Cisco Network Function Virtualization Infrastructure Overview
Cisco Network Function Virtualization Infrastructure (NFVI) provides the virtual layer and hardware environment in which virtual network functions (VNFs) can operate. VNFs provide well-defined network functions such as routing, intrusion detection, domain name service (DNS), caching, network address translation (NAT), and other network functions. While these network functions require a tight integration between network software and hardware, the use of VNF enables to decouple the software from the underlying hardware.
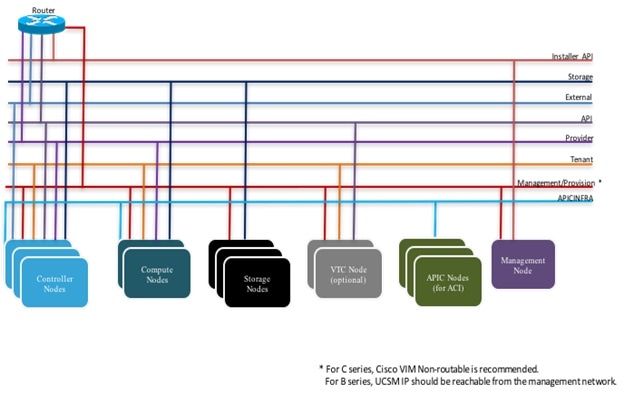
The following figure shows the high level architecture of Cisco NFVI.
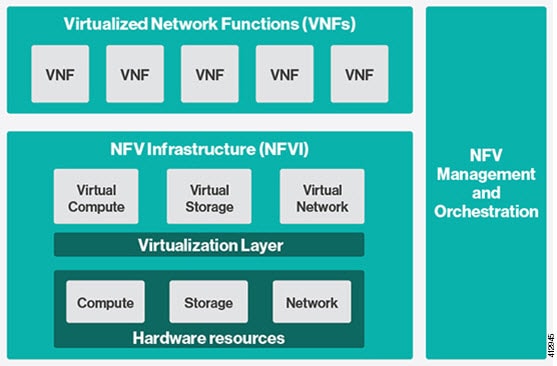
Cisco NFVI includes a virtual infrastructure layer (Cisco VIM) that embeds the Red Hat OpenStack Platform (OSP 13). Cisco VIM includes the Queens release of OpenStack, which is an open source cloud operating system that controls large pools of compute, storage, and networking resources. Cisco VIM manages the OpenStack compute, network, and storage services, and all NFVI management and control functions. Key Cisco NFVI roles include:
-
Control (including Networking)
-
Compute
-
Storage
-
Management (including logging, and monitoring)
Hardware that is used to create the Cisco NFVI pods include a specific combination of the following based on pre-defined BOMs. For more details, contact Cisco VIM Product Management.
-
Cisco UCS® C240 M4/M5: Performs management and storage functions and services. Includes dedicated Ceph (UCS 240-M4 or UCS 240-M5) distributed object store and file system. (Only Red Hat Ceph is supported).
-
Cisco UCS C220/240 M4/M5: Performs control and compute services.
-
HP DL360 Gen9: It is a third-party compute where the control plane is Cisco UCS servers.
-
Cisco UCS 220/240 M4/M5 (SFF): In a Micropod environment, expandable to maximum of 16 computes.
-
Cisco UCS B200 M4 blades: It can be used instead of the UCS C220 for compute and control services. The B200 blades and C240 Ceph server are connected with redundant Cisco Fabric Interconnects managed by UCS Manager.
-
Combination of M5 series servers are supported in M5-based Micropod and VIC/NIC (pure 40G) based Hyper-Converged and Micropod offering.
-
Quanta servers as an alternate to Cisco UCS servers: Use of specific Quanta servers for the installation of the cloud both at the core and edge. An automated install of Central Ceph cluster to the edge pods is supported for Glance image services.
The UCS C240 and C220 servers are of type M4 or M5 Small Form Factor (SFF) models where the nodes can boot off a pair of HDDs or SSD as specified in BOM. Each UCS C240, UCS C220, and UCS B200 have two 10 GE Cisco UCS Virtual Interface Cards.
