Cisco Common Data Layer(CDL)は、クラウドネイティブなすべてのアプリケーションに対応する、高性能の次世代キーバリュー(KV)データストアレイヤです。これらのアプリケーションは、高可用性(HA)と Geo HA 機能を備えた状態管理として
CDL を使用します。CDL は以下を提供します。
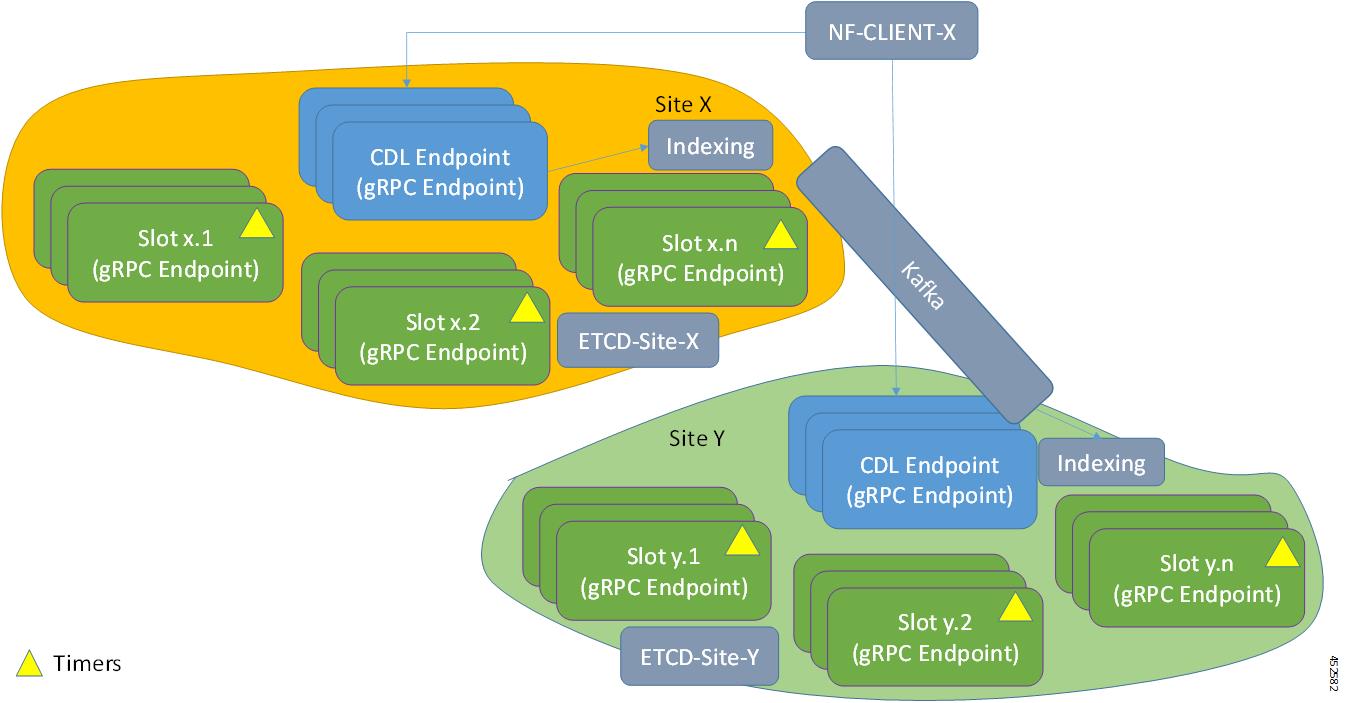
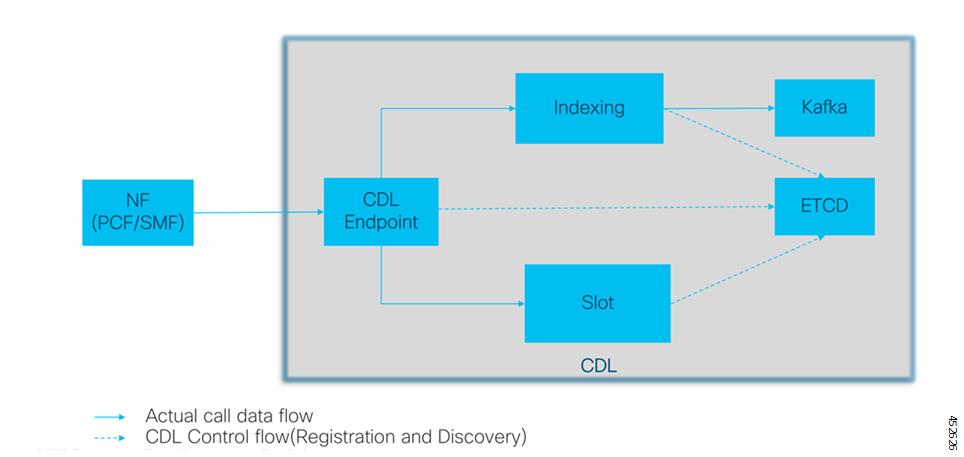
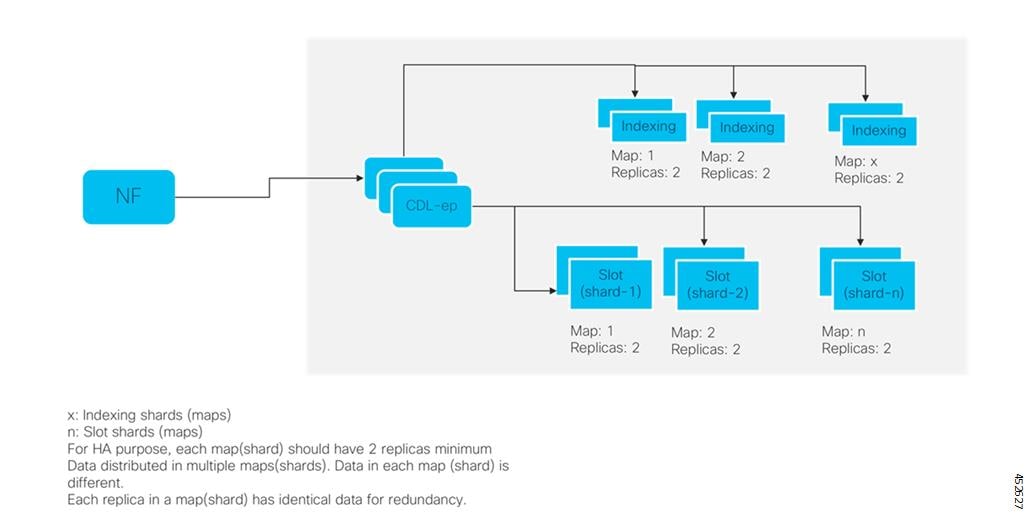
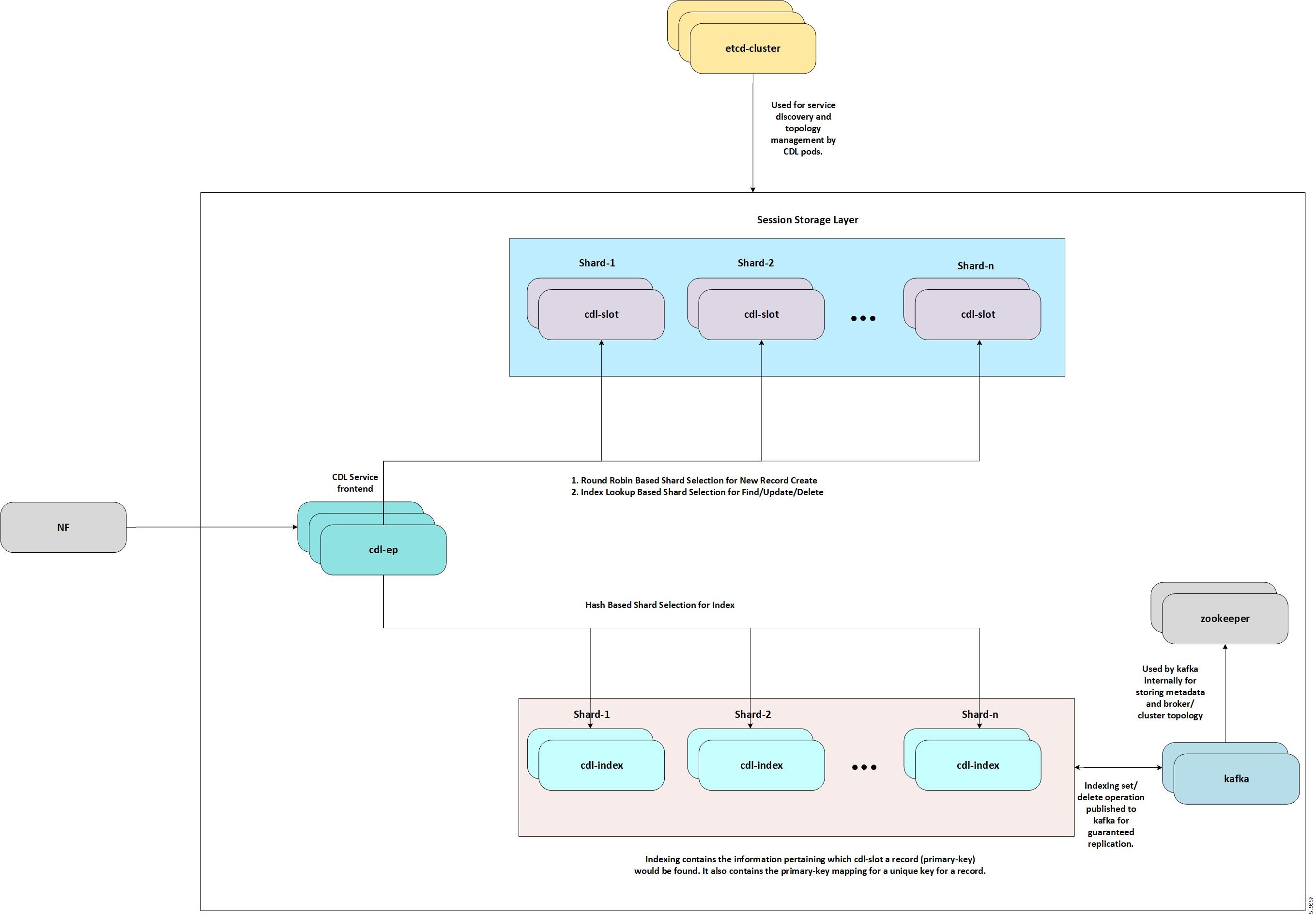
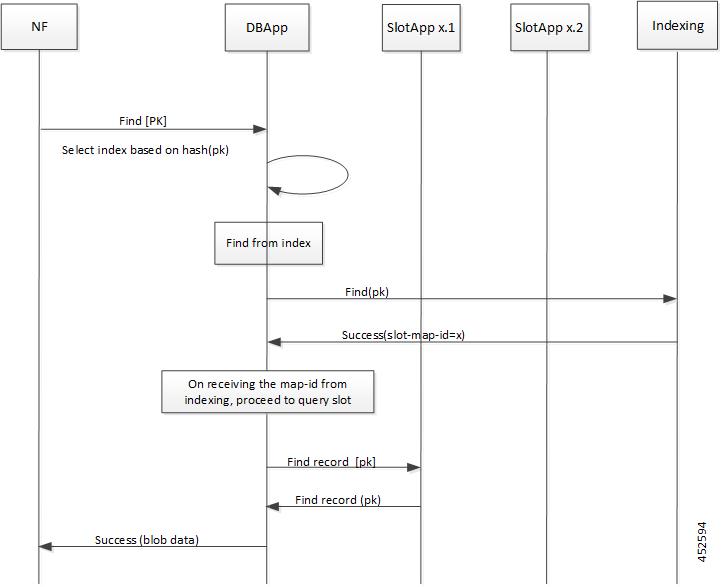
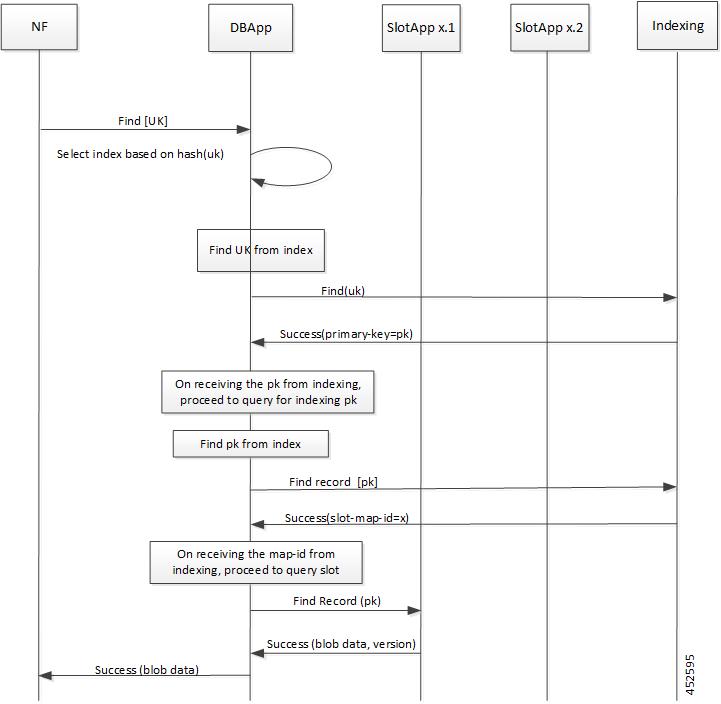
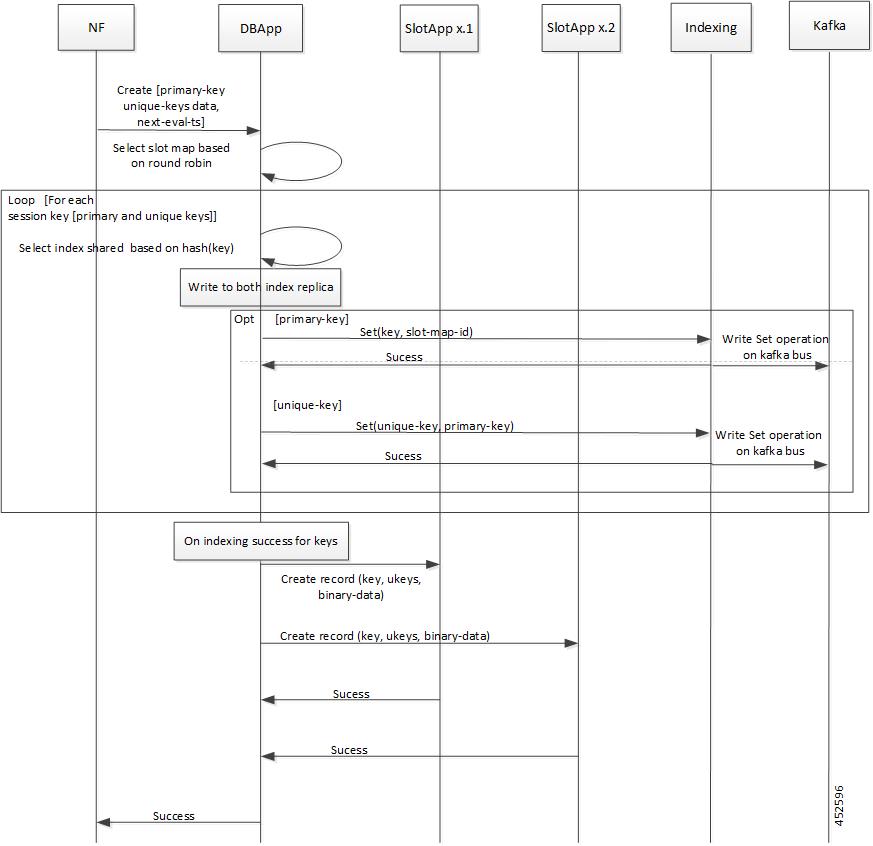
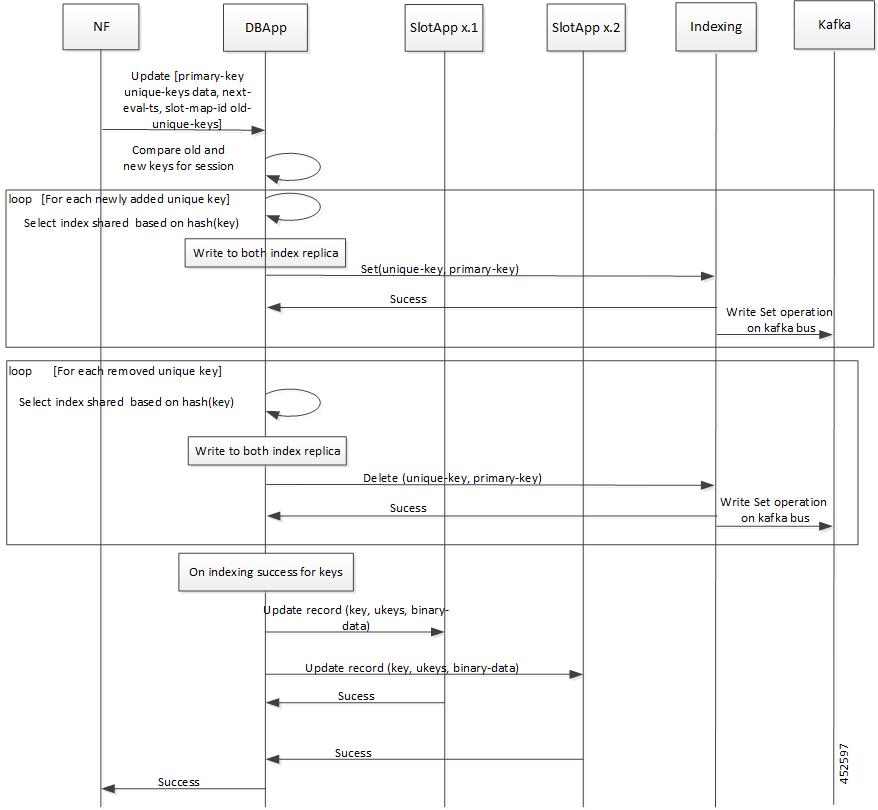
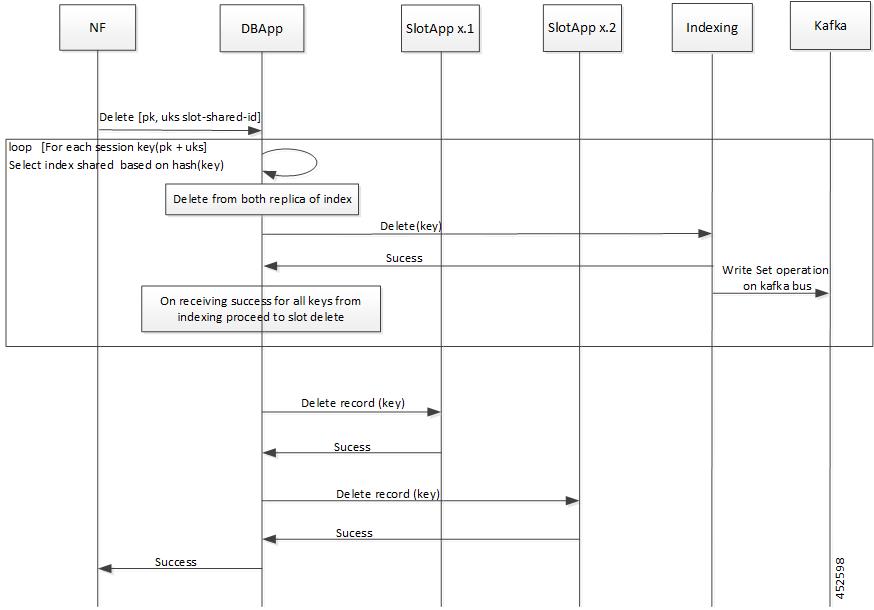
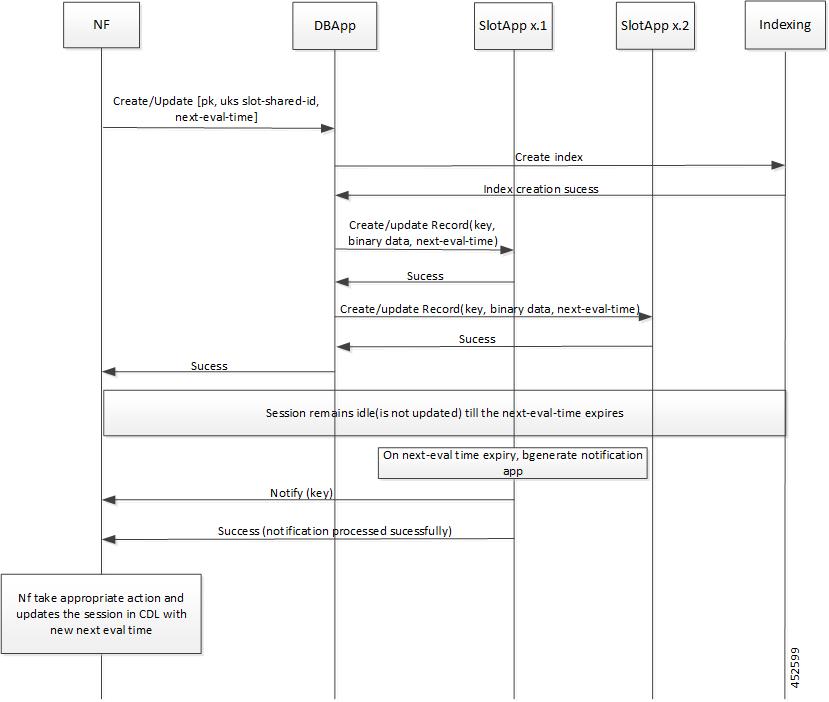
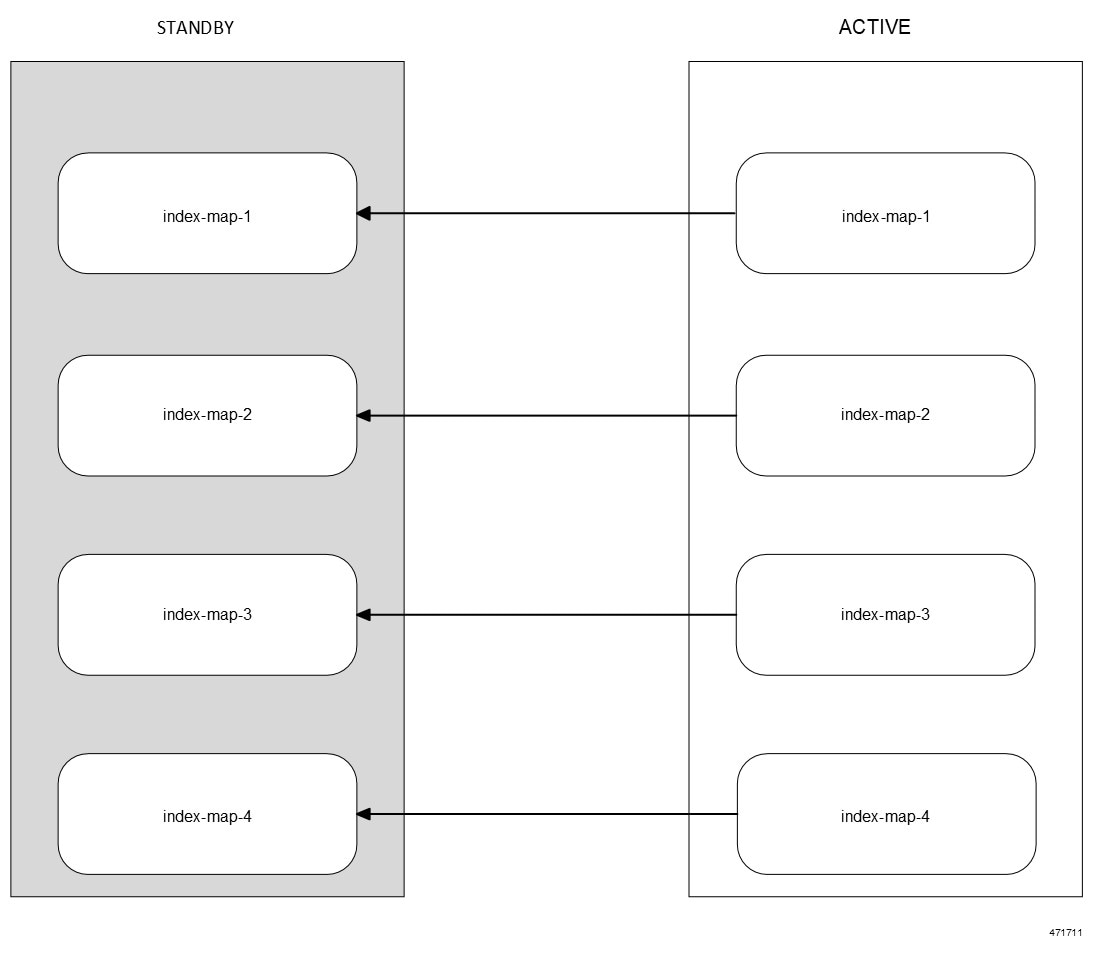
