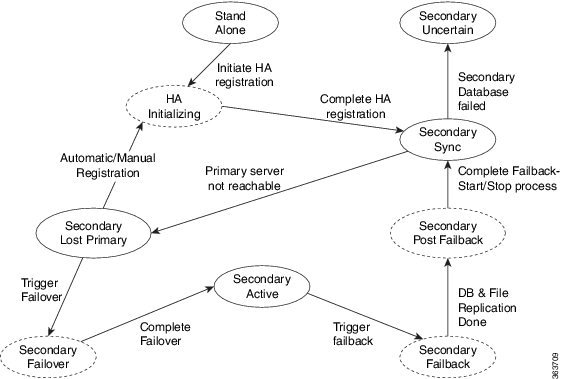
ハイ アベイラビリティの仕組み
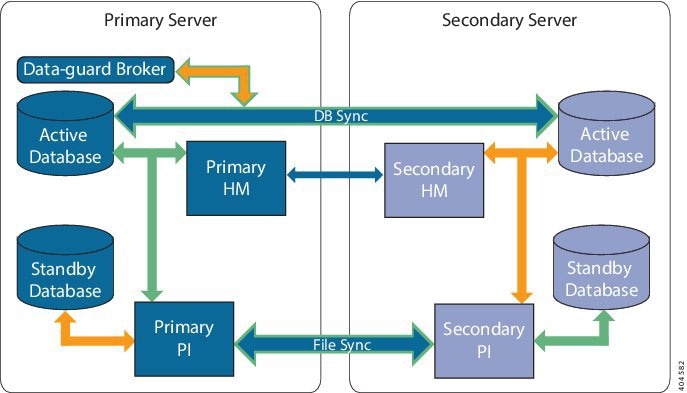
HA の導入には、2 台の Prime Infrastructure サーバー(プライマリとセカンダリ)が必要です。これらのサーバーのそれぞれに、アクティブ データベースとアクティブ データベースのスタンバイ バックアップ コピーがあります。通常状態では、プライマリ サーバーがアクティブです。つまり、プライマリ サーバーが自身のアクティブ データベースに接続されており、ネットワークを管理します。セカンダリ サーバーはパッシブ状態で、自身のスタンバイ データベースのみに接続されていますが、プライマリ サーバーとは継続的な通信状態にあります。
両方のサーバーで実行されているヘルス モニター プロセスにより、お互いのサーバーのステータスがモニターされています。両方のサーバー上で実行されている Oracle Recovery Manager(RMAN)は、アクティブ データベースおよびスタンバイ データベースを作成し、変更の発生時には、プライマリ サーバーで実行される Oracle Data Guard Broker の効果によりデータベースを同期します。
プライマリ サーバーに障害が発生すると、セカンダリが引き継ぎ、自身のアクティブ データベースに接続します。このデータベースは、アクティブ プライマリ データベースと同期されています。この切り替えは「フェールオーバー」と呼ばれ、手動(推奨)または自動でトリガーできます。その後は、プライマリ サーバーへのアクセスの復元作業をしながら、セカンダリ サーバーを使用してネットワークを管理します。プライマリ サーバーが再度使用可能になると、プライマリ サーバーに戻するための切り替え(「フェールバック」)を開始し、プライマリを使用してネットワーク管理を再開できます。
プライマリ サーバーとセカンダリ サーバーを同一 IP サブネットに導入する場合は、1 つの仮想 IP アドレスで Prime Infrastructure に通知を送信するようにデバイスを設定できます。ディザスタ リカバリの実施などの目的で、2 台のサーバーを地理的に離れた位置に分散する場合は、両方のサーバーに通知を送信するようにデバイスを設定する必要があります。
プライマリ サーバーとセカンダリ サーバーについて
すべての Prime Infrastructure HA 実装には、プライマリ サーバーの特定のインスタンスに対して専用のセカンダリ サーバーが 1 台のみ必要です。
通常、HA サーバーごとに独自の IP アドレスまたはホスト名が設定されています。同一サブネット上に配置されているサーバーは、仮想 IP を使用して同じ IP を共有できます。これにより、デバイスの設定が容易になります。Prime Infrastructure のプライマリおよびセカンダリ サーバーは、HA 実装時にネットワーク インターフェイス ethernet0(eth0)で有効にする必要があります。
HA をセットアップした後は、HA サーバーの IP アドレスやホスト名を変更しないください。変更すると、HA 設定が失われます(「関連項目」の「サーバーの IP アドレスまたはホスト名のリセット」を参照)。
障害の原因
Prime Infrastructure サーバーの障害は、以下の 1 つ以上の分野での問題が原因で発生する可能性があります。
