Cisco APIC Installation and ACI Upgrade and Downgrade Guide
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Check some basic information on your fabric to ensure that you have everything that you need for a smooth upgrade. Specifically,
it is critical that you clear all faults. Although some faults are described as specific issues in Check Configurations and Conditions That May Cause An Upgrade Failure, you should always clear any faults before performing an upgrade except for the faults that are expected due to configurations
in staging phase.
Clear all your faults
Perform a configuration export with AES Encryption
Verify access to out-of-band IP addresses of all your ACI nodes (all your APIC nodes and switch nodes)
Verify CIMC access for all your APICs
Verify console access for all your switches
Understand Changes in Behavior in Release Notes of both APIC and ACI switches for versions between the target and current version
Understand Open Issues and Known Issues in Release Notes of both APIC and ACI switches for the target version
Check Configurations and Conditions That May Cause An Upgrade Failure
The table below lists configurations and conditions that you should check to avoid upgrade failures or any known issues related
to upgrades.
The items in the table should be detected automatically by the pre-upgrade validator embedded in APIC. However, some items
might not be included in the APIC at this time or your APICs might be running a version that does not yet have the check implemented.
In those cases, you can run the Pre-Upgrade Validator app from dcappcenter.cisco.com, or use the standalone script referenced below.
Pre-Upgrade Validator (APIC): A validator embedded in the APIC Upgrade Configuration. This is automatically performed when configuring an update group
for APIC or switches.
Pre-Upgrade Validator (App Center app): A validator that can be installed on APICs as an app that can be downloaded through dcappcenter.cisco.com. This can be run
on demand and is supported on release 3.2 and later.
Script: For any feature not currently implemented in the Pre-Upgrade Validator, a standalone script can be run directly on the APIC
to validate any existing issues prior to upgrading. The script supports all versions of software. See https://github.com/datacenter/ACI-Pre-Upgrade-Validation-Script for more details about the script.
1 IPN connectivity is not checked by the pre-upgrade validator
Note
If the column does not have a checkbox next to the respective item, that means that the corresponding validation item is not
yet covered by that automated option.
Details of Configurations and Conditions for Pre-Upgrade Validations
All Your APICs Are In a Fully Fit State
Check the status in System > Dashboard > Controller to ensure that the cluster status on all your APICs is in a Fully Fit state. If one or more of the APICs are in other state, such as Data Layer Partially Diverged, you must resolve the status of your APIC cluster first.
If your APICs are currently on release 4.2(1) or later, the command acidiag cluster on each APIC CLI will check the basic items related to APIC clustering for you. If not, follow Initial Fabric Setup in ACI
Troubleshooting Guide 2nd Edition (http://cs.co/9003ybZ1d)
All Your ACI Switches Are In an Active State
Check Fabric > Inventory > Fabric Membership in the APIC GUI to ensure that all your ACI switches are in an Active state. If one or more of the ACI switches are in other state, such as Inactive, Maintenance and so on, you must resolve those issues first.
Inactive: This means that the switch has fabric discovery issues, such as IP reachability from APICs through the ACI infra network.
If your switches are currently on release 14.2(1) or later, the command show discoveryissues on the switch CLI will check the basic items related to switch fabric discovery for you.
Maintenance : This means that the switch is in Maintenance Mode through the GIR (Graceful Insertion and Removal) operation. This implies that the switch is isolated from the fabric and
does not process most of the APIC communications, including the upgrade-related communications. You must bring the switch
back to the Active state before you can perform an upgrade. If you want to gracefully upgrade the switch by isolating the switches from the
network first, consider Graceful Upgrade instead. See Graceful Upgrade of ACI Switches for details.
Check the APIC Upgrade/Downgrade Support Matrix for the supported UCS HUU version for your target APIC version to make sure all server components are running the version
from the supported HUU bundle.
Compatibility (APIC, Switch Hardware)
Check the Release Notes of both the APIC and ACI switches for the target version to make sure your hardware is supported.
Compatibility (Remote Leaf Switch)
It is critical to enable Direct Traffic Forwarding for remote leaf switches prior to upgrading to APIC release 5.0(1) as the option becomes mandatory starting from this release.
Direct Traffic Forwarding can be enabled starting from the APIC release 4.1(2). Note that additional configuration for TEP IP addresses such as Routable
Subnets or External TEP might be required for this option to be enabled. This means that if you are running a version prior
to 4.1(2) and you have remote leaf switch configured, you cannot directly upgrade to release 5.0. In this case, we recommend
that you upgrade to a 4.2 release, enable Direct Traffic Forwarding, and then upgrade to the desired 5.0 version.
A related issue is addressed in "Remote Leaf Switch with Direct Traffic Forwarding Enabled" (CSCvs16767). If you are upgrading
to the release 14.2(2) release while Direct Traffic Forwarding is enabled for the remote leaf nodes, you may hit a defect (CSCvs16767) that could cause remote leaf nodes to crash due to the Multicast FIB Distribution Manager (MFDM) process. This issue happens
only when spine nodes are upgraded to release 14.2(2) first while remote leaf nodes with Direct Traffic Forwarding are still on release 14.1(2). Note that Direct Traffic Forwarding was introduced in release 14.1(2).
To avoid this issue, it is critical that you upgrade to release 14.2(3) or a later release instead of release 14.2(2) when
Direct Traffic Forwarding is enabled.
If you must upgrade to release 14.2(2) for any reason, you must upgrade the remote leaf nodes first to avoid this issue.
NTP (Clocks Are Synchronized Across the Fabric)
Ensure that NTP is configured on both the APICs and the switches along with the necessary IP reachability to the NTP servers
through Out-of-band (OOB) or In-band (INB) from each individual node.
Implementation Change for Firmware Update Groups on APICs from Release 4.0(1)
Beginning with APIC release 4.0(1), there is only one type of switch update group instead of the two that were used in previous
releases (the firmware groups and maintenance groups). By consolidating two groups into one, the upgrade configurations are
simplified. However, when upgrading Cisco APICs from a pre-4.0 release to release 4.0(1) or later, you must remove all firmware
group and maintenance group policies prior to the upgrade.
To remove a firmware group policy, navigate to Admin > Firmware > Fabric Node Firmware > Firmware Groups, then right-click on the name of firmware group and choose Delete the Firmware Group.
To remove a maintenance group policy, navigate to Admin > Firmware > Fabric Node Firmware > Maintenance Groups, then right-click on the name of maintenance group and choose Delete the Maintenance Group.
Once the APICs are upgraded to 4.0(1) or later, you can create new switch update groups and perform the switch upgrade from
pre-14.0 release to 14.0(1) or later.
This is applicable only when you are upgrading your APICs from pre-4.0 to 4.0(1) or later. Once your APICs are on 4.0(1) or
later, you do not have to worry about this for any further upgrades.
Note
Internally, APICs running the 4.0(1) or later release handle the switch update groups with the same objects as the old maintenance
group policies (such as maintMaintP), but with additional attributes. If you are using an API to configure upgrade policies, you should only use maintenance
group policies starting from APIC release 4.0(1) or later without manually creating any firmware group policies, unlike the
old pre-4.0 releases.
Configurations That Must Be Disabled Prior To Upgrades
The following features must be disabled prior to upgrades:
Rogue Endpoint (only when the running version is 14.1(x) or when upgrading to 14.1(x))
Deprecated Managed Objects
The Pre_Upgrade checker script checks for the existence of the following deprecated managed objects on the running version
of the software and blocks the upgrade, if they exist in the configuration. You must update your script or code to use the
new managed object.
