MPLS Configuration Guide for Cisco NCS 5500 Series Routers, IOS XR Release 6.3.x
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
MPLS (Multi Protocol Label Switching) is a forwarding mechanism based on label switching. In an MPLS network, data packets
are assigned labels and packet-forwarding decisions are taken based on the contents of the label. To switch labeled packets
across the MPLS network, predetermined paths are established for various source-destination pairs. These predetermined paths
are known as Label Switched Paths (LSPs). To establish LSPs, MPLS signaling protocols are used. Label Distribution Protocol
(LDP) is an MPLS signaling protocol used for establishing LSPs. This module provides information about how to configure MPLS
LDP.
Prerequisites for
Implementing MPLS Label Distribution Protocol
The following are the
prerequisites to implement MPLS LDP:
You must be in a user group associated with a task group that includes the proper task IDs. The command reference guides include
the task IDs required for each command. If you suspect user group assignment is preventing you from using a command, contact
your AAA administrator for assistance.
You must be
running
Cisco IOS XR software.
You must install a composite mini-image and the MPLS package.
Note
This point is not appplicable for a Cisco NCS 540 Series Router.
You must activate
IGP.
We recommend to use a lower session holdtime bandwidth such as neighbors so that a session down occurs before an adjacency-down
on a neighbor. Therefore, the following default values for the hello times are listed:
Holdtime is 15 seconds.
Interval is 5 seconds.
For example, the
LDP session holdtime can be configured as 30 seconds by using the
holdtime
command.
Overview of Label
Distribution Protocol
In IP forwarding, when
a packet arrives at a router the router looks at the destination address in the
IP header, performs a route lookup, and then forwards the packet to the next
hop. MPLS is a forwarding mechanism in which packets are forwarded based on
labels. Label Distribution Protocols assign, distribute, and install the labels
in an MPLS environment. It is the set of procedures and messages by which Label
Switched Routers (LSRs) establish LSPs through a network by mapping
network-layer routing information directly to data-link layer switched paths.
These LSPs may have an endpoint at a directly attached neighbor (comparable to
IP hop-by-hop forwarding), or may have an endpoint at a network egress node,
enabling switching via all intermediary nodes.
LSPs can be created
statically, by RSVP traffic engineering (TE), or by LDP. LSPs created by LDP
perform hop-by-hop path setup instead of an end-to-end path. LDP enables LSRs
to discover their potential peer routers and to establish LDP sessions with
those peers to exchange label binding information. Once label bindings are
learned, the LDP is ready to setup the MPLS forwarding plane.
Depending on the requirements, LDP
requires some basic configuration tasks described in the following topics:
Configuring Label
Distribution Protocol
This section explains
the basic LDP configuration. LDP should be enabled on all interfaces that
connects the router to potential LDP peer routers. You can enable LDP on an
interface by specifying the interface under mpls ldp configuration mode.
Configuration
Example
This example shows
how to enable LDP over an interface.
Configuring Label
Distribution Protocol Discovery Parameters
LSRs that are running
LDP sends hello messages on all the LDP enabled interfaces to discover each
other. So, the LSR that receives the LDP hello message on an interface is aware
of the presence of the LDP router on that interface. If LDP hello messages are
sent and received on an interface, there is an LDP adjacency across the link
between the two LSRs that are running LDP. By default, hello messages are sent
every 5 seconds with a hold time of 15 seconds. If the LSR does not receive a
discovery hello from peer before the hold time expires, the LSR removes the
peer LSR from the list of discovered LDP neighbors . The LDP discovery
parameters can be configured to change the default parameters.
LDP session between
LSRs that are not directly connected is known as targeted LDP session. For
targeted LDP sessions, LDP uses targeted hello messages to discover the
extended neighbors. By default, targeted hello messages are sent every 10
seconds with a hold time of 90 seconds.
Configuration
Example
This example shows
how to configure the following LDP discovery parameters:
This section
verifies the MPLS LDP discovery parameters configuration.
