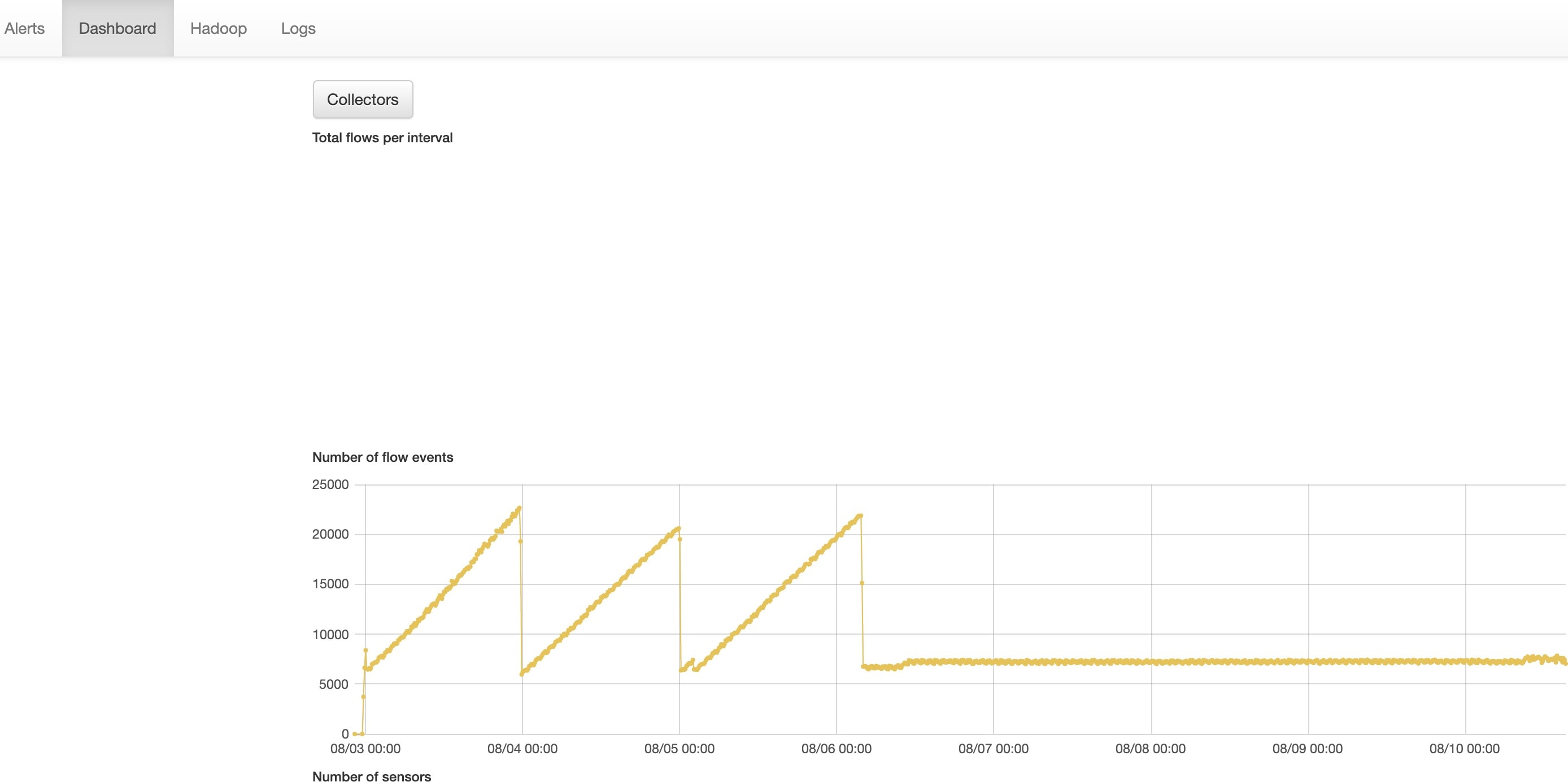
サービスのステータス
左側のナビゲーションウィンドウの ページには、Cisco Secure Workload クラスタで使用されている全サービスの正常性と、サービスの依存関係が表示されます。
![[サービスステータス(Service Status)] ページ](/c/dam/en/us/td/i/400001-500000/460001-470000/469001-470000/469743.jpg)
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
このドキュメントは、米国シスコ発行ドキュメントの参考和訳です。リンク情報につきましては、日本語版掲載時点で、英語版にアップデートがあり、リンク先のページが移動/変更されている場合がありますことをご了承ください。あくまでも参考和訳となりますので、正式な内容については米国サイトのドキュメントを参照ください。
この章では、アップグレード、再起動、データバックアップのスケジュール設定、データの復元など、実行できるさまざまなクラスタ メンテナンス アクションの詳細について説明します。[トラブルシューティング(Troubleshoot) ] メニューで使用可能なオプションからも、サービスとクラスタのステータスを確認できます。
 注目 |
最近の GUI の更新により、ユーザーガイドで使用されているイメージやスクリーンショットの一部に、製品の現在の設計が完全に反映されていない可能性があります。最も正確に視覚的に参照するには、このガイドを最新バージョンのソフトウェアと組み合わせて使用することを推奨します。 |
|
機能名 |
リリース |
機能説明 |
どこにあるか |
|---|---|---|---|
|
SMTP が無効になっている場合のクラスタリセットワークフロー |
3.10 |
SMTP が無効になっている場合は、 サイト管理者が リカバリコードを生成できるように、 [電子メール/ユーザー名と SMTP(Email/Username and SMTP)] タブが使用可能であることを確認します。この設定は、クラスタのリセットに進む前に構成する必要があります。 |
Secure Workload クラスタのリセット |
|
DBR の拡張機能:再イメージ化を伴わないクラスタのリセット |
3.9 |
Cisco Secure Workload クラスタをリセットします。サービスが再初期化され、データストアがクリアされます。また、[リセット(Reset)] オプションを使用してクラスタモードをプライマリからセカンダリ(アクティブからスタンバイ)に切り替えられます。 |
Secure Workload クラスタのリセット |
|
M6(Gen3)HDD ノードのハードウェア RAID5 |
3.9 |
TA-BNODE-G3 および TA-CNODE-G3 ノードで RAID5 をサポートします。 |
左側のナビゲーションウィンドウの ページには、Cisco Secure Workload クラスタで使用されている全サービスの正常性と、サービスの依存関係が表示されます。
アドミラルは、統合されたアラートシステムです。サービスステータスによって報告されたサービスの正常性に基づいてアラートを処理します。そのため、統一された方法でユーザーはサービス/クラスタの健全性を判断することができます。サービスステータスは、サービスの現在(特定の時点)の状態を示します。サービスステータスが赤色と報告された場合、サービスは停止していると見なされ、それ以外の場合は稼働していると見なされます。稼働時間は、サービスが稼働していると報告される時間です。アドミラルは、一定期間におけるサービスステータスによって報告されたサービスの正常性を評価し、サービスの稼働時間の割合が特定のしきい値を下回った場合にアラートを生成します。一定期間にわたってこの評価を行うことで、誤検知を減らし、本当のサービス停止時にのみ警告を発することが保証されます。
サービスによってアラートのニーズは異なるため、この割合と時間間隔は、サービスごとに異なる方法で固定されています。
顧客は、アドミラル通知を使用して、これらのイベントの通知を受けることができます。これらのイベントは、プラットフォームタイプの ページにも表示されます。
Note |
アドミラルアラートは、選択したサービスのサブセットのみに関連付けられます。サービスが上記のサブセットに含まれていない場合、サービスがダウンしてもアドミラルアラートは発生しません。このサービスのサブセットで設定されているアドミラルアラート、およびそれぞれのアラートしきい値の割合と時間間隔は固定であり、ユーザーは設定できません。 |
次のセクションでは、アドミラルアラートと通知について詳しく説明します。
アドミラルは、サービスステータスでサービスの稼働時間をチェックします。稼働時間がアラートの事前設定済みしきい値を下回ると、アラートが発生します。
たとえば、Rpminstall は、展開、アップグレード、パッチなどの実行中に RPM をインストールするために使用されるサービスで、1 時間の稼働時間が 80% 未満の場合に、アドミラルアラートを生成するように設定されています。Rpminstall サービスが上で指定されたしきい値よりも長い期間ダウンした場合、RPminstall のアドミラルアラートが生成され、ステータスが ACTIVE になります。

サービスが回復すると、稼働時間の割合が増加し始めます。稼働時間がしきい値を超えると、アラートは自動的にクローズし、ステータスは CLOSED に移行します。前述の Rpminstall の例では、1 時間の稼働時間が 80% を超えると、Rpminstall アドミラルアラートは自動的にクローズします。
Note |
アラートのクローズにより、サービスが正常に戻るまで常に遅延が生じます。これは、一定期間、アドミラルでサービスの正常性が監視されるためです。前述の例では、Rpminstall アラートのしきい値が 1 時間の稼働時間の 80% に設定されているため、アラートがクローズするまでに少なくとも 48 分間(1 時間の 80%)稼働している必要があります。 |
アラートをクローズするために必要なアクションはありません。アクティブなアドミラルアラートは、注意が必要な現在の根本的な問題を示すようになります。
Note |
アラートがクローズしても、専用の通知は生成されません。 |
CLOSED に移行したアラートは、ACTIVE アラートの下に表示されなくなります。クローズされたアラートは、次に示すように、フィルタの Status=CLOSED を使用して、UI に引き続き表示されます。

アドミラルアラートには次の 2 種類があります。
前のセクションで説明したアラート、個々のサービスに対して発生するアラートは、個別のアドミラルアラートカテゴリに分類されます。このアラートのテキストには常に <Service Name> Admiral Alert が含まれているため、個別のアラートをサービスまたは Admiral Alert サフィックスで簡単にフィルタ処理できます。
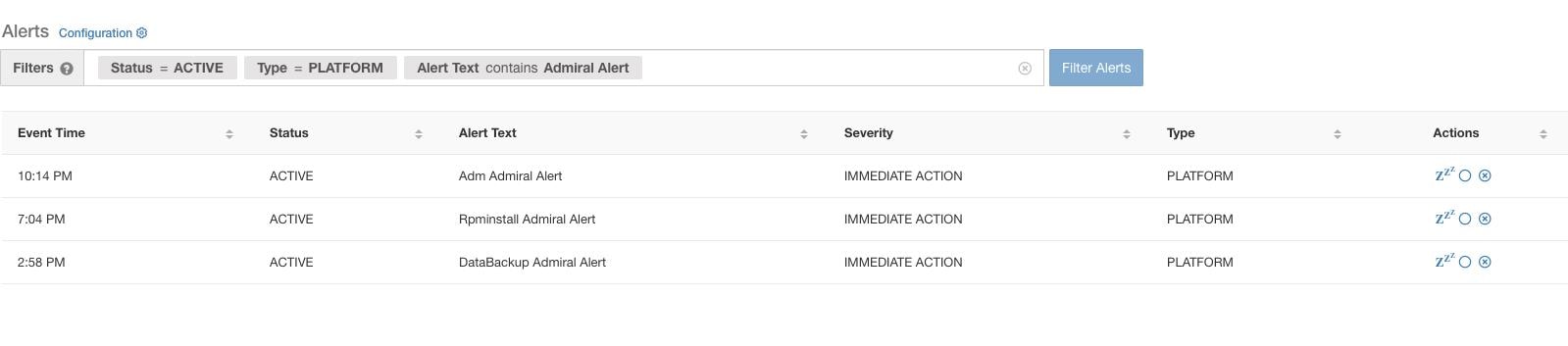
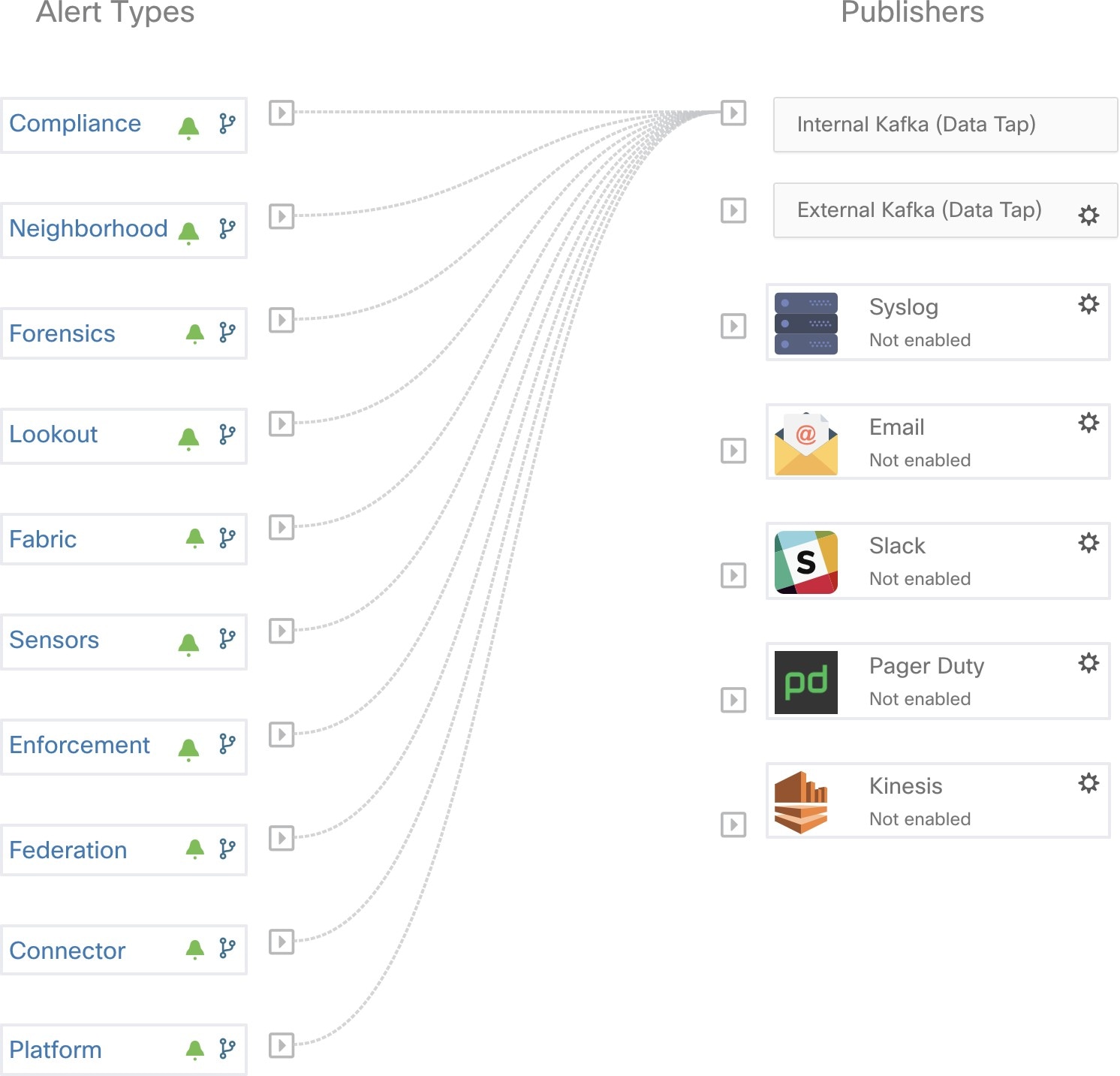
アドミラルは、UTC の午前 0 時に毎日サマリーアラートを生成します。サマリーアラートには、現在アクティブなアラートと、過去 1 日以内にクローズされたすべてのアラートのリストが含まれているため、ユーザーは、アドミラルによって報告された全体的なクラスタの正常性を 1 か所で確認できます。これは、専用の通知を生成しないクローズされたアラートを表示する場合にも役立ちます。クラスタが正常で、過去 1 日以内にクローズされたアラートがない場合、その日のサマリー通知は生成されません。これは、不要な通知とノイズを減らすために行われます。
この場合のアラートテキストは常にアドミラルサマリーなので、以下の図に示されているように、サマリーアラートを簡単にフィルタ処理できます。

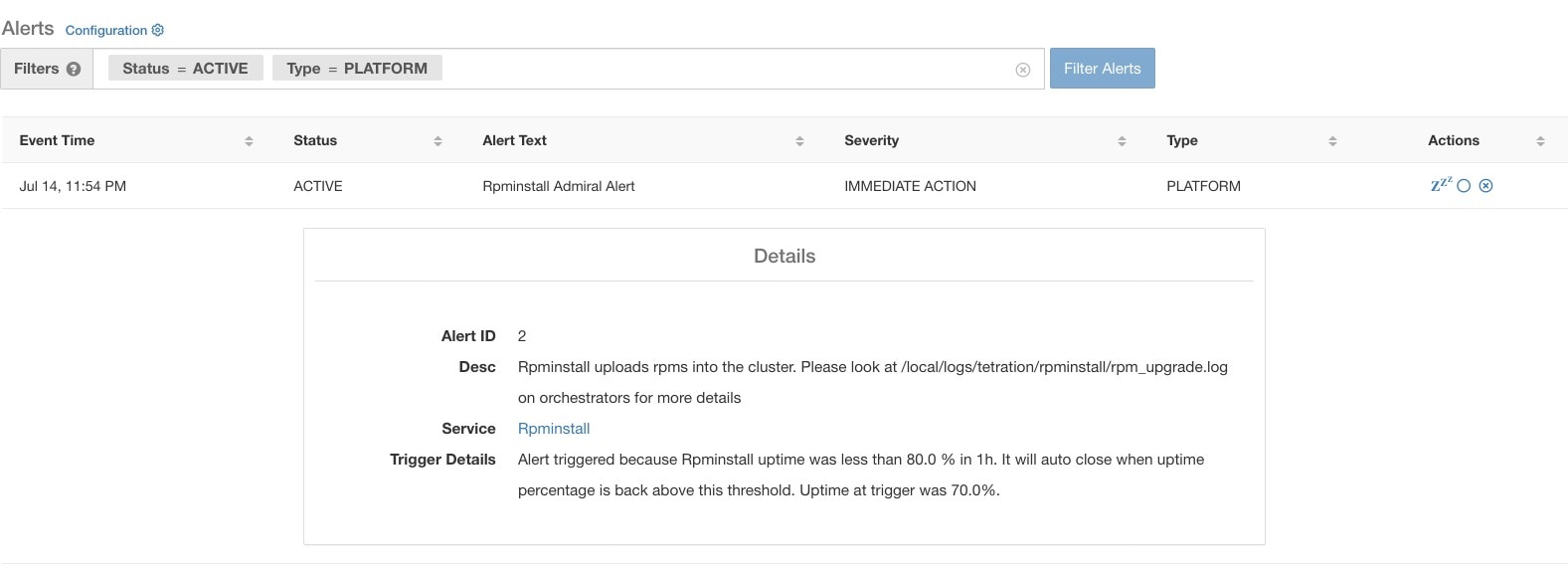
個別のアドミラルアラートのアラートをクリックすると、アラートが展開され、アラートのデバッグと分析に役立つフィールドが表示されます。
|
フィールド |
説明 |
|---|---|
|
[アラートID(Alert ID)] |
アラートの一意の ID。この ID は、特定のサービスダウン発生を一意に把握するのに役立ちます。前述のように、アラートによってレポートされているサービスの基本的な稼働時間が正常になると、アラートは自動的に閉じます。次に同じサービスが再びダウンすると、別のアラート ID を持つ新しいアラートが生成されます。このように、アラート ID は、発生したアラートの各インシデントを一意に把握するのに役立ちます。 |
|
Desc |
説明フィールドには、アラートの原因となっているサービスの問題についての追加情報が含まれています。 |
|
サービス |
このフィールドには、ユーザーがサービスのステータスを確認できる [サービスステータス(Service Status)] ページへのリンクが含まれています。ユーザーは、サービスステータスページでサービスがダウンとマークされている理由の詳細を把握することもできます。 |
|
トリガーの詳細情報 |
このフィールドには、サービスのトリガーしきい値に関する詳細情報が含まれます。ユーザーは、これらのしきい値を確認することで、基本的なサービスが復旧した後にアラートが閉じるタイミングを把握できます。たとえば、Rpminstall のしきい値は、1 時間で 80% の稼働時間と記されているため、アラートが自動的に閉じる前に、Rpminstall サービスは少なくとも 48 分間(1 時間の 80%)稼働している必要があります。ここには、アラートが発生した時点でサービスに表示された稼働時間の値も示されます。 |
次に、JSON Kafka 出力のサンプルを示します。
{
"severity": "IMMEDIATE_ACTION",
"tenant_id": 0,
"alert_time": 1595630519423,
"alert_text": "Rpminstall Admiral Alert",
"key_id": "ADMIRAL_ALERT_5",
"alert_id": "/Alerts/5efcfdf5497d4f474f1707c2/DataSource{location_type='TETRATION', location_name='platform', location_grain='MIN', root_scope_id='5efcfdf5497d4f474f1707c2'}/66eb975f5f987fe9eaefa81cee757c8b6dac5facc26554182d8112a98b35c4ab",
"root_scope_id": "5efcfdf5497d4f474f1707c2",
"type": "PLATFORM",
"event_time": 1595630511858,
"Check /local/logs/tetration/rpminstall/rpm_upgrade.log on
orchestrators for more details\",\"Trigger Details\":\"Alert triggered because Rpminstall
uptime was less than 80.0 % in 1h. It will auto close when uptime percentage is back above
this threshold. Uptime at trigger was 65.0%. \"}"
}
個別のアラートはすべて、JSON Kafka の形式に従います。アドミラルモニタリングの対象となる(サービスステータスからの)サービスのリストを次の表に示します。
|
サービス |
トリガー条件 |
重大度 |
|---|---|---|
|
KubernetesApiServer |
過去 15 分間でサービスの稼働時間が 90% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
|
Adm |
過去 1 時間のサービスの稼働時間が 90% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
|
DataBackup |
過去 6 時間のサービスの稼働時間が 90% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
|
DiskUsageCritical |
過去 1 時間のサービスの稼働時間が 80% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
|
RebootRequired |
過去 1 時間のサービスの稼働時間が 90% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
|
Rpminstall |
過去 1 時間のサービスの稼働時間が 80% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
|
SecondaryNN_checkpoint_status |
過去 1 時間のサービスの稼働時間が 90% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
8RU または 39RU 物理クラスタの場合、次のハードウェア コンポーネントとサービスの稼働時間がモニタされます。
Note |
|
|
サービス |
トリガー条件 |
重大度 |
|---|---|---|
|
DIMMFailure |
過去 1 時間のサービスの稼働時間が 80% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
|
DiskFailure |
過去 1 時間のサービスの稼働時間が 80% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
|
FanSpeed |
過去 1 時間のサービスの稼働時間が 80% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
|
ClusterSwitches |
過去 1 時間のサービスの稼働時間が 80% を下回っている。 |
即時対応(IMMEDIATE ACTION) |
Note |
アドミラルは、サービスステータスによって生成された処理メトリックに依存してアラートを生成します。メトリックスの取得が長期間不可能な場合(たとえば、サービス ステータスが停止している場合)、アラート(TSDBOracleConnectivity)が発生し、クラスタでサービス ベースのアラート処理がオフになっていることが通知されます。 |
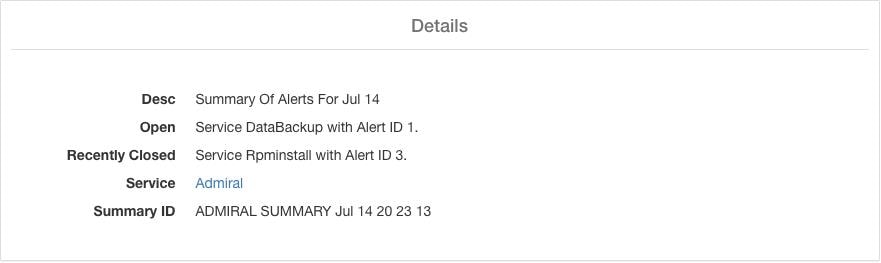
サマリーアラートは本質的に情報提供であり、優先順位は常に LOW に設定されます。アドミラルサマリーアラートをクリックすると、アドミラルアラートに関する概要情報を含む複数のフィールドが展開されて表示されます。
|
フィールド |
説明 |
|---|---|
|
Desc |
説明フィールドには、日次概要の日付が含まれています。 |
|
オープン(Open) |
オープンアラートは、概要が生成された時点でアクティブだったアラートを示しています。 |
|
[最近閉じたアラート(Recently Closed)] |
このフィールドには、過去 24 時間以内、つまり概要が生成された日に閉じたアラートが含まれています。各アラートの ID も含まれます。アラートは自動的に閉じるため、特定のサービスがダウンしてアラートが作成された後、正常になり、アラートが自動的に閉じる場合があります。アラートが閉じるケースが 1 日に複数回発生した場合、各インシデントとその固有のアラート ID が一覧表示されます。ただし、アラートが閉じる前に各サービスがしきい値時間の間稼働状態になっている必要があることを考えると、こうした状況が頻繁に発生することは想定されていません。ユーザーは、Status = CLOSED でフィルタリングして、各インシデントに関する詳細情報を取得できます。 |
|
サービス |
サービスを処理し、日次概要を生成するアドミラルのサービスステータスリンク。 |
|
[サマリーID(Summary ID)] |
サマリーアラートの ID。 |
次に、JSON Kafka 出力のサンプルを示します。
{
"severity": "LOW",
"tenant_id": 0,
"alert_time": 1595721914808,
"alert_text": "Admiral Summary",
"key_id": "ADMIRAL_SUMMARY_Jul-26-20-00-04",
"alert_id": "/Alerts/5efcfdf5497d4f474f1707c2/DataSource{location_type='TETRATION', location_name='platform', location_grain='MIN', root_scope_id='5efcfdf5497d4f474f1707c2'}/e95da4521012a4789048f72a791fb58ab233bbff63e6cbc421525d4272d469aa",
"root_scope_id": "5efcfdf5497d4f474f1707c2",
"type": "PLATFORM",
"event_time": 1595721856303,
"alert_details": "{\"Desc\":\"Summary of alerts for Jul-26\",\"Recently Closed\":\"None\",\"Open\":\" Service Rpminstall with Alert ID 5.\",\"Service\":\"Admiral\",\"Summary ID\":\"ADMIRAL_SUMMARY_Jul-26-20-00-04\"}"
}
1 日に複数のアラートを発生させるサービスを含むサマリーアラートの例を以下に示します。
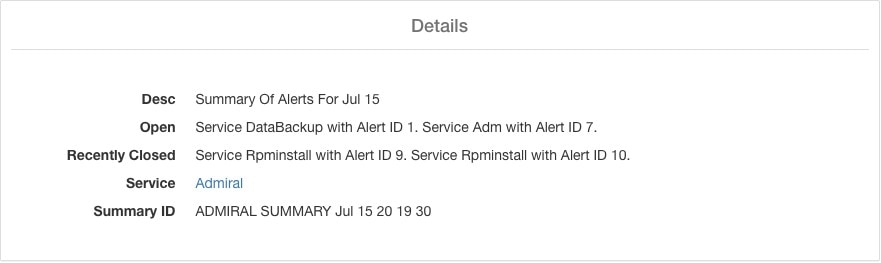
アドミラルアラートはアラートごとに 1 回だけ個別の通知を生成するため、特定のアラートを含めたり除外したり、スヌーズしたりする必要はありません。上述のとおり、しきい値である稼働時間の間サービスが正常に動作すると、アラートが自動的に閉じます。アラートを強制的に閉じるための強制終了オプションがあります。個々のアラートは自動的に閉じるため、通常、このオプションの使用は、UI からサマリーアラートを削除する場合に限る必要があります。

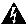 Warning |
個々のアラートを強制終了しないでください。基礎となるサービスがまだダウンしているか、稼働時間が予想されるしきい値を下回っているときに強制終了すると、次のアドミラル処理の反復で同じサービスに対して別のアラートが発生します。 |
アドミラル アラートのタイプは PLATFORM です。したがって、これらのアラートは、構成ページでの構成によるプラットフォーム アラートへの適切な接続によって、さまざまなパブリッシャに送信されるように構成できます。プラットフォーム アラートと内部 Kafka 間の接続は便宜上、デフォルトでオンになっているため、アドミラルアラートは [現在のアラート(Current Alerts)] ページに表示されます。手動で設定せずに 。
アドミラルアラートは、 で設定された電子メールアドレスにも送信されます。
Note |
プラットフォームの問題に関するアラートは、E メールまたはその他のコネクタ、アラートのパブリッシャチャネル(同一ネットワーク内に Edge アプライアンスが設定されている場合)を使用して受け取ることができます。 |
Note |
SMTP サーバーの設定が オフに なっているため、電子メール通信でのアドミラルアラートの送信に影響が生じる場合は、デフォルトのアドミラルアラート電子メールを設定できません。 |

したがって、ユーザーは TAN エッジアプライアンスをセットアップしていなくても、アドミラル通知を受け取ることができます。この動作は、以前のリリースの Bosun の動作に似ています。