- アプリケーション プロセス:NMS サーバー、MATLAB、TFTP、FTP を含め、1 つ以上の Prime Infrastructure サーバー プロセスが失敗した場合。各アプリケーション プロセスの動作ステータスを確認するには、管理コンソールから ncs status コマンドを実行します。
- データベース サーバー:1 つ以上のデータベース関連のプロセスがダウンした場合。データベース サーバーは、Prime Infrastructure 内のサービスとして実行されます。
- ネットワーク:ネットワーク アクセスの問題や、到達可能性の問題が発生した場合。
- システム:サーバーの物理ハードウェアまたはオペレーティング システムに関連する問題が発生した場合。
- 仮想マシン(VM):プライマリ サーバーとセカンダリ サーバーがインストールされている VM 環境に問題が発生した場合(HA が VM 環境で稼動している場合)。
詳細については、「ハイ アベイラビリティの仕組み」を参照してください。
ファイルおよびデータベースの同期
HA コンフィギュレーションが、プライマリ サーバーでの変更を判別すると、常にその変更がセカンダリ サーバーに同期されます。これらの変更には、次の 2 種類があります。
- データベース:コンフィギュレーション、パフォーマンス、およびモニタリング データに関連するデータベースの更新などです。
- ファイル:コンフィギュレーション ファイルに対する変更などです。
両方のサーバー上で実行されている Oracle Recovery Manager(RMAN)は、アクティブ データベースおよびスタンバイ データベースを作成し、変更の発生時には、プライマリ サーバーで実行される Oracle Data Guard Broker の効果によりデータベースを同期します。
ファイルの変更内容は、HTTPS プロトコルを使用して同期されます。ファイルの同期は、以下のいずれかの方法で行われます。
- バッチ:このカテゴリには、頻繁に更新されないファイル(ライセンス ファイルなど)が含まれます。これらのファイルは、500 秒間隔で同期されます。
- ほぼリアルタイム:頻繁に更新されるファイルは、このカテゴリに分類されます。これらのファイルは、11 秒間隔で同期されます。
デフォルトでは、HA フレームワークは、必要なすべての構成データをコピーするように設定されます。これらの構成データには、以下が含まれます。
- レポート設定
- コンフィギュレーション テンプレート
- TFTP ルート
- 管理設定
- ライセンス ファイル
HA サーバー通信
プライマリおよびセカンダリ HA サーバーは、HA システムのヘルスを維持するために、次のメッセージを交換します。
- データベース同期:プライマリ サーバーとセカンダリ サーバー上のデータベースが稼働および同期するために必要なすべての情報が含まれます。
- ファイル同期:頻繁に更新されるコンフィギュレーション ファイルが含まれます。これらのファイルは 11 秒間隔で同期され、他の頻繁に更新されないコンフィギュレーション ファイルは 500 秒間隔で同期されます。
- プロセス同期:アプリケーションおよびデータベースに関連するプロセスの実行が継続されるようにします。これらのメッセージは、ハートビート カテゴリに分類されます。
- Health Monitor 同期:これらのメッセージは、以下の障害状態の有無を確認します。
- ネットワーク障害
- システム障害(サーバー ハードウェアとオペレーティング システムでの障害)
- ヘルス モニター障害
ヘルス モニター プロセス
