Service-Centric Approach to AIOps White Paper
Available Languages
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Operations teams are undergoing a paradigm shift and embracing artificial intelligence, machine learning, and advanced analytics technologies to boost operations efficiency with proactive, personal, and dynamic insight. Gartner has coined the term AIOps (artificial intelligence for IT operations) to capture the spirit of these changes.
Current methodologies, techniques, and best practices are shackled by traditional siloed Operations Support System (OSS) stacks, rigid rule-based systems, and monolithic architectures. AIOps helps to quickly extract actionable insights from the operational data to help automate tasks and processes that have traditionally required human intervention.
According to Gartner, AIOps is going to drive a major change in operations over the next few years. Both Communications Service Providers (CSPs) and enterprises will substantially benefit from this shift as they undergo digital transformation. The change is manifesting as adoption and integration of different digital technologies to fundamentally change the way services are delivered to end customers. However, it is also posing new challenges for operations teams in terms of scale (Figure 1) and pace of change.
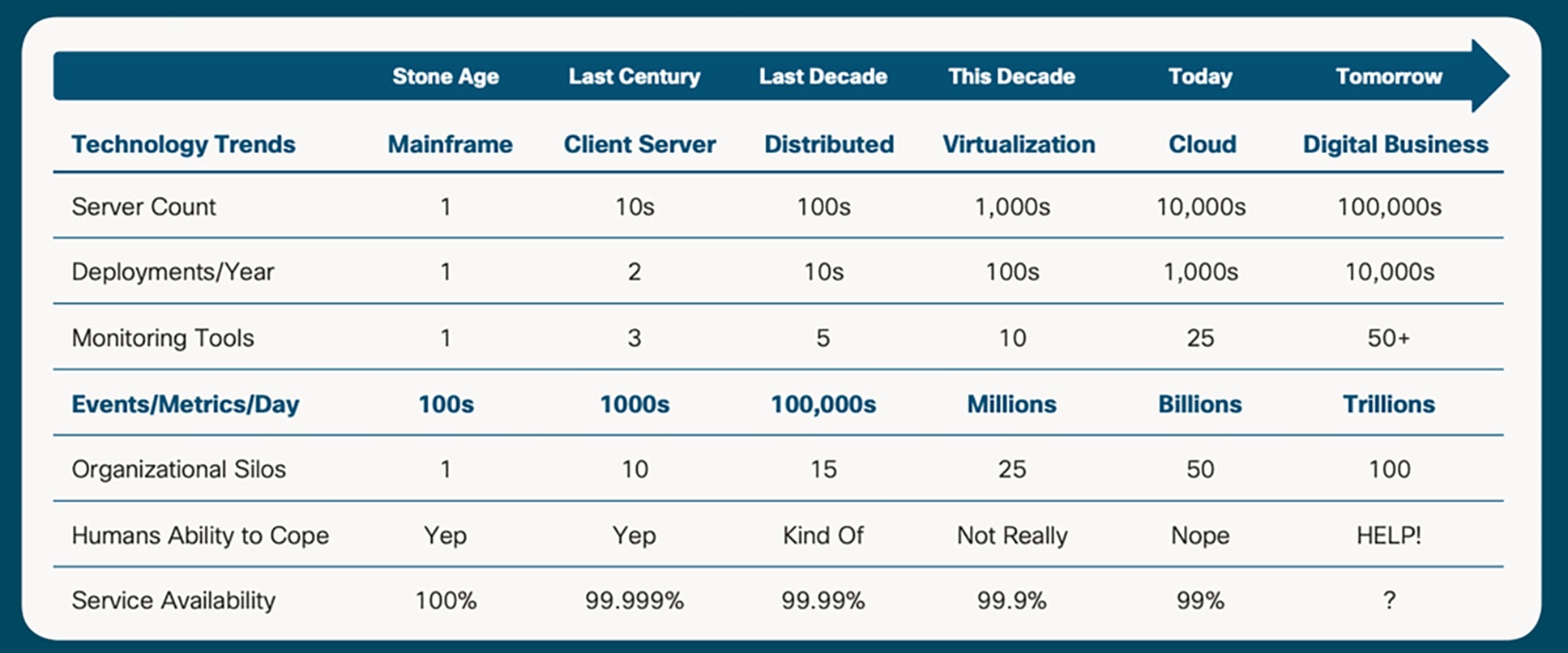
Digital transformation poses a scalability challenge
Digital transformation encompasses trends that stakeholders need to understand in order to effectively embrace digitization as part of service delivery.
