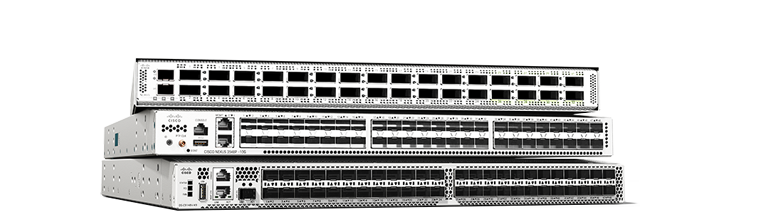
Ultra-reliable performance. Scalable infrastructure. Put a data center switching powerhouse at the heart of your network and be amazed at what's possible.
If spine and leaf or top of rack are your style, these fixed switches support ports from 1G to 400G to 800G. Enable AI-ready 800G infrastructure for data centers of any size.
Simplifies data center network management, boosts security with centralized app-centric approach with automation and policy-based control driving agile IT.
Book an expert consultation to start your AI-ready infrastructure journey
Receive expert guidance on modernizing your network and compute infrastructure with AI-ready infrastructure—combining technologies, products, and Cisco Validated Designs to support and scale AI workloads, all while advancing sustainability initiatives.