高可用性の設計
Cisco Contact Center Enterprise ソリューションは、設計により高可用性の機能を備えています。ソリューション設計には、コアコンポーネントの冗長性を含める必要があります。冗長コンポーネントは自動的にフェールオーバーし、手動操作なしで復元します。設計にも基本以上の高可用性機能を含めることができます。導入を成功させるには、データや音声インターネットワーキング、システム管理および Contact Center Enterprise ソリューション設計および構成に関する経験があるチームが必要です。
高可用性を促す各変更には、コストがかかります。このコストには、より多くのハードウェア、より多くのソフトウェアコンポーネント、およびより多くのネットワーク帯域幅が含まれる場合があります。コストと変更による結果のバランスを取ってください。フェールオーバーシナリオ中に切断を防止することはどれくらい重要でしょうか。システムの一部が復旧するまで、カスタマーに数分待ってもらうことは許容範囲でしょうか。障害中、一部の通話のコンテキストがなくなってしまうことをカスタマーは許してくれるでしょうか。初期設計中により優れたフォールトトレランスに投資し、将来的な拡張性のためにコンタクトセンターを配置するでしょうか。
導入サイクルにおける再設計や今後のメンテナンスの問題を避けるために慎重に計画しましょう。すべての導入サイトの将来的な拡張性を念頭に置いて常に、最悪の障害シナリオを想定して設計します。
 Note |
このガイドでは、Contact Center Enterprise ソリューションそのものの設計に焦点を当ててください。ソリューションは、他のシステムのフレームワークで動作します。このガイドでは、コンタクトセンターをサポートする各システムに関する完全な情報は記載されていません。このガイドは、Cisco Contact Center Enterprise 製品に焦点をおいています。このガイドで別のシステムについて説明する場合は、包括的なビューは提供されません。完全な Cisco Unified Communications 製品一式に関する情報は、http://www.cisco.com/en/US/docs/voice_ip_comm/uc_system/design/guides/UCgoList.html に記載されているシスコソリューション設計書を参照してください。 |
