Cisco Silicon One P200 Deep Buffer Router Chip Data Sheet
Available Languages
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Cisco Silicon One™ P200 is the first to market 51.2Tbps full duplex deep buffer router processor. The P200 is the most power efficient 51.2Tbps deep buffer router, AI future proof device and the only device with both data and system security.
The rapid scaling of AI training clusters, while driving advancements in artificial intelligence, has significantly increased power consumption, making it a critical limiting factor for infrastructure growth.
Traditional scaling methods (‘scale-up’ and ‘scale-out’) are no longer sufficient to meet the demands of modern networks. Massive data centers, consuming vast energy and real estate, are migrating to less populated areas with cheaper electricity, but this shift escalates WAN traffic and fails to address the need for scaling AI clusters beyond single-site constraints. To overcome these challenges, a ‘scale-across’ approach is essential—enabling seamless AI workload distribution across geographically dispersed data centers to optimize resources, mitigate power constraints, and sustain future growth
Cisco Silicon One P200 marks a groundbreaking milestone as the industry’s first 51.2Tbps full-duplex, deep-buffer routing processor, purpose-built for the Scale Across Era. Built on the industry’s only scalable and programmable unified networking architecture, the Cisco Silicon One P200 is the definitive answer. It is the only 51.2Tbps deep-buffer routing chip designed to scale across all DCI needs – from single-box deployments to modular and multi petabit fabrics. The P200 delivers industry-leading low power and features groundbreaking programmable run-to-completion engines to prepare networks for future protocols and new advances in integrated security. With the P200 you get the peace of mind that your DCI network is built with a highly efficient, low-power, secure, and future-ready device, helping ensure that you are ready for both today’s and tomorrow’s AI demands.
The Cisco Silicon One P200 Processor is a 51.2Tbps full-duplex routing processor with deep buffers that can be configured as:
● 51.2Tbps full-duplex, standalone routing processor with deep buffers
● 25.6Tbps full-duplex line card routing processor with deep buffers
