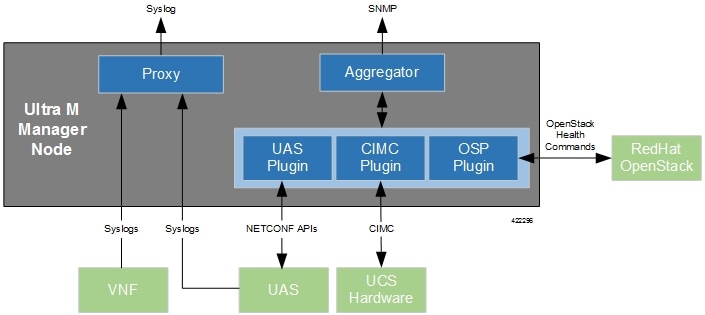
Syslog Proxy
The Ultra M Manager Node can be configured as a proxy server for syslogs received from UCS servers and/or OpenStack. As a proxy, the Ultra M Manager Node acts a single logging collection point for syslog messages from these components and relays them to a remote collection server.
NOTES:
-
This functionality is currently supported only with Ultra M deployments based on OSP 10 and that leverage the Hyper-Converged architecture.
-
You must configure a remote collection server to receive and filter log files sent by the Ultra M Manager Node.
-
Though you can configure syslogging at any severity level your deployment scenario requires, it is recommended that you only configure syslog levels with severity levels 0 (emergency) through 4 (warning).
Once the Ultra M Manager RPM is installed, a script provided with this release allows you to quickly enable syslog on the nodes and set the Ultra M Manager Node as the proxy. Leveraging inputs from a YAML-based configuration file, the script:
-
Inspects the nodes within the Undercloud and Overcloud
-
Logs on to each node
-
Enables syslogging at the specified level for both the UCS hardware and for the following OpenStack services on their respective nodes:
-
Controller Nodes: Nova, Keystone, Glance, Cinder, and Ceph
-
Compute Nodes: Nova
-
OSD Compute Nodes: Nova, Ceph

Important
Syslogging support for Ceph is only available using Ultra M Manager 1.0.4.
-
-
Sets the Ultra M Manager Node’s address as the syslog proxy
Important |
The use of this script assumes that all of the nodes use the same login credentials. |
 Caution |
Enabling/disabling syslog proxy functionality on OpenStack changes the service configuration files and automatically restarts the services. It is highly recommended that this process only be performed during a maintenance window. |
To enable this functionality:
-
Install the Ultra M Manager bundle RPM using the instructions in Install the Ultra M Manager RPM.
Note
This step is not needed if the Ultra M Manager bundle was previously installed.
-
Become the root user.
sudo su -
Verify that there are no previously existing configuration files for logging information messages in /etc/rsyslog.d.
-
Navigate to /etc/rsyslog.d.
cd /etc/rsyslog.d ls -alExample output:
total 24 drwxr-xr-x. 2 root root 4096 Sep 3 23:17 . drwxr-xr-x. 152 root root 12288 Sep 3 23:05 .. -rw-r--r--. 1 root root 49 Apr 21 00:03 listen.conf -rw-r--r--. 1 root root 280 Jan 12 2017 openstack-swift.conf -
Check the listen.conf file.
cat listen.confExample output:
$SystemLogSocketName /run/systemd/journal/syslog -
Check the configuration of the openstack-swift.conf.
cat openstack-swift.confExample configuration:
# LOCAL0 is the upstream default and LOCAL2 is what Swift gets in # RHOS and RDO if installed with Packstack (also, in docs). # The breakout action prevents logging into /var/log/messages, bz#997983. local0.*;local2.* /var/log/swift/swift.log & stop
-
-
Configure IPTables.
-
On OSPD node, execute the following command to configure the IPTables.
$ vi /etc/sysconfig/iptables
-
Add the following lines at the beginning of filter configuration in the IPTables.
-A INPUT -p udp -m multiport --dports 514 -m comment --comment "514 - For UDP syslog" -m state --state NEW -j ACCEPT-A INPUT -p tcp -m multiport --dports 514 -m comment --comment "514 - For TCP syslog" -m state --state NEW -j ACCEPT -
Restart the IPTables service.
systemctl restart iptables
-
Verify the status of IPTables service.
systemctl status iptables
Example output:
iptables.service - IPv4 firewall with iptables Loaded: loaded (/usr/lib/systemd/system/iptables.service; enabled; vendor preset: disabled) Active: active (exited) since Mon 2017-11-20 13:31:08 EST; 10s ago Process: 3821 ExecStop=/usr/libexec/iptables/iptables.init stop (code=exited, status=9) Process: 4258 ExecStart=/usr/libexec/iptables/iptables.init start (code=exited, status=0/SUCCESS) Main PID: 4258 (code=exited, status=0/SUCCESS) Nov 20 13:31:08 tb3-ospd.mitg-bxb300.cisco.com systemd[1]: Starting IPv4 firewall with iptables... Nov 20 13:31:08 tb3-ospd.mitg-bxb300.cisco.com iptables.init[4258]: iptables: Applying firewall rules: [ OK ] Nov 20 13:31:08 tb3-ospd.mitg-bxb300.cisco.com systemd[1]: Started IPv4 firewall with iptables.
-
-
Enable syslogging to the external server by configuring the /etc/rsyslog.conf file.
vi /etc/rsyslog.conf-
Enable TCP/UDP reception.
