Cependant, certaines propriétés sont uniques à l’unité de secours. Vous pouvez modifier les éléments suivants sur une unité de secours :
-
Adresse IP de l’interface de gestion et passerelle.
-
(Interface de ligne de commande uniquement.) Le mot de passe du compte d’utilisateur admin et des autres comptes d’utilisateurs locaux. Vous pouvez effectuer cette modification dans l’interface de ligne de commande uniquement ; vous ne pouvez pas la faire dans FDM. Tout utilisateur local devra modifier son mot de passe sur les deux unités séparément.
En outre, les actions suivantes sont disponibles sur un périphérique de secours.
-
Actions de haute disponibilité, telles que la suspension, la reprise, la réinitialisation et l’interruption de la haute disponibilité, ainsi que la commutation des modes entre actif et en veille.
-
Les données de tableau de bord et d’événements sont propres à chaque périphérique et ne sont pas synchronisées. Cela inclut les affichages personnalisés dans Event Viewer (Visionneuse d’événements)
-
Les informations du journal d’audit sont uniques par périphérique.
-
Enregistrement de licence Smart. Cependant, vous devez activer ou désactiver les licences facultatives sur l’unité active, et l’action est synchronisée avec l’unité de secours, qui demande ou libère la licence appropriée.
-
Sauvegarde, mais pas restauration. Vous devez interrompre la haute disponibilité sur l’unité pour restaurer une sauvegarde. Si la sauvegarde comprend la configuration à haute disponibilité, l’unité rejoindra le groupe à haute disponibilité.
-
Installation de mise à niveau logicielle.
-
Génération de journaux de dépannage.
-
Mise à jour manuelle des bases de données de géolocalisation ou de Security Intelligence. Ces bases de données ne sont pas synchronisées entre les unités. Si vous créez un calendrier de mise à jour, les unités peuvent maintenir indépendamment la cohérence.
-
Vous pouvez afficher les sessions utilisateur FDM actives et supprimer des sessions à partir de la page .







 Commentaires
Commentaires