Increasing infrastructure complexity and scale
Digitization demands that service delivery infrastructure be scalable and extensible to support growing numbers of applications, services, and subscribers. Such infrastructure would leverage multiple technology layers such as IP, Multiprotocol Label Switching (MPLS), and optical, and would connect multiple domains such as RF, backhaul, access, and core. In addition, a proliferation of diverse use cases is demanding different architectural requirements. For example, Internet of Things (IoT), autonomous vehicles, and edge analytics demand a combination of cloud and edge computing.
Managing such mass-scale infrastructure can be complex. From an operational perspective, the systems need to effectively deal with technology layers, domains, a large number and variety of devices, data volumes, and disparate data formats while delivering a simplified experience to improve operational efficiency. Virtualization adds complexity by decoupling the software from the underlying hardware and dynamic workload-based scaling. Microservices add additional complexity by decomposing applications into discrete services.
Dynamic infrastructure and software-defined networking
According to the Open Networking Foundation (ONF), Software-Defined Networking (SDN) is a new approach to networking in which network control is decoupled from the data forwarding function and is directly programmable. The net result is an extremely dynamic, manageable, cost-effective, and adaptable architecture that gives administrators unprecedented programmability, automation, and control. Implementing SDN as an open standard enables rapid service development and deployment, reduced operational costs, and flexibility for network administrators to integrate best- in-class technology.
The rise of data- and context-driven decision making
Traditional management systems can easily be overloaded with operational data, impeding operator productivity. What is required are dynamic insights, such as detection of anomalous behaviors or identification of causal patterns. Further, such insights need to be translated to precise actions that can be automated within a relevant context to improve service quality and ultimately the end-user experience.
AIOps as a critical business enabler
Customer experience and delivery of committed service levels is paramount. As part of digitization, services are increasingly offered as Software as a Service (SaaS) or Platform as a Service (PaaS) and are associated with stringent Service-Level Agreements (SLAs) around service availability. Service disruption or degradation can have a significant impact in terms of revenue or customer churn. The success of operations will be measured not just in terms of its effectiveness in managing the complex infrastructure, but, more importantly, in how quickly and proactively it can respond to service issues.
Such transitions pose significant challenges for the current BSS/OSS system. In the next section, we will discuss what is needed to effectively embrace the digital transformation.
The Cisco and Vitria SolutionsPlus Advantage
As the operational focus expands beyond infrastructure to services spanning multilayer, multivendor, and multidomain environments, the benefits of tying service context to statistical results to improve AIOps accuracy become more evident, as highlighted in this white paper. In this context, Vitria VIA AIOps for Cisco® Network Automation offers comprehensive capabilities to address such operational challenges and delivers substantial improvement in operational efficiency. As an approved Cisco DevNet SolutionsPlus offer, service providers worldwide are able to approach Cisco and approved Cisco partners to purchase Vitria VIA AIOps as a validated solution and addition to Cisco Crosswork™. It can be deployed in conjunction with Cisco Network Services Orchestrator (NSO), which helps to enrich AIOps by implementing a service-centric approach to AIOps.
Embracing digital transformation
To realize the full potential of the digital transformation, a fundamental shift in operational best practices and adoption of AIOps principles is required. Realistically, the change can be implemented in phases, driven by specific business outcomes and use cases.
Today, restrained by the current toolset, IT and telco operations are still reactive, relying on rules-based anomaly detection and manual remediation procedures. The goal is to adopt AIOps to help transition from a reactive approach to a proactive and predictive one, and to use analytics for anomaly detection and automation of closed-loop operational workflows. A service-centric approach to AIOps advocates the principles in the table below to boost operational efficiency.
