关于 Firepower 4100/9300 机箱上的集群
在 Firepower 4100/9300 机箱 上部署集群时,它执行以下操作:
-
为设备间通信创建 集群控制链路 (默认情况下,使用端口通道 48)。
对于同一个 Firepower 9300 机箱内的安全模块隔离的集群,此链路利用 Firepower 9300 背板进行集群通信。
对于多机箱集群,需要手动将物理接口分配到此 EtherChannel 以进行机箱间通信。
-
在应用中创建集群引导程序配置。
在部署集群时,机箱管理引擎将最低引导程序配置推送到包含集群名称、集群控制链路接口及其他集群设置的每个设备。 如果您需要自定义集群环境,可以在应用内对引导程序配置的某些用户可配置部分进行配置。
-
将数据接口作为跨网络 接口分配给集群。
对于同一个 Firepower 9300 机箱内的安全模块隔离的集群,跨网络接口不限于 EtherChannel,就像用于多个机箱的集群一样。 Firepower 9300 管理引擎在内部利用 EtherChannel 技术,将流量负载均衡到共享接口上的多个模块,使任何数据接口类型都可用于跨网络模式。 对于多机箱集群,必须对所有数据接口使用跨网络 EtherChannel。

注
除管理接口以外,不支持独立接口。
-
向集群中的所有设备分配管理接口。
有关集群的详细信息,请参阅以下各节:
引导程序配置
在部署集群时,Firepower 4100/9300 机箱管理引擎将最低引导程序配置推送到包含集群名称、集群控制链路接口及其他集群设置的每个设备。 如果您需要自定义集群环境,则用户可以配置引导程序配置的某些部分。
集群成员
集群成员协调工作来实现安全策略和流量的共享。
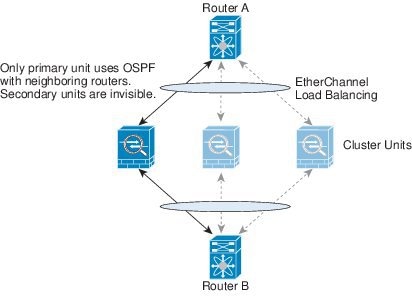
一个集群成员是控制设备。系统自动确定控制设备。所有其他成员都是数据设备。
您必须仅在控制设备上执行所有配置;然后,配置将复制到数据设备。