Health Monitor(HM)とは、HA 操作を管理する主要コンポーネントです。プライマリ サーバーとセカンダリ サーバーでは、それぞれ別個の HM インスタンスがアプリケーション プロセスとして実行されます。HM は、以下の役割を果たします。
- HA に関連するデータベースおよび構成データを同期します(Oracle Data Guard を使用して別途同期されるデータベースは除きます)。
- プライマリ サーバーとセカンダリ サーバーの間で 5 秒間隔でハートビート メッセージを交換し、サーバー間の通信が維持されていることを確認します。
- 両方のサーバー上で使用可能なディスク容量を定期的に確認し、ストレージ容量が不足している場合にはイベントを生成します。
- リンクされた HA サーバー全体のヘルスを管理、制御、モニターします。プライマリ サーバーで障害が発生した場合にセカンダリ サーバーをアクティブ化するのは、Health Monitor の役目です。
ヘルス モニター Web ページ
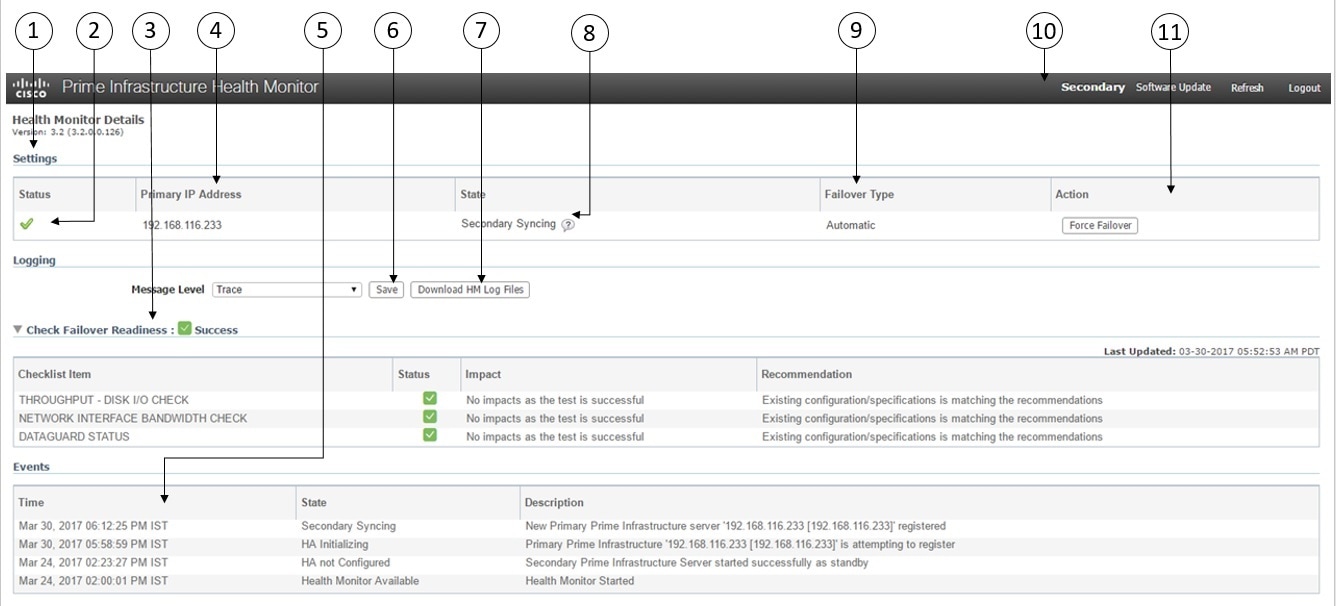
Health Monitor Web ページを使用して HA の動作を制御します。プライマリ サーバーまたはセカンダリ サーバーで実行される Health Monitor インスタンスごとに、専用の Web ページがあります。次の図に、「プライマリ アクティブ」状態と「セカンダリ同期中」状態にあるセカンダリ サーバーのヘルス モニター Web ページの例を示します。
|
1 |
[設定(Settings)] 領域に、ヘルス モニターの状態と設定の詳細情報を示す 5 つのセクションが表示されています。 |
|
2 |
[Status] は、HA セットアップの現在の機能ステータスを示します(緑色のチェック マークは、HA がオンであり機能していることを実行します)。 |
|
3 |
[フェールオーバーの準備状況の確認(Check Failover Readiness)] フィールドに、チェックリスト項目のシステム フェールバックの値とシステム フェールオーバーの詳細が表示されます。 詳細については、表の下の「フェールオーバーの準備状況の確認」を参照してください。 |
|
4 |
[プライマリ IP アドレス(Primary IP Address)] は、このセカンダリ サーバーのピア サーバーの IP を示します(プライマリ サーバーの場合、このフィールドには [セカンダリ IP アドレス(Secondary IP Address)] というラベルが付いています)。 |
|
5 |
[イベント(Events)] 表には、現在のすべての HA 関連イベントが最新のイベントを先頭に時系列順に表示されます。 |
|
6 |
[Message Level] フィールドでは、ログ レベル([Error]、[Informational]、[Trace])を変更できます。ログ レベルを変更するには、[保存(Save)] をクリックする必要があります。 |
|
7 |
[ロギング ダウンロード(Logging Download)] 領域では、ヘルス モニター ログ ファイルをダウンロードできます。 |
|
8 |
[状態(State)] は、この Health Monitoring インスタンスが実行されているサーバーの現在の HA の状態を示します。 |
|
9 |
[フェールオーバー タイプ(Failover Type)] は、設定されているフェールオーバー タイプ([手動(Manual)] または [自動(Automatic)])を示します。 |
|
10 |
表示している Health Monitor Web ページの対象 HA サーバーを示します。 |
