
Cisco Nexus Hyperfabric:サーバ
サーバ(Servers)
Cisco UCS サーバは、人工知能(AI)アプリケーションに必要とされる、高性能のコンピューティング サーバとスケーラブルで高速なストレージ サーバの組み合わせを提供します。これらのサーバは、テレメトリを使用して各デバイスからリアルタイムのパフォーマンスと正常性データを収集する Cisco Nexus Hyperfabric を介してモニタリングされます。Cisco Nexus Hyperfabric は、サーバ メトリックを追跡しますが、構成の変更を許可しません。
サーバ情報の表示
手順
ステップ 1 | 対象のサーバに移動します。
|
ステップ 2 | [モニタ(Monitor)] 領域で、表示するポート プロパティを選択します。
|
BMC および一般的なサーバの詳細の表示
ベースボード管理コントローラ(BMC)は、サーバのマザーボードに組み込まれるマイクロコントローラです。BMC を使用すると、管理者は、電源が切れている、クラッシュしている、応答しない状態であっても、サーバをモニタおよび制御できます。
管理者は、 BMC の詳細を表示して
- 接続とトラブルシューティングのためのサーバ イーサネット インターフェイスをモニタおよび管理し、
- セキュア認証と通信を確保するためのサーバ証明書を処理します。
- ファームウェア一覧を追跡して、システムのセキュリティと安定性を更新および維持します。