Class: config:RsExportDestination
Class: config:RsImportSource
Class: fabric:RsResMonFabricPol
Class: infra:RsResMonInfraPol
Class: fabric:RsResMonCommonPol
Class: trig:Triggered
Class: trig:TriggeredWindow
Class: fv:CCg
Class: fv:RsToCtrct
Class: mgmt:RsOobEpg
Class: mgmt:RsInbEpg
Class: vns:RsCIfAtt
Class: fault:RsHealthCtrlrRetP
Class: fv:PndgCtrctCont
Class: vz:RsAnyToCtrct
Class: fv:PndgCtrctEpgCont
Class: fv:AREpPUpd
Class: vns:Chkr
Class: aaa:RsFabricSetup
Class: ap:PluginPol
Class: tag:ExtMngdInst
Class: telemetry:Server
Class: telemetry:FltPolGrp
Class: telemetry:FilterPolicy
Class: telemetry:FlowServerP
Class: pol:RsFabricSelfCAEp
Class: fabric:PodDhcpServer
Class: fabric:SetupAllocP
Class: fabric:AssociatedSetupP
Class: cloud:AEPgSelector
Class: fv:VmmSelCont
All Switch Nodes In vPC
High availability (HA) is always the key in network design. There are multiple ways to achieve this, such as with server configurations
like NIC teaming, virtualization technology like VMware vMotion, or network device technology like link aggregation across
different chassis. ACI provides high availability using virtual Port Channel (vPC) as the link aggregation across chassis.
It is important to keep the traffic flowing even during upgrades by upgrading one switch in the same HA pair at a time. In
ACI, that will be a vPC pair unless you have other HA technologies on the server or virtualization side.
The Pre-Upgrade Validator checks if all switch nodes are in a vPC pair. This check is done when you upgrade APICs instead
of switches because in ACI, APICs are upgraded first prior to switches, and configuring a new vPC pair potentially requires
a network design change and that should be done prior to any upgrades. If you have other HA technologies in place, you can
ignore this validation. vPC is not a requirement for the upgrade to complete, but the built-in tools to prevent leaf switches
in a vPC domain from upgrading at the same time will not work if they are not in a vPC. If you are not using vPC, you must
ensure the switches being upgraded will not cause an outage if done at the same time.
APIC Disk Space Usage (F1527, F1528, F1529)
If an APIC is running low on disk space for any reason, the APIC upgrade can fail. The APIC will raise three different faults
depending on the amount of disk space remaining. If any of these faults are raised on the system, the issue should be resolved
prior to performing the upgrade.
F1527: A warning level fault for APIC disk space usage. This is raised when the utilization is between 80% and 85%.
F1528: A major level fault for APIC disk space usage. This is raised when the utilization is between 85% and 90%.
F1529: A critical level fault for APIC disk space usage. This is raised when the utilization is between 90% and above.
You can run the following moqueries on the CLI of any APIC to check if these faults exist on the system. The faults are visible within the GUI as well. In the
example below, with the faults against /firmware, you can simply remove unnecessary firmware images under Admin > Firmware in the APIC GUI. You should not perform the Linux command rm to remove an image directly from /firmware, as the firmware images are synchronized across APICs. If the fault is raised against a disk space that you are not aware
of, contact Cisco TAC to resolve the issue prior to the upgrade.
Fault Example (F1528: Major Fault for APIC disk space usage)
The following shows an example situation where the disk space in /firmware is running low on APIC 1 (node 1).
admin@apic1:~> moquery -c faultInst -f 'fault.Inst.code=="F1528"'
Total Objects shown: 1
# fault.Inst
code : F1528
ack : no
annotation :
cause : equipment-full
changeSet : available (Old: 5646352, New: 6036744), capUtilized (Old: 86, New: 85), used (Old: 33393968, New: 33003576)
childAction :
created : 2021-05-27T11:58:19.061-04:00
delegated : no
descr : Storage unit /firmware on Node 1 with hostname apic1 mounted at /firmware is 85% full
dn : topology/pod-1/node-1/sys/ch/p-[/firmware]-f-[/dev/mapper/vg_ifc0-firmware]/fault-F1528
domain : infra
extMngdBy : undefined
highestSeverity : major
lastTransition : 2021-05-27T12:01:37.128-04:00
lc : raised
modTs : never
occur : 1
origSeverity : major
prevSeverity : major
rn : fault-F1528
rule : eqpt-storage-full-major
severity : major
status :
subject : equipment-full
type : operational
uid :
Note that all three faults look the same except for the utilization percentage and the fault’s severity.
ACI Switch bootflash Usage
ACI switches mainly have two different faults about the filesystem usage of each partition:
F1820: A minor level fault for switch partition usage. This is raised when the utilization of the partition exceeds the minor threshold.
F1821: A major level fault for switch partition usage. This is raised when the utilization of the partition exceeds the major threshold.
The threshold for minor and major depends on partitions. The critical one for upgrades is /bootflash. The threshold of bootflash
is 80% for minor and 90% for major threshold.
On top of this, there is a built-in behavior added to every switch node where it will take action to ensure that the /bootflash
directory maintains 50% capacity. This is specifically to ensure that switch upgrades are able to successfully transfer and
extract the switch image over during an upgrade.
To do this, there is an internal script that is monitoring /bootflash usage and, if over 50% usage, it will start removing
files to free up the filesystem. Given its aggressiveness, there are some corner case scenarios where this cleanup script
could potentially trigger against the switch image it is intending to use, which can result in a switch upgrade booting a
switch into the loader prompt given that the boot image was removed from /bootflash.
To prevent this, check the /bootflash prior to an upgrade and take the necessary steps to understand what is written there
and why. Once understood, take the necessary steps to clear up unnecessary /bootflash files to ensure there is enough space
to prevent the auto-cleanup corner case scenario.
The Pre-Upgrade Validator (both APIC and App) monitors the fault F1821, which can capture the high utilization of any partition.
When this fault is present, we recommend that you resolve it prior to the upgrade even if the fault is not for bootflash.
The ACI Pre-Upgrade Validation script described earlier in this chapter focuses on the utilization of bootflash on each switch
specifically to see if there are any issues with bootflash where the usage is more than 50%, which might trigger the internal
cleanup script.
You can run either the Pre-Upgrade Validator or the script to check this issue. Following is the detailed information regarding
the internal cleanup of bootflash with 50% threshold.
Validation
Once logged into a leaf switch CLI, /bootflash usage can be checked using df -h:
You can run the following moquery on the CLI of any APIC to check the usage of bootflash of each switch node.
f2-apic1# moquery -c eqptcapacityFSPartition -f
'eqptcapacity.FSPartition.path=="/bootflash"'
Total Objects shown: 6
# eqptcapacity.FSPartition
name : bootflash
avail : 7214920
childAction :
dn : topology/pod-1/node-101/sys/eqptcapacity/fspartition-bootflash
memAlert : normal
modTs : never
monPolDn : uni/fabric/monfab-default
path : /bootflash
rn : fspartition-bootflash
status :
used : 4320184
MD5sum Check for APIC and Switch Firmware
When performing an upgrade in an ACI fabric, there are multiple image transfers that must occur to prepare all nodes for upgrades.
Most of these transfers perform a first level image validation. However, in the event of a failure, there is value in double-checking
the image on each respective node.
Upgrade Image transfer touchpoints:
Transfer the image onto your desktop/file server from cisco.com.
Manually run MD5 against this image. You can validate the expected MD5 of the image from cisco.com.
Upload the image from your desktop or ftp server onto one of the APICs.
See the Downloading APIC and Switch Images on APICs section in the appropriate chapter for instructions on performing this operation on APICs:
The APIC will automatically perform an image validation and raise a fault F0058 if the image looks corrupt or incomplete once
the transfer has completed.
Once the image is added into the firmware repository, the initially uploaded APIC will copy that image to the remaining APICs
in the cluster.
