This list comprises the preconfigured CallManager alerts.
- BeginThrottlingCallListBLFSubscriptions
- CallAttemptBlockedByPolicy
- CallProcessingNodeCpuPegging
- CARIDSEngineCritical
- CARIDSEngineFailure
- CARSchedulerJobFailed
- CDRAgentSendFileFailed
- CDRFileDeliveryFailed
- CDRHighWaterMarkExceeded
- CDRMaximumDiskSpaceExceeded
- CodeYellow
- DBChangeNotifyFailure
- DBReplicationFailure
- DBReplicationTableOutofSync
- DDRBlockPrevention
- DDRDown
- EMCCFailedInLocalCluster
- EMCCFailedInRemoteCluster
- ExcessiveVoiceQualityReports
- IMEDistributedCacheInactive
- IMEOverQuota
- IMEQualityAlert
- InsufficientFallbackIdentifiers
- IMEServiceStatus
- InvalidCredentials
- LowTFTPServerHeartbeatRate
- MaliciousCallTrace
- MediaListExhausted
- MgcpDChannelOutOfService
- NumberOfRegisteredDevicesExceeded
- NumberOfRegisteredGatewaysDecreased
- NumberOfRegisteredGatewaysIncreased
- NumberOfRegisteredMediaDevicesDecreased
- NumberOfRegisteredMediaDevicesIncreased
- NumberOfRegisteredPhonesDropped
- RouteListExhausted
- SDLLinkOutOfService
- TCPSetupToIMEFailed
- TLSConnectionToIMEFailed
- UserInputFailure
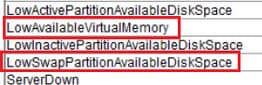
LowAvailableVirtualMemory and LowSwapPartitionAvailableDiskSpace
Linux servers have a tendency to ‘not clear’ the virtual memory usage over a period of time and it has been seen to accumulate and hence those alerts.
Linux operates a little differently as an operating system.
Once memory is allocated to a process it will not be taken back by the processor unless some other process requests for memory more than the available memory.
This causes high virtual memory.
A request for an increase in the threshold for the alarm in the higher versions of call manager has been documented in the defect; https://bst.cloudapps.cisco.com/bugsearch/bug/CSCuq75767/?reffering_site=dumpcr
For swap partitions, this alert indicates that the swap partition is left with low available space, and is heavily used by the system. The swap partition is normally used to extend the physical RAM capacity when needed. Under normal conditions, if RAM is enough, swap should not be used too much.
Also, these may be throw up RTMT alerts caused by a build-up of temp files, a reboot of the server is recommended to clear out any unnecessary temp files.
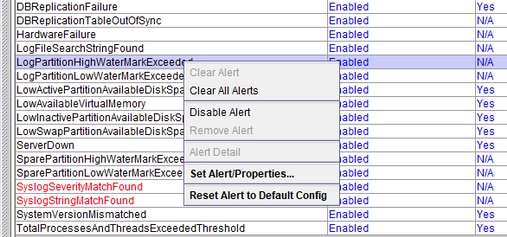
LogPartitionHighWaterMarkExceeded and LogPartitionLowWaterMarkExceeded
On running show status on the CLI of a CUCM server, a value that specifies the occupied and free percentage of logging partition in the CUCM disk space is shown. Also known as common partition, these values specify the space occupied by the logs/traces and the CDR files in the server, which even though are harmless, might cause issues in install/upgrade procedure due to lack of space over time. These alerts serve as a warning to the administrator to clear those logs which might have accumulated over time in the cluster/server.
LogPartitionLowWaterMarkExceeded: This alert is generated when the filled space reaches the threshold values configured for the alert. This alert serves as a pre-check indicator for the disk usage.
LogPartitionHighWaterMarkExceeded: This alert is generated when the filled space reaches the threshold values configured for the alert. Once the alert is generated, the server starts to auto-purge the oldest logs in order to bring down the space to value lesses that the HighWaterMark threshold.
Best practice would be to purge the logs manually as soon as LogPartitionLowWaterMarkExceeded alert is received.
Steps to do so are:
Step 1. Launch RTMT.
Step 2. Select Alert Central, then perform these tasks:
Select LogPartitionHighWaterMarkExceeded, note its value and change its threshold value to 60%.
Select LogPartitionLowWaterMarkExceeded, note its value and change its threshold value to 50%.
Polling occurs every 5 minutes, so wait for 5-10 minutes, then verify that the required disk space is available. If you want to free up more disk space in the common partition, change LogPartitionHighWaterMarkExceeded and LogPartitionLowWaterMarkExceeded thread values to lower values (for example, 30% and 20%) again.
Give it 15 to 20 minutes to clear the space in common partition. You can monitor the decrease in disk usage with the command show status from CLI.
That would bring down the common partition.
CpuPegging
CpuPegging alert monitors CPU usage on the basis of configured threshold.
When the CPU pegging alert is received, the process that occupies the highest CPU can be occupied by going to the System Drawer on the left, that is Process.
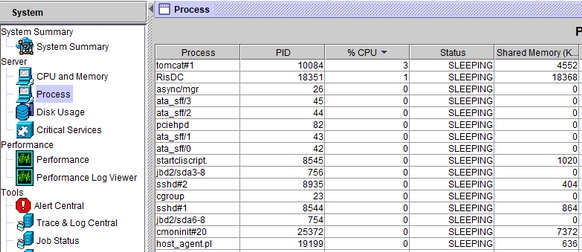
From the CLI of the concerned server, these outputs will lend some insight.
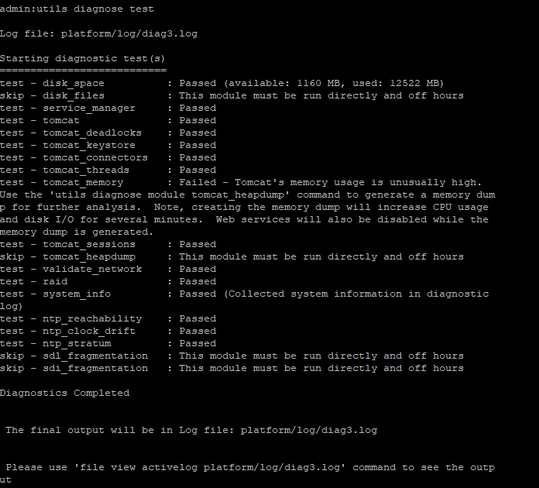
- utils diagnose test
- show process load cpu sorted
- show status
- utils core active list
It is recommended to observe if the CPU spike happens at a specific time or randomly. If it occurs randomly then the required detailed CUCM traces as well as RisDC perfmon logs to check what is triggering the spike in CPU. If the alerts are happening at a specific time of the day then it could be due to some scheduled activity like Disaster Recovery System (DRS) backup, CDR Load etc.
Also, on the basis of information about which process occupies the most CPU, specific logs are taken for further investigation. For eg. if the culprit is Tomcat, then the Tomcat related logs are needed.
 Feedback
Feedback