RP/0/RP0/CPU0:Router# show mpls ldp parameters
LDP Parameters:
Role: Active
Protocol Version: 1
Router ID: 192.168.70.1
Discovery:
Link Hellos: Holdtime:30 sec, Interval:10 sec
Targeted Hellos: Holdtime:120 sec, Interval:15 sec
Quick-start: Enabled (by default)
Transport address: IPv4: 192.168.70.1
Label Distribution
Protocol Discovery for Targeted Hellos
LDP session between
LSRs that are not directly connected is known as targeted LDP session. For LDP
neighbors which are not directly connected, you should manually configure the
LDP neighborship on both the routers.
Configuration
Example
This example shows
how to configure LDP for non-directly connected routers, Router1 and Router 2.
LDP allows you to
control the advertising and receiving of labels. You can control the exchange
of label binding information by using label advertisement control (outbound
filtering ) or label acceptance control (inbound filtering).
Label
Advertisement Control (Outbound Filtering)
Label Distribution
Protocol advertises labels for all the prefixes to all its neighbors. When this
is not desirable (for scalability and security reasons), you can configure LDP
to perform outbound filtering for local label advertisement for one or more
prefixes to one more peers. This feature is known as LDP outbound label
filtering, or local label advertisement control. You can control the exchange
of label binding information using the
mpls ldp
label advertise
command. Using the optional keywords, you can advertise
selective prefixes to all neighbors, advertise selective prefixes to defined
neighbors, or disable label advertisement to all peers for all prefixes.
Prefixes and peers advertised selectively are defined in the access list.
Configuration
Example: Label Advertisement Control
This example shows
how to configure outbound label advertisement control. In this example,
neighbors are specified to advertise and receive label advertisements. Also an
interface is specified for label advertisement.
RP/0/RP0/CPU0:Router(config)# mpls ldp
RP/0/RP0/CPU0:Router(config-ldp)# address-family ipv4
RP/0/RP0/CPU0:Router(config-ldp-af)# label local advertise to 1.1.1.1:0 for pfx_ac11
RP/0/RP0/CPU0:Router(config-ldp-af)# label local advertise interface TenGigE 0/0/0/5
RP/0/RP0/CPU0:Router(config-ldp-af)# commit
Label
Acceptance Control (Inbound Filtering)
LDP accepts labels
(as remote bindings) for all prefixes from all peers. LDP operates in liberal
label retention mode, which instructs LDP to keep remote bindings from all
peers for a given prefix. For security reasons, or to conserve memory, you can
override this behavior by configuring label binding acceptance for set of
prefixes from a given peer. The ability to filter remote bindings for a defined
set of prefixes is also referred to as LDP inbound label filtering or label
acceptance control.
Configuration
Example : Label Acceptance Control (Inbound Filtering)
This example shows
how to configure label acceptance control. In this example, an LSR is
configured to accept and retain label bindings from neighbors for prefixes
defined in access list .
RP/0/RP0/CPU0:Router(config)#mpls ldp
RP/0/RP0/CPU0:Router(config-ldp)#address-family ipv4
RP/0/RP0/CPU0:Router(config-ldp-af)#label remote accept from 192.168.1.1:0 for acl_1
RP/0/RP0/CPU0:Router(config-ldp-af)#label remote accept from 192.168.2.2:0 for acl_2
RP/0/RP0/CPU0:Router(config-ldp-af)#commit
Configuring Local
Label Allocation Control
LDP creates label bindings for all IGP prefixes and receives label
bindings for all IGP prefixes from all its peers. If an LSR receives label
bindings from several peers for thousands of IGP prefixes, it consumes
significant memory and CPU. In some scenarios, most of the LDP label bindings
may not useful for any application and you may required to limit the allocation
of local labels. This is accomplished using LDP local label allocation control,
where an access list can be used to limit allocation of local labels to a set
of prefixes. Limiting local label allocation provides several benefits,
including reduced memory usage requirements, fewer local forwarding updates,
and fewer network and peer updates.
Configuration Example
This example shows how to configure local label allocation using an IP
access list to specify a set of prefixes that local labels can allocate and
advertise.