これらの電子メール通知は、[現在のアラート(Current Alerts)] ページと同じトリガーに基づいて生成されます。したがって、電子メール通知はアラートの作成時に送信され、UTC の午前 0 時に日次概要メールが送信されます。日次概要メールには、すべてのアクティブなアラートと過去 24 時間以内に閉じられたアラートが一覧表示されます。
アクティブなアラートがなく、過去 24 時間以内に閉じられたアラートもない場合、電子メールノイズを減らすために概要メールはスキップされます。
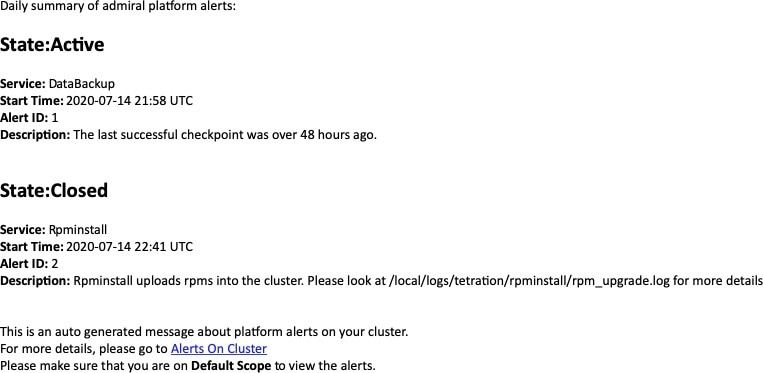
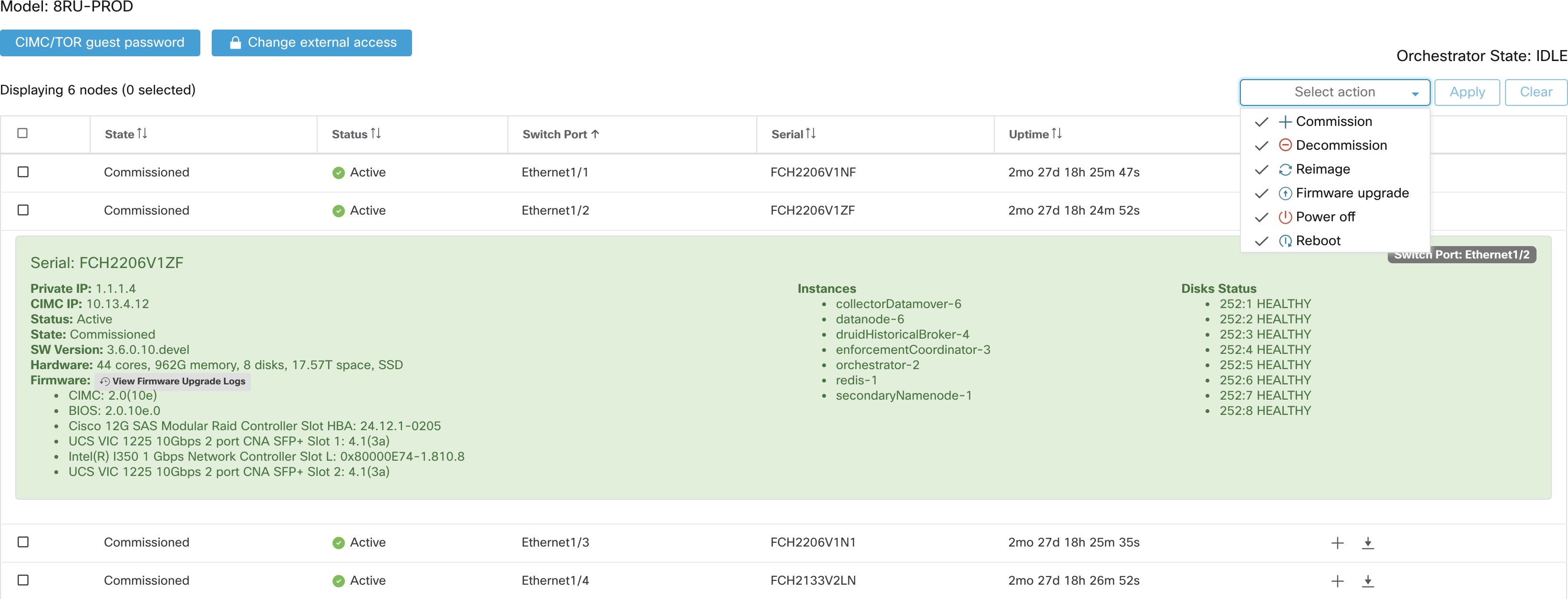
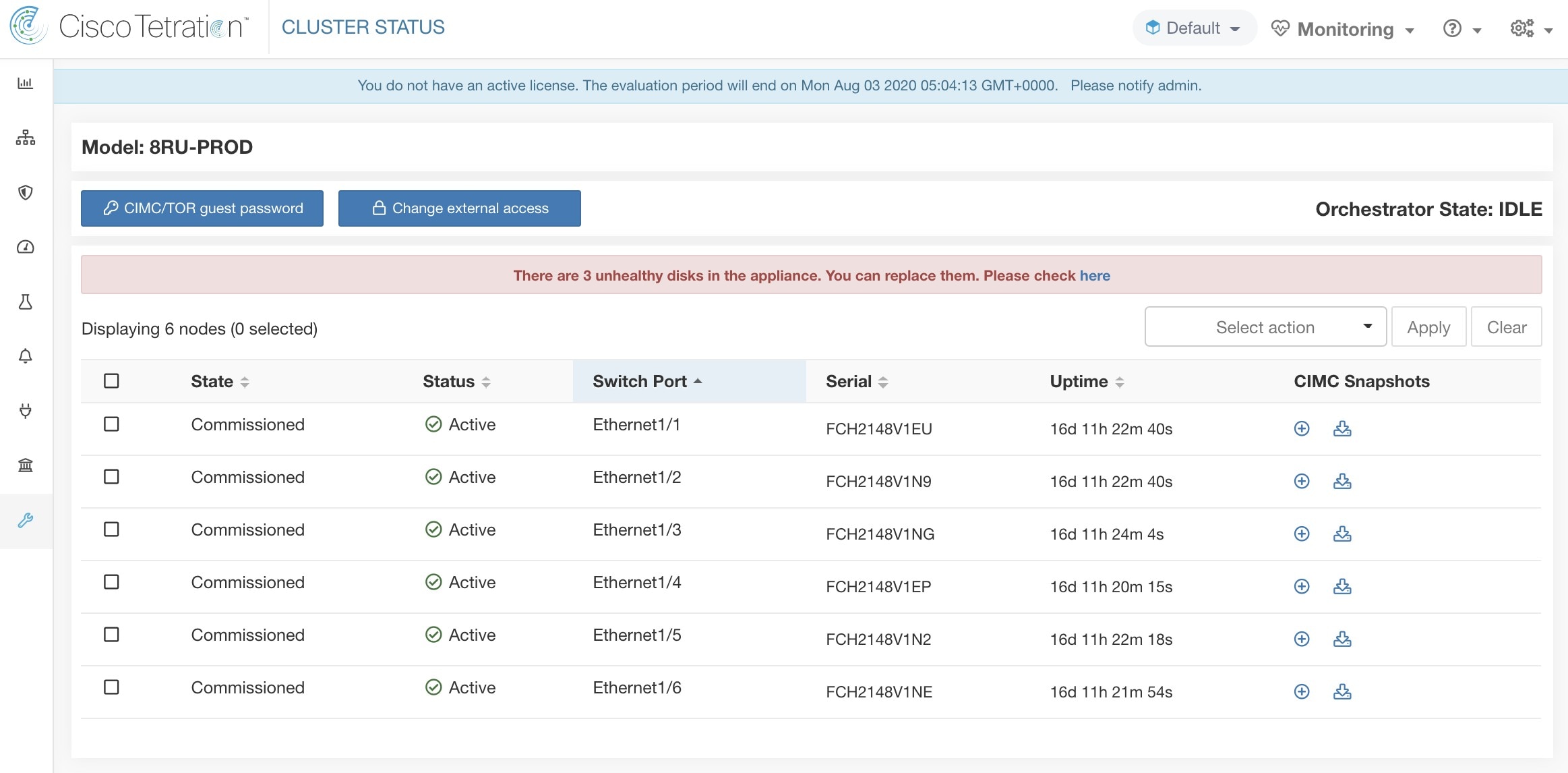
クラスタステータスには、Cisco Secure Workload ラック内のすべてのサーバーのステータスが表示されます。ナビゲーションウィンドウで、[トラブルシュート(Troubleshoot)] > [クラスタのステータス(Cluster Status)] の順に選択します。
Note |
サイト管理者とカスタマー サポートの両方のユーザーが、[クラスタ ステータス(Cluster Status)] ページにアクセスしてアクションを実行できます。 |
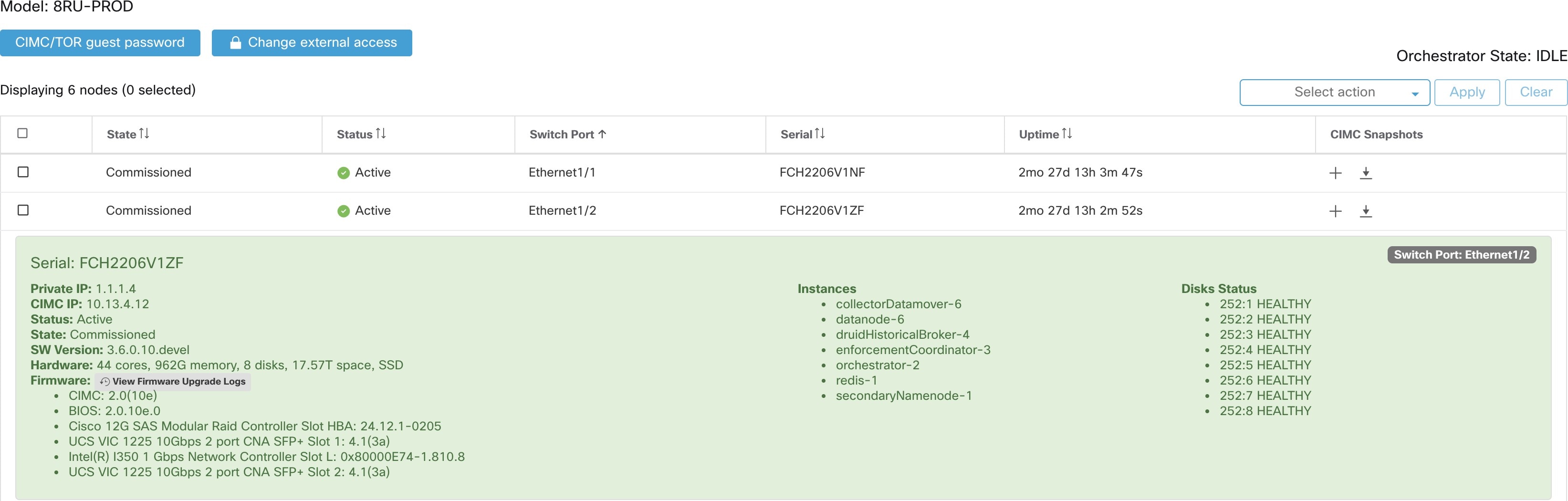
テーブルの各行は物理ノードを表し、ハードウェアとファームウェアの設定、CIMC IP アドレス(割り当てられている場合)などが示されます。ノードの詳細を表示するには、その行をクリックします。
ノードの CIMC パスワードを変更したり、外部アクセスを有効または無効にすることができます。[クラスタのステータス(Cluster Status)] にはオーケストレータの状態も表示され、それらに関する情報をカスタマーサポートに提供できます。
すべてのノードに影響するアクション
CIMC パスワードの変更と外部 CIMC アクセスの有効化または無効化は、[CIMC/TORゲストパスワード(CIMC/TOR guest password)] オプションおよび [外部アクセスの変更(Change external access)] オプションを使用して行うことができます。これらのアクションはクラスタ内のすべてのノードに影響します。
外部 CIMC アクセスノードの詳細
[外部アクセスの変更(Change external access)] をクリックするとダイアログボックスが開き、外部 CIMC アクセスのステータスが表示され、CIMC への外部アクセスを有効化、更新、または無効化できます。
[有効化(Enable)] をクリックすると、クラスタがバックグラウンドで設定され、外部 CIMC アクセスが有効になります。それらのタスクが完了し、外部 CIMC アクセスが完全に有効になるまでに最大 60 秒かかる場合があります。外部 CIMC アクセスが有効になっており、アクセスの自動期限切が設定されている場合、ダイアログボックスが表示され、[有効化(Enable)] が [更新(Renew)] に変わり、外部 CIMC アクセスを更新できることが反映されます。外部 CIMC アクセスを更新すると、有効期限が現在の時刻から 2 時間延長されます。
外部 CIMC アクセスが有効になっている場合、ノードの詳細(ノードの行をクリックして表示可能)の CIMC IP アドレスは、CIMC UI に直接アクセスできるクリック可能なリンクになります。このリンクを表示するには、[クラスタのステータス(Cluster Status)] ページのリロードが必要になる場合あります。
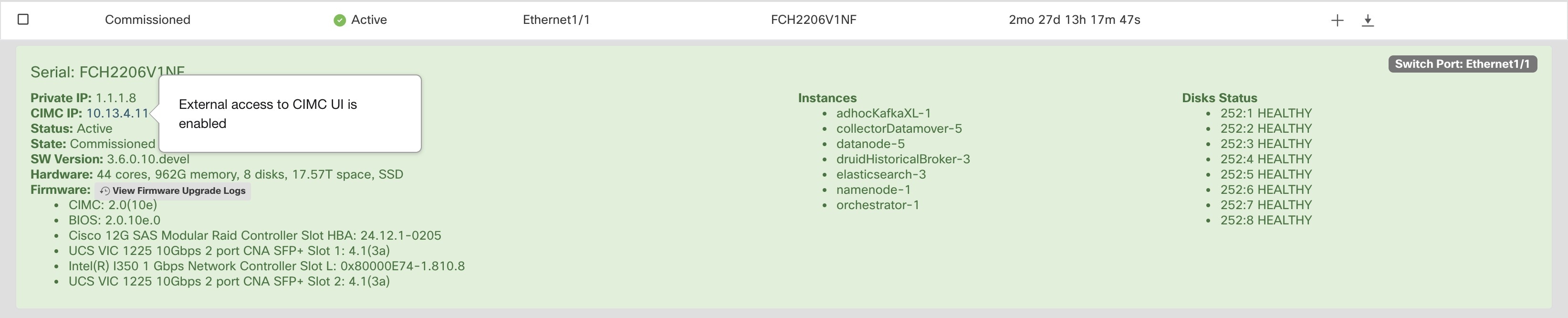
CIMC UI には通常、自己署名証明書があり、CIMC UI にアクセスすると、証明書が無効であることを示すエラーがブラウザに表示される可能性があります。Google Chrome を使用している場合、証明書チェックをバイパスして CIMC UI にアクセスするためには、無効な証明書エラーが Google Chrome に表示されたときに、引用符なしで「thisisunsafe」と入力する必要があります。
CIMC UI では、CIMC バージョンが 4.1(1g) 以降の場合にのみ、KVM アクセスが機能します。外部 CIMC アクセスが有効になると、アクセスを更新または無効にしない限り、2 時間後に自動的に無効になります。
外部 CIMC アクセスを無効にするとクラスタがバックグラウンドで設定され、外部 CIMC アクセスが無効になります。それらのタスクが完了し、外部 CIMC アクセスが完全に無効になるまでに最大 60 秒かかる場合があります。
|
フィールド |
説明 |
|---|---|
|
ステータス(Status) |
[ステータス(Status)] フィールドは、ノードの電源ステータスを示します。値は以下のとおりです。
|
|
[状態(State)] |
[状態(State)] フィールドは、ノードのクラスタメンバーシップの状態を示します。値は以下のとおりです。
|
|
[スイッチポート(Switch Port)] |
物理ノードが接続されている 2 つのスイッチのスイッチポートを指します。 |
|
[稼働時間(Uptime)] |
ノードが再起動またはシャットダウンせずに稼働していた時間を示します。 |
|
[CIMCスナップショット(CIMC Snapshots)] |
CIMC テクニカルサポートデータの収集を開始して、ダウンロードするために使用できます。 |
|
アクション |
説明 |
||
|---|---|---|---|
|
[コミッション(Commission)] |
このアクションを選択すると、新しいノードがクラスタに組み込まれます。このアクションについては、状態が [新規(New)] のノードのみを選択できます。 |
||
|
[デコミッション(Decommission)] |
クラスタに属しているノードを削除するには、このアクションを選択します。このアクションについては、状態が [稼働済み(Commissioned)] または [初期化済み(Initialized)] のノードのみを選択できます。 |
||
|
再稼働 |
ベア メタルのコミッションが失敗した場合は、このアクションを選択してベア メタルを再コミッションします。このアクションにより、既存のセットアップが自動的にクリーンアップされ、再イメージ化を必要とせずにコミッショニング プロセスが続行されます。 |
||
|
[再イメージ化(Reimage)] |
Secure Workload を再展開するには、このアクションを選択します。これにより、すべてのクラスタデータが消去されます。ベアメタル オペレーティング システムを旧バージョンから新バージョンにアップグレードする際に特に便利です。この手順は、ベアメタルがデコミッションされるときに必要になります。 |
||
|
[ファームウェアのアップグレード(Firmware upgrade)] |
ファームウェア情報は、CIMC IP に到達可能なノードで利用できます。このアクションは、旧バージョンのノードのファームウェアをアップグレードするのに役立ちます。 |
||
|
[電源オフ(Power off)] |
ノードの電源を切るには、このアクションを選択します。
|
Secure Workload オンプレミスクラスタには、ユニファイド コンピューティング システム(UCS)Cisco Integrated Management Controller(CIMC)ホスト アップグレード ユーティリティ(HUU)の ISO イメージがバンドルされています。[クラスタのステータス(Cluster Status)] ページでファームウェア アップグレード オプションを使用して、物理ベアメタルを Secure Workload RPM ファイルにバンドルされている HUU ISO に含まれる UCS ファームウェアのバージョンに更新できます。
ベアメタルホストは、ステータスが [アクティブ(Active)] または [非アクティブ(Inactive)] で、ベアメタルのステータスが [初期化(Initialized)] または [SKU不一致(SKU Mismatch)] でない場合に、ファームウェアの更新を開始できます。UCS ファームウェアを一度に更新できるベアメタルは 1 つだけです。ファームウェアの更新を開始するには、Secure Workload オーケストレータの状態が [アイドル(Idle)] である必要があります。UCS ファームウェアの更新が開始されると、Consul リーダー、アクティブなオーケストレータ、またはアクティブなファームウェアマネージャ(fwmgr)を他のホストに切り替える必要がある場合、[クラスタのステータス(Cluster Status)] ページに固有の UI 機能の一部が一時的に影響を受けることがあります。これらのスイッチオーバーは自動的に行われます。ファームウェアの更新中は、更新中のベアメタルホストのファームウェアの詳細は表示されません。更新が完了した後、[クラスタのステータス(Cluster Status)] ページにファームウェアの詳細が再度表示されるまで最大 15 分かかることがあります。ファームウェアの更新を開始する前に、[サービスのステータス(Service Status)] ページですべてのサービスが正常であることを確認してください。
ベアメタルでファームウェアの更新を開始すると、fwmgr では更新が続行できることを確認し、必要に応じてベアメタルを正常にパワーダウンし、ベアメタルの CIMC にログインして HUU ベースのファームウェアの更新を開始します。この HUU ベースのファームウェアの更新プロセスには、HUU ISO でベアメタルを起動させ、更新を実行し、CIMC を再起動して新しいファームウェアをアクティブ化し、その後 HUU ISO でベアメタルを再起動して、更新が完了したことを確認することが含まれます。全体的な更新プロセスには、G1 ベアメタルの場合は 2 時間以上、G2 ベアメタルの場合は 1 時間以上かかる場合があります。ファームウェアの更新プロセスが開始されると、ベアメタルと、そのベアメタルで実行されているすべての仮想マシンがクラスタ内でアクティブでなくなるため、[サービスのステータス(Service Status)] ページに、一部のサービスが正常でないと示される場合があります。ファームウェアの更新が完了すると、ベアメタルがクラスタ内で再びアクティブになるまでにさらに 30 分かかり、すべてのサービスが再び正常になるまでにさらに時間がかかる場合があります。ファームウェアの更新後 2 時間以内にサービスが回復しない場合は、カスタマーサービス担当者にお問い合わせください。
[クラスタのステータス(Cluster Status)] ページで、ベアメタルノードをクリックして、ベアメタルに関する詳細を展開できます。ファームウェアの更新が開始されたら、[ファームウェアのアップグレードログを表示(View Firmware Upgrade Logs)] ボタンをクリックして、ファームウェア更新のステータスを表示できます。ログには、ファームウェア更新の全体的なステータスが表示されます。ステータスは次のいずれかです。
[ファームウェアの更新がトリガーされました(Firmware update has been triggered)]:ファームウェアの更新が要求されましたが、まだ開始されていません。このステータス中に、fwmgr では、ファームウェアの更新に必要なサービスが機能していること、および CIMC がそれらのサービスに到達できることが確認されます。
[ファームウェアの更新を実行中です(Firmware update is running)]:ファームウェアの更新が開始されました。ファームウェアの更新がこの状態に達すると、CIMC と HUU で更新が制御され、Secure Workload クラスタでは CIMC から取得した更新に関するステータスが報告されます。
[ファームウェアの更新がタイムアウトしました(Firmware update has timed out)]:ファームウェア更新の一部のプロセスが、完了予測時間を超えたことを示します。[ファームウェアの更新を実行中です(Firmware update is running)] のフェーズに入ると、ファームウェア更新プロセス全体の制限時間は 240 分になります。ファームウェアの更新中に、新しいバージョンでリブートすると CIMC が到達不能になることがあります。この到達不能状態のタイムアウトは、ファームウェアの更新が「タイムアウト」と宣言されるまでの 40 分間です。ファームウェアの更新が開始されると、その更新のモニタリングは 120 分後にタイムアウトします。
[ファームウェアの更新がエラーのため失敗しました(Firmware update has failed with an error)]:エラーが発生し、ファームウェアの更新が失敗したことを示します。通常、CIMC では成功または失敗は示されません。そのため、この状態は通常、ファームウェアの更新が実際に実行される前にエラーが発生したことを示しています。
[ファームウェアの更新が終了しました(Firmware update has finished)]:ファームウェアの更新は、エラーやタイムアウトが発生することなく終了しました。通常、CIMC では成功または失敗は示されないため、[クラスタのステータス(Cluster Status)] ページでこれらの詳細が確認できるようになったら、UCS ファームウェアバージョンが更新されているか確認することをお勧めします。詳細が確認できるようになるまで最大 15 分かかります。
[ファームウェアのアップグレードログを表示(View Firmware Upgrade Logs)] ポップアップウィンドウの全体的なステータスの下にある [更新の進行状況(Update progress)] セクションには、ファームウェア更新の進行状況を示すタイムスタンプ付きのログメッセージが含まれます。これらのログメッセージに [ホストの再起動が進行中です(Rebooting Host In Progress)] ステータスが表示されると、CIMC で更新が制御され、クラスタがその更新をモニターします。後続のほとんどのログメッセージは CIMC から直接送信され、更新のステータスが変更された場合にのみログメッセージのリストに追加されます。
CIMC で個々のコンポーネント更新ステータスの提供が開始されると、[ファームウェアのアップグレードログを表示(View Firmware Upgrade Logs)] ポップアップの [更新の進行状況(Update progress)] セクションの下に、[コンポーネントの更新ステータス(Component update status)] セクションが表示されます。このセクションでは、ベアメタル上のさまざまな UCS コンポーネントの更新ステータスを要約します。
データのバックアップと復元は、Cisco Secure Workload クラスタ、コネクタ、および外部オーケストレータからオフサイトストレージにデータをコピーするディザスタ リカバリ メカニズムです。災害が発生した場合は、オフサイトストレージから同じフォームファクタのクラスタにデータが復元されます。別のバックアップサイトに切り替えることもできます。
データのバックアップと復元は、物理クラスタ(8 RU と 39 RU)でサポートされています。
データは、S3V4 API と互換性のある任意の外部オブジェクトストアにバックアップできます。
Cisco Secure Workload には、データをバックアップするための十分な帯域幅とストレージが必要です。ネットワーク速度が遅く、遅延が大きいと、バックアップに失敗する可能性があります。
データストレージの制限は、選択したバックアップのタイプに基づきます。
継続的モードを使用したデータバックアップでは、フローデータを含む完全バックアップに必要な最小ストレージは 50 TB です。必要な実際のストレージ容量を判断するには、[データバックアップ(Data Backup)] ページで使用可能な [キャパシティプランナー(Capacity Planner)] オプションを使用してください。詳細については、キャパシティプランナーの使用を参照してください。複数のバックアップ用のストレージ容量が不足していると、ストレージの制限内でバックアップを管理できるように、古いバックアップが頻繁に削除されます。少なくとも 1 つのバックアップのために十分なストレージが必要です。
リーンモードのバックアップの場合は、バックアップデータの大部分を構成するフローデータがバックアップに含まれないため、1 TB のストレージで十分です。
データは、プライマリと同じバージョンを実行している互換性のあるフォームファクタのクラスタにのみ復元できます。たとえば、8 RU クラスタからは、別の 8 RU クラスタにのみデータを復元できます。
データバックアップのスケジュールは、UI の [データバックアップ(Data Backup)] セクションを使用して設定できます。バックアップは、設定に基づいて 1 日に 1 回スケジュールされた時刻にトリガーされるか、継続的に実行されるように設定することができます。バックアップの成功は、チェックポイントと呼ばれます。チェックポイントは、クラスタのプライマリデータストアのポイント イン タイム スナップショットです。
成功したチェックポイントを使用して、データを別のクラスタまたは同じクラスタに復元できます。
クラスタ設定データは、すべてのチェックポイントで常にバックアップされます。フローおよびその他のデータが、バックアップされるデータの大部分を占めます。そのため、適切に設定されている場合は、増分変更のみがバックアップされます。増分バックアップは、外部ストレージにプッシュされるデータの量を減らすために役立ち、ネットワークの過負荷を回避できます。増分バックアップが設定されている場合、必要に応じて、すべてのデータソースに対してスケジュールに従って完全バックアップをトリガーすることができます。完全バックアップでは、チェックポイント内のすべてのオブジェクトがコピーされます。オブジェクトが変更されていない場合でもコピーされます。これにより、クラスタ、クラスタとオブジェクトストア間のネットワーク、およびオブジェクトストア自体にかなりの負荷がかかる可能性があります。オブジェクトが破損している場合、またはオブジェクトストアに回復不能なハードウェア障害がある場合は、完全バックアップが必要になることがあります。さらに、バックアップ用に提供されているバケットが変更された場合は、完全バックアップが自動的に適用されます。これは、増分バックアップを役立てるには事前に完全バックアップが必要なためです。
|
Cisco Secure Workload クラスタデータ |
完全バックアップモードでデータがバックアップされるか |
リーンモードでデータがバックアップされるか |
|---|---|---|
|
クラスタ設定 |
〇 |
〇 |
|
クラスタのイメージングに使用される RPM |
〇 |
〇 |
|
ソフトウェアエージェント展開イメージ |
〇 |
〇 |
|
フロー データベース |
〇 |
いいえ |
|
自動ポリシー検出に必要なデータ |
〇 |
いいえ |
|
ファイルハッシュ、データリークモデルなどのフォレンジックに役立つデータ |
〇 |
いいえ |
|
攻撃対象領域の分析に役立つデータ |
〇 |
いいえ |
|
CVE データベース |
〇 |
いいえ |
Note |
|
クラスタでデータのバックアップと復元オプションを有効にするには、Cisco Technical Assistance Center にお問い合わせください。
データをバックアップおよび復元できるのは、サイト管理者ロールを持つユーザーのみです。
オブジェクトストアのアクセスキーと秘密鍵が必要です。データのバックアップと復元オプションは、オブジェクトストアの事前認証されたリンクでは機能しません。
S3 サーバーの完全修飾ドメイン名(FQDN)の A および AAAA DNS レコードを更新する必要があります。S3 URL へのアクセスに IPv6 アドレスを使用するようにクラスタが設定されている場合は、S3 サーバー FQDN の AAAA DNS レコードのみを更新します。
Cisco Secure Workload アプライアンスがオブジェクトストアに使用する帯域幅を調整するポリシングを設定します。バックアップするデータの量が多い場合に低帯域幅でポリシングすると、バックアップが失敗することがあります。
クラスタの完全修飾ドメイン名(FQDN)を設定し、ソフトウェアエージェントが完全修飾ドメイン名(FQDN)を解決できることを確認します。
エージェントリストページのすべてのエージェントに、フェールオーバーの準備ができていることを示す緑色のチェックマークが表示されていることを確認します。さらに、エージェントのスムーズなフェールオーバーのために、すべてのエージェントがスタンバイクラスタに接続されていることを確認します。
Note |
データのバックアップと復元を有効にすると、現在および以降のソフトウェア エージェント バージョンのみをインストールとアップグレードに使用できます。現在のクラスタバージョンよりも前のバージョンは、互換性がないため非表示のままです。 |
ソフトウェアエージェントまたは Kafka の FQDN の要件
ソフトウェアエージェントは、IP アドレスを使用して Cisco Secure Workload アプライアンスから制御情報を取得します。データのバックアップと復元を有効にして、災害後のシームレスなフェールオーバーを可能にするには、FQDN の使用にエージェントを切り替える必要があります。このスイッチに対しては、Cisco Secure Workload クラスタのアップグレードだけでは不十分です。ソフトウェアエージェントは、Cisco Secure Workload バージョン 3.3 以降で FQDN の使用をサポートしています。そのため、エージェントのフェールオーバーを有効にして、データのバックアップと復元の準備ができていることを確認するには、エージェントをバージョン 3.3 以降にアップグレードします。
FQDN が設定されていない場合、デフォルトの FQDN は次のとおりです。
|
IP タイプ(IP Type) |
デフォルトの FQDN |
|---|---|
|
センサー VIP |
wss{{cluster_ui_fqdn}} |
|
Kafka 1 |
kafka-1-{{cluster_ui_fqdn}} |
|
Kafka 2 |
kafka-2-{{cluster_ui_fqdn}} |
|
Kafka 3 |
kafka-3-{{cluster_ui_fqdn}} |
FQDN は、 ページで変更できます。
![[クラスタ設定(Cluster Configuration)] ページでのデータのバックアップと復元の FQDN または IP](/c/dam/en/us/td/i/400001-500000/460001-470000/467001-468000/467631.jpg)
FQDN の DNS レコードを、同じページで提供される IP で更新します。次の表に、IP と FQDN のマッピングを示します。
|
フィールド名 |
対応する IP フィールド |
説明 |
|---|---|---|
|
センサー VIP FQDN |
センサー VIP |
FQDN を更新してクラスタ コントロール プレーンに接続する |
|
Kafka 1 FQDN |
Kafka 1 IP |
Kafka ノード 1 IP |
|
Kafka 2 FQDN |
Kafka 2 IP |
Kafka ノード 2 IP |
|
Kafka 3 FQDN |
Kafka 3 IP |
Kafka ノード 3 IP |
Note |
センサー VIP および Kafka ホストの FQDN は、データのバックアップと復元が設定される前にのみ変更できます。設定後は、FQDN は変更できません。 |
オブジェクトストアは、S3V4 準拠のインターフェイスを提供する必要があります。
Note |
一部の S3V4 準拠のオブジェクトストアでは、DeleteObjects 機能がサポートされていません。古いチェックポイント情報を削除するには、DeleteObjects 機能が必要です。DeleteObjects 機能がないと、古いチェックポイントをストレージから削除しようとすると障害が発生し、ストレージの領域が不足する可能性があります。 |
所在地(Location)
オブジェクトストアの場所は、ストアからのバックアップと復元に伴う遅延にとって重要です。復元時間を短縮するには、オブジェクトストアがスタンバイクラスタの近くにあることを確認します。
Bucket
オブジェクトストアに、Cisco Secure Workload の専用の新しいバケットを作成します。クラスタのみが、このバケットへの書き込みアクセス権を持つ必要があります。このバケットに対して、クラスタがオブジェクトを書き込み、保持を管理します。バケット用に少なくとも 200 TB のストレージをプロビジョニングし、バケットのアクセスと秘密鍵を取得します。Cisco Secure Workload でのデータのバックアップと復元は、事前認証されたリンクでは機能しません。
Note |
オブジェクトストアとして Cohesity が使用されている場合は、スケジュール時にマルチパートアップロードを無効にします。 |
HTTPS
データ バックアップ オプションは、オブジェクトストアでの HTTPS インターフェイスのみをサポートします。オブジェクトストアへ転送中のデータが暗号化され、安全であることを保証するためです。ストレージ SSL/TSL 証明書が信頼できるサードパーティ CA によって署名されている場合、クラスタはその証明書を使用してオブジェクトストアを認証します。オブジェクトストアが自己署名証明書を使用している場合は、[サーバーCA証明書を使用(Use Server CA Certificate)] オプションを選択して、公開キーまたは CA をアップロードできます。
サーバー側の暗号化
Cisco Secure Workload クラスタに割り当てられたバケットのサーバー側の暗号化をオンにすることを強く推奨します。クラスタは、HTTPS を使用してオブジェクトストアにデータを転送します。ただし、オブジェクトストアはオブジェクトを暗号化して、保存されたデータの安全性を確保する必要があります。
Note |
|
Cisco Secure Workload でデータバックアップを設定するには、次の手順を実行します。
計画:データバックアップのオプションでは、プランナーを使用して、オブジェクトストアへのアクセスをテストし、ストレージ要件と、各日に必要なバックアップ期間を決定できます。これは、スケジュールを設定する前の試験に使用できます。
データのバックアップと復元の計算ツールを使用するには、 に移動します。データのバックアップと復元が設定されていない場合は、データバックアップのランディングページに移動します。

