- The Virtual SAN Shared Datastore
- Read Caching and Write Buffering
- Virtual SAN Storage Policy Based Management (SPBM)
- Virtual SAN Recommendations and Limits
- Virtual SAN Requirements
- Defining Virtual Machine Requirements
- Distributed RAID
- Virtual SAN Storage Objects and Components
- Flash-Based Devices in Virtual SAN
Technology Overview
This white paper is focused on the benefits that that Cisco UCS brings to the DRaaS solution when combined with the VMware Virtual SAN hypervisor converged storage offering. These two key technologies are discussed in more detail below.
System Architecture
This section describes the high level architecture of the DRaaS 2.0 system. The system provides disaster recovery for customer physical/virtual servers by deploying recovery VMs in the VMDC VSA 1.0-based container on the provider side.
Figure 2-1 shows the high level architecture of the DRaaS 2.0 system.
Figure 2-1 DRaaS 2.0 High Level Architecture
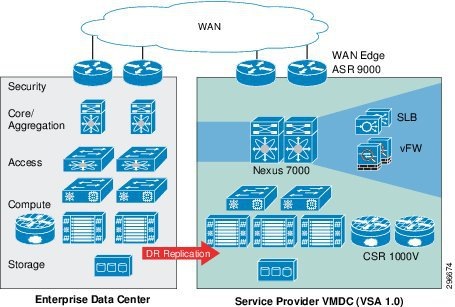
The physical system architecture consists of the following building blocks:
- Provider Cloud
- Enterprise Data Center
- WAN Connectivity
- Partner Solution for Providing Disaster Recovery
These building blocks are described in further detail below.
Provider Cloud
The provider cloud within the DRaaS 2.0 system is based on VMDC VSA 1.0. The VSA 1.0 design is based on the earlier VMDC 2.2 design, with changes to optimize the design for lower cost, fewer layers, and increased tenancy scale. The VMDC system provides vPC-based L3 hierarchical virtual routing and forwarding (VRF)-Lite DC design, multi-tenancy, secure separation, differentiated service tiers, and high availability in a data center environment. It also provides secure separation between replicated workloads and provides shared network services for customers in DRaaS.
The VMDC VSA 1.0 architecture works with Vblock, FlexPod, or any other integration stack. Integrated stacks can be added as required to scale the CSP cloud environment.
Based on the customer's production environment and needs, a specific tenancy model can be selected to provide similar services in the cloud-matching production environment. VMDC architecture and deployment models will be covered in detail in this chapter.
Enterprise Data Center
The DR solutions should address enterprise customer requirements for various vertical industries and geographies. The enterprise data center design is therefore expected to vary from customer to customer. The intent of the DRaaS 2.0 system is to keep the enterprise DC architecture generic so as to provide the greatest coverage. While the enterprise DC architecture is almost irrelevant and the solution supports heterogeneous replication across any-to-any infrastructure, a typical three tier (core/aggregation and access) DC architecture is suggested in the system.
WAN Connectivity
The WAN connectivity design principles provided by VMDC are maintained and supported without requiring any additional components and technologies. The replicated data between the enterprise and CSP data center can be encrypted with the help of Cisco technologies like IPsec VPN, based on Cisco ASA firewalls.
To support partial failover of a customer's environment, technologies like Overlay Transport Virtualization (OTV) can be used for L2 extension between the customer's data center and the cloud. L2 connectivity allows customers to use the same IP from enterprise network in the cloud without the need to change for accessing workloads in the cloud after recovery.
Partner Solution for Providing Disaster Recovery
ZVR provides a business continuity (BC) and disaster recovery (DR) solution in a virtual environment, enabling the replication of mission-critical applications and data as quickly as possible and with minimal data loss. When devising a recovery solution, these two objectives, minimum time to recover and maximum data to recover, are assigned target values: the RTO and the RPO. ZVR enables a virtual-aware recovery with low values for both the RTO and RPO.
ZVR is installed in both the protected and the DR sites. Administrators can manage the replication from within a standalone UI in a browser, enabling DR management from anywhere or from a vSphere Client console. All recovery that does not rely on native replication functionality can be managed from the vSphere Client console. Recovery that does rely on native replication functionality, such as recovery available with Microsoft Active Directory or SQL Server, can also be replicated using ZVR, and whether the native replication functionality is used or not is determined by site considerations, such as increased complexity of having multiple points of control and possible additional costs incurred when using vendor native replication.
Replication is configured by first pairing the site with virtual machines to be protected with a recovery site. The administrator then defines the virtual machines that need protection into groups, where the virtual machines in the group comprise the application and data that needs to be recovered together. Different virtual machines can be grouped together or kept separated. Creating more granular replication affinity groups allows for optimal recovery operations.