You can manually check MD5 on each APIC's copy of the upgrade image by running the md5sum command against each APIC's copy of the image.
After the image is downloaded to one of the APICs, the image is synchronized to all APICs in the cluster. This is critical
especially for APIC images because each APIC needs the image locally to upgrade itself.
To do so, you can login to each APIC and check /firmare/fwrepos/fwrepo for the target image.
If the image is missing in one or more of APICs, wait for about 5 min if it’s right after the download. If the image is still
missing, ensure that the APIC clustering status is healthy on all of the APICs and remove the image from the GUI or API (but
not with the Linux command rm), then re-download the image to trigger the file synchronization again. If the image is still missing, contact Cisco TAC.
Filesystem on Standby APICs
Because a standby APIC is a cold standby and is not part of the cluster, it is not actively monitored for fault conditions.
As filesystem full checks falls under this category, this means that any standby APICs exhibiting these conditions will not
flag a fault and instead must be manually verified.
To do so, you can login to a standby APIC as rescue-user, then run df -h to manually verify the filesystem usage.
If any filesystem is found to be at 75% or above, contact TAC to identify and clear out the condition.
EPG Configuration on Ports Connected to APICs (F0467: port-configured-for-apic)
In a healthy ACI deployment, there should be no EPG or policy deployment pushed to any interfaces where an APIC controller
is connected. When an APIC is connected to a leaf switch, LLDP validation occurs between the APIC and the leaf switch to allow
it into the fabric without any configuration by the user. When a policy is pushed to a leaf switch interface that is connected
to an APIC, that configuration will be denied and a fault will be raised. However, if the link to the APIC flaps for any reason,
primarily during an upgrade when the APIC reboots, the policy can then be deployed to that leaf switch interface. This results
in the APIC being blocked from re-joining the fabric after it has reloaded.
It is critical that you resolve these issues before the upgrade to prevent any issues. You can run the moquery below on the
CLI of any APIC to check if these faults exist on the system. The faults are visible within the GUI as well.
Fault Example (F0467: port-configured-for-apic):
The following fault shows an example of node 101 eth1/1 that is connected to an APIC that has some EPG configurations on it.
admin@apic1:~> moquery -c faultInst -x 'query-target-filter=wcard(faultInst.descr,"port-configured-for-apic")'
Total Objects shown: 1
# fault.Inst
code : F0467
ack : no
annotation :
cause : configuration-failed
changeSet : configQual:port-configured-for-apic, configSt:failed-to-apply, debugMessage:port-configured-for-apic: Port is connected to the APIC;, temporaryError:no
childAction :
created : 2021-06-03T07:51:42.263-04:00
delegated : yes
descr : Configuration failed for uni/tn-jr/ap-ap1/epg-epg1 node 101 eth1/1 due to Port Connected to Controller, debug message: port-configured-for-apic: Port is connected to the APIC;
dn : topology/pod-1/node-101/local/svc-policyelem-id-0/uni/epp/fv-[uni/tn-jr/ap-ap1/epg-epg1]
/node-101/stpathatt-[eth1/1]/nwissues/fault-F0467
domain : tenant
extMngdBy : undefined
highestSeverity : minor
lastTransition : 2021-06-03T07:53:52.021-04:00
lc : raised
modTs : never
occur : 1
origSeverity : minor
prevSeverity : minor
rn : fault-F0467
rule : fv-nw-issues-config-failed
severity : minor
status :
subject : management
type : config
uid :
This is another type of the F0467 fault code family that you should check before an upgrade. This fault alerts that an interface
configured under a Layer3 Out (L3Out) has failed because the port that the policy is deployed for is operating in the opposite
mode. For example, you might have configured a routed sub-interface under an L3Out, making the port an L3 port. However, there
is already L2 policy on that port. A port in ACI can either be L2 or L3, but not both, just like a port on any layer 3 switches
that can be either “switchport” (L2) or “no switchport” (L3), so this policy fails in this situation. The same rule applies if a port is already an L3 port, but you deploy L2 config
onto it. After an upgrade, it’s possible that the previously working configuration will break if this faulty policy is deployed
first after the switch reloads.
It is critical that you resolve these issues before the upgrade to prevent any issues. The interface that the fault is raised
on should either be corrected or deleted in order to clear the fault. You can run the moquery below on the CLI of any APIC
to check if these faults exist on the system. The faults are visible within the GUI as well.
Fault Example (F0467: port-configured-as-l2):
The following fault shows an example of the configuration from L3Out OSPF under tenant jr has failed on node 101 eth1/7 because the same port is already configured as L2 by other components, such
as EPGs or other L3Outs using the same port as SVI. It implies that, in this case, L3Out OSPF is trying to use node 101 eth1/7 as a routed port or routed sub-interface (L3) as opposed to SVI (L2).
admin@apic1:~> moquery -c faultDelegate -x 'query-target-filter=wcard(faultInst.changeSet,"port-configured-as-l2")'
Total Objects shown: 1
# fault.Delegate
affected : resPolCont/rtdOutCont/rtdOutDef-[uni/tn-jr/out-OSPF]/node-101/stpathatt-[eth1/7]/nwissues
code : F0467
ack : no
cause : configuration-failed
changeSet : configQual:port-configured-as-l2, configSt:failed-to-apply, temporaryError:no
childAction :
created : 2021-06-23T12:17:54.775-04:00
descr : Fault delegate: Configuration failed for uni/tn-jr/out-OSPF node 101 eth1/7 due to Interface Configured as L2, debug message:
dn : uni/tn-jr/out-OSPF/fd-[resPolCont/rtdOutCont/rtdOutDef-[uni/tn-jr/out-OSPF]/node-101/
stpathatt-[eth1/7]/nwissues]-fault-F0467
domain : tenant
highestSeverity : minor
lastTransition :2021-06-23T12:20:09.780-04:00
lc : raised
modTs : never
occur : 1
origSeverity : minor
prevSeverity : minor
rn : fd-[resPolCont/rtdOutCont/rtdOutDef-[uni/tn-jr/out-OSPF]/node-101/stpathatt-[eth1/7]/nwissues]-fault-F0467
rule : fv-nw-issues-config-failed
severity : minor
status :
subject : management
type : config
Fault Example (F0467: port-configured-as-l3):
The following fault shows an example of the opposite of above situation. In this example, L3Out IPV6 tries to use node 101 eth1/7 as an L2 port and it failed because other L3Outs are already using the same port as an L3 port.
admin@apic1:~> moquery -c faultDelegate -x 'query-target-filter=wcard(faultInst.changeSet,"port-configured-as-l3")'
Total Objects shown: 1
# fault.Delegate
affected : resPolCont/rtdOutCont/rtdOutDef-[uni/tn-jr/out-IPV6]/node-101/stpathatt-[eth1/7]/nwissues
code : F0467
ack : no
cause : configuration-failed
changeSet : configQual:port-configured-as-l3, configSt:failed-to-apply, debugMessage:port-configured-as-l3: Port has one or more layer3 sub-interfaces;, temporaryError:no
childAction :
created : 2021-06-23T12:31:41.949-04:00
descr : Fault delegate: Configuration failed for uni/tn-jr/out-IPV6 node 101 eth1/7 due to Interface Configured as L3, debug message: port-configured-as-l3: Port has one or more layer3 sub-interfaces;
dn : uni/tn-jr/out-IPV6/fd-[resPolCont/rtdOutCont/rtdOutDef-[uni/tn-jr/out-IPV6]/node-101/
stpathatt-[eth1/7]/nwissues]-fault-F0467
domain : tenant
highestSeverity : minor
lastTransition : 2021-06-23T12:31:41.949-04:00
lc : soaking
modTs : never
occur : 1
origSeverity : minor
prevSeverity : minor
rn : fd-[resPolCont/rtdOutCont/rtdOutDef-[uni/tn-jr/out-IPV6]/node-101/stpathatt-[eth1/7]/nwissues]-fault-F0467
rule : fv-nw-issues-config-failed
severity : minor
status :
subject : management
type : config
Conflicting L3Out Subnets for Contracts (F0467: prefix-entry-already-in-use)
There is another type of the F0467 fault code family that you should check before an upgrade. This fault alerts that an external
EPG defined under a Layer3 Out (L3Out) has a subnet with the “External Subnet for the External EPG” scope configured that overlaps with another L3Out external EPG in the same VRF. After an upgrade, it’s possible that the
previous working configuration will break if this faulty policy is deployed first after the switch reloads.
