Ultra-M UCS 240M4 Single HDD Failure - Hot Swap Procedure - CPS
Available Languages
Download Options
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Contents
Introduction
This document describes the steps required in order to replace the faulty HDD drive in a server in an Ultra-M setup that hosts Cisco Policy Suite (CPS) Virtual Network Function (VNFs).
Background Information
Ultra-M is a pre-packaged and validated virtualized mobile packet core solution designed to simplify the deployment of VNFs. OpenStack is the Virtualized Infrastructure Manager (VIM) for Ultra-M and consists of these node types:
- Compute
- Object Storage Disk - Compute (OSD - Compute)
- Controller
- OpenStack Platform - Director (OSPD)
The high-level architecture of Ultra-M and the components involved are as shown in this image:
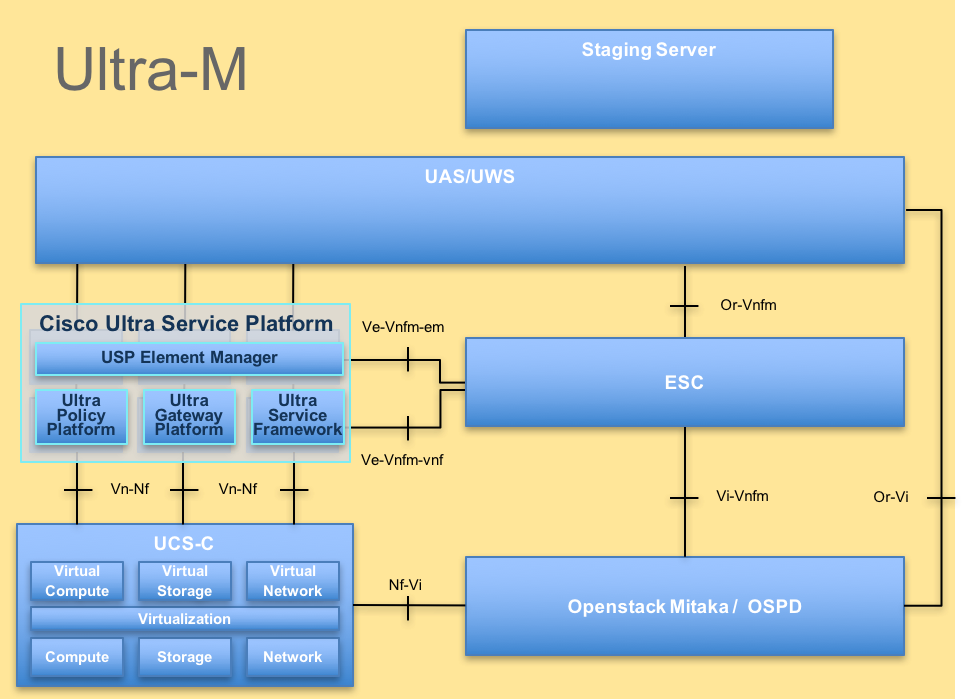 UltraM Architecture
UltraM Architecture
Note: Ultra M 5.1.x release is considered in order to define the procedures in this document. This document is intended for the Cisco personnel who are familiar with the Cisco Ultra-M platform and it details the steps required to be carried out at OpenStack level at the time of the OSPD Server replacement.
Abbreviations
| VNF | Virtual Network Function |
| ESC | Elastic Service Controller |
| MOP | Method of Procedure |
| OSD | Object Storage Disks |
| HDD | Hard Disk Drive |
| SSD | Solid State Drive |
| VIM | Virtual Infrastructure Manager |
| VM | Virtual Machine |
| EM | Element Manager |
| UAS | Ultra Automation Services |
| UUID | Universally Unique IDentifier |
Workflow of the MoP
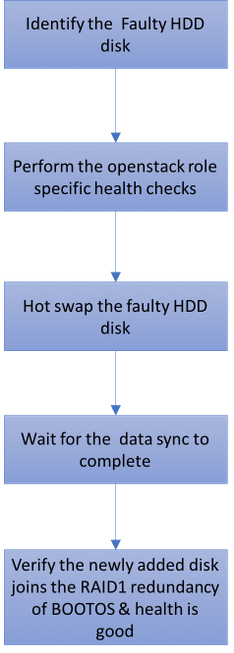
Single HDD Failure
1. Each Baremetal server will be provisioned with two HDD drives in order to act as Boot Disk in Raid 1 configuration. In case of single HDD failure, since there is Raid 1 level redundancy, the faulty HDD drive can be Hot Swapped.
2. Refer to the procedure in order to replace a faulty component on UCS C240 M4 server here: Replacing the Server Components
3. In case of single HDD failure, only the faulty HDD will be Hot Swapped and hence no BIOS upgrade procedure is required after you replace new disks.
4. After you replace the disks, wait for the data sync between the disks. It might take a couple of hours to complete.
5. In an OpenStack based (Ultra-M) solution, UCS 240M4 baremetal server can take up one of these roles: Compute, OSD-Compute, Controller and OSPD.
6. The steps required in order to handle the single HDD failure in each of these server roles are same and this section describes the health checks to be performed before the Hot Swap of the disk.