RP/0/RP0/CPU0:Router(config)# mpls ldp
RP/0/RP0/CPU0:Router(config-ldp)# address-family ipv4
RP/0/RP0/CPU0:Router(config-ldp-af)# label local allocate for pfx_acl_1
RP/0/RP0/CPU0:Router(config-ldp-af)# commit
Configuring
Downstream on Demand
By default, LDP uses downstream unsolicited mode in which label
advertisements for all routes are received from all LDP peers. The downstream
on demand feature adds support for downstream-on-demand mode, where the label
is not advertised to a peer, unless the peer explicitly requests it. At the
same time, since the peer does not automatically advertise labels, the label
request is sent whenever the next-hop points out to a peer that no remote label
has been assigned.
In downstream on demand configuration, an ACL is used to specify the set
of peers for downstream on demand mode. For down stream on demand to be
enabled, it needs to be configured on both peers of the session. If only one
peer in the session has downstream-on-demand feature configured, then the
session does not use downstream-on-demand mode.
Configuration Example
This example shows how to configure LDP Downstream on Demand.
RP/0/RP0/CPU0:Router(config)# mpls ldp
RP/0/RP0/CPU0:Router(config-ldp)# session downstream-on-demand with ACL1
RP/0/RP0/CPU0:Router(config-ldp)# commit
Configuring Explicit
Null Label
Cisco MPLS LDP uses
implicit or explicit null label as local label for routes or prefixes that
terminate on the given LSR. These routes include all local, connected, and
attached networks. By default, the null label is
implicit-null
that allows LDP control plane to implement penultimate hop popping (PHP)
mechanism. When this is not desirable, you can configure
explicit-null
label that allows LDP control plane to implement ultimate hop popping (UHP)
mechanism. You can configure explicit-null feature on the ultimate hop LSR.
Access-lists can be used to specify the IP prefixes for which PHP is desired.
You can enforce
implicit-null local label for a specific prefix by using the
implicit-null-override command even if the prefix
requires a non-null label to be allocated by default. For example, by default,
an LSR allocates and advertises a non-null label for an IGP route. If you wish
to terminate LSP for this route on penultimate hop of the LSR, you can enforce
implicit-null label allocation and advertisement for this prefix using the
implicit-null-override
command.
Configuration
Example: Explicit Null
This example shows
how to configure explicit null label.
This example shows
how to configure implicit null override for a set of prefixes.
RP/0/RP0/CPU0:Router(config)# mpls ldp
RP/0/RP0/CPU0:Router(config-ldp)# address-family ipv4
RP/0/RP0/CPU0:Router(config-ldp-af)# label local advertise implicit-null-override for acl-1
RP/0/RP0/CPU0:Router(config-ldp-af)# commit
Label Distribution
Protocol Auto-configuration
LDP auto-configuration allows you to automatically configure LDP on all
interfaces for which the IGP protocol is enabled. Typically, LDP assigns and
advertises labels for IGP routes and must often be enabled on all active
interfaces by an IGP. During LDP manual configuration, you must define the set
of interfaces under LDP which is a time-intensive procedure. LDP
auto-configuration eliminates the need to specify the same list of interfaces
under LDP and simplifies the configuration tasks.
Configuration Example: Enabling LDP Auto-Configuration for
OSPF
This example shows how to enable LDP auto-configuration for a
specified OSPF instance.
When a new link or
node comes up after a link failure, IP converges earlier and much faster than
MPLS LDP and may result in MPLS traffic loss until the MPLS convergence. If a
link flaps, the LDP session also flaps due to loss of link discovery. LDP
session protection minimizes traffic loss, provides faster convergence, and
protects existing LDP (link) sessions. When session protection is enabled for a
peer, LDP starts sending targeted hello (directed discovery) in addition to
basic discovery link hellos. When the direct link goes down, the targeted
hellos can still be forwarded to the peer LSR over an alternative path as long
as there is one. So, the LDP session stays up after the link goes down.
You can configure LDP
session protection to automatically protect sessions with all or a given set of
peers (as specified by peer-acl). When configured, LDP initiates backup
targeted hellos automatically for neighbors for which primary link adjacencies
already exist. These backup targeted hellos maintain LDP sessions when primary
link adjacencies go down.