It is critical that you resolve these issues before the upgrade to prevent any unexpected outages when the switch(es) upgrade.
The subnet that the fault is raised on should either be corrected or deleted in order to clear the fault. You can run the
moquery below on the CLI of any APIC to check if these faults exist on the system. The faults are visible within the GUI as
well.
Fault Example (F0467: prefix-entry-already-in-use):
The following shows an example of L3Out OSPF with an external EPG called all. In this external EPG, an L3Out subnet 112.112.112.112/32 is configured with “External Subnet for the External EPG” in the attempt to classify the source or destination IP address of packets to this external EPG for contracts application.
However, it failed because the same subnet is already in use by another external EPG in the same VRF.
admin@apic1:~> moquery -c faultInst -x'query-target-filter=wcard(faultInst.descr,"prefix-entry-already-in-use")'
Total Objects shown: 1
# fault.Inst
code : F0467
ack : no
annotation :
cause : configuration-failed
changeSet : configQual:prefix-entry-already-in-use, configSt:failed-to-apply, debugMessage:prefix-entry-already-in-use: Prefix entry sys/ctx-[vxlan-2621440]/pfx-[112.
112.112.112/32] is in use;, temporaryError:no
childAction :
created : 2021-06-22T09:02:36.630-04:00
delegated : yes
descr : Configuration failed for uni/tn-jr/out-OSPF/instP-all due to Prefix Entry Already Used in Another EPG, debug message: prefix-entry-already-in-use: Prefix
entry sys/ctx-[vxlan-2621440]/pfx-[112.112.112.112/32] is in use;
dn : topology/pod-1/node-101/local/svc-policyelem-id-0/uni/epp/rtd-[uni/tn-jr/out-OSPF/instP-all]/nwissues/fault-F0467
domain : tenant
extMngdBy : undefined
highestSeverity : minor
lastTransition : 2021-06-22T09:04:51.985-04:00
lc : raised
modTs : never
occur : 1
origSeverity : minor
prevSeverity : minor
rn : fault-F0467
rule : fv-nw-issues-config-failed
severity : minor
status :
subject : management
type : config
uid :
Overlapping BD Subnets In the Same VRF (F0469: duplicate, F1425: subnet-overlap)
If at any point in time an overlapping IP address or subnet is deployed within a VRF, that policy will fail and a fault will
be raised at the node level. However, on upgrade, it’s possible that this previously failing configuration will get pushed
to the leaf switch before the previously working configuration. This results in a situation where the known working state
before the upgrade is broken after the upgrade, and can cause connectivity issues for the previously working subnet.
There are two faults for this situation:
F0469 (duplicate-subnets-within-ctx) is raised when multiple BD subnets are configured with the exact same subnet in the same
VRF
F1425 (subnet-overlap) is raised when BD subnets are not the same but overlapping
It is critical that you resolve these issues before the upgrade to prevent any issues. The subnet that the fault is raised
on should either be corrected or deleted in order to clear the fault. You can run the moquery below on the CLI of any APIC
to check if these faults exist on the system. The faults are visible within the GUI as well.
Fault Example (F0469: duplicate-subnets-within-ctx):
admin@f1-apic1:~> moquery -c faultInst -f 'fault.Inst.code=="F0469"'
Total Objects shown: 4
# fault.Inst
code : F0469
ack : no
annotation :
cause : configuration-failed
changeSet : configQual (New: duplicate-subnets-within-ctx), configSt (New: failed-to-apply), debugMessage (New: uni/tn-TK/BD-BD2,uni/tn-TK/BD-BD1)
childAction :
created : 2021-07-08T17:40:37.630-07:00
delegated : yes
descr : BD Configuration failed for uni/tn-TK/BD-BD2 due to duplicate-subnets-within-ctx: uni/tn-TK/BD-BD2 ,uni/tn-TK/BD-BD1
dn : topology/pod-1/node-101/local/svc-policyelem-id-0/uni/bd-[uni/tn-TK/BD-BD2]-isSvc-no/bdcfgissues/fault-F0469
domain : tenant
extMngdBy : undefined
highestSeverity : minor
lastTransition : 2021-07-08T17:40:37.630-07:00
lc : soaking
modTs : never
occur : 1
origSeverity : minor
prevSeverity : minor
rn : fault-F0469
rule : fv-bdconfig-issues-config-failed
severity : minor
status :
subject : management
type : config
uid :
Fault Example (F1425: subnet-overlap):
admin@apic1:~> moquery -c faultInst -f 'fault.Inst.code=="F1425"'
Total Objects shown: 1
# fault.Inst
code : F1425
ack : no
annotation :
cause : ip-provisioning-failed
changeSet : ipv4CfgFailedBmp (New: ipv4:Addraddr_failed_flag,ipv4:Addrctrl_failed_flag,ipv4:AddrlcOwn_failed_flag,
ipv4:AddrmodTs_failed_flag,ipv4:AddrmonPolDn_failed_flag,ipv4:Addrpref_failed_flag,ipv4:Addrtag_failed_flag,
ipv4:Addrtype_failed_flag,ipv4:AddrvpcPeer_failed_flag), ipv4CfgState (New: 1), operStQual (New: subnet-overlap)
childAction :
created : 2020-02-27T01:50:45.656+01:00
delegated : no
descr : IPv4 address(10.10.10.1/24) is operationally down, reason:Subnet overlap on node 101 fabric hostname leaf-101
dn : topology/pod-1/node-101/sys/ipv4/inst/dom-jr:v1/if-[vlan10]/addr-[10.10.10.1/24]/fault-F1425
domain : access
extMngdBy : undefined
highestSeverity : major
lastTransition : 2020-02-27T01:52:49.812+01:00
lc : raised
modTs : never
occur : 1
origSeverity : major
prevSeverity : major
rn : fault-F1425
rule : ipv4-addr-oper-st-down
severity : major
status :
subject : oper-state-err
type : operational
uid :
SSD Health Status on APICs (F0101, F2730, F2731, F2732)
Starting from APIC release 2.3(1), faults occur when the SSD media wearout indicator (life remaining) is less than a certain
percentage on APIC nodes. An SSD with little lifetime may cause any operations that require updates for the internal database,
such as upgrade or downgrade operations, to fail. The APIC will raise three different faults, depending on the amount of SSD
life remaining. If the most critical fault (F2732) is raised on the system, you must replace the SSD by contacting Cisco TAC
prior to performing the upgrade.
F2730: A warning level fault for APIC SSD life remaining. This is raised when the life remaining is less than 10%.
F2731: A major level fault for APIC SSD life remaining. This is raised when the life remaining is less than 5%.
F2732: A critical level fault for APIC SSD life remaining. This is raised when the life remaining is less than 1%.
Also, in very rare occasions, the SSD might have other operational issues than its lifetime. In such a case, look for the
fault F0101.
You can run the moquery below on the CLI of any APIC to check if these faults exist on the system. The faults are visible
within the GUI as well.