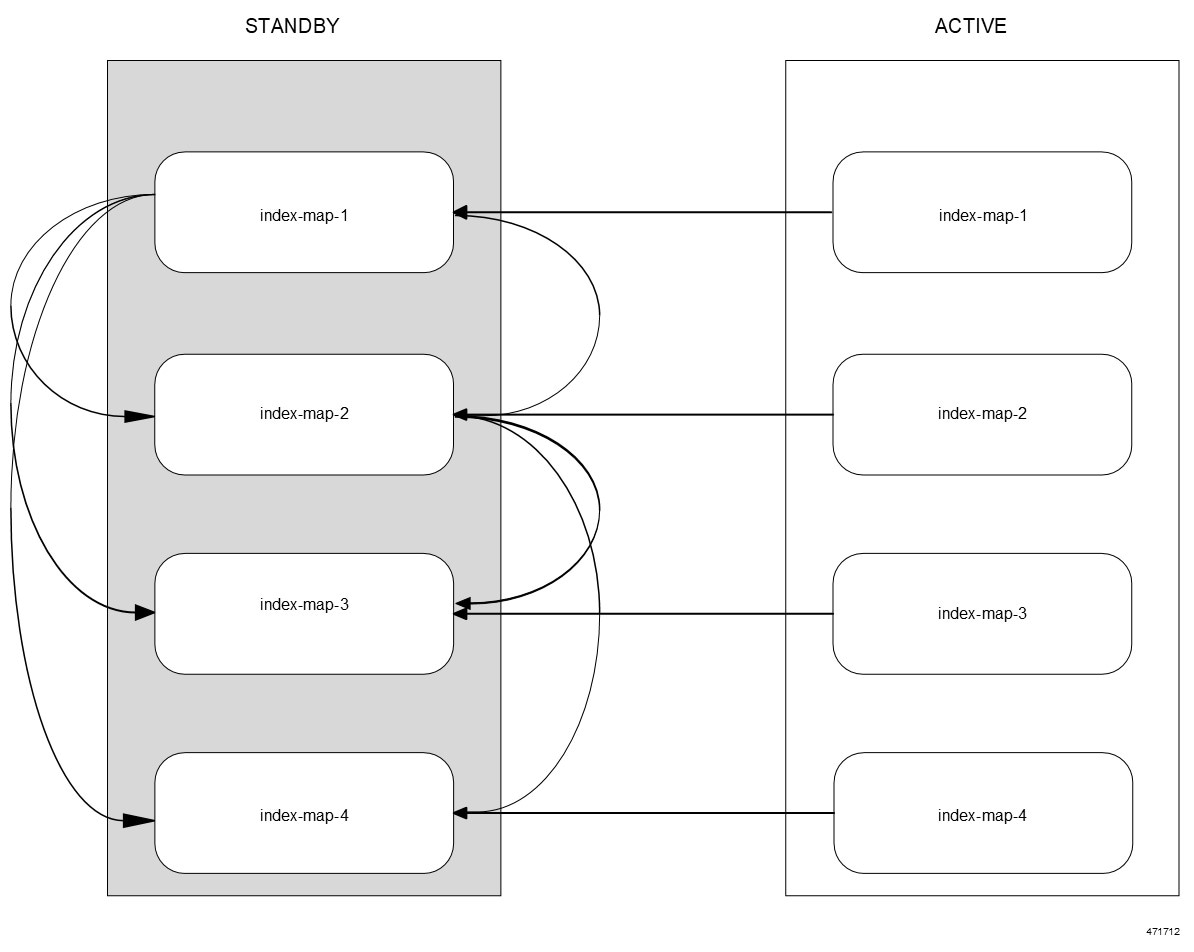
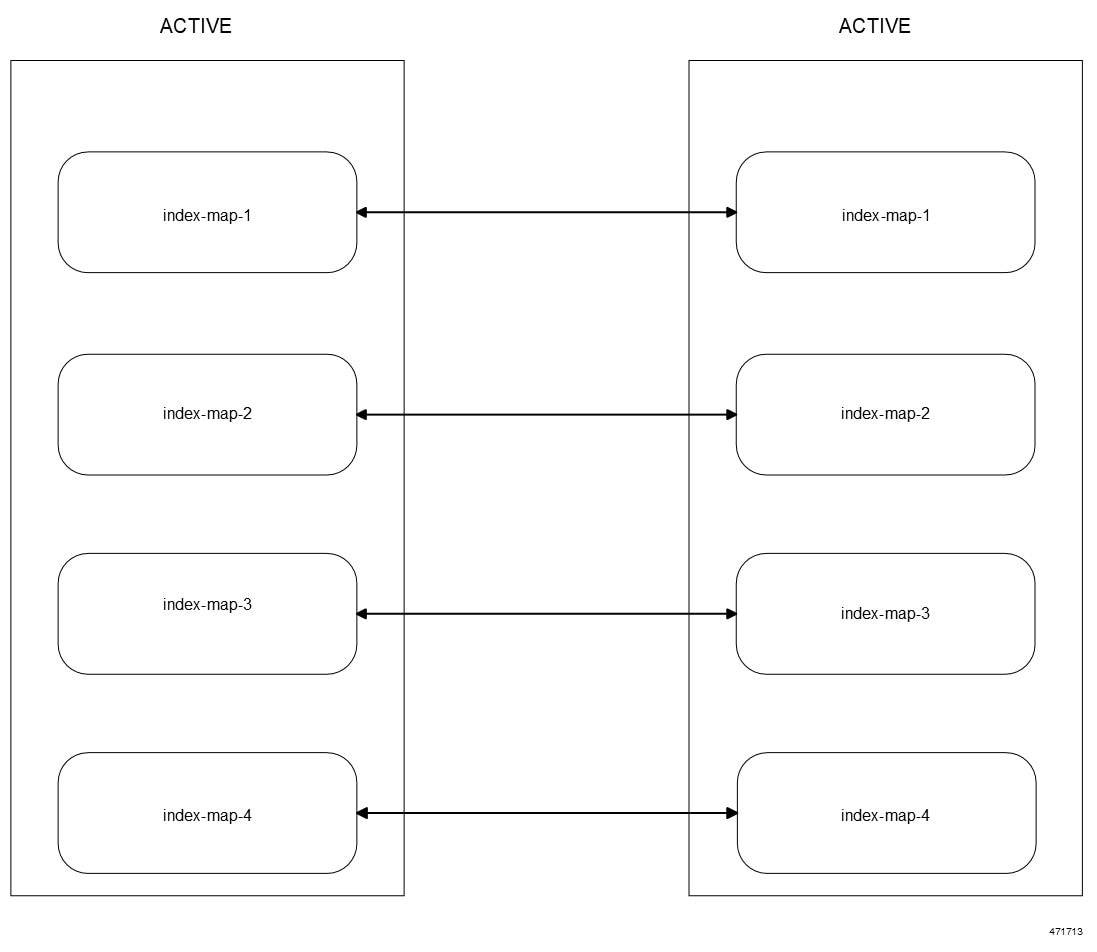
CDL エンドポイントは、サイト内の他のポッドについて、etcdを使用して自動的に学習します。また、Cisco Data Store K8s ポッドは本質的にステートレスであり、セッションのスティッキ性は維持されません。CDL エンドポイントは NF アプリケーションから要求を受信し、GRPC を介して内部的にスロットポッドおよびインデックスポッドと通信して、それに応じて要求を処理します。処理が完了すると応答を返します。
features index-overwrite-detection max-tps variable
features index-overwrite-detection queue-size variable
features index-overwrite-detection unique-keys-prefix uk
action [delete-record, notify-record, log-record]
cdl datastore session
features index-overwrite-detection max-tps 250
