Health and Performance Monitor Overview
The Health and Performance Monitor is a stand-alone application that you can launch from the other stand-alone Security Manager applications (Dashboard, Configuration Manager, Event Viewer, Report Manager, and Image Manager) or from the Cisco Security Manager Client login screen accessed from the Windows Start menu.
The HPM application complements the Event Viewer and Report Manager applications, as follows:
-
Event Viewer – Monitors your network for syslog (system log) events from ASA and FWSM devices and their security contexts, and for SDEE (Secure Device Event Exchange) events from IPS devices and virtual sensors. These events include firewall traffic information, NAT events, failover events, IPS alerts, and so on. Event Viewer collects and displays this information, organized into a variety of views. See Introduction to Event Viewer Capabilities for more information.
-
Report Manager – Collects, displays and exports network usage and security information for ASA and IPS devices, and for remote-access IPsec and SSL VPNs. These reports aggregate security data such as top sources, destinations, attackers, victims, as well as security information such as top bandwidth, duration, and throughput users. Data is also aggregated for hourly, daily, and monthly periods. See Understanding Report Management for more information.
-
Health and Performance Monitor (HPM) – Monitors and displays key health, performance and VPN data for ASA and IPS devices in your network. This information includes critical and non-critical issues, such as memory usage, interface status, dropped packets, tunnel status, and so on. You also can categorize devices for normal or priority monitoring, and set different alert rules for the priority devices.
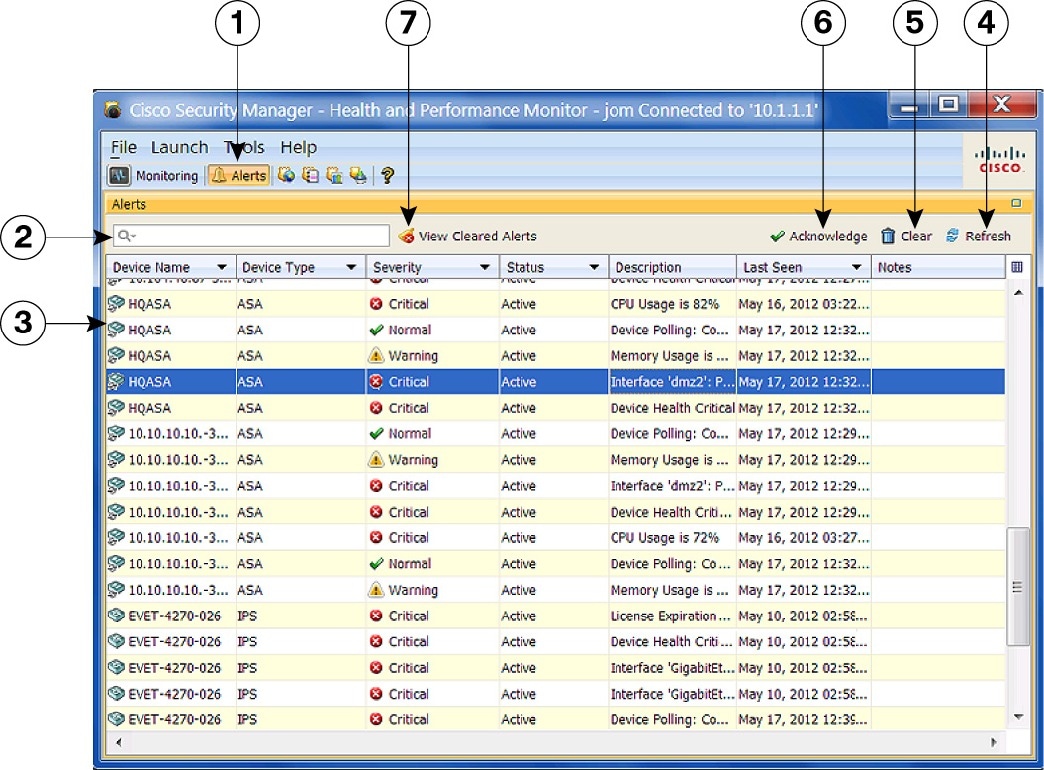
You can add notes to displayed alerts, you can “acknowledge” them, and you can clear them. When an alert is cleared, it is removed from the Alerts display; however, the alert information is retained in a database for 30 days. See Alerts: Acknowledging and Clearing for more information about adding notes, and acknowledging and clearing alerts.
 Note |
You can use the Alerts History window to access and view previously cleared alerts, as described in Alerts: History. |
This section contains the following topics:
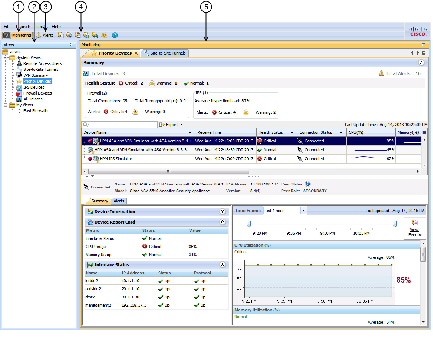
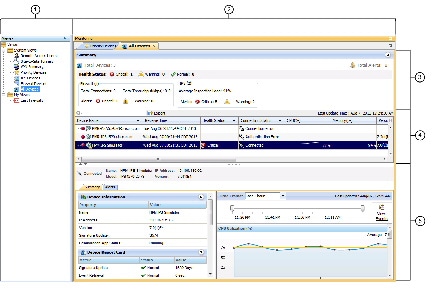
Trend Information
The Health and Performance Monitor periodically polls monitored devices for status and performance data. This information is used for alert generation, and to display real-time views and historical trends based on aggregated data.
Trends are displayed graphically for a specific set of metrics. Each trend for the currently selected device is represented as a graph generated for a chosen time interval. Comparing current values with the weekly averages for CPU and memory usage, for example, can provide an operational context for the selected device. Available trend intervals for monitored devices are one hour, 24 hours, and one week.
Metrics used for generating trends include:
-
CPU usage
-
Memory usage (only for single-context devices)
-
Connections per second (firewall devices)
-
Translations per second (firewall devices)
-
Inspection load (IPS devices)
-
Missed packets as a percentage (IPS devices)
-
Number of VPN tunnels
-
Number of RA VPN sessions
-
Total VPN throughput
-
Firewall throughput
-
Total dropped packets (firewall interfaces)
For additional graphical information about the health and performance of a specific device, you can launch the related device manager by right-clicking the entry for a device, a cluster node, or the system context for a multi-context device, and then choosing Device Manager from the pop-up menu. See Starting Device Managers for more information about the device managers.
Monitoring Multiple Contexts
The Health and Performance Monitor can monitor single- and multiple-context ASA devices. For multiple-context devices, each context is monitored and displayed as if it was a separate device.
Each context will be polled separately for all applicable metrics, with HPM polling a maximum of five contexts at a time from any given device. For devices with more than five contexts, data will be acquired from each successive batch of five contexts, with each batch being polled progressively during successive polling cycles. This means that all contexts may not be updated at the same time.
For multiple-context devices, basic device health—memory usage, device status, and so on—is monitored only on the physical device (that is, from the system context), while traffic data—number of connections, number of translations, dropped packets and so on—are monitored at context level.
For virtual contexts, CPU usage data are used only for pattern analysis, not for alert generation. Only interface-status alerts will be generated for virtual contexts.


 Feedback
Feedback