- Monitor alerts using Cisco Prime Unified Operations Manager
- Monitor alerts using Unified RTMT
- List of alerts
- IM and Presence Service alerts
- CTIGWProviderDown
- CTIGWProviderFailedToOpen
- DbmonQueueWorkerExistWithError
- ESPSharedMemAllocFailed
- ESPSharedMemCreateFailed
- ESPSharedMemSetPermFailed
- ESPStopped
- ICSACertificateFingerPrintMisMatch
- ICSACertificateValidationFailure
- InterclusterSyncAgentAXLConnectionFailed
- InterclusterSyncAgentFailedToCleanUpPeer
- InterclusterSyncAgentFailedToSendCN
- InterclusterSyncAgentPeerDuplicate
- InterclusterSyncAgentPeerSyncFailed
- NotInCucmAppServerListError
- PEConfigNotificationFailure
- PEDatabaseError
- PEIDSQueryError
- PEIDSSubscribeError
- PEIDStoIMDBDatabaseSyncError
- PEOamInitialConfigFileError
- PEOamInvalidInitialConfigFile
- PEOamConfigFileError
- PEPeerNodeFailure
- PESipSgHostUnavailable
- PESipSocketBindFailure
- SRMFailed
- SRMFailover
- SyncAgentAXLConnectionFailed
- SyncAgentCucmDbmonConnectionFailed
- XCPConfigMgrConfigurationFailure
- XCPConfigMgrHostNameResolutionFailed
- XCPConfigMgrJabberRestartRequired
- XCPConfigMgrQueueAtCriticalLevel
- XCPConfigMgrR2RPasswordEncryptionFailed
- XcpSIPGWStackResourceError
- Cisco Prime Unified Operations Manager Alerts
- System Alerts
- CiscoDRFFailure
- CpuPegging
- CriticalServiceDown
- HardwareFailure
- LogPartitionHighWaterMarkExceeded
- LogPartitionLowWaterMarkExceeded
- LowActivePartitionAvailableDiskSpace
- LowAvailableVirtualMemory
- LowSwapPartitionAvailableDiskSpace
- ServerDown
- SystemVersionMismatched
- TotalProcessesAndThreadsExceededThreshold
- IM and Presence Service alerts
Alerts and alarms
- Monitor alerts using Cisco Prime Unified Operations Manager
- Monitor alerts using Unified RTMT
- List of alerts
Monitor alerts using Cisco Prime Unified Operations Manager
Cisco Prime Unified Operations Manager (Unified Operations Manager) 8.6 is capable of raising system alerts only for IM and Presence Service. Unified Operations Manager 8.7 and later include a custom syslog feature. This feature makes it possible to add syslog messages that are not in the Unified Operations Manager default list. These alerts will be raised based on their Cisco Unified Real-Time Monitoring Tool (Unified RTMT) default thresholds.
Complete the following procedure to monitor alerts using Unified Operations Manager.
| Step 1 | First on IM and Presence. |
| Step 2 | Then on Unified Operations Manager. |
Monitor alerts using Unified RTMT
You can monitor both system and IM and Presence-specific alerts for an IM and Presence server using Cisco Unified Real-Time Monitoring Tool.