features index-overwrite-detection queue-size 2000
features index-overwrite-detection unique-keys-prefix uk
action notify-record
exit
exit
トラブルシューティング
古いインデックスレコードをトラブルシュートするには、index.overwrite.session ロガーを INFO レベルに設定します。エンドポイントポッドおよびインデックスポッドからのログは、障害対応に役立ちます。
CDL の設定:
cdl logging logger index.overwrite.session
level info
exit
ネットワーク機能(NF)(セッション管理機能(SMF)およびポリシー制御機能(PCF))の Ops Center を介して CDL を展開できます。
SMF Ops Center を介した CDL の展開については、『Ultra Cloud Core 5G Session Management Function - Configuration and Administration Guide』の「Cisco Common Data Layer in SMF」の章を参照してください。
PCF Ops Center を介した CDL の展開については、『Ultra Cloud Core 5G Policy Control Function -Configuration and Administration Guide』の「Cisco Common Data Layer in PCF」の章を参照してください。
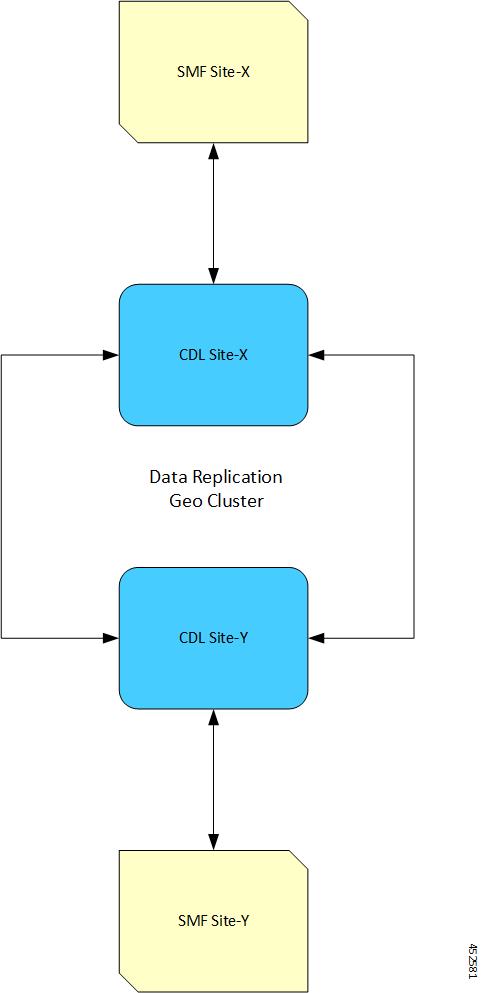
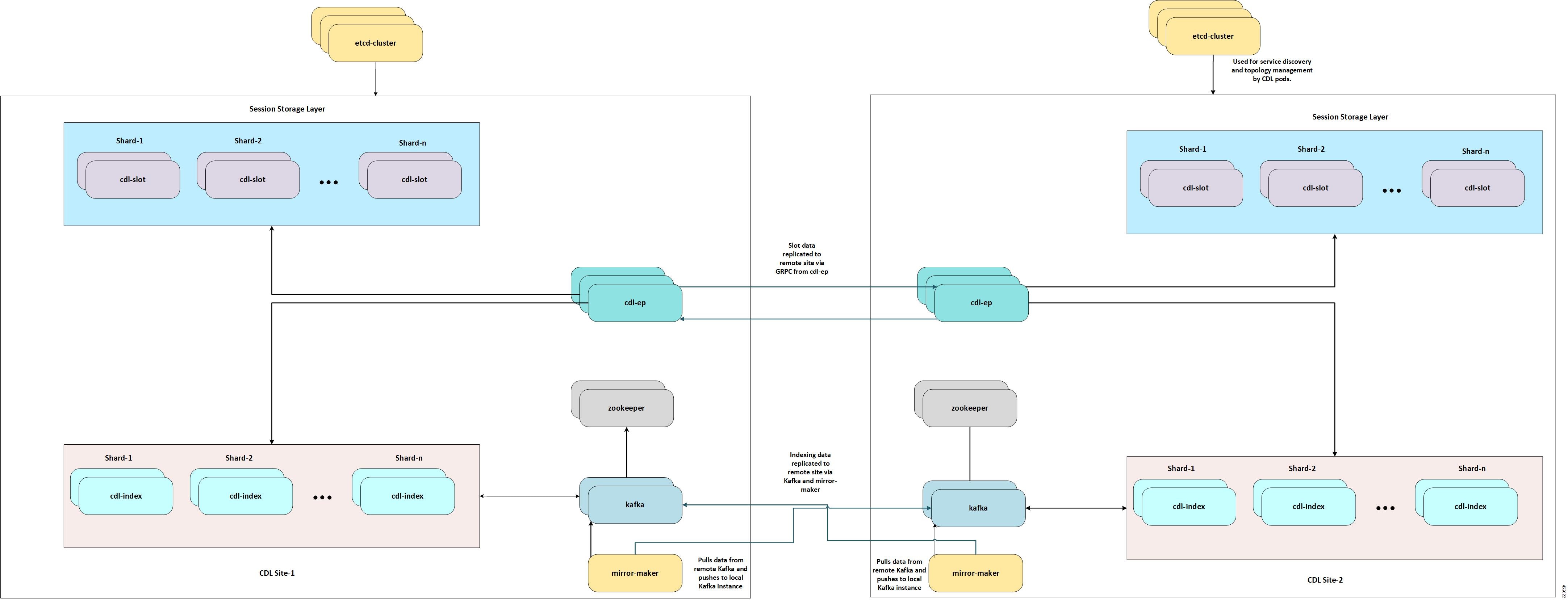
CDL Geo レプリケーション(GR)の展開
このセクションでは、Geo レプリケーション(GR)の CDL を展開する方法について説明します。
CDL GR の前提条件
CDL GR を展開する前に、次の設定を行います。
CDL セッションデータベースを設定し、基本設定を定義します。
CDL 用の Kafka を設定します。
CDL 用の Zookeeper を設定します。
CDL セッションデータベースの設定と基本設定の定義
このセクションでは、CDL セッションデータベースを設定し、NF(SMF または PCF)Ops Center を介して基本構成を定義する方法について説明します。
site_external_ip_address:リモートサイトの外部 IP アドレスを指定します。
ssl-keyssl_key:生成された SSL キーを指定します。