手順
ステップ 1 | 対象のサーバに移動します。
|
ステップ 2 | [モニタ(Monitor)] 領域で、 [情報(Information)]をクリックします。 |
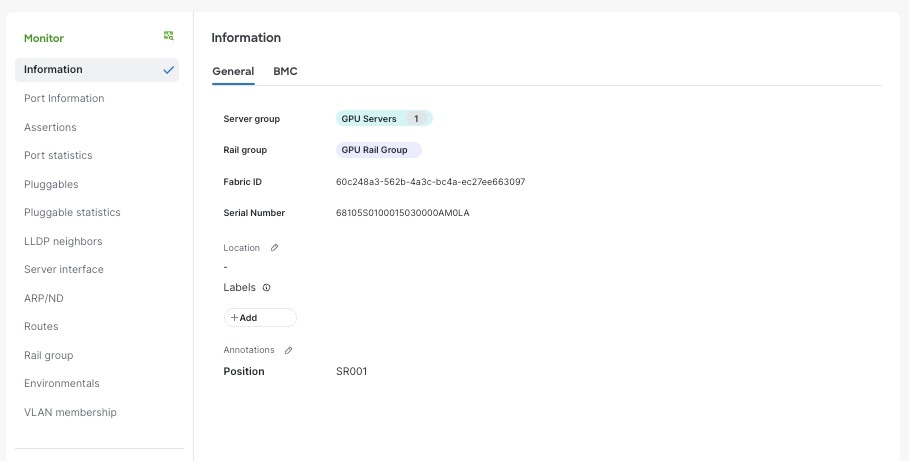
ステップ 3 | デフォルトでは、[全般(General)] サーバの詳細が表示されます。利用可能な場合、サーバの詳細には次のものが含まれます
 |
ステップ 4 | [BMC] をクリックして
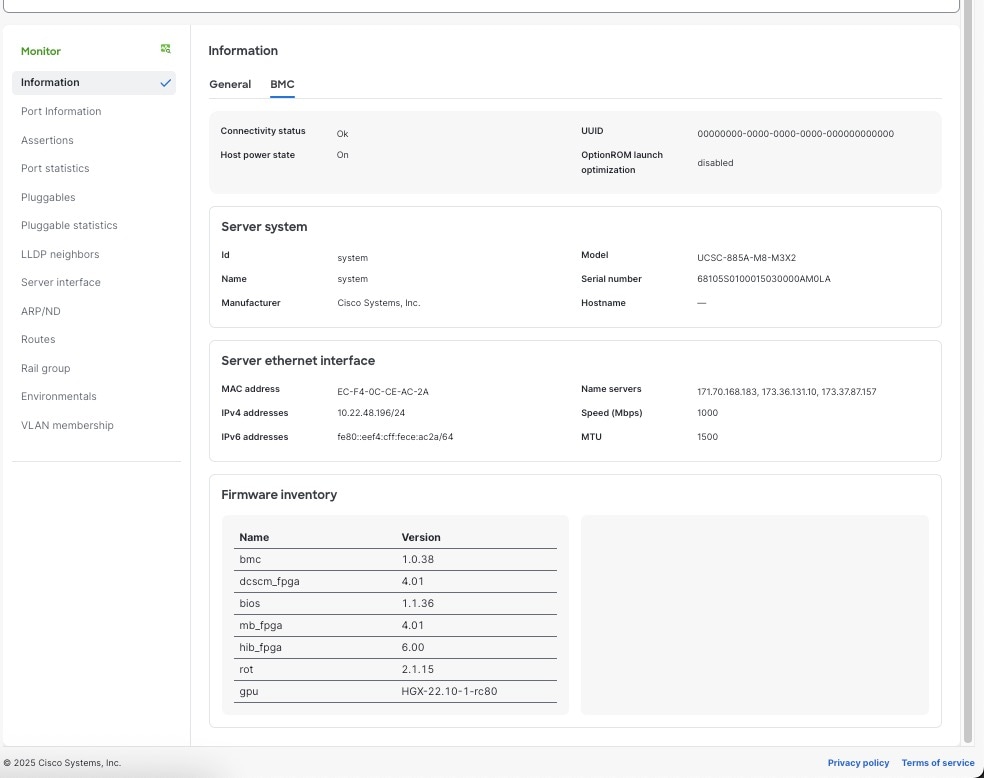 |
サーバのポートの表示
一目で、どのサーバ ポートがアップしているか、接続されていないか、または無効になっているかを確認できます。サーバ内のすべてのポートのリストを表示して、接続されているスイッチ ポートまたはレール グループをすばやく識別できます。このリストは、ネットワークの問題を分離し、リンク ステータス、速度、 VLAN 構成を確認するのに役立ちます。特定のサーバ ポートの詳細を調査することもできます。
手順
ステップ 1 | 対象のサーバに移動します。
|
ステップ 2 | [ポート(Ports)] 領域で、 [ポート ステータス(Port status)] または [前面プレート(Faceplate)]を選択します。
|