有些功能在集群中无法扩展,控制设备将处理这些功能的所有流量。请参阅集群集中化功能。
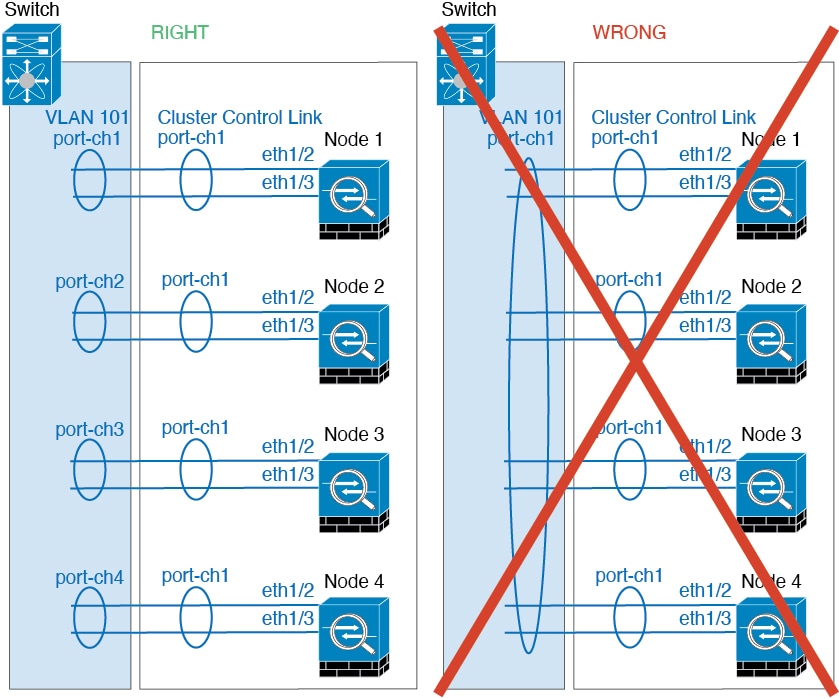
集群控制链路
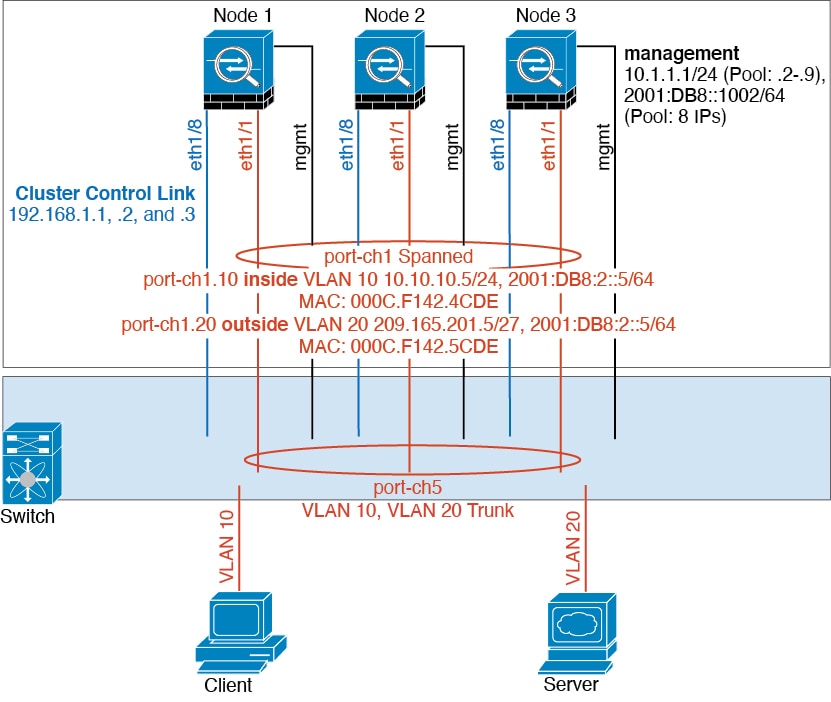
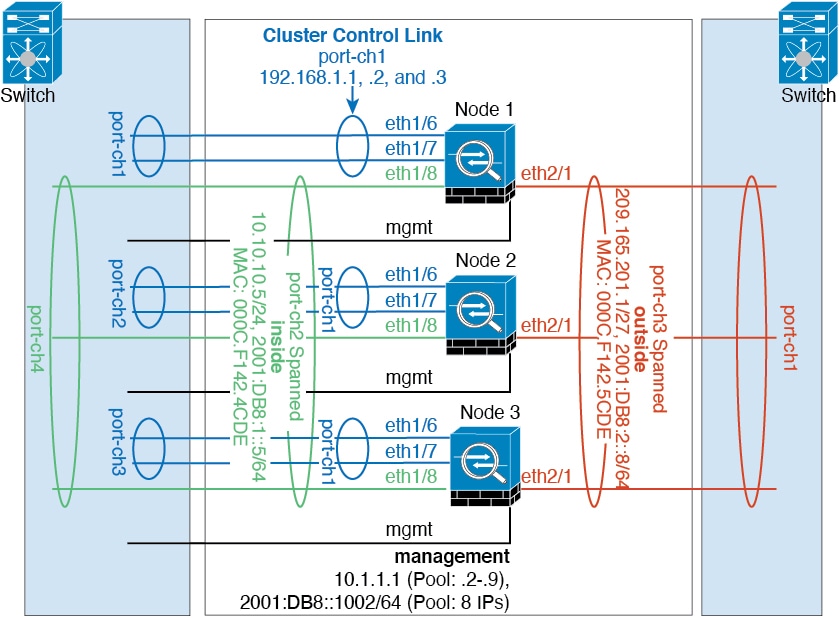
集群控制链路是用于设备到设备通信的 EtherChannel(端口通道 48)。对于机箱内集群,此链路利用 Firepower 9300 背板进行集群通信。对于机箱间集群,需要手动将物理接口分配到 Firepower 4100/9300 机箱 上的此 EtherChannel 以进行机箱间通信。
对于有 2 个机箱的机箱间集群,请勿将集群控制链路从一机箱直接连接至另一机箱。如果直接连接两个接口,则当一台设备发生故障时,集群控制链路失效,会导致剩下的那台正常设备也发生故障。而如果通过交换机连接集群控制链路,则集群控制链路仍会对正常设备打开。
集群控制链路流量包括控制流量和数据流量。
控制流量包括:
-
控制节点选举。
-
配置复制。
-
运行状况监控。
数据流量包括:
-
状态复制。
-
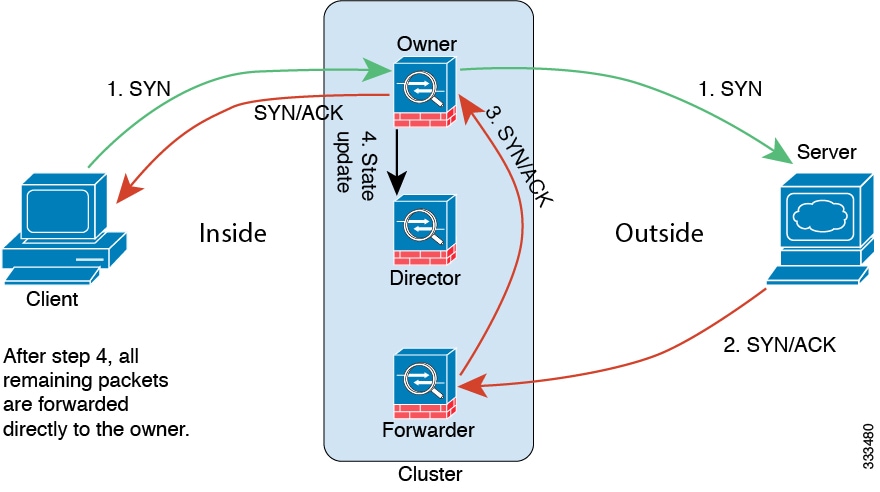
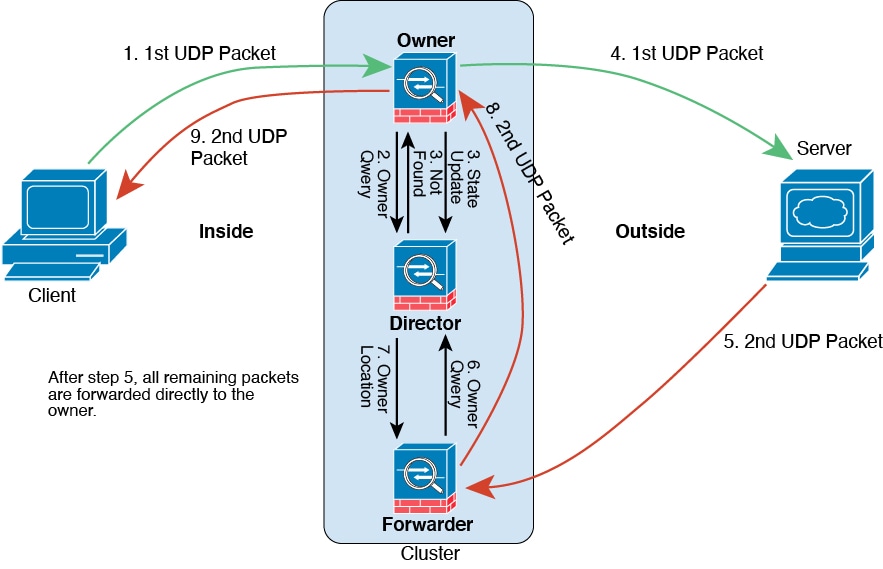
连接所有权查询和数据包转发。
有关集群控制链路的详细信息,请参阅以下部分。
确定集群控制链路规格
如果可能,应将集群控制链路的大小设定为与每个机箱的预期吞吐量匹配,以使集群控制链路可以处理最坏情况。
集群控制链路流量主要由状态更新和转发的数据包组成。集群控制链路在任一给定时间的流量大小不尽相同。转发流量的大小取决于负载均衡的效率或是否存在大量用于集中功能的流量。例如:
-
NAT 会使连接的负载均衡不佳,需要对所有返回流量进行再均衡,将其转发到正确的设备。
-
用于网络访问的 AAA 是集中功能,因此所有流量都会转发到控制设备。