Geo レプリケーション(GR)のフェールオーバーの通知
CDL には Geo レプリケーション(GR)フェールオーバー通知が用意されていているため、セッションデータのタイマー切れの通知や、現在アクティブなサイトへの一括通知が可能です。CDL は GR フェールオーバー通知のために、App-Infra
を介してボーダー ゲートウェイ プロトコル(BGP)を使用します。
CDL は両方の GR サイトでキー値を登録します。登録したキー値に変更があると、App-Infra は CDL に通知を送信します。キー値は、CDL システム ID または GR インスタンスの状態を示します。GR インスタンスは、 キーの
CDL システム ID または GR インスタンス ID を使用して CDL スライスにマップされます。
CDL GR フェールオーバー通知に、次のパラメータが導入されました。
instance-aware-notification enable true or false:GR フェールオーバー通知を有効にするには、これを true に設定します。
instance-aware-notification system-id :system-id は sliceName にマップされます。つまり、プライマリ system-id はその特定の sliceName のプライマリサイト ID にマップされます。この情報は、すべての Geo サイトで構成する必要があります。FindAllNotify 通知および TimerExpiry 通知は、一括処理タスクのシステム ID の詳細を使用します。
システム ID は両方のサイトで必須です。NF 構成の GR インスタンス ID が CDL システム ID と一致している必要があります。
cdl datastore session features overload-protection critical-alert-threshold<percentage>
cdl datastore session features overload-protection major-alert-threshold<percentage>
アラートの確認
CEE Ops Center CLI で次のコマンドを使用して、アラートを確認できます。
show alerts active { detail | summary }
また、次のコマンドを使用して、CEE Ops Center CLI でアラートをフィルタ処理できます。
show alerts active detail sumary"CDL is overloaded."
次の例では、システムキャパシティが 80% 以上になった場合に cdlOverloaded - major アラートがトリガーされます。