Configuration
Example
This example shows
how to configure LDP session protection for peers specified by the access
control list peer-acl-1 for a maximum duration of 60 seconds.
Configuring Label
Distribution Protocol- Interior Gateway Protocol (IGP) Synchronization
Lack of
synchronization between LDP and Interior Gateway Protocol (IGP) can cause MPLS
traffic loss. Upon link up, for example, IGP can advertise and use a link
before LDP convergence has occurred or, a link may continue to be used in IGP
after an LDP session goes down.
LDP IGP
synchronization coordinates LDP and IGP so that IGP advertises links with
regular metrics only when MPLS LDP is converged on that link. LDP considers a
link converged when at least one LDP session is up and running on the link for
which LDP has sent its applicable label bindings and received at least one
label binding from the peer. LDP communicates this information to IGP upon link
up or session down events and IGP acts accordingly, depending on sync state.
LDP-IGP
synchronization is supported for both OSPF and ISIS protocols and is configured
under the corresponding IGP protocol configuration mode. Under certain
circumstances, it might be required to delay declaration of re-synchronization
to a configurable interval. LDP provides a configuration option to delay
declaring synchronization up for up to 60 seconds. LDP communicates this
information to IGP upon linkup or session down events.
From the 7.1.1 release, you can configure multiple MPLS-TE tunnel end points on an LER using the TLV 132 function in IS-IS.
You can configure a maximum of 63 IPv4 addresses or 15 IPv6 addresses on an LER.
Configuring LDP
IGP Synchronization: Open Shortest Path First (OSPF) Example
This example shows
how to configure LDP-IGP synchronization for an OSPF instance. The
synchronization delay is configured as 30 seconds.
Configuring Label
Distribution Protocol Graceful Restart
LDP Graceful Restart
provides a mechanism for LDP peers to preserve the MPLS forwarding state when
the LDP session goes down. Without LDP Graceful Restart, when an established
session fails, the corresponding forwarding states are cleaned immediately from
the restart and peer nodes. In this case, LDP forwarding has to restart from
the beginning, causing a potential loss of data and connectivity. If LDP
graceful restart is configured, traffic can continue to be forwarded without
interruption, even when the LDP session restarts. The LDP graceful restart
capability is negotiated between two peers during session initialization time.
During session initialization, a router advertises its ability to perform LDP
graceful restart by sending the graceful restart typed length value (TLV). This
TLV contains the reconnect time and recovery time. The values of the reconnect
and recovery times indicate the graceful restart capabilities supported by the
router. The reconnect time is the amount of time the peer router waits for the
restarting router to establish a connection. When a router discovers that a
neighboring router is restarting, it waits until the end of the recovery time
before attempting to reconnect. Recovery time is the amount of time that a
neighboring router maintains its information about the restarting router.
Configuration
Example
This example shows
how to configure LDP graceful restart. In this example, the amount of time that
a neighboring router maintains the forwarding state about the gracefully
restarting router is specified as 180 seconds. The reconnect time is configured
as 169 seconds.
Configuring Label
Distribution Protocol Nonstop Routing
LDP nonstop routing
(NSR) functionality makes failures, such as Route Processor (RP) or Distributed
Route Processor (DRP) fail over, invisible to routing peers with minimal to no
disruption of convergence performance. By default, NSR is globally enabled on
all LDP sessions except AToM.
A disruption in
service may include any of these events:
Route processor
(RP) or distributed route processor (DRP) failover
LDP process
restart
Minimum disruption
restart (MDR)
Note
Unlike graceful
restart functionality, LDP NSR does not require protocol extensions and does
not force software upgrades on other routers in the network, nor does LDP NSR
require peer routers to support NSR. L2VPN configuration is not supported on
NSR. Process failures of active LDP results in session loss and, as a result,
NSR cannot be provided unless RP switchover is configured as a recovery action.
Configuration
Example
This example shows
how to configure LDP Non-Stop Routing.