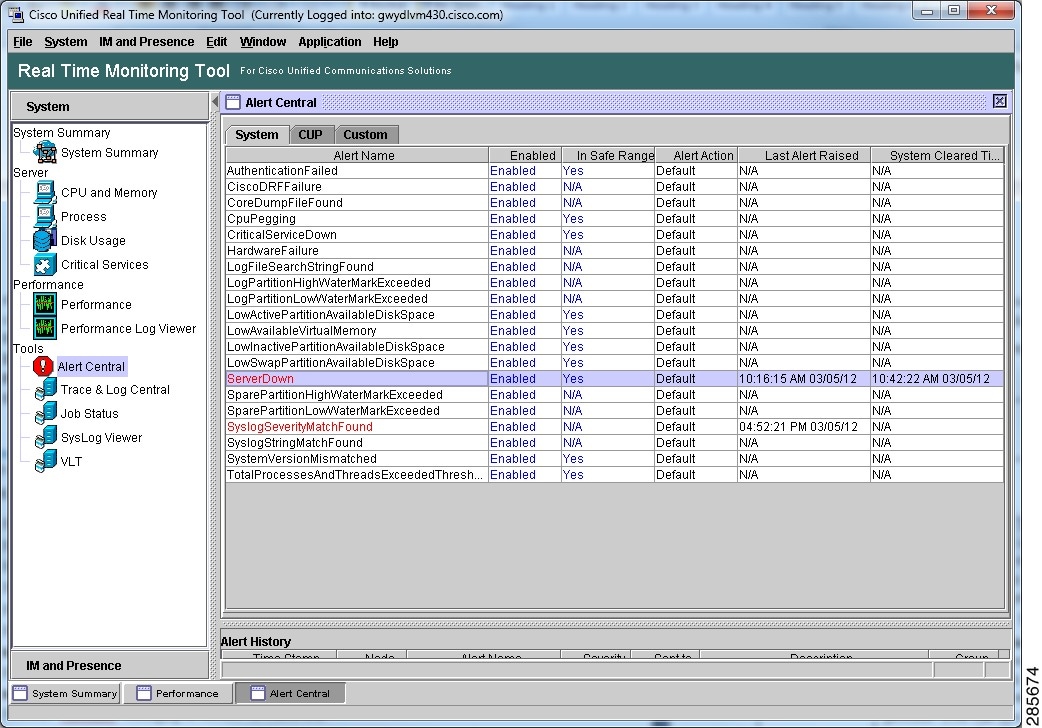
List of alerts
Alert messages are generated to notify administrators when a predefined condition is met, such as when an activated service goes from up to down. Cisco recommends that you monitor the following IM and Presence, Unified Operations Manager, and System alerts.
IM and Presence Service alerts
The following is a list of common IM and Presence Service alerts.
- CTIGWProviderDown
- CTIGWProviderFailedToOpen
- DbmonQueueWorkerExistWithError
- ESPSharedMemAllocFailed
- ESPSharedMemCreateFailed
- ESPSharedMemSetPermFailed
- ESPStopped
- ICSACertificateFingerPrintMisMatch
- ICSACertificateValidationFailure
- InterclusterSyncAgentAXLConnectionFailed
- InterclusterSyncAgentFailedToCleanUpPeer
- InterclusterSyncAgentFailedToSendCN
- InterclusterSyncAgentPeerDuplicate
- InterclusterSyncAgentPeerSyncFailed
- NotInCucmAppServerListError
- PEConfigNotificationFailure
- PEDatabaseError
- PEIDSQueryError
- PEIDSSubscribeError
- PEIDStoIMDBDatabaseSyncError
- PEOamInitialConfigFileError
- PEOamInvalidInitialConfigFile
- PEOamConfigFileError
- PEPeerNodeFailure
- PESipSgHostUnavailable
- PESipSocketBindFailure
- SRMFailed
- SRMFailover
- SyncAgentAXLConnectionFailed
- SyncAgentCucmDbmonConnectionFailed
- XCPConfigMgrConfigurationFailure
- XCPConfigMgrHostNameResolutionFailed
- XCPConfigMgrJabberRestartRequired
- XCPConfigMgrQueueAtCriticalLevel
- XCPConfigMgrR2RPasswordEncryptionFailed
- XcpSIPGWStackResourceError
CTIGWProviderDown
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the CTI provider is currently unavailable.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Check the connection to the configured Cisco Unified Communications Manager nodes and verify that the Cisco CTI Gateway application is enabled on the Administration GUI CTI Settings page.
CTIGWProviderFailedToOpen
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the CTI Provider failed to open due to a configuration error.
- Unified RTMT Default Threshold
- Not Applicable.
- Recommended Actions
- Verify the Cisco Unified Communications Manager addresses and application user credentials on the Administration GUI CTI Settings page.