-
当成员身份更改时,集群需要对大量连接进行再均衡,因此会暂时耗用大量集群控制链路带宽。
带宽较高的集群控制链路可以帮助集群在发生成员身份更改时更快地收敛,并防止出现吞吐量瓶颈。
注 |
如果集群中存在大量不对称(再均衡)流量,应增加集群控制链路的吞吐量大小。 |
集群控制链路冗余
我们建议将 EtherChannel 用于集群控制链路,以便在 EtherChannel 中的多条链路上传输流量,同时又仍能实现冗余。
下图显示了如何在虚拟交换系统 (VSS)、虚拟端口通道 (vPC)、StackWise 或 StackWise Virtual 环境中使用 EtherChannel 作为集群控制链路。EtherChannel 中的所有链路都是活动链路。如果交换机是冗余系统的一部分,则您可以将同一个 EtherChannel 中的防火墙接口连接到冗余系统中单独的交换机。交换机接口是同一个 EtherChannel 端口通道接口的成员,因为两台不同的交换机的行为就像一台交换机一样。请注意,此 EtherChannel 是设备本地的,而非跨网络 EtherChannel。
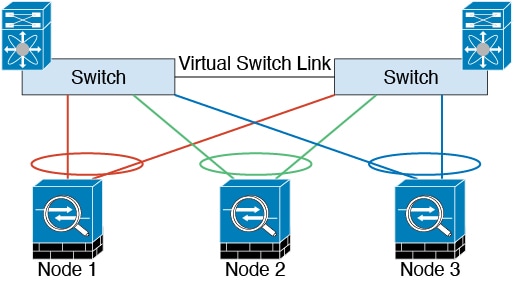
机箱间集群的集群控制链路可靠性
为了确保集群控制链路的功能,设备之间的往返时间 (RTT) 务必要小于 20 毫秒。此最大延迟能够增强与不同地理位置安装的集群成员的兼容性。要检查延迟,请在设备之间的集群控制链路上执行 ping 操作。
集群控制链路必须可靠,没有数据包无序或丢弃数据包的情况;例如,站点间部署应使用专用链路。
集群控制链路网络
Firepower 4100/9300 机箱基于机箱 ID 和插槽 ID 自动为每个设备生成集群控制链路接口 IP 地址:127.2.chassis_id.slot_id。当您部署集群时,您可以自定义此 IP 地址。集群控制链路网络不能包括设备之间的任何路由器;仅可执行第 2 层交换。 对于站点间流量,思科建议使用重叠传输虚拟化 (OTV)。