If your APICs are still running on a release older than the 2.3(1) release, contact Cisco TAC to check the SSD life remaining.
Fault Example (F2731: Major Fault for APIC SSD life remaining):
The following shows an example of APIC 3 (node 3) with an SSD life remaining of 1% (the major fault F2731). In this case,
although the critical fault F2732 for the life remaining less than 1% is not raised, it is close enough to F2732’s threshold
and it is recommended to replace the SSD.
APIC1# moquery -c faultInfo -f 'fault.Inst.code=="F2731"'
Total Objects shown: 1
# fault.Inst
code : F2731
ack : no
annotation :
cause : equipment-wearout
changeSet : mediaWearout (Old: 2, New: 1)
childAction :
created : 2019-10-22T11:47:40.791+01:00
delegated : no
descr : Storage unit /dev/sdb on Node 3 mounted at /dev/sdb has 1% life remaining
dn : topology/pod-2/node-3/sys/ch/p-[/dev/sdb]-f-[/dev/sdb]/fault-F2731
domain : infra
extMngdBy : undefined
highestSeverity : major
lastTransition : 2019-10-22T11:49:48.788+01:00
lc : raised
modTs : never
occur : 1
origSeverity : major
prevSeverity : major
rn : fault-F2731
rule : eqpt-storage-wearout-major
severity : major
status :
subject : equipment-wearout
type : operational
uid :
SSD Health Status on ACI Switches (F3074, F3073)
Starting from release 2.1(4), 2.2(4), 2.3(1o), and 3.1(2m), faults occur if the flash SSD lifetime usage has reached a certain
endurance limit on the leaf or spine switches. A flash SSD with little lifetime may cause any operations that require updates
for the internal database, such as APIC communication, to fail, or the switch may fail to boot up. The ACI switch will raise
two different faults depending on the amount of SSD life it’s consumed. If the most critical fault (F3073) is raised on the
system, you must replace the SSD by contacting Cisco TAC prior to performing the upgrade.
F3074: A warning level fault for switch SSD lifetime. This is raised when the lifetime reached 80% of its limit.
F3073: A major level fault for switch SSD lifetime. This is raised when the lifetime reached 90% of its limit.
You can run the moquery below on the CLI of any APIC to check if these faults exist on the system. The faults are visible
within the GUI as well.
If your APICs are still running an older release, contact Cisco TAC to check the SSD life status.
Fault Example (F3074: Warning Fault for switch SSD lifetime):
The following shows an example of node 101 that has reached 85% of its SSD lifetime.
APIC1# moquery -c faultInst -f 'fault.Inst.code=="F3074"'
Total Objects shown: 4
# fault.Inst
code : F3074
ack : no
annotation :
cause : equipment-flash-warning
changeSet : acc:read-write, cap:61057, deltape:23, descr:flash, gbb:0, id:1, lba:0, lifetime:85, majorAlarm:no, mfgTm:2020-09-22T02:21:45.675+00:00, minorAlarm:yes, model:Micron_M600_MTFDDAT064MBF, operSt:ok, peCycles:4290, readErr:0, rev:MC04, ser:MSA20400892, tbw:21.279228, type:flash, vendor:Micron, warning:yes, wlc:0
childAction :
created : 2020-09-21T21:21:45.721-05:00
delegated : no
descr : SSD has reached 80% lifetime and is nearing its endurance limit. Please plan for Switch/Supervisor replacement soon
dn : topology/pod-1/node-101/sys/ch/supslot-1/sup/flash/fault-F3074
domain : infra
extMngdBy : undefined
highestSeverity : minor
lastTransition : 2020-09-21T21:24:03.132-05:00
lc : raised
modTs : never
occur : 1
origSeverity : minor
prevSeverity : minor
rn : fault-F3074
rule : eqpt-flash-flash-minor-alarm
severity : minor
status :
subject : flash-minor-alarm
type : operational
VMM Controller Connectivity (F0130)
If there is an issue in communication between the APIC and the VMM controller, the VMM controller status is marked as offline
and the fault F0130 is raised. Ensure that the connectivity between them is restored prior to upgrades so that any resources
that are currently deployed on switches based on the communication with the VMM controller will not be changed or lost due
to the APICs not being able to retrieve necessary information after an upgrade.
You can run the moquery below on the CLI of any APIC to check if these faults exist on the system. The faults are visible
within the GUI as well.
Fault Example (F0130: VMM Controller connection failure):
The following is an example of the APIC failing to communicate with the VMM controller MyVMMControler with the IP 192.168.100.100 in VMM domain LAB_VMM.
apic1# moquery -c faultInst -f 'fault.Inst.code=="F0130"'
Total Objects shown: 1
# fault.Inst
code : F0130
ack : no
cause : connect-failed
changeSet : operSt (Old: unknown, New: offline)
childAction :
created : 2016-05-23T16:07:50.205-05:00
delegated : yes
descr : Connection to VMM controller: 192.168.100.100 with name MyVMMController in datacenter LAB1 in domain: LAB_VMM is failing repeatedly with error: [Failed to retrieve ServiceContent from the vCenter server 192.168.100.100]. Please verify network connectivity of VMM controller 192.168.100.100 and check VMM controller user credentials are valid.
dn : comp/prov-VMware/ctrlr-[LAB_VMM]-MyVMMController/fault-F0130
domain : external
highestSeverity : major
lastTransition : 2016-05-23T16:10:04.219-05:00
lc : raised
modTs : never
occur : 1
origSeverity : major
prevSeverity : major
rn : fault-F0130
rule : comp-ctrlr-connect-failed
severity : major
status :
subject : controller
type : communications
uid :
Missing LLDP/CDP Adjacency Between Leaf Nodes and VMM Hypervisors (F606391)
With On Demand or Immediate resolution immediacy as opposed to pre-provision in the VMM domain when attaching it to an EPG, for some VMM integrations such as VMware DVS integration, the APIC checks
LLDP or CDP information from leaf switches connected to the hypervisors and also from the VMM controller managing the hypervisors.
This information is required from both leaf switches and hypervisors to dynamically detect the leaf interface connecting to
the hypervisor, even when there is an intermediate switch in between such as Cisco UCS Fabric Interconnect. Once the interface
is detected, the APIC dynamically deploys VLANs only on the necessary interface(s) of the leaf switch that the hypervisor
is connected to.
Prior to APIC release 3.0(1), VLANs used to be removed from the leaf interfaces if the APIC loses the connectivity to the
VMM controller because the APIC can no longer compare the LLDP or CDP information from the hypervisor’s point of view. Starting
from APIC release 3.0(1), VLANs will not be removed from the leaf interfaces even if the APIC loses the connectivity to the
VMM controller to prevent transient management plane issues from impacting the data plane traffic. However, it may cause some
churns in the APIC process by repeatedly trying to obtain the LLDP/CDP information. When the LLDP/CDP information is missing,
the fault F606391 is raised.
Due to these reasons, regardless of the APIC release, it is important to resolve this fault prior to the upgrade. If the faults
are raised on a VMM domain configured for the Cisco Application Virtual Edge (AVE), LLDP and CDP can be disabled entirely
since the control plane built to program the switches is based on the opflex protocol and not LLDP/CDP. When LLDP and CDP
are disabled, the faults should clear. The configuration to change the LLDP/CDP state for a VMM domain is configured under
the vSwitch Policy for the VMM Domain.
You can run the moquery below on the CLI of any APIC to check if these faults exist on the system. The faults are visible
within the GUI as well.