RP/0/RP0/CPU0:Router# show mpls ldp nsr summary
Mon Dec 7 04:02:16.259 UTC
Sessions:
Total: 1, NSR-eligible: 1, Sync-ed: 0
(1 Ready)
MPLS Label
Distribution Protocol : Details
This section provides
detailed conceptual information about setting up LSPs, LDP graceful restart,
and LDP session protection.
Setting Up Label
Switched Paths
MPLS packets are forwarded between the nodes on the MPLS network using
Label Switched Paths(LSPs). LSPs can be created statically or by using a label
distribution protocol like LDP. Label Switched Paths created by LDP performs
hop-by-hop path setup instead of an end-to-end path. LDP enables label switched
routers (LSRs) to discover their potential peer routers and to establish LDP
sessions with those peers to exchange label binding information.
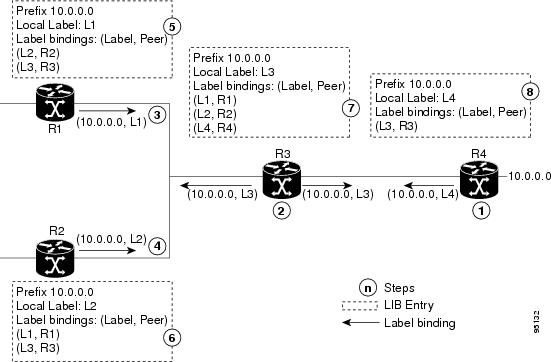
The following figure illustrates the process of label binding exchange
for setting up LSPs.
Figure 1. Setting Up Label Switched Paths
For a given network (10.0.0.0), hop-by-hop LSPs are set up between each
of the adjacent routers (or, nodes) and each node allocates a local label and
passes it to its neighbor as a binding:
R4 allocates local label L4 for prefix 10.0.0.0 and advertises it to
its neighbors (R3).
R3 allocates local label L3 for prefix 10.0.0.0 and advertises it to
its neighbors (R1, R2, R4).
R1 allocates local label L1 for prefix 10.0.0.0 and advertises it to
its neighbors (R2, R3).
R2 allocates local label L2 for prefix 10.0.0.0 and advertises it to
its neighbors (R1, R3).
R1’s label information base (LIB) keeps local and remote labels
bindings from its neighbors.
R2’s LIB keeps local and remote labels bindings from its neighbors.
R3’s LIB keeps local and remote labels bindings from its neighbors.
R4’s LIB keeps local and remote labels bindings from its neighbors.
MPLS
Forwarding
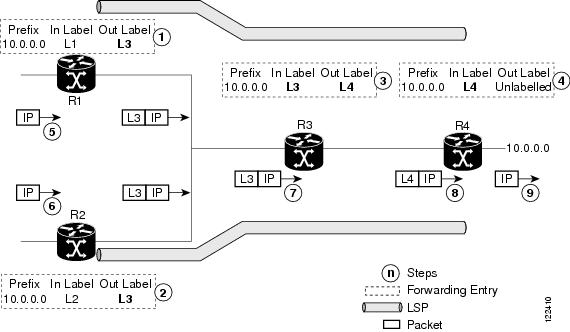
Once the label
bindings are learned, MPLS forwarding plane is setup and packets are forwarded
as shown in the following figure.
Figure 2. MPLS
Forwarding
Because R3 is
next hop for 10.0.0.0 as notified by the FIB, R1 selects label binding from R3
and installs forwarding entry (Layer 1, Layer 3).
Because R3 is
next hop for 10.0.0.0 (as notified by FIB), R2 selects label binding from R3
and installs forwarding entry (Layer 2, Layer 3).
Because R4 is
next hop for 10.0.0.0 (as notified by FIB), R3 selects label binding from R4
and installs forwarding entry (Layer 3, Layer 4).
Because next hop
for 10.0.0.0 (as notified by FIB) is beyond R4, R4 uses NO-LABEL as the
outbound and installs the forwarding entry (Layer 4); the outbound packet is
forwarded IP-only.
Incoming IP
traffic on ingress LSR R1 gets label-imposed and is forwarded as an MPLS packet
with label L3.
Incoming IP
traffic on ingress LSR R2 gets label-imposed and is forwarded as an MPLS packet
with label L3.