System Logical Topology
In the logical topology Figure 2-2, each customer will have a dedicated network container created on the CSP VMDC cloud. The network containers will be created based on the necessary security and network services required by the enterprise customers. Any network topology on the customer's data center can be matched on the VMDC cloud using network containers. Pre-defined containers provide examples for different types of deployments. Automated provisioning and management logic for each customer type is pre-defined in the management and orchestration software. Customers can choose from existing models or define their own customized models. The production workloads from each enterprise data center will be replicated to the corresponding network container on the VMDC cloud and will be available for recovery purposes.
Figure 2-2 DRaaS Logical Topology
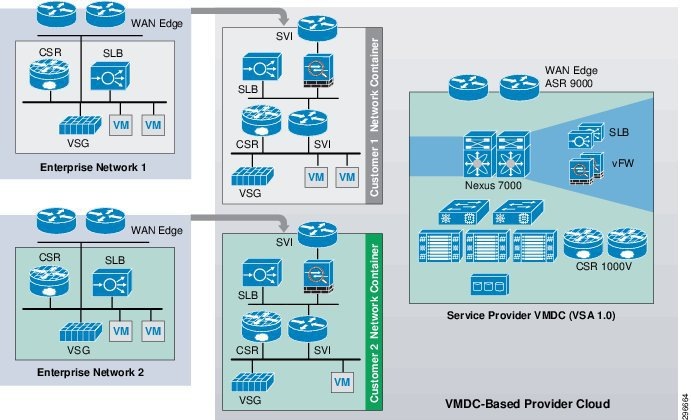
End-to-End Architecture
The DRaaS 2.0 system addresses the following design principles and architectural goals:
- Secure multi-tenancy
- Secure, modular, and highly available cloud
- Continuous Data Protection (CDP)
- Physical-to-Virtual (P2V) and Virtual-to-Virtual (V2V) Disaster Recovery
- Near-zero RPO- and RTO-capable DRaaS
- Automated run book automation
- Self-service multi-tenant portal
By utilizing the architecture above, DRaaS in a multi-tenant environment can be supported as shown in Figure 2-3.
Figure 2-3 End-to-End Architecture
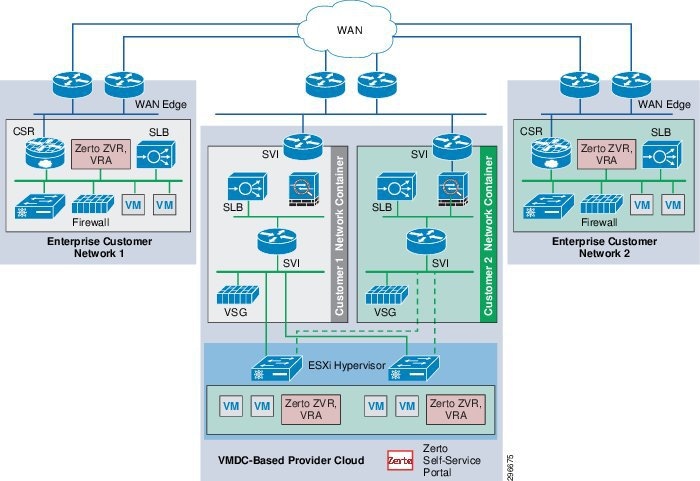
In a multi-tenant environment, each customer is mapped as a separate VMDC tenant where the necessary network security is provided and traffic segregation is maintained. Figure 77 depicts the end-to-end architecture of the DRaaS 2.0 system based on VMDC. With the deployment of lightweight components and by utilizing the network security provided by VMDC architecture, customers can replicate their data into a secure cloud environment for recovery.
Data changes are collected from the production servers as they occur, directly in memory before they are written to disk, and sent to a software appliance within an enterprise data center. Because of this approach, absolutely no additional I/O load is induced on production servers due to replication. The appliance is responsible for further offloading compute-intensive tasks from production systems, such as compression, encryption, WAN acceleration, and consolidated bandwidth management.
The system provides the journal for the customer's production servers. The customers will be able to recover their environments to any point in time before the disaster occurred. The servers are not only protected from the physical disasters, but also from logical disasters, due to the journal.
Application consistency is enforced at regular intervals through VSS integration on Windows and native application-specific mechanisms on Linux and Solaris systems. Application consistency is also enforced at the guest level in virtual environments running VMware vSphere. These application-consistent points are tagged by a ZVR checkpoint and included as part of the journal data. They can be leveraged to perform application consistent recoveries within stringent RTOs.
The following use cases are covered as part of the DRaaS 2.0 system and will be discussed in more detail in the following sections.
DRaaS Operational Workflows
Following are the workflows for protecting and recovering the customer's production workloads into the cloud. These workflows describe the process of creating the network containers for customers within the CSP cloud, replication of workloads into the network containers, and recovery of workloads in the event of a disaster.
The workflow in Figure 2-4 is used for protection and failover scenarios.