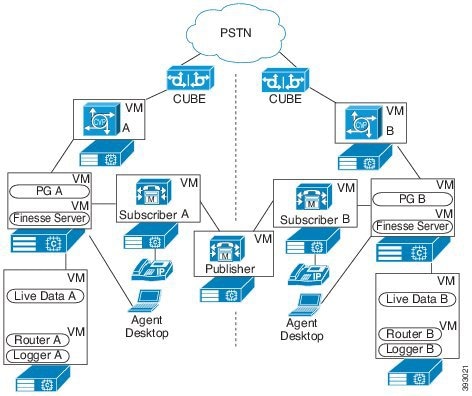
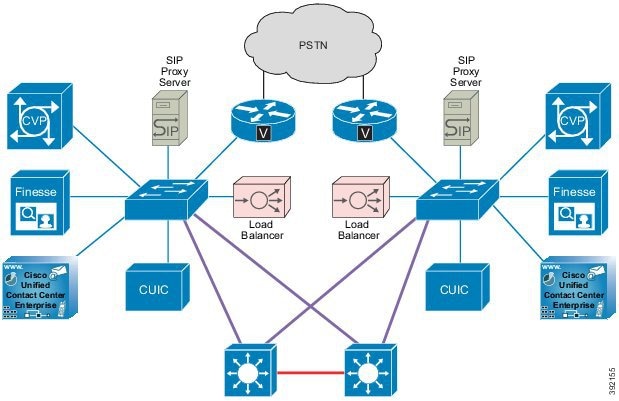
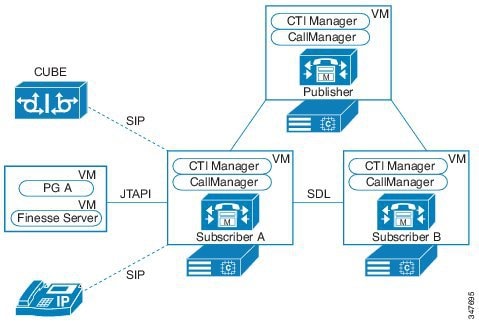
次の図は、フォールトトレランス Unified CCE 単一サイト展開を示しています。
Note |
Contact Center Enterprise ソリューションは、実稼働環境で非冗長性(シンプレックス)導入をサポートしません。テスト環境のみで非冗長展開を使用できます。 |
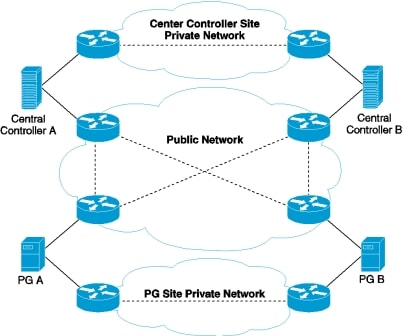
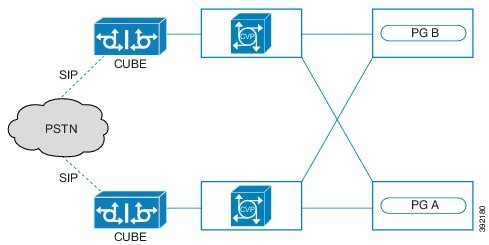
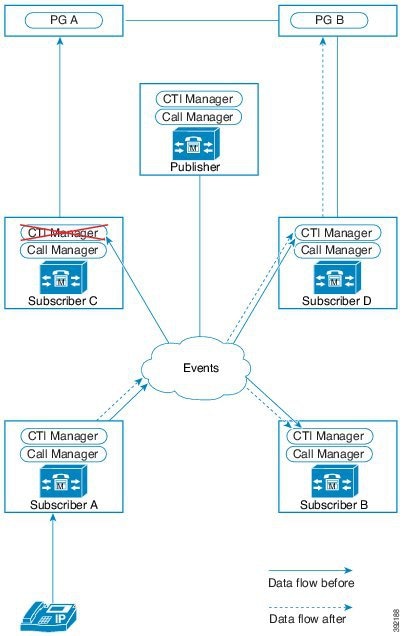
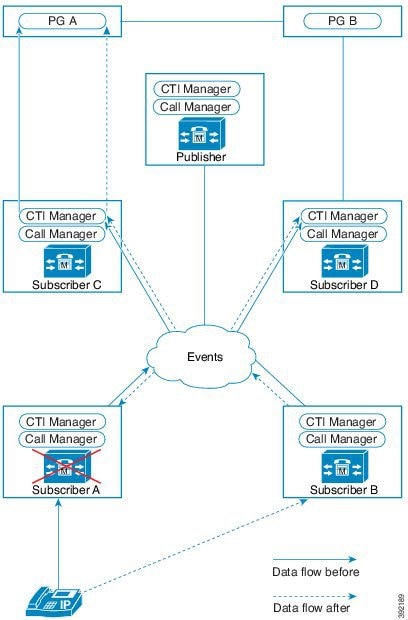
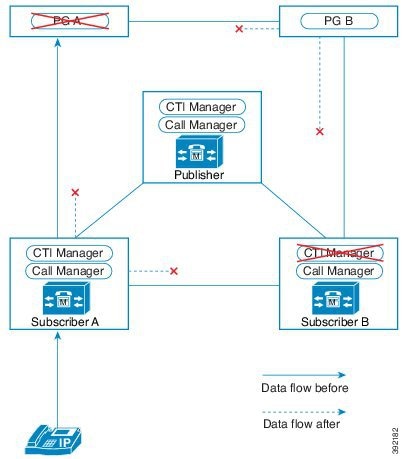