DbmonQueueWorkerExistWithError
- Type
- IM and Presence Service
- Alert Description
-
This alert indicates that the Cisco Sync Agent service is no longer processing change notifications from the Cisco Unified Communications Manager cluster. This error can cause the data on the IM and Presence Service cluster to get out of sync with the data on the Cisco Unified Communications Manager cluster.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the Cisco Unified Communications Manager server is active. You might need to restart the Cisco Sync Agent service.
ESPSharedMemAllocFailed
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco SIP Proxy service failed to allocate shared memory segments while trying to initialize tables.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Use Unified RTMT to check system shared memory, check the Cisco SIP Proxy service trace log file for any detailed error messages and contact Cisco TAC for assistance.
ESPSharedMemCreateFailed
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco SIP Proxy service failed to create shared memory segments while trying to initialize tables.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Use Unified RTMT to check system shared memory, check the Cisco SIP Proxy service trace log file for any detailed error messages, and contact Cisco TAC for assistance.
ESPSharedMemSetPermFailed
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco SIP Proxy service failed to set permissions on shared memory segments while trying to initialize tables.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Use Unified RTMT to check system shared memory, check the Cisco SIP Proxy service trace log file for any detailed error messages, and contact Cisco TAC for assistance.
ESPStopped
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco SIP Proxy service child process has stopped.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- If the administrator has not manually stopped the Proxy service, this may indicate a problem. Use Unified RTMT to check for any related alarms and contact Cisco TAC for assistance.
ICSACertificateFingerPrintMisMatch
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Intercluster Sync Agent service detected a fingerprint mismatch on the certificate being processed.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Use the IM and Presence Service OS Administration GUI to compare the certificates that are loaded on this server with the certificates on the source server. You might need to delete the problem certificates and reload them.
ICSACertificateValidationFailure
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Intercluster Sync Agent service detected a validation error on the certificate being processed.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Use the IM and Presence Service OS Administration GUI to compare the certificates that are loaded on this server with the certificates on the source server. You might need to delete the problem certificates and reload them.
InterclusterSyncAgentAXLConnectionFailed
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Intercluster Sync Agent service failed authentication to the remote IM and Presence Service cluster and therefore is unable to connect.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the AXL credentials are correct and whether the Cisco AXL Web service is running on the remote IM and Presence Service cluster.
InterclusterSyncAgentFailedToCleanUpPeer
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Intercluster Sync Agent service failed to successfully clean up data after a peer was removed during a sync.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the Cisco DB service is still up and accepting connections. See Cisco Inter Cluster Sync Agent logs for the root cause and contact Cisco TAC for assistance.
InterclusterSyncAgentFailedToSendCN
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Intercluster Sync Agent service failed to send change notifications to the remote IM and Presence Service cluster.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the AXL credentials are correct and whether the Cisco AXL Web service is running on the remote IM and Presence Service cluster.
InterclusterSyncAgentPeerDuplicate
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Intercluster Sync Agent service failed to sync user location data from a remote peer. The remote peer is from an IM and Presence Service cluster which already has a peer in the local cluster.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the hostname of the remote peer is not a secondary node from the identified existing peer. If the new peer is a secondary node, then remove this peer from the IM and Presence Service Administration GUI Inter-cluster details page. You can also run the System Troubleshooter for more details.
InterclusterSyncAgentPeerSyncFailed
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Intercluster Sync Agent service failed to sync user location data from the remote IM and Presence Service cluster.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the remote IM and Presence Service peer is not also configured as a node in the local cluster, and on the Administration GUI run the System Troubleshooter for more information about this issue.
NotInCucmAppServerListError
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Sync Agent failed to start because the IM and Presence Service Server node is not in the application server list on the Cisco Unified Communications Manager publisher.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Add IM and Presence Service Server node to the application server list on the Cisco Unified Communications Manager server and start the Cisco Sync Agent service.
PEConfigNotificationFailure
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Presence Engine service cannot bind to the socket that is used for communication with the IM and Presence Service OAM Agent service through XML-RPC.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the IM and Presence Service OAM Agent service listen interface is configured correctly on the IM and Presence Service Administration GUI Application Listener page. Verify that no other process is listening on the same port using netstat.