R3 receives an
MPLS packet with label L3, looks up in the MPLS label forwarding table and
switches this packet as an MPLS packet with label L4.
R4 receives an
MPLS packet with label L4, looks up in the MPLS label forwarding table and
finds that it should be Unlabeled, pops the top label, and passes it to the IP
forwarding plane.
IP forwarding
takes over and forwards the packet onward.
Details of Label
Distribution Protocol Graceful Restart
LDP (Label
Distribution Protocol) graceful restart provides a control plane mechanism to
ensure high availability and allows detection and recovery from failure
conditions while preserving Nonstop Forwarding (NSF) services. Graceful restart
is a way to recover from signaling and control plane failures without impacting
forwarding.
Without LDP graceful
restart, when an established session fails, the corresponding forwarding states
are cleaned immediately from the restarting and peer nodes. In this case LDP
forwarding restarts from the beginning, causing a potential loss of data and
connectivity.
The LDP graceful
restart capability is negotiated between two peers during session
initialization time, in FT SESSION TLV. In this typed length value (TLV), each
peer advertises the following information to its peers:
Reconnect time
Advertises the
maximum time that other peer will wait for this LSR to reconnect after control
channel failure.
Recovery time
Advertises the
maximum time that the other peer has on its side to reinstate or refresh its
states with this LSR. This time is used only during session reestablishment
after earlier session failure.
FT flag
Specifies
whether a restart could restore the preserved (local) node state for this flag.
Once the graceful
restart session parameters are conveyed and the session is up and running,
graceful restart procedures are activated.
When configuring the
LDP graceful restart process in a network with multiple links, targeted LDP
hello adjacencies with the same neighbor, or both, make sure that graceful
restart is activated on the session before any hello adjacency times out in
case of neighbor control plane failures. One way of achieving this is by
configuring a lower session hold time between neighbors such that session
timeout occurs before hello adjacency timeout. It is recommended to set LDP
session hold time using the following formula:
This means that for
default values of 15 seconds and 5 seconds for link Hello holdtime and interval
respectively, session hold time should be set to 30 seconds at most.
Phases in
Graceful Restart
The graceful restart
mechanism is divided into different phases:
Control
communication failure detection
Control
communication failure is detected when the system detects either:
Missed LDP
hello discovery messages
Missed LDP
keepalive protocol messages
Detection
of Transmission Control Protocol (TCP) disconnection a with a peer
Forwarding
state maintenance during failure
Persistent
forwarding states at each LSR are achieved through persistent storage
(checkpoint) by the LDP control plane. While the control plane is in the
process of recovering, the forwarding plane keeps the forwarding states, but
marks them as stale. Similarly, the peer control plane also keeps (and marks as
stale) the installed forwarding rewrites associated with the node that is
restarting. The combination of local node forwarding and remote node forwarding
plane states ensures NSF and no disruption in the traffic.
Control state
recovery
Recovery
occurs when the session is reestablished and label bindings are exchanged
again. This process allows the peer nodes to synchronize and to refresh stale
forwarding states.
Control Plane
Failure
When a control plane
failure occurs, connectivity can be affected. The forwarding states installed
by the router control planes are lost, and the in-transit packets could be
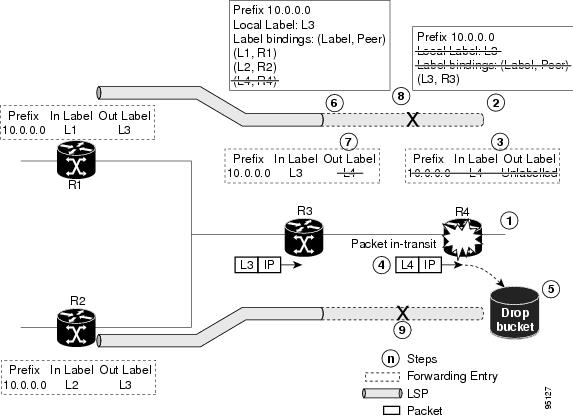
dropped, thus breaking NSF. The following figure illustrates control plane
failure and recovery with graceful restart and shows the process and results of
a control plane failure leading to loss of connectivity and recovery using
graceful restart.