Figure 2-4 New Customer Protection Workflow
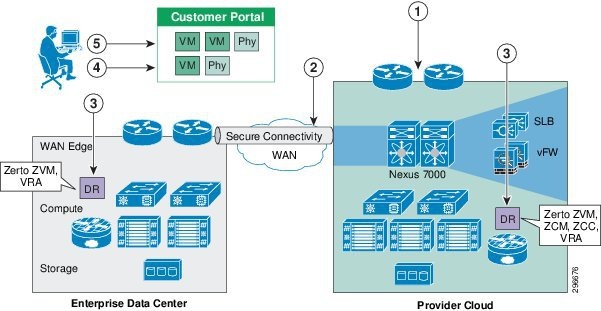
Step 1![]() Based on the customer requirements, deploy a VMDC network container using BMC.
Based on the customer requirements, deploy a VMDC network container using BMC.
Step 2![]() Secure IPsec connectivity is manually set up between the Enterprise and the VMDC-based cloud provider setup.
Secure IPsec connectivity is manually set up between the Enterprise and the VMDC-based cloud provider setup.
Step 3![]() At both enterprise and CSP data centers, deploy and configure the necessary DR components.
At both enterprise and CSP data centers, deploy and configure the necessary DR components.
Step 4![]() Use the Zerto UI to select the machines to be protected and set up the recovery plans.
Use the Zerto UI to select the machines to be protected and set up the recovery plans.
Step 5![]() Allow customers to monitor the status of DR and RPO/RTO utilizing the Partner Product portals.
Allow customers to monitor the status of DR and RPO/RTO utilizing the Partner Product portals.
The workflow in case of a failure scenario is shown in Figure 2-5.
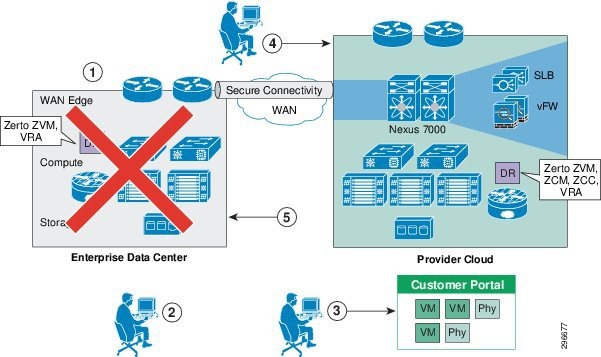
Step 6![]() When the customer DC goes down, the customer declares a disaster and communicates to the CSP what VMs to restore and what checkpoints to use. The CSP can use the recovery plan (which could be preconfigured), which details the list of protected VMs, the startup order, and any custom steps.
When the customer DC goes down, the customer declares a disaster and communicates to the CSP what VMs to restore and what checkpoints to use. The CSP can use the recovery plan (which could be preconfigured), which details the list of protected VMs, the startup order, and any custom steps.
Step 7![]() The CSP logs into the DR product portal and brings up the required VMs in its environment. Customers with self-service capabilities will be able to recover VMs in the cloud themselves using the self-service portal.
The CSP logs into the DR product portal and brings up the required VMs in its environment. Customers with self-service capabilities will be able to recover VMs in the cloud themselves using the self-service portal.
Step 8![]() The customer works with its DNS provider to direct the client traffic to the CSP DC. If the customer is utilizing a Global Site Selector (GSS)-based DNS solution or has an L2 extension, this step will be automatic or not required.
The customer works with its DNS provider to direct the client traffic to the CSP DC. If the customer is utilizing a Global Site Selector (GSS)-based DNS solution or has an L2 extension, this step will be automatic or not required.
Step 9![]() When the Enterprise DC is back up, the customer works with the CSP during a maintenance window to bring up the VMs in customer DC, failback the VMs from CSP to enterprise, and update the DNS so that the client traffic is re-routed to the customer DC.
When the Enterprise DC is back up, the customer works with the CSP during a maintenance window to bring up the VMs in customer DC, failback the VMs from CSP to enterprise, and update the DNS so that the client traffic is re-routed to the customer DC.
Network Deployment Considerations Supporting Recovery Environment
Table 2-1 shows the considerations in matching the networks between the enterprise's and CSP's VPC. Logically, the enterprise network will consist of VLANs and network services, including firewall rules and load balancing. Based on the requirements of the enterprise, which depend on the type of applications that are protected, network containers can be created on the VMDC to meet those requirements.
|
|
|
|
|---|---|---|
Cisco UCS
The Cisco Unified Computing System (Cisco UCS) is a next-generation data center platform that unites computing, networking, storage access, and virtualization resources into a cohesive system designed to reduce total cost of ownership (TCO) and increase business agility. The system integrates a low-latency, lossless 10 Gigabit Ethernet unified network fabric with enterprise-class, x86-architecture servers. The system is an integrated, scalable, multi-chassis platform in which all resources participate in a unified management domain.
