ハイ アベイラビリティの仕組み
Cisco EPN Manager ハイ アベイラビリティ(HA)フレームワークでは、障害が発生してもシステム動作が継続されます。HA では、リンクされて同期された Cisco EPN Manager サーバーのペアを使用して、いずれかのサーバーで発生する可能性のあるアプリケーション障害またはハードウェア障害による影響を最小限に、あるいは完全に排除します。サーバーの障害は、以下の 1 つ以上の領域での問題が原因で発生する可能性があります。
-
アプリケーション プロセス:サーバー、TFTP、FTP などのプロセスの失敗。CLI ncs status コマンドを使用して、これらのプロセスのステータスを確認できます。
-
データベース サーバー:データベース関連のプロセスの失敗(データベース サーバーは Cisco EPN Manager でサービスとして実行されます)。
-
ネットワーク:ネットワーク アクセスまたは到達可能性に関連する問題。
-
システム:サーバーの物理ハードウェアまたはオペレーティング システムに関連する問題。
-
仮想マシン(HA が VM 環境で稼動している場合):プライマリ サーバーとセカンダリ サーバーがインストールされている VM 環境に関する問題。
次の図は、HA セットアップの主なコンポーネントとプロセス フローを示しています。
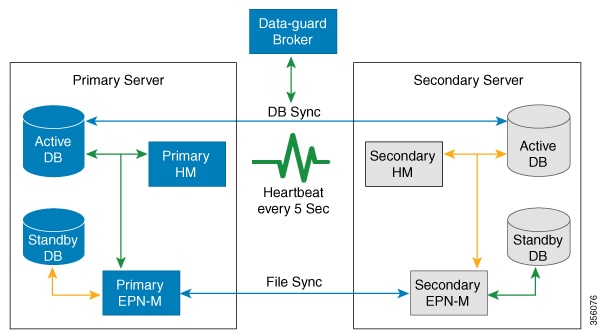
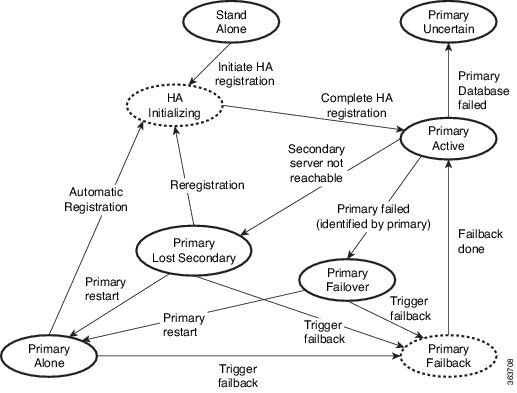
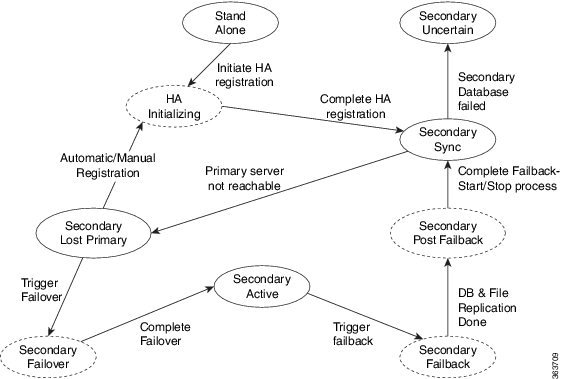
HA 展開は、プライマリ サーバーとセカンダリ サーバーで構成され、両方のサーバー上にヘルス モニター(HM)インスタンス(アプリケーション プロセスとして実行)が存在します。プライマリ サーバーに障害が発生(自動的に発生、または手動で停止したために発生)すると、プライマリ サーバーへのアクセスが復元されるまでの間はセカンダリ サーバーがネットワークの管理を引き継ぎます。展開で自動フェールオーバーを設定すると、セカンダリ サーバーはフェールオーバー後 2 ~ 3 分以内にアクティブ ロールを引き継ぎます。この HA は、アクティブ/パッシブまたはコールド スタンバイの動作モデルに基づいています。クラスタ化されたシステムではないため、プライマリ サーバーに障害が発生した場合、セッションはセカンダリ サーバーに保持されません。
プライマリ サーバーの問題が解決してサーバーが実行状態になっても、アクティブなセカンダリ サーバーとのデータの同期を開始する間はスタンバイ モードのままになります。プライマリ サーバーが再び使用可能になった時点で、フェールバック操作を開始できます。フェールバックがトリガーされると、プライマリ サーバーがアクティブ ロールを再度引き継ぎます。このようなプライマリ サーバーとセカンダリ サーバー間でのロールの切り替えは、2 ~ 3 分以内に実行されます。
HA 設定によってプライマリ サーバーでの変更が確認されると、変更内容がセカンダリ サーバーと同期されます。これらの変更には、次の 2 種類があります。
-
ファイルの変更。HTTPS プロトコルを使用して同期されます。対象となる項目には、レポート設定、設定テンプレート、TFTP ルート ディレクトリ、管理設定、ライセンス ファイル、キー ストアなどがあります。ファイルの同期は、以下のいずれかで行われます。
-
頻繁に更新されないファイル(ライセンス ファイルなど)の同期は、一括で行われます。これらのファイルは、500 秒間隔で同期されます。
-
頻繁に更新されるファイルの同期は、ほぼリアルタイムで行われます。これらのファイルは、11 秒間隔で同期されます。
-
-
データベースの変更(設定、パフォーマンス、およびモニターリング データに関連する更新など)。Oracle Recovery Manager(RMAN)が最初のスタンバイ データベースを作成し、変更が発生すると、Oracle Active Data Guard がデータベースを同期します。
プライマリ HA サーバーとセカンダリ HA サーバーは、次のメッセージを交換して 2 つのサーバー間の同期を維持します。
-
データベース同期:プライマリ サーバーとセカンダリ サーバー上のデータベースが稼働および同期するために必要なすべての情報が含まれます。
-
ファイル同期:頻繁に更新されるコンフィギュレーション ファイルが含まれます。これらのファイルは 11 秒間隔で同期され、他の頻繁に更新されないコンフィギュレーション ファイルは 500 秒間隔で同期されます

(注)
プライマリで手動で更新されたコンフィギュレーション ファイルは、セカンダリに同期されません。プライマリでコンフィギュレーション ファイルを手動で更新する場合は、セカンダリ上のファイルも更新する必要があります。
-
プロセス同期:アプリケーションおよびデータベースに関連するプロセスの実行が継続されるようにします。これらのメッセージは、ハートビート カテゴリに分類されます。
-
ヘルス モニター同期:これらのメッセージは、ネットワーク、システム、およびヘルス モニターの障害状態の有無を確認します。
 フィードバック
フィードバック