Note |
[プラットフォーム(Platform)] の下に [データバックアップ(Data Backup)] オプションが表示されない場合は、データのバックアップと復元を有効にするライセンスがあることを確認してください。 |
データバックアップの設定とスケジューリング:Cisco Secure Workload は、設定された時間枠でのみオブジェクトストアにデータをコピーします。バックアップを初めて設定するときに、事前チェックが実行され、FQDN が解決可能であり、正しい IP に解決されることを確認します。最初の検証後に、登録済みのソフトウェアエージェントに更新がプッシュされ、FQDN の使用に切り替わります。FQDN がないと、エージェントはディザスタイベント後に別のクラスタにフェールオーバーできません。FQDN の使用をサポートするには、クラスタでサポートされている最新バージョンにエージェントをアップグレードする必要があり、すべてのエージェントがセンサー VIP FQDN を解決できる必要があります。Cisco Secure Workload リリース 3.3 以降では、優れた可視性エージェントと適用エージェントのみがデータのバックアップと復元をサポートしており、FQDN の使用に切り替えます。
スケジュールを作成し、データバックアップを設定するには、データバックアップの設定を参照してください。
|
Step 1 |
ストレージに Cisco Secure Workload との互換性があることを確認するには、次のいずれかのアクションを実行します。
|
||
|
Step 2 |
次の詳細を入力します。
|
||
|
Step 3 |
(オプション)必要に応じて、HTTP プロキシを有効にできます。 |
||
|
Step 4 |
(オプション)バックアップされたデータのマルチパートアップロードを使用するには、[マルチパートアップロードの使用(Use Multipart Upload)] を有効にします。 |
||
|
Step 5 |
(オプション)ストレージサーバーの認証に CA 証明書が必要な場合は、[サーバーCA証明書の使用(Use Server CA Certificate)] を有効にして、証明書の詳細を入力します。 |
||
|
Step 6 |
[テスト(Test)] をクリックします。 |
ストレージの検証では、次のことがテストされます。
オブジェクトストアとバケットに対して認証およびアクセスします。
設定されたバケットにアップロードし、そのバケットからダウンロードします。
帯域幅をチェックします。
ストレージ プランニング プロセスが完了するまでに、約 5 分かかる可能性があります。
|
Step 1 |
想定されるストレージサイズとバックアップ時間を計画するために、次のいずれかのアクションを実行します。
|
|
Step 2 |
データをバックアップするための最大帯域幅制限を入力します。 この帯域幅は、オブジェクトストアへのデータをスロットリングするポリサー設定の値以下である必要があります。 |
|
Step 3 |
登録済みソフトウェアエージェント数は自動的に入力されます。予測に基づいて、エージェント数を変更できます。 |
|
Step 4 |
(オプション)設定データ以外をバックアップから除外するには、[リーンデータモード(Lean Data Mode)] を有効にします。このオプションを使用すると、ストレージの制限が 75% 軽減されます。 |
|
Step 5 |
ストレージバケットに設定される最大ストレージ。これにより、バックアップの保持期間が自動的に設定されます。 |
必要な詳細を入力すると、[推定バックアップ期間(Estimated Backup Duration)] に 1 日のデータのバックアップに必要な時間が表示されます。この値は、一般的なエージェント負荷、推定エージェント数、および設定された最大帯域幅に基づく推定値です。[推定最大ストレージ(Estimated Maximum Storage)] には、指定された保持と推定エージェント数をサポートするために Cisco Secure Workload で必要となる最大ストレージの推定値が表示されます。
データ バックアップを設定するには、スケジュールされたバックアップの時間の前にチェックポイントを作成します。これにより、バックアップ プロセスが計画どおりに開始されます。データ バックアップ プロセスには次の手順が含まれます。
チェックポイントの作成
データのバックアップ
現在のスケジュール済みバックアップが完了した後、次のバックアップの開始を 1 時間後にスケジュールして、新しいチェックポイントを開始できます。
|
Step 1 |
データバックアップのランディングページで、[新しいスケジュールの作成(Create new schedule)] をクリックします。 |
||
|
Step 2 |
実行する前提条件チェックを確認するには、[承認(Approve)] ボタンをオンにして、[続行(Proceed)] をクリックします。 前提条件チェックは完了するまでに約 30 分かかり、スケジュールが初めて設定されたときにのみ実行されます。 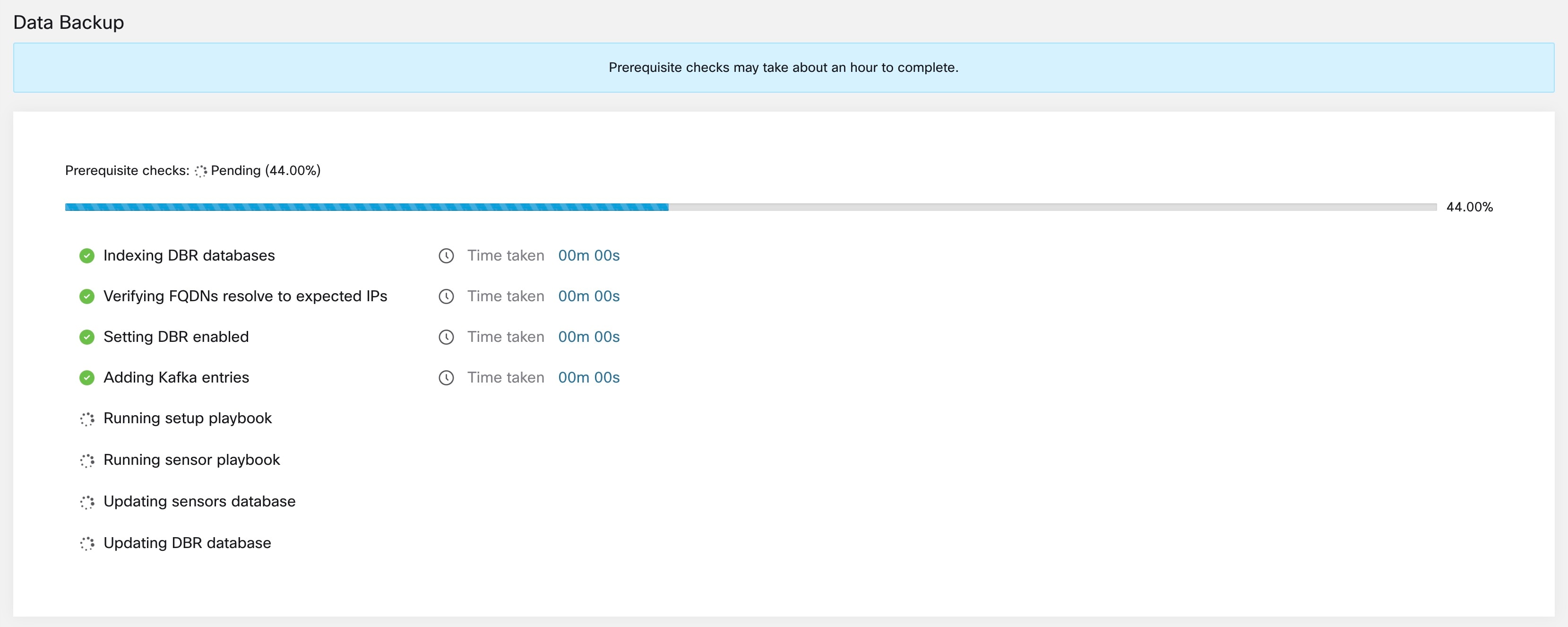
|
||
|
Step 3 |
ストレージを設定するには、次の詳細を入力して、[テスト(Test)] をクリックします。
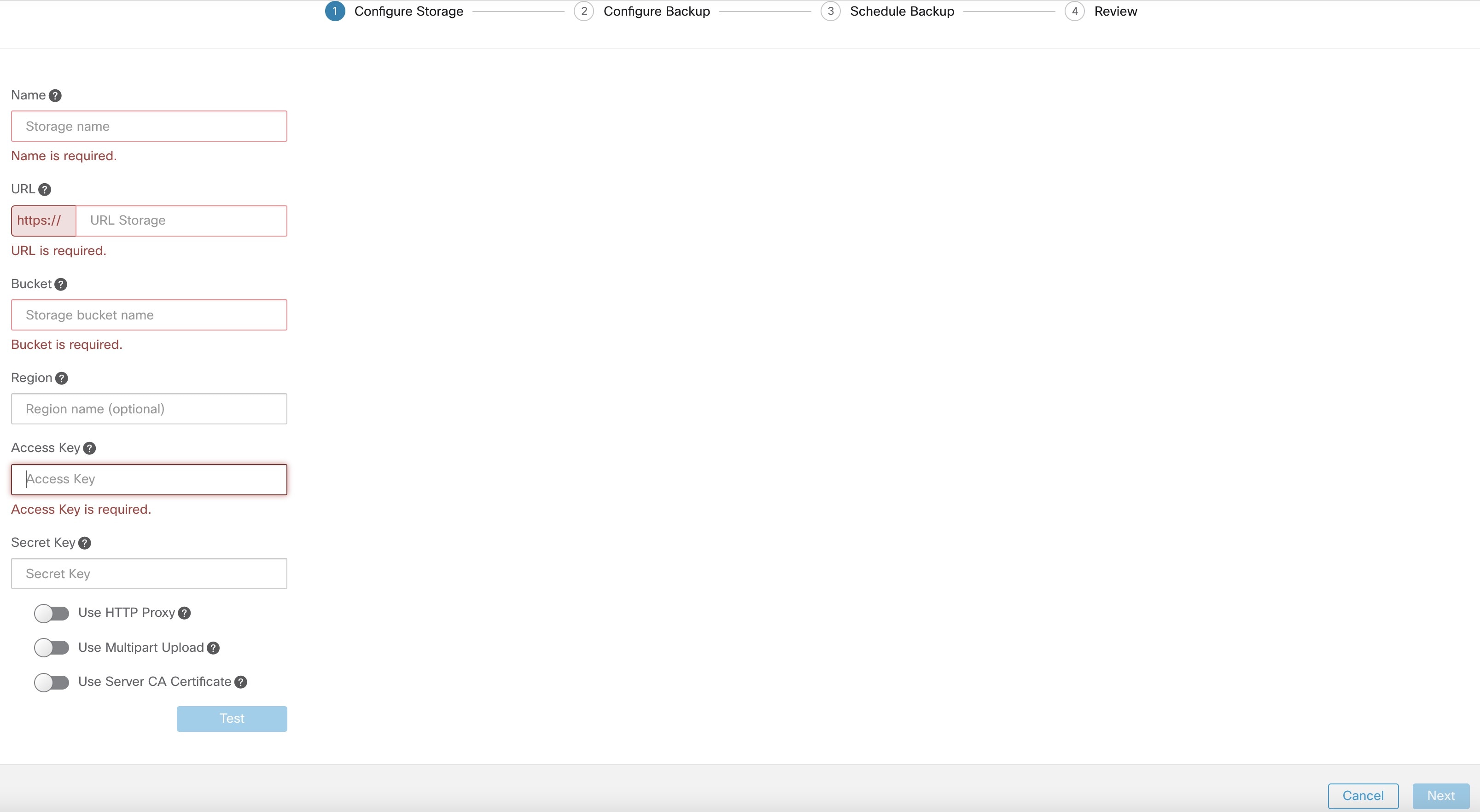
|
||
|
Step 4 |
ストレージ容量を設定するには、次の詳細を入力します。
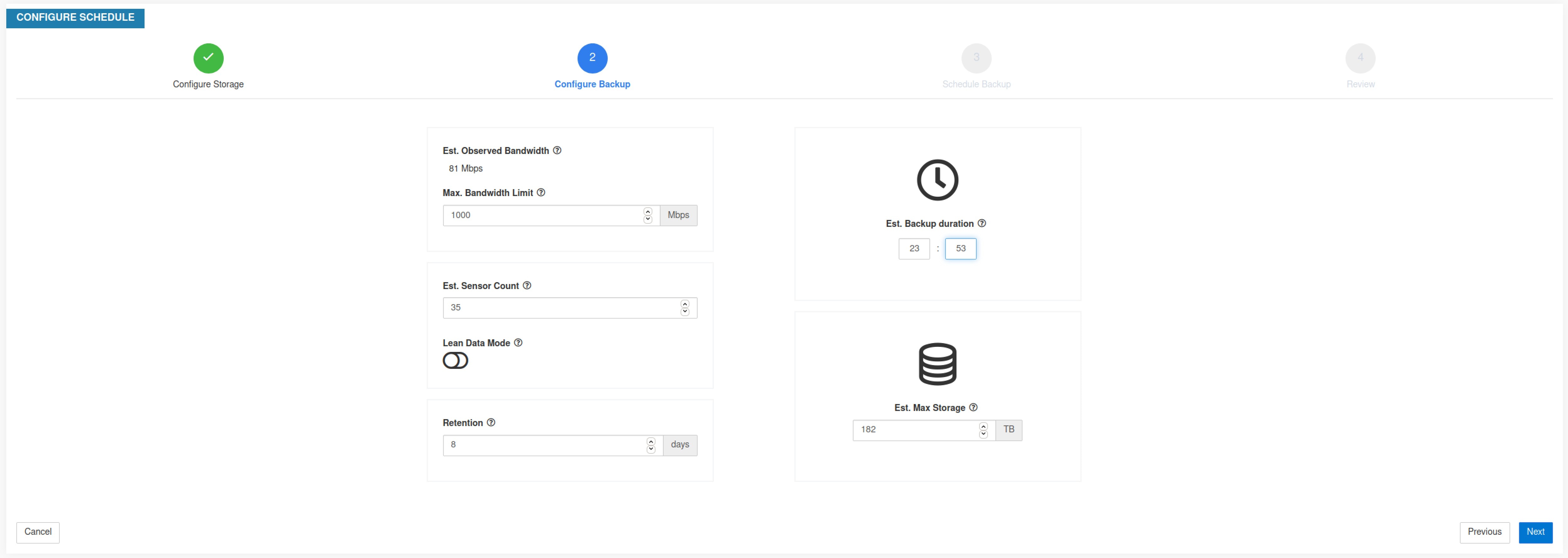
|
||
|
Step 5 |
バックアップをスケジュールするには、以下を有効にします。
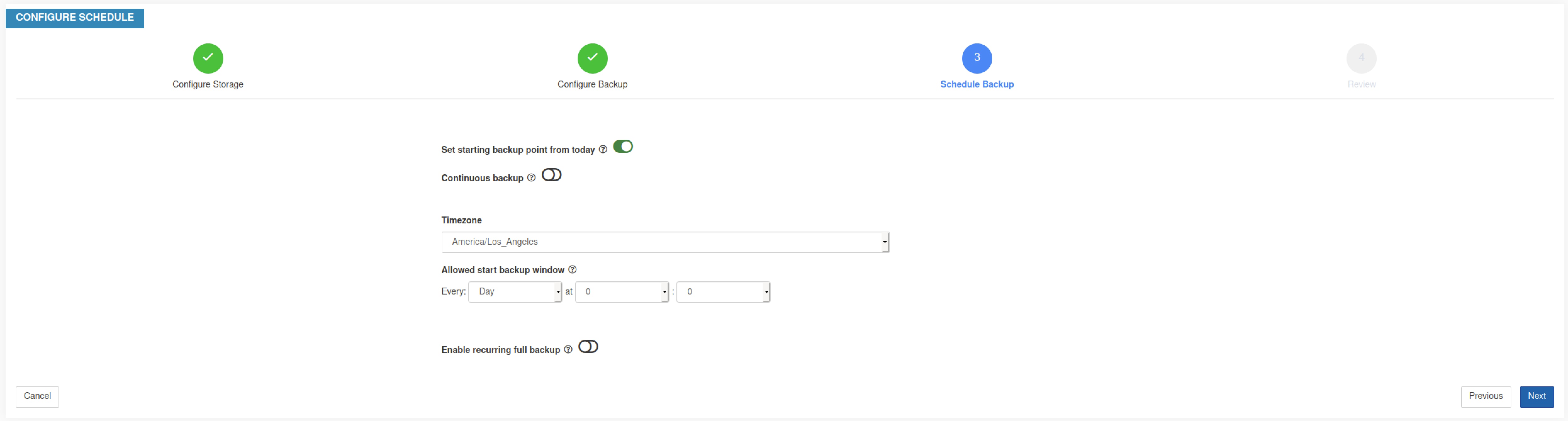
|
||
|
Step 6 |
設定済みのバックアップスケジュールと設定を確認し、[ジョブの開始(Initiate Job)] をクリックします。 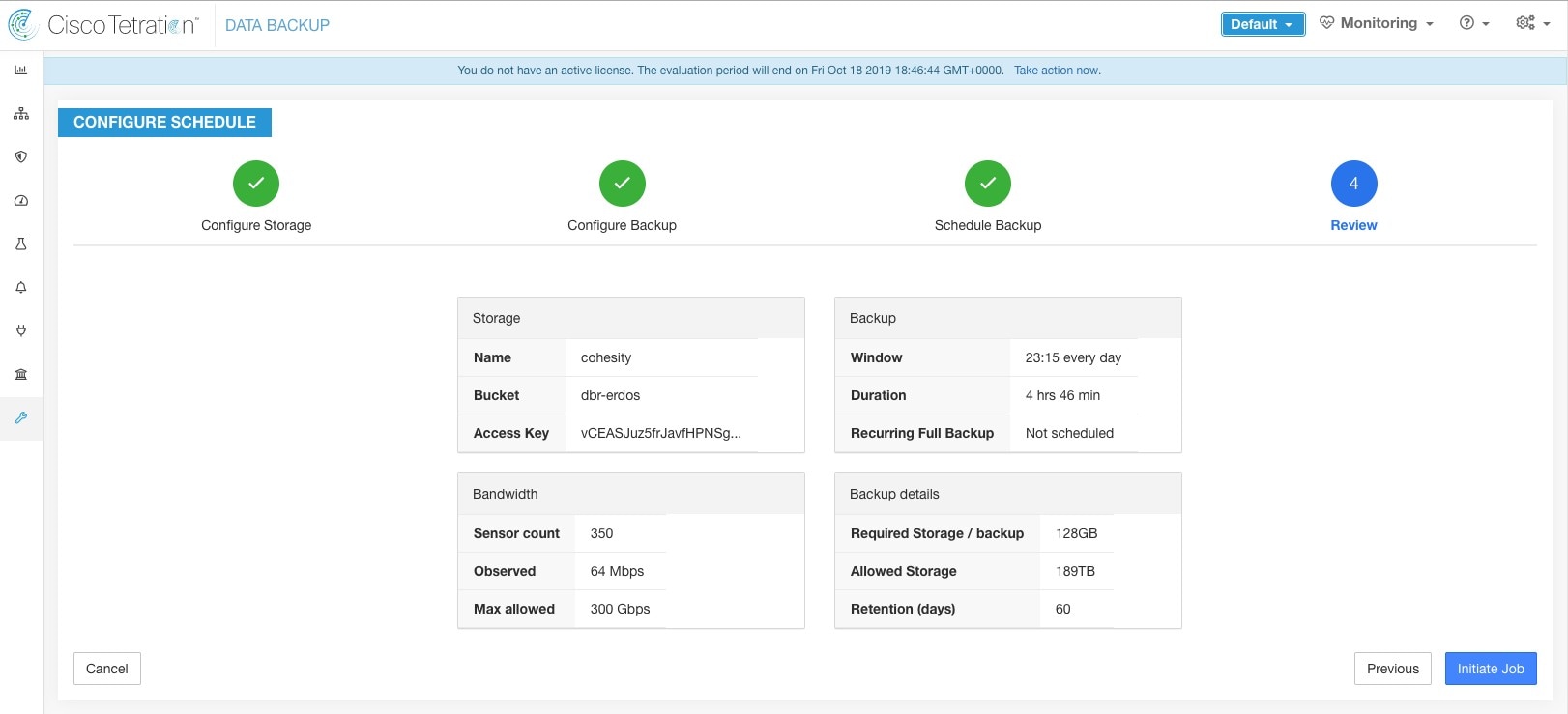
|
データバックアップの設定後は、継続的なモードが有効になっていない限り、スケジュールされた時刻に毎日バックアップがトリガーされます。バックアップのステータスは、 に移動することで、[データバックアップ(Data Backup)] ダッシュボードで確認できます。
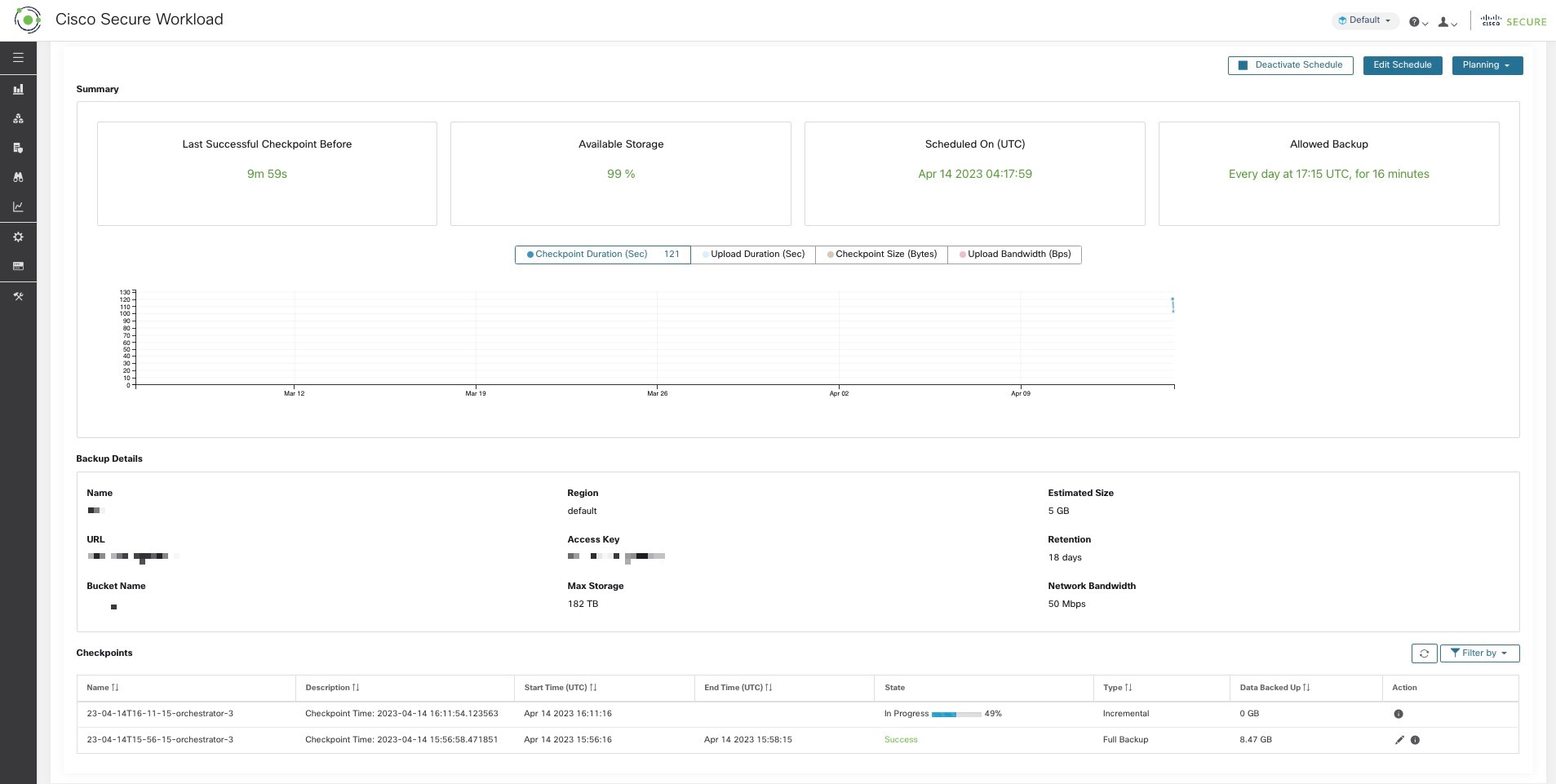
最後に成功したチェックポイントからの経過時間は、チェックポイントにかかる時間と 24 時間を足した時間未満である必要があります。たとえば、チェックポイントとバックアップに約 6 時間かかる場合、最後に成功したチェックポイントからの経過時間は 30 時間未満である必要があります。
次のグラフでは、追加情報を提供します。
[チェックポイント期間(Checkpoint Duration)]:このグラフには、チェックポイントにかかる時間の近似曲線が表示されます。
[アップロード時間(Upload Duration)]:このグラフには、チェックポイントをバックアップにアップロードするためにかかる時間の近似曲線が表示されます。
[チェックポイントサイズ(Checkpoint Size)]:このグラフには、チェックポイントのサイズの近似曲線が表示されます。
[アップロード帯域幅(Upload Bandwidth)]:このグラフには、アップロード帯域幅の近似曲線が表示されます。
この表は、すべてのチェックポイントを示しています。チェックポイントラベルは編集可能で、スタンバイクラスタでデータを復元するためにチェックポイントを選択するときにラベルを使用できます。
チェックポイントは、複数の状態に移行します。使用される状態を以下に示します。
[作成済み/保留中(Created/Pending)]:チェックポイントは作成済みで、コピーされるのを待機しています。
[実行中(Running)]:データが、外部ストレージにアクティブにバックアップされています。
[成功(Success)]:チェックポイントが完了し、成功しました。データ復元に使用できます。
[失敗(Failed)]:チェックポイントは完了しましたが、失敗しました。データ復元には使用できません。
[削除中/削除済み(Deleting/Deleted)]:期限切れのチェックポイントが削除中であるか、削除されました。
スケジュールまたはバケットを変更するには、[スケジュールの編集(Edit Schedule)] をクリックします。ウィザードを完了するには、「データバックアップの設定」の項を参照してください。
チェックポイントの作成中のエラーをトラブルシューティングするには、トラブルシューティング:Data Backup and Restoreを参照してください。
[スケジュールの非アクティブ化(Deactivate Schedule)] ボタンをクリックすることで、バックアップを非アクティブ化できます。スケジュールを変更する前に、バックアップスケジュールを非アクティブ化することをお勧めします。スケジュールを無効にするのは、進行中のチェックポイントがない場合のみにします。チェックポイントの進行中にテストを実行したり、スケジュールを無効にしたりすると、進行中のチェックポイントが失敗し、アップロードが未定義の状態になる可能性があります。
Cisco Secure Workload クラスタは、バケット内のオブジェクトのライフサイクルを管理します。バケットのオブジェクトを削除または追加してはなりません。これを行うと、不整合が発生し、正常なチェックポイントが破損する可能性があります。構成ウィザードで、使用する最大ストレージを指定する必要があります。Cisco Secure Workload は、バケットの使用量が設定された制限内に収まるようにします。オブジェクトをエージアウトしてバケットから削除するストレージ保持サービスがあります。ストレージ使用量は、設定された最大ストレージと受信データレートに基づいて計算されます。保持サービスは、使用量がしきい値(バケット容量の 80%)に達すると、使用量をしきい値未満に減らすために、保存されていないチェックポイントを削除しようとします。また、保持サービスでは、常に最低 2 つの成功したチェックポイントと、保存されたすべてのチェックポイントの、いずれか多い方が維持されます。保持サービスでチェックポイントを削除して容量を空けることができない場合、チェックポイントでエラーが発生し始めます。
バックアップデータを使用して復元するには、クラスタが DBR スタンバイモードになっている必要があります。現在、クラスタは初期設定時にのみスタンバイモードに設定できます。
クラスタがスタンバイモードになったら、ナビゲーションウィンドウから [プラットフォーム(Platform)] を選択して、データ復元オプションにアクセスします。
Cisco Secure Workload は、次の組み合わせをサポートしています。
|
プライマリクラスタ SKU |
スタンバイクラスタ SKU |
|---|---|
|
8RU-PROD |
8RU-PROD、8RU-M5、8RU-M6 |
|
8RU-M5 |
8RU-PROD、8RU-M5、8RU-M6 |
|
39RU-GEN1 |
39RU-GEN1、39RU-M5、39RU-M6 |
|
39RU-M5 |
39RU-GEN1、39RU-M5、39RU-M6 |
|
8RU-M6 |
8RU-PROD、8RU-M5、8RU-M6 |
|
39RU-M6 |
39RU-GEN1、39RU-M5、39RU-M6 |
Note |
データの復元を開始するには、Cisco Technical Assistance Center に連絡します。 |
サイト情報でリカバリオプションを設定することにより、クラスタをスタンバイモードで展開できます。展開中にサイト情報を設定するときに、展開中の設定 UI の [リカバリ(Recovery)] タブで復元の詳細を設定します。
スタンバイクラスタを展開するには 3 つのモードがあり(「スタンバイ展開モード」の項を参照)、3 つすべてのモードで次の設定を行います。
[スタンバイ設定(Standby Config)] を [オン(On)] に設定します。この設定は、一度設定するとクラスタが再展開されるまで変更できません。
プライマリクラスタ名と FQDN を設定します。この設定は後で変更できます。
Note |
Kafka とセンサーの FQDN は、プライマリクラスタと一致する必要があります。一致しない場合、復元プロセスは失敗します。 |
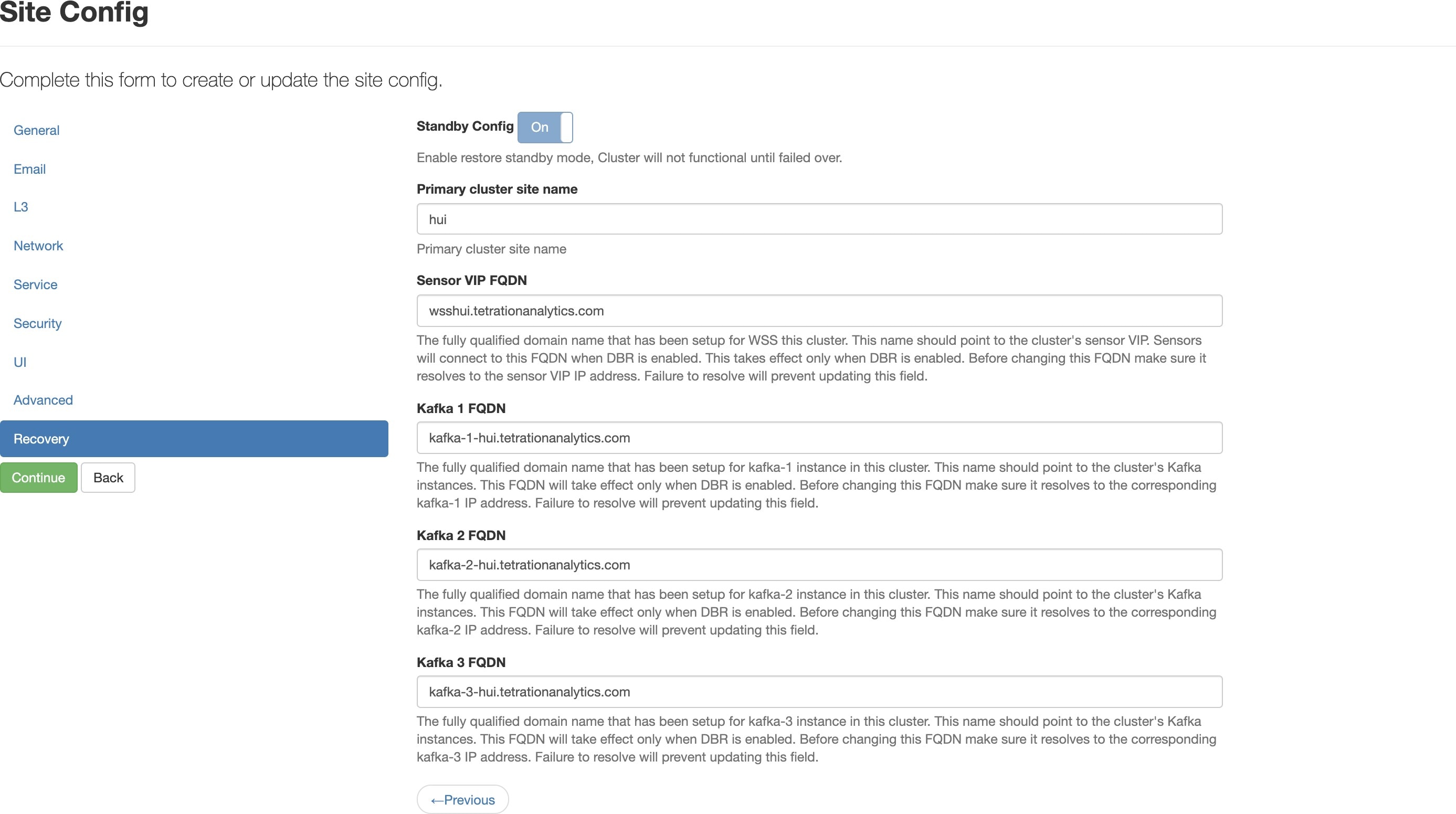
展開の残りの部分は、Cisco Secure Workload クラスタの通常の展開と同じです。
クラスタがスタンバイモードになると、Cisco Secure Workload の UI にバナーが表示されます。
展開後にプライマリクラスタ名と FQDN を再設定して、スタンバイクラスタが別のクラスタを追跡できるようにすることが可能です。この設定は、[クラスタ設定(Cluster Configuration)] ページからフェールオーバーがトリガーされる前に、後で再設定できます。
コールドスタンバイ:スタンバイクラスタはありません。ただし、プライマリクラスタはデータを S3 にバックアップします。災害時には、新しいクラスタ(またはプライマリと同じクラスタ)をプロビジョニングし、スタンバイモードで展開して復元する必要があります。
ウォームスタンバイ:スタンバイクラスタが使用可能であり、スタンバイモードで展開されています。災害発生時に使用できるように、S3 クラスタから定期的に状態を取得し、準備完了状態にします。災害時には、この新しいクラスタにログインして、フェールオーバーをトリガーします。
ルークウォームスタンバイ:複数のプライマリクラスタが、より少ないスタンバイクラスタによってバックアップされます。スタンバイクラスタはスタンバイモードで展開されます。災害発生後にのみ、ストレージバケット情報が設定され、データがプリフェッチされて、クラスタが復元されます。
|
Step 1 |
(オプション)ストレージの詳細をすでに設定している場合は、手順 2 に進みます。S3 ストレージを設定するには、次の詳細を入力します。
|
||||
|
Step 2 |
[テスト(Test)] をクリックして、Cisco Secure Workload クラスタから S3 ストレージにアクセスできるかどうかを確認します。 実行されたテストのステータスがテーブルに表示されます。ストレージへの接続中にエラーが発生した場合は、説明を読み、エラーのトラブルシュートを行って、次の手順に進みます。 |
||||
|
Step 3 |
[次へ(Next)] をクリックします。 |
||||
|
Step 4 |
[事前チェック(Pre-checks)] の下に、Cisco Secure Workload による事前チェックの実行のステータスが表示されます。事前チェックを手動で実行するには、[チェックの実行(Perform Check)] をクリックします。 すべてのチェックのステータスが表示されます。
|
||||
|
Step 5 |
[復元プロセスの開始(Start restore process)] をクリックします。 [復元(Restore)] の下に、実行されたすべてのデータ復元ジョブ、設定された S3 ストレージの詳細、およびデータ復元の事前チェックのステータスが表示されます。 |
||||
|
Step 6 |
[今すぐ復元(Restore now)] をクリックします。 |
||||
|
Step 7 |
確認ダイアログボックスで、チェックボックスをオンにして、エージェントの接続が失われ、データの復元中にデータが失われる可能性があることへの同意を確認します。[確認(Confirm)] をクリックして、データ復元プロセスを開始します。 データ復元プロセスの進捗状況が表示されます。
「復元後プレイブック」の段階の後は、GUI にアクセスでき、すべてのジョブのステータスが更新されます。データが正常に復元されたことを示す確認メッセージが表示されます。 |
設定された FQDN をクラスタ IP アドレスにリダイレクトするように DNS サーバーを更新します。これにより、クラスタフェールオーバーの完了後にソフトウェアエージェントがクラスタと通信できるようになります。
クラスタデータは、次の 2 つのフェーズで復元されます。
必須フェーズ:サービスを再開するために必要なデータが最初に復元されます。必須フェーズにかかる時間は、設定、インストールされているソフトウェアエージェントの数、バックアップされているデータの量、およびフローメタデータによって異なります。必須フェーズ中は、UI にアクセスできません。必須フェーズに UI にアクセスする必要が生じた場合、サポートを受けるにはワーキング TA ゲストキーが必要です。
レイジーフェーズ:クラスタデータ(フローデータを含む)はバックグラウンドで復元され、クラスタの使用はブロックされません。クラスタ UI にアクセスでき、復元の完了率を示すバナーが表示されます。このフェーズ中、クラスタは動作可能であり、データパイプラインは正常に機能し、フロー検索も使用できます。
復元の必須フェーズが完了し、UI にアクセスできるようになったら、クラスタの変更をソフトウェアエージェントに伝達する必要があります。エージェントが使用する DNS サーバーでは、クラスタの FQDN に関連付けられている IP アドレスを更新する必要があり、DNS エントリは復元されたクラスタを指す必要があります。プライマリクラスタへの接続が切断されると、エージェントによって DNS ルックアップがトリガーされます。更新された DNS エントリに基づいて、エージェントは復元されたクラスタに接続します。
この項では、データのバックアップおよび復元ソリューションの目標復旧時間(RTO)と目標復旧時点(RPO)について説明します。
プライマリクラスタで開始されたバックアップは、バックアップされるデータの量とバックアップ設定に応じて、完了するまでに時間がかかります。さまざまなバックアップモードによって、ソリューションの RPO が定義されます。
スケジュールされている場合、継続的でないバックアップが使用され、バックアップは 1 日に 1 回開始されます。災害が発生した場合、失われるデータの最大時間は、約 24 時間 + バックアップストレージにデータをコピーするためにかかる時間です。そのため、RPO は少なくとも 24 時間です。
継続的なモードのバックアップを使用する場合は、新しいバックアップが前のバックアップの 15 分後に開始されます。各バックアップで、作成のために一定の時間がかかり、その後、データをバックアップストレージにアップロードするために一定の時間がかかります。最初のバックアップは完全バックアップで、その後のバックアップは増分バックアップです。増分バックアップにはそれほど時間がかかりません。災害が発生した場合、失われるデータの量は、バックアップの作成にかかった時間と、ストレージへのバックアップのアップロードにかかった時間の合計になります。通常、この場合の RPO は約数分から 1 時間です。
クラスタを復元する場合、まず必須データがストレージからプリフェッチされ、次に必須復元フェーズがトリガーされます。必須復元フェーズ中は、UI を使用できません。必須復元が完了すると、UI を使用できるようになります。残りのデータは、遅延復元フェーズで復元されます。この場合の RTO は、必須フェーズが完了した後、UI が使用可能になるまでにかかる時間です。RTO は、スタンバイ展開モードによって異なります。
コールドスタンバイモード:このモードでは、クラスタを最初に展開する必要があります。これには約数時間かかります。次に、バックアップストレージのログイン情報を使用してクラスタを設定する必要があります。初めてバックアップがスタンバイクラスタにアップロードされるため、取得して処理する必要がある必須データが多数あります。プリフェッチにかかる時間は約数十分です(バックアップされるデータの量によって異なります)。必須復元フェーズが完了するまで約 30 分かかります。まとめると、主にクラスタの起動と展開にかかる時間が原因で、RTO 時間は約数時間になります。
ルーク ウォーム スタンバイ モード:このモードでは、クラスタはすでに展開されていますが、バックアップストレージは設定されていません。バックアップストレージのログイン情報を使用してクラスタを設定する必要があります。初めてバックアップがスタンバイクラスタにアップロードされるため、取得して処理する必要がある必須データが多数あります。プリフェッチにかかる時間は約数十分です(バックアップされるデータの量によって異なります)。必須復元フェーズが完了するまで約 30 分かかります。まとめると、バックアップされるデータの量とバックアップストレージからデータをプルするためにかかる時間に応じて、RTO 時間は約 1 ~ 2 時間になります。
ウォームスタンバイモード:このモードでは、クラスタがすでに展開され、バックアップストレージが設定されていて、プリフェッチによりストレージからデータが取得されています。クラスタはすぐに復元できるようになります。復元により必須復元フェーズがトリガーされ、完了するまで約 30 分かかります。RTO 時間は約 30 分になります。アクティブからストレージにバックアップがアップロードされてから、スタンバイによってバックアップがプルされるまでには、ある程度の遅延が生じることに注意してください。これには約数分かかります。(ディザスタイベントが発生する前に)アクティブから最新のバックアップがスタンバイにプリフェッチされていない場合は、取得されるまで数分間待つ必要があります。
クラスタでデータのバックアップと復元が有効になっている場合は、アップグレードを開始する前にスケジュールを非アクティブ化することを推奨します。「バックアップスケジュールの非アクティブ化」を参照してください。これにより、アップグレードが開始される前に正常なバックアップが存在し、新しいバックアップがアップロードされないことが保証されます。失敗したチェックポイントが作成されることを回避するため、スケジュールの非アクティブ化は、チェックポイントが進行中でないときに実行する必要があります。
ストレージテストが失敗した場合は、右側のペインに表示される障害シナリオを特定し、以下の点を確認します。
S3 準拠のストレージの URL が正しい。
ストレージのアクセスキーと秘密鍵が正しい。
ストレージ上にバケットが存在し、正しいアクセス権限(読み取り/書き込み)が付与されている。
プロキシが設定されている(ストレージに直接アクセスする必要がある場合)。
マルチパート アップロード オプションが無効になっている(Cohesity を使用している場合)。
次の表は、一般的なエラーシナリオと解決策を示したものであり、すべてを網羅したものではありません。
| エラーメッセージ |
シナリオ |
解像度 |
|---|---|---|
|
見つからない(Not found) |
正しくないバケット名 | ストレージに設定されているバケットの正しい名前を入力します。 |
|
SSL接続エラー(SSL connection error) |
SSL 証明書の有効期限または検証のエラー |
SSL 証明書を確認します |
|
無効な HTTPS URL |
|
|
|
接続がタイムアウトしました(Connection that is timed out) |
S3 サーバーの IP アドレスに到達できません |
クラスタと S3 サーバーの間のネットワーク接続を確認します |
|
URLに接続できません(Unable to connect to URL) |
正しくないバケットリージョン |
正しいバケットのリージョンを入力します |
|
無効な URL |
S3 ストレージエンドポイントの正しい URL を再入力します |
|
|
Forbidden |
無効な秘密鍵 |
ストレージの正しい秘密鍵を入力します |
|
無効なアクセスキー |
ストレージの正しいアクセスキーを入力します |
|
|
S3設定を確認できません(Unable to verify S3 configuration) |
その他の例外または一般的なエラー |
しばらくしてから S3 ストレージの設定を試みます |
次の表は、チェックポイントの一般的なエラーコードを示したものであり、すべてを網羅したものではありません。
|
エラーコード |
説明 |
|---|---|
|
E101:DBのチェックポイントの失敗(E101: DB checkpoint failure) |
Mongodb oplog のスナップショットを取得できません |
|
E102:フローデータのチェックポイントの失敗(E102: Flow data checkpoint failure) |
Druid データベースのスナップショットを取得できません |
|
E103:DBスナップショットのアップロードの失敗(E103: DB snapshot upload failure) |
Mongo DB スナップショットをアップロードできません |
|
E201:DBのコピーの失敗(E201: DB copy failure) |
Mongo スナップショットを HDFS にアップロードできません |
|
E202:設定のコピーの失敗(E202: Config copy failure) |
Consul-Vault スナップショットを HDFS にアップロードできません |
|
E203:設定のチェックポイントの失敗(E203: Config checkpoint failure) |
consul-vault データのチェックポイントを実行できません |
|
E204:チェックポイント中の設定データの不一致(E204: Config data mismatch during checkpoint) |
最大再試行回数後に consul/vault チェックポイントを生成できません |
|
E301:バックアップデータのアップロードの失敗(E301: Backup data upload failure) |
HDFS チェックポイントの失敗 |
|
E302:チェックポイントのアップロードの失敗(E302: Checkpoint upload failure) |
Copydriver が S3 にデータをアップロードできませんでした |
|
E401:チェックポイント中のシステムアップグレード(E401: System upgrade during checkpoint) |
このチェックポイント中にクラスタがアップグレードされました。チェックポイントは使用できません |
|
E402:チェックポイント中のサービスの再起動(E402: Service restart during checkpoint) |
Bkpdriver が作成状態で再起動しました。チェックポイントは使用できません |
|
E403:前のチェックポイントの失敗(E403: Previous checkpoint failure) |
前回の実行でチェックポイントが失敗しました |
|
E404:別のチェックポイントが進行中(E404: Another checkpoint in progress) |
別のチェックポイントが進行中です |
|
E405:チェックポイントを作成できない(E405: Unable to create checkpoint) |
チェックポイントのサブプロセスでエラーが発生しました |
|
失敗:完了(Failed: Completed) |
先行するチェックポイントの一部が失敗しました。同時に開始する複数のチェックポイントが重複している可能性があります |
ストレージ構成フェーズ:S3 ストレージ構成時のエラーのトラブルシューティングに推奨される解決策については、「S3 構成チェックのエラーシナリオ」を参照してください。
セカンダリクラスタの正常性を確認するための事前チェック:正常ではないサービスまたは警告があるサービスの場合は、[サービスステータス(Service Status)] ページに移動して、サービスを正常にレンダリングするための詳細情報を確認します。
ストレージへの接続を確認するための事前チェック:
|
エラーシナリオ |
説明 |
|---|---|
|
構成された S3 ストレージからデータをダウンロードできない。 |
ネットワーク接続が原因で、S3 ストレージへのアクセスに失敗しました。接続が復元され、新しいチェックポイントが S3 ストレージからプリフェッチされるまで、エラーメッセージが表示されます。 |
|
セカンダリ(バックアップ)クラスタ SKU がプライマリクラスタと互換性がない。 |
39 RU から別の 39 RU クラスタにのみデータを復元していることを確認します。8 RU クラスタデータは 8 RU クラスタにのみ復元できます。 |
|
セカンダリ(バックアップ)クラスタのバージョンがプライマリと異なっている。 |
プライマリクラスタとセカンダリクラスタで同じバージョンが実行されていることを確認します。 |
|
MongoDB の復元に失敗する。 |
MongoDB メタデータを復元できません。この問題は、次のチェックポイント プリフェッチ時に修正されます。 |
|
DBRInfo マニュアルの形式が不明である。 |