集群接口
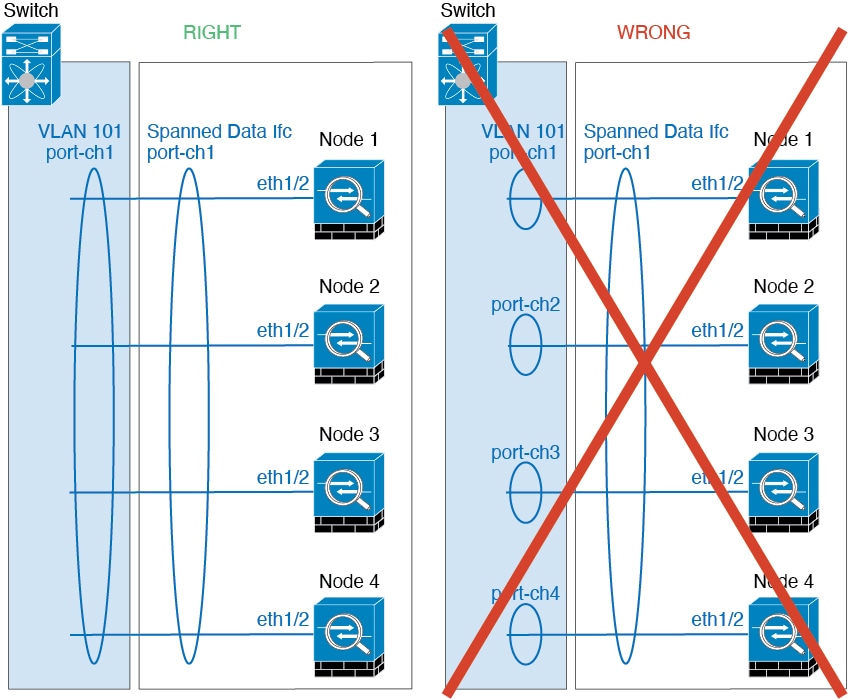
对于同一个 Firepower 9300 机箱内的安全模块隔离的集群,可以为集群分配物理接口或 EtherChannel 接口(也称为端口通道)。分配给集群的接口是对集群各个成员间的流量进行负载均衡的跨网络接口。
对于多机箱集群,只能为集群分配数据 EtherChannel 接口。这些跨网络 EtherChannel 在每个机箱上都包括相同的成员接口;在上游交换机上,所有这些接口都包括在一个 EtherChannel 内,因此交换机不知道它连接到多台设备。
除管理接口以外,不支持独立接口。
连接到冗余交换机系统
我们建议将 EtherChannel 连接到冗余交换机系统(例如 VSS、vPC、StackWise 或 StackWise Virtual 系统),以便为接口提供冗余。
配置复制
集群中的所有节点共享一个配置。您只能在控制节点上进行配置更改(引导程序配置除外),这些更改会自动同步到集群中的所有其他节点。
Cisco Secure Firewall ASA集群管理
使用 ASA集群的一个好处可以简化管理。本节介绍如何管理集群。
管理网络
我们建议将所有设备都连接到一个管理网络。此网络与集群控制链路分隔开来。
管理接口
必须为集群分配管理类型的接口。此接口是与跨网络接口相对立的一种特殊接口。通过管理接口,可以直接连接到每个设备。
集群的主集群 IP 地址是集群的固定地址,始终属于当前的控制单元。您也可以配置一个地址范围,使每个设备(包括当前控制单元在内)都能使用该范围内的本地地址。主集群 IP 地址提供对地址的统一管理访问;当主设备更改时,主集群 IP 地址将转移到新的主设备,使集群的管理得以无缝继续。
例如,您可以连接到主集群 IP 地址来管理集群,该地址始终属于当前的控制设备。要管理单个成员,您可以连接到本地 IP 地址。
注 |