Table 1. AIOps principles Principle
| Principle |
Description |
| Service awareness |
Service delivery is a central theme across digital transformation trends. Enrichment of operational data with service attributes such as service name, identifier, and topology helps to provide necessary context for AIOps to improve accuracy in data processing and consequently service support quality. |
| Unified cross-domain visibility |
Today’s siloed operational model is a big impediment to operational efficiency. End-to-end cross-domain awareness is essential to track service health, contextually monitor the performance of underlying infrastructure components, and characterize traffic flows and the interplay among different technologies. |
| Scalable data processing and effective use of machine learning techniques |
From an operational perspective, the systems need to effectively deal with technology layers, domains, and a large number and variety of physical and virtual devices, monitoring data volumes and disparate data formats. Data analysis is becoming too complex and resource intensive to be efficiently addressed by human resources. AIOps transformative algorithmic approaches are needed to effectively handle massive data volume and extract dynamic insights to help improve operational efficiency. |
| Knowledge sharing and collaboration |
Digitization simplifies knowledge capture and sharing and facilitates cross- silo operational workflows. Collaboration results in significant productivity gains and reduction of operational metrics such as Mean Time To Know (MTTK) and Mean Time To Restore (MTTR). |
| Automation focus |
Dynamic insights help to drive automation and implement large-scale change with closed-loop control This minimizes error-prone manual methods or procedures and substantially improves operational efficiency. |
The power of a service-centric approach to AIOps
Dynamic and programmable infrastructure can generate a lot of operational data. This data can be related to infrastructure health, application performance, activity logs, event notifications, traffic flows, social media interaction, IT Service Management (ITSM) system integration, and more. The data volumes and variety are increasing daily, and it is impossible for humans to process the data and deliver the stringent SLAs. Applying AIOps helps to address the challenge. The software algorithms reduce large volumes of data into actionable bits of information and assist in the learning and codification of the knowledge. Termed “proactive insight” by Gartner, it speeds up the analysis and operational decisions. For example, it would take numerous hours for a human to manually analyze and correlate every event in your production environment; however, the algorithms can accomplish the task in a matter of seconds (Figure 2). Combining machine learning with human skills and knowledge offers an optimal approach to delivering the target SLA and boost operational efficiency in a large-scale and growing IT or telco environment.
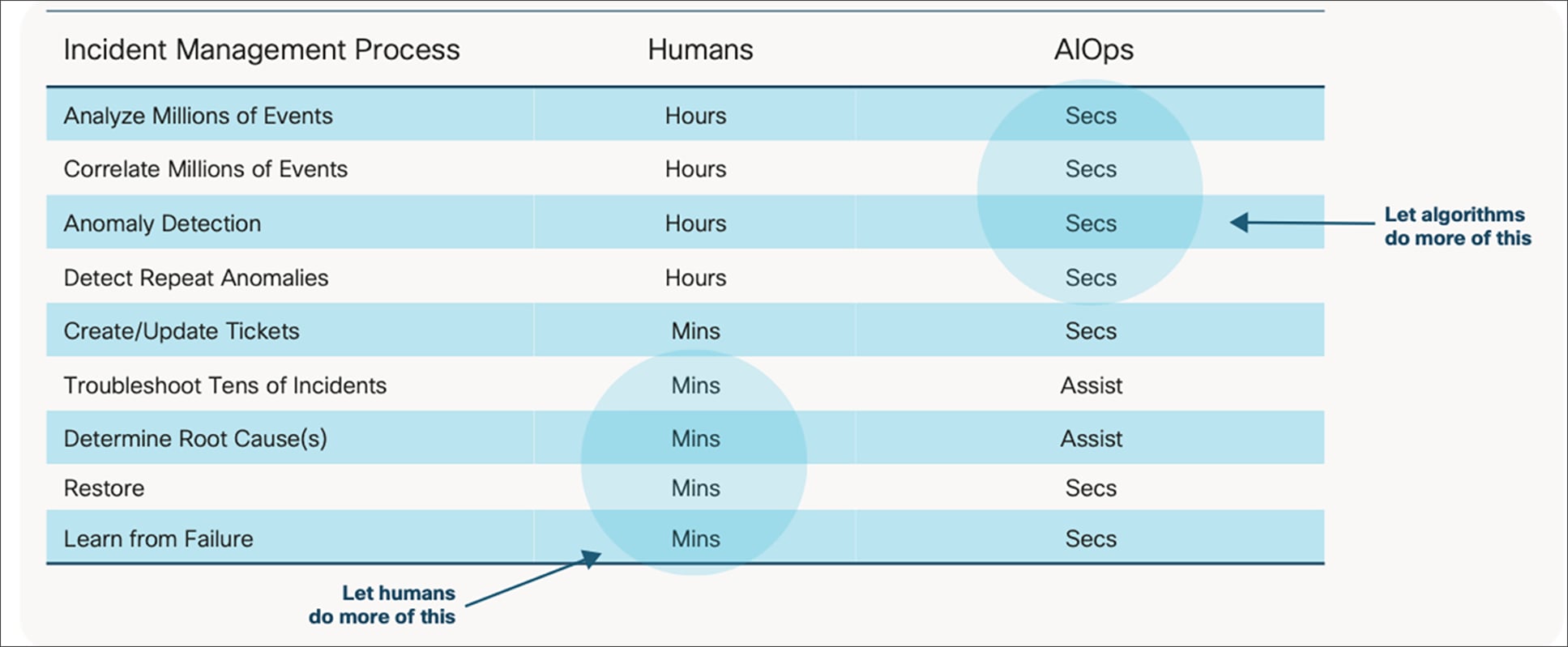
Applying artificial intelligence to network operations
The more AIOps learns the context associated with the data, the greater the accuracy with which the alert can be processed. Enriching the event streams with contextual attributes such as service name, tenant name, and service topology from Cisco NSO enables more precise correlations and reinforces functions such as service impact analysis and probable root cause analysis.