The B-Series pod consists of Cisco UCS B200 M4 blades for the Cisco NFVI compute and controller nodes with dedicated Ceph on a UCS C240 M4. The blades and Ceph server are connected via redundant fabric interconnects (FIs) managed by Cisco UCS Manager. The Cisco VIM installer performs bare metal installation and deploys OpenStack services using Docker™ containers to allow for OpenStack services and pod management software updates.
The following table shows the functions, hardware, and services managed by Cisco NFVI nodes.
|
Function |
Number |
Hardware |
Services |
|---|---|---|---|
|
Management |
1 |
|
|
|
Control |
3 |
|
|
|
Compute |
2+ |
|
|
|
Storage |
3 or more |
SSD and HDD drives must be in a 1:4 ratio per storage node minimum. Storage node configuration options: Fullon environment::
Micropod/UMHC/NGENAHC environment:
|
|
|
Top of Rack (ToR) |
2 |
Recommended Cisco Nexus 9000 series switch software versions:
Cisco NCS 5500 as ToRs or Cisco Nexus 9000 switches running ACI 3.0 (when ACI is used) |
ToR services
|
 Note |
|
Software applications that manage Cisco NFVI hosts and services include:
-
Red Hat Enterprise Linux 7.6 with OpenStack Platform 13.0—Provides the core operating system with OpenStack capability. RHEL 7.6 and OPS 13.0 are installed on all target Cisco NFVI nodes.
-
Cisco Virtual Infrastructure Manager (VIM)—An OpenStack orchestration system that helps to deploy and manage an OpenStack cloud offering from bare metal installation to OpenStack services, taking into account hardware and software redundancy, security and monitoring. Cisco VIM includes the OpenStack Queens release with more features and usability enhancements that are tested for functionality, scale, and performance.
-
Cisco Unified Management—Deploys, provisions, and manages Cisco VIM on Cisco UCS servers.
-
Cisco UCS Manager—Used to perform certain management functions when UCS B200 blades are installed. Supported UCS Manager firmware versions are 2.2(5a) and above.
-
Cisco Integrated Management Controller (IMC)— Cisco IMC 2.0(13i) or later is supported, when installing Cisco VIM 2.4.
For the Cisco IMC lineup, the recommended version is as follows:
UCS-M4 servers
Recommended: Cisco IMC 2.0(13n) or later. It is also recommended to switch to 3.0(3a) or later for pure intel NIC based pods.
For Cisco IMC 3.x and 4.y lineup, the recommended version is as follows:
UCS-M4 servers
Cisco IMC versions are 3.0(3a) or later, except for 3.0(4a). Recommended: Cisco IMC 3.0(4d).
Expanded support of CIMC 4.0(1a), 4.0(1b), 4.0(1c). You can move to 4.0(2f) only if your servers are based on Cisco VIC.
UCS-M5 servers
We recommend that you use CIMC 3.1(2b) or higher versions. Do not use 3.1(3c) to 3.1(3h), 3.0(4a), 4.0(2c), or 4.0(2d).
Support of CIMC 4.0(4e) or later. We recommend that you use CIMC 4.0(4e).
The bundle version of a minimum of CIMC 4.0 (4d) is needed for Cascade Lake support.
For GPU support, you must ensure that the server is running with CIMC 4.0(2f).
Enables embedded server management for Cisco UCS C-Series Rack Servers. Supports Cisco IMC firmware versions of 2.0(13i) or greater for the fresh install of Cisco VIM. Because of recent security fixes, we recommend you to upgrade Cisco IMC to 2.0(13n) or higher. Similarly, Cisco IMC version of 3.0 lineup is supported. For this, you must install Cisco IMC 3.0 (3a) or above.