传入设备的流量必须指向节点的管理 IP 地址;传入设备的流量不会通过群集控制链路转发到任何其他节点。 |
对于 TFTP 或系统日志等出站管理流量,包括控制设备在内的每台设备都使用本地 IP 地址连接到服务器。
控制设备管理与数据设备管理
所有管理和监控均可在控制节点上进行。从控制节点中,您可以检查所有节点的运行时统计信息、资源使用情况或其他监控信息。您也可以向集群中的所有节点发出命令,并将控制台消息从数据节点复制到控制节点。
如果需要,您可以直接监控数据节点。虽然在控制节点上可以执行文件管理,但在数据节点上也可以如此(包括备份配置和更新映像)。以下功能在控制节点上不可用:
-
监控每个节点的集群特定统计信息。
-
监控每个节点的系统日志(控制台复制启用时发送至控制台的系统日志除外)。
-
SNMP
-
NetFlow
加密密钥复制
当您在控制节点上创建加密密钥时,该密钥将复制到所有数据节点。如果您有连接到主集群 IP 地址的 SSH 会话,则控制节点发生故障时连接将断开。新控制节点对 SSH 连接使用相同的密钥,这样当您重新连接到新的控制节点时,无需更新缓存的 SSH 主机密钥。
ASDM 连接证书 IP 地址不匹配
默认情况下,ASDM 连接将根据本地 IP 地址使用自签名证书。如果使用 ASDM 连接到主集群 IP 地址,则可能会因证书使用的是本地 IP 地址而不是主集群 IP 地址,系统会显示一则警告消息,指出 IP 地址不匹配。您可以忽略该消息并建立 ASDM 连接。但是,为了避免此类警告,您也可以注册一个包含主集群 IP 地址和 IP 地址池中所有本地 IP 地址的证书。然后,您可将此证书用于每个集群成员。有关详细信息,请参阅 https://www.cisco.com/c/en/us/td/docs/security/asdm/identity-cert/cert-install.html。
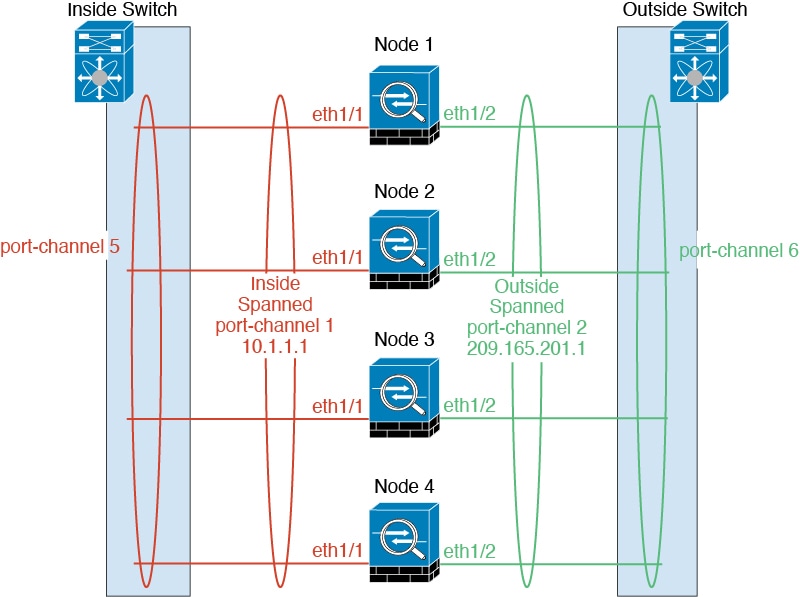