ステップ 3 | サーバ上のすべてのポートのリストを表示するには、[モニタ(Monitor)] 領域で [ポート情報(Port information)]をクリックします。 [ポート情報(Port information)] テーブルには、サーバのすべてのポートが表示されます。次を表示します。
|
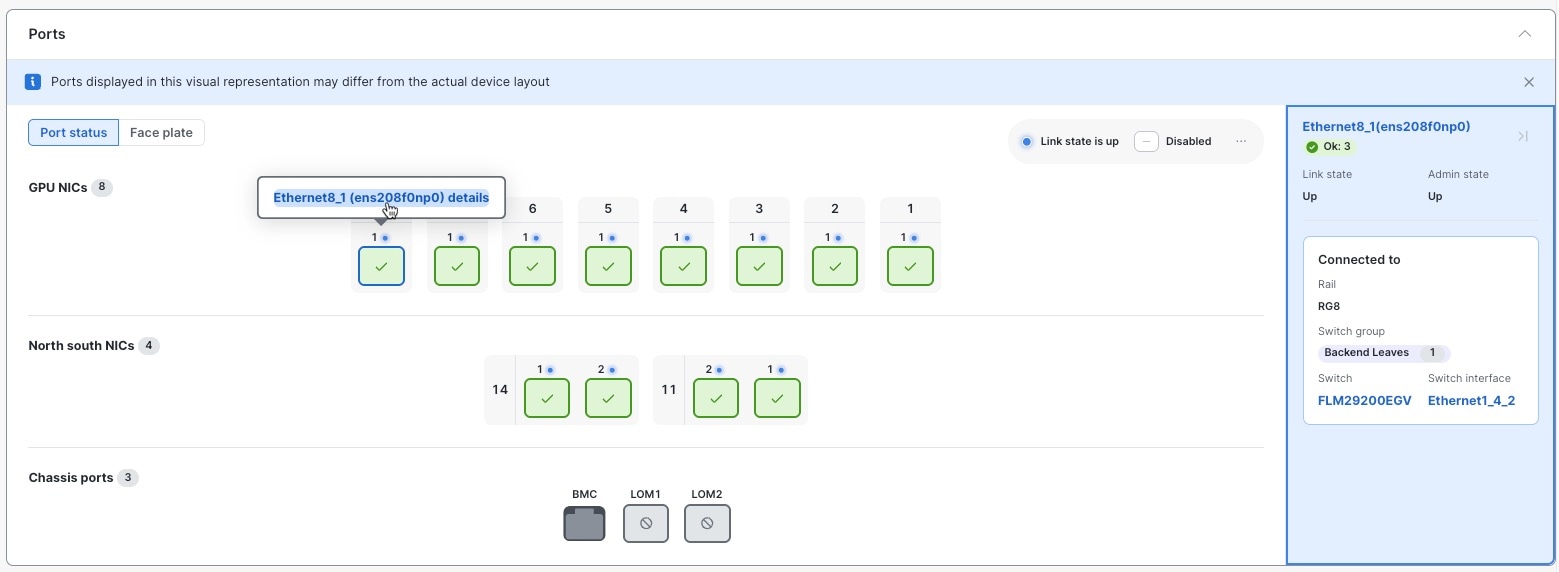
ステップ 4 | 特定のポートに関する詳細を表示するには、次の手順を実行します。
|
ポート統計情報の表示
サーバ ポートの統計情報をモニタすると、ネットワーク ポートの動作状態およびパフォーマンスを把握できます。また、物理層の問題、輻輳、トラフィックの異常、セキュリティ上の問題など、潜在的な問題の特定にも役立ちます。
手順
ステップ 1 | 使用するサーバに移動します。
|
ステップ 2 | [モニタ(Monitor)] 領域で、 [ポート統計情報(Port statistics)]をクリックします。 [ポート統計情報(Port statistics)] テーブルの各メトリックはインサイトを提供します。
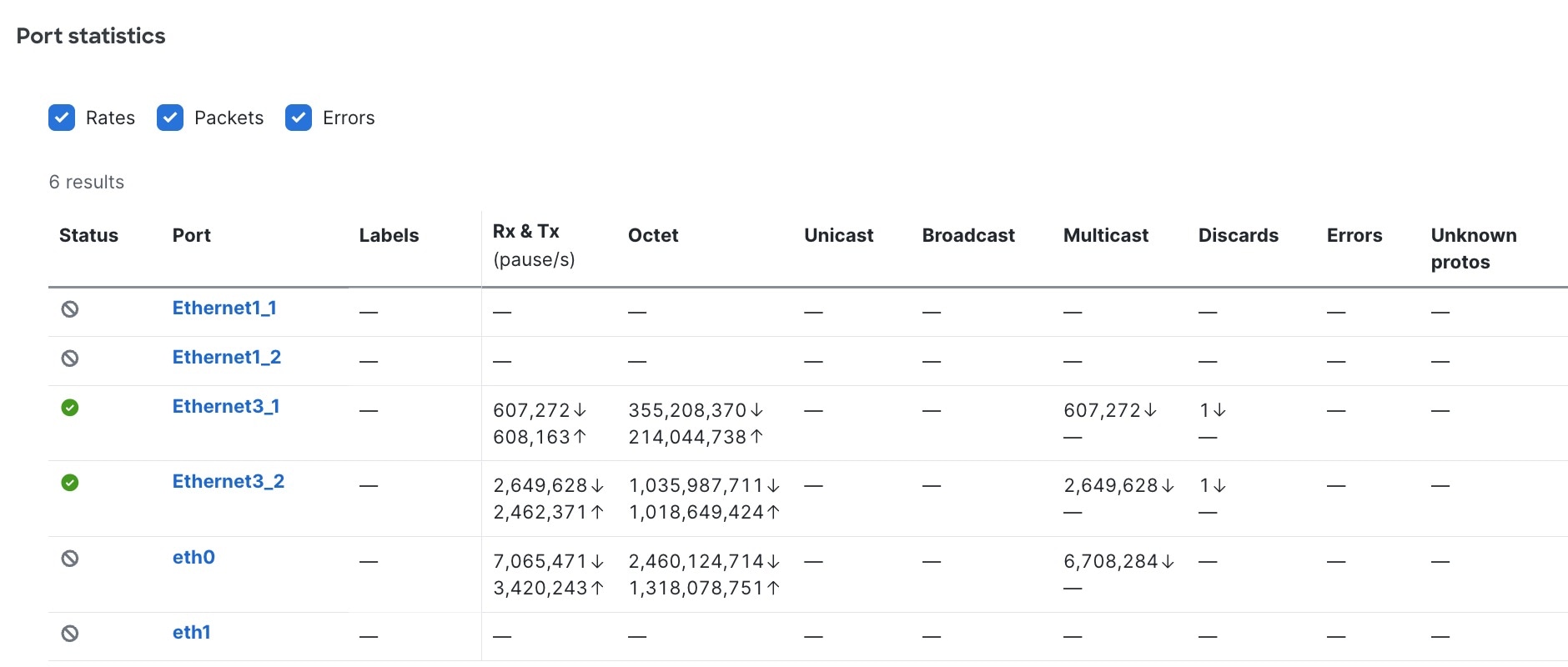 |
ケーブル接続
Cisco Nexus HyperFabric は、デバイスペアごとの接続数とケーブル接続戦略に基づいて、ファブリック内のデバイスをケーブル接続する方法を自動的に決定します。ケーブル接続戦略は 2 つの概念で構成されます。