Orchestrating AIOps service context with Cisco NSO
Cisco NSO is an industry-leading orchestration platform for hybrid networks. It provides comprehensive lifecycle service automation to enable the design and delivery of high-quality services much faster and more easily, reinforcing the digital transformation. In addition, it simplifies the automation of configuration tasks in a rapidly growing, complex network environment.
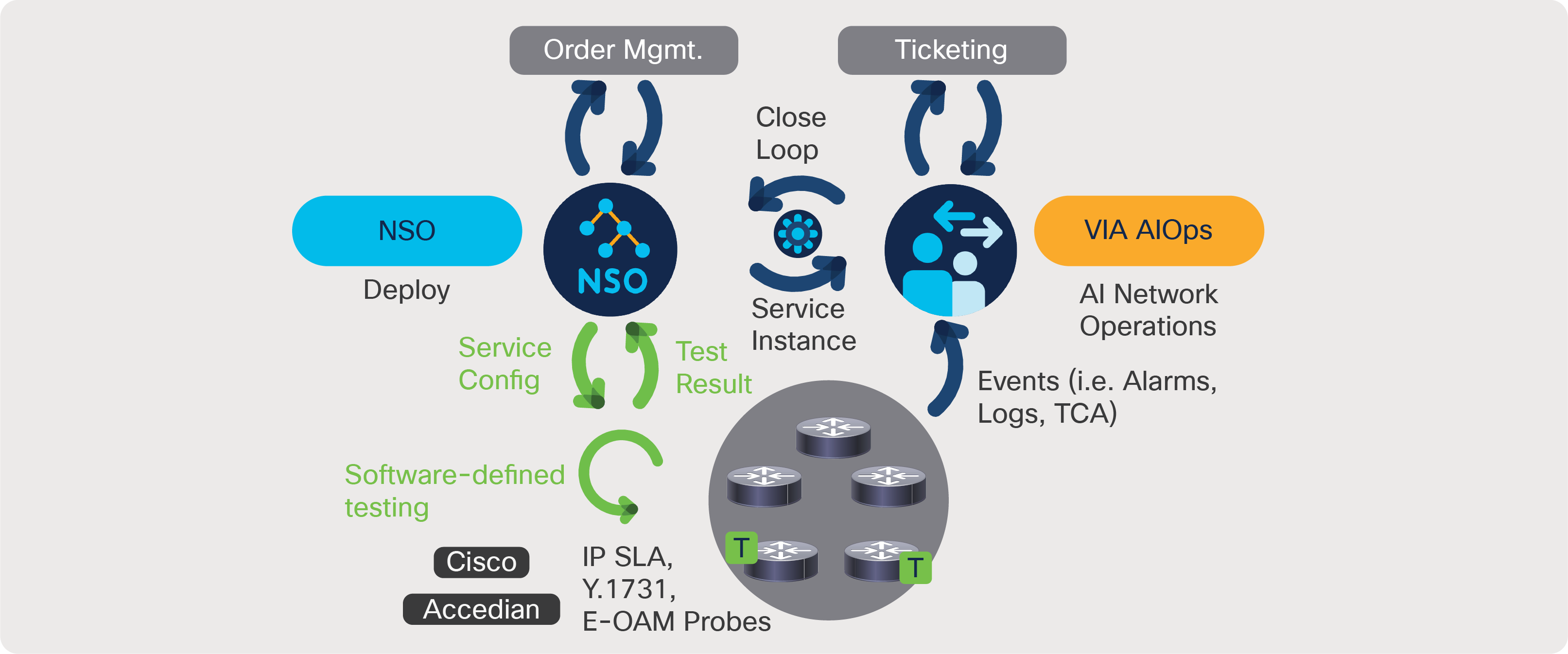
Cisco NSO interplays with Vitria VIA AIOps as part of self-healing closed-loop automation
The top priority for the operations team is to improve the service level, that is, to proactively detect and remediate any service- and customer-impacting issues. Deploying VIA AIOps in conjunction with Cisco NSO (Figure 3) helps enrich the service context, delivering the following benefits:
● Bridge the disconnect between service and infrastructure views. Enrich AIOps data with service and device attributes such as service name, service components, and topology to help correlate them across the service and infrastructure layers.
