Ultra Cloud Core Subscriber Microservices Infrastructure Overview
The Ultra Cloud Core Subscriber Microservices Infrastructure (SMI) provides a run time environment for deploying and managing Cisco's cloud-native network functions (cNFs), also referred to as applications.
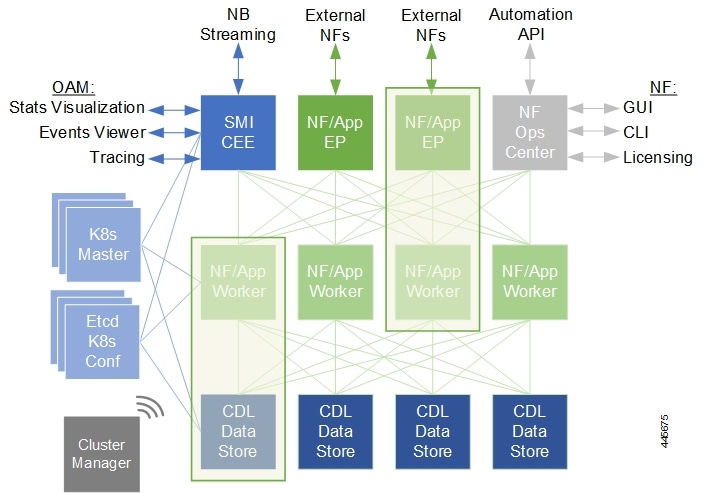
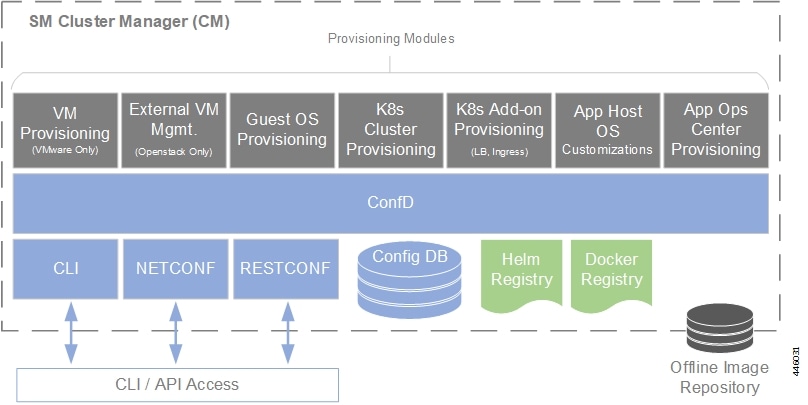
It is built around open source projects like Kubernetes (K8s), Docker, Helm, etcd, confd, and gRPC and provides a common set of services used by deployed cNFs including:
-
Protocol Load Balancing: These microservices provide the external NF interfaces (HTTP, Diameter, GTP, LDAP, etc.) and load balance requests to the application microservices. They normalize internal communications and allow application evolution independent of the interface evolution. Each protocol type is usually implemented as a separate microservice. gRPC is used for internal communication with the application microservices
-
Database Service: The database service provides a normalized gRPC interface to the application microservices. The database service can interface to different databases allowing the use of different back-end databases depending on the application requirements while maintaining the same interface.