S3 ストレージ内のチェックポイントメタデータが破損しているか、マニュアルが間違ったストレージにあります。S3 ストレージから dbrinfo.json ファイルをダウンロードし、確認のために Cisco TAC と共有します。 |
|
コピーサービスと同期できない。 |
データ復元マネージャと S3 コピーサービスの間で内部エラーが発生しました。問題のトラブルシューティングについては、Cisco TAC にお問い合わせください。 |
FQDN 事前チェック:FQDN 事前チェックに対して警告サインが表示された場合、FQDN の DNS エントリがセカンダリクラスタを指していません。
解決策:データを復元後、DNS エントリを変更して、ソフトウェアエージェントとセカンダリクラスタ間の接続を有効にします。
データ復元フェーズ:データ復元の確認ダイアログボックスで、外部オーケストレータのチェックボックスに緑色のチェックマークが付いていない場合は、セカンダリクラスタと外部オーケストレータ間の接続を確認します。
Note |
データが復元され、セカンダリクラスタがプライマリ状態になっても、[データ復元(Data Restore)] ページは引き続き使用でき、復元の所要時間と再接続したエージェントの数を確認できます。データが復元されないクラスタの場合、[データ復元(Data Restore)] ページは空白になります。 |
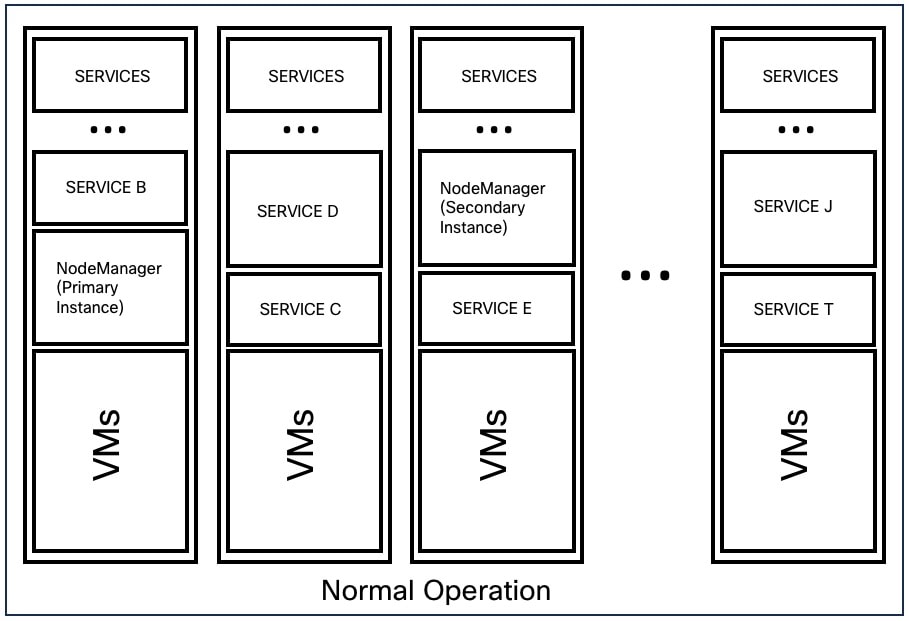
Cisco Secure Workload は、サービス、ノード、および VM に障害が発生する可能性がある場合に高可用性を提供します。高可用性では、ダウンタイムを最小限に抑え、サイト管理者による介入を最小限に抑えることで、リカバリ方法が提供されます。
Cisco Secure Workload では、サービスはクラスタのノード全体に分散されます。サービスの複数のインスタンスがノード間で同時に実行されます。プライマリインスタンスと 1 つ以上のセカンダリインスタンスは、複数のノード間で高可用性を実現するように設定されます。サービスのプライマリインスタンスに障害が発生すると、サービスのセカンダリインスタンスがプライマリとしてレンダリングされ、すぐにアクティブになります。
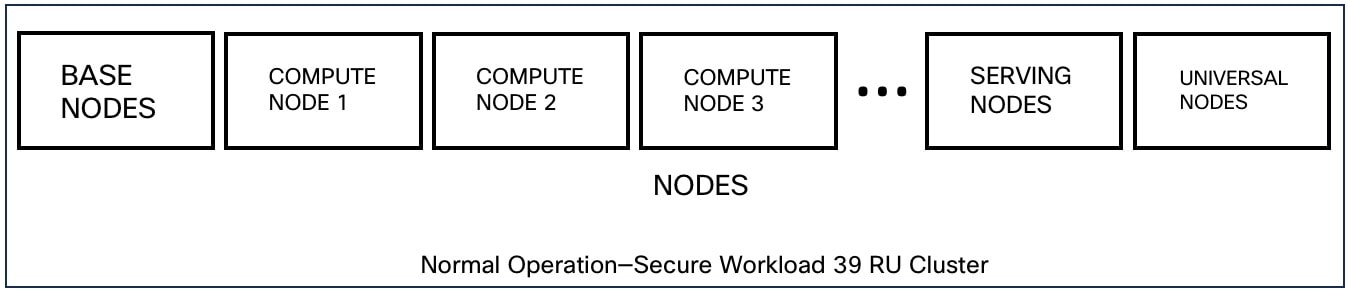
Cisco Secure Workload クラスタの主要コンポーネントは次のとおりです。
複数の VM をホストし、多くのサービスをホストするベアメタルサーバー。
Cisco UCS C シリーズ ラックサーバーと Cisco Nexus 9300 シリーズ スイッチは、統合された高性能ネットワークに貢献します。
特定の数のワークロードをサポートする小型または大型フォームファクタのハードウェアベースのアプライアンスモデル:
6 台のサーバーと 2 台の Cisco Nexus 9300 スイッチを使用した小型フォームファクタの導入。
36 台のサーバーと 3 台の Cisco Nexus 9300 スイッチを使用した大型フォームファクタの導入。
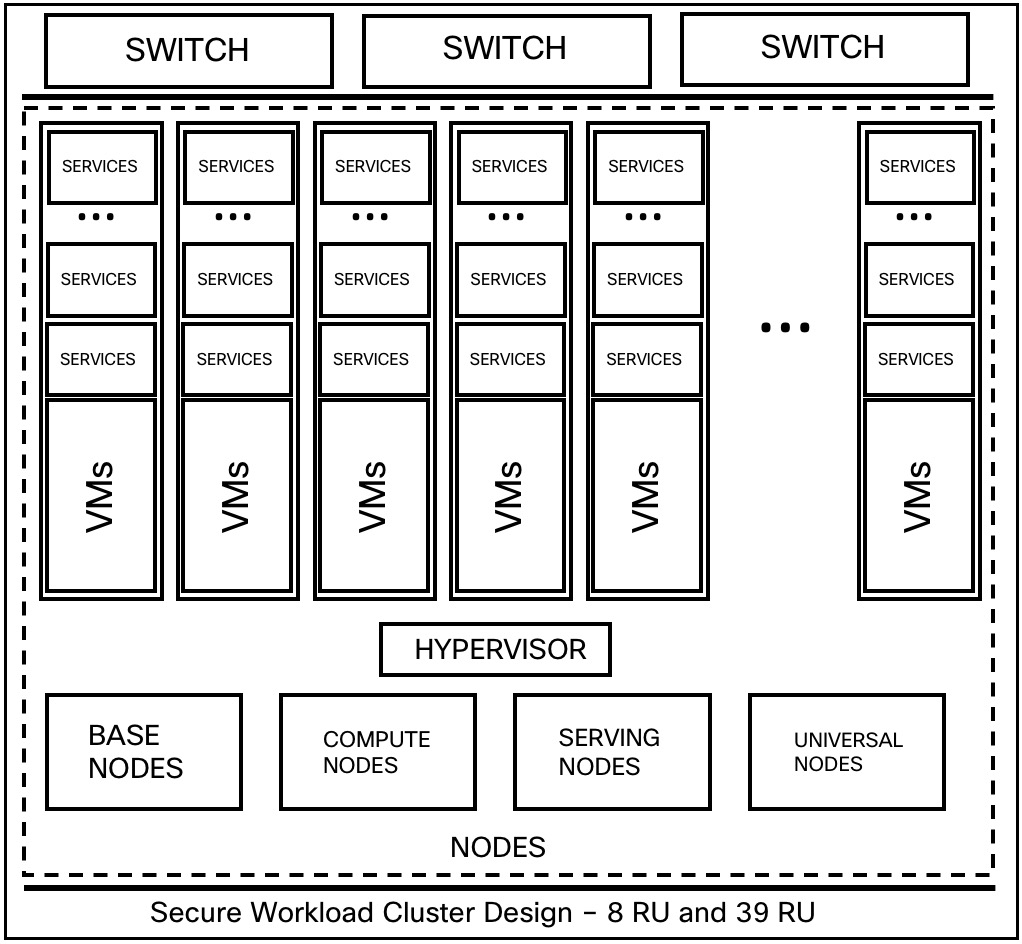
|
属性/フォームファクタ |
8 RU |
39 RU |
|---|---|---|
|
ノード数 |
6 |
36 |
|
コンピューティングノードの数 |
— |
16 |
|
ベースノードの数 |
— |
12 |
|
サービス提供ノードの数 |
— |
8 |
|
ユニバーサルノードの数 |
6 |
— |
|
VM の数 |
50 |
106 |
|
コレクタの数 |
6 |
16 |
|
ネットワークスイッチの数 |
2 |
3 |
Cisco Secure Workload リリース 3.9.x 以降では、クラスタの両方のフォームファクタ(8RU と 39RU)で、Hadoop NameNode VM をホストしているノードに障害が発生した場合、セカンダリ NameNode VM にフェールオーバーするために手動での操作は必要ありません。
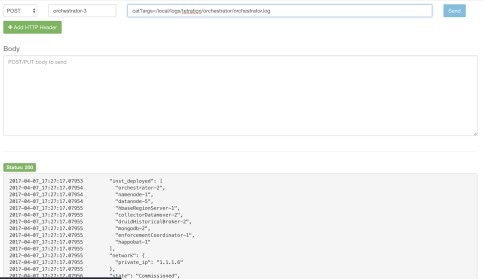
アップグレード前のチェックで、namenode-1 がアクティブではないか正常な状態ではないことが示された場合は、UPGRADE または REBOOT を実行する前に、手動での操作が必要です。この場合は、エクスプローラページから、launcherHost-1.node.consul(または動作中のいずれかの launcherHosts)に対して POST namenode_failover を実行する必要があります。
Note |
Cisco Secure Workload リリース 3.8.x 以前では、フェールオーバーは自動的に実行されません。 |
オーケストレータ、Redis、MongoDB、Elasticsearch、enforcementpolicystore、AppServer、ZooKeeper、TSDB、Grafana などの 2 VM または 3 VM サービスの場合、1 つの VM 障害のみがサポートされます。2 番目の VM に障害が発生すると、サービスは非アクティブルーティング
どの時点でも、クラスタの動作に影響はありません。
シングルポイント障害はありません。クラスタ内のいずれかのノードや VM に障害が発生しても、クラスタ全体の障害にはなりません。
サービス、ノード、または VM による障害からの回復には、最小限のダウンタイムが発生します。
ソフトウェアエージェントによって維持される Cisco Secure Workload クラスタへの接続には影響はありません。エージェントは、クラスタの使用可能なすべてのコレクタと通信します。コレクタまたは VM に障害が発生した場合、ソフトウェアエージェントとコレクタの他のインスタンスとの接続により、データフローは中断されず、機能は失われません。
クラスタサービスは、外部オーケストレータと通信します。サービスのプライマリインスタンスに障害が発生すると、セカンダリインスタンスが引き継ぐため、外部オーケストレータとの通信は失われません。
高可用性では、次の障害シナリオがサポートされます。
サービスの障害
VM の障害
ノード障害
ネットワークスイッチの障害
ノードのサービスで障害が発生すると、そのサービスの別インスタンスが、障害が発生したサービスの機能を取得し、実行を継続します。
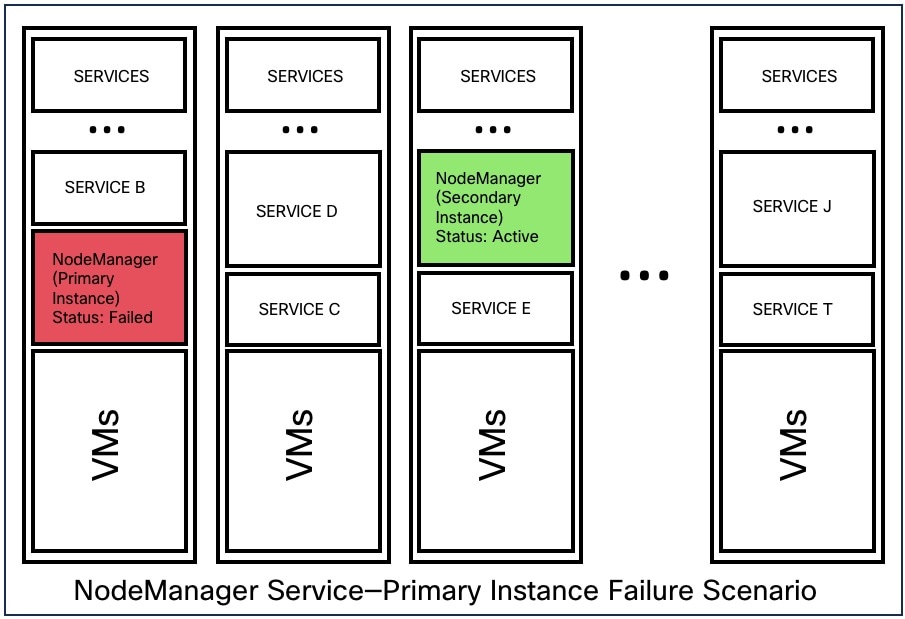
|
Impact |
目に見える影響はありません。 |
|
リカバリ |
|
VM の 1 つに障害が発生すると、セカンダリ VM が使用可能になります。セカンダリ VM のサービスが、障害が発生した VM が実行していたサービスを引き継ぎます。その間、Cisco Secure Workload が障害が発生した VM を再起動して回復します。たとえば、図:VM の障害シナリオに示されているように、VM(このインスタンスでは VM1)に障害が発生すると、その VM で実行されているサービスでも障害が発生します。セカンダリ VM は引き続き動作し、セカンダリインスタンスが、障害が発生した VM が実行していたサービスを引き継ぎます。
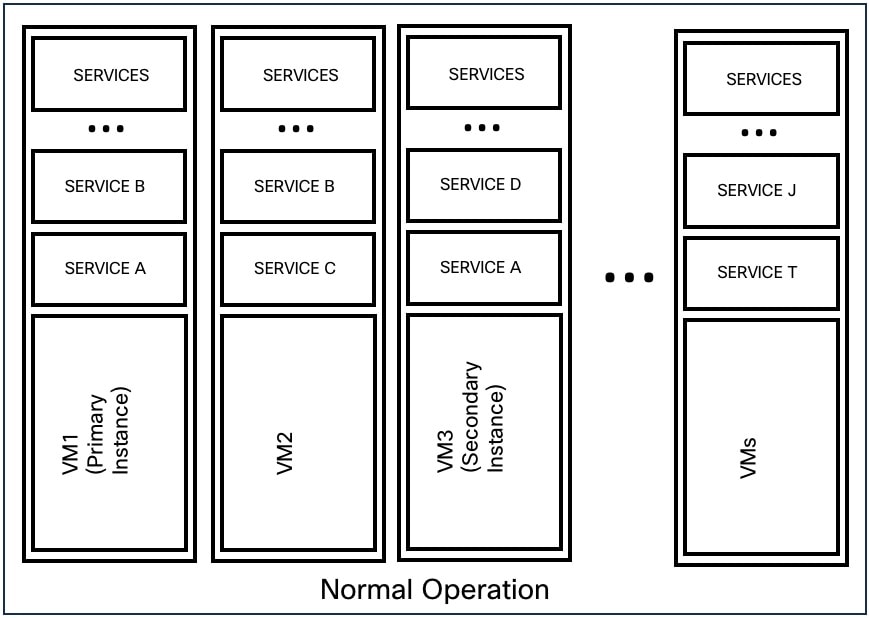
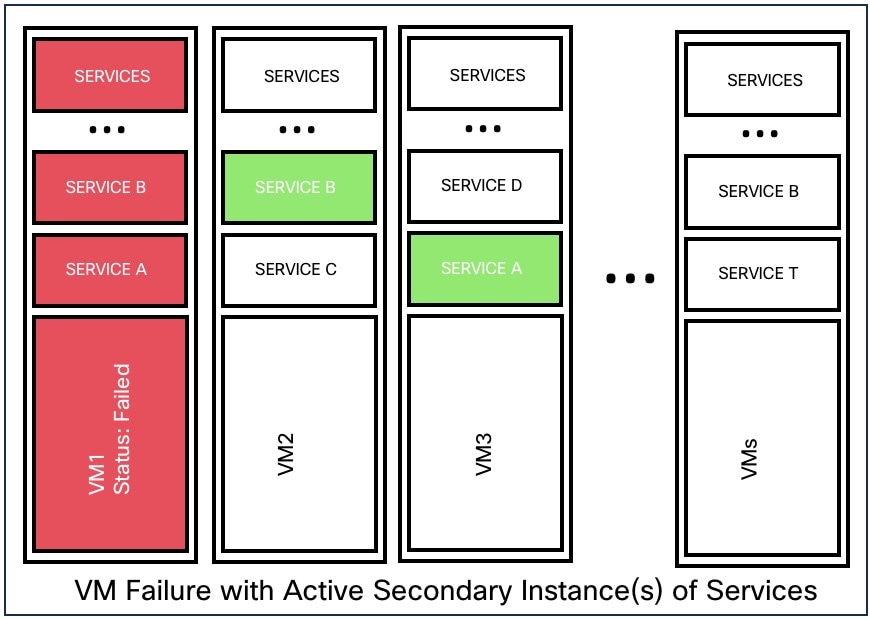
CollectorDataMover、DataNode、NodeManager、druidHistoricalBroker VM などの対称 VM によって提供されるサービスの場合、複数の VM で障害が発生する可能性がありますが、アプリケーションはキャパシティを減らして機能し続けます。
|
サービス タイプ(Service Type) |
VM の総数 |
サポートされる VM 障害の数 |
|---|---|---|
|
DataNode |
6 |
4 |
|
DruidHistorical |
4 |
2 |
|
CollectorDataMover |
6 |
5 |
|
NodeManager |
6 |
4 |
|
UI/AppServer |
2 |
1 |
Note |
非対称 VM タイプでは、対応するサービスが使用できなくなる前に、1 つの VM 障害のみ許容されます。 |
|
Impact |
目に見える影響はありません。 |
|
リカバリ |
|
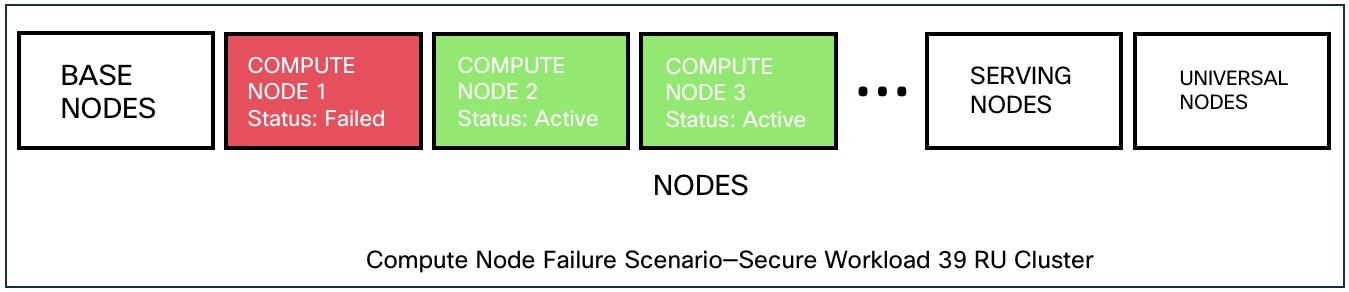
|
ノード障害 |
8 RU |
39 RU |
|---|---|---|
|
高可用性のために許容されるノード障害の数 |
1 |
1* |
* 39 RU クラスタでは、単一ノード障害は常に許容されます。障害が発生した 2 つのノードがオーケストレータ、Redis、MongoDB、Elasticsearch、enforcementpolicystore、AppServer、ZooKeeper、TSDB、Grafana などの 2 VM または 3 VM サービスの VM をホストしていない限り、2 番目のノード障害が許可される場合があります。一般に、2 番目のノード障害が発生すると、2 つの VM が影響を受けるため、重要なサービスが使用できなくなります。
 Caution |
2 番目のノード障害が発生すると、機能停止する可能性が高いため、障害が発生したノードをすぐに復元することを推奨します。 |
|
Impact |
クラスタの機能には影響しません。ただし、Cisco Technical Assistance Center に連絡して、障害が発生したノードをただちに交換してください。2 番目のノードで障害が発生すると、機能停止する可能性が高くなります。 |
|
リカバリ |
|
Cisco Secure Workload のスイッチは常にアクティブままです。8RU フォームファクタ展開では、スイッチに障害が発生しても影響はありません。39RU フォームファクタ展開では、スイッチに障害が発生した場合、クラスタの入力キャパシティは半分になります。
Note |
Cisco Secure Workload クラスタのスイッチには、パブリックネットワークの VPC 設定をサポートするための推奨のポート密度はありません。 |
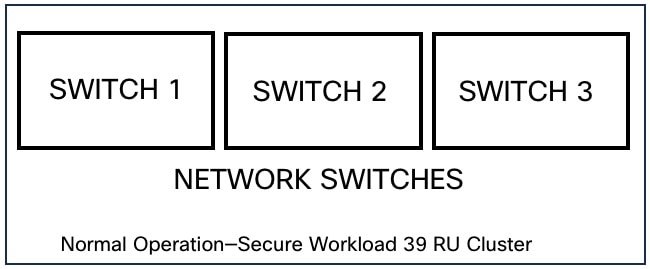
|
フォーム ファクタ |
8 RU |
39 RU |
||||
|---|---|---|---|---|---|---|
|
高可用性のために許容されるスイッチ障害の数 |
1
|
1
|
|
Impact |
|
|
リカバリ |
|
[トラブルシューティング(Troubleshoot)] メニューの [仮想マシン(Virtual Machine)] ページには、Cisco Secure Workload クラスタの一部であるすべての仮想マシンが表示されます。クラスタの起動またはアップグレード(あれば)中の展開ステータス、さらにパブリック IP も表示されます。クラスタ内のすべての VM はパブリックネットワークの一部ではないため、パブリック IP を持たない場合があることに注意してください。
Secure Workload は、フルアップグレードとパッチアップグレードの 2 種類のアップグレードをサポートしています。ここでは、フルアップグレードプロセスについて説明します。フルアップグレード中に、クラスタ内のすべての VM がシャットダウンされ、新しい VM が展開され、サービスが再プロビジョニングされます。クラスタ内のすべてのデータは、アップグレード中のダウンタイムを除き、このアップグレード中に保持されます。
アップグレードを開始するには、ナビゲーション バーで の順に選択します。クラスタのアップグレード、パッチアップグレード、シャットダウン、または再起動ができます。
Secure Workload クラスタでサポートされているアップグレードの種類
フル アップグレード(Full Upgrade):フルアップグレードを開始するには、ナビゲーションウィンドウから の順に選択します。[アップグレード(Upgrade)] タブで、[アップグレード(Upgrade)] を選択します。完全なアップグレードプロセス中に、VM の電源がオフになり、VM がアップグレードされて再展開されます。クラスタのダウンタイムが発生し、その間、Secure Workload UI にはアクセスできません。
パッチアップグレード:パッチアップグレードでは、クラスタのダウンタイムが最小限に抑えられます。パッチを適用する必要があるサービスが更新され、VM は再起動しません。ダウンタイムは通常、数分程度です。パッチアップグレードを開始するには、[パッチアップグレード(Patch Upgrade)] を選択し、[パッチアップグレードリンクの送信(Send Patch Upgrade Link)] をクリックします。
[アップグレード リンクの生成(Generate Upgrade Link)]を有効にする前に、次の必須の事前チェックが完了していることを確認してください。
UI 管理者のユーザー名が存在します
UI 管理者のカスタマー サポート ユーザー名が存在します
UI 管理者ユーザー名のリカバリ コードが存在します
すべての事前チェックが承認されると、アップグレード リンクとトークンが UI に表示されます。
Note |
事前チェックのいずれかが失敗した場合、アップグレード リンクとトークンは生成されません。 |
オーケストレータは電子メールを送信する前に、いくつかの検証チェックを実行して、クラスタがアップグレード可能であることを確認します。検証チェックの内容は次のとおりです。
[デコミッション済み(Decommissioned)] のノードがないことを確認します。
各ベアメタルをチェックして、以下のようなハードウェア障害がないことを確認します。
ドライブの障害
ドライブの予測可能な障害
ドライブの欠落
StorCLI の障害
MCE ログエラー
ベアメタルがコミッション状態であることを確認します。39RU の場合は 36 台、8RU の場合は 6 台以上のサーバーが必要です。
Note |
障害がある場合は、登録された電子メールアドレスにアップグレードリンクが送信されず、HW 障害やホストの欠落などの情報とともに 500 エラーが表示されるので、オーケストレータログで詳細を確認します。このシナリオでは、ホストの orchestrator.service.consul にある /local/logs/tetration/orchestrator/orchestrator.log で、最後の 100 個のエラーメッセージを確認できます。ログには、3 つの中で障害の原因であるチェックに関する詳細情報が提供されます。通常はハードウェアの修正とノードの再稼働が必要になります。アップグレード プロセスを再開します。 |
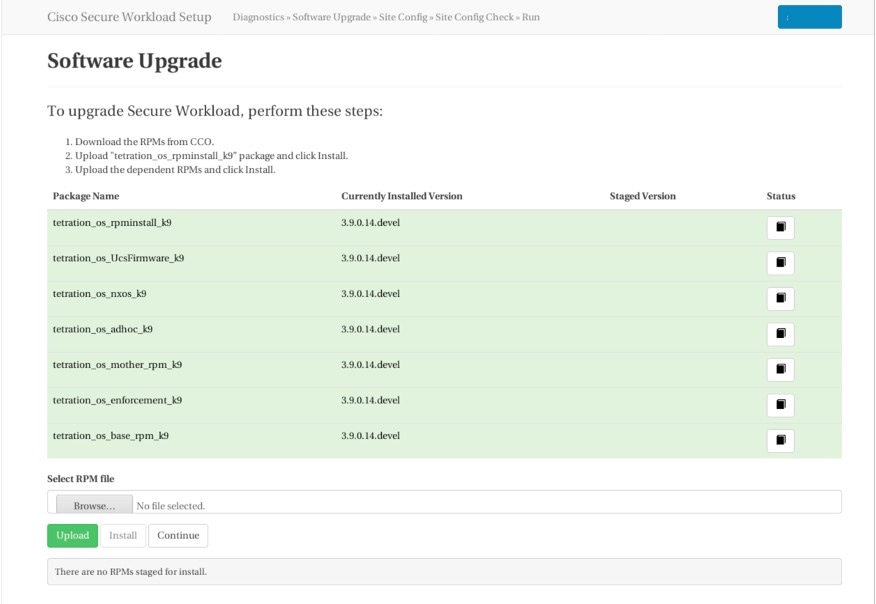
電子メールで受信したアップグレードリンクをクリックすると、[Cisco Secure Workloadのセットアップ(Secure Workload Setup)] ページが表示されます。セットアップ UI は、クラスタの展開またはアップグレードに使用されます。ランディングページには、現在クラスタに展開されている RPM のリストが表示されます。RPM をアップロードしてクラスタをアップグレードできます。
Note |
vSphere に展開された Secure Workload 仮想クラスタの場合は、必ず tetration_os_ova_k9 RPM もアップグレードしてください。tetration_os_base_rpm_k9 RPM はアップロードしないでください。 |
RPM をアップロードするには、次の手順を実行します。
[ソフトウェアのダウンロード(Software Download)]https://software.cisco.com/download/home/286309796/typeページから、展開に適した RPM をダウンロードします。
tetration_os_rpminstall_k9 RPM をアップロードし、[インストール(Install)] をクリックします。
他の依存 RPM をアップロードし、RPM のインストール済みバージョンとステージング済みバージョンを確認します。
[インストール(Install)] をクリックして、ステージング済み RPM ファイルをインストールします。
RPM が正常にアップロードされたら、[続行(Continue)] をクリックしてアップグレードを続行します。
詳細な手順については、『Cisco Secure Workload Upgrade Guide』を参照してください。
クラスタをアップグレードする際の次の手順は、サイト情報を更新することです。すべてのサイト情報フィールドが更新可能というわけではありません。次のフィールドのみを更新できます。
SSH 公開キー
Sentinel アラート電子メール(Bosun 用)
CIMC 内部ネットワーク
CIMC 内部ネットワークゲートウェイ
外部ネットワーク
Note |
既存の外部ネットワークは変更しないでください。既存のネットワークに付加することで、さらにネットワークを追加できます。既存のネットワークを変更または削除すると、クラスタが使用できなくなります。 |
DNS リゾルバ
DNS ドメイン
NTP サーバ
SMTPサーバ
SMTPポート
SMTP ユーザー名(オプション)
SMTP パスワード(オプション)
Syslog サーバー(オプション)
Syslog ポート(オプション)
Syslog シビラティ(重大度)(オプション)
Note |
|
残りのフィールドは更新できません。変更がない場合は、[続行(Continue)] をクリックしてアップグレード前のチェックをトリガーします。変更がある場合は、フィールドを更新して [続行(Continue)] をクリックします。
クラスタをアップグレードする前に、クラスタでいくつかのチェックが実行され、正常であることが確認されます。次のアップグレード前チェックが実行されます。
RPM バージョンチェック:すべての RPM がアップロードされ、バージョンが正しいことが確認されます。順序の正しさはチェックされず、アップロードされているかチェックされるだけです。順序のチェックは、アップロード自体の一部として実行されます。
サイトリンター:サイト情報のリンティングが実行されます。
スイッチ設定:リーフまたはスパインスイッチが設定されます。
サイトチェッカー:DNS、NTP、および SMTP サーバーのチェックを行います。トークン付きの電子メールを送信します。このメールは、プライマリサイトの管理者アカウントに送信されます。DNS、NTP、または SMTP のいずれかのサービスが使用できない場合、この手順は失敗します。
トークンの検証:電子メールで送信されたトークンを入力し、アップグレードプロセスを続行します。
Caution |
|
|
Step 1 |
[続行(Continue)] をクリックして、アップグレードを開始します。 |
|
Step 2 |
(オプション)クラスタ名をクリックして、サイト情報を表示します。 |
次のボタンを更新します。
[更新(Refresh)]:ページを更新します。
[詳細(Details)]:[詳細(Details)] をクリックすると、アップグレード中に完了したすべてのステップが表示されます。ログを表示するには、その横にある矢印をクリックします。
[リセット(Reset)]:オーケストレータの状態をリセットするオプションがあります。このオプションを選択すると、アップグレードがキャンセルされて、最初に戻ります。アップグレードに失敗した場合を除き、このボタンは使用しないでください。また、アップグレードが失敗した後、すべてのプロセスが完了し、アップグレード再開されるまで数分かかります。
[再起動(Restart)]:アップグレードが失敗した場合は、[再起動(Restart)] をクリックしてクラスタを再起動し、新しいアップグレードを開始します。これは、保留中のクリーンアップ操作や、アップグレードプロセスをブロックしている可能性のある問題を解決するのに役立ちます。
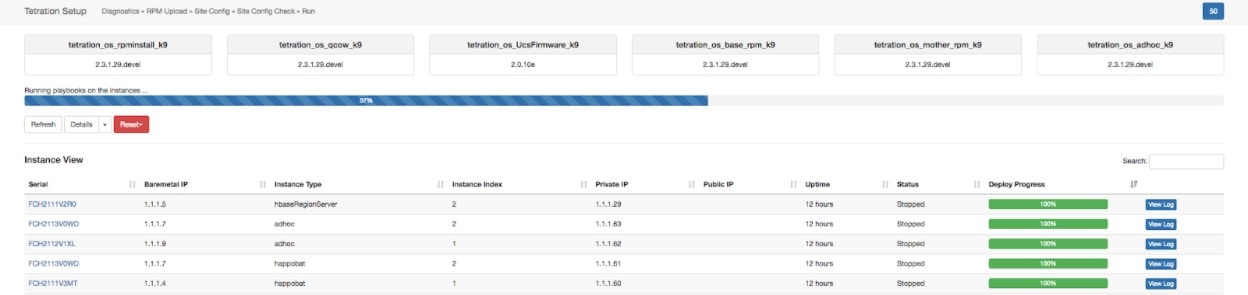
インスタンスビューでは、個々の VM の展開ステータスがすべて追跡されます。インスタンスビューは次の列で構成されます。
[シリアル(Serial)]:この VM をホストするベアメタルのシリアル番号
[ベアメタルIP(Baremetal IP)]:このベアメタルに割り当てられている内部 IP
[インスタンスタイプ(Instance Type)]:VM のタイプ
[インスタンスインデックス(Instance Index)]:VM のインデックス - 高可用性向けに同じタイプの VM が複数あります。
[プライベートIP(Private IP)]:この VM に割り当てられた内部 IP
[パブリックIP(Pubic IP)]:この VM に割り当てられたルーティング可能な IP - すべての VM にあるわけではありません。
[稼働時間(Uptime)]:VM の稼働時間
[ステータス(Status)]:[停止(Stopped)]、[展開(Deployed)]、[失敗(Failed)]、[未開始(Not Started)]、または [進行中(In Progress)]。
[展開の進行状況(Deploy Progress)]:展開の進行割合
[ログの表示(View Log)]:VM の展開ステータスを表示するためのボタン
ログには次の 2 種類があります。
|
Step 1 |
VM 展開ログ:VM 展開ログを表示するには、[ログの表示(View Log)] をクリックします。 |
|
Step 2 |
オーケストレーションログ:オーケストレーションログを表示するには、[詳細(Details)] ボタンの横にある矢印をクリックします。 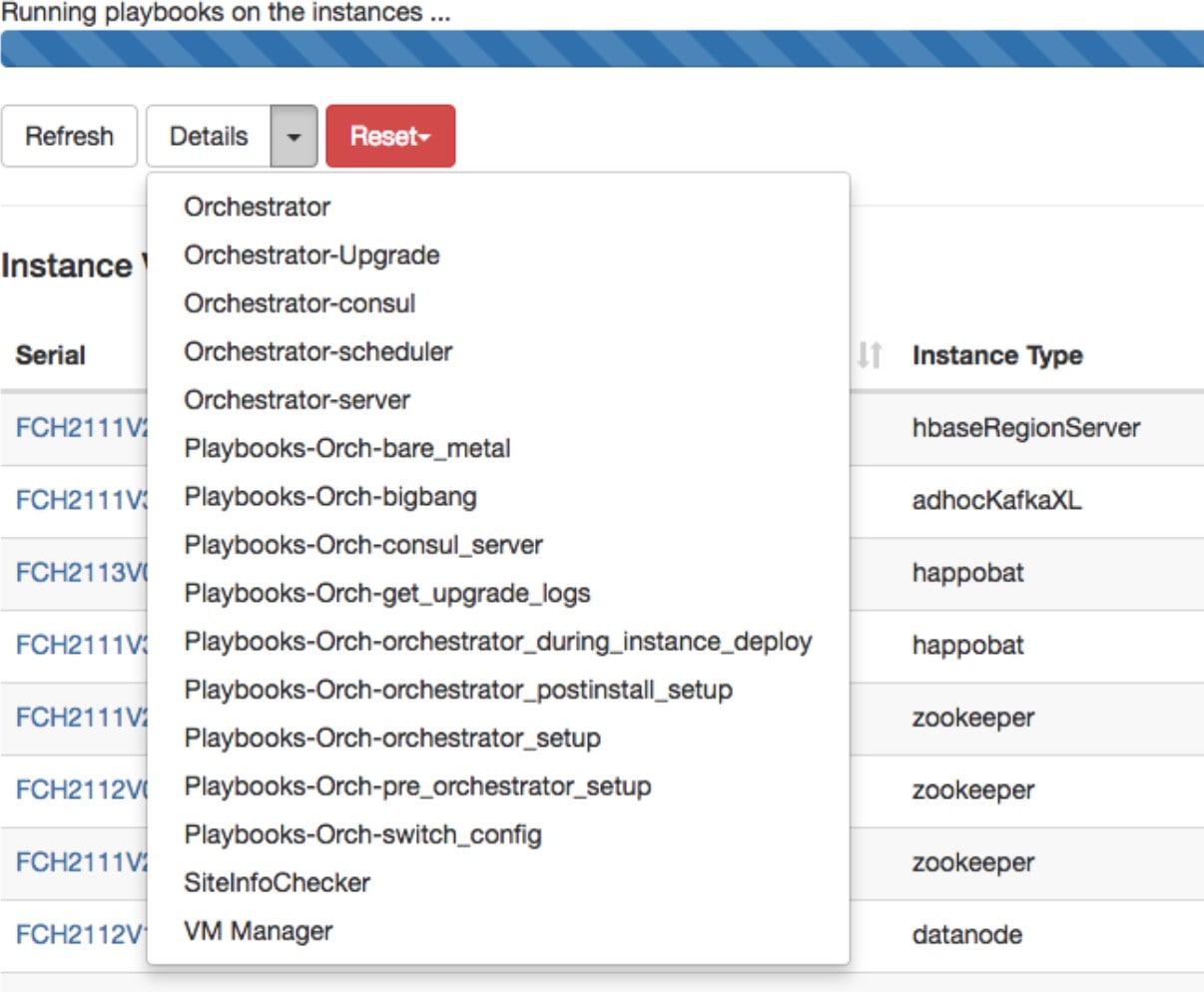
各リンクはログを指します。
|
場合によっては、アップグレードをスケジュールした後、アップグレードを開始しているときに、ハードウェア障害が発生するか、クラスタをアップグレードする準備ができていないことがあります。アップグレードを続行する前に、これらのエラーを修正する必要があります。アップグレードウィンドウまで待たなくても、アップグレードの事前チェックを開始できます。これらのチェックは、アップグレード、パッチアップグレード、または再起動が開始されたときを除いて、いつでも何回でも実行できます。
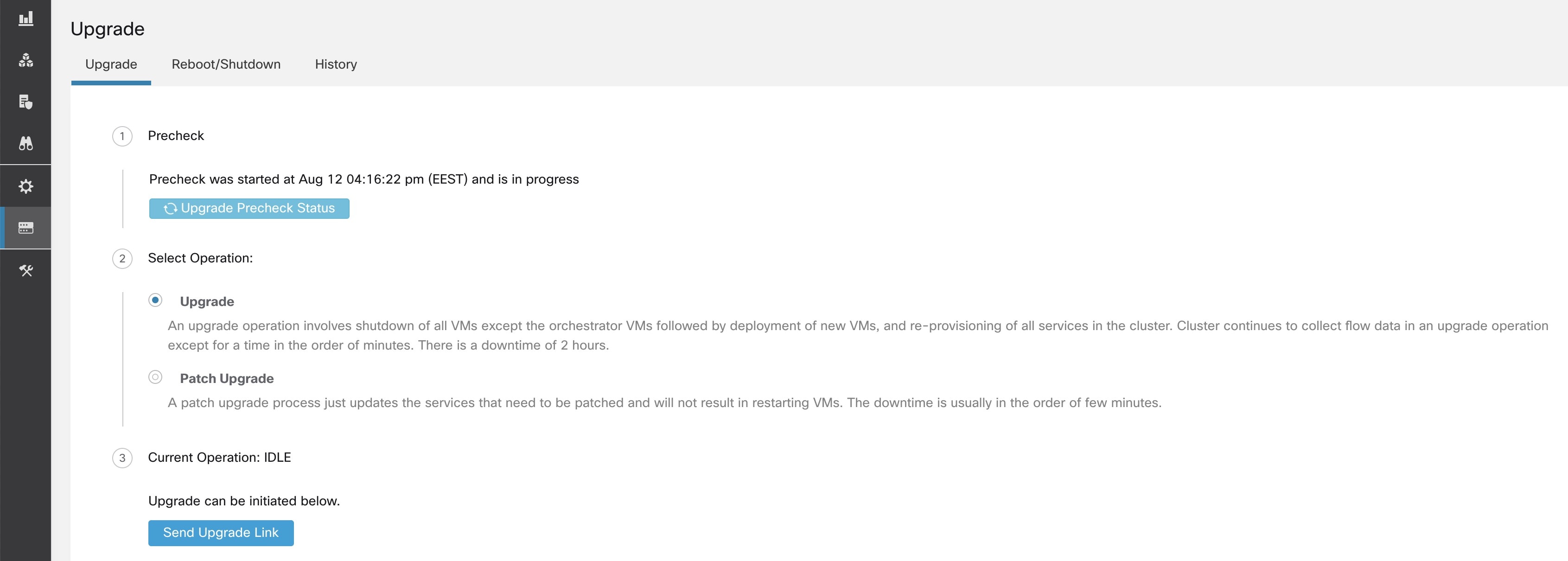
アップグレードの事前チェックを実行するには、次の手順を実行します。
[アップグレード(Upgrade)] タブで、[アップグレードの事前チェックの開始(Start Upgrade Precheck)] をクリックします。
これにより、アップグレードの事前チェックが開始され、実行状態に移行します。
オーケストレータによって実行されるすべてのチェックに合格すると、トークンが記載された電子メールが、登録された電子メール ID に送信されます。トークンを入力して、アップグレードの事前チェックを完了します。
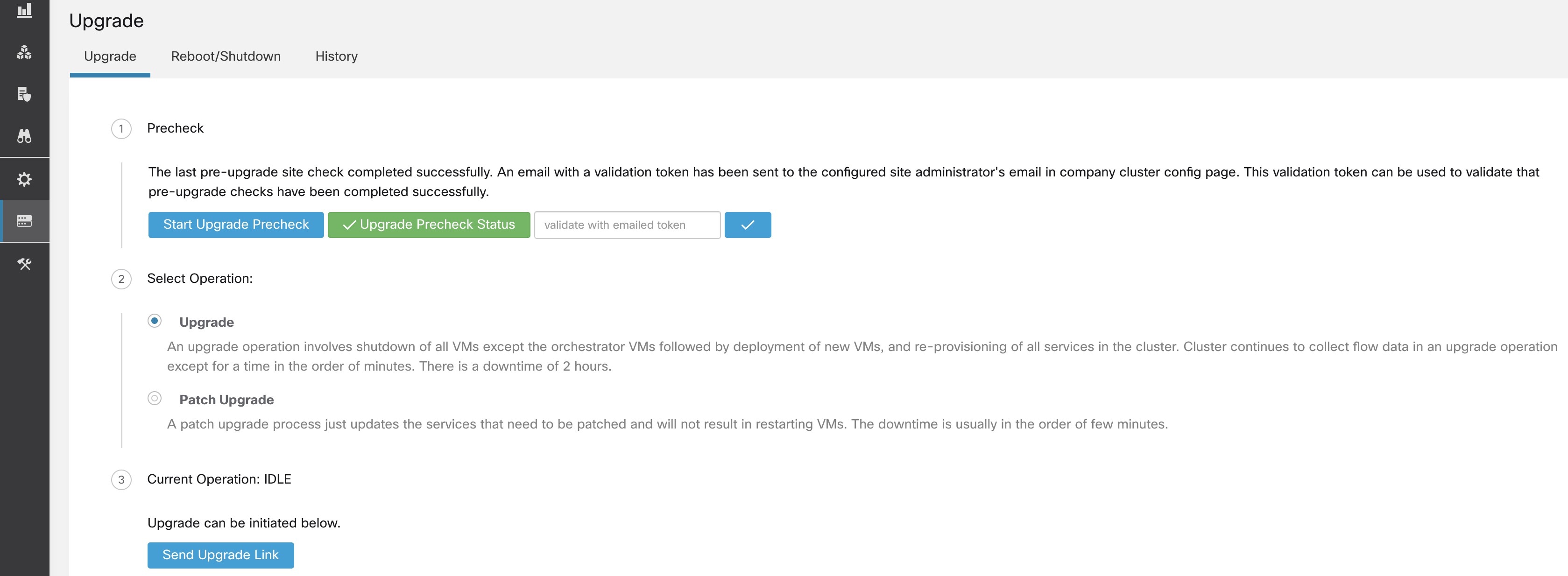
チェックのステータスを確認できます。アップグレードの事前チェック中にエラーが発生した場合は、失敗したチェックを確認でき、それらのチェックは失敗状態に移行します。
クラスタで DBR が有効になっている場合は、「アップグレード(DBR あり)」も参照してください。
カスタマーサポートロールを持つユーザーは、ウィンドウの左側にあるナビゲーションバーから を選択して、スナップショットツールにアクセスできます。
スナップショットツールを使用して、クラシックスナップショットまたは Cisco Integrated Management Controller(CIMC)テクニカルサポートバンドルを作成できます。スナップショット ファイル リスト ページで [スナップショットの作成(Create Snapshot)] ボタンをクリックすると、クラシックスナップショットまたは CIMC スナップショット(テクニカルサポートバンドル)を選択するページがロードされます。CIMC スナップショットを選択するオプションは、Secure Workload ソフトウェアのみ(ESXi)および Secure Workload SaaS では無効になっています。
[クラシックスナップショット(Classic Snapshot)] ボタンをクリックすると、スナップショットツールを実行するためのユーザーインターフェイスがロードされます。
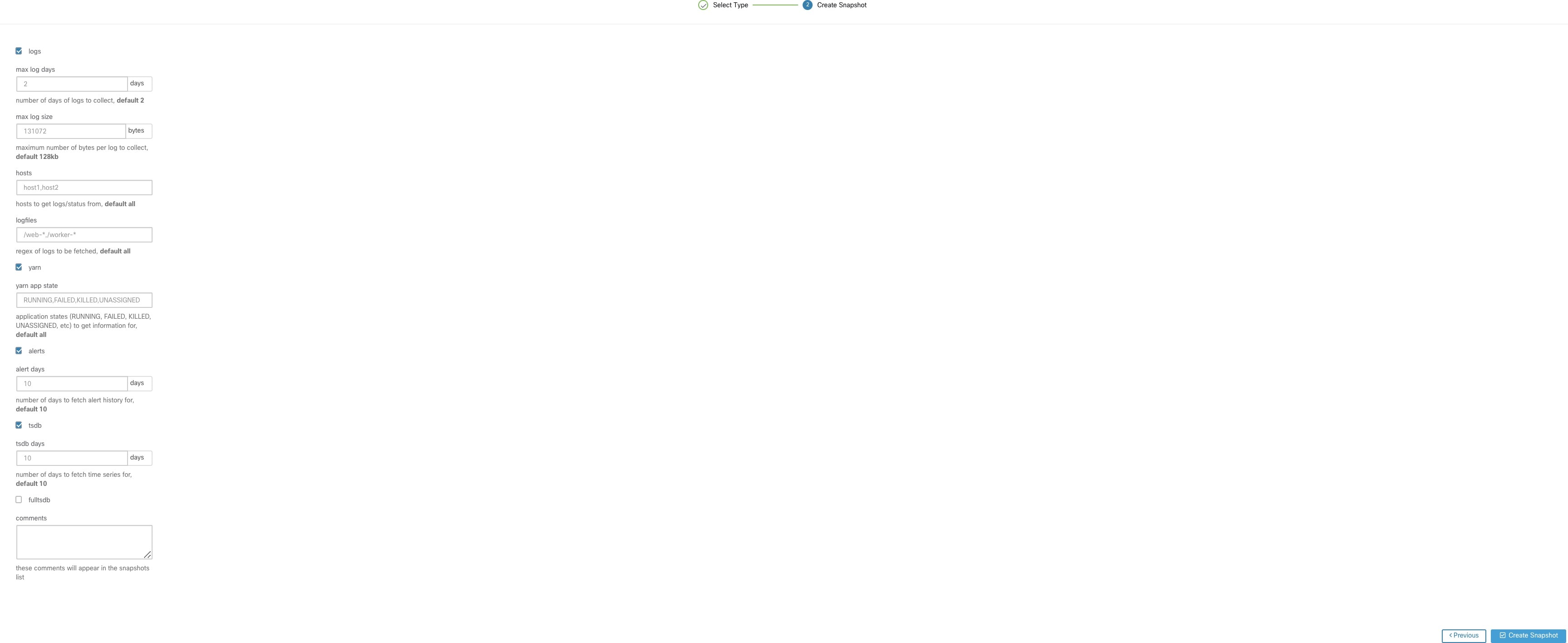
[CIMC スナップショット(CIMC Snapshot)] ボタンをクリックすると、CIMC テクニカルサポートツールを実行するためのユーザーインターフェイスがロードされます。
[スナップショットの作成(Create Snapshot)] でデフォルトのオプションを選択すると、スナップショットツールで次の情報が収集されます。
ログ
Hadoop または YARN アプリケーションの状態とログ
アラート履歴
さまざまな TSDB 統計情報
デフォルトをオーバーライドして、特定のオプションを指定することができます。
ログオプション
最大ログ日数(max log days):収集するログの日数、デフォルトは 2。
最大ログサイズ(max log size ):収集するログごとの最大バイト数、デフォルトは 128 KB。
ホスト(hosts):ログ/ステータスを取得するホスト、デフォルトは [すべて(all)]。
ログファイル(logfiles): 取得するログの正規表現、デフォルトは [すべて(all)]。
yarn オプション
yarn アプリの状態(yarn app state):情報を取得するアプリケーションの状態([実行中(RUNNING)]、[失敗(FAILED)]、[強制終了(KILLED)]、[未割り当て(UNASSIGNED)] など)。デフォルトは all。
アラートオプション
アラート日数(alert days):アラートデータを収集する日数。
tsdb オプション
tsdb 日数(tsdb days):tsdb データを収集する日数。この値を増やすと、非常に大規模なスナップショットが作成される可能性があります。
fulltsdb オプション
fulltsdb:startTime、endTime fullDumpPath、localDumpFile、nameFilterIncludeRegex を指定し、収集するメトリックを制限するために使用できる JSON オブジェクト。
コメント(comments):スナップショットを収集する理由や収集するユーザーを記載するために追加できます。
[スナップショットの作成(Create Snapshot)] を選択すると、スナップショット ファイル リスト ページの上部にスナップショットの進行状況バーが表示されます。スナップショットが完了したら、スナップショット ファイル リスト ページの [ダウンロード(Download)] ボタンを使用してダウンロードできます。一度に収集できるスナップショットは 1 つだけです。
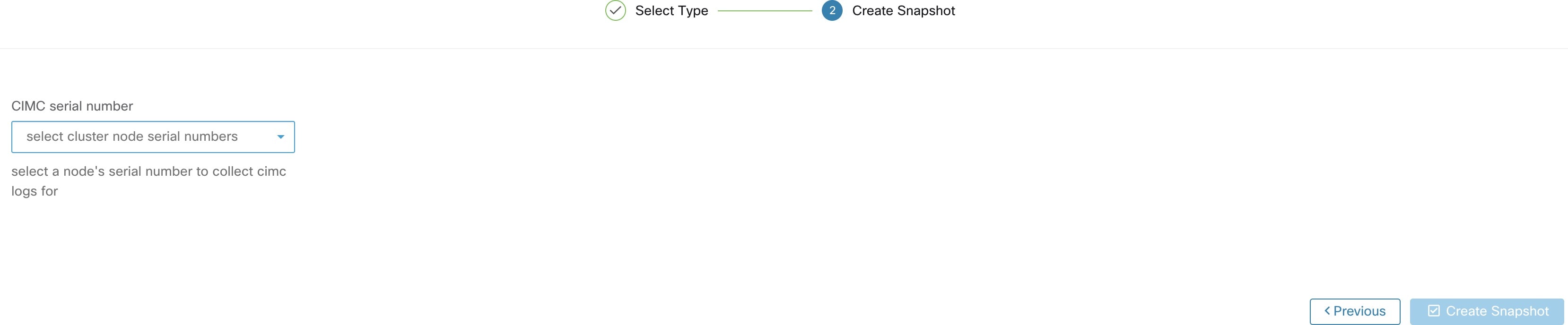
[CIMCスナップショット(CIMC Snapshot)](テクニカルサポートバンドル)ページで、CIMC テクニカルサポートバンドルを作成するノードのシリアル番号を選択し、[スナップショットの作成(Create Snapshot)] ボタンをクリックします。CIMC テクニカルサポートバンドル収集の進行状況バーが [スナップショット ファイル リスト(Snapshot File List)] ページに表示され、CIMC テクニカルサポートバンドル収集がトリガーされたことが [コメント(Comments)] セクションに反映されます。CIMC テクニカルサポートバンドルの収集が完了すると、[スナップショット ファイル リスト(Snapshot File List)] ページからファイルをダウンロードできます。
スナップショットを解凍すると、各マシンのログを含む ./clustername_snapshot ディレクトリが作成されます。ログは、マシンのいくつかのディレクトリのデータを含むテキストファイルとして保存されます。スナップショットは、JSON 形式でキャプチャされたすべての Hadoop/TSDB データも保存します。
パッケージ化された index.html をブラウザで開くと、次のタブが表示されます。
アラート状態の変化についての簡潔なリスト。
grafana ダッシュボードの複製。
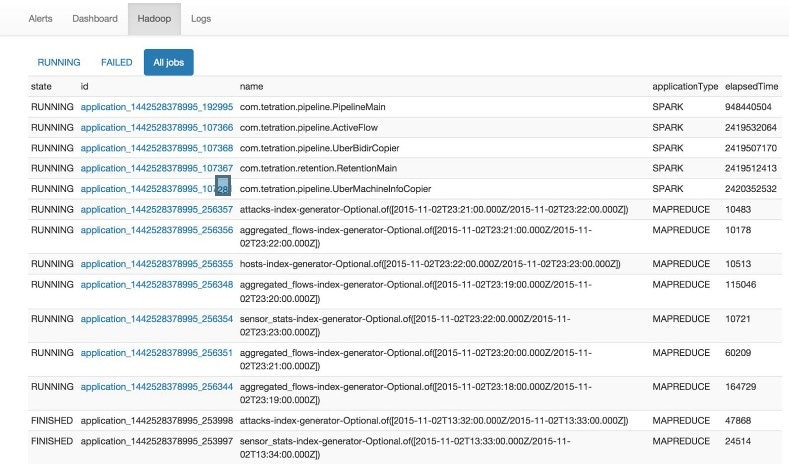
ジョブとその状態を含む Hadoop Resource Manager のフロントエンドの複製。ジョブを選択すると、そのジョブのログが表示されます。
収集されたすべてのログのリスト
スナップショットサービスを使用してサービスコマンドを実行できますが、これにはカスタマーサポート権限が必要です。
Explore ツール (])を使用すると、クラスタ内の任意の URI に到達できます。