● Keep up with dynamic infrastructure. Subscribe to Cisco NSO for any changes in the service lifecycle status, underlying service components, and topology to help ensure accuracy in the analytics outcomes using machine learning techniques.
● Prioritize based on business and service impact. Enrich AIOps with customer attributes, which, when correlated with the service and infrastructure information, helps to characterize the impact of the issues that require attention from the operator.
● Automate service assurance through a model-driven approach. Cisco NSO enables “orchestrated assurance” to validate service status at the time of service provisioning and monitor service health throughout the service lifecycle. Based on the assurance intent expressed in the YANG model in conjunction with the definition of the service, NSO can configure the device instrumentation, such as Simple Network Management Protocol (SNMP) and model-driven telemetry pertaining to a specific service. It can provision active probes to monitor end-to-end service status. It can also configure the AIOps system to contextualize and analyze streamed data during the entire service lifecycle, immediately after the service is provisioned until it is retired.
● Simplify multivendor device configuration. Cisco NSO offers a single interface to configure all devices as part of closed-loop automation.
The service-centric approach to AIOps can drive closed-loop automation. Coupling of service monitoring with orchestration and configuration changes helps to reduce the typical delays between monitoring and control. The reduction of latency between orchestration, provisioning, and change with monitoring to near zero helps ensure continuous service quality from the moment the service is activated to its retirement.
End-to-end service assurance with VIA AIOps
VIA delivers improvement within the full service assurance lifecycle moving from noise reduction and fault detection to performance management and predictive analytics within and across the infrastructure, network, and applications. Designed to run and collect data in cloud-native environments from a wide range of sources, cloud-based application monitoring, dynamic data correlation, and root cause analysis can be implemented across vertical and horizontal application clusters, improving detection and resolution time and enabling operational cost reduction.