alerts active detail cdlOverloaded-major 5446095ab264
severity major
type "Processing Error Alarm"
startsAt 2020-10-15T15:09:00.425Z
source System
summary "CDL is overloaded."
alerts active detail cdlOverloaded-critical 5446095ab264
severity critical
type "Processing Error Alarm"
startsAt 2020-10-15T15:09:16.425Z
source System
summary "CDL is overloaded."
CDL Ops Center で cdl show statusコマンドを使用して、CDL のステータスを確認し、クライアントによって挿入されたデータを調べることができます。cdl show status コマンドの詳細については、『UCC CDL Command Reference Guide』を参照してください。
次の例は、すべての CDL コンポーネントのステータスとクライアントのデータを示しています。
[unknown] cdl# cdl show status
message params: {cmd:status mode:cli dbName:session sessionIn:{mapId:0 limit:10000 filters:[]}}
site {
system-id 1
cluster-id 1
db-endpoint {
state STARTED
}
slot {
map-id 1
instance-id 2
records 100
capacity 1000000
state STARTED
}
slot {
map-id 1
instance-id 1
records 100
capacity 1000000
state STARTED
}
index {
map-id 1
instance-id 2
records 500
capacity 2500000
state ONLINE
}
index {
map-id 1
instance-id 1
records 500
capacity 2500000
state ONLINE
}
}
[unknown] cdl#

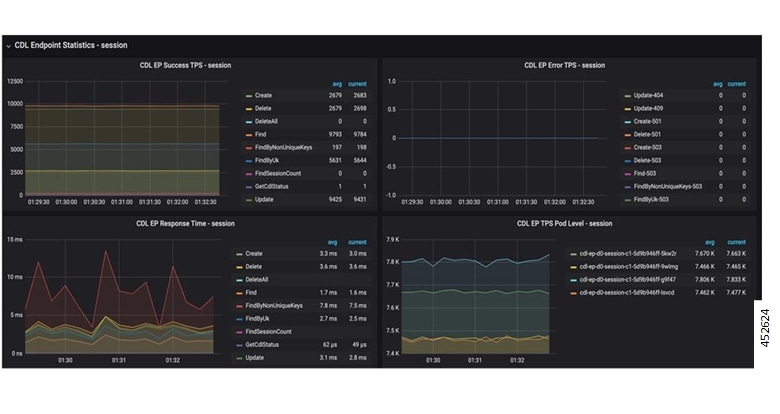
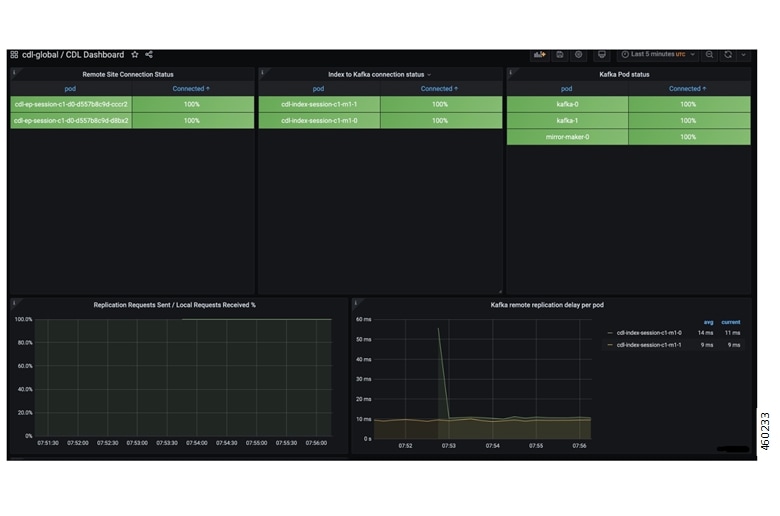
 フィードバック
フィードバック