|
11 |
[アクション(Actions)] は、実行できるアクション(フェールオーバーまたはフェールバック)を示します。[アクション(Actions)] のボタンは、HA 状態の変更が必要なアクションが Health Monitor により検出された場合にだけ有効になります。 |
|
チェックリスト名 |
説明 |
||
|---|---|---|---|
|
システム - ディスク IOPS の確認(SYSTEM - CHECK DISK IOPS) |
プライマリ サーバーとセカンダリ サーバーの両方でディスク IOPS を検証します。 必要な最小ディスク IOPS は 200 Mbps です。 |
||
|
ネットワーク - ネットワーク インターフェイスの帯域幅確認(NETWORK - CHECK NETWORK INTERFACE BANDWIDTH) |
プライマリ サーバーとセカンダリ サーバーの両方で eth0 インターフェイス速度が推奨速度の 100 Mbps と一致するかどうかを確認します。 このテストでは、プライマリ サーバーとセカンダリ サーバー間でのデータ送信によるネットワーク帯域幅の測定は行いません。 |
||
|
ネットワーク - ネットワーク帯域幅速度の確認(NETWORK - CHECK NETWORK BANDWIDTH SPEED) |
プライマリ サーバーとセカンダリ サーバーの両方でネットワーク帯域幅速度が推奨速度の 100 Mbps と一致するかどうかを確認します。 このテストでは、プライマリ サーバーとセカンダリ サーバーの間でデータを送信することによってネットワーク帯域幅を測定します。
|
||
|
データベース - 同期ステータス(DATABASE - SYNC STATUS) |
プライマリ データベースとセカンダリ データベースを同期する Oracle Data Guard Broker の設定を確認します。 |
フェールオーバー準備状況の確認に関する傾向グラフ:
-
傾向グラフの [ここをクリック(Click here)] リンクをクリックして、すべてのフェールオーバー準備状況の確認テストに関する傾向グラフを確認します。傾向グラフには、テストの履歴サマリーとシステム/ネットワークの安定性に関するステータスが示されます。
-
[日付範囲の選択(Select Date Range)] をクリックして日付と時刻を変更し、[適用(Apply)] をクリックします。デフォルトでは、過去 6 時間の値が傾向グラフに表示されます。
HA での仮想 IP アドレッシングの使用
通常の状況下では、Prime Infrastructure を使用して、管理対象デバイスがその syslog、SNMP トラップ、およびその他の情報を Prime Infrastructure サーバーの IP アドレスに送信するように設定します。HA を実装する場合、それぞれ異なる IP アドレスを持つ 2 台の Prime Infrastructure サーバーが導入されます。プライマリ サーバーと同様にセカンダリ サーバーにも通知を送信するようにデバイスを再設定しないと、セカンダリ Prime Infrastructure サーバーがアクティブ モードになったときに、セカンダリ サーバーではすべての通信が受信されません。
管理対象デバイスすべてで 2 台の別個のサーバーに通知を送信するよう設定する場合、追加のデバイス設定作業が必要です。この追加のオーバーヘッドを回避するため、HA では両方のサーバーが管理アドレスとして共有できる仮想 IP アドレスの使用がサポートされています。フェールオーバー プロセスとフェールバック プロセスの実行中に、この 2 台のサーバーは必要に応じて IP を切り替えます。仮想 IP アドレスは常に、正しい Prime Infrastructure サーバーを指し示します。