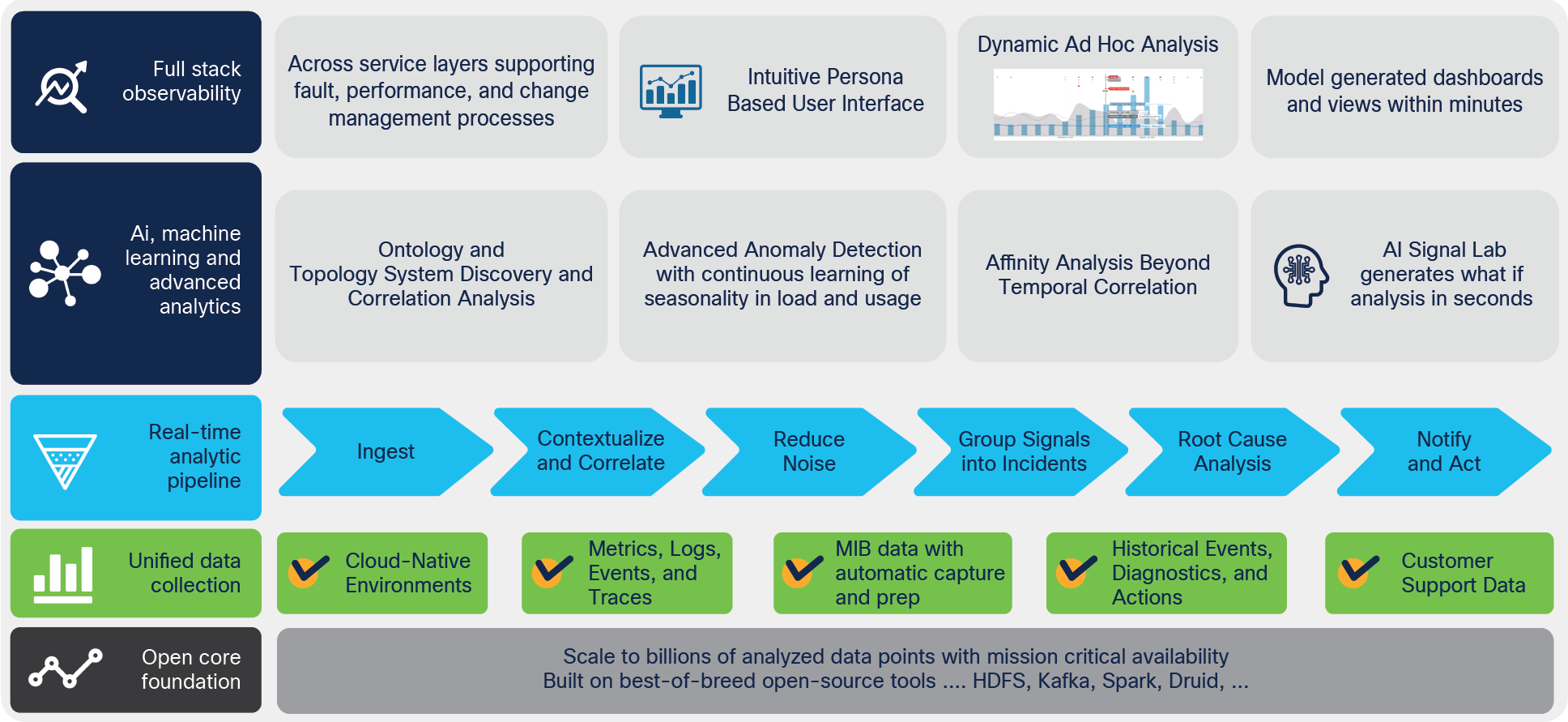
VIA AIOps end-to-end service assurance architecture
VIA AIOps uses artificial intelligence, machine learning, and advanced analytics to automatically reduce alert volume, detect service-impacting issues earlier, and distinguish symptoms from root cause across the technology stack and operational silos. VIA makes existing systems and fix agents more efficient with intelligent and timely insights. Actions can be prescribed automatically to quickly resolve faults and performance-related issues. Integration with incident management systems allows tickets to be opened, closed, or updated, the right fix agent to be notified for resolution, and other operational teams affected by the symptoms to be notified of the event and the actions being taken. Further, VIA identifies the impacted population for targeted remediation.
VIA delivers faster mean time to detect and resolve service-impacting issues. VIA AIOps collects and enriches streaming data from end devices, physical and virtual network elements, and applications in real time. It easily ingests metrics, logs, events, and traces and integrates with existing monitoring tools and processes, enhancing their value.
With VIA, fault, performance, and change management processes are optimized with a single AIOps application. Built for horizontal scaling, VIA AIOps reliably supports mission-critical operations that require massive data capabilities.
VIA AIOps implementation delivers a drastic reduction in the overall number of incidents affecting production systems and in the time to detect and resolve incidents that do occur (Mean Time To Detect [MTTD] and MTTR), improving your quality of service and reducing your overall operating cost.
Implementation of VIA AIOps has resulted in:

The table below gives a list of features provided by VIA AIOps and the related benefits.