最初の概念は、次のとおりです。
- 厳格:Cisco Nexus HyperFabric は、選択した接続数で各デバイスペアを接続します。何らかの理由でデバイスに使用可能なポートが不足している場合、 Cisco Nexus HyperFabric は、ケーブル接続にエラーがあることを示しています。
- ベスト エフォート:Cisco Nexus HyperFabric は、可能な場合は、選択した接続数で各デバイス ペアを接続します。ただし、何らかの理由でデバイスに十分な数の使用可能なポートがない場合、Cisco Nexus HyperFabric は、ペアのデバイスを、十分な数の使用可能なポートがある同じスイッチ グループ内の他のデバイスに接続します。
第 2 の概念は次のとおりです。
-
密度:Cisco Nexus HyperFabric は、デバイスの連続するポートをペアリングされたデバイスの連続するポートに接続します。連続するポートの数は、選択したデバイス ペアごとの接続数と同じです。 Cisco Nexus HyperFabric は、ペアリングされたデバイスごとに、連続するポートのこの接続を繰り返します。これはスイッチ間接続に使用されます。
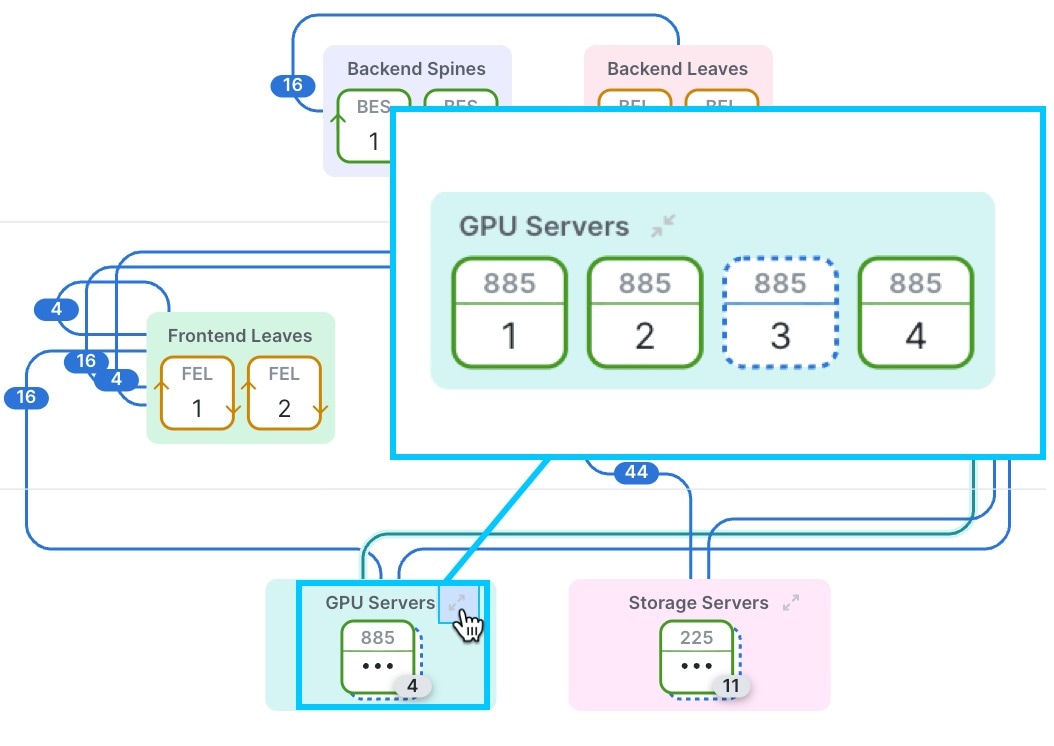
2 つのスパインスイッチと 2 つのリーフ スイッチを使用したスイッチ間高密度ケーブル接続戦略 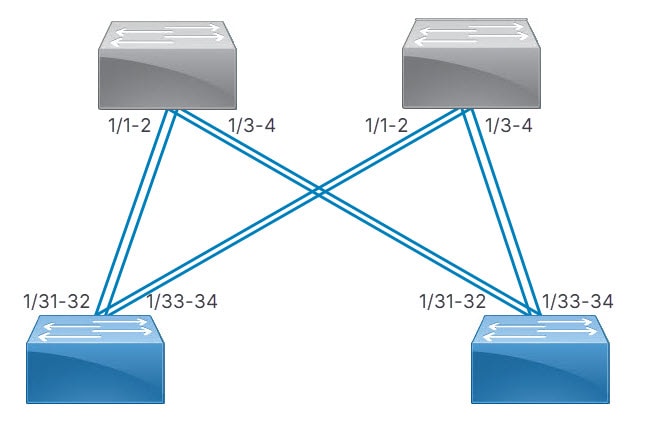
