Use ML-Based Document Classification for Efficient DLP Policy Management
Available Languages
Contents
Introduction
This document describes how to use ML-based document classification (Built with Meta Llama 3) to simplify and enhance data loss prevention (DLP) policy management.
Overview
ML document classification improves content matching and makes DLP policy management easier. You can select from predefined, pre-trained document types, eliminating the need to build complex data classifications from scratch based on terms and patterns.
How to Use ML-Based Document Classification
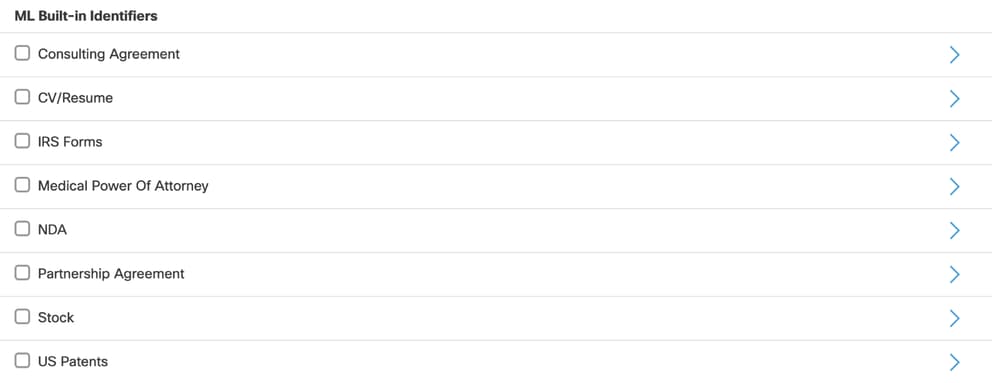
- ML-based document classification is available as a built-in identifier when you create a data classification.
- All supported ML-based identifiers appear in the ML Built-in Identifiers section during data classification setup.
 26221783199892
26221783199892
Supported Document Types
You can use ML-based classification for these document types:
- Consulting agreements
- CVs and resumes
- IRS forms
- Medical power of attorney
- Non-disclosure agreements (NDA)
- Partnership agreements
- Stock and US patents
Supported Languages and Regions
The initial release supports US English language documents only. Support for additional languages and regions is planned for future updates.
Multimode DLP Support
ML-based document classification works with both Realtime DLP and SaaS API DLP. It is compatible with all DLP supported file types.
Related Resources
Refer to Secure Access and Umbrella documentation for guidance on using ML-based data identifiers in data classifications and DLP rules:
- Secure Access: Built In Data Identifiers
- Umbrella: Built In Data Identifiers
Revision History
| Revision | Publish Date | Comments |
|---|---|---|
2.0 |
20-Jul-2026
|
Initial Release |
1.0 |
21-Oct-2025
|
Initial Release |
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)