機能の概要と変更履歴
要約データ
|
該当製品または機能エリア |
SMF |
|
該当するプラットフォーム |
SMI |
|
機能のデフォルト設定 |
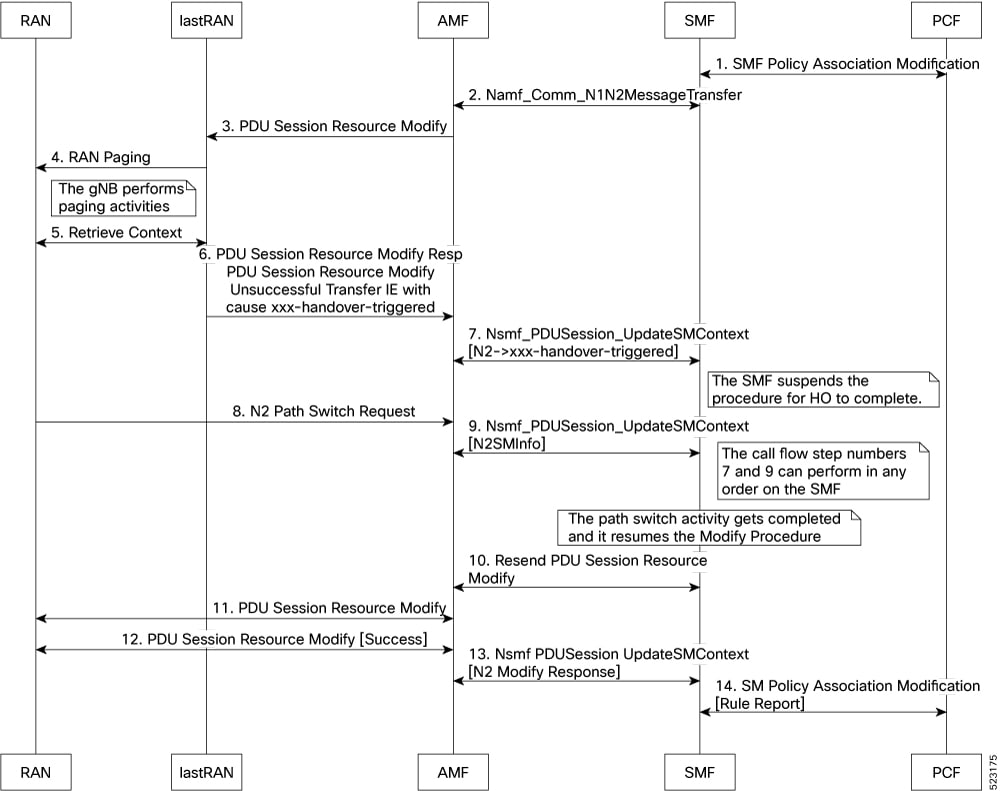
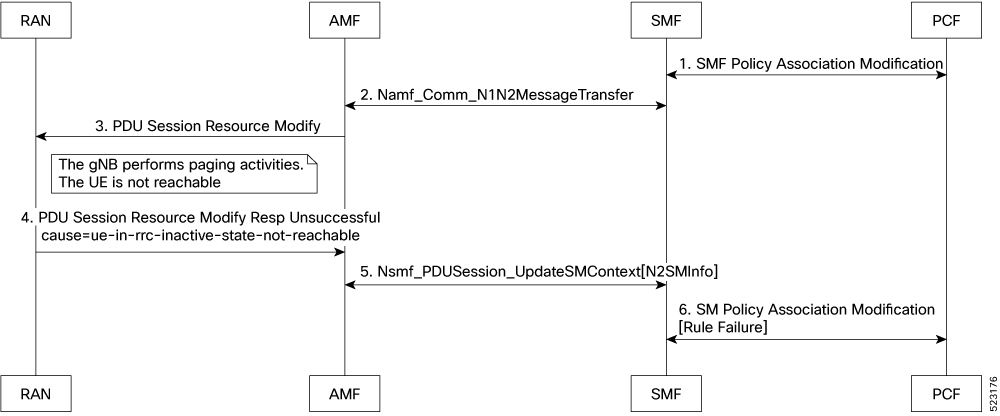
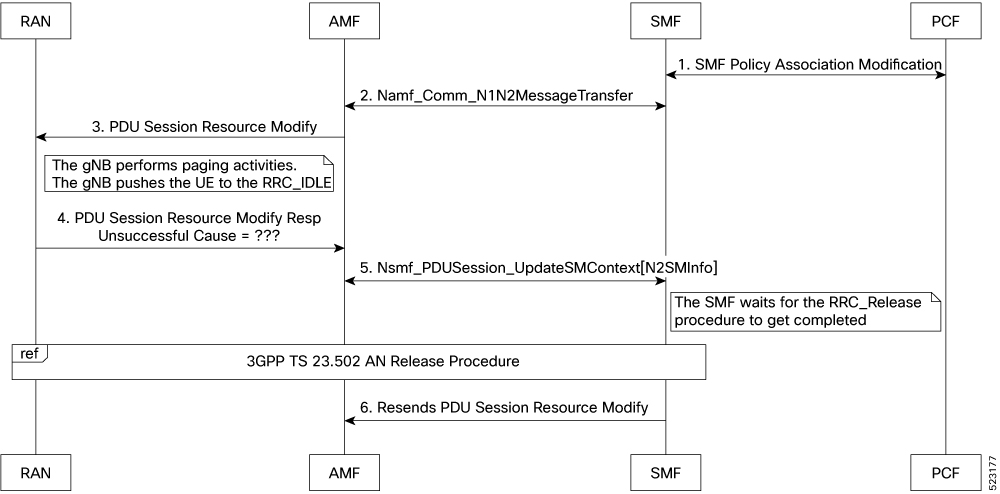
バッチ ID の割り当て、リリース、調整のサポート:無効:有効にするには構成が必要 キャッシュ ポッドの最適化 CDL フラッシュ間隔およびセッション有効期限のチューニング構成:有効:無効にするには構成が必要 Ops センターを使用したドメインベースのユーザー認可 エッジ エコーの実装:有効:常時オン GTPC エンドポイント ポッドのエンコーダとデコーダの最適化:無効:有効にするには構成が必要 ETCD ピア最適化のサポート:有効:常時オン ETCD トラフィックの最適化:有効:常時オン ローミングピアの最適化:無効:有効にするには構成が必要 DB データベース更新へのフラグの設定:有効:常時オン GTPC IPC クロスラックのサポート:無効:有効にするには構成が必要 RRC 非アクティブ原因コードに基づく PDU セッション変更の処理:無効:有効にするには構成が必要 サービス間ポッド通信:無効:有効にするには構成が必要 復元力の処理:無効:有効にするには構成が必要 |
|
関連資料 |
該当なし |
更新履歴
|
改訂の詳細 |
リリース |
|---|---|
|
次のサポートが追加されました:
|
2023.03.0 |
|
次のサポートが追加されました
|
2023.01.0 |
|
最初の導入。 次のサポートが追加されました。
|
2022.04.0 |

 フィードバック
フィードバック