Table 2. VIA AIOps features and benefits
| Features |
Benefits |
| Unified data collection |
|
| Ingests metrics, logs, event, and trace data via native connectors from applications, network, and infrastructure monitoring tools. |
With VIA AIOps, a single application can be implemented to optimize fault, performance, and change management processes. |
| Collects and analyzes data from cloud-native environments from a wide range of sources. |
One AIOps application can be used for both traditional in-house and cloud-based application environments. |
| Onboards raw data in standard and nonstandard formats. |
Never-before-seen data can be directly incorporated into performance and fault management processes in a matter of minutes. |
| Automates the preparation and capture of MIB data. |
MIB data can be more quickly incorporated into service assurance management processes. New traps can be ingested without code changes. |
| Data is not required to fit a specific data model or data specifications. |
Operations become more efficient by eliminating the development of thousands of lines of code to ingest and parse data sets. |
| Advanced anomaly detection |
|
| Determines automatically the correct algorithm to use on collected data to generate baselines and detect signals. |
The correct algorithm reduces noise and accelerates the detection of service-impacting issues. This enables the operations team to focus their attention only on the anomalies requiring action. False positives and true negatives are filtered out, improving operator effectiveness and reducing operator fatigue from excessive alert volumes. |
| Continuously learns seasonality in load and usage for every dimension. |
Baselines using intraday seasonality identify performance issues earlier than threshold-based systems, improving both the mean time to detect and mean time to repair. Continuous learning sustains optimal baselines across billions of dimensions and metrics with dynamic baseline changes as new data is collected. |
| Ontology discovery and reasoning |
|
| Application and service dependencies for all dimensions can be both learned using AI and taught. Information on the logical, topical, and physical characteristics across and between devices, infrastructure, customers, and all other system components and entities is automatically discovered. |
Ontology provides deeper and richer data to accelerate analysis and diagnosis across the system and subsystems to determine cause from symptom and assess impact. |
| Correlation and affinity analysis |
|
| Signal grouping analysis across service layers, applications, and workloads. Dynamic analysis and root cause identification across vertical and horizontal application and workload layers in cloud-based environments. |
VIA’s correlation and affinity analysis determines if events and signals coming from multiple sources across service layers are related and whether they should be treated together as a single incident or separately. This avoids:
● Staff time associated with responding to symptoms and not the root cause
● Higher service incident rate as the root cause has not been identified
● Customer experience cost, as customer perception of the service declines or usage decreases
VIA’s unique methods used in correlation and affinity analysis accelerates diagnostic analysis and the identification of root cause within and across service layers, dramatically improving operational efficiency. |
| AI Signal Lab |
|
| Actual data can be pushed to the signal lab environment to implement what-if analysis. |
The Signal Lab combines artificial intelligence and human intelligence to optimize service assurance processes. Running what-if analyses validates that planned system configuration changes would positively affect system performance. |
| Full stack observability |
|
| Delivers persona-based views with an intuitive and dynamic UI. Enables flexible and dynamic ad hoc forensic analysis. Creates views and dashboards automatically. |
Provides the right information on a timely basis to the right people to improve their efficiency and effectiveness. Avoids staff development time to meet unique user and environment requirements. Views and dashboards are generated based on the data. |
| Open core foundation |
|
| Built on best-of-breed open-source tools and platforms, including HDFS, Kafka, Spark, and Druid. |
VIA AIOps reliably supports mission-critical applications with the ability to scale to billions of analyzed data points. The open core foundation enables integration with existing service management and monitoring systems. Integration allows VIA to prescribe actions to these systems, including opening, closing, or updating a ticket, engaging the right fix agent, and notifying teams of the symptoms and probable causes of the event. |
Groundbreaking improvement in operational efficiency
Deploying Cisco NSO in conjunction with VIA AIOps allows you to implement a service-centric approach to AIOps and realize groundbreaking improvement in operational efficiency. It is alarming to know that Mean Time To Identify (MTTI) and MTTK make up to 80% of the total MTTR, as found by Gartner. Applying AI and machine learning techniques, as discussed earlier, can substantially reduce MTTI and MTTK, as show in Figure 8, hence reducing the overall MTTR.