Figure 2-6 Cisco Unified Computing System
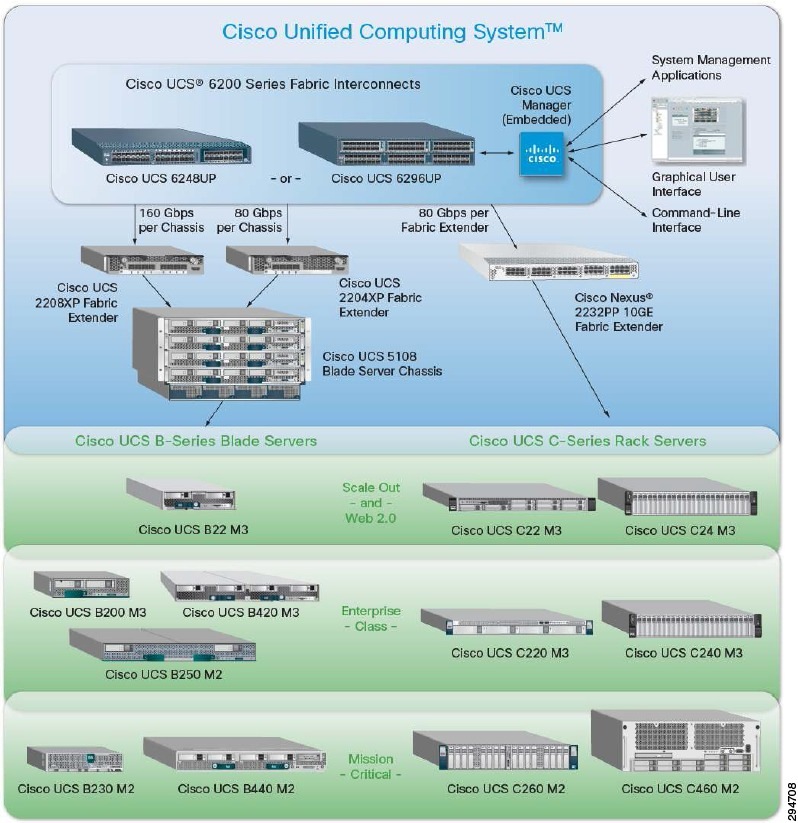
Two elements of the Cisco UCS architecture, immediately relevant to the use of Virtual SAN in the DRaaS solution, are highlighted in this white paper: the C-Series rack-mount server and UCS service profiles. Much additional material is already available discussing the capabilities and features of Cisco UCS technologies. Please see the following resources for more information:
http://cisco.com/c/en/us/td/docs/solutions/Hybrid_Cloud/DRaaS/Service_Template/Service_Templates.pdf
Cisco UCS C-Series Rack-Mount Servers
Cisco UCS C-Series rack-mount servers extend Cisco's Unified Computing to an industry-standard form factor reducing total cost of ownership and increasing agility. A full range of rack servers address workload challenges with a balance of processing, memory, I/O, and internal storage resources. These servers can be managed by the built-in standalone software—called Cisco Integrated Management Controller (CIMC)—or by Cisco UCS Manager when connected through a Cisco Nexus 2232PP Fabric Extender. Cisco UCS Manager, which supplies a totally integrated management process for both rack and blade servers inside a single tool, was used for this white paper. All Cisco UCS servers use leading Intel® Xeon® processors.
There are several UCS C-Series rack-mount server models available, each optimized for particular deployments. For Virtual SAN deployments, disk density drives the model selection, with computing power also being an important consideration. For these reasons, the UCS C240 M3 was chosen for the development of this white paper. The UCS C240 M3 is a 2RU form factor server that comes in two varieties supporting either large form factor (3.5”) or small form factor (2.5”) hard drives. Due to the need for SSDs by the Virtual SAN technology, the small form factor variety is necessary. This provides capacity for up to 24 SAS/SATA/SSD drives and up to 24 TB of capacity (Virtual SAN capacity particulars will be discussed below). The C240 M3 also supports two CPUs and up to 768 GB RAM. Compute performance is important because the VMs leveraging the Virtual SAN datastore will reside on the same hosts that contribute the disk capacity to the datastore.
The following URL provides the complete spec sheet for the UCS C240 M3 small form factor server:
http://www.cisco.com/en/US/prod/collateral/ps10265/ps10493/C240M3_SFF_SpecSheet.pdf
For more details on each of the available models, please visit:
http://www.cisco.com/c/en/us/products/servers-unified-computing/ucs-c-series-rack-servers/datasheet-listing.html
For a side-by-side comparison between the different models, please visit:
http://www.cisco.com/c/en/us/products/servers-unified-computing/ucs-c-series-rack-servers/models-comparison.html
Service Profiles
In Cisco UCS, a service profile adds a layer of abstraction to the actual physical hardware. The server is defined in a configuration file, which is stored on the UCS 6200 Series Fabric Interconnects and can be associated with physical hardware in a simple operation from the UCS Manager. When the service profile is applied, the UCS Manager configures the server, adaptors, Fabric Extenders, and Fabric Interconnects as specified in the service profile. The service profile makes the physical hardware transparent to the OSs and VMs running on it, enabling stateless computing and maximization of data center resources.