Single HDD Failure on a Compute Server
1. If the failure of HDD drives is observed in UCS 240M4 which acts as a Compute node, perform these health checks before you initiate the Hot Swap procedure of the faulty disk.
2. Identify the VMs running on this server and verify the status of the functions are good.
Identify the VMs Hosted in the Compute Node
Identify the VMs that are hosted on the Compute server and verify that they are active and running.
The Compute server contains CPS VMs/Elastic Services Controller (ESC) combination of VMs:
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c2_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
Note: In the output shown here, the first column corresponds to the Universally Unique IDentifier (UUID), the second column is the VM name and the third column is the hostname where the VM is present.
Health Checks
1. Log in to the ESC hosted in the compute node and check the status.
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
2. Log in to the UAS hosted in the compute node and check the status.
ubuntu@autovnf2-uas-1:~$ sudo su
root@autovnf2-uas-1:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on autovnf2-uas-1
autovnf2-uas-1#show uas ha
uas ha-vip 172.18.181.101
autovnf2-uas-1#
autovnf2-uas-1#
autovnf2-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.18.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.18.180.4 alive CONFD-SLAVE
172.18.180.5 alive CONFD-MASTER
172.18.180.8 alive NA
autovnf2-uas-1#show errors
% No entries found.
3. If health checks are fine, proceed with the faulty disk Hot Swap procedure and wait for the data sync as it might take a couple of hours to complete. Refer to: Replacing the Server Components
4. Repeat these health check procedures in order to confirm that the health status of the VMs hosted on compute node are restored.
Single HDD Failure on a Controller Server
1. If the failure of the HDD drives is observed in UCS 240M4 which acts as the Controller node, perform these health checks before you initiate the Hot Swap procedure of the faulty disk.
2. Check the Pacemaker status on the controllers.
3. Log in to one of the active controllers and check the Pacemaker status. All services must be running on the available controllers and stopped on the failed controller.
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Thu Jun 28 07:53:06 2018 Last change: Wed Jan 17 11:38:00 2018 by root via cibadmin on pod1-controller-0
3 nodes and 22 resources conimaged
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.2.2.2 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.50 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.48 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-2
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
4. Check the MariaDB status in the active controllers.
[stack@director] nova list | grep control
| 4361358a-922f-49b5-89d4-247a50722f6d | pod1-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.102 |
| d0f57f27-93a8-414f-b4d8-957de0d785fc | pod1-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.110 |
[stack@director ~]$ for i in 192.200.0.102 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done
*** 192.200.0.152 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
*** 192.200.0.154 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
Verify that these lines are present for each active controller:
wsrep_local_state_comment: Synced
wsrep_cluster_size: 2
5. Check Rabbitmq status in the active controllers.
[heat-admin@pod1-controller-0 ~]$ sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod1-controller-0' ...
[{nodes,[{disc,['rabbit@pod1-controller-0','rabbit@pod1-controller-1',
'rabbit@pod1-controller-2']}]},
{running_nodes,['rabbit@pod1-controller-2',
'rabbit@pod1-controller-1',
'rabbit@pod1-controller-0']},
{cluster_name,<<"rabbit@pod1-controller-0.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod1-controller-2',[]},
{'rabbit@pod1-controller-1',[]},
{'rabbit@pod1-controller-0',[]}]}]
6. If health checks are fine, proceed with faulty disk Hot Swap procedure and wait for the data sync as it might take a couple of hours to complete. Refer to: Replacing the Server Components
7. Repeat these health check procedures in order to confirm that the health status on the controller is restored.
Single HDD Failure on an OSD-Compute Server
If the failure of HDD drives is observed in UCS 240M4 which acts as an OSD-Compute node, perform these health checks before you initiate the Hot Swap procedure of the faulty disk.
Identify the VMs Hosted in the OSD-Compute Node
1. The Compute server contains ESC VM.
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain | ACTIVE |
Note: In the output shown here, the first column corresponds to the (UUID), the second column is the VM name and the third column is the hostname where the VM is present.
2. Ceph processes are active on the OSD-Compute server.
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
3. Verify that the mapping of OSD (HDD disk) to Journal (SSD) is good.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
4. Verify that the Ceph health and the OSD tree mapping is good.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
5. If health checks are fine, proceed with the faulty disk Hot Swap procedure and wait for the data sync as it might take a couple of hours to complete. Refer to Replacing the Server Components
6. Repeat these health check procedures in order to confirm that the health status of the VMs hosted on OSD-Compute node are restored.
Single HDD Failure on an OSPD Server
1. If the failure of the HDD drives is observed in UCS 240M4, which acts as an OSPD node, it is recommended you perform these checks before you initiate the Hot Swap procedure of the faulty disk.
2. Check the status of the OpenStack stack and the node list.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
3. Check if all the undercloud services are in loaded, active and running status from the OSPD node.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
4. If health checks are fine, proceed with faulty disk Hot Swap procedure and wait for the data sync as it might take a couple of hours to complete. Refer to Replacing the Server Components
5. Repeat these health check procedures in order to confirm that the health status of the OSPD node is restored.
Revision History
| Revision | Publish Date | Comments |
|---|---|---|
1.0 |
24-Sep-2018
|
Initial Release |
Contributed by Cisco Engineers
- Aaditya DeodharCisco Advanced Services
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)