Explore ツールは、カスタマーサポートの権限を持つユーザーのみに表示されます。
スナップショットサービスは、すべてのノードのポート 15151 で実行されます。内部ネットワークのみでリッスンし(外部には公開されません)、さまざまなコマンド用の POST エンドポイントがあります。
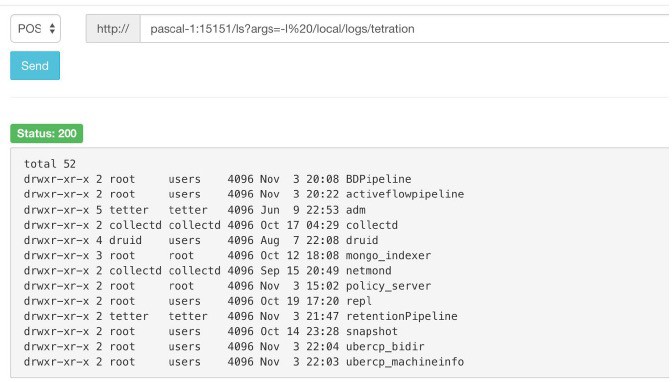
到達する必要がある URI は POST http://<hostname>:15151/<cmd>?args=<args> です。ここで args はスペースで区切られ、URI はエンコードされます。この URI によってシェルでコマンドが実行されることはありません。これにより、何かが実行されることを回避できます。
スナップショットのエンドポイントは、次に対して定義されています。
snapshot 0.2.5
̶Is
̶ svstatus、svrestart - sv status、sv restart を実行 例:1.1.11.15:15151/svrestart?args=snapshot
̶ hadoopls - hadoop fs -ls <args> を実行
̶ hadoopdu - hadoop fs -du <args> を実行
̶ ps 例:1.1.11.31:15151/ps?args=eafux
̶ du
̶ ambari - ambari_service.py を実行
̶ monit
̶ MegaCli64(/usr/bin/MegaCli64)
̶ service
̶ hadoopfsck - hadoop -fsck を実行
snapshot 0.2.6
̶ makecurrent - make -C /local/deploy-ansible current を実行
̶ netstat
snapshot 0.2.7(uid “nobody” として実行)
̶ cat
̶ head
̶ tail
̶ grep
̶ ip -6 neighbor
̶ ip address
̶ ip neighbor
別のエンドポイント POST /runsigned があります。これは、Secure Workload により署名されたシェルスクリプトを実行します。これは、POST されたデータ上で gpg -d を実行します。署名に対して検証できる場合は、暗号化されたテキストをシェルで実行します。これは、Ansible セットアップの一部として各サーバーに公開鍵をインポートすること、および秘密鍵を安全に保つ必要があることを意味します。
カスタマーサポートの権限を持つユーザーは、ウィンドウの左側にあるナビゲーションバーから を選択して、ランブックを使用できます。ドロップダウンメニューから [POST] を選択します。(そうしないと、コマンドの実行時に Page Not Found エラーが発生します。)
スナップショット REST エンドポイントを使用してサービスを再起動します。
druid: 1.1.11.17:15151/service?args=supervisord%20restart
— druid ホストは、すべて .17 から .24 までの IP です。.17、.18 はコーディネータ、.19 はインデクサ、.20 ~ .24 はブローカです。
hadoop パイプラインランチャ:
̶ 1.1.11.25:15151/svrestart?args=activeflowpipeline
̶ 1.1.11.25:15151/svrestart?args=adm
̶ 1.1.11.25:15151/svrestart?args=batchmover_bidir
̶ 1.1.11.25:15151/svrestart?args=batchmover_machineinfo
̶ 1.1.11.25:15151/svrestart?args=BDPipeline
̶ 1.1.11.25:15151/svrestart?args=mongo_indexer
̶ 1.1.11.25:15151/svrestart?args=retentionPipeline
ポリシー エンジン
̶ 1.1.11.25:15151/svrestart?args=policy_server
wss
̶ 1.1.11.47:15151/svrestart?args=wss
エンドポイントを実行するには、ウィンドウの左側にあるナビゲーションバーから ページに移動する必要があります。
また、<end- point>?usage=true のように任意のホストで POST コマンドを実行して、エクスプローラページで各エンドポイントの概要を表示することもできます。
例:makecurrent?usage=true
|
エンドポイント |
説明 |
|---|---|
|
bm_details |
ベアメタル情報を表示します。 |
|
endpoints |
ホスト上のすべてのエンドポイントを一覧表示します。 |
|
メンバー |
consul メンバーの現在のリストとそのステータスを表示します。 |
|
port2cimc |
|
|
status |
ホスト上のスナップショットサービスのステータスを表示します。 |
|
vm_info |
|
|
エンドポイント |
説明 |
||
|---|---|---|---|
|
bm_shutdown_or_reboot |
|
||
|
cat |
UNIX コマンド cat のラッパーコマンド |
||
|
cimc_password_random |
|
||
|
cleancmdlogs |
/local/logs/tetration/snapshot/cmdlogs/snap- shot_cleancmdlogs_log 内のログをクリアします。 |
||
|
clear_sel |
|
||
|
cluster_fw_upgrade |
|
||
|
cluster_fw_upgrade_status |
|
||
|
cluster_powerdown |
|
||
|
collector_status |
|
||
|
consul_kv_export |
|
||
|
consul_kv_recurse |
|
||
|
chronyc |
UNIX コマンド chronyc のラッパー コマンド |
||
|
df |
UNIX コマンド df のラッパーコマンド |
||
|
dig |
UNIX コマンド dig のラッパーコマンド |
||
|
dmesg |
UNIX コマンド dmesg のラッパーコマンド |
||
|
dmidecode |
UNIX コマンド dmidecode のラッパーコマンド |
||
|
druid_coordinator_v1 |
DRUID のステータスを表示します。 |
||
|
du |
UNIX コマンド du のラッパーコマンド |
||
|
dusorted |
UNIX コマンド dusorted のラッパーコマンド |
||
|
externalize_change_tunnel |
|
||
|
externalize_mgmt |
|
||
|
externalize_mgmt_read_only_password |
|
||
|
fsck |
|
||
|
get_cimc_techsupport |
|
||
|
syslog_endpoints |
|
||
|
grep |
UNIX コマンド grep のラッパーコマンド |
||
|
hadoopbalancer |
|
||
|
hadoopdu |
|
||
|
hadoopfsck |
|
||
|
hadoopls |
|
||
|
hbasehbck |
|
||
|
hdfs_safe_state_recover |
|
||
|
initctl |
UNIX コマンド initctl のラッパーコマンド |
||
|
head |
UNIX コマンド head のラッパーコマンド |
||
|
internal_haproxy_status |
|
||
|
ip |
UNIX コマンド ip のラッパーコマンド |
||
|
ipmifru |
|
||
|
ipmilan |
|
||
|
ipmisel |
|
||
|
ipmisensorlist |
|
||
|
jstack |
指定された Java プロセスまたはコアファイルの Java スレッドの Java スタックトレースを出力します。 |
||
|
ls |
UNIX コマンド ls のラッパーコマンド |
||
|
lshw |
UNIX コマンド lshw のラッパーコマンド |
||
|
lsof |
UNIX コマンド lsof のラッパーコマンド |
||
|
lvdisplay |
UNIX コマンド lvdisplay のラッパーコマンド |
||
|
lvs |
UNIX コマンド lvs のラッパーコマンド |
||
|
lvscan |
UNIX コマンド lvscan のラッパーコマンド |
||
|
makecurrent |
|
||
|
malicious_ips |
|
||
|
mongo_rs_status |
|
||
|
mongo_stats |
|
||
|
mongodump |
|
||
|
monit |
UNIX コマンド monit のラッパーコマンド |
||
|
namenode_jmx |
プライマリネームノードの JMX メトリックを表示します。 |
||
|
namenode_checkpoint |
チェックポインティングは、スタンバイネームノードで 1 時間ごとに実行されます。 この状態をクリアするには、手動チェックポインティングが必要です。
|
||
|
namenode_failover |
UPGRADE または REBOOT を実行する前に、必ず、アップグレードの事前チェックを実行してください。 |
||
|
namenodeha_get_details |
各 |
||
|
ndisc6 |
UNIX コマンド ndisc6 のラッパーコマンド |
||
|
netstat |
UNIX コマンド netstat のラッパーコマンド |
||
|
orch_reset |
|
||
|
orch_stop |
|
||
|
ping |
UNIX コマンド ping のラッパーコマンド |
||
|
ping6 |
UNIX コマンド ping6 のラッパーコマンド |
||
|
ps |
UNIX コマンド ps のラッパーコマンド |
||
|
pv |
UNIX コマンド pv のラッパーコマンド |
||
|
pvs |
UNIX コマンド pvs のラッパーコマンド |
||
|
pvdisplay |
UNIX コマンド pvdisplay のラッパーコマンド |
||
|
rdisc6 |
UNIX コマンド rdisc6 のラッパーコマンド |
||
|
rebootnode |
|
||
|
recover_rpmdb |
|
||
|
recoverhbase |
|
||
|
recovervm |
|
||
|
runsigned |
|
||
|
service |
UNIX コマンド service のラッパーコマンド |
||
|
smartctl |
|
||
|
storcli |
UNIX コマンド storcli のラッパーコマンド |
||
|
sudocat |
/var/log または /local/logs でのみ機能する cat コマンドのラッパー |
||
|
sudogrep |
/var/log または /local/logs でのみ機能する grep コマンドのラッパー |
||
|
sudohead |
/var/log または /local/logs のみで機能する「head」コマンドのラッパー |
||
|
sudols |
/var/log または /local/logs のみで機能する「ls」コマンドのラッパー |
||
|
sudotail |
/var/log または /local/logs のみで機能する「tail」コマンドのラッパー |
||
|
sudozgrep |
/var/log または /local/logs のみで機能する「zgrep」コマンドのラッパー |
||
|
sudozcat |
/var/log または /local/logs のみで機能する「zcat」コマンドのラッパー |
||
|
svrestart |
入力したサービスを再起動します。コマンドを |
||
|
svstatus |
入力したサービスのステータスを出力します。 |
||
|
switchinfo |
クラスタスイッチに関する情報を取得します。 |
||
|
tail |
UNIX コマンド tail のラッパーコマンド |
||
|
toggle_chassis_locator |
|
||
|
tnp_agent_logs |
|
||
|
tnp_datastream |
|
||
|
ui_haproxy_status |
外部 haproxy の haproxy 統計情報とステータスを出力します。 |
||
|
uptime |
UNIX コマンド uptime のラッパーコマンド |
||
|
userapps_kill |
|
||
|
vgdisplay |
UNIX コマンド vgdisplay のラッパーコマンド |
||
|
vgs |
UNIX コマンド vgs のラッパーコマンド |
||
|
vmfs |
|
||
|
vminfo |
|
||
|
vmlist |
|
||
|
vmreboot |
|
||
|
vmshutdown |
|
||
|
vmstart |
|
||
|
vmstop |
|
||
|
yarnkill |
|
||
|
yarnlogs |
|
||
|
zcat |
UNIX コマンド zcat のラッパーコマンド |
||
|
zgrep |
UNIX コマンド zgrep のラッパーコマンド |
サーバーのメンテナンスには、故障したサーバーコンポーネント(ハードディスク、メモリなど)、またはサーバーの交換が含まれます。
Note |
クラスタ上にメンテナンスが必要なサーバーが複数ある場合は、一度に 1 つのサーバーをメンテナンスします。複数のサーバーを同時にデコミッションすると、データが失われる可能性があります。 |
サーバーのメンテナンスに関連するすべての手順を実行するには、ナビゲーションウィンドウで、 の順に選択します。このページにはすべてのユーザーがアクセスできますが、アクションを実行できるのはカスタマーサポートユーザーのみです。このページには、Cisco Secure Workload ラック内のすべての物理サーバーのステータスが表示されます。
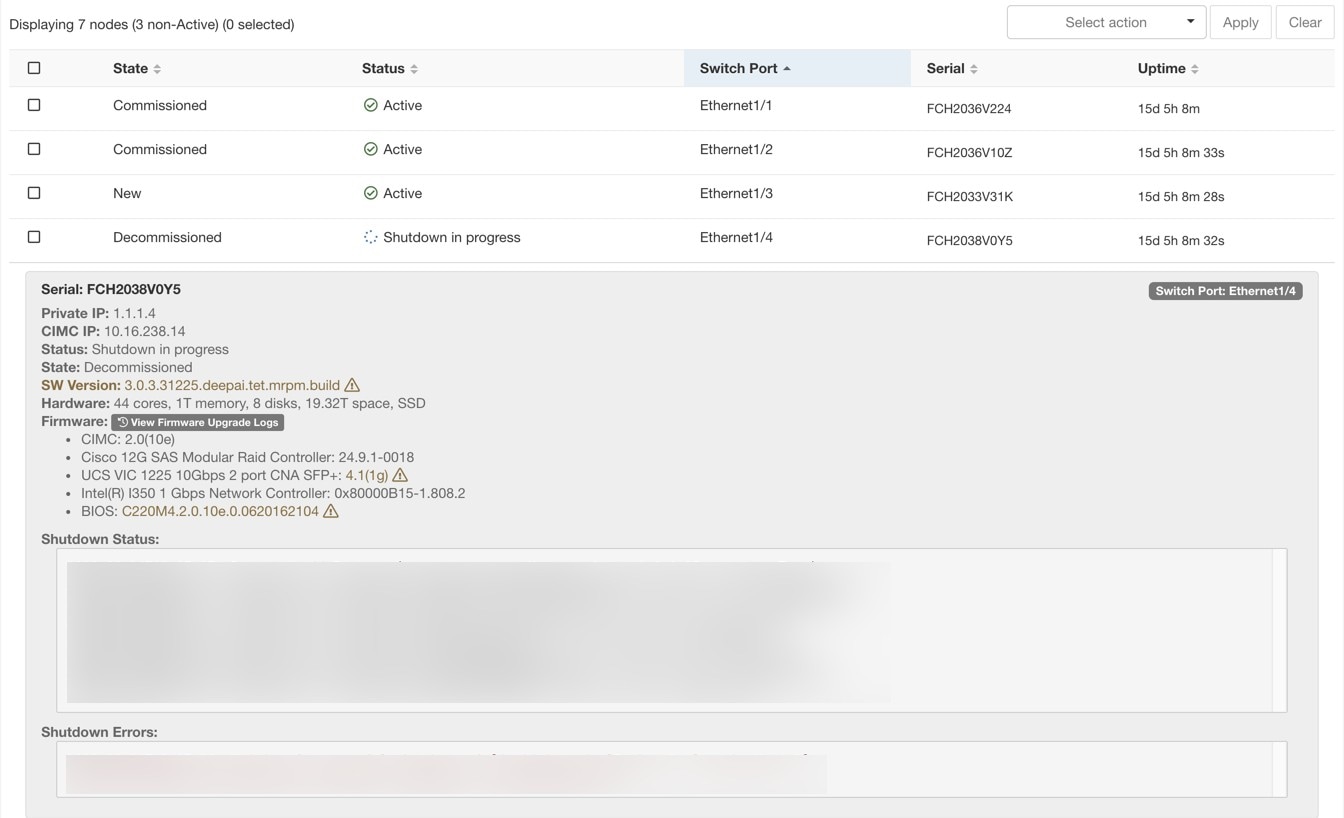
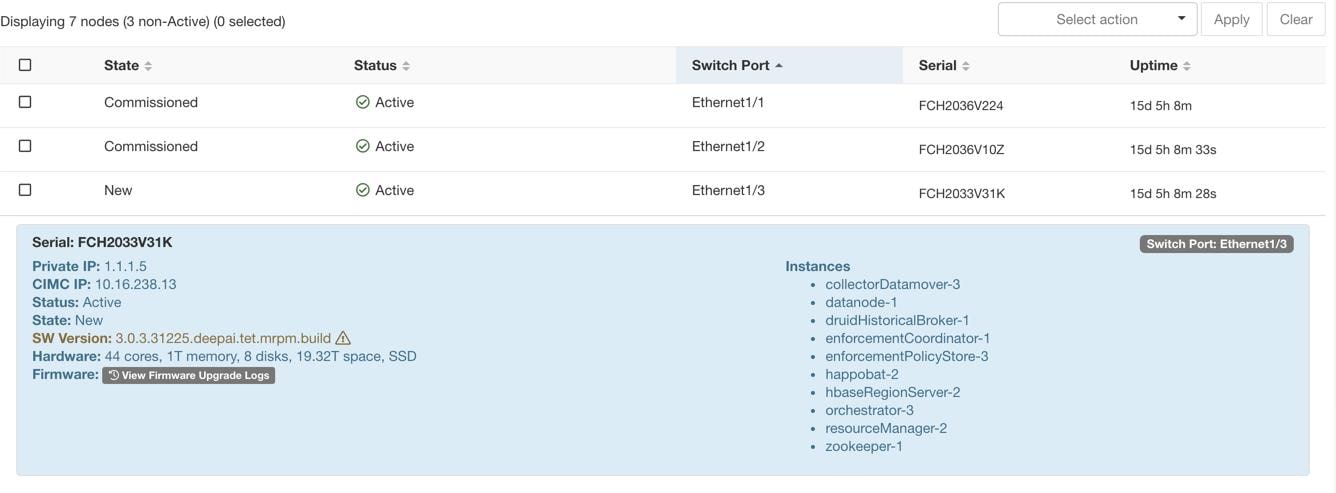
サーバーまたはコンポーネントの交換に関連する手順
メンテナンスが必要なサーバーの判断:[クラスタステータス(Cluster Status)] ページで、サーバーの [シリアル(Serial)] 番号またはサーバーが接続されている [スイッチポート(Switch Port)] を使用して判断できます。交換するサーバーの CIMC IP をメモします。CIMC IP は、[クラスタステータス(Cluster Status)] ページのサーバーボックスに表示されます。
特別な VM のアクションの確認:サーバーボックスから、サーバーに存在する VM またはインスタンスを見つけ、それらの VM に対して特別なアクションを実行する必要があるか確認します。次のセクションに、サーバーメンテナンス中の VM のアクションが一覧表示されています。
サーバーのデコミッション:デコミッション前のアクションが実行されたら、[クラスタステータス(Cluster Status)] ページを使用してサーバーをデコミッションします。サーバーに障害が発生し、ページに [非アクティブ(Inactive)] と表示された場合でも、サーバーのメンテナンス手順をすべて実行できます。デコミッション手順は、サーバーの電源がオフの場合でも実行できます。
サーバーのメンテナンスの実行:[クラスタステータス(Cluster Status)] ページでノードが [デコミッション済み(Decommissioned)] とマークされたら、VM に対してデコミッション後の特別なアクションを実行します。これで、コンポーネントまたはサーバーを交換できます。サーバー全体を交換する場合は、新しいサーバーの CIMC IP を、交換したサーバーと同じ CIMC IP に変更します。各サーバーの CIMC IP は、[クラスタステータス(Cluster Status)] ページで確認できます。
コンポーネント交換後の再イメージ化:[クラスタステータス(Cluster Status)] ページを使用して、コンポーネント交換後にサーバーを再イメージ化します。再イメージ化には約 30 分かかり、サーバーへの CIMC アクセスが必要です。再イメージ化が完了したサーバーは [新規(NEW)] とマークされます。
サーバー全体の交換:サーバー全体を交換した場合、そのサーバーは [クラスタステータス(Cluster Status)] ページに [新規(NEW)] 状態で表示されます。サーバーのソフトウェアバージョンは、同じページで確認できます。ソフトウェアバージョンがクラスタのバージョンと異なる場合は、サーバーを再イメージ化します。
サーバーのコミッション:サーバーが [新規(NEW)] とマークされたら、[クラスタステータス(Cluster Status)] ページからノードのコミッショニングを開始できます。この手順により、サーバー上に VM がプロビジョニングされます。サーバーのコミッショニングには約 45 分かかります。コミッショニングが完了すると、サーバーは [コミッション済み(Commissioned)] とマークされます。
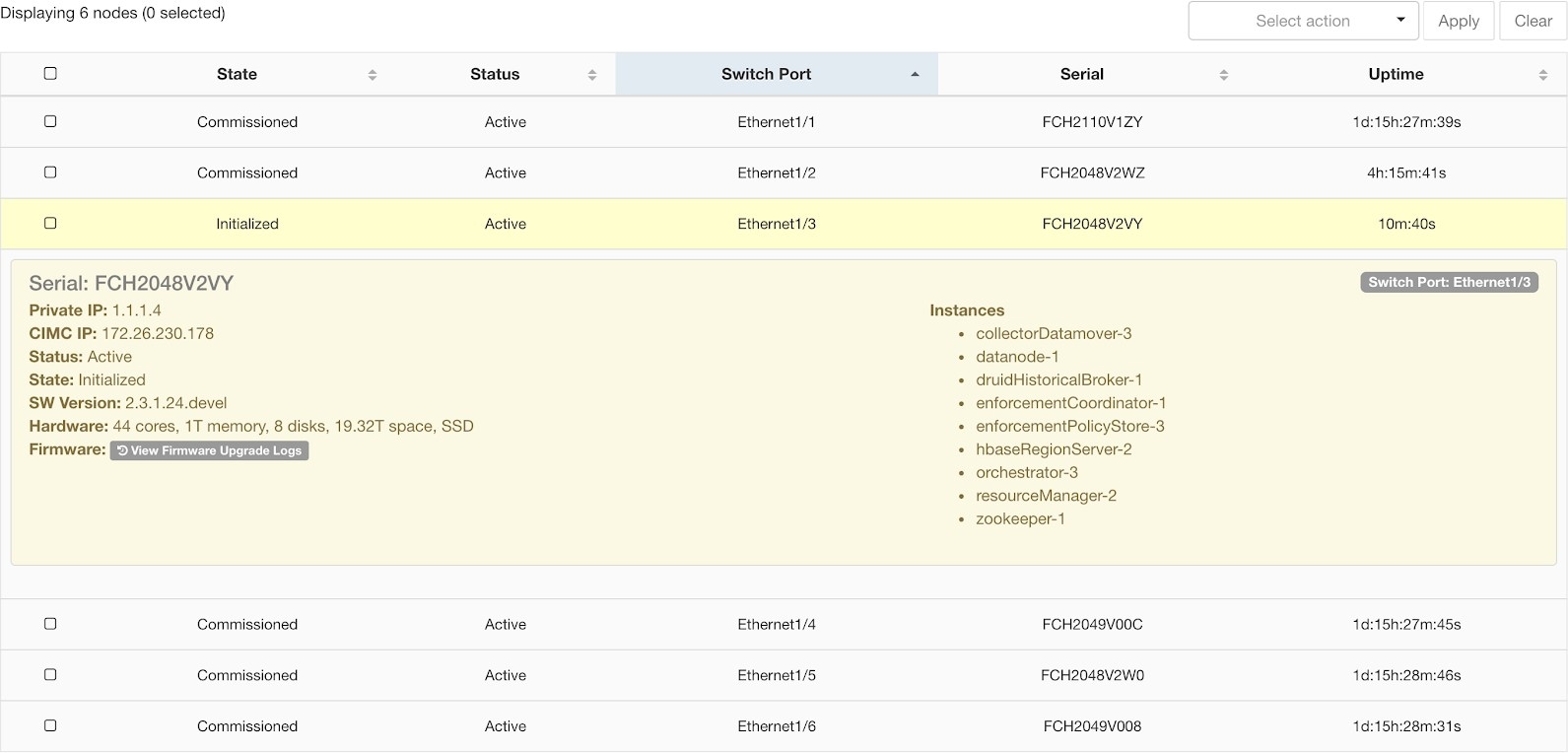
サーバーメンテナンス中の VM のアクション
一部の VM では、サーバーのメンテナンス手順中に特別なアクションを実行する必要があります。それらのアクションは、デコミッション前、デコミッション後、またはコミッション後に実行できます。
オーケストレータのプライマリ:これはデコミッション前のアクションです。メンテナンス中のサーバーにプライマリオーケストレータがある場合は、デコミッションする前に探索ページから orchestrator.service.consul に orch_stop コマンドを POST します。これで、プライマリオーケストレータが切り替わります。