A number of parameters can be defined in the service profile depending on the environment requirements. Administrators can create policies to define specific rules and operating characteristics, and be referenced in the service profiles to ensure consistent configuration across many servers. Updates to a policy can be propagated to all servers that reference that policy in their service profile immediately, or in the case of firmware updates, at the next power cycle event.
The advantages of the service profile can be extended further when server-specific parameters such as UUID, MAC address, and WWN are themselves parameterized and the service profile is converted to a template. The template can be used to rapidly deploy new servers with consistent general parameters and unique server-specific parameters
Service profiles, in use with templates, enable rapid provisioning of servers with consistent operational parameters and high availability functionality. They can be configured in advance and used to move servers to a new blade, chassis, or rack in the event of a failure. The main configurable parameters of a service profile are summarized in Table 2-2 .
Compute Over-Subscription
DRaaS utilizes shared resources on the recovery site. Since resources at the failover site sit idle most of the time, DR enables high over-subscription ratios, making it ideal for cloud environments.
The SP can maintain fewer compute resources compared to the customer's production environments. The compute within the CSP cloud is based on Cisco UCS servers, which can be rapidly deployed with the help of the UCS service profiles to meet any unexpected or rare scenario where all the customers fail over to the cloud. In this scenario, new UCS servers can quickly be deployed and added to the existing compute clusters for additional compute resource needs.
VMware Virtual SAN
Virtual SAN is a new software-defined storage solution that is fully integrated with vSphere. Virtual SAN aggregates locally attached disks in a vSphere cluster to create a storage solution—a shared datastore—that rapidly can be provisioned from VMware vCenter™ during virtual machine provisioning operations. It is an example of a hypervisor-converged platform—that is, a solution in which storage and compute for virtual machines are combined into a single device, with storage’s being provided within the hypervisor itself as opposed to via a storage virtual machine running alongside other virtual machines.
Virtual SAN is an object-based storage system designed to provide virtual machine–centric storage services and capabilities through a Storage Based Policy Management (SPBM) platform. SPBM and virtual machine storage policies are solutions designed to simplify virtual machine storage placement decisions for vSphere administrators.
Virtual SAN is fully integrated with core vSphere enterprise features such as VMware vSphere High Availability (vSphere HA), VMware vSphere Distributed Resource Scheduler™ (vSphere DRS), and VMware vSphere vMotion®. Its goal is to provide both high availability and scale-out storage functionality. It also can be considered in the context of quality of service (QoS) because virtual machine storage policies can be created to define the levels of performance and availability required on a per–virtual machine basis.

Note![]() This and the remainder of this technology overview has been compiled, directly and indirectly, from resources available on the Virtual SAN resources website, at the following URL: This and the remainder of this technology overview has been compiled, directly and indirectly, from resources available on the Virtual SAN resources website, at the following URL: http://www.vmware.com/products/virtual-san/resources.html.
This and the remainder of this technology overview has been compiled, directly and indirectly, from resources available on the Virtual SAN resources website, at the following URL: This and the remainder of this technology overview has been compiled, directly and indirectly, from resources available on the Virtual SAN resources website, at the following URL: http://www.vmware.com/products/virtual-san/resources.html.
Another highly recommended resource for Virtual SAN administrators will be the forthcoming Essential Virtual SAN (VSAN): Administrator’s Guide to VMware VSAN by Cormac Hogan and Duncan Epping.
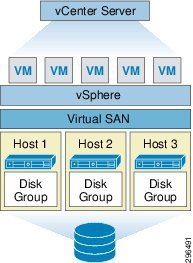
The Virtual SAN Shared Datastore
The Virtual SAN shared datastore is constructed with the minimum three ESXi hosts, each containing at least one SSD and one MD (magnetic drive). Each SSD forms a disk group on the host to which the MD belongs. The VMware virtual machine (VM) files are stored on the MD while the SSD handles the read caching and write buffering. The disk group on each host is joined to a single Network Partition Group, shared and controlled between the hosts. Figure 2-7 shows a Virtual SAN cluster with the minimum configuration.
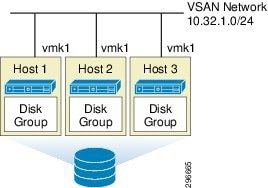
For this white paper, the base Virtual SAN cluster was built with three hosts, each having one disk group comprised of one 400GB SSD and four 1TB MDs, controlled by a RAID controller. Each host had a single VMkernel NIC (vmk1), on the 10.32.1.0/24 network, for Virtual SAN communication on a 10Gb physical NIC. Multicast was enabled as required for Virtual SAN control and data traffic. Figure 2-8 illustrates the particular environment built for this white paper. Details of the physical configuration are in “Architecture Configuration,”.