The Quanta servers need to run with a minimum version of BMC and BIOS as listed below:
SKU Type
BMC Version
BIOS Version
D52BQ-2U 3UPI (CDC SKU)
4.68.22
3A11.BT17
D52BE-2U (GC SKU)
4.68.22
3A11.BT17
-
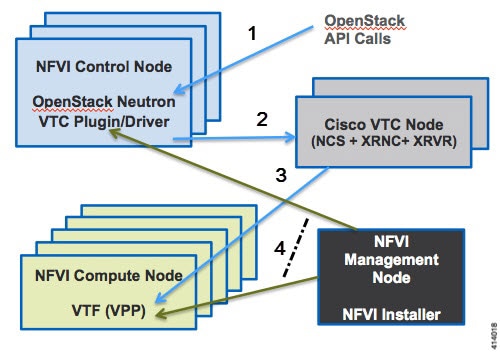
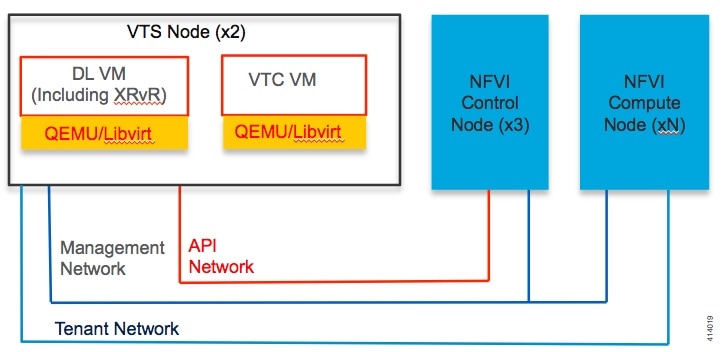
Cisco Virtual Topology System (VTS)—It is an open, overlay management and provisioning system for data center networks. VTS automates DC overlay fabric provisioning for physical and virtual workloads. This is an optional service that is available through Cisco VIM.
-
Cisco Virtual Topology Forwarder (VTF)—Included with VTS. VTF leverages Vector Packet Processing (VPP) to provide high performance Layer 2 and Layer 3 VXLAN packet forwarding.
Two Cisco VNF orchestration and management applications that are used with Cisco NFVI include:
-
Cisco Network Services Orchestrator, enabled by Tail-f—Provides end-to-end orchestration spanning multiple network domains to address NFV management and orchestration (MANO) and software-defined networking (SDN). For information about Cisco NSO, see Network Services Orchestrator Solutions.
-
Cisco Elastic Services Controller—Provides a single point of control to manage all aspects of the NFV lifecycle for VNFs. ESC allows you to automatically instantiate, monitor, and elastically scale VNFs end-to-end. For information about Cisco ESC, see the Cisco Elastic Services Controller Data Sheet.
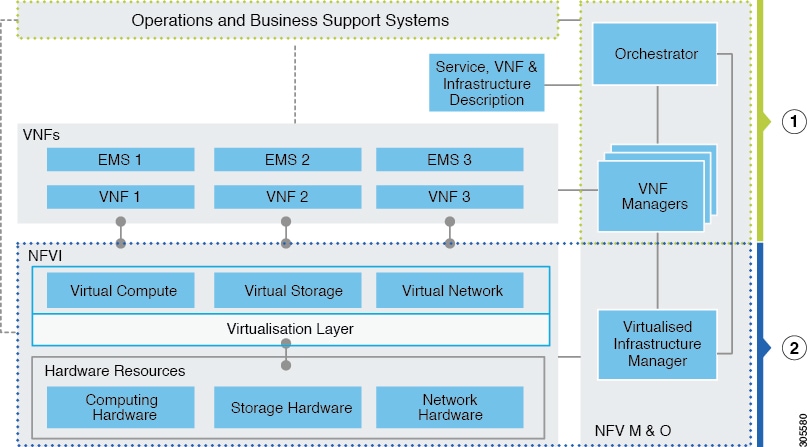
At a high level, the NFVI architecture includes a VNF Manager and NFV Infrastructure.