PEDatabaseError
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Presence Engine service encountered an error while retrieving information from the database. This may indicate a problem with the Cisco DB service.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the Cisco DB service is running. Use Unified RTMT to check the Cisco Presence Engine service logs for errors. Consult Cisco TAC for guidance.
PEIDSQueryError
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Presence Engine service has detected an error while querying the IM and Presence Service database.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Restart the Cisco Presence Engine service when convenient. See the associated error message and log files and consult Cisco TAC if the problem persists.
PEIDSSubscribeError
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Presence Engine service was unable to subscribe for IM and Presence Service database change notifications.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Restart the Cisco Presence Engine service when convenient. See the associated error message and log files and consult Cisco TAC if the problem persists.
PEIDStoIMDBDatabaseSyncError
- Type
- IM and Presence Service
- Alert Description
-
This alert indicates that synchronization between the IM and Presence database and the Cisco Presence Engine and a database service has failed (Cisco Login Datastore, Cisco Route Datastore, Cisco Presence Datastore, and Cisco SIP Registration Datastore).
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
-
Restart the Cisco Presence Engine service when convenient. See associated error message and log files and consult Cisco TAC if the problem persists.
PEOamInitialConfigFileError
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Presence Engine service configuration file is missing or malformed.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the IM and Presence Service OAM Agent service is running through the Serviceability GUI.
PEOamInvalidInitialConfigFile
PEOamConfigFileError
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Presence Engine service configuration file is missing or malformed.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the IM and Presence Service OAM Agent service is running through the Serviceability GUI.
PEPeerNodeFailure
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that Cisco Presence Engine service on the peer node of a subcluster has failed.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Use Cisco Unified Serviceability to verify that the Cisco Presence Engine service is running. Consult Cisco TAC for further assistance
PESipSgHostUnavailable
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Presence Engine service could not contact the indicated outbound proxy server group.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the outbound proxy is configured correctly and listening on the configured ports.
PESipSocketBindFailure
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Presence Engine service was unable to connect to the indicated configured interface. No SIP traffic can be processed on this interface.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the Cisco Presence Engine service listen interface is configured correctly on the IM and Presence Service Administration GUI Application Listener page. Verify that no other process is listening on the same port using netstat.
SRMFailed
SRMFailover
SyncAgentAXLConnectionFailed
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco Sync Agent service failed authentication to the remote Cisco Unified Communications Manager publisher and therefore is unable to connect.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the AXL credentials are correct and whether the Cisco AXL Web service is running on the remote Cisco Unified Communications Manager publisher.
SyncAgentCucmDbmonConnectionFailed
- Type
- IM and Presence Service
- Alert Description
-
This alert indicates that the Cisco Sync Agent service lost the connection to the Cisco Database Layer Monitor service. This error can cause the data on the IM and Presence Service cluster to get out of sync with the data on the Cisco Unified Communications Manager cluster.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify that the Cisco Unified Communications Manager server is active and that the Cisco Unified Communications Manager publisher has opened port 8001.
XCPConfigMgrConfigurationFailure
- Type
- IM and Presence Service
- Alert Description
-
This alert indicates that the Cisco XCP Config Manager failed to successfully update XCP configuration.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
-
See the Cisco XCP Config Manager logs for the root cause. Contact Cisco TAC for assistance.
XCPConfigMgrHostNameResolutionFailed
- Type
- IM and Presence Service
- Alert Description
- This alert indicates that the Cisco XCP Config Manager could not resolve a DNS name to allow Cisco XCP Routers to connect to that node.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify DNS resolvability of all hostnames and FQDNs in both local and remote clusters. Restart the Cisco XCP Config Manager and then restart the Cisco XCP Router after DNS is resolvable.
XCPConfigMgrJabberRestartRequired
- Type
- IM and Presence Service
- Alert Description
-
This alert indicates that the Cisco XCP Config Manager has regenerated XCP XML files after system halt due to buffer size. The Cisco XCP Router must now be restarted to apply changes.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
-
When it is convenient to do so, restart the Cisco XCP Router.