-
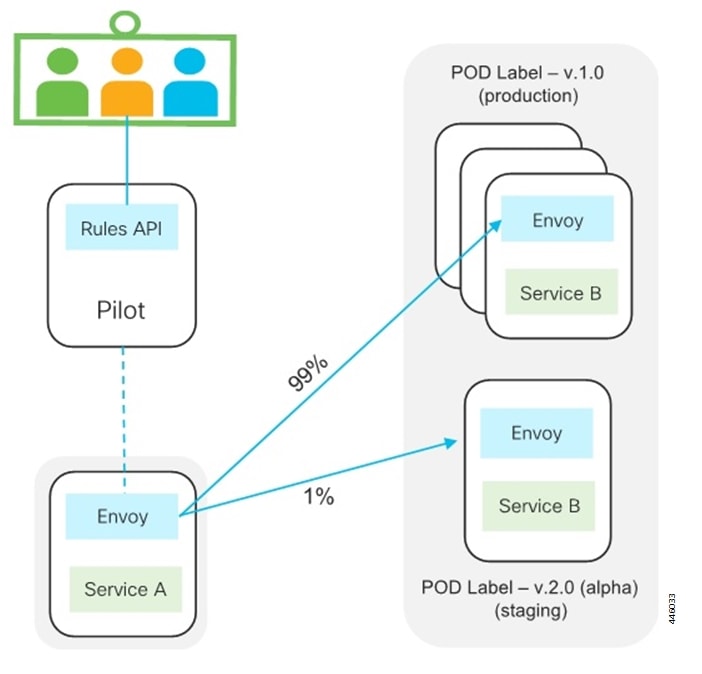
Cisco Service Mesh: This service provides rule-based control over load balancing decisions across different application containers. Through this service, SMI supports and automates operations such as canary upgrades, new service roll-outs, and in-service upgrades.
-
Telemetry Service: Telemetry functionality is provided through a common set of microservices which collect real-time statistics, alarms, logs from various deployed application components, and translates and streams them to external functions.
-
Dashboard Service: The dashboard service works with the telemetry service to provide operational overview data for application containers such as state, utilization, and key performance indicators (KPIs).
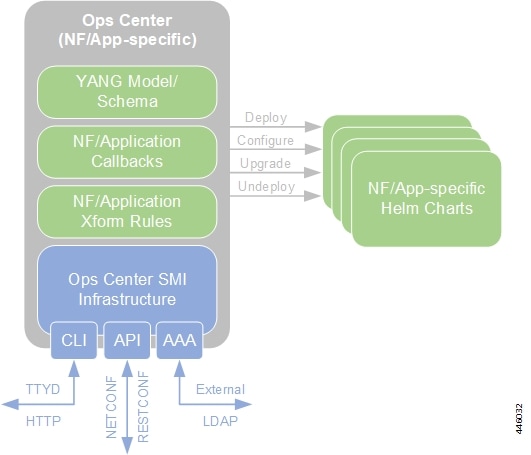
Cisco's cNFs are implemented as a set of microservices that make use of the common platform services offered by SMI. Refer to the NF's documentation for additional details.
SMI on Bare Metal - Overview
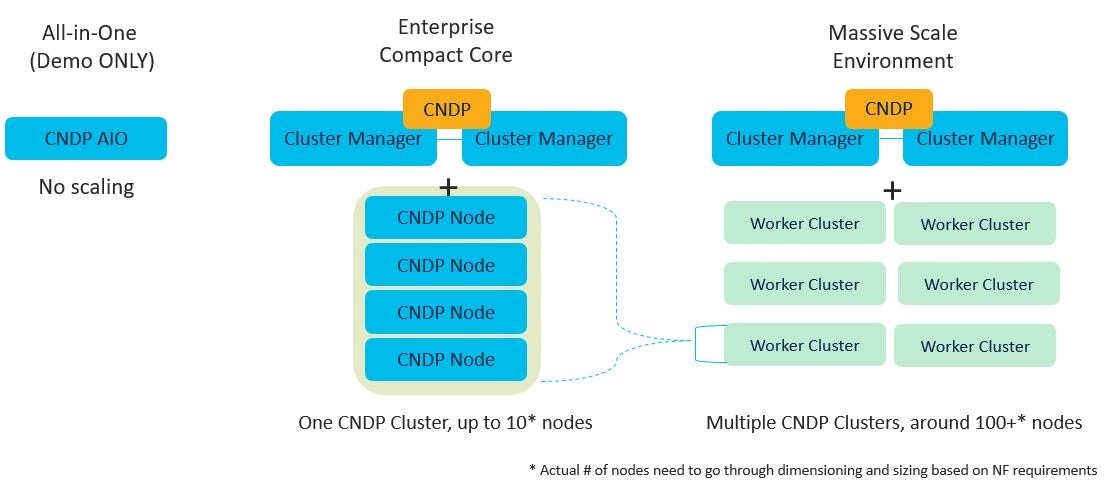
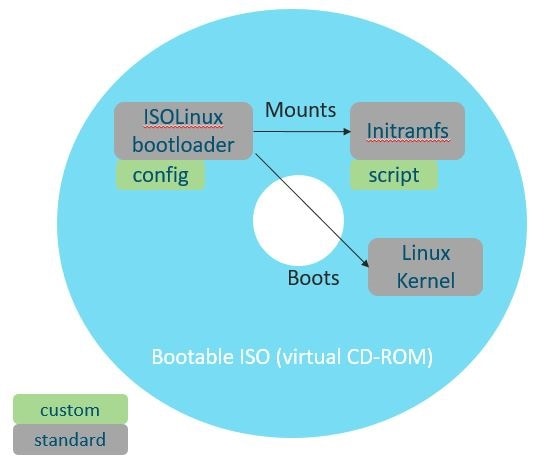