The Cisco Silicon One P200 can be used together to build a wide range of products covering fixed-form-factor routers and switches, modular-chassis routers and switches, and multipetabit disaggregated routers and switches.
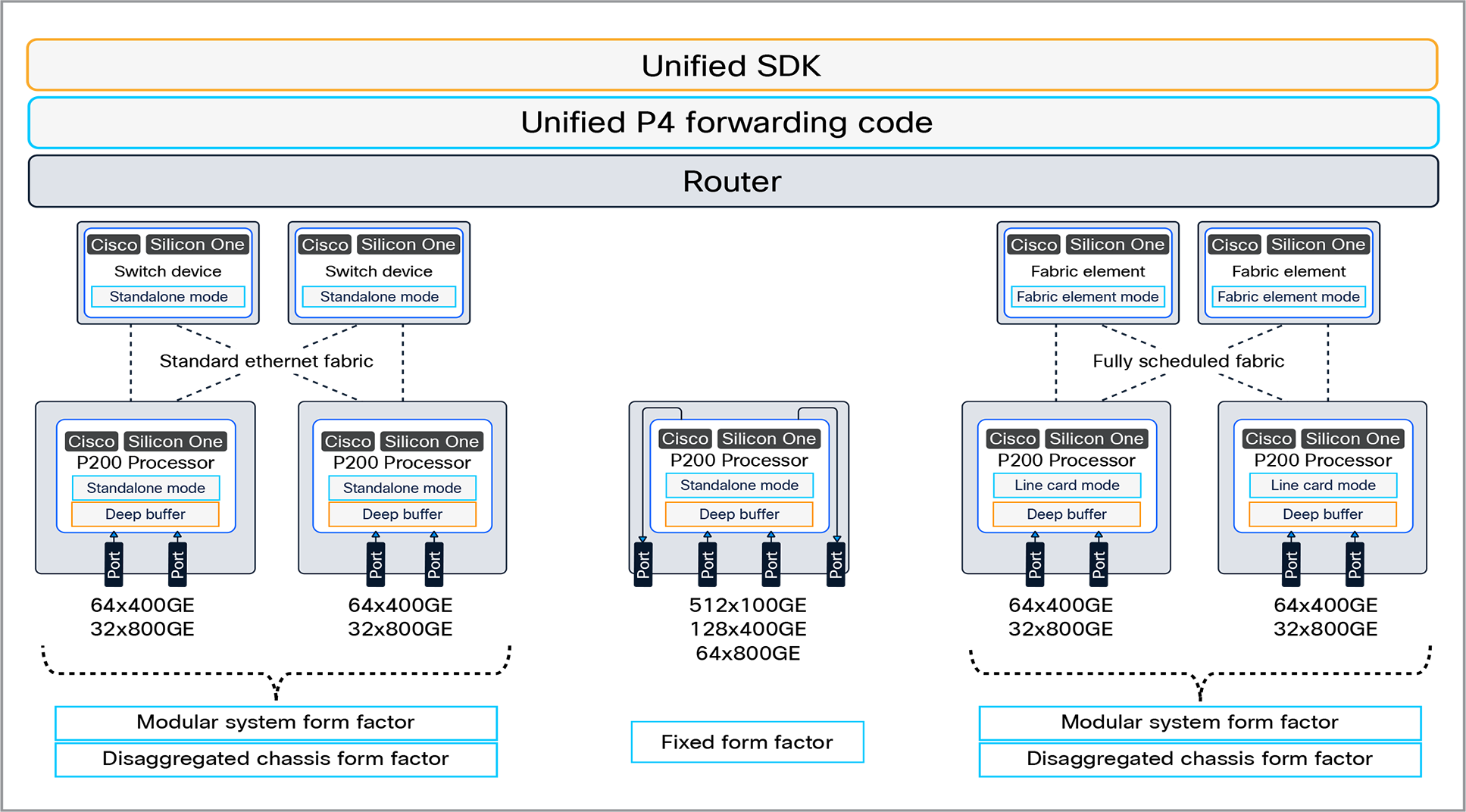
Cisco Silicon One form factors
Table 1. Architectural characteristics and benefits
| Feature |
Benefit |
| Unified architecture across multiple markets |
Greatly simplifies customer network infrastructure deployments |
| Unified Software Development Kit (SDK) across market segments and applications |
Provides a consistent point of integration for all applications across the entire network infrastructure |
| High-bandwidth routing silicon |
51.2Tbps full duplex deep buffer silicon |
| High-performance routing silicon |
Highly programmable run-to-completion packet processor |
| Power-efficient routing silicon |
The most power efficient 51.2Tbps full duplex deep buffer silicon |
| Large and fully unified packet buffer |
Fully shared on-die buffer with large external packet buffer |
| Switching efficiency with routing features and scale |
Addresses the requirements of web-scale providers’ and service providers’ routing applications |
| Run-to-completion network processor |
Feature flexibility without compromising performance or power efficiency |
| Programmable |
The P200 programmable processor allows for rapid feature development and assures the system is future proof |
Flexibility, Performance, and Power Efficiency for Next-Generation Scale Across Networks
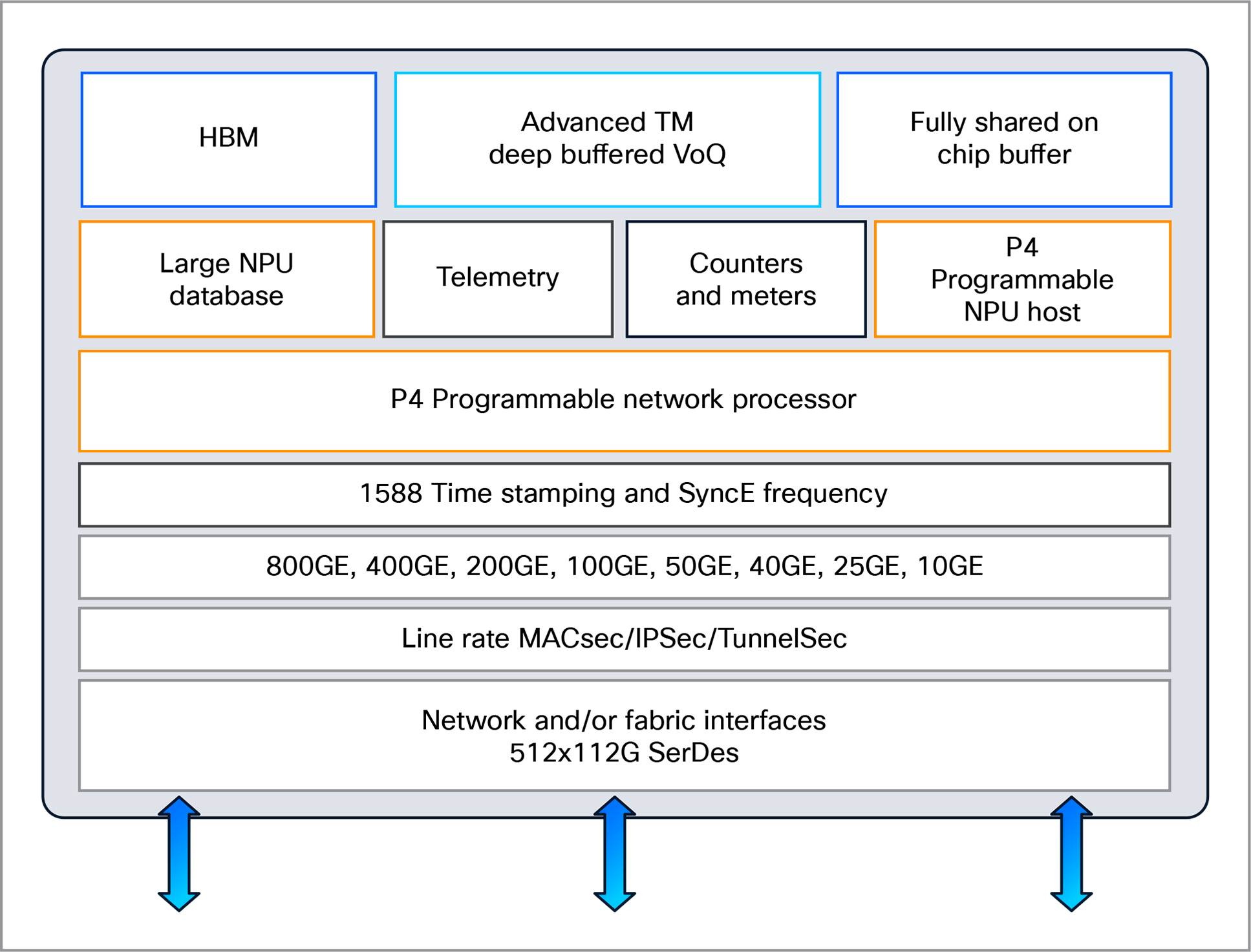
Block diagram
Features
● 512x 112G SerDes; each can be configured independently to operate in 10GE, 25GE, 50GE, or 100GE using Non-Return-to-Zero (NRZ) modulation or four-level Pulse-Amplitude Modulation (PAM4)
● Flexible port configuration supporting 10, 25, 40, 50, 100, 200, 400, or 800 Gbps
● Large, fully shared, on-die packet buffer
● Large in package external packet buffer
● 1588v2 and Synchronous Ethernet (SyncE) support with nanosecond-level accuracy
● On-chip, high-performance, programmable host Neural Processing Unit (NPU) for high-bandwidth offline packet processing (for example, Operations, Administration, and Maintenance [OAM] processing, MAC learning)
● Multiple embedded processors for CPU offloading
Traffic management
