Geo-Redundancy
CPC can be deployed in a geographically redundant (GR) manner to maintain service availability during catastrophic failures, such as the loss of a data center. Two cnAAA clusters connect either locally or remotely. The system achieves redundancy by replicating subscriber and session data across sites.
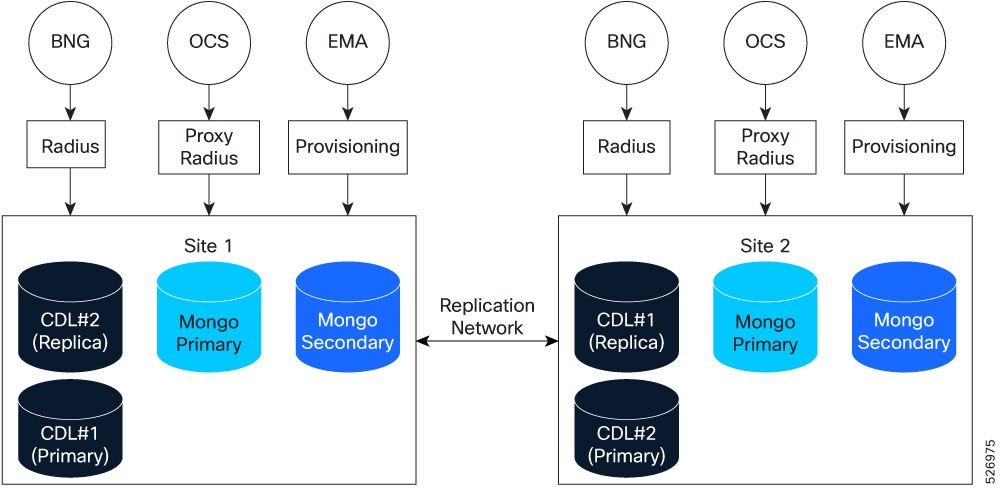
Subscriber traffic from the BNG and OCS flows into the RADIUS endpoints at Site 1 and Site 2. Provisioning data from the EMA also flows into these endpoints. This ensures that both sites are prepared to handle active sessions and maintain service continuity during a site-level failover.
Redundancy is achieved by:
-
Session replication: Each site operates its own CDL instance. Local session data is replicated to the remote site through the replication network.
-
Subscriber replication: For subscriber management, MongoDB is used, with data persisted to disk. A single replica set can be deployed. The primary and one secondary are hosted at the local site. Two additional secondary members are hosted at the remote site. Customers may deploy additional replica sets to meet scale requirements. Data is replicated between the local and remote sites via the replication network.
CDL session redundancy
Each site operates an individual CDL instance that stores local RADIUS sessions. This data replicates to the other site through the replication network. If a site fails, BNG traffic fails over to the remote site, which handles the traffic using replicated data.
MongoDB subscriber redundancy
MongoDB persists data to disk. A single replica set typically includes:
-
Local Site: Primary and one secondary member.
-
Remote Site: Two secondary members.
-
Replication: In the replication process, data is transmitted through the replication network. All write operations are sent to the primary member. Read operations take place on local secondary members to reduce overhead.

 Feedback
Feedback