両方の HA サーバーのアドレスおよび仮想 IP がすべて同じサブネット上にない場合、仮想 IP アドレッシングを使用できないことに注意してください。これは、HA サーバー導入の選択方法に影響する可能性があります(「関連項目」の「HA の導入計画」および「ローカル モデルの使用」参照)。
また、仮想 IP アドレスを 2 つのサーバー IP アドレスの代わりとして使用することは一切意図されていないことに注意してください。仮想 IP は、syslog やトラップなど Prime Infrastructure サーバーに送信されるデバイス管理メッセージの宛先として使用されます。デバイスのポーリングは、2 つの Prime Infrastructure サーバー IP アドレスのうちの 1 つから常に実施されます。このことを考慮すると、仮想 IP アドレッシングを使用している場合、3 つすべてのアドレス(仮想 IP アドレスおよび 2 つの実際のサーバー IP)における着信および発信 TCP/IP 通信に対してファイアウォールを開く必要があります。
オペレーション センターでの HA の使用を計画している場合、仮想 IP アドレッシングを使用することもできます。オペレーション センターが有効になっている Prime Infrastructure インスタンスに仮想 IP を SSO として割り当てることができます。オペレーション センターを使用して管理されているインスタンスには、仮想 IP は必要ありません(「オペレーション センター用の HA の有効化」を参照)。
プライマリ サーバーでの HA の登録時に仮想 IP アドレッシングを有効にできます。そのためには、この機能を使用する旨を指定し、プライマリ サーバーとセカンダリ サーバーで共有する仮想 IPv4(必要な場合は IPv6)アドレスを入力します(「プライマリ サーバーでの HA の登録方法」を参照)。
仮想 IP アドレッシングを有効化した後に仮想 IP アドレッシングを削除するには、HA を完全に削除する必要があります(「GUI での HA の削除」を参照)。
HA 環境で SSL 証明書を使用する方法
Prime Infrastructure サーバーとユーザー間の通信をセキュアなものにするために SSL 認証を使用することを決め、HA の実装も計画している場合、プライマリ HA サーバーとセカンダリ HA サーバー用に別々の証明書を生成する必要があります。
これらの証明書は、各サーバーの FQDN(完全修飾ドメイン名)を使用して生成する必要があります。つまり、プライマリ サーバーで使用する予定の証明書の生成にはプライマリ サーバーの FQDN を使用し、セカンダリ サーバーで使用する予定の証明書の生成にはセカンダリ サーバーの FQDN を使用する必要があります。
証明書を生成したら、各サーバーに署名付き証明書をインポートします。
仮想 IP アドレスを使用して SSL 証明書を生成しないでください。仮想 IP アドレス機能は、Prime Infrastructure とネットワーク デバイス間の通信を可能にするために使用します。
Cisco Prime Infrastructure の HTTPS アクセスを設定するには、「Prime Infrastructure への HTTPS アクセスをセットアップする」を参照してください。