プライマリオーケストレータでサーバーをデコミッションしようとすると、次のエラーが表示されます。

プライマリオーケストレータを特定するには、任意のホストで explore コマンド primaryorchestrator を実行します。
NameNode:メンテナンス中のサーバーに NameNode VM がある場合は、secondaryNameNode-1 インスタンスが実行されており、NameNode サービスが稼働していることを確認します。LauncherHost-1 またはその他の実行中の
LauncherHosts で POST namenodeha_get_details explore コマンドを実行して、ステータスを確認します。secondaryNameNode-1 のステータスは、アクティブまたはスタンバイ状態である必要があります。secondaryNameNode-1 がアクティブまたはスタンバイ状態でない場合は、デコミッションしないでください。
セカンダリ NameNode:メンテナンス中のサーバーに secondaryNameNode VM がある場合は、NameNode-1 インスタンスが実行されており、NameNode サービスが稼働していることを確認します。LauncherHost-1 またはその他の実行中の
LauncherHosts で POST namenodeha_get_details explore コマンドを実行して、ステータスを確認します。NameNode-1 のステータスはアクティブまたはスタンバイである必要があります。NameNode-1 がアクティブまたはスタンバイ状態でない場合は、デコミッションしないでください。
Resource Manager プライマリ:メンテナンス中のサーバーに Resource Manager プライマリがある場合、探索ページから orchestrator.service.consul に switch_yarn を POST します。これらは、デコミッション後とコミッション後のアクションです。
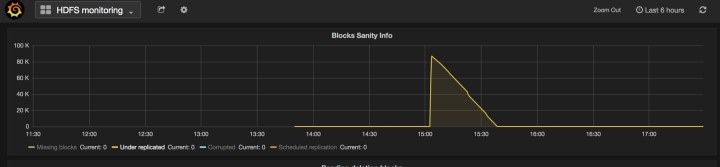
DataNode:クラスタでは、一度に 1 つの DataNode 障害のみ許容されます。DataNode VM を持つ複数のサーバーにメンテナンスが必要な場合は、一度に 1 つずつサーバーのメンテナンスを実行します。各サーバーのメンテナンス後、[モニタリング(Monitoring)] | [hawkeye] | [hdfs-monitoring] | [健全性情報のブロック(Block Sanity Info)] の下に表示されるチャートの [欠落ブロック数(Missing blocks)] および [レプリケーション中(Under replicated)] の数が 0 になるのを待ちます。
サーバーメンテナンスのトラブルシューティング
ログ:サーバーのメンテナンスログはすべて、オーケストレータログの一部で、orchestrator.service.consul の /local/logs/tetration/orchestrator/orchestrator.log にあります。
[デコミッション(Decommission)]
この手順により、サーバー上の VM またはインスタンスが削除されます。
次に、バックエンド consul テーブル内にある削除されたインスタンスのエントリが削除されます。
この手順は約 5 分かかります。
完了すると、サーバーは [デコミッション済み(Decommissioned)] とマークされます。
Note |
[デコミッション済み(Decommissioned)] は、サーバーの電源がオフになっていることを意味するものではありません。デコミッションでは、サーバー上の Secure Workload コンテンツのみ削除されます。 |
電源がオフになっているサーバーは [非アクティブ(Inactive)] とマークされます。このサーバーのデコミッションは、[クラスタステータス(Cluster Status)] ページから引き続き実行できます。ただし、サーバーの電源がオフになっているため、VM の削除手順は実行されないため、このサーバーが [デコミッション済み(Decommissioned)] 状態でクラスタに再び参加しないようにしてください。サーバーは再イメージ化してクラスタに追加し直す必要があります。
[再イメージ化(Reimage)]
この手順では、サーバーに Secure Workload ベース OS またはハイパーバイザ OS をインストールします。
また、ハードドライブをフォーマットし、サーバーにいくつかの Secure Workload ライブラリをインストールします。
再イメージ化では、mjolnir というスクリプトを実行して、サーバーのイメージングが開始されます。mjolnir の実行には約 5 分かかり、その後、実際のイメージングが開始されます。イメージングには約 30 分かかります。イメージング中のログは、再イメージ化されているサーバーのコンソールでのみ確認できます。ユーザーは、ta_dev キーを使用して、再イメージ化に関する追加情報を確認できます。PXE ブート時の /var/log/nginx ログ、DHCP IP および PXE ブート構成を確認するための /var/log/messages などがあります。
再イメージ化には、オーケストレータからの CIMC 接続が必要です。CIMC の接続を確認する最も簡単な方法は、探索ページを使用し、orchestrator.service.consul から ping?args=<cimc ip> を POST する方法です。サーバーを交換した場合は、CIMC IP を変更し、CIMC パスワードをデフォルトのパスワードに設定することを忘れないでください。
また、スイッチが正しいルートで設定されるように、クラスタの展開時に CIMC ネットワークがサイト情報に設定されている必要があります。クラスタ CIMC 接続が正しく設定されていない場合、オーケストレータログに次の結果が表示されます。
[コミッション(Commission)]
コミッショニングでは、サーバー上の VM がスケジュールされ、VM でプレイブックを実行して Secure Workload ソフトウェアがインストールされます。
コミッショニングが完了するまでに約 45 分かかります。
ワークフローは、展開またはアップグレードのワークフローと同様です。
ログには、コミッショニング中の障害が示されます。
[クラスタステータス(Cluster Status)] ページのサーバーは、コミッショニング中は [初期化済み(Initialized)] となり、手順完了後にのみ [コミッション済み(Commissioned)] としてマークされます。
電源シャットダウン後のクラスタの再起動時にハードウェア障害が検出された場合、現在のところ、サービスを安定させるための再起動ワークフローの実行も、コミッションワークフローの実行もできない(サービスが停止するとコミッションが失敗するため)状態でクラスタがスタックします。この機能は、このようなシナリオで役立つことが期待されており、ユーザーは障害のあるハードウェアで再起動(アップグレード)でき、その後、失敗したベアメタルの通常の RMA プロセスを実行できます。
ユーザーは、POST を使用して、除外するベアメタルのシリアルでエンドポイントを探索する必要があります。
アクション:POST
ホスト:orchestrator.service.consul
エンドポイント:exclude_bms?method=POST
本文:{“baremetal”:[“BMSERIAL”]}
オーケストレータは、除外が実行可能か判断するためにいくつかのチェックを実行します。この場合、オーケストレータはいくつかの consul キーをセットアップし、次の再起動またはアップグレードワークフローで除外されるベアメタルと VM を示す成功メッセージを返します。ベアメタルに特定の VM が含まれている場合、それらの VM は除外できません(以下の「制限事項」セクションを参照)。探索エンドポイントは、除外できない理由を示すメッセージで応答します。探索エンドポイントでの POST が成功すると、ユーザーはメイン GUI から再起動またはアップグレードを開始し、通常どおり再起動を続行できます。アップグレードの最後に、除外 BM リストを削除します。BM を除外してアップグレードまたは再起動を再度実行する必要がある場合、ユーザーは bmexclude 探索エンドポイントに再度 POST する必要があります。
制限事項
次の VM は除外できません。
namenode
secondaryNamenode
mongodb
mongodbArbiter
ディスクメンテナンスには、1 つ以上のサーバーから障害のあるハードディスクを交換することが含まれます。オーケストレータは、クラスタ内のすべてのサーバーで bmmgr によって報告されるディスクの状態を監視します。障害のあるディスクがある場合は、[クラスタステータス(Cluster Status)] ページのバナーにエラーが表示されます。ナビゲーションウィンドウで、の順に選択します。
バナーには、異常(UNHEALTHY)状態のディスクの数が表示されます。バナーでこちらをクリックすると、ディスク交換ウィザードが表示されます。ディスク交換ページにのみアクセスできますが、カスタマーサポートは、このウィザードを使用して、ディスクメンテナンスに必要なすべての手順を実行できます。
ディスクのデコミッションまたはコミッションを実行する前に、バックエンドでさまざまなチェックが実行されます。ディスクのデコミッションまたはコミッションを続行する前に、すべてのチェックに合格する必要があります。
失敗したチェックは、失敗の詳細と修正アクションとともにディスク交換ウィザードで報告されるので、次の手順に進む前に対処する必要があります。たとえば、データノードは一度に 1 つのみデコミッションできます。NameNode と secondaryNameNode は一緒にデコミッションできません。また、ディスクをコミッションする前に NameNode が正常であることを確認します。
ユーザーは、障害が発生したディスクの任意のセットを、まとめてデコミッションするために選択し、デコミッションの事前チェックを開始できます。障害が発生したディスクのセットを変更するには、事前チェックを再実行する必要があります。ディスクのデコミッションまたはコミッションを開始する前に、事前チェックを再度確認します。最後の事前チェックの実行からデコミッションタスクの開始までの間に、新しい事前チェックの失敗がないことを確認します。
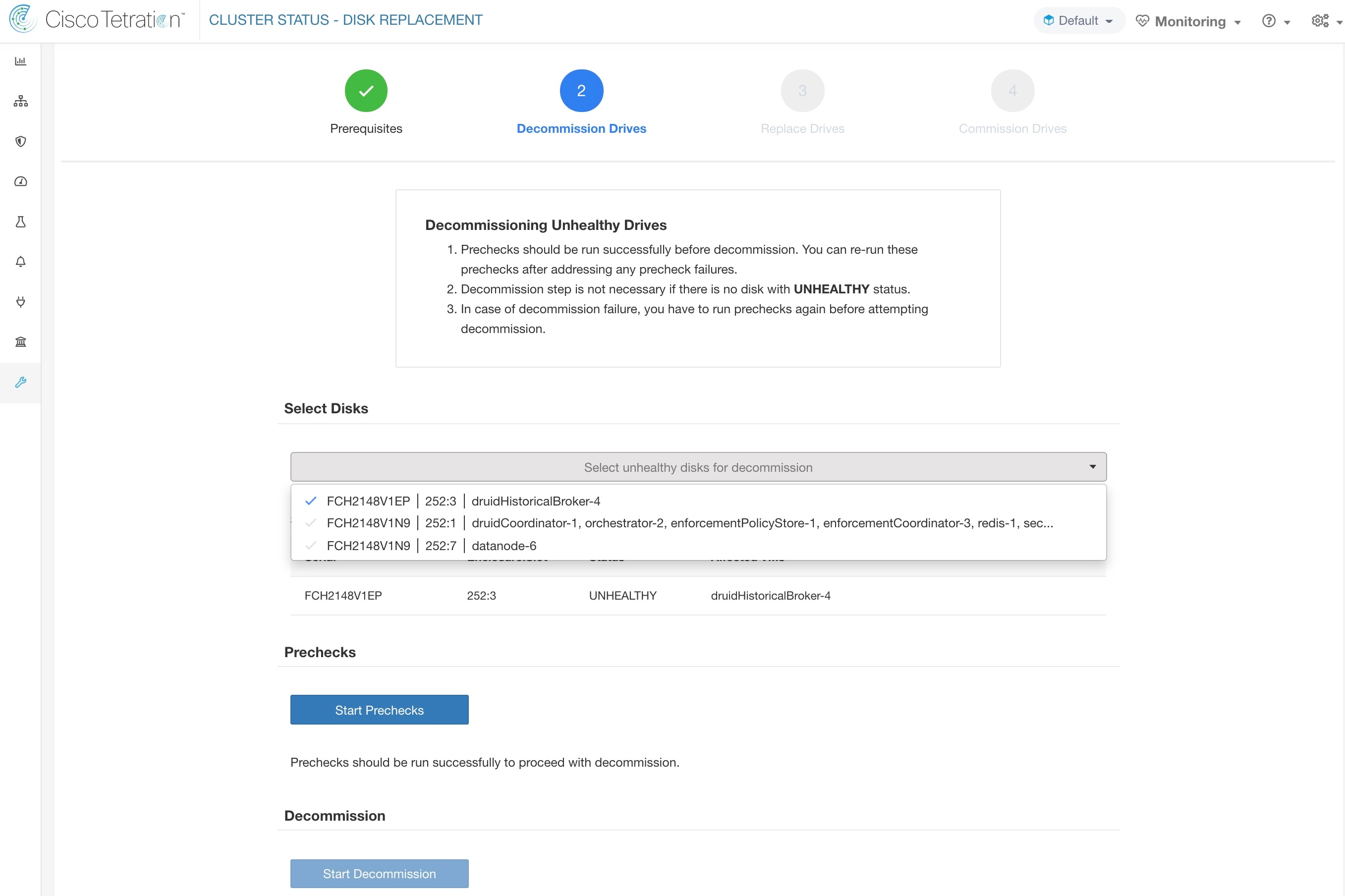
事前チェックに失敗した場合、詳細なメッセージが表示されます。失敗メッセージをクリックし、ポインターを十字ボタンの上に置くと、推奨処置がポップオーバーに表示されます。
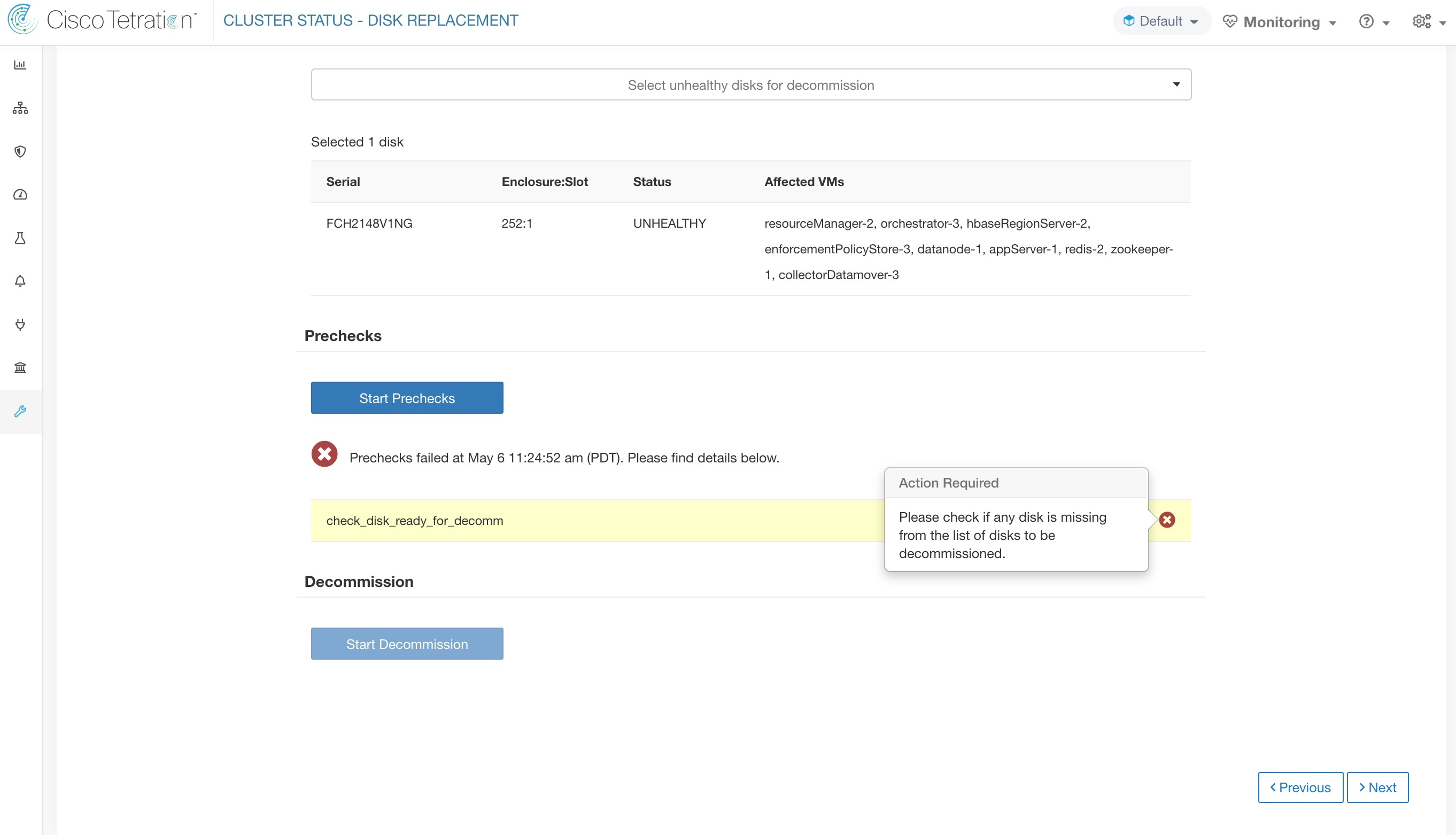
ユーザーは、障害が発生したディスクの任意のセットを、まとめてデコミッションするために選択し、デコミッションの事前チェックを開始できます。障害が発生したディスクのセットを変更するには、事前チェックを再実行する必要があります。タスク(デコミッションまたはコミッション)を開始する前に、同じ事前チェックを再度実行して、最後の事前チェックの実行からデコミッションタスクの開始までの間に新しい事前チェックの失敗がないことを確認します。
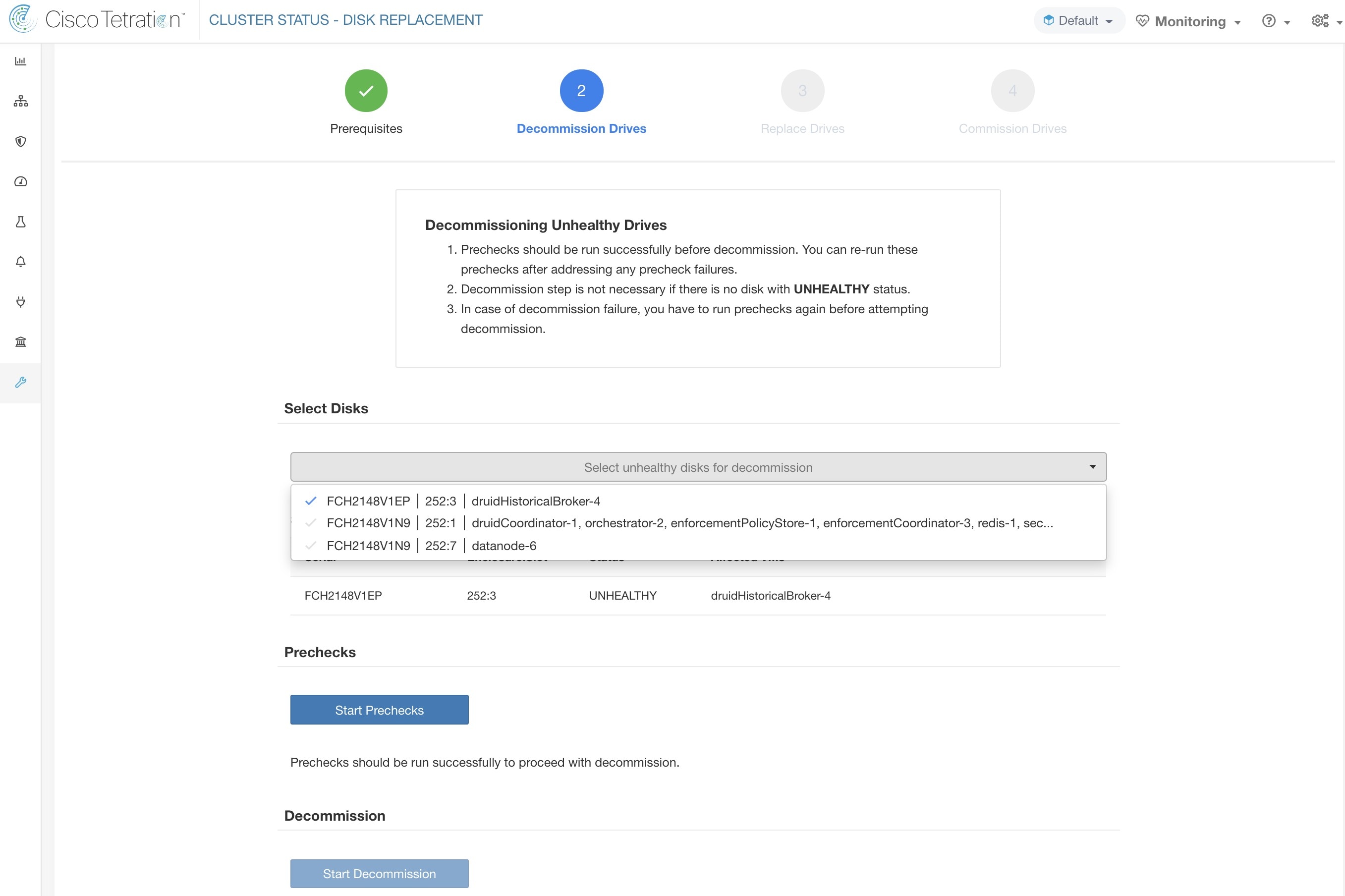
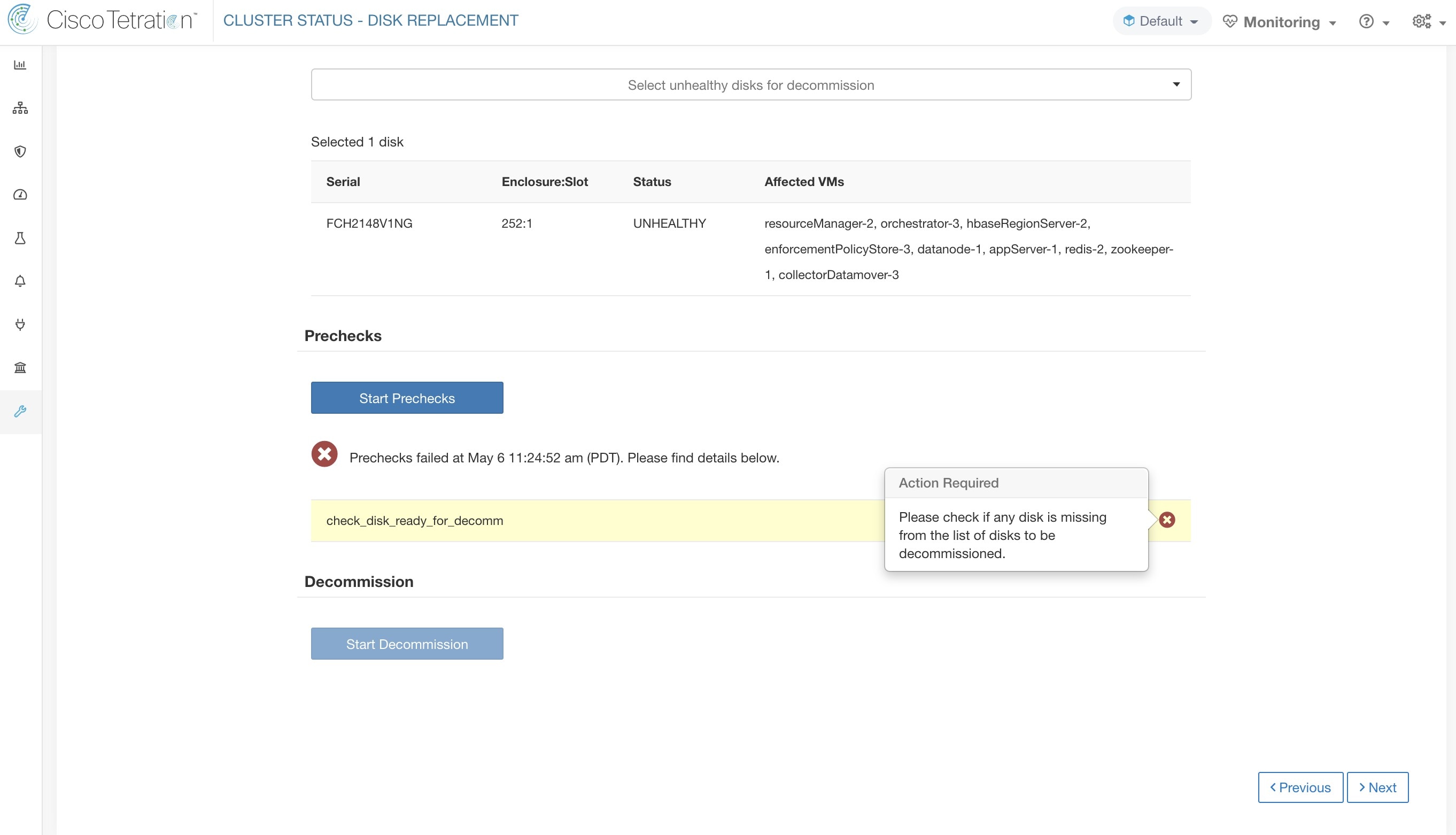
事前チェックが失敗した場合、失敗メッセージをクリックすると詳細メッセージが表示され、ポインターを赤い十字ボタンの上に置くと、推奨される処置がポップオーバーに表示されます。
はじめる前に
正常でないディスクの交換プロセスを開始する前に、使用可能な新しいディスクがあることを確認します。
ディスク交換ウィザードには、交換が必要なすべてのディスクのサイズ、タイプ、製造元、およびモデルを含む、障害が発生したディスクの詳細が表示されます。また、スロット ID が表示され、交換が必要な各ディスクを使用するすべての VM が一覧表示されます。
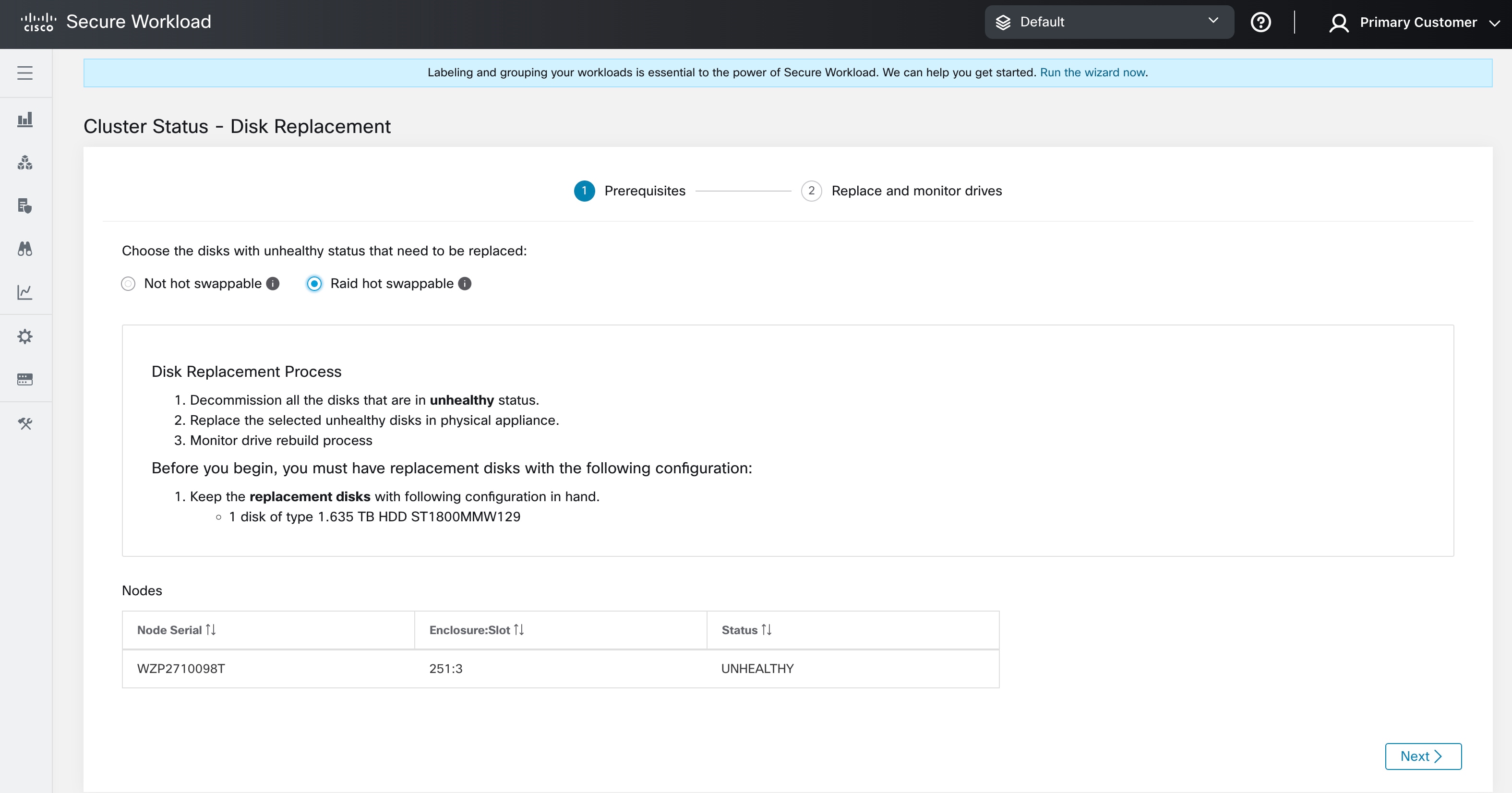
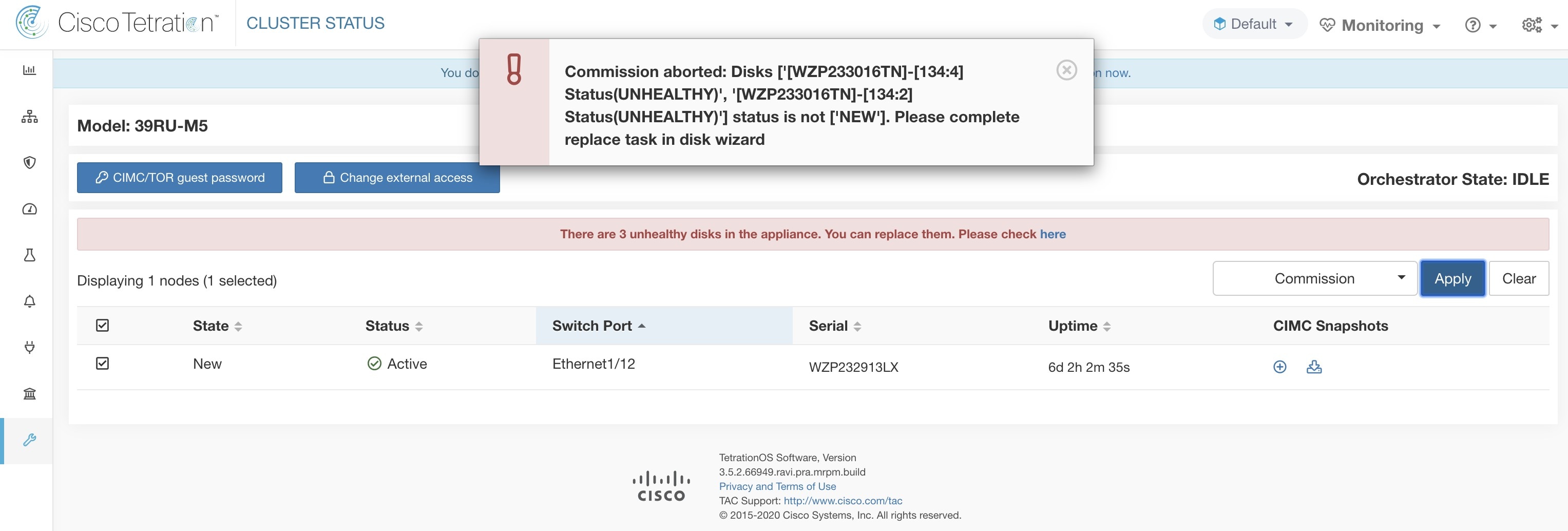
物理的には、ドライブとハードウェアはホットスワップに対応しています。39RU-G3(M6)クラスタのみが、ドライブのスワップを可能にするために必要なハードウェア構成を備えています。ドライブを交換後、クラスタ上の仮想マシンをコミッションする前に、ドライブを使用する仮想マシンをデコミッションせずにドライブをスワップできます。
ドライブが [ホットスワップ非対応(Not Hot Swappable)] の下に表示されている場合は、「シングルドライブの交換」プロセスに従ってドライブを交換する必要があります。ドライブが [RAIDホットスワップ対応(Raid Hot Swappable)] の下に表示されている場合は、ノードでハードウェアベースの RAID5 が使用されているため、仮想マシンをデコミッションせずにドライブを交換できます。
Note |
39RU M6 クラスタでは、RAID 対応ドライブを HDD ノードで使用できます。システムをシャットダウンしたり、動作を中断したりせずに、RAID ホットスワップ対応ディスクを交換できます。 39RU M6 クラスタでは、非 RAID 対応ドライブの場合、システムの実行中はディスクを交換できません。ディスクを交換する前に、システムをシャットダウンする必要があります。 |
どのクラスタでも、RAID ホットスワップ対応な場合、ハードディスクには 正常(HEALTHY)、異常(UNHEALTHY)、および 新規(NEW)の 3 つの状態があります。異常(UNHEALTHY)のドライブが 正常(HEALTHY)状態に移行し、ストレージコントローラで RAID アレイ再構築プロセスが完了したらドライブを交換できます。
ディスクをデコミッション後、ディスクを取り外し、新しいディスクと交換します。このプロセスを支援するために、ディスクとサーバーのロケータ LED へのアクセス機能を交換ページに追加しました。サーバーとディスクロケータの LED がオフになっていることを確認します。
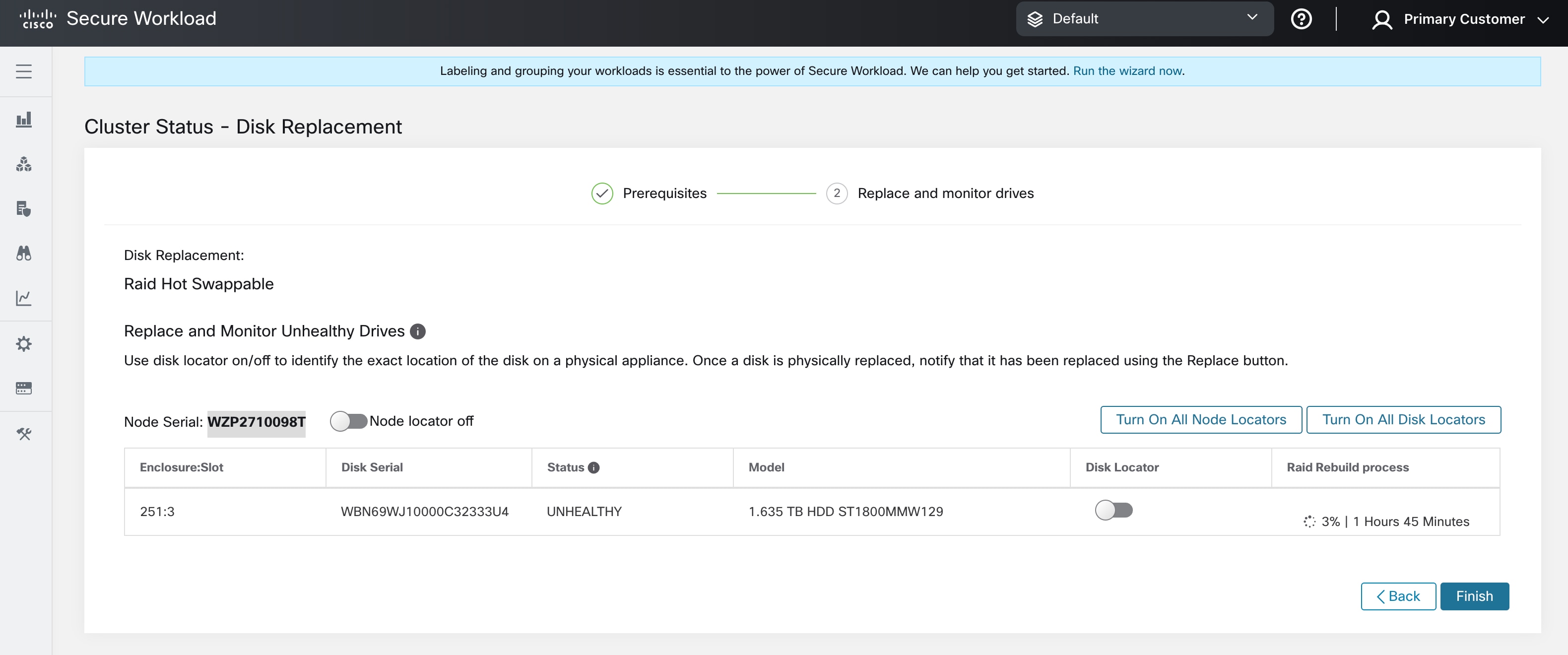
ディスクの物理的な交換は任意の順序で行えますが、再設定は特定のサーバーの最小スロット番号から最大スロット番号の順序で行う必要があります。この順序は、UI とバックエンドを通じて適用されます。UI では、ステータスが UNUSED で、スロット番号が最も小さいディスクの交換ボタンがアクティブになります。
すべてのディスクを交換したら、コミッションに進みます。デコミッションと同様に、コミッションを続行する前に一連の事前チェックを実行する必要があります。コミッションの進行状況は、ディスクコミッションページで監視します。コミッションが正常に終了すると、すべてのディスクのステータスが正常(HEALTHY)に変わります。
サーバーのホットスワップ非対応ドライブの場合、ホスト OS はサーバーの最初のドライブに保存されます。サーバーの最初のドライブ(スロット 1)に障害が発生すると、ほとんどの場合、ノード全体が非アクティブになり、デコミッションする必要があります。また、ドライブを交換し、サーバーを再イメージ化してシステムに再コミッションする必要があります。サポートについては、シスコテクニカルサポートにお問い合わせください。
RAID ホットスワップ対応サーバーでは、ハードウェア RAID5 が使用されます。ハードウェア RAID5 では、データブロックごとに 1 つのパリティブロックが保存されるため、そのサーバーで障害が発生しているドライブが 1 台である限り、システムは問題なく稼働し続けます。RAID ホットスワップ対応ドライブを搭載したサーバーで複数のドライブに障害が発生すると、ほとんどの場合、サーバーは非アクティブになり、コミッションする必要があります。また、ドライブを交換し、サーバーを再イメージ化してシステムに再コミッションする必要があります。サポートについては、シスコテクニカルサポートにお問い合わせください。
同じサーバーにある複数のホットスワップ非対応ドライブに障害が発生した場合は、UI の [交換(Replace)] ボタンをクリックして、各サーバーの一番低いスロット番号から一番高いスロット番号に変更します。
ホットスワップ非対応ドライブの [交換(Replace) ] ボタンをクリック後、UI でドライブが [交換済み(REPLACED)] から [新規(NEW)] に移行するまでに 3 ~ 10 分かかります。
