機能の概要と変更履歴
要約データ
|
該当製品または機能エリア |
SMF |
|
該当するプラットフォーム |
SMI |
|
機能のデフォルト設定 |
|
|
関連資料 |
該当なし |
更新履歴
|
改訂の詳細 |
リリース |
|---|---|
|
高可用性冗長性のサポートが強化され、マスター ノード間のアプリケーション VIP スイッチオーバー時のセッション損失を最小限に抑えました。 |
2023.04.0 |
|
次のサブ機能のサポートが追加されました。
|
2023.03.0 |
|
メンテナンス モードのサポートが追加されました。 |
2021.04.0 |
|
地理的冗長(GR)サポートが導入されました。 |
2021.02.0 |
|
最初の導入。 |
2020.02.0 より前 |


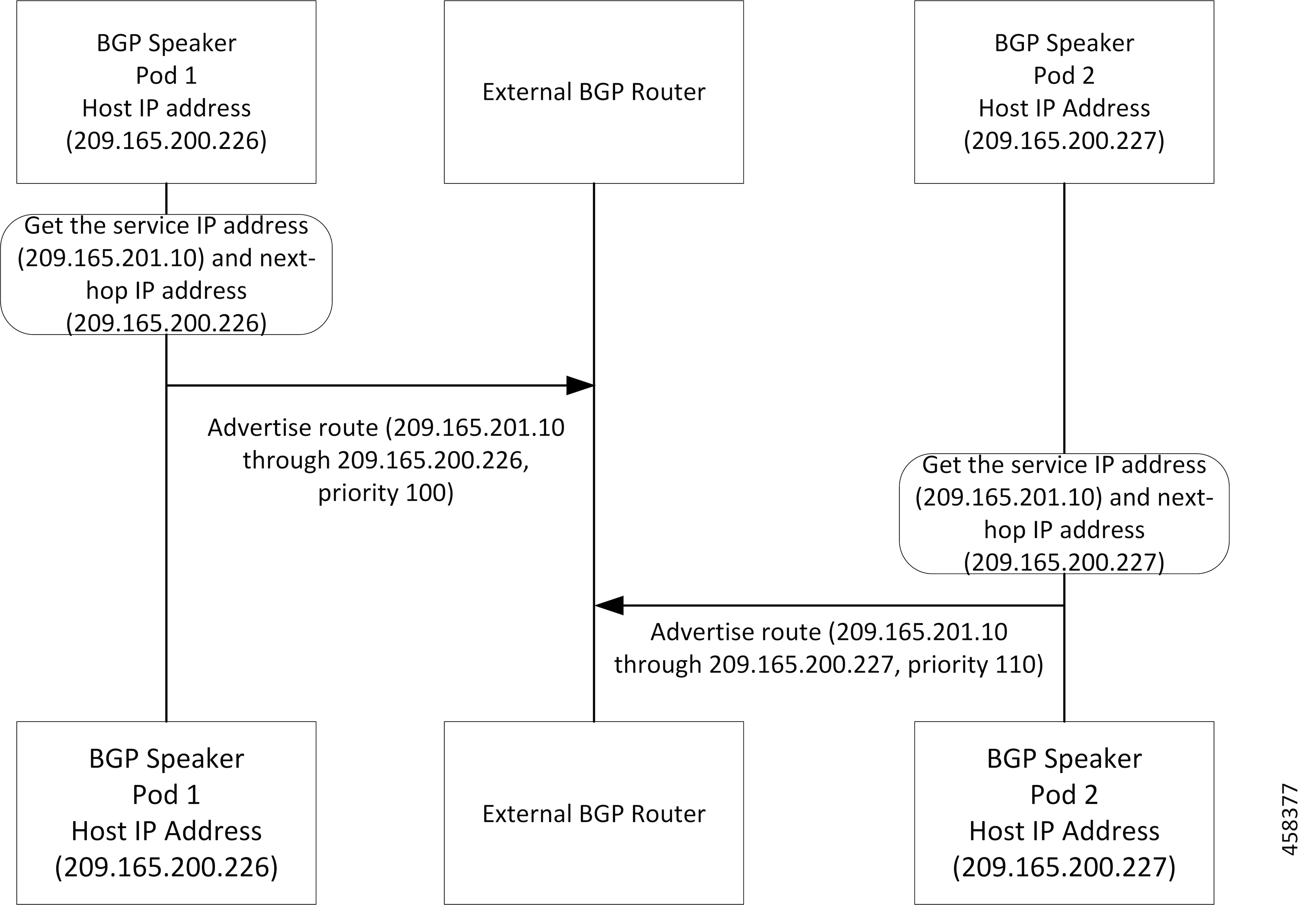