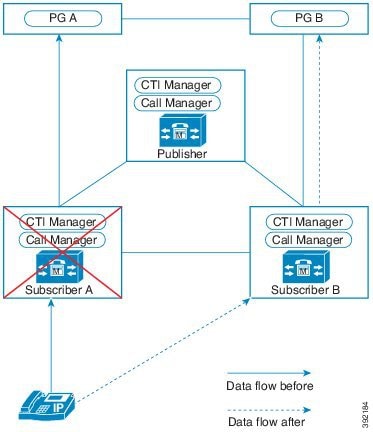
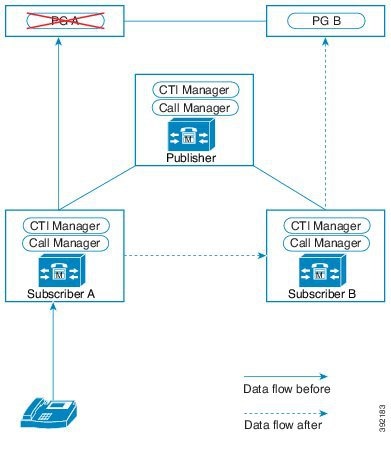
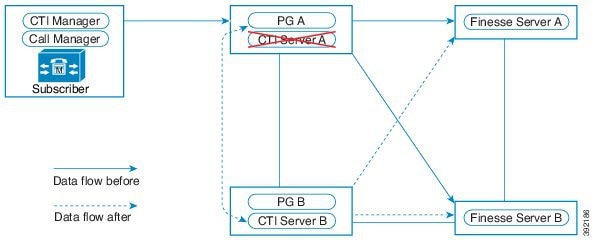
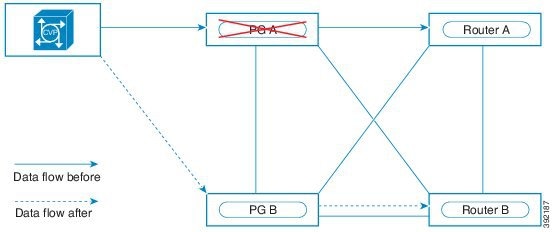
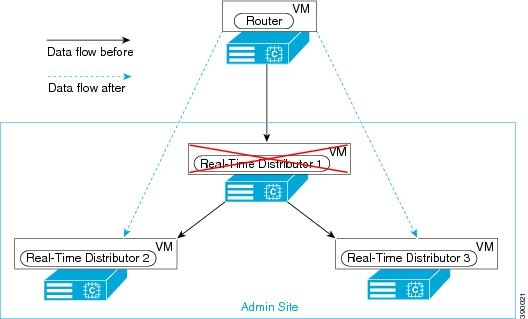
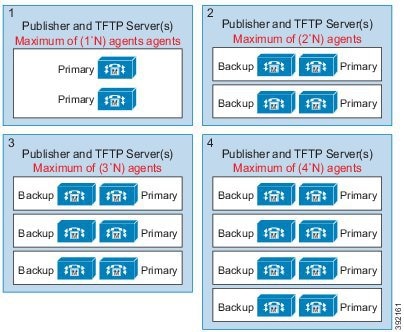
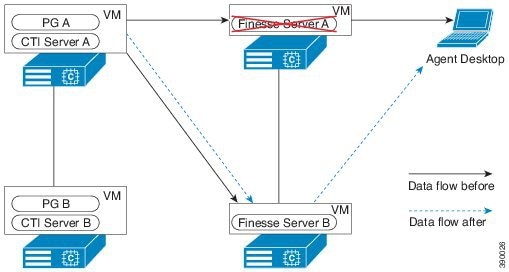
この設計は、冗長性に対して、コンポーネントがどう重複するかを示しています。すべての Contact Center Enterprise 導入は、冗長 Unified CM、Unified CCE、Unified CVP のコンポーネントを使用します。冗長性のために、導入でコア システムの半分が失われることがありますが、ソリューションは引き続き機能します。この状態の場合、導入では、Unified CVP を介してコールを VRU セッションまたは引き続き接続されているエージェントに再ルーティングできます。