Figure 2-8 Virtual SAN White Paper Environment
The size and capacity of the Virtual SAN shared datastore are dictated by the number of magnetic disks per disk group in a vSphere host and by the number of vSphere hosts in the cluster. For example, using the configuration of this white paper environment, the cluster is composed of three vSphere hosts, where each host contains one disk group composed of four magnetic disks of 1TB in size each, the total raw capacity of the Virtual SAN shared datastore is 11.9TB after subtracting the metadata overhead capacity.
- One (1) disk group x four (4) magnetic disks x 1TB x three (3) hosts = 11.9TB raw capacity
- 12TB raw capacity – 21GB metadata overhead = 11.9TB usable raw capacity
With the Cisco UCS C240-M3 rack-mount servers being used to build the Virtual SAN cluster, the theoretical maximum datastore capacity is roughly 168TB, according to the following formula:
After the Virtual SAN shared datastore has been formed, a number of datastore capabilities are surfaced up to vCenter Server. These capabilities are based on storage capacity, performance, and availability requirements and are discussed in greater detail in the “Storage Policy Based Management” section of this paper. The essential point is that they can be used to create a policy that defines the storage requirements of a virtual machine.
These storage capabilities enable the vSphere administrator to create virtual machine storage policies that specify storage service requirements that must be satisfied by the storage system during virtual machine provisioning operations. This simplifies the virtual machine provisioning operations process by empowering the vSphere administrator to easily select the correct storage for virtual machines.
Read Caching and Write Buffering
The flash-based device (e.g. SSD) in the Virtual SAN host serves two purposes: caching the reads and buffering the writes coming from the resident VMs. The read cache keeps a cache of commonly accessed disk blocks. This reduces the I/O read latency in the event of a cache hit. The actual block that is read by the application running in the virtual machine might not be on the same vSphere host on which the virtual machine is running.
To handle this behavior, Virtual SAN distributes a directory of cached blocks between the vSphere hosts in the cluster. This enables a vSphere host to determine whether a remote host has data cached that is not in a local cache. If that is the case, the vSphere host can retrieve cached blocks from a remote host in the cluster over the Virtual SAN network. If the block is not in the cache on any Virtual SAN host, it is retrieved directly from the magnetic disks.
The write cache performs as a nonvolatile write buffer. The fact that Virtual SAN can use flash-based storage devices for writes also reduces the latency for write operations.
Because all the write operations go to flash storage, Virtual SAN ensures that there is a copy of the data elsewhere in the cluster. All virtual machines deployed onto Virtual SAN inherit the default availability policy settings, ensuring that at least one additional copy of the virtual machine data is available. This includes the write cache contents.
After writes have been initiated by the application running inside of the guest operating system (OS), they are sent in parallel to both the local write cache on the owning host and the write cache on the remote hosts. The write must be committed to the flash storage on both hosts before it is acknowledged.
This means that in the event of a host failure, a copy of the data exists on another flash device in the Virtual SAN cluster and no data loss will occur. The virtual machine accesses the replicated copy of the data on another host in the cluster via the Virtual SAN network.
Virtual SAN Storage Policy Based Management (SPBM)
All VMs deployed on a Virtual SAN cluster must use a VM Storage Policy and, in the case where there is none administratively defined, the default is applied. VM Storage Policies define the requirements of the application running in the VM from an availability, sizing, and performance perspective. There are five VM Storage Policy requirements in Virtual SAN, presented in Table 2-3 .
Virtual SAN Recommendations and Limits
The following are the limits and recommendations for Virtual SAN at this white paper’s publication date.
- Maximum 32 hosts per Virtual SAN cluster
- Maximum 5 disk groups per host
- Maximum 7 MDs per disk group
- Maximum 1 SSD per disk group
- Each cluster host shares identical hardware configuration
- Each cluster host has like number of disk groups
- SSD-to-MD capacity ratio of 1:10 of the anticipated consumed storage capacity before the Number of Failures to Tolerate (FTT) is considered
- Each cluster host has a single Virtual SAN-enabled VMkernel NIC
Virtual SAN Requirements
An abbreviated listing of the requirements needed for running a Virtual SAN virtual storage environment follows:
- vCenter Server: Minimum version 5.5 Update 1
- vSphere: Minimum version 5.5
- Hosts: Minimum three (3) ESXi hosts
- Disk Controller:
- SAS or SATA HBA or
- RAID controller
- Must function in either pass-through (preferred) or RAID 0 modes
- Hard Disk Drives: Minimum one (1) SAS, NL-SAS, or SATA magnetic hard drive per host
- Flash-Based Devices: Minimum one (1) SAS, SATA, or PCI-E SSD per host
- Network Interface Cards: Minimum one (1) 1Gb or 10Gb (recommended) network adapter per host.
- Virtual Switch: VMware VDS or VSS, or Cisco Nexus 1000v
- VMkernel Network: VMkernel port per host for Virtual SAN communication
Defining Virtual Machine Requirements
When the Virtual SAN cluster is created, the shared Virtual SAN datastore—which has a set of capabilities that are surfaced up to vCenter—is also created.