XCPConfigMgrQueueAtCriticalLevel
- Type
- IM and Presence Service
- Alert Description
-
This alert indicates that the Cisco XCP Config Manager buffer has reached critical levels. The system will halt until configuration stabilizes, and then it will regenerate all files. The Cisco XCP Router will need to be restarted to apply these changes.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
-
Restart the Cisco XCP Router after the alarm is sent that indicates that configuration has been regenerated successfully.
XCPConfigMgrR2RPasswordEncryptionFailed
- Type
- IM and Presence Service
- Alert Description
-
This alert indicates that the Cisco XCP Config Manager was unable to encrypt the password that is associated with an Inter-cluster Router-to-Router configuration.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
-
When it is convenient to do so, restart the Cisco XCP Config Manager and then restart the Cisco XCP Router.
XcpSIPGWStackResourceError
- Type
- IM and Presence Service
- Alert Description
-
This alert indicates that the maximum supported concurrent SIP Federation subscriptions or SIP Federation IM sessions has been reached, and the Cisco XCP SIP Federation Connection Manager does not have the resources that are required to handle any addition subscriptions or IM sessions.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
-
Increase the Pre-allocated SIP stack memory Service Parameter for the Cisco XCP SIP Federation Connection Manager. Note: If you are changing this setting, make sure that you have the memory available. If you do not have enough memory, you may have reached the limit of your hardware capability.
Cisco Prime Unified Operations Manager Alerts
The following is a list of common Unified Operations Manager alerts.
 Note |
Unified Operations Manager maintains its own set of alerts that are related to IM and Presence Service. Some of these mirror existing native alerts. For example, the native alert LowAvailableVirtualMemory and the Unified Operations Manager alert InsufficientFreeVirtualMemory both alert on the same item and are based on the same data, yet the default threshold is different on Unified Operations Manager (< 15%) and Unified RTMT (< 25%). |
- DevicePartiallyMonitored
- HighUtilization
- HTTPInaccessible
- InsufficientFreeVirtualMemory
- ServerUnreachable
- Unresponsive
DevicePartiallyMonitored
- Type
- Unified Operations Manager
- Alert Description
- This alert is generated based on polling Unified RTMT precanned counters and is raised when Unified Operations Manager is not able to collect Unified RTMT data for Unified RTMT polling supported devices. Unified RTMT data collection can fail if there are HTTP communication failures or network issues or if the Unified RTMT application on the device has issues and is unable to provide the data to Unified Operations Manager.
- Default Threshold
- Not Applicable
- Recommended Actions
HighUtilization
- Type
- Unified Operations Manager
- Alert Description
- Current utilization exceeds the utilization threshold that is configured for this processor.
- Default Threshold
- > 90%
- Recommended Actions
- Identify the processes that are using excessive CPU space. You may want to take action, which may include restarting the identified process or processes.
HTTPInaccessible
- Type
- Unified Operations Manager
- Alert Description
- HTTP service cannot be used to communicate to all servers in the cluster. This might be due to one or both of the following:
- Default Threshold
- Not Applicable
- Recommended Actions
- Verify that all servers are accessible through Web Service with the credentials that are provided in Unified Operations Manager. Provide the correct username and password if the credentials are wrong. You might need to restart the web server if Web Service is down.
InsufficientFreeVirtualMemory
- Type
- Unified Operations Manager
- Alert Description
- System is running out of virtual memory resources. This may degrade the performance of the device.
- Default Threshold
- < 15%
- Recommended Actions
- Verify insufficient memory using the CPU and Memory tool in Unified RTMT. This alert may be due to a memory leak. It is important to identify which process is using excessive memory. This can be done using the Process tool. After the process is identified, if you suspect a memory leak (for example, if the memory usage for a process increases continually, or a process is using more memory than it should), you may want to restart that process.
ServerUnreachable
- Type
- Unified Operations Manager
- Alert Description
- Host is not reachable through Unified RTMT polling. This alert is generated based on polling Unified RTMT precanned counters.
- Default Threshold
- Not Applicable
- Recommended Actions
- Investigate whether the indicated host is running and whether a network problem exists.
Unresponsive
- Type
- Unified Operations Manager
- Alert Description
-
Device does not respond to ICMP or SNMP requests. Probable causes are:
- On a system: ICMP ping requests and SNMP queries to the device timeout receive no response.