● Large pool of configurable queues, supporting DiffServ and hierarchical Quality of Service (QoS)
● Support for system-level, end-to-end QoS and scheduling for both unicast and multicast traffic
● Seamless extension of on-die buffer to external packet buffer
● Support for ingress and egress traffic mirroring
● Support for link-level (IEEE 802.3x), Priority Flow Control (PFC) (802.1Qbb), and Explicit Congestion Notification (ECN) marking
● Support for port extenders
Network processor
● Run-to-completion, distributed programmable network processor
● Line rate at very small packets, even with complex packet processing
● Large and shared fungible tables
● Support for complex packet processing features without impacting data rate
● Support for simple packet processing features with optimized power and latency
Load balancing
● Flow load balancing using Equal Cost Multipath (ECMP) or Link Aggregation Group (LAG)
● Adaptive flow switching
● Packet-by-packet load balancing, creating an optimal, flow-independent, end-to-end scheduled and lossless fabric
Instrumentation and telemetry
● Programmable meters used for traffic policing and coloring
● Programmable counters used for flow statistics and OAM loss measurements
● Programmable counters used for port utilization, microburst detection, delay measurements, flow tracking, elephant flow detection, and congestion tracking
● Traffic mirroring: Encapsulated Remote Switched Port Analyzer [(ER)SPAN] on drop
● Support for sFlow and NetFlow
● Support for in-band telemetry
SDK
● APIs provided in both C++ and Python
● Switch Abstraction Interface (SAI) and SONiC support
● Configurability via high-level networking objects
● Distribution-independent Linux packaging
● Robust simulation environment, enabling rapid feature development
P4 programmability
● Application development is handled by an Integrated Development Environment (IDE)
● At compilation, the application generates low-level register/memory access APIs and higher-level SDK application APIs
● Provides application support for a wide range of data center, service provider, and enterprise protocols
● Ability to develop the SDK and applications running over the SDK over a simulated Cisco Silicon One device
Cisco P4 application
Due to Silicon One’s extensible programming toolkit, we are always adding features to address new markets and new customer requirements; however, a sample of the features that are currently available with the application code is provided below.