RAID ホットスワップ対応ドライブを物理的に交換した後、再構築プロセスのステータスが UI に表示されるまでに 3 ~ 10 分かかります。
Cisco Secure Workload バージョン 3.8 を使用して展開された 39RU-G3 クラスタは、 RAID ホットスワップ対応ドライブを使用して構成されません。Cisco Secure Workload バージョン 3.9 を使用してクラスタを再展開するか、クラスタを Cisco Secure Workload バージョン 3.9 にアップグレードした後に、各 TA-BNODE-G3 および TA-CNODE-G3 を一度に 1 つずつデコミッション、再イメージ化、およびコミッションする必要がありクラスタ。TA-BNODE-G3 および TA-CNODE-G3 を RAID ホットスワップ対応ドライブに変換するデコミッション、再イメージ化、またはコミッション方式を使用する場合は、デコミッションを開始する前に、すべてのサービスのクラスタサービスステータスが緑色であることを確認します。
はじめる前に
正常でないディスクの交換プロセスを開始する前に、使用可能な新しいディスクがあることを確認します。
ディスク交換ウィザードには、交換が必要なすべてのディスクのサイズ、タイプ、製造元、およびモデルを含む、障害が発生したディスクの詳細が表示されます。また、スロット ID が表示され、交換が必要な各ディスクを使用するすべての VM が一覧表示されます。
Note |
物理的には、ドライブとハードウェアはホットスワップに対応しています。 |
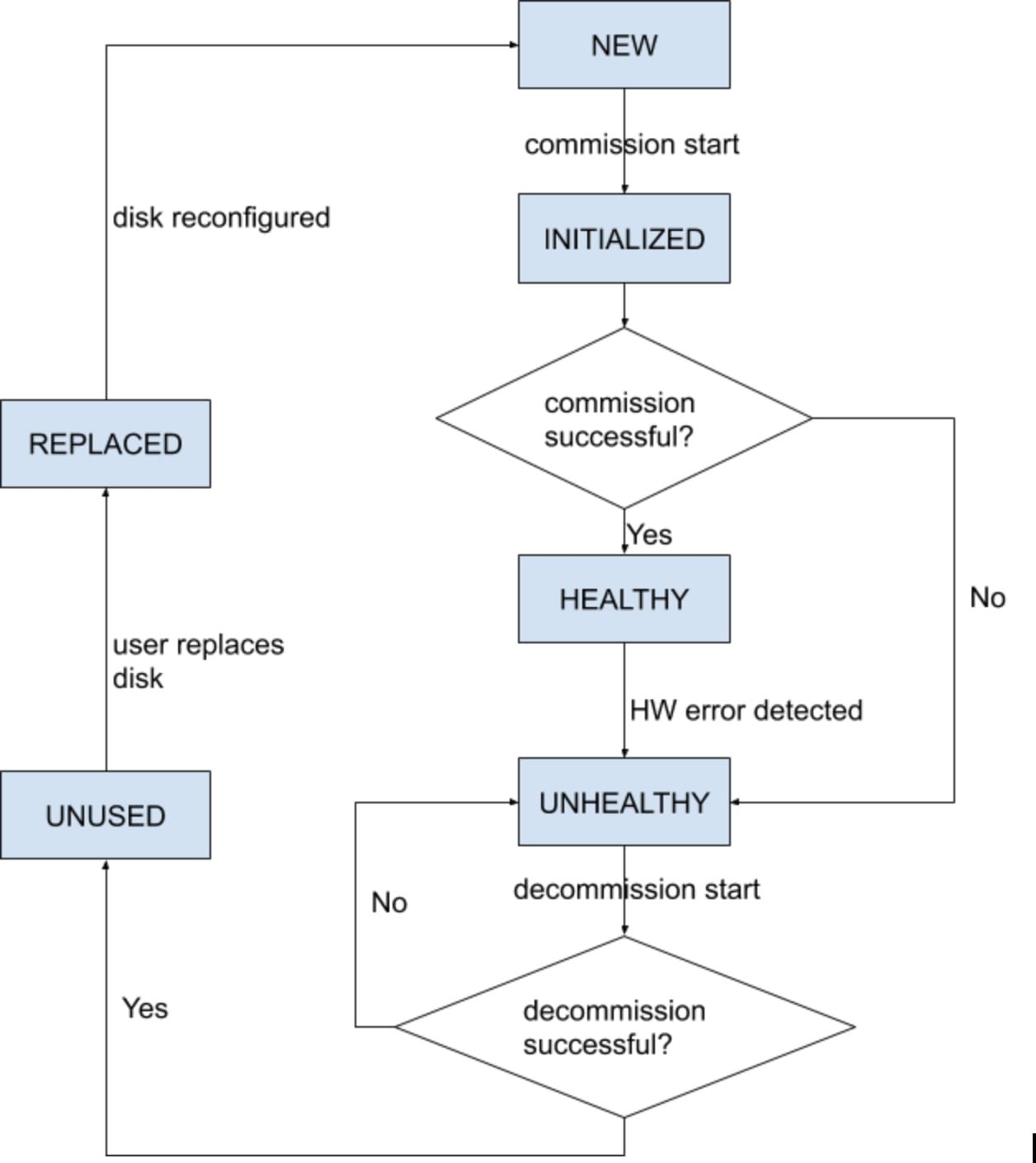
どのクラスタでも、非 RAID の場合、ハードディスクには正常(HEALTHY)、異常(UNHEALTHY)、未使用(UNUSED)、交換済み(REPLACED)、新規(NEW)、および初期化済み(INITIALIZED)の 6 つの状態があります。クラスタの展開またはアップグレード後、クラスタ内のすべてのディスクのステータスは正常(HEALTHY)です。さまざまなエラーが検出され、1 つ以上のディスクのステータスが異常(UNHEALTHY)に変わることがあります。
Note |
ホットスワップ非対応ドライブは、M4 および M5 クラスタでのみ使用できます。 |
ディスクのステータスが異常(UNHEALTHY)に変わらない限り、アクションは実行されません。ディスクのコミッションを開始する前に、デコミッションプロセスの一部として削除されたすべての VM を展開します。
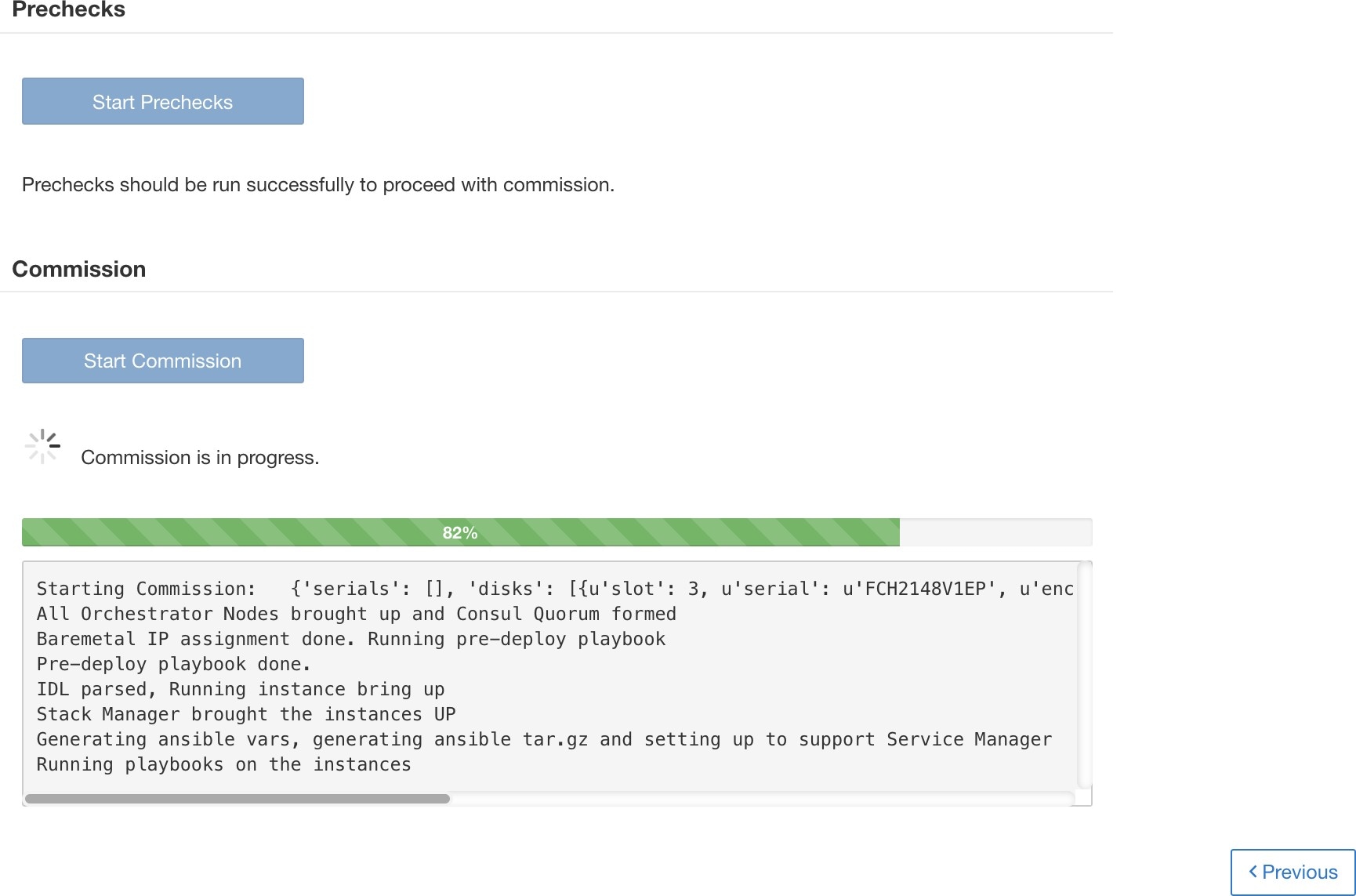
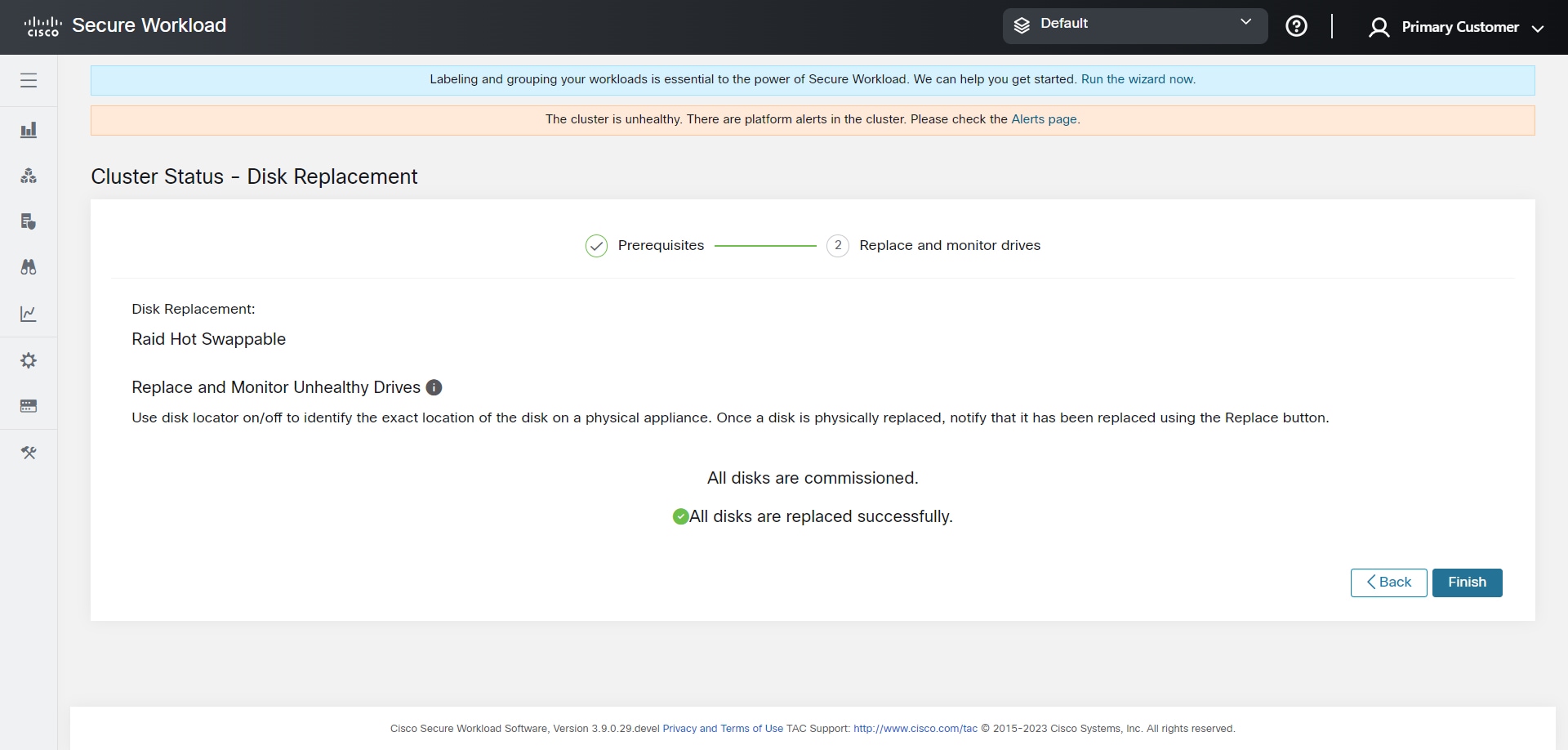
エラーが発生せずにディスクのコミッションが正常に完了すると、ディスクのステータスは正常(HEALTHY)に変わります。ディスクのコミッションに失敗した場合、ステータスは異常(UNHEALTHY)と表示されます。異常(UNHEALTHY)のディスクについて、ディスクデデコミッションのプロセスを開始します。デコミッションプロセスが成功すると、ディスクのステータスは未使用(UNUSED) に変わります。デコミッション中にディスクに障害が発生した場合は、ディスクのステータスが未使用(UNUSED)に変わるまでこのプロセスを繰り返します。
異常(UNHEALTHY)のディスクをクラスタから削除し、新しいディスクと交換すると、ステータスが交換済み(REPLACED)に変わります。交換用ディスクを再設定し、異常がないかハードウェアをスキャンします。異常が検出されない場合、ディスクのステータスは新規(NEW)に変わります。それ以外の場合は、問題のトラブルシューティングが必要である可能性があります。ステータスの移行には最大 3 分かかる場合があります。
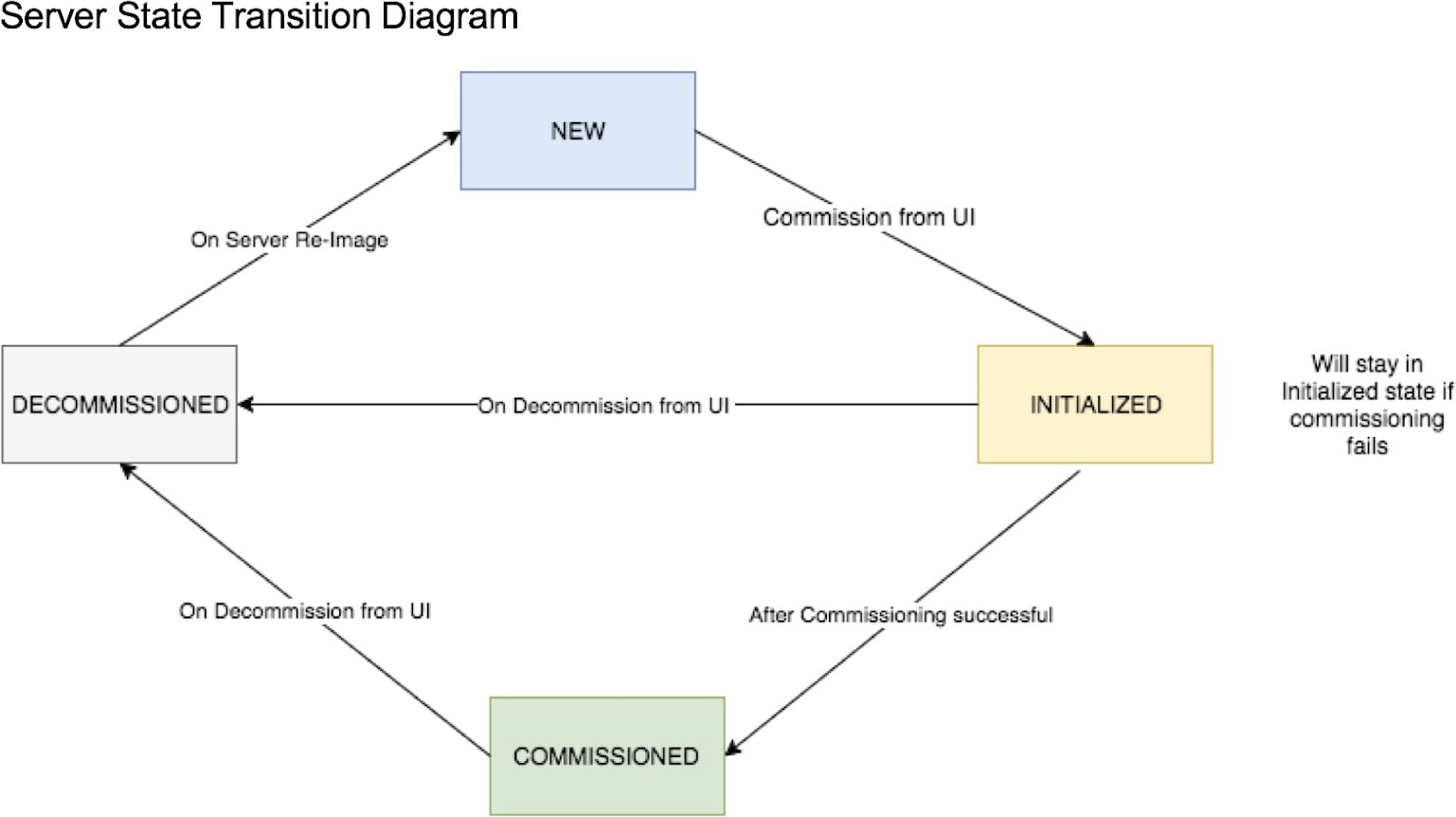
ディスクステータスの遷移がどのように処理されるかを理解するには、次のフロー図を参照してください。
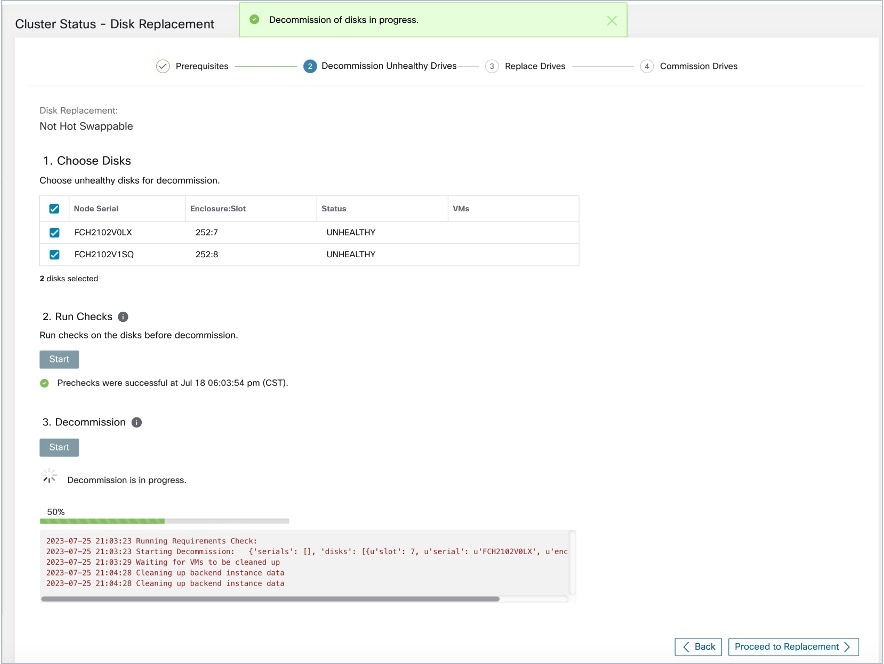
事前チェックに合格したら、ディスクのデコミッションに進めます。デコミッションの進行状況は、ディスク交換ウィザードに表示されます。デコミッションの進行状況が 100% に達すると、デコミッションされたすべてのディスクのステータスが UNUSED に変わります。
ディスクをデコミッション後、ディスクを取り外し、新しいディスクと交換します。このプロセスを支援するために、ディスクとサーバーのロケータ LED へのアクセス機能を交換ページに追加しました。サーバーとディスクロケータの LED がオフになっていることを確認します。
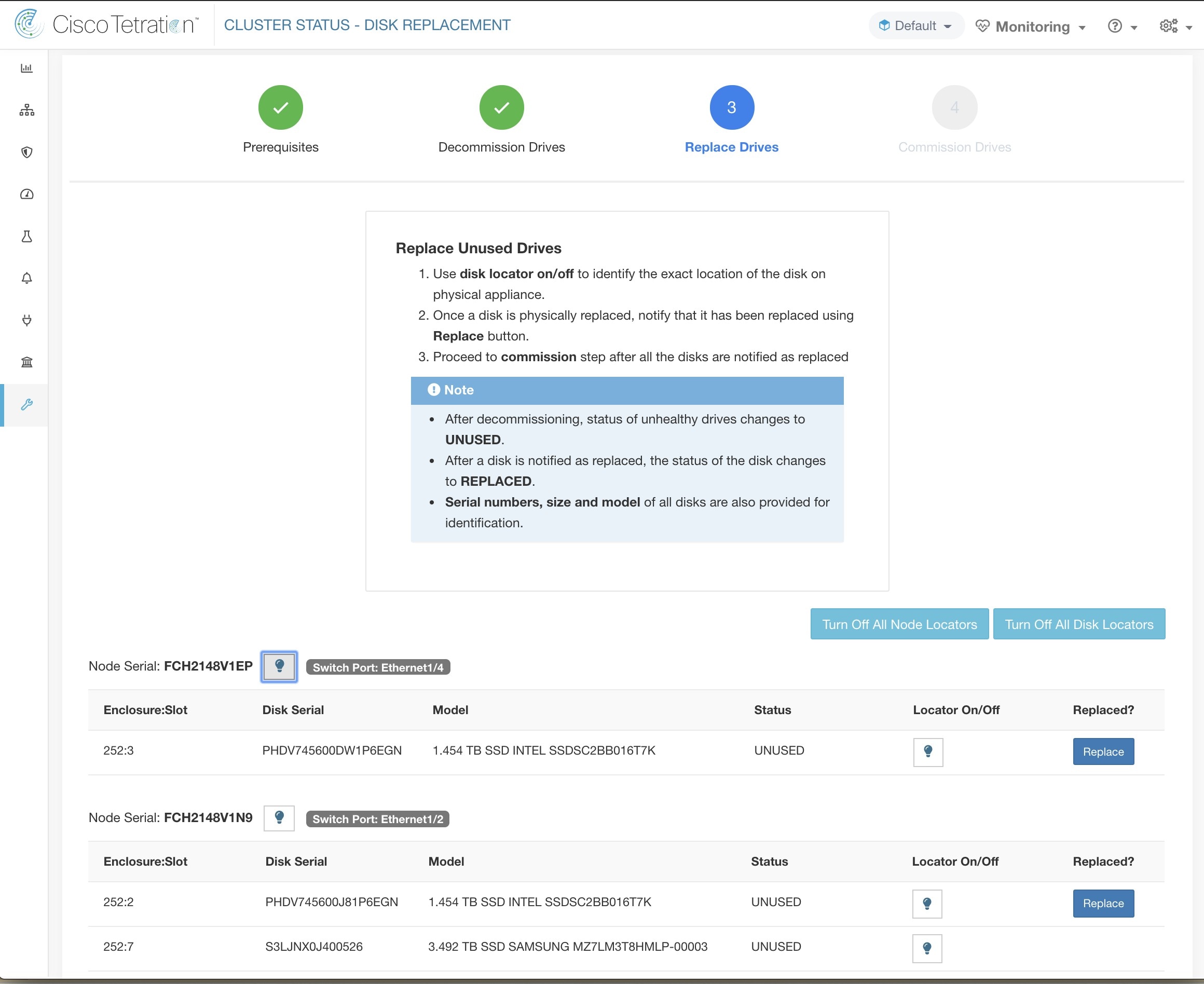
ディスクの物理的な交換は任意の順序で行えますが、再設定は特定のサーバーの最小スロット番号から最大スロット番号の順序で行う必要があります。この順序は、UI とバックエンドを通じて適用されます。UI では、ステータスが UNUSED で、スロット番号が最も小さいディスクの交換ボタンがアクティブになります。
すべてのディスクを交換したら、コミッションに進みます。デコミッションと同様に、コミッションを続行する前に一連の事前チェックを実行する必要があります。
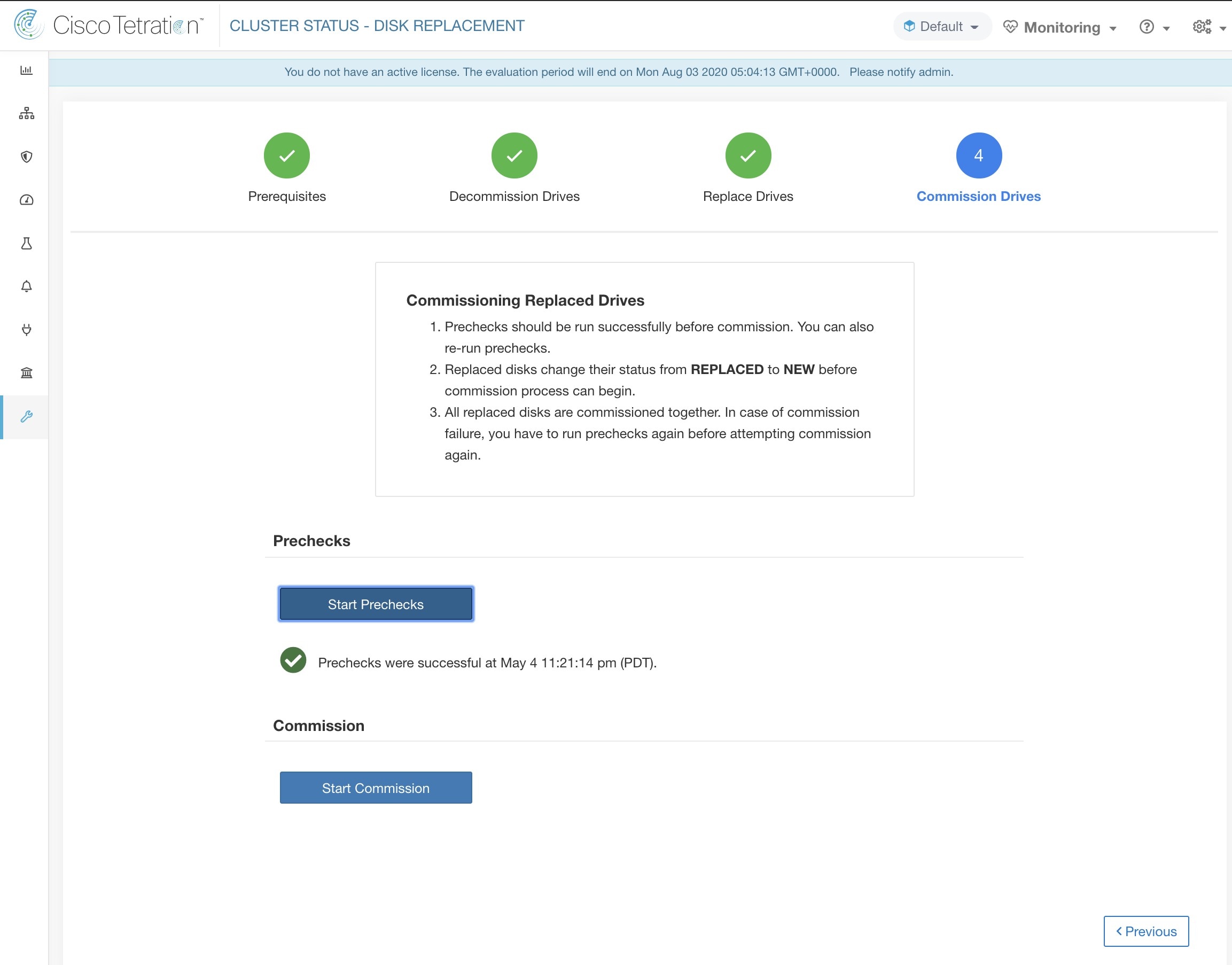
コミッションの進行状況は、ディスクコミッションページで監視します。コミッションが正常に終了すると、すべてのディスクのステータスが正常(HEALTHY)に変わります。
VM を展開後に障害が発生した場合は、[コミッションの再開(Resume Commission)] ボタンを使用して回復できます。ディスクのコミッションを続行するには、[コミッションの再開(Resume Commission)] ボタンをクリックして、展開後のプレイブックを再開します。
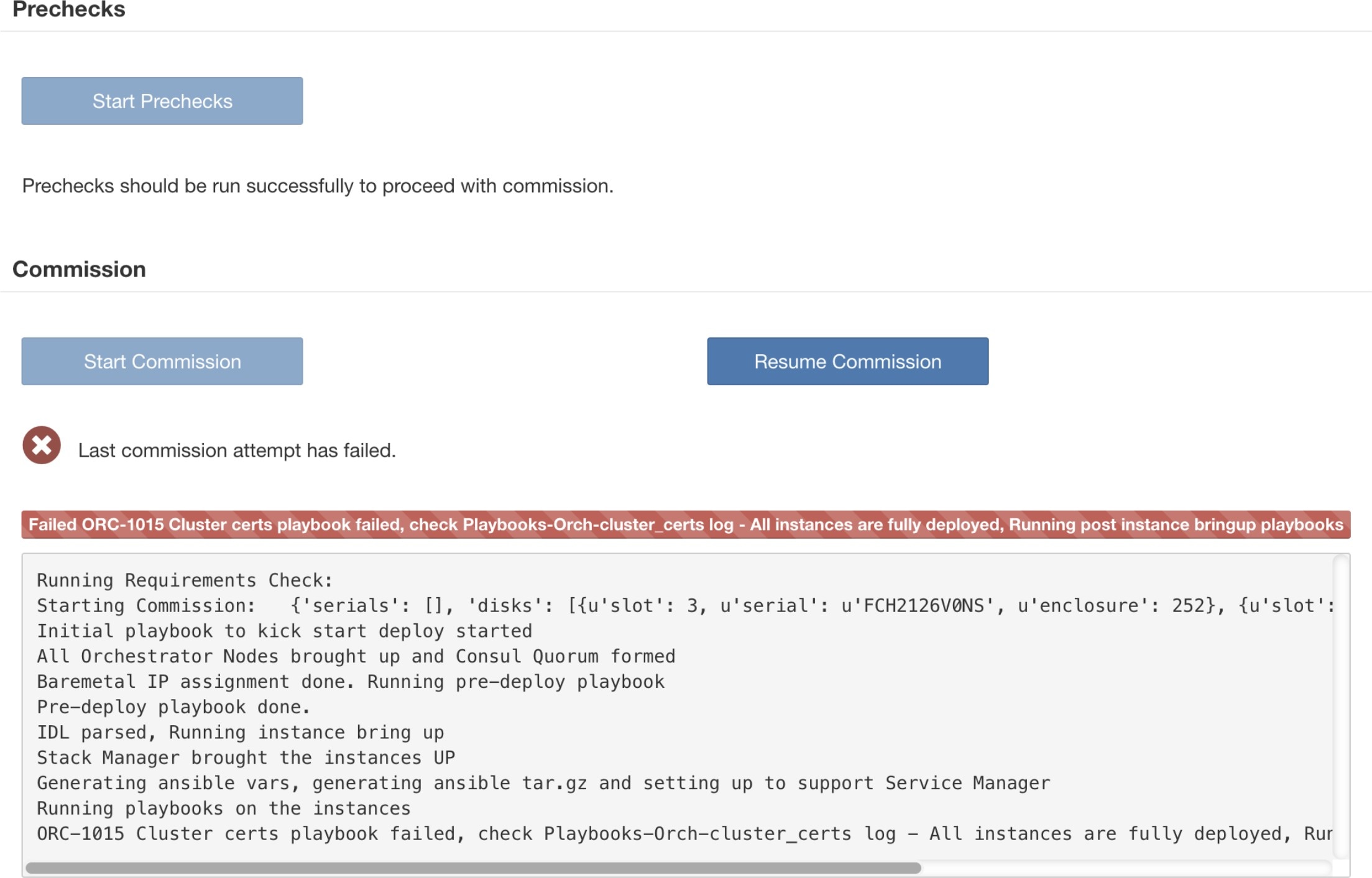
VM を展開する前に障害が発生した場合、コミッション中だったディスクのステータスは異常(UNHEALTHY)に変わります。そのため、交換プロセスは異常(UNHEALTHY)ディスクのデコミッションから再開する必要があります。
ディスクのコミッションの進行中に交換対象のディスク以外のディスクに障害が発生した場合、進行中のコミッションプロセスが成功または失敗した後に、ディスク交換ウィザードにこの障害に関する通知が表示されます。
再開可能な障害が発生した場合、ユーザーは次のステップについて 2 つのオプションから選択することができます。
現在のコミッションを再開および完了してから、新しい障害に対するディスク交換プロセスを試行できます。
または、新しく故障したディスクのデコミッションを開始し、すべてのディスクのコミッションをまとめて実行します。
この 2 番目の方法は、再開不可能な障害が発生した場合に使用できる唯一の方法です。新たに障害が発生したディスクが原因で展開後に障害が発生した場合、再開ボタンは使用できますが、やはり 2 番目の方法が唯一の方法になります。
サーバーのルートボリュームを含むディスクは、この手順では交換できません。このようなディスク障害は、サーバー メンテナンス プロセスを使用して修正する必要があります。
ディスクのコミッションは、すべてのサーバーがアクティブで、コミッション済みの状態にある場合にのみ実行できます。ディスクとサーバーの交換を組み合わせることが必要な場合の対応方法については、「特別な対処方法」の項を参照してください。
SSD ディスクは非常に高価であり、障害発生率も非常に低いため、この貴重なキャパシティを冗長データストレージに費やしたくありません。
最初に 3.8 ソフトウェアで展開された M6 クラスタでは、サーバーが 3.9 ソフトウェアでコミッションされると、RAID 設定が HDD ドライブに適用されます。これにより、クラスタには、RAID を使用したいくつかのノードと、3.8 以降の非 RAID ディスク設定を使用したいくつかのノードが含まれます。多くの場合、Cisco Secure Workload 39RU ハードウェアは、最初から 3.9 がインストールされた状態で出荷されますが、一部の初期の M6 は 3.8 が展開された状態で出荷されています。
3.9 ソフトウェアにアップグレードした後に、すべてのサーバーでサーバーのデコミッションとコミッションが段階的に実行された場合、クラスタを RAID に変換できます。
M6 8RU クラスタはすべて SSD ノードであり、RAID は SSD ドライブで設定されないため、8RU には RAID が実装されません。
古い世代(M4/M5)のドライブ設定では、これらの世代の Cisco Secure Workload ハードウェアで RAID をサポートできません。
ディスクとサーバーを同時にコミッションする必要がある障害シナリオでは、ユーザーは、デコミッション可能なすべてのディスクをデコミッションして交換する必要があります。事前チェックで以下ことが確認されるため、これらのディスクをコミッションすることはできません。
すべての正常でないディスクのステータスが新規(NEW)であること。
すべてのサーバーのステータスがアクティブで、コミッション済みの状態であること。
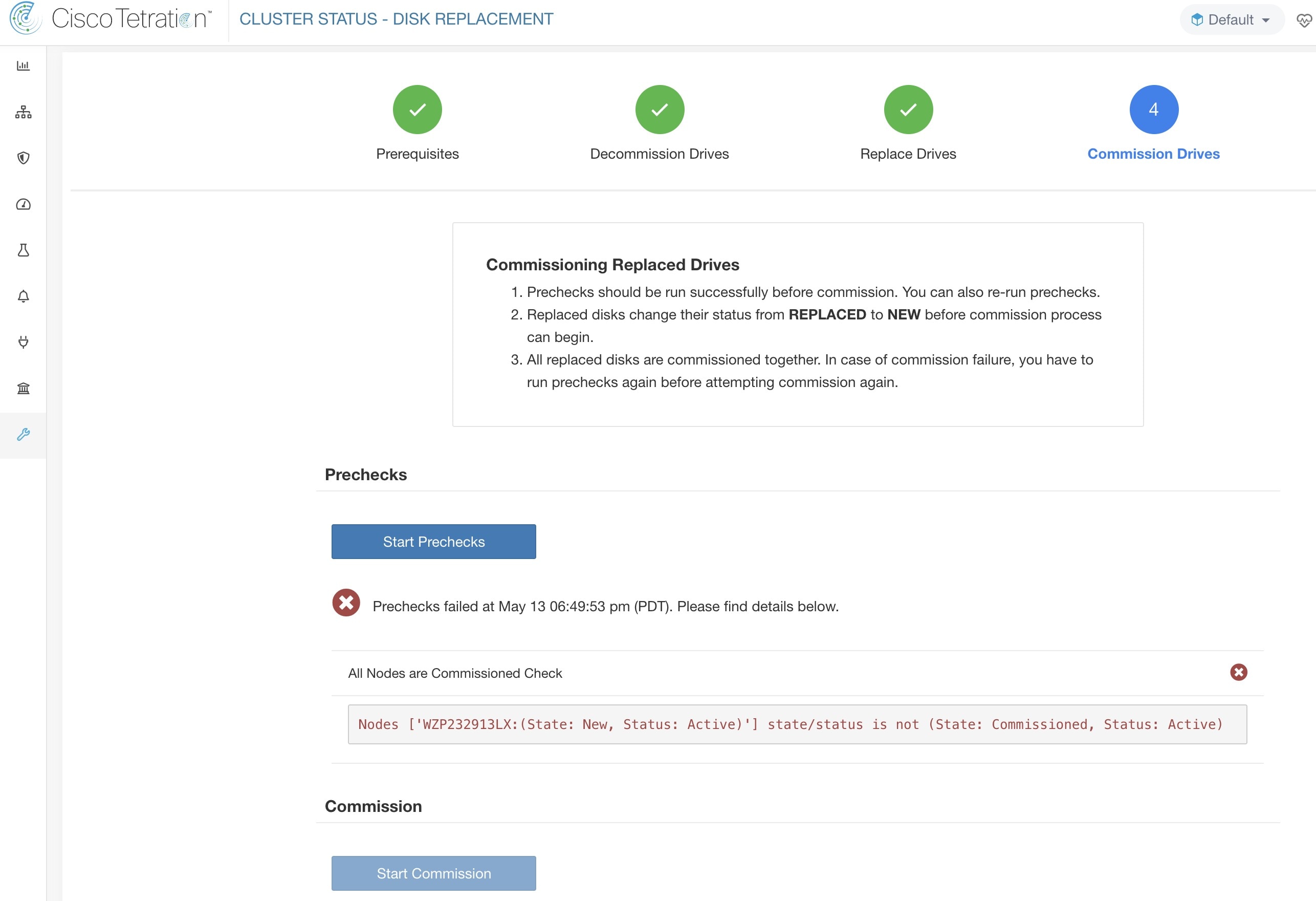
すべての異常(UNHEALTHY)ディスクが新規(NEW)状態になると、障害の発生したサーバーは、サーバーメンテナンス手順を使用してデコミッション/再イメージ化/再コミッションさせることが期待されます。
これで、ステータスが正常(HEALTHY)または新規(NEW)でないディスクがある場合、サーバーのコミッションが防止されます。サーバーのコミッションが成功すると、すべてのディスクのステータスも正常(HEALTHY)になります。
このセクションでは、クラスタ全体に影響を及ぼす 2 つのメンテナンス操作について説明します。
クラスタをシャットダウンすると、実行中のすべての Secure Workload プロセスが停止し、個々のノードの電源がすべてダウンします。クラスタをシャットダウンするには、次の手順を実行します。
|
Step 1 |
ナビゲーションウィンドウで、の順に選択します。 |
||
|
Step 2 |
[再起動/シャットダウン(Reboot/Shutdown)] タブをクリックします。 |
||
|
Step 3 |
[シャットダウン(Shutdown)] を選択し、[シャットダウンリンクの送信(Send Shutdown Link)] をクリックします。シャットダウンリンクが電子メールアドレスに配信されます。 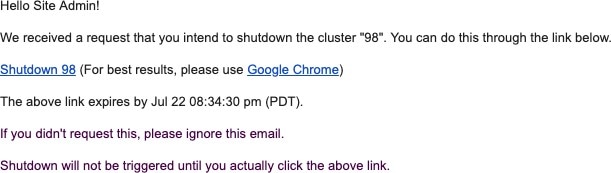
|
||
|
Step 4 |
[クラスタシャットダウン(Cluster Shutdown)] ページで、[シャットダウン(Shutdown)] をクリックします。
|
クラスタのシャットダウンを開始すると、シャットダウンの進行状況とステータスが表示されます。
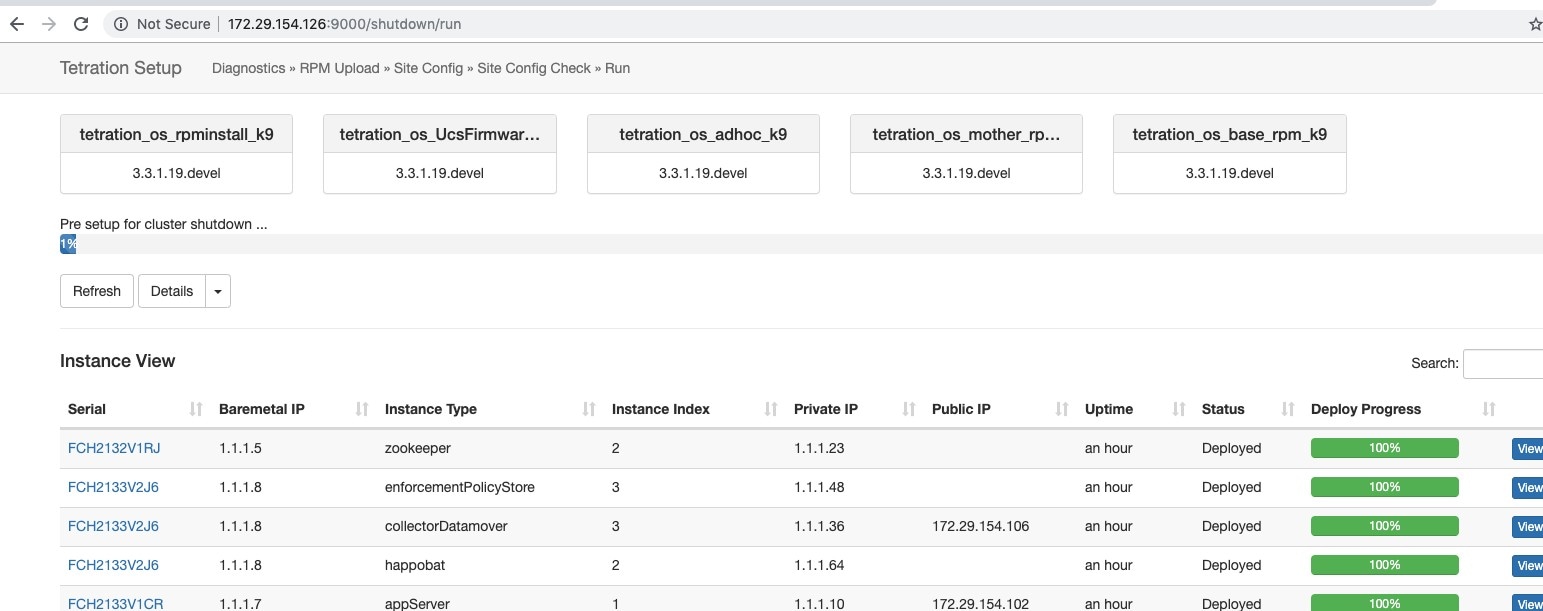
最初のシャットダウンの事前チェックでエラーが発生した場合、進行状況バーが赤くなります。エラーを修正後、再開ボタンをクリックしてシャットダウンを再開します。
事前チェックが完了すると、VM が停止します。VM が徐々に停止し、進行状況が表示されます。このページに表示される内容は、アップグレード時の VM の停止に似ています。詳細については、各フィールドのアップグレードセクションを参照してください。すべての VM が停止するまで、最大 30 分かかることがあります。
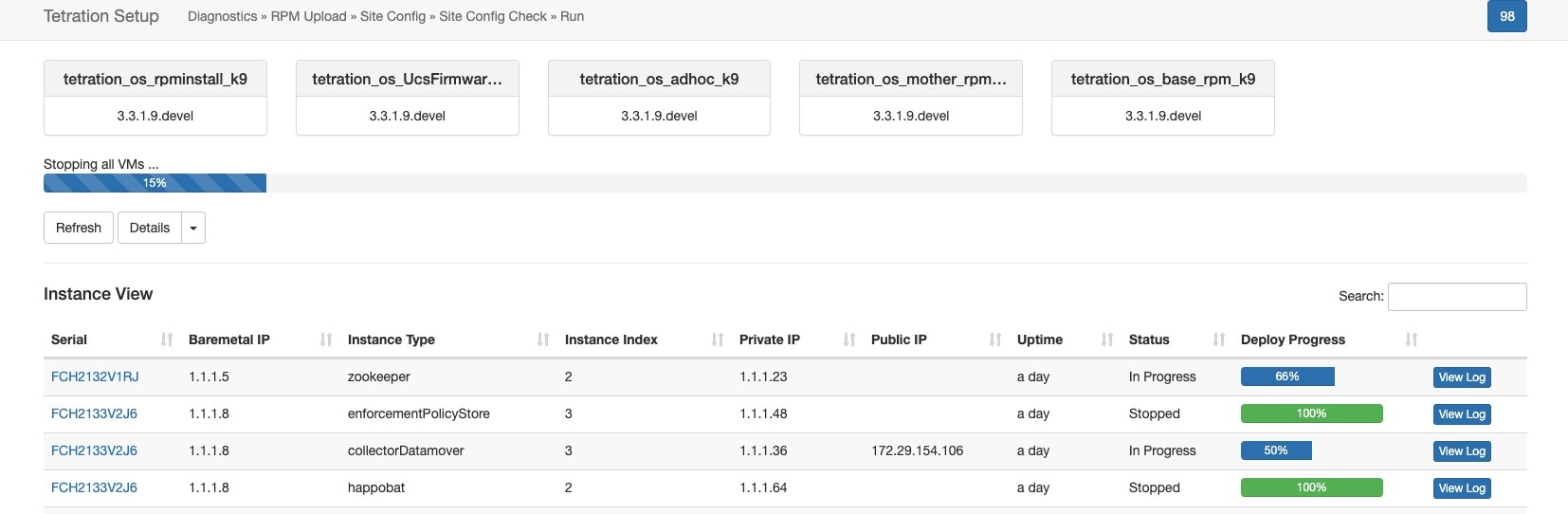
クラスタのシャットダウン準備が整うと、進行状況バーが 100% になり、クラスタの電源を安全に切断できる時刻が示されます。次のスクリーンショットで強調表示されている箇所を参照してください。
Note |
進行状況バーに表示される時刻を過ぎるまで、クラスタの電源を切らないでください。 |
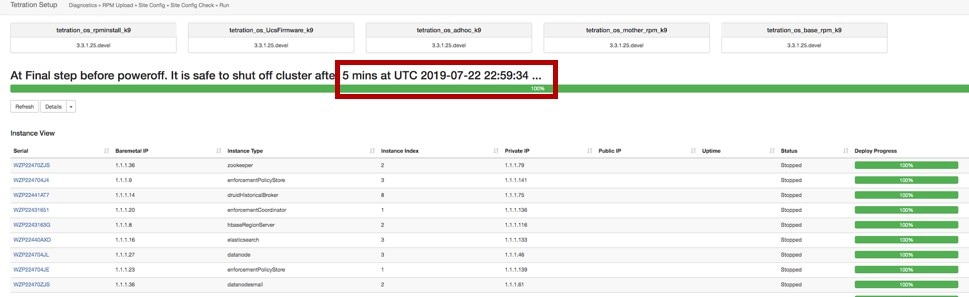
シャットダウン後にクラスタを回復するには、ベアメタルの電源をオンにします。個々のベアメタルがすべて起動すると、UI にアクセスできるようになります。クラスタにログインした後、クラスタを再起動してクラスタを動作可能な状態にします。
Note |
クラスタを動作可能な状態にするには、シャットダウン後にクラスタの再起動が必要です。 |
|
Step 1 |
ナビゲーションウィンドウで、の順に選択します。 |
|
Step 2 |
[再起動/シャットダウン(Reboot/Shutdown)] タブをクリックします。 |
|
Step 3 |
[再起動(Reboot)] を選択し、[再起動リンクを送信(Send Reboot Link)] をクリックします。 電子メール ID で受信したリンクをクリックして、クラスタを再起動します。セットアップ UI ページで、クラスタの再起動を開始します。再起動中は、制限付きのアップグレード操作が実行されます。 |
以前に実行したクラスタメンテナンスジョブを表示するには、次の手順を実行します。
に移動し、[履歴(History)] タブをクリックします。
[クラスタ操作(Cluster Operation)] 列には、クラスタのタスク(展開、アップグレード、再起動、シャットダウンなど)が一覧表示されます。
クラスタジョブのログをダウンロードするには、[ログのダウンロード(Download Logs)] をクリックします。
Caution |
|
Note |
クラスタ関連の問題のトラブルシューティングに [クラスタのリセット(Cluster Reset)] オプションを使用しないでください。このオプションは、必要な場合にのみ使用してください。 |
Cisco Technical Assistance Center に連絡して、クラスタをリセットする際の支援を得ることをお勧めします。
[リセット(Reset)] オプションは、すべてのサービスを停止し、Secure Workload クラスタ内のすべてのデータストアをクリアするために使用されます。リセットプロセスは、完了までに最大 6 時間かかります。クラスタがリセットされると、サービスは新たに初期化され、オンラインに戻ります。
Note |
|
|
Step 1 |
ナビゲーションウィンドウで、の順に選択します。 |
||
|
Step 2 |
[リセット(Reset)] をクリックして、次のアクションを実行します。
[リセット リンクの生成(Generate Reset Link)]を有効にする前に、次の必須の事前チェックが完了していることを確認してください。
|
||
|
Step 3 |
[Cisco Secure Workloadのセットアップ(Cisco Secure Workload Setup)] ページで、次のアクションを実行します。
|
Note |
Cisco Secure Workload UI は、クラスタのリセット中は使用できません。UI にアクセスできなくなった後の障害は再開できません。クラスタのトラブルシューティングと展開については、Cisco Technical Assistance Center にお問い合わせください。 |
クラスタのリセット操作中は、Cisco Secure Workload UI と [Cisco Secure Workloadのセットアップ(Secure Workload Setup)] ページに 20 ~ 30 分間アクセスできません。
クラスタは、パッチリリースではなく、基本の Cisco Secure Workloadリリースバージョンにリセットされます。クラスタをパッチリリースに手動でアップグレードします。パッチリリースへのアップグレード方法の詳細については、『Cisco Secure Workload アップグレードガイド』を参照してください。
クラスタをリセットするには、電子メールに記載されている IPv4 リンクを使用する必要があります。IPv6 リンクはサポートされていません。
クラスタのリセット中は、必要なサイト設定のみ編集でき、他のオプションは編集できません。
Note |
Secure Workload は、データタップ用に Kafka Broker 0.9.x、0.10.x、1.0.x、1.1.x への書き込みをサポートしています。 |
Secure Workload クラスタからアラートを送信するには、設定されたデータタップを使用する必要があります。データタップ管理者ユーザーは、新規または既存のデータタップを設定およびアクティブ化できます。ユーザーは自分のテナントのデータタップを表示できます。