The SMI extends the deployment of Virtual Network Functions (VNF) and Cloud-Native Network Functions (CNFs) to bare metal servers (Cisco UCS-C servers) with the current release. Also, the SMI supports vertically integrated deployment on bare metal servers.
The following are some of the significant features deploying SMI on Bare Metal servers:
-
Elimination of VIM-related overhead on Bare Metal servers
-
Zero touch deployment for both VNF and CNF based applications
-
Automated infrastructure upgrades
-
Exposed API for deployment, configuration, and management to enable automation.
-
Addresses edge deployment
-
Provides single compute user plane to run at remote sites
-
-
Scales out without any additional overhead
-
Ground up API (NETCONF, REST) driven design and architecture
-
All the interfaces are compliant with northbound NFVO (for instance, NSO).
-
-
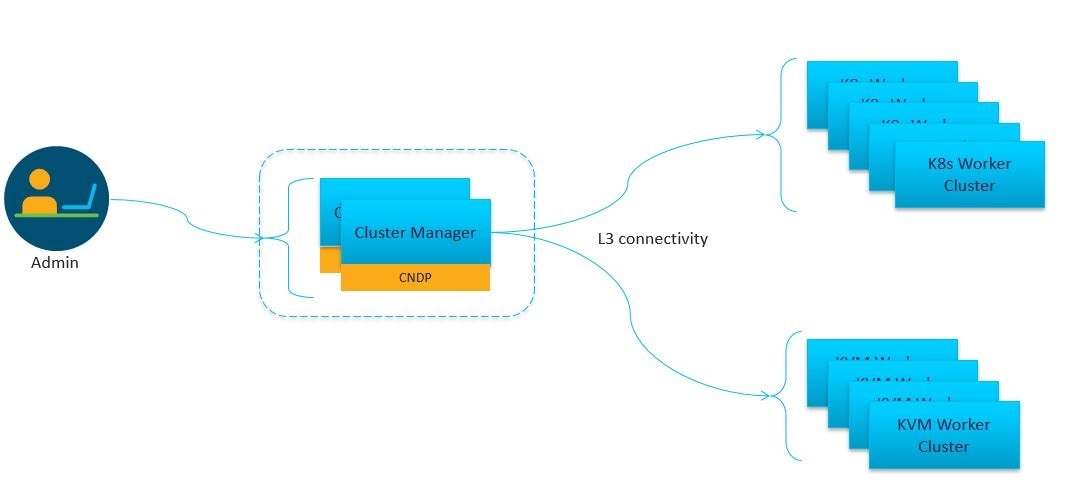
Simplification and remote management
-
Removes shared storage from the architecture
-
Single monitoring endpoint for both server and application health
 Note |
The SMI has the ability to run virtual machines for legacy applications (CUPS CP and UPF). |
 Feedback
Feedback