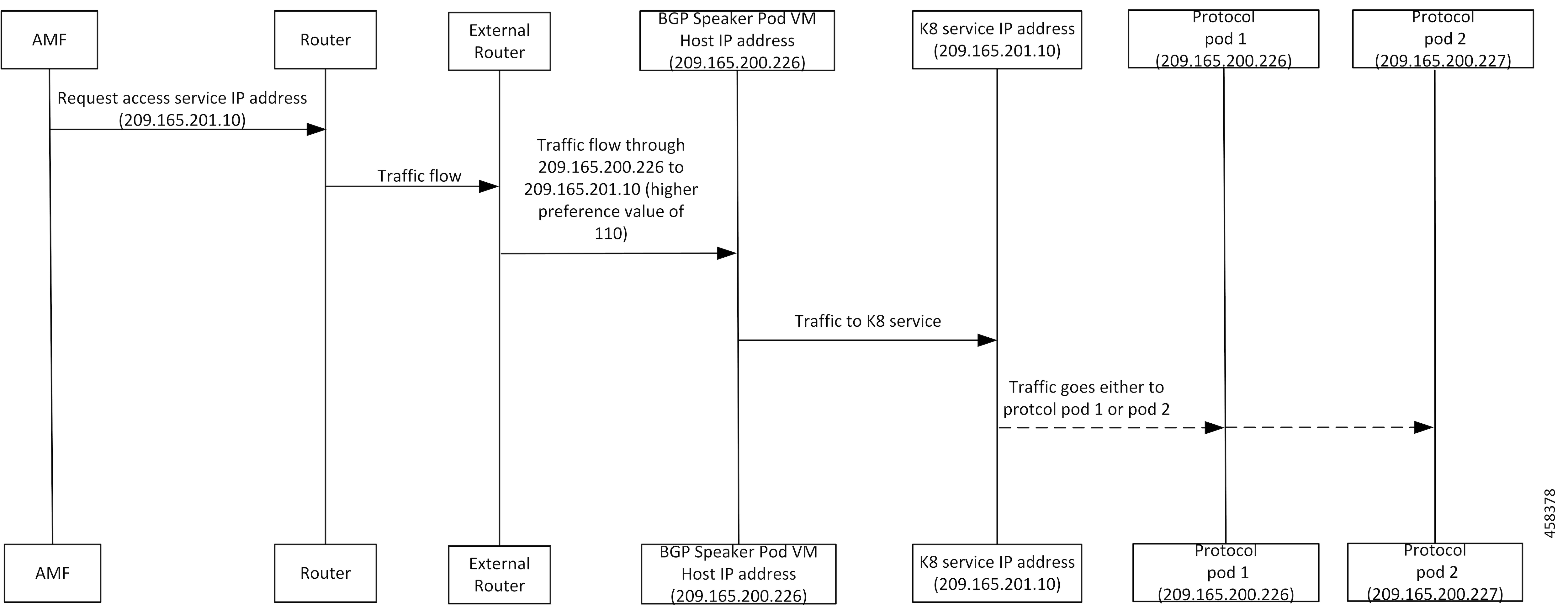
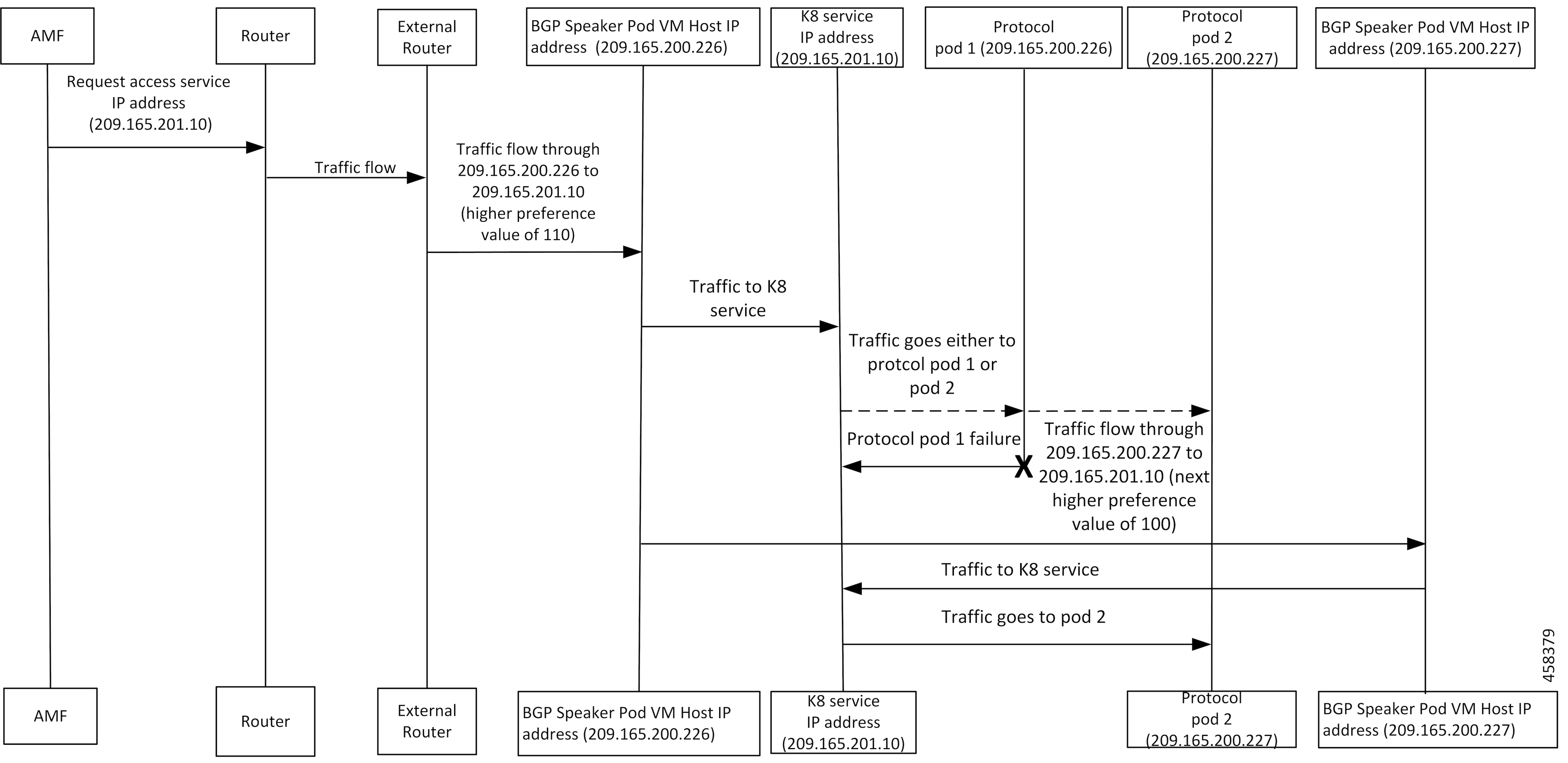
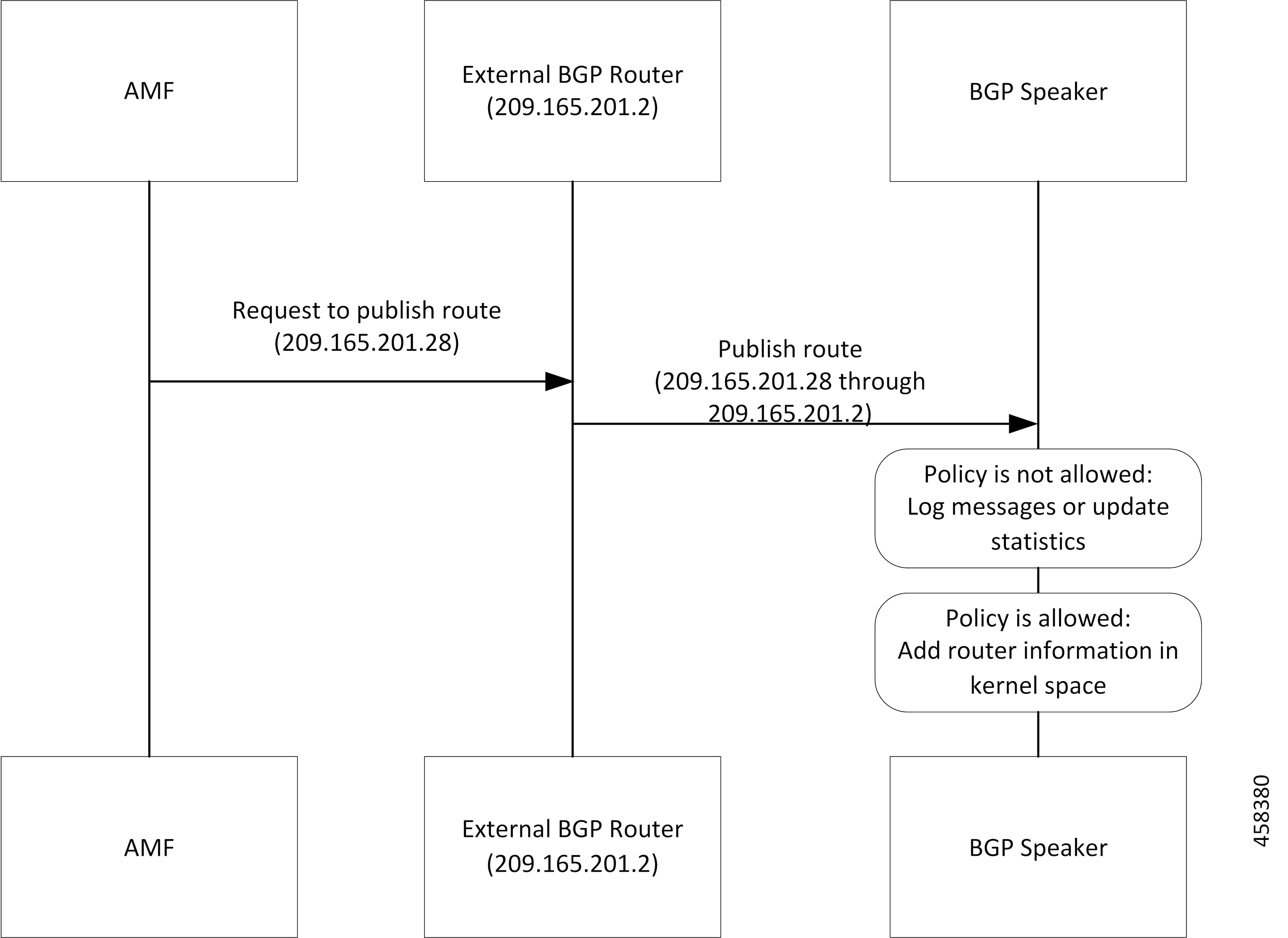



 フィードバック
フィードバック