- On an SNMP Agent: Device ICMP ping requests are successful, but SNMP requests time out with no response.
A system might also be reported as unresponsive if the only link (for example, an interface) to the system goes down. Unified Operations Manager performs root cause analysis for any unresponsive events.
If Unified Operations Manager receives a device unresponsive event, it will clear any interface unresponsive events from that device until the device is recognized as responsive.
- Default Threshold
- Not Applicable
- Recommended Actions
- Check whether the device is reachable from Unified Operations Manager.
System Alerts
The following is a list of common System alerts.
- CiscoDRFFailure
- CpuPegging
- CriticalServiceDown
- HardwareFailure
- LogPartitionHighWaterMarkExceeded
- LogPartitionLowWaterMarkExceeded
- LowActivePartitionAvailableDiskSpace
- LowAvailableVirtualMemory
- LowSwapPartitionAvailableDiskSpace
- ServerDown
- SystemVersionMismatched
- TotalProcessesAndThreadsExceededThreshold
CiscoDRFFailure
- Type
- System
- Alert Description
- This alert indicates that the Disaster Recovery Failure (DRF) backup or restore process encountered errors. The alert is generated by monitoring the syslog messages that are received from the IM and Presence Service Server.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Verify whether /common/drf has the required permission and enough space for the DRF user. Check the application logs for further details. Consult Cisco TAC for assistance.
CpuPegging
- Type
- System
- Alert Description
- This alert occurs when the percentage of CPU load on a presence server is over the configured percentage for the configured period of time. This alert is generated based on polling Unified RTMT performance counters. To view the threshold, right-click the alert and select Set Alert/Properties.
- Unified RTMT Default Threshold
- 99%
- Recommended Actions
-
The most common reason for this alert is that one or more processes are using excessive CPU space. The alert has information about which process is using the most CPU. After the process is identified, you may want to take action, which could include restarting the process. You can also verify the current CPU usage of the problem process using the Process tool.
It is helpful to check the trace setting for that process. Using the detailed/debug trace level is known to take up excessive CPU space. If so, you may want to take more drastic measures, such as stopping nonessential services or scheduling a restart of IM and Presence Server during off hours.
CriticalServiceDown
- Type
- System
- Alert Description
-
This alert is generated when one of the critical services (any of the services in the Critical Services tool in Unified RTMT) is not running. The problem could be due to someone manually stopping the service. If you intend to stop the service for a long period of time, you should deactivate it on the Serviceability GUI: .
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
-
Identify which services are not running. You can start the service manually from the Serviceability GUI: .
Also, check to see whether there are any core files. Download the core files, if any, as well as service trace files.
HardwareFailure
- Type
- System
- Alert Description
- This alert indicates that a hardware failure has occurred in a presence server. This event is generated by monitoring the syslog messages received from the IM and Presence server.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Check the Unified RTMT Syslog Viewer tool for further details.
LogPartitionHighWaterMarkExceeded
- Type
- System
- Alert Description
- This alert indicates that the percentage of used disk space in the log partition has exceeded the configured high water mark. This alert is generated based on polling Unified RTMT performance counters. To view the threshold, right-click the alert and select Set Alert/Properties.
- Unified RTMT Default Threshold
- > 95%
- Recommended Actions
-
Log partition usage can be monitored from the Unified RTMT Disk Usage page. It appears as Common Partition. Check trace settings and also check for core dump files. Note that core dump files are fairly large. Typically, a core dump file is 200 to 300 MB in size, but it can also be 1 GB or 2 GB.
Note that after the log partition disk usage goes above the high water mark threshold, Cisco Log Partition Monitoring Tool (LPM) starts deleting files to put log partition disk usage under the low water mark threshold. Because LPM may delete the trace/log/core dump files you want to keep, it is very important to act when you receive a LogPartitionLowWaterMarkExceeded alert. You can use Trace and Log Central (TLC) In Unified RTMT to download files and delete them from the server.