Fault Example (F606391: LLDP/CDP adjacency missing for hypervisors):
apic1# moquery -c faultInst -f 'fault.Inst.code=="F606391"'
Total Objects shown: 5
# fault.Inst
code : F606391
ack : no
annotation :
cause : fsm-failed
changeSet :
childAction :
created : 2019-07-18T01:17:39.435+08:00
delegated : yes
descr : [FSM:FAILED]: Get LLDP/CDP adjacency information for the physical adapters on the host: hypervisor1.cisco.com(TASK:ifc:vmmmgr:CompHvGetHpNicAdj)
dn : comp/prov-VMware/ctrlr-[LAB_VMM]-MyVMMController/hv-host-29039/fault-F606391
domain : infra
extMngdBy : undefined
highestSeverity : major
lastTransition : 2019-07-18T01:17:39.435+08:00
lc : raised
modTs : never
occur : 1
origSeverity : major
prevSeverity : major
rn : fault-F606391
rule : fsm-get-hp-nic-adj-fsm-fail
severity : major
status :
subject : task-ifc-vmmmgr-comp-hv-get-hp-nic-adj
type : config
uid :
Different Infra VLAN Being Injected Through LLDP (F0454: infra-vlan-mismatch)
If you have interfaces connected back-to-back between two different ACI fabrics, you must disable LLDP on those interfaces
prior to upgrades. This is because when the switch comes back up after the upgrade, it may receive and process LLDP packets
from the other fabric that may be using a different infra VLAN. If that happens, the switch incorrectly tries to be discovered
through the infra VLAN of the other fabric and will not be discoverable in the correct fabric.
There is a fault to detect if an ACI switch is currently is receiving an LLDP packet with infra VLAN mismatch from other fabrics.
You can run the moquery below on the CLI of any APIC to check if the fault exists on the system.
Fault Example (F0454: LLDP with mismatched parameters):
apic1# moquery -c faultInst -f 'fault.Inst.code=="F0454"'
Total Objects shown: 2
# fault.Inst
code : F0454
ack : no
alert : no
annotation :
cause : wiring-check-failed
changeSet : wiringIssues (New: ctrlr-uuid-mismatch,fabric-domain-mismatch,infra-ip-mismatch,infra-vlan-mismatch)
childAction :
created : 2021-06-30T10:44:25.576-07:00
delegated : no
descr : Port eth1/48 is out of service due to Controller UUID mismatch,Fabric domain name mismatch,Infra subnet mismatch,Infra vlan mismatch
dn : topology/pod-1/node-104/sys/lldp/inst/if-[eth1/48]/fault-F0454
--- snip ---
Policy CAM Programming for Contracts (F3545)
The fault F3545 occurs when the switch fails to activate a contract rule (zoning-rule) due to either a hardware or software
programming failure. If you see this, it's because the policy CAM is full and no more contracts can be deployed on the switch,
and a different sets of contracts may deploy after a reboot or upgrade. This may lead to services that used to work before
an upgrade begins to fail after an upgrade. Note that the same fault could occur for other reasons, such as an unsupported
type of filter in the contract(s) instead of policy CAM usage. For instance, first generation ACI switches support EtherType
IP but not IPv4 or IPv6 in contract filters. When this fault is present, check the Operations > Capacity Dashboard > Leaf Capacity in the APIC GUI for policy CAM usage.
You can run the moquery below on the CLI of any APIC to check if these faults exist on the system. The faults are visible
within the GUI as well.
Fault Example (F3545: Zoning Rule Programming Failure):
The following shows an example of node 101 with programming failure for 266 contract rules (zoneRuleFailed). Although it also
shows the programming failure of L3Out subnets (pfxRuleFailed) in the changeSet, a separate fault F3544 is raised for that.
apic1# moquery -c faultInst -f 'fault.Inst.code=="F3545"'
Total Objects shown: 1
# fault.Inst
code : F3545
ack : no
annotation :
cause : actrl-resource-unavailable
changeSet : pfxRuleFailed (New: 80), zoneRuleFailed (New: 266)
childAction :
created : 2020-02-26T01:01:49.256-05:00
delegated : no
descr : 266 number of Rules failed on leaf1
dn : topology/pod-1/node-101/sys/actrl/dbgStatsReport/fault-F3545
domain : infra
extMngdBy : undefined
highestSeverity : major
lastTransition : 2020-02-26T01:03:59.849-05:00
lc : raised
modTs : never
occur : 1
origSeverity : major
prevSeverity : major
rn : fault-F3545
rule : actrl-stats-report-zone-rule-prog-failed
severity : major
status :
subject : hwprog-failed
type : operational
uid :
L3Out Subnets Programming for Contracts (F3544)
The fault F3544 occurs when the switch fails to activate an entry to map a prefix to pcTag due to either a hardware or software programming failure. These entries are configured for L3Out subnets with the “External Subnets for the External EPG” scope under an external EPG in an L3Out, and used to map L3Out subnets to L3Out EPGs. If you see this because of the LPM
or host routes capacity on the switch, such a switch may activate different sets of entries after a reboot or upgrade. This
may lead to services that used to work before an upgrade begins to fail after an upgrade. When this fault is present, check
the Operations > Capacity Dashboard > Leaf Capacity in the APIC GUI for LPM and /32 or /128 routes usage.
You can run the moquery below on the CLI of any APIC to check if these faults exist on the system. The faults are visible
within the GUI as well.
Fault Example (F3544: L3Out Subnet Programming Failure):
The following shows an example of node 101 with programming failure for 80 L3Out subnets with “External Subnets for the External
EPG” (pfxRuleFailed). Although it also shows the programming failure of contracts themselves (zoneRuleFailed) in the changeSet,
a separate fault F3545 is raised for that.
apic1# moquery -c faultInst -f 'fault.Inst.code=="F3544"'
Total Objects shown: 1
# fault.Inst
code : F3544
ack : no
annotation :
cause : actrl-resource-unavailable
changeSet : pfxRuleFailed (New: 80), zoneRuleFailed (New: 266)
childAction :
created : 2020-02-26T01:01:49.246-05:00
delegated : no
descr : 80 number of Prefix failed on leaf1
dn : topology/pod-1/node-101/sys/actrl/dbgStatsReport/fault-F3544
domain : infra
extMngdBy : undefined
highestSeverity : major
lastTransition : 2020-02-26T01:03:59.849-05:00
lc : raised
modTs : never
occur : 1
origSeverity : major
prevSeverity : major
rn : fault-F3544
rule : actrl-stats-report-pre-fix-prog-failed
severity : major
status :
subject : hwprog-failed
type : operational
uid :
General Scalability Limits
Check the Capacity Dashboard from Operations > Capacity Dashboard on the APIC GUI to ensure that any capacity does not exceed its limit. When it’s exceeding the limit, it may cause inconsistency
on resources that are deployed before and after an upgrade just like it was warned for Policy CAM Programming for Contracts (F3545) and L3Out Subnets Programming for Contracts (F3544).
We recommend that you check the Capacity Dashboard for each switch through Operations > Capacity Dashboard > Leaf Capacity because those are typically the hardware limit instead of a software qualified limit. For instance, the number of endpoints
such as MAC (Learned), IPv4 (Learned), Policy CAM, LPM, host routes and so on.
Overlapping VLAN Pool
Overlapping VLAN blocks across different VLAN pools may result in some forwarding issues, such as:
Packet loss due to issues in endpoint learning
Spanning tree loop due to BPDU forwarding domains
These issues may suddenly appear after upgrading your switches because switches fetch the policies from scratch after an upgrade and may apply the same VLAN ID from a different pool than
what was used prior to the upgrade. As a result, the VLAN ID is mapped to a different VXLAN VNID than other switch nodes.
This causes the two problems mentioned above.