可能な場合は、コンタクトセンターを導入して、Unified CM Publisher でデバイス、コール処理、または CTI Manager サービスが実行されていないことを確認します。
自動フェールオーバーとリカバリを有効にするには、冗長コンポーネントをプライベート ネットワーク パスでインターコネクトします。コンポーネントは、障害検出にハートビートメッセージを使用します。Unified CM は、フェールオーバーとリカバリにクラスタ設計を使用します。各クラスタには、発行元と複数のサブスクライバが含まれます。エージェントの電話とデスクトップはプライマリ ターゲットに登録されますが、プライマリで障害が発生した場合は、バックアップターゲットに自動的に再登録されます。
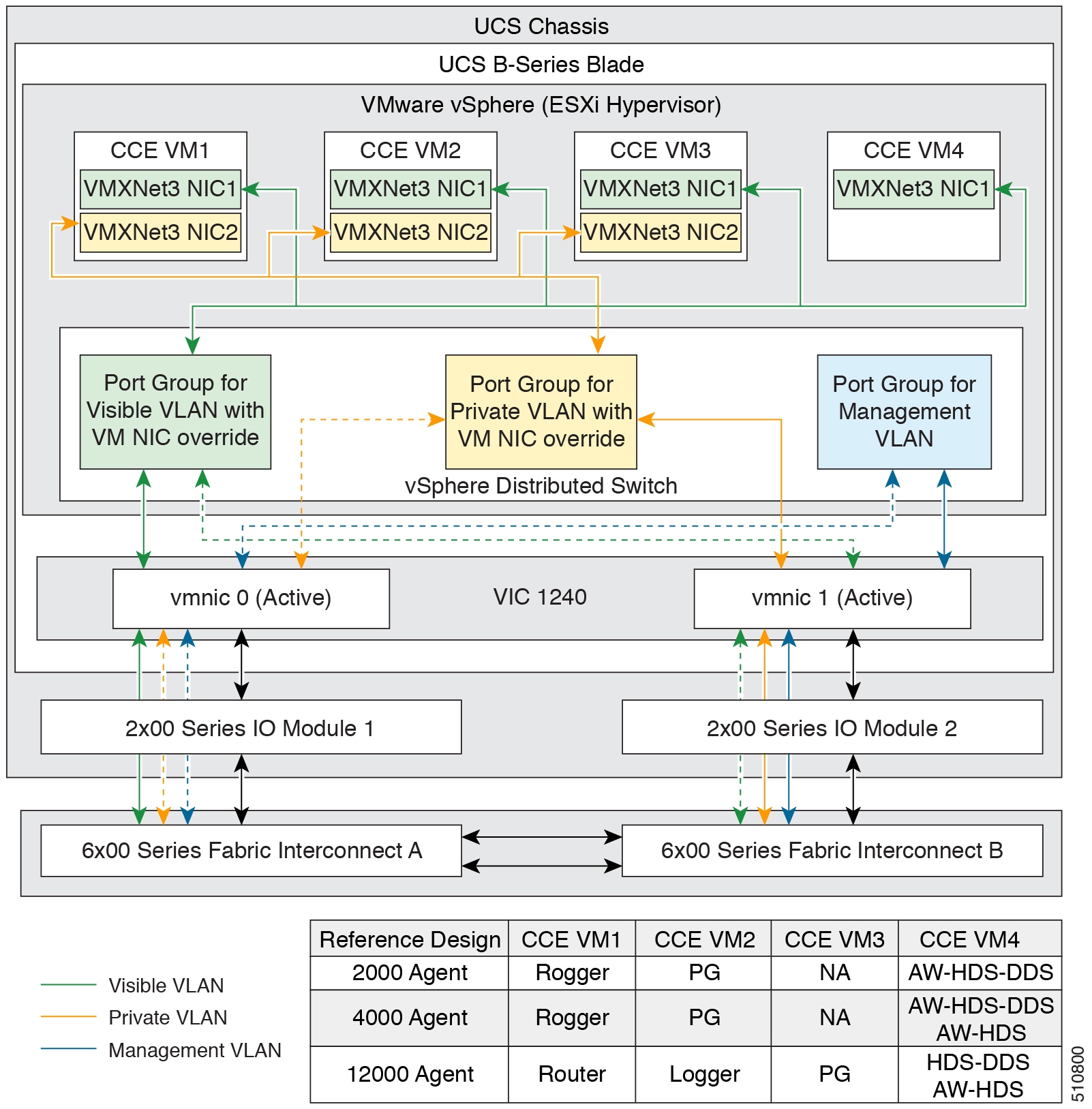
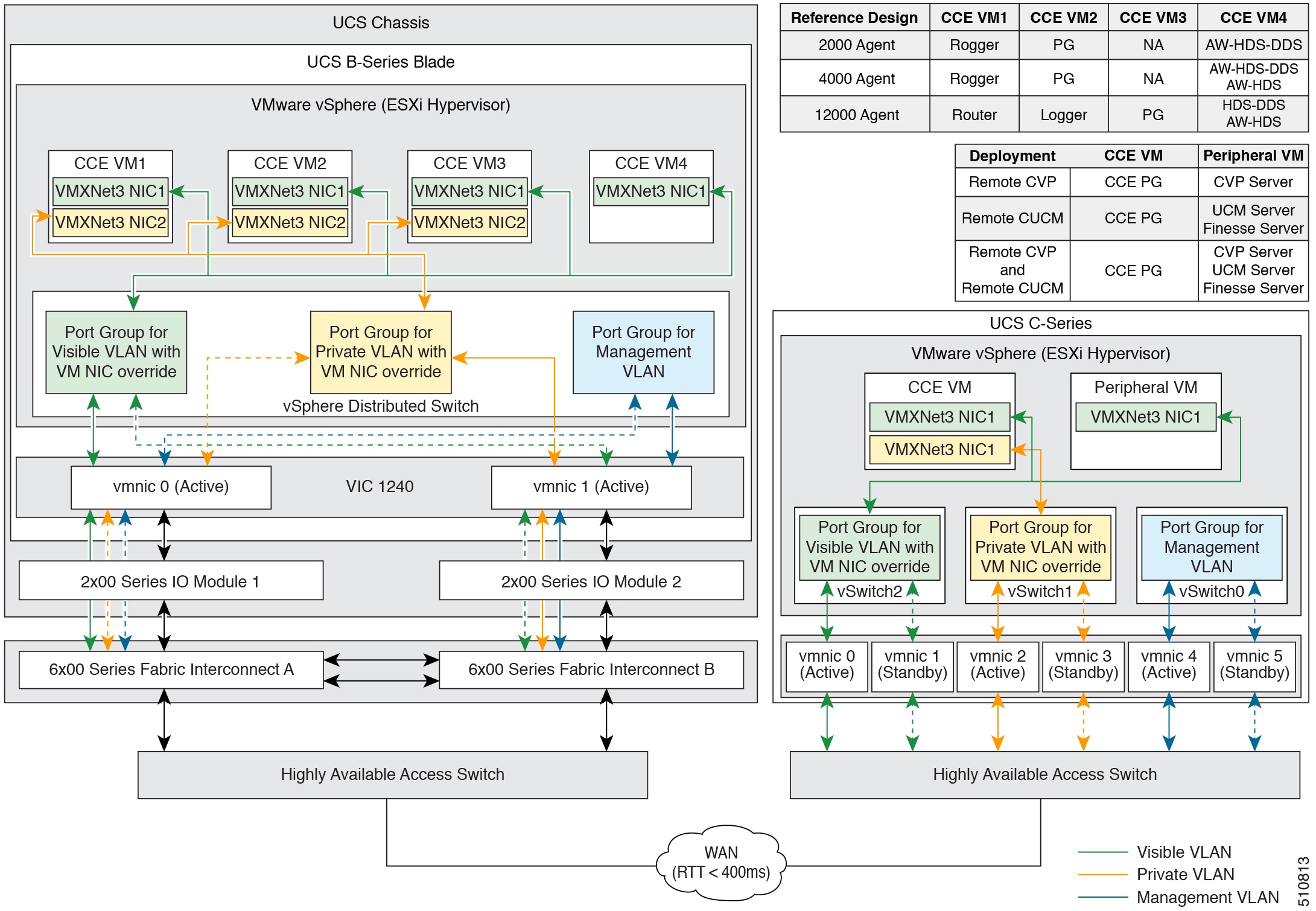
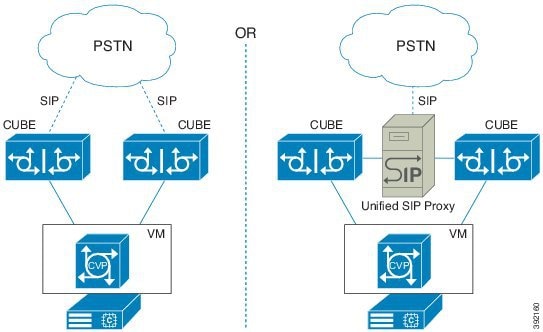

 フィードバック
フィードバック