When a vSphere administrator begins to design a virtual machine, that design is influenced by the application it will be hosting. This application might potentially have many sets of requirements, including storage requirements.
The vSphere administrator uses a virtual machine storage policy to specify and contain the application’s storage requirements in the form of storage capabilities that will be attached to the virtual machine hosting the application; the specific storage requirements will be based on capabilities surfaced by the storage system. In effect, the storage system provides the capabilities, and virtual machines consume them via requirements placed in the virtual machine storage policy.
Distributed RAID
In additional storage environments, redundant array of independent disks (RAID) refers to disk redundancy inside the storage chassis to withstand the failure of one or more disk drives.
Virtual SAN uses the concept of distributed RAID, by which a vSphere cluster can contend with the failure of a vSphere host, or of a component within a host—for example, magnetic disks, flash-based devices, and network interfaces—and continue to provide complete functionality for all virtual machines. Availability is defined on a per–virtual machine basis through the use of virtual machine storage policies.
vSphere administrators can specify the number of host component failures that a virtual machine can tolerate within the Virtual SAN cluster. If a vSphere administrator sets zero as the number of failures to tolerate in the virtual machine storage policy, one host or disk failure can impact the availability of the virtual machine.
Using virtual machine storage policies along with Virtual SAN distributed RAID architecture, virtual machines and copies of their contents are distributed across multiple vSphere hosts in the cluster. In this case, it is not necessary to migrate data from a failed node to a surviving host in the cluster in the event of a failure.
Virtual SAN Storage Objects and Components
While the traditional understanding of a virtual machine is that it is a set of files (.vmx, .vmdk, etc.), because the Virtual SAN datastore is an object datastore, a VM on a Virtual SAN is now made up of a set of objects. For VMs on Virtual SAN there are four kinds of Virtual SAN objects:
- The VM home or “namespace” directory
- A swap object (if the VM is powered on)
- Virtual disks/VMDKs
- Delta-disks created for snapshots (each delta-disk is an object)
Note![]() The VM namespace directory holds all VM files (.vmx, log files, etc.), excluding VM disks, deltas, and swap, all of which are maintained as separate objects. The VM namespace directory holds all VM files (.vmx, log files, etc.), excluding VM disks, deltas, and swap, all of which are maintained as separate objects.
The VM namespace directory holds all VM files (.vmx, log files, etc.), excluding VM disks, deltas, and swap, all of which are maintained as separate objects. The VM namespace directory holds all VM files (.vmx, log files, etc.), excluding VM disks, deltas, and swap, all of which are maintained as separate objects.
Note![]() It is important to understand how objects and components are built and distributed in Virtual SAN because there are soft limitations and exceeding those limitations may impact performance. It is important to understand how objects and components are built and distributed in Virtual SAN because there are soft limitations and exceeding those limitations may impact performance.
It is important to understand how objects and components are built and distributed in Virtual SAN because there are soft limitations and exceeding those limitations may impact performance. It is important to understand how objects and components are built and distributed in Virtual SAN because there are soft limitations and exceeding those limitations may impact performance.
Each object is deployed on Virtual SAN as a distributed RAID tree and each leaf of the tree is said to be a component. The policies relevant to Virtual SAN object and component count and limitations include the Failures-to-Tolerate (FTT) policy and the Stripe-Width policy. If, for example, deploying a VM with a Stripe Width of two means that a RAID-0 stripe would be configured across two magnetic disks for the VM disk. Similarly, if the FTT policy for that VM is configured as one, a RAID-1 mirror of the VM components would be set up across hosts.
Figure 2-9 represents a possible layout for the components in the above scenario. The stripe components form a RAID-0 configuration, which is then mirrored across hosts using a RAID-1 configuration.
Figure 2-9 Sample component layout for VM on Virtual SAN
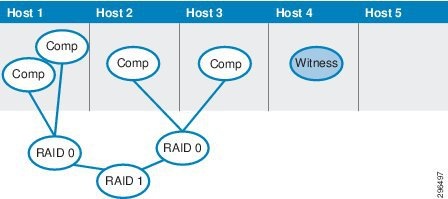
Following are some considerations to keep in mind when working with objects and components:
–![]() Namespace: Every VM has a namespace object, and only one
Namespace: Every VM has a namespace object, and only one
–![]() VMDK: Every VM will have one VMDK object for each attached virtual disk
VMDK: Every VM will have one VMDK object for each attached virtual disk
–![]() Swap: Every powered-on VM will have a swap object
Swap: Every powered-on VM will have a swap object
–![]() Delta-disk: Every VM will have one delta-disk object for each snapshot created
Delta-disk: Every VM will have one delta-disk object for each snapshot created
- Of the four families of objects, only the VMDKs and delta-disks will inherit the StripeWidth policy administratively applied to the VM. Because performance is not a major requirement for the namespace or swap objects, the StripeWidth will always be set to 1.
- Witness components will be created to arbitrate between remaining copies should a failure occur so that two identical copies of data are not activated at the same time. Witnesses are not objects but are components within each object RAID tree. More information on witnesses is provided below.