Figure 3. Control Plane
Failure
Recovery with
Graceful Restart
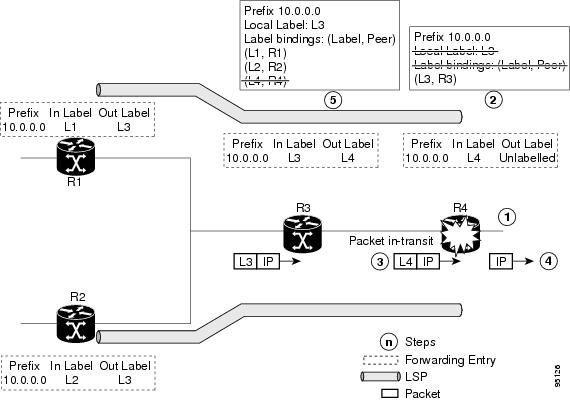
Figure 4. Recovering
with Graceful Restart
The R4 LSR
control plane restarts.
LIB is lost when
the control plane restarts.
The forwarding
states installed by the R4 LDP control plane are immediately deleted.
Any in-transit
packets flowing from R3 to R4 (still labeled with L4) arrive at R4.
The MPLS
forwarding plane at R4 performs a lookup on local label L4 which fails. Because
of this failure, the packet is dropped and NSF is not met.
The R3 LDP peer
detects the failure of the control plane channel and deletes its label bindings
from R4.
The R3 control
plane stops using outgoing labels from R4 and deletes the corresponding
forwarding state (rewrites), which in turn causes forwarding disruption.
The established
LSPs connected to R4 are terminated at R3, resulting in broken end-to-end LSPs
from R1 to R4.
The established
LSPs connected to R4 are terminated at R3, resulting in broken LSPs end-to-end
from R2 to R4.
When the LDP control
plane recovers, the restarting LSR starts its forwarding state hold timer and
restores its forwarding state from the checkpointed data. This action
reinstates the forwarding state and entries and marks them as old.
The restarting LSR
reconnects to its peer, indicated in the FT Session TLV, that it either was or
was not able to restore its state successfully. If it was able to restore the
state, the bindings are resynchronized.
The peer LSR stops
the neighbor reconnect timer (started by the restarting LSR), when the
restarting peer connects and starts the neighbor recovery timer. The peer LSR
checks the FT Session TLV if the restarting peer was able to restore its state
successfully. It reinstates the corresponding forwarding state entries and
receives binding from the restarting peer. When the recovery timer expires, any
forwarding state that is still marked as stale is deleted.
If the restarting
LSR fails to recover (restart), the restarting LSR forwarding state and entries
will eventually timeout and is deleted, while neighbor-related forwarding
states or entries are removed by the Peer LSR on expiration of the reconnect or
recovery timers.
Details of Session
Protection
LDP session protection
lets you configure LDP to automatically protect sessions with all or a given
set of peers (as specified by peer-acl). When configured, LDP initiates backup
targeted hellos automatically for neighbors for which primary link adjacencies
already exist. These backup targeted hellos maintain LDP sessions when primary
link adjacencies go down.
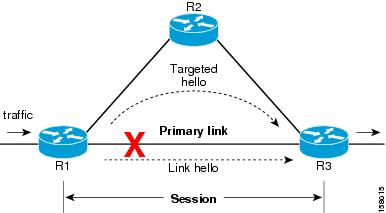
The Session Protection
figure illustrates LDP session protection between neighbors R1 and R3. The
primary link adjacency between R1 and R3 is directly connected link and the
backup; targeted adjacency is maintained between R1 and R3. If the direct link
fails, LDP link adjacency is destroyed, but the session is kept up and running
using targeted hello adjacency (through R2). When the direct link comes back
up, there is no change in the LDP session state and LDP can converge quickly
and begin forwarding MPLS traffic.
Figure 5. Session
Protection
Note
When LDP session
protection is activated (upon link failure), protection is maintained for an
unlimited period time.

 Feedback
Feedback