Table 2. Sample of features currently available
|
● IPv4/v6 routing
◦ SRv6 ◦ Open Shortest Path First (OSPF) ◦ Intermediate System-to-Intermediate System (IS-IS) ◦ Border Gateway Protocol (BGP)
● Multiprotocol Label Switching (MPLS) forwarding
◦ Label Distribution Protocol (LDP), LDPoTE ◦ RSVP-TE ◦ Segment Routing (SR)-MPLS ◦ SR for Traffic Engineering (SR-TE) ◦ L3VPN, IPv6 Provider Edge (6PE), IPv6 VPN PE (6VPE) ◦ BGP Labeled Unicast (LU) ◦ Virtual Private Wire Service (VPWS)/ Ethernet over MPLS (EoMPLS) ◦ Virtual Private LAN Services (VPLS)
● Ethernet switching
◦ 802.1d, 802.1p, 802.1q, 802.1ad
● IP tunneling
◦ IP-in-IP ◦ Generic Routing Encapsulation (GRE) ◦ VXLAN
● Integrated Routing and Bridging (IRB)
● Hot Standby Router Protocol (HSRP)/ Virtual Router Redundancy Protocol (VRRP)
● Policy-based routing
● Security and QoS ACLs
|
● ECMP and LAG (802.3ad)
● Multicast
◦ Protocol Independent Multicast sparse mode (PIM-SM)/Source Specific Multicast (SSM) ◦ Internet Group Management Protocol (IGMP) ◦ Multicast LDP (MLDP) ◦ Multicast VPN (MVPN)
● Network Address Translation (NAT)/Port Address Translation (PAT)
● Protection (link/node/path and Topology-Independent Loop-Free Alternate [TI-LFA])
● QoS classification and marking
● Congestion management
● Telemetry
◦ NetFlow, sFlow ◦ (ER)SPAN ◦ Packet mirroring with appended metadata ◦ Lawful intercept
● Distributed Denial-of-Service (DDoS) mitigation
◦ Control-plane policing ◦ BGP flow specification (flowspec)
● Timing and frequency synchronization
◦ SyncE ◦ 1588 |
Information about Cisco’s Environmental, Social and Governance (ESG) initiatives and performance is provided in Cisco’s CSR and sustainability reporting.
Table 3. Cisco environmental sustainability information
| Sustainability topic |
Reference |
|
| General |
Information on product-material-content laws and regulations |
Materials |
| Information on electronic waste laws and regulations, including our products, batteries, and packaging |
||
| Information on our product takeback and reuse program |
||
| Sustainability inquiries |
Contact: csr_inquiries@cisco.com |
|
| Material |
Product packaging weight and materials |
Contact: environment@cisco.com |
Learn more about Cisco Silicon One.