Web ブラウザへのクライアント証明書のインポート
証明書認証が設定された Prime Infrastructure サーバーにアクセスするユーザーは、認証用にクライアント証明書をブラウザにインポートする必要があります。このプロセスは各種ブラウザで同様ですが、実際の詳細部分についてはブラウザによって異なります。以下の手順では、ユーザーが Prime Infrastructure 互換の Firefox を使用しているものとしています。
クライアント証明書をインポートするユーザーに関して、以下について確認する必要があります。
- クライアント マシンのローカル ストレージ リソースに証明書ファイルのコピーをダウンロード済みであること。
- 証明書ファイルが暗号化されている場合は、証明書ファイルの暗号化に使用されたパスワードを保有していること。
Procedure
|
Step 1 |
Firefox を起動し、次の URL をロケーション バーに入力します:about:preferences#advanced Firefox の [オプション(Options)] > [詳細設定(Advanced)] タブが表示されます。 |
|
Step 2 |
[証明書(Certificates)] > [証明書の表示(View Certificates)] > 自分の証明書の順に選択して [インポート...(Import...)] をクリックします。. |
|
Step 3 |
ダウンロードした証明書ファイルに移動してそれらを選択し、[OK] または [開く(Open)] をクリックします。 |
|
Step 4 |
証明書ファイルが暗号化されている場合、証明書ファイルの暗号化に使用されたパスワードの入力が求められます。該当するパスワードを入力し、[OK] をクリックします。 これで証明書がブラウザにインストールされました。 |
|
Step 5 |
Ctrl+Shift+Del を押して、ブラウザのキャッシュをクリアします。 |
|
Step 6 |
証明書認証を使用してブラウザで Prime Infrastructure サーバーにアクセスします。 要求されたサーバー認証に応答するための証明書の選択が求められます。適切な証明書を選択し、[OK] をクリックします。 |
ホット スタンバイ動作
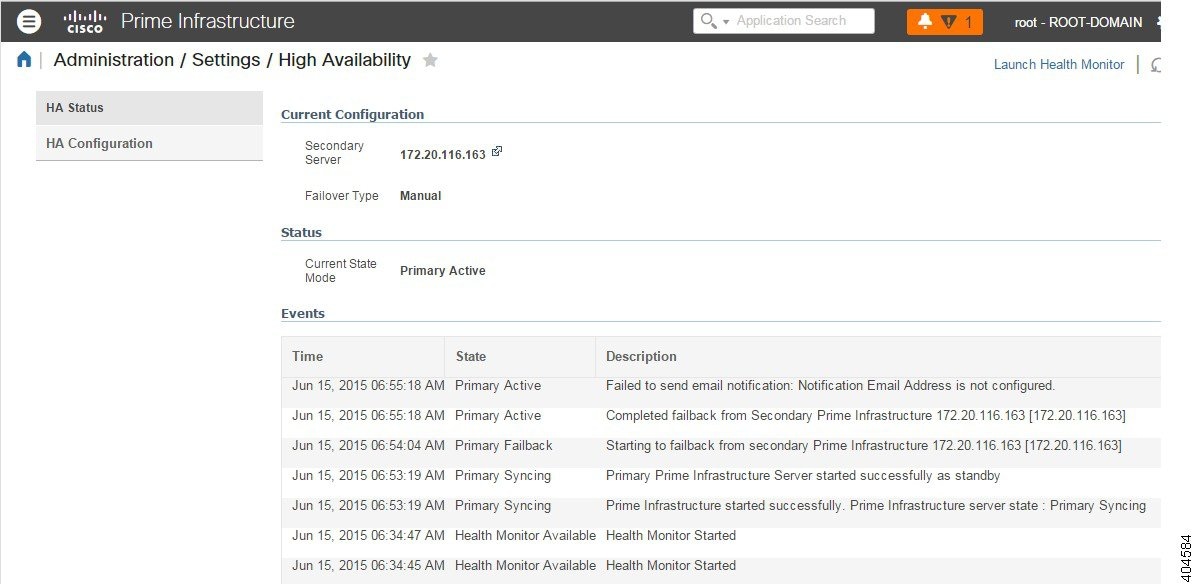
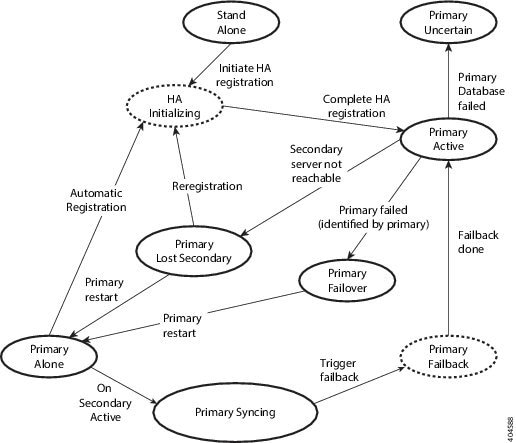
プライマリ サーバがアクティブ状態のとき、セカンダリ サーバは、プライマリ サーバと常時同期状態にあり、高速で切り替えができるように、すべての Prime Infrastructure プロセスを実行しています。プライマリ サーバに障害が発生すると、セカンダリ サーバがフェールオーバー後 2 ~ 3 分以内にアクティブなロールを素早く引き継ぎます。
プライマリ サーバでの問題が解消され、プライマリ サーバが実行状態に戻ると、プライマリ サーバがスタンバイ ロールになります。プライマリ サーバがスタンバイ ロールになると、ヘルス モニタの GUI には「Primary Syncing」状態が表示され、プライマリ サーバ上のデータベースおよびファイルとアクティブなセカンダリ サーバとの同期が開始されます。
プライマリ サーバが再度使用可能になり、フェールバックがトリガーされると、再度プライマリ サーバがアクティブ ロールを引き継ぎます。このようなプライマリ サーバーとセカンダリ サーバー間でのロールの切り替えは、2 ~ 3 分以内に実行されます。


 フィードバック
フィードバック