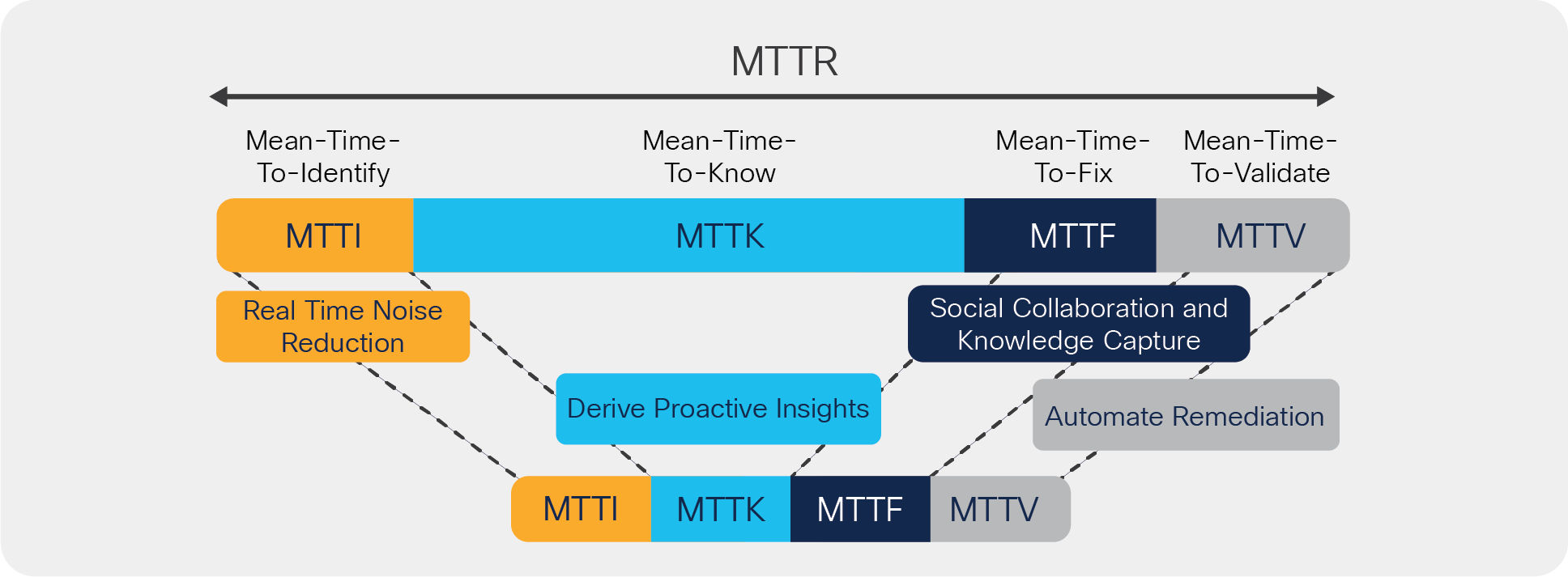
Reduction in MTTR
Deploying Cisco NSO in conjunction with VIA AIOps allows:
● Multivendor, multilayer, and multidomain correlation and service impact detection and localization
● Fully automated service onboarding and incident ticketing automation
● Automated service deployment, verification, and assurance onboarding through YANG definition
● Resource and service contextualization to expedite impact isolation
● Assessment of impact of infrastructure vs. overlay service via machine learning in a multilayer, multivendor, and multidomain environment
● Expedited troubleshooting and closed-loop remediation via NSO services exposure
MTTR can be significantly reduced and incident and problem management processes can be streamlined with VIA AIOps, combining the strengths of algorithms and human intellect. The benefits include:
● Drastically reduced alert volumes by eliminating operational noise, deduplication of data, and clustering of related alerts
● Proactive detection of service-impacting issues in a matter of seconds
● Automated ticket creation and stakeholder notifications
● Streamlined collaboration and an automated workflow across teams and tools
● Identification of a probable root cause and the populations impacted
● Capture of knowledge and automated sharing to make operators more knowledgeable over time
Vitria VIA AIOps for Cisco Network Automation is a next-generation approach to service assurance driven by real-time machine learning to detect and analyze incidents across the full service delivery stack of applications, infrastructure, and network. This provides development and operations teams a single pane of glass and unique operational insight, so they can detect issues in seconds, troubleshoot in minutes, and give customers a superior level of service.
Deploying Cisco NSO with VIA AIOps helps to enrich the alerts with service context so that the service impact can be accurately characterized. Moreover, the use of the YANG model decouples the definition of the services from the actual implementation. As a result, the solution can support multivendor deployments and the coexistence of SDN/NFV and legacy technologies and is future ready for any new definition of service.
The benefits of this service-centric approach to AIOps include:
● Discovering and acting on service issues proactively before they affect end users
● Empowering IT and network operations to embrace new agility-enhancing technologies such as cloud and SDN with greater confidence
● Facilitating more effective collaboration among IT and network operators across technology domains, locations, and organizations
● Enabling delivery of new services within existing staff constraints
● Increasing customer satisfaction, IT credibility, and business performance
Take advantage of VIA AIOps to implement innovative artificial intelligence for IT and network operations, accelerating detection, diagnosis, triage, and remediation of incidents while smoothing collaboration and automating workflow across technological and organizational boundaries.
For more information on Cisco’s network automation portfolio for service providers, please visit https://www.cisco.com/go/crosswork. To learn more about Vitria VIA AIOps for Cisco Network Automation or to schedule a demonstration, contact your Cisco sales representative.