It is critical to ensure that there are no overlapping VLAN pools in your fabric unless it is on purpose with the appropriate
understanding of VLAN ID and VXLAN ID mapping behind the scene. If you are not sure, consider Enforce EPG VLAN Validation under System > System Settings > Fabric Wide Setting in the APIC GUI [available starting with release 3.2(6)], which prevents the most common problematic configuration (two domains
containing overlapping VLAN pools being associated to the same EPG).
Refer to the following documents to understand how overlapping VLAN pools become an issue and when this scenario might occur:
It is critical to ensure that MTU values on ACI L3Out interfaces and the routers that connect to them match. Otherwise, when
the ACI switch boots up after an upgrade, it may cause problem during the routing protocol neighborship establishment or exchanging
the route information between peers.
See below for example details on each protocol.
BGP is the protocol which would establish session without MTU consideration. BGP "Open and Establish" messages are small,
but the messages to exchange routes can be huge.
OSPF will fail to form neighborship if the MTU from both end of the link does not match. However, although it is strongly
not recommended, if the side with larger MTU is configured to ignore MTU to bring up OSPF neighborship, then OSPF neighborship
will be formed.
During a border leaf switch upgrade, routing sessions will be teared off. When a border leaf switch comes online with a new
version, it will bring up routing peer. After this, when it starts to exchange information about routing prefix, it will generate
frames with a possibly bigger payload. Based on the size of the table, the update may need a larger frame size which might
not reach the other side. The size of this payload will depend upon local MTU. If the MTU on the other side does not match
(if it's smaller than the local MTU size), then these exchanges will fail, resulting in routing issues.
You can check and configure the MTU on L3Out interfaces through Tenant > Networking > L3Out > Logical Node Profile > Logical Interface Profile > Select interface type.
You can run the moquery below on the CLI of any APIC to check the configured MTU of all L3Out interfaces. Use grep for concise output if necessary, such as this example:
egrep “dn|encap|mtu”
In this example, an L3Out interface with VLAN 2054 is configured with MTU 9000 in tenant TK, L3Out OSPF, Logical Node Profile OSPF_nodeProfile, and Logical Interface Profile OSPF_interfaceProfile.
Alternatively, you can run fabric <node_id> show interface on your border leaf nodes as well.
If the MTU shows inherit, the value is inherited from Fabric > Fabric Policies > Policies > Global > Fabric L2 MTU > default.
The script provided in this chapter checks the MTU of all L3Out interfaces for you. However, you have to run the script on
APIC, and the APIC does not have visibility on the MTU value configured on the connected devices. Therefore, you should manually
check the MTU on the connected devices.
L3Out BGP Peer Connectivity Profile Under a Node Profile Without a Loopback
Prior to upgrading to release 4.1(2) or later, you must ensure that one of the following two requirements are met:
A node profile with a BGP Peer Connectivity Profile has a loopback configured for all switches in the profile, or
BGP Peer Connectivity Profiles are configured per interface.
You can configure the BGP Peer Connectivity Profile per node profile or per interface. The former is to source the BGP session
from a loopback while the latter is to source the BGP session from each interface.
Prior to release 4.1(2), when a BGP Peer Connectivity Profile is configured at a node profile without configuring a loopback,
APIC uses another available IP address on the same border leaf switch in the same VRF as the BGP source, such as a loopback
IP address from another L3Out or an IP address configured for each interface. This has a risk of the BGP source IP address
being changed unintentionally across reboots or upgrades. This behavior has been changed based on CSCvm28482 and ACI no longer establishes a BGP session through a BGP Peer Connectivity Profile at a node profile when a loopback is
not configured in the node profile. Instead, a fault F3488 is raised in these situations. This fault cannot be used as a pre-upgrade
check because it is raised only after an upgrade.
Due to this change, when upgrading from an older version to release 4.1(2) or later, a BGP session is no longer established
if the session was generated via a BGP Peer Connectivity Profile under a node profile and a loopback is not configured in
the node profile.
When multiple interfaces in the same node profile need to establish a BGP peer with the same peer IP, you might attempt to
configure a BGP Peer Connectivity Profile at a node profile without a loopback so that the same BGP Peer configuration is
applied, as a fallback due to the missing loopback, to each interface in the same node profile. This is because a BGP Peer
Connectivity Profile with the same peer IP address could not be configured at multiple interface profiles within the same
node profile. This limitation was loosened based on CSCvw88636 on 4.2(7f). Until then, for this specific requirement, you need to configure a node interface per interface profile and configure
the BGP Peer Connectivity Profile at each interface profile in a different node profile.
L3Out Incorrect Route Map Direction (CSCvm75395)
Prior to upgrading to release 4.1(1) or later, you must ensure that the route map (route profile) configuration is correct.
Due to the defect CSCvm75395, the following configuration might have worked prior to release 4.1(1) despite the wrong configuration (a mismatch in the
direction):
A route map with export direction attached to an L3Out subnet with Import Route Control Subnet
A route map with import direction attached to an L3Out subnet with Export Route Control Subnet
Where the L3Out subnet means the subnet configured under an External EPG in an L3Out.
However, these wrong configurations will no longer work, which is the expected behavior, after you upgrade the fabric to release
4.1(1) or later.
Although this method is not the most common or recommended one among many ways to control the routes being advertised or learned
by ACI L3Outs, the correct configuration with this method should be as follows:
A route map with export direction attached to an L3Out subnet with Export Route Control Subnet
A route map with import direction attached to an L3Out subnet with Import Route Control Subnet
Or alternatively, you can follow the recommended configurations below to control the route exchange in L3Outs instead:
default-export route map with IP prefix-lists
default-import route map with IP prefix-lists
With this configuration, you don’t need Export Route Control Subnet or Import Route Control Subnet in the external EPGs, and you can have external EPGs that are dedicated for contracts or route leaking while you have the
full control of routing protocol through route maps just like a normal router.
Also note that any import direction route maps only take effect when Route Control Enforcement is enabled for import under Tenant > Networking > L3Out > Main profile. Otherwise, everything is imported (learned) by default.
EP Announce Version Mismatch (CSCvi76161)
If your current ACI switch version is pre-12.2(4p) or 12.3(1) and you are upgrading to release 13.2(2) or later, you are susceptible
to a defect CSCvi76161, where a version mismatch between Cisco ACI leaf switches may cause an unexpected EP announce message to be received by the
EPM process on the leaf switch, resulting in an EPM crash and the reload of the switch.
To avoid this issue, it is critical that you upgrade to a fixed version of CSCvi76161 prior to upgrading to release 13.2(2)
or later.
For fabrics running a pre-12.2(4p) ACI switch release, upgrade to release 12.2(4r) first, then upgrade to the desired destination
release.
For fabrics running a 12.3(1) ACI switch release, upgrade to release 13.1(2v) first, then upgrade to the desired destination
release.
Intersight Device Connector is Upgrading
If you start an APIC upgrade while an intersight Device Connector (DC) upgrade is in progress, the DC upgrade may fail.
You can check the status of intersight DC from System > System Settings > intersight. If the upgrade of the DC is in progress, wait for a minute and retry the APIC upgrade. The upgrade of the Intersight Device
Connector typically takes less than a minute.
Checklists for Downgrade
In general, the same checklists as upgrades should be applied to downgrades. On top of that, you need to pay attention to
the new features that may not yet be supported on older versions. If you are using such features, you should disable or change
the configurations prior to the downgrade. Otherwise, some functionality will stop working after downgrades.
The following lists some of the example features that you should pay attention to prior to downgrades. However, note that
the following list is not complete and we highly recommend that you check the Release Notes or Configuration Guides to confirm
that features that you are using are supported on older releases as well.