|
1 |
|
|
2 |
Cisco NFVI:
|
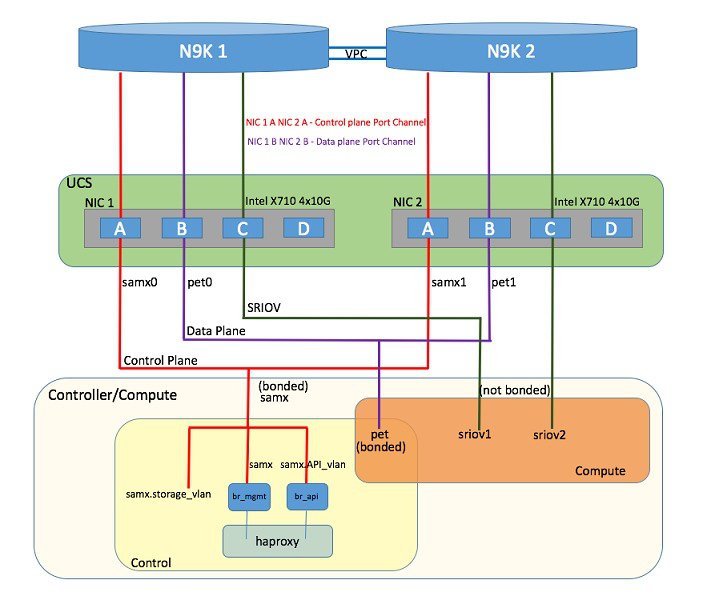
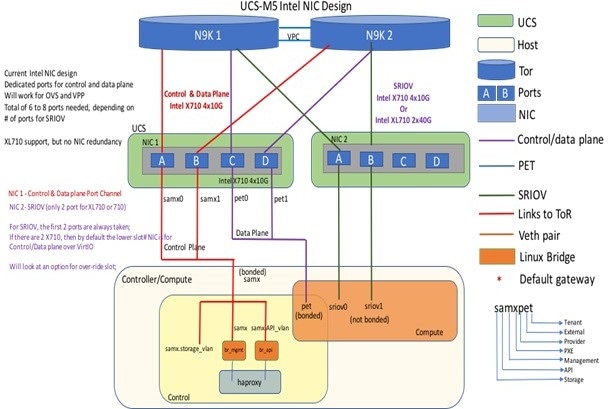
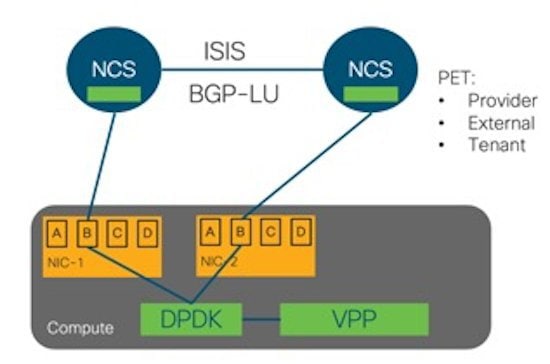
For cloud networking, Cisco NFVI supports Open vSwitch over VLAN as the cloud network solution for both UCS B-series and UCS C-Series pods. Both B-Series and C-Series deployments support provider networks over VLAN.
In addition, with a C-series pod, you can choose:
-
To run with augmented performance mechanism by replacing OVS/LB with VPP/VLAN (for Intel NIC).
-
To have cloud that is integrated with VTC which is an SDN controller option.
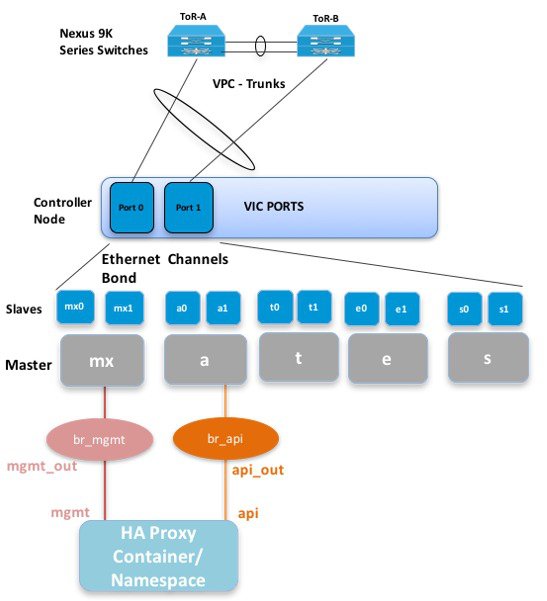