データタップを管理するには、ナビゲーションウィンドウで、 の順に選択します。
推奨される Kafka 設定
Kafka クラスタを設定する場合、Secure Workload は Kafka の発信トラフィックに対して 9092、9093、または 9094 のポートを開くため、これらのポートを使用することを推奨します。
Kafka Broker の推奨設定は次のとおりです。
broker.id=<incremental number based on the size of the cluster>
auto.create.topics.enable=true
delete.topic.enable=true
listeners=PLAINTEXT://:9092
port=9092
default.replication.factor=2
host.name=<your_host_name>
advertised.host.name=<your_adversited_hostname>
num.network.threads=12
num.io.threads=12
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=<directory where logs can be written, ensure that there is sufficient space to hold the kafka journal logs>
num.partitions=72
num.recovery.threads.per.data.dir=1
log.retention.hours=24
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.cleaner.enable=false
zookeeper.connect=<address of zookeeper ensemble>
zookeeper.connection.timeout.ms=18000
データタップ管理セクション
[データタップ管理者(Data Tap Admins)] は、 に移動して、利用可能なデータタップを表示して設定できます。データタップは [テナント(Tenant)] ごとに設定されます。

新しいデータタップの追加
データタップ管理者は、 をクリックして新しいデータタップを追加できます。
をクリックして新しいデータタップを追加できます。
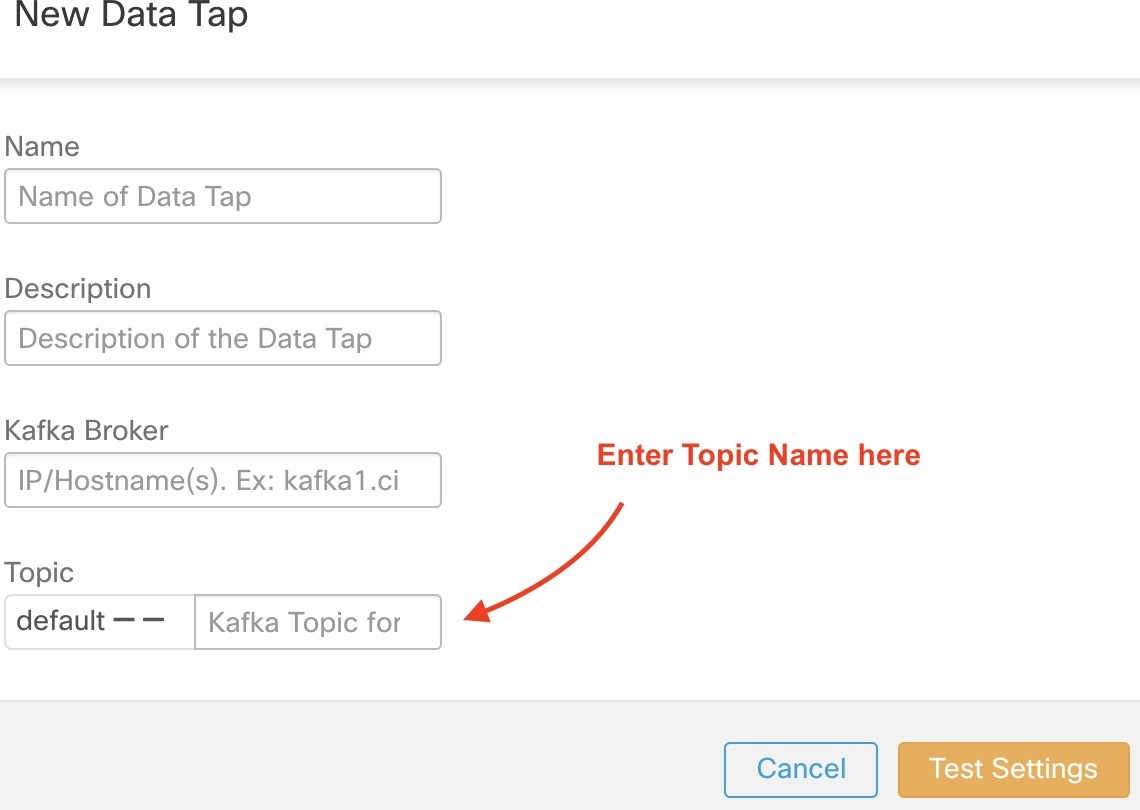
Note |
データタップの値を変更するには、設定を検証する必要があります。 |
データタップの非アクティブ化
データ管理者は、Secure Workload からの発信メッセージを一時的に停止するために、データタップを非アクティブ化できます。そのデータタップへのメッセージは送信されません。データタップはいつでも再開できます。

データタップの削除
データタップを削除すると、そのアプリケーションに依存するすべての Secure Workload アプリケーション インスタンスが削除されます。たとえば、ユーザーがコンプライアンスアラートを(Secure Workload アプリケーションアラートで)データタップ A に送信するように指定し、管理者がデータタップ A を削除した場合、アラートアプリケーションはデータタップ A をアラート出力対象にしなくなります。
管理対象データタップ(MDT)は、Secure Workload クラスタ内でホストされるデータタップで、認証、暗号化、承認に関しては安全です。MDT との間でメッセージを送受信するには、クライアントを認証する必要があり、ネットワーク経由で送信されるデータは暗号化され、承認されたユーザーのみが Secure Workload MDT との間でメッセージを読み書きできます。Secure Workload は、UI からダウンロードされるクライアント証明書を提供します。Secure Workload では Apache Kafka 1.1.0 がメッセージブローカとして使用されます。クライアントでは、同じバージョンと互換性のある安全なクライアントを使用することを推奨します。
MDT はルート範囲の作成後に自動的に作成されます。すべてのルート範囲には、作成されたアラート MDT があります。Secure Workload クラスタからアラートを取得するには、アラート MDT を使用する必要があります。データタップ管理者ユーザーのみ、証明書をダウンロードできます。ユーザーは自分のルート範囲の MDT を確認できます。

すべての Secure Workload アラートはデフォルトで MDT に送信されますが、別のデータタップに変更できます。
証明書は次の 2 つの方法でダウンロードできます。
Java キーストア:JKS 形式は Java クライアントに最適です。
証明書:通常の証明書は、Go クライアントで簡単に使用できます。

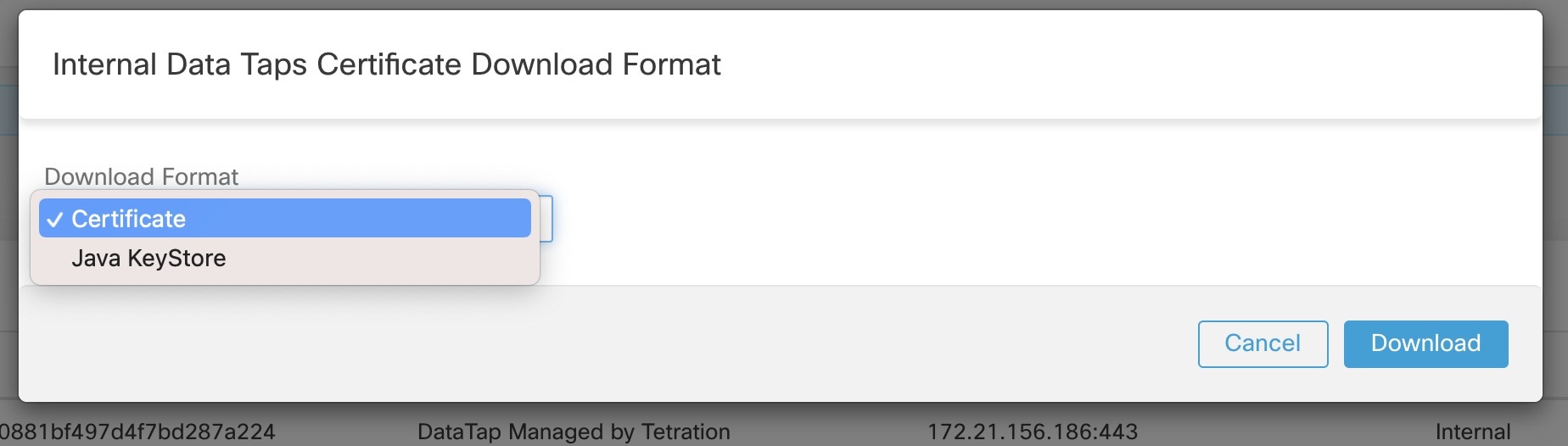
alerts.jks.tar.gz をダウンロードすると、Secure Workload MDT に接続してメッセージを受信するための情報を含む次のファイルが表示されます。
kafkaBrokerIps.txt:このファイルには、Kafka クライアントが Secure Workload MDT への接続に使用する IP アドレス文字列が含まれています。
topic.txt:このファイルには、このクライアントによるメッセージの読み取りが可能なトピックが含まれています。トピックは <root_scope_id> のトピック形式です。この root_scope_id は、Java クライアントで他のプロパティを設定するときに使用します。
keystore.jks:以下に示す接続設定で Kafka クライアントが使用するキーストアです。
truststore.jks:以下に示す接続設定で Kafka クライアントが使用するトラストストアです。
passphrase.txt:このファイルには、#3 と #4 で使用するパスワードが含まれています。
キーストアとトラストストアを使用する Consumer.properties(Java クライアント)を設定する際には、次の Kafka 設定を使用する必要があります。
security.protocol=SSL
ssl.truststore.location=<location_of_truststore_downloaded>
ssl.truststore.password=<passphrase_mentioned_in_passphrase.txt>
ssl.keystore.location=<location_of_truststore_downloaded>
ssl.keystore.password=<passphrase_mentioned_in_passphrase.txt>
ssl.key.password=<passphrase_mentioned_in_passphrase.txt>
Java コードで Kafka コンシューマを設定する際には、次のプロパティを使用します。
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("group.id", ConsumerGroup-<root_scope_id>); // root_scope_id is same as mentioned above
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("security.protocol", "SSL");
props.put("ssl.truststore.location", "<filepath_to_truststore.jks>");
props.put("ssl.truststore.password", passphrase);
props.put("ssl.keystore.location", <filepath_to_keystore.jks>);
props.put("ssl.keystore.password", passphrase);
props.put("ssl.key.password", passphrase);
props.put("zookeeper.session.timeout.ms", "500");
props.put("zookeeper.sync.time.ms", "250");
props.put("auto.offset.reset", "earliest");
証明書を使用する場合は、Sarama Kafka ライブラリを使用している Go クライアントを使用して Secure Workload MDT に接続します。alerts.cert.tar.gz をダウンロードすると、次のファイルが表示されます。
kafkaBrokerIps.txt:このファイルには、Kafka クライアントが Secure Workload MDT への接続に使用する IP アドレス文字列が含まれています。
topic:このファイルには、このクライアントによるメッセージの読み取りが可能なトピックが含まれています。トピックは <root_scope_id> のトピック形式です。この root_scope_id は、Java クライアントで他のプロパティを設定するときに使用します。
KafkaConsumerCA.cert:このファイルには、Kafka コンシューマの証明書が含まれています。
KafkaConsumerPrivateKey.key:このファイルには、Kafka コンシューマの秘密キーが含まれています。
KafkaCA.cert:このファイルは、Go クライアントのルート CA 証明書のリストで使用する必要があります。
Secure Workload MDT に接続する Goクライアントの例を表示するには、「Sample Go Client to consume alerts from MD」を参照してください。
 フィードバック
フィードバック{kind=link}