LogPartitionLowWaterMarkExceeded
- Type
- System
- Alert Description
- This alert indicates that the percentage of used disk space in the log partition has exceeded the configured low water mark. This alert is generated based on polling Unified RTMT performance counters. To view the threshold, right-click the alert and select Set Alert/Properties.
- Unified RTMT Default Threshold
- > 90%
- Recommended Actions
- See LogPartitionHighWaterMarkExceeded.
LowActivePartitionAvailableDiskSpace
- Type
- System
- Alert Description
- This alert indicates that the percentage of available disk space in the active partition is lower than the configured value. This alert is generated based on polling Unified RTMT performance counters. To view the threshold, right-click the alert and select Set Alert/Properties.
- Unified RTMT Default Threshold
- < 4%
- Recommended Actions
-
Some of the symptoms of low active disk space are:
- Administration GUI does not operate correctly.
- Cisco Unified Communications Manager Bulk Administration Tool (BAT) does not operate correctly.
- Unified RTMT does not operate correctly.
Because there are no user-manageable files in Active Partition, check the alert threshold. If the alert threshold is at the Cisco default, contact Cisco TAC for guidance.
LowAvailableVirtualMemory
- Type
- System
- Alert Description
- This alert occurs when the percentage of available virtual memory is lower than the configured value. This alert indicates that the available virtual memory is running low. This alert is generated based on polling Unified RTMT performance counters. To view the threshold, right-click the alert and select Set Alert/Properties. A LowAvailableVirtualMemory alert generally means that the server has allocated all of its physical memory and has begun using its Swap Space on disk more intensively. This will lead to higher CPU usage and longer I/O wait times.
- Unified RTMT Default Threshold
- < 25%
- Recommended Actions
- Verify insufficient memory using the CPU and Memory tool in Unified RTMT. This alert may be due to a memory leak. It is important to identify which process is using excessive memory. This can be done using the Process tool. After the process is identified, if you suspect a memory leak (for example, if the memory usage for a process increases continually, or a process is using more memory than it should), you may want to restart that process.
LowSwapPartitionAvailableDiskSpace
- Type
- System
- Alert Description
- This alert occurs when the percentage of available disk space of the swap partition is lower than the configured value. This alert indicates that available swap partition is running low. Note that the swap partition is part of virtual memory. Therefore, low available swap partition disk space also means low virtual memory. This alert is generated based on polling Unified RTMT performance counters. To view the threshold, right-click the alert and select Set Alert/Properties.
- Unified RTMT Default Threshold
- < 10%
- Recommended Actions
- When you receive this alert, you should find out how much swap space and virtual memory are still available. You should also find out find out which process is using the most memory. This alert may be due to a memory leak. After you determine that there is a memory leak and virtual memory is running low, you may want to restart the service after saving the necessary troubleshooting information. Consult Cisco TAC for further information.
ServerDown
- Type
- System
- Alert Description
- This alert indicates that the host is not reachable through Unified RTMT polling. This alert is generated based on polling Unified RTMT performance counters.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Investigate whether the indicated host is running and whether a network problem exists.
SystemVersionMismatched
- Type
- System
- Alert Description
-
This alert occurs when there is a mismatch in the system version among all servers in the cluster. This alert is generated by monitoring the syslog messages that are received from the IM and Presence server.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Make sure that all servers in the cluster are running the same system version.
TotalProcessesAndThreadsExceededThreshold
- Type
- System
- Alert Description
- This alert indicates that the current total number of processes or threads has exceeded the maximum number of tasks. This situation could indicate that some processes or threads are not being shut down correctly. System access must stop thread counter update to avoid CPU pegging, and only provide process counter information for up to the maximum number of processes. This alert is generated by monitoring the syslog messages that are received from the IM and Presence Server.
- Unified RTMT Default Threshold
- Not Applicable
- Recommended Actions
- Check the alert detail for the process that has the highest number of threads and the process that has the most instances. If the process has an unusual number of threads or process instances, save the trace for the service and perhaps restart the service. Make sure to download trace files that are associated with the service. Note that the Cisco SIP Proxy process sipd and the Database process cmoninit can each have over 20 instances. This is expected behavior.
 Feedback
Feedback