
Cutting-edge features that improve performance and sustainability

Expect more from your data center and storage network infrastructure with Cisco Nexus and Cisco MDS switches.
Industry-leading performance
Get deep visibility, tighter security, and faster application performance with Cisco silicon.
Scalable infrastructure
Virtualization, high density, and performance—all supporting scalable and efficient growth.
Easy programming
Automate from day 0 to day N with APIs and programmable tools.
Energy efficiency
Efficient power and cooling with real-time energy insights drive sustainable data center operations, helping lower your total cost of ownership.

Cisco named a Leader in Gartner® 2025 Magic Quadrant™ for Data Center Switching
See why we believe our industry-leading performance, simplicity, and scalability helped us earn this recognition.
Cisco Nexus 9400 Series switches
These switches pack high performance and density plus better telemetry into a compact, modular design.
Nexus 9500 Series switches
Enterprise or high growth? Modular configurations can support you with ports from 1G to 400G.
Nexus 9800 Series switches
Get high-density 400G switching that's designed for 800G adoption and beyond.
Nexus 400G and 800G family
Bandwidth like you’ve never known. Adopt 400G with scalability to 800G with confidence in a family of 1, 2, and 4 RU switches.
Optics
Fiber-optic transceiver modules to accelerate your network connections.
Cisco Nexus 3500 Series portfolio
Design efficient, low-latency networks with programmable platforms, switches, and smart adapters.
Cisco Nexus 3550-T Series
FPGA-based programmable network platform for critical, ultra-low latency network applications.
Cisco Nexus SmartNICs
FPGA-based network interface cards (NICs). Ideal for ultra-low latency, high-resolution timestamping.
Cisco Nexus 3500 Series switches
Low-latency, 1 RU switches supporting 1G to 40G. Ideal for high-frequency trading (HFT) and big data environments.
Cisco MDS 9700 Series
A SAN director with scale, performance, integrated analytics, and superior port density.
MDS 9300 Series
Next-generation high-density fabric switch with integrated analytics and telemetry.
MDS 9200 Series
High-performance SAN extension, disaster recovery, intelligent fabrics, and multiprotocol connectivity.
MDS 9100 Series
Flexible and agile, highly available and secure, and easy to use, with visibility to every flow.
Cisco SAN Analytics
Visibility and data-driven guidance, for faster troubleshooting and optimized infrastructure.
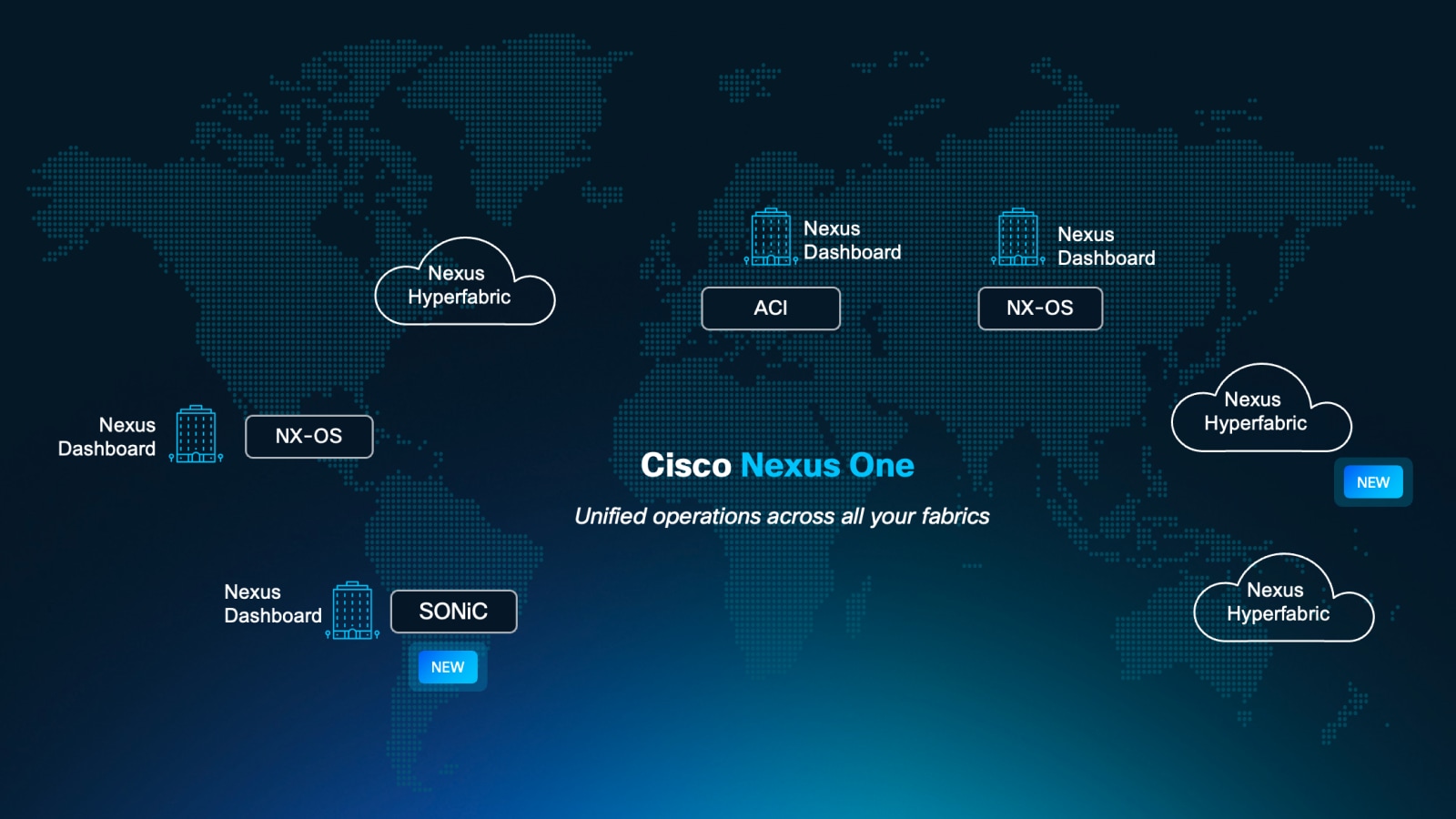
Cisco Application Centric Infrastructure (ACI)
Simplifies data center network management, boosts security with centralized app-centric approach with automation and policy-based control driving agile IT.
Cisco NX-OS
Make your network agile, easily scalable, and secure with simplified network operations and integrated automation.
Cisco Nexus Dashboard
Configure, operate, and analyze, all from one place. Private cloud managed across your data center networks.
Cisco Nexus Hyperfabric
New plug-and-play, cloud-managed operations and validation of the full lifecycle of data center networks.
Cisco N9300 Series Smart switches
Cisco smart switch with Cisco Hypershield is our platform play that integrates networking with security services.


Data center transformation starts here
Customer stories
Services and support
Portfolio buying guide
Cisco Enterprise Agreement
Bring the power and breadth of our entire technology portfolio under a single, simplified agreement.
Business-critical services
Move your business forward
Build modern, agile IT environments with advisory services designed to help you adapt and transform.