Note![]() VMware recommends the default settings for NumberOfFailuresToTolerate and StripeWidth. VMware recommends the default settings for NumberOfFailuresToTolerate and StripeWidth.
VMware recommends the default settings for NumberOfFailuresToTolerate and StripeWidth. VMware recommends the default settings for NumberOfFailuresToTolerate and StripeWidth.
Witness Components
As mentioned above, witnesses are components that are deployed to arbitrate between the remaining copies of data should a failure occur within the Virtual SAN cluster, ensuring no split-brain scenarios occur. At first glance, the way witnesses are deployed seems to have no rhyme or reason, but the algorithm governing this mechanism is not very complex and is worth mentioning here.
Witness deployment is not predicated on any FailuresToTolerate or StripeWidth policy setting. Rather, witness components are defined by three names (Primary, Secondary, and Tiebreaker) and are deployed based on the following three rules.
Need at least (2 * FTT) + 1 nodes in a cluster to be able to tolerate FTT number of node / disk failures. If after placing all the data components, we do not have the required number of nodes in the configuration, primary witnesses are on exclusive nodes until there are (2*FTT)+ 1 nodes in the configuration.
Secondary witnesses are created to make sure that every node has equal voting power towards quorum. This is important because every node failure should affect the quorum equally. Secondary witnesses are added so that every node gets equal number of component, this includes the nodes that only hold primary witnesses. So the total count of data component + witnesses on each node are equalized in this step.
If after adding primary and secondary witnesses we end up with even number of total components (data + witnesses) in the configuration then we add one tiebreaker witnesses to make the total component count odd.
Note![]() This is all that will be said about witness functionality here, though some Chapter 4 below demonstrates these three rules in action in deployment examples for this project. This paper is indebted to Rawlinson’s blog post on this topic, from which the three rules were quoted verbatim and to which the reader is encouraged to go to gain an even better understanding. This is all that will be said about witness functionality here, though some Chapter 4 below demonstrates these three rules in action in deployment examples for this project. This paper is indebted to Rawlinson’s blog post on this topic, from which the three rules were quoted verbatim and to which the reader is encouraged to go to gain an even better understanding. http://www.punchingclouds.com/2014/04/01/vmware-virtual-san-witness-component-deployment-logic/
This is all that will be said about witness functionality here, though some Chapter 4 below demonstrates these three rules in action in deployment examples for this project. This paper is indebted to Rawlinson’s blog post on this topic, from which the three rules were quoted verbatim and to which the reader is encouraged to go to gain an even better understanding. This is all that will be said about witness functionality here, though some Chapter 4 below demonstrates these three rules in action in deployment examples for this project. This paper is indebted to Rawlinson’s blog post on this topic, from which the three rules were quoted verbatim and to which the reader is encouraged to go to gain an even better understanding. http://www.punchingclouds.com/2014/04/01/vmware-virtual-san-witness-component-deployment-logic/
Flash-Based Devices in Virtual SAN
Flash-based devices serve two purposes in Virtual SAN. They are used to build the flash tier in the form of a read cache and a write buffer, which dramatically improves the performance of virtual machines. In some respects, Virtual SAN can be compared to a number of “hybrid” storage solutions on the market that also use a combination of flash-based devices and magnetic disk storage to boost the performance of the I/O and that have the ability to scale out based on low-cost magnetic disk storage.
Read Cache
The read cache keeps a cache of commonly accessed disk blocks. This reduces the I/O read latency in the event of a cache hit. The actual block that is read by the application running in the virtual machine might not be on the same vSphere host on which the virtual machine is running.
To handle this behavior, Virtual SAN distributes a directory of cached blocks between the vSphere hosts in the cluster. This enables a vSphere host to determine whether a remote host has data cached that is not in a local cache. If that is the case, the vSphere host can retrieve cached blocks from a remote host in the cluster over the Virtual SAN network. If the block is not in the cache on any Virtual SAN host, it is retrieved directly from the magnetic disks.
Write Cache (Write Buffer)
The write cache performs as a nonvolatile write buffer. The fact that Virtual SAN can use flash-based storage devices for writes also reduces the latency for write operations.
Because all the write operations go to flash storage, Virtual SAN ensures that there is a copy of the data elsewhere in the cluster. All virtual machines deployed onto Virtual SAN inherit the default availability policy settings, ensuring that at least one additional copy of the virtual machine data is available. This includes the write cache contents.
After writes have been initiated by the application running inside of the guest operating system (OS), they are sent in parallel to both the local write cache on the owning host and the write cache on the remote hosts. The write must be committed to the flash storage on both hosts before it is acknowledged.
This means that in the event of a host failure, a copy of the data exists on another flash device in the Virtual SAN cluster and no data loss will occur. The virtual machine accesses the replicated copy of the data on another host in the cluster via the Virtual SAN network.
 Feedback
Feedback