The ability to use the DUO application as an authentication method when logging in to Cisco APIC was introduced as part of the Cisco APIC release 5.0(1). If you are running release 5.0(1) and you have DUO set up as your default authentication method, but then
you decide to downgrade from release 5.0(1) to a previous release where DUO was not supported as an authentication method,
we recommend that you change the default authentication method from DUO to an option that was available prior to release 5.0(1),
such as Local, LDAP, RADIUS, and so on. If you do not change the default authentication method before downgrading in this
situation, you will have to log in using the fallback option after the downgrade, then you will have to change the authentication
method to an option that was available prior to release 5.0(1) at that point.
Navigate to Admin > AAA > Authentication, then change the setting in the Realm field in the Default Authentication area of the page to change the default authentication method before downgrading your system. You will also have to manually
delete the DUO login domain after the downgrade.
Beginning in the 4.2(6) release, SNMPv3 supports the Secure Hash Algorithm-2 (SHA-2) authentication type. If you are running
on Cisco APIC release 4.2(6) or later and you are using the SHA-2 authentication type, and then downgrade from Cisco APIC release 4.2(6) to a previous release, the downgrade will be blocked with the following error message:
SHA-2authentication type is not supported.
You can choose to either change the authentication type to MD5 or delete the corresponding SNMPv3 users to continue.
Changing the container bridge IP address on APIC is supported only on APIC release 4.2(1) or later. If the container bridge
IP address on APIC for AppCenter is configured with a non-default IP address, change it back the default 172.17.0.1/16 prior
to downgrading to the older versions than 4.2(1).
A static route (MO:mgmtStaticRoute) for Inband and/or Out-of-band EPG under Tenants > mgmt > Node Management EPGs is supported only on APIC release 5.1 or later. Delete this configuration and ensure the required service is still reachable
via other means prior to the downgrade.
Newly added microsegment EPG configurations must be removed before downgrading to a software release that does not support
it.
Downgrading the fabric starting with the leaf switch will cause faults such as policy-deployment-failed with fault code F1371.
If you must downgrade the firmware from a release that supports FIPS to a release that does not support FIPS, you must first
disable FIPS on the Cisco ACI fabric and reload all the switches in the fabric for the FIPS configuration change.
If you have Anycast services configured in your Cisco ACI fabric, you must disable the Anycast gateway feature and stop Anycast
services on external devices before downgrading from Cisco APIC 3.2(x) to an earlier release.
CiscoN9K-C9508-FM-E2 fabric modules must be physically removed before downgrading to releases earlier than Cisco APIC 3.0(1). The same applies to any new modules for their respective supported version.
If you have remote leaf switches deployed, and you downgrade the Cisco APIC software from release 3.1(1) or later to an earlier release that does not support the remote leaf switches feature, you must
decommission the nodes before downgrading. For information about prerequisites to downgrading Remote Leaf switches, see the
Remote Leaf Switches chapter in the Cisco APIC Layer 3 Networking Configuration Guide.
If the following conditions are met:
You are running the 5.2(4) release and the Cisco APIC created one or more system-generated policies.
You downgrade the Cisco APIC from the 5.2(4) release, then later upgrade back to the 5.2(4) release.
Then, one of the following behaviors will occur:
If the Cisco APIC finds a policy with the same name and parameters as a system-generated policy that it is trying to create, then the Cisco APIC will take ownership of the policy and you cannot modify the policy. This occurs if you did not modify the policy after downgrading
from the 5.2(4) release.
If the Cisco APIC finds a policy with the same name as a system-generated policy that the Cisco APIC is trying to create, but the parameters are different, then the Cisco APIC will consider the policy to be a custom policy and you can modify the policy. This occurs if you modified the policy after
downgrading from the 5.2(4) release.
Because of this behavior, you should not modify the system-generated policies after you downgrade from the 5.2(4) release.
You must decommission an unsupported leaf switch that is connected to the Cisco APIC and move the cables to the other leaf
switch that is part of the fabric before you downgrade the image.
Example Error Messages and Override Options Through the GUI with APIC Release 4.2(5)
There are three situations where warning messages might appear through the GUI:
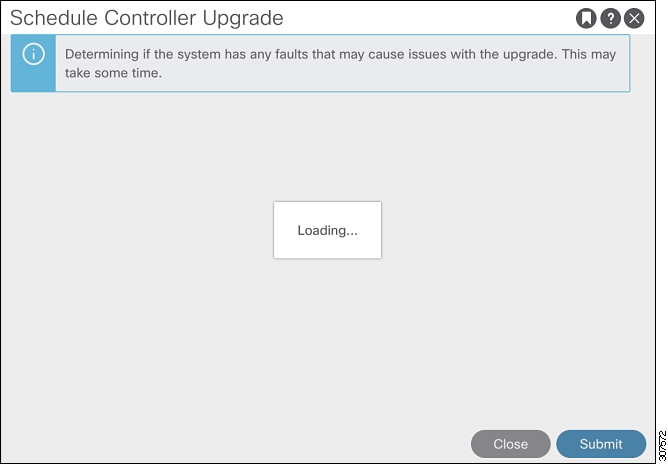
While the query is loading, where you might see a message similar to the following:
This might occur because it sometimes takes a bit of time to load the data from a query. In this situation, be patient and
wait for the system to finish loading the data from the query.
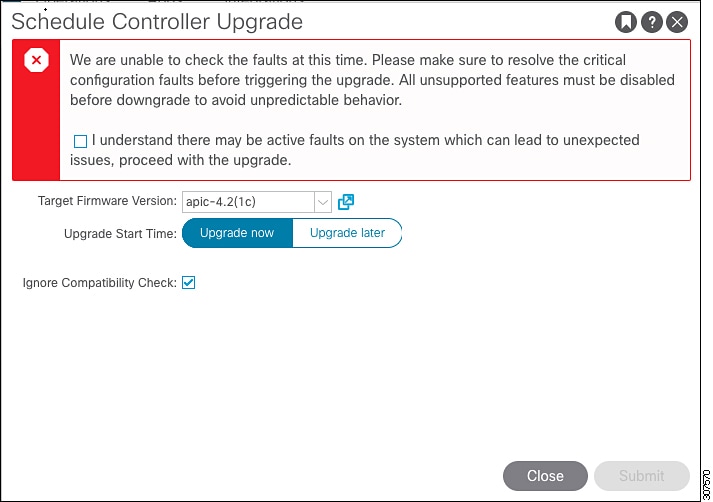
If the query fails for some reason, you might see a message similar to the following:
This warning will appear if the query failed for some reason (for example, there might be so many faults that the system is
overloaded). In this case, it is up to you to verify if there are any faults that might cause an issue with the upgrade.
However, if you want to override the block and proceed with an upgrade or downgrade without addressing the issue with the
failed query, check the box next to the I understand there may be active faults on the system which can lead to unexpected issues, proceed with the upgrade field. This allows you continue with the upgrade or downgrade process without addressing the issue with the failed query.
Once the fault query is complete, where you might see a message similar to the following:
This warning message will appear when the fault query is complete and the system has found one or more faults. In this situation,
click the Click Here link to get more information on the faults that the system found.
However, if you want to override the block and proceed with an upgrade or downgrade without addressing the issue that was
raised in the fault, check the box next to the I understand there are active faults on the system which can lead to unexpected issues, proceed with the upgrade field. This allows you continue with the upgrade or downgrade process without addressing the faults that were detected.
Example Error Messages and Override Options Through the NX-OS Style CLI
When you attempt to upgrade the software through the NX-OS style CLI:
apic# firmware upgrade controller-group
You might see an error message similar to the following if faults on the fabric are detected:
Error: Migration cannot proceed due to 23 active critical config faults. Resolve the faults to proceed
However, if you want to override the block and proceed with an upgrade or downgrade without addressing the issue that was
raised in the fault, use the ignore-validation option to proceed with the upgrade:


 Feedback
Feedback