# provides UDP syslog reception $ModLoad imudp $UDPServerRun 514 # provides TCP syslog reception $ModLoad imtcp $InputTCPServerRun 514 -
Disable logging for private authentication messages.
# Don't log private authentication messages! #*.info;mail.none;authpriv.none;cron.none /var/log/messages -
Configure the desired log severity levels.
# log 0-4 severity logs to external server 172.21.201.53 *.4,3,2,1,0 @<external_syslog_server_ipv4_address>:514This enables the collection and reporting of logs with severity levels 0 (emergency) through 4 (warning).
Caution
Though it is possible to configure the system to locally store syslogs on the Ultra M Manager Node, it is highly recommended that you avoid doing so to avoid the risk of data loss and to preserve disk space.
-
-
Restart the syslog server.
systemctl restart rsyslog -
Navigate to /etc.
cd /etc -
Create and/or edit the ultram_cfg.yaml file based your VIM Orchestrator and VIM configuration. A sample of this configuration file is provided in Example ultram_cfg.yaml File.
Important
The ultram_cfg.yaml file pertains to both the syslog proxy and event aggregation functionality. Some parts of this file’s configuration overlap and may have been configured in relation to the other function.
vi ultram_cfg.yaml-
Optional. Configure your Undercloud settings if they are not already configured.
under-cloud: OS_AUTH_URL: <auth_url> OS_USERNAME: admin OS_TENANT_NAME: <tenant_name> OS_PASSWORD: <admin_user_password> ssh-key: /opt/cisco/heat_admin_ssh_key -
Optional. Configure your Overcloud settings if they are not already configured.
over-cloud: enabled: true environment: OS_AUTH_URL: <auth_url> OS_TENANT_NAME: <tenant_name> OS_USERNAME: <user_name> OS_PASSWORD: <user_password> OS_ENDPOINT_TYPE: publicURL OS_IDENTITY_API_VERSION: 2 OS_REGION_NAME: regionOne -
Specify the IP address of the Ultra M Manager Node to be the proxy server.
<-- SNIP --> rsyslog: level: 4,3,2,1,0 proxy-rsyslog: <ultram_manager_address>Important
-
You can modify the syslog levels to report according to your requirements using the level parameter as shown above.
-
<ultram_manager_address> is the internal IP address of the Ultra M Manager Node reachable by OpenStack and the UCS servers.
-
If you are copying the above information from an older configuration, make sure the proxy-rsyslog IP address does not contain a port number.
-
-
Optional. Configure the CIMC login information for each of the nodes on which syslogging is to be enabled.
ucs-cluster: enabled: true user: <username> password: <password>Important
The use of this script assumes that all of the nodes use the same login credentials.
-
-
Navigate to /opt/cisco/usp/ultram-manager.
cd /opt/cisco/usp/ultram-manager -
Optional. Disable rsyslog if it was previously configured on the UCS servers.
./ultram_syslogs.py --cfg /etc/ultram_cfg.yaml –u -d -
Execute the ultram_syslogs.py script to load the configuration on the various nodes.
./ultram_syslogs.py --cfg /etc/ultram_cfg.yaml -o –uImportant
Additional command line options for the ultram_syslogs.py script can be seen by entering ultram_syslogs.py –help at the command prompt. An example of the output of this command is below:
usage: ultram_syslogs.py [-h] -c CFG [-d] [-u] [-o] optional arguments: -h, --help show this help message and exit -c CFG, --cfg CFG Configuration file -d, --disable-syslog Disable Syslog -u, --ucs Apply syslog configuration on UCS servers -o, --openstack Apply syslog configuration on OpenStack
Example output:
2017-09-13 15:24:23,305 - Configuring Syslog server 192.200.0.1:514 on UCS cluster 2017-09-13 15:24:23,305 - Get information about all the nodes from under-cloud 2017-09-13 15:24:37,178 - Enabling syslog configuration on 192.100.3.5 2017-09-13 15:24:54,686 - Connected. 2017-09-13 15:25:00,546 - syslog configuration success. 2017-09-13 15:25:00,547 - Enabling syslog configuration on 192.100.3.6 2017-09-13 15:25:19,003 - Connected. 2017-09-13 15:25:24,808 - syslog configuration success. <---SNIP---> <---SNIP---> 2017-09-13 15:46:08,715 - Enabling syslog configuration on vnf1-osd-compute-1 [192.200.0.104] 2017-09-13 15:46:08,817 - Connected 2017-09-13 15:46:09,046 - - /etc/rsyslog.conf 2017-09-13 15:46:09,047 - Enabling syslog ... 2017-09-13 15:46:09,130 - Restarting rsyslog 2017-09-13 15:46:09,237 - Restarted 2017-09-13 15:46:09,321 - - /etc/nova/nova.conf 2017-09-13 15:46:09,321 - Enabling syslog ... 2017-09-13 15:46:09,487 - Restarting Services 'openstack-nova-compute.service' -
Ensure that client log messages are being received by the server and are uniquely identifiable.
NOTES:
-
If necessary, configure a unique tag and hostname as part of the syslog configuration/template for each client.
-
Syslogs are very specific in terms of the file permissions and ownership. If need be, manually configure permissions for the log file on the client using the following command:
chmod +r <URL>/<log_filename>
-
 Feedback
Feedback