跨网络 EtherChannel(推荐)
您可以将每个机箱的一个或多个接口组成跨集群中所有机箱的 EtherChannel。EtherChannel 汇聚通道中所有可用活动接口上的流量。
在路由模式和透明防火墙模式下均可配置跨区以太网通道。在路由模式下,EtherChannel 配置为具有单个 IP 地址的路由接口。在透明模式下,IP 地址分配到 BVI 而非网桥组成员接口。
负载均衡属于 EtherChannel 固有的基本操作。
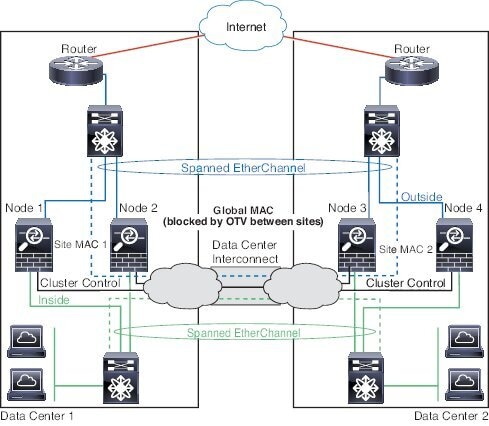
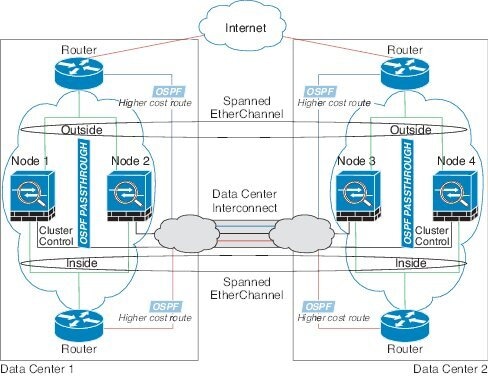
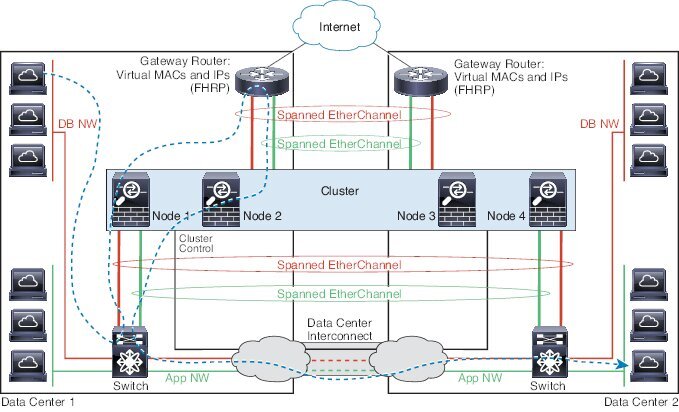
站点间集群
对于站点间安装,您只要遵循建议的准则即可充分发挥 ASA 集群的优势。
您可以将每个集群机箱配置为属于单独的站点 ID。
站点 ID 与站点特定的 MAC 地址和 IP 地址配合使用。集群发出的数据包使用站点特定的 MAC 地址和 IP 地址,而集群接收的数据包使用全局 MAC 地址和 IP 地址。此功能可防止交换机从两个不同端口上的两个站点获知相同全局 MAC 地址,导致 MAC 地址摆动;相反,它们仅获知站点 MAC 地址。只有使用跨区以太网通道的路由模式支持站点特定的 MAC 地址和 IP 地址。
站点 ID 还用于使用 LISP 检查、导向器本地化来实现流量移动,以提高性能、减少数据中心的站点间集群的往返时间延迟以及连接的站点冗余,其中流量流的备用所有者始终位于与所有者不同的站点上。
有关站点间集群的详细信息,请参阅以下各节:
-
调整数据中心互联的规模 - Firepower 4100/9300 机箱上的集群要求和前提条件
-
站点间准则 - 集群准则和限制
-
配置集群流移动性 -配置集群流移动性
-
启用导向器本地化 - 启用导向器本地化
-
启用站点冗余 - 启用导向器本地化


 反馈
反馈