-
分散型:Cisco Nexus HyperFabric は、最初のサーバの最初のネットワーク インターフェイス カード(NIC)を最初のスイッチの最初のポートに接続し、次にサーバの 2 番目のNIC を2 番目のスイッチの最初のポートに接続します。サーバが 1 つの各スイッチの最初のポートに接続します。 Cisco Nexus HyperFabric は、後続のサーバでこのプロセスを繰り返しますが、NIC は各スイッチの次のポートに接続します。各サーバの NIC が各スイッチに接続された後、指定された接続数と等しい数の各サーバから各スイッチへの接続数が存在するようになるまで、プロセス全体が繰り返されます。
GPU を備えたサーバ ポート グループも分散ケーブル戦略を使用します。レール グループ プロパティでは、これらのサーバの幅は GPU サーバの数と同じで、数は 8 です。
GPU がある場合とない場合で、、同じスイッチに接続するには、各サーバで同じ NIC 番号を使用します。したがって、2 台のサーバ(server1 と server2)と 2 台のスイッチ(switch1 と switch2)があるファブリックの場合、両方のサーバの NIC1 は switch1 に接続され、両方のサーバの NIC2 は switch2 に接続します。
2 つのリーフスイッチと 2 つのサーバによるスイッチからサーバへの分散ケーブル戦略 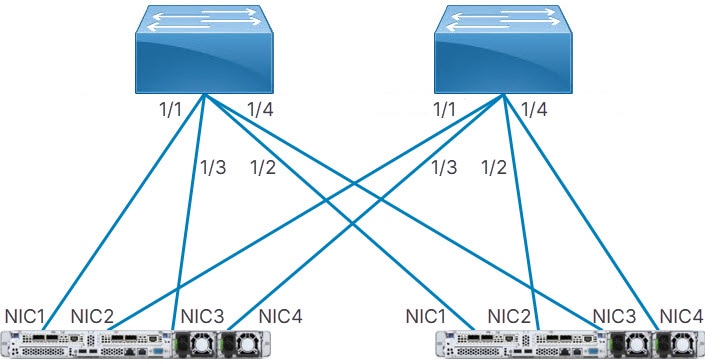
ファブリックに同じスイッチ グループまたはサーバ グループ内のデバイス間の接続が含まれている場合、Cisco Nexus HyperFabric はまず異なるグループのデバイス ペアにポートを割り当ててから、同じグループ内のデバイスにポートを割り当てます。
サーバのケーブル接続
GPU を備えていないサーバのアップリンク冗長性のために、ケーブル配線戦略は常に分散型です。接続は、スイッチのポートからサーバのネットワーク インターフェイス カード(NIC)のポートに行われます。
GPU を備えたサーバ ポート グループも分散ケーブル戦略を使用します。レール グループ プロパティでは、これらのサーバの幅は GPU サーバの数と同じで、数は 8 です。
いずれかの場合、同じスイッチに接続するには、各サーバで同じ NIC 番号を使用します。したがって、2 台のサーバ(server1 と server2)と 2 台のスイッチ(switch1 と switch2)があるファブリックの場合、両方のサーバの NIC1 は switch1 に接続され、両方のサーバの NIC2 は switch2 に接続します。
スイッチとサーバ間の接続は分散されるため、サーバの後続の各NIC は、すべてのスイッチがサーバごとの異なる NIC から 1 つの接続を確立できるようになるまで、異なるスイッチに接続します。その後、各サーバの次のNICが最初のスイッチに接続され、このプロセスが繰り返されます。
この例を続け、2 つの接続を選択した場合、server1 には次の接続があります。
- NIC1 から switch1
- NIC2 から switch2
- NIC3 から switch1
- NIC4 から switch2
Server2 は同じ接続がありますが、スイッチの異なるポートに接続しています。
ケーブル接続トポロジの表示
ファブリック内のケーブルをグラフィカルに表示し、関連するデバイス グループの接続情報を表示できます。
手順
ステップ 1 | [ファブリック(Fabrics)]を選択し、ケーブル接続を表示するファブリックをクリックします。 ケーブル接続は、異なるデバイス グループを結ぶ色付きの線として表示されます。ケーブルの各数字は、デバイス グループ間の接続数を示します。 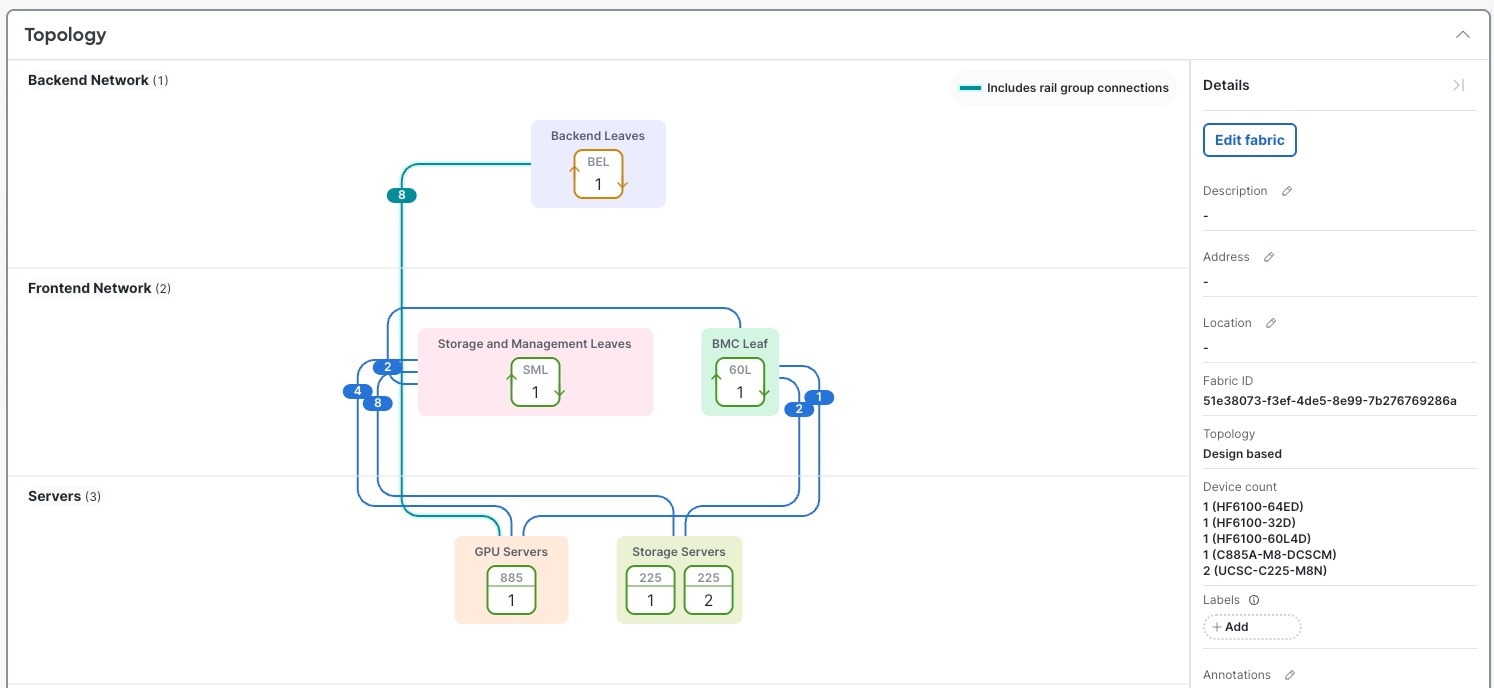 |
ステップ 2 | 対象のケーブルの番号をクリックします。 ケーブル接続ドロワーに、選択したケーブルのすべての接続が一覧表示されます。接続ごとに、デバイス グループ名、デバイス名、およびインターフェイスが表示されます。 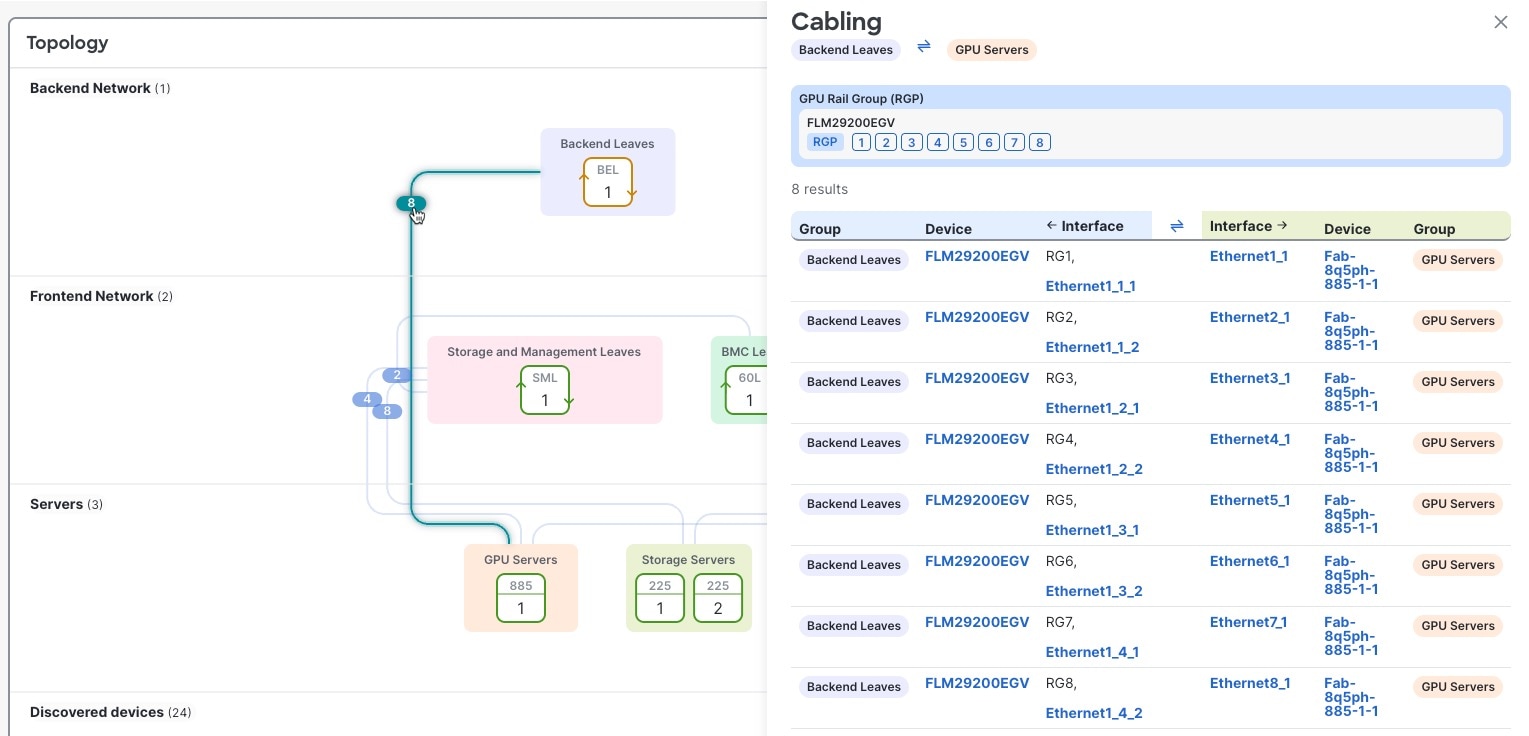 |
ケーブル配線の変更
スイッチに関連付けられているすべてのファブリック接続を表示、エクスポート、および変更できます。
手順
ステップ 1 | 対象のスイッチに移動します。
|
ステップ 2 | [構成(Configure)] 領域で、[ケーブル接続(Cabling)] をクリックします。[ケーブル接続(Cabling)] テーブルには、スイッチに関連付けられているすべてのファブリック接続が一覧表示されます。このリストをエクスポートするには、 [CSVのエクスポート(Export CSV)]をクリックします。 |
ステップ 3 | [ケーブルの編集 cabling)]をクリックします。 |
ステップ 4 | スイッチ グループの接続を変更するには、次の手順を実行します。
|
ステップ 5 | レール グループを変更するには、新しいレール グループを追加するか、次のフィールドを変更します。
|
ステップ 6 | サーバ ポート グループからスイッチ グループへの接続を変更するには、次のフィールドを編集します。
|
ステップ 7 | [構成の保存(Save Configuration)] をクリックして変更を保存します。 |
ステップ 8 | [ケーブル接続の実行(Run cabling)] をクリックして、構成変更を適用します。 |
 )をクリックし、プラガブルの PID を選択します。
)をクリックし、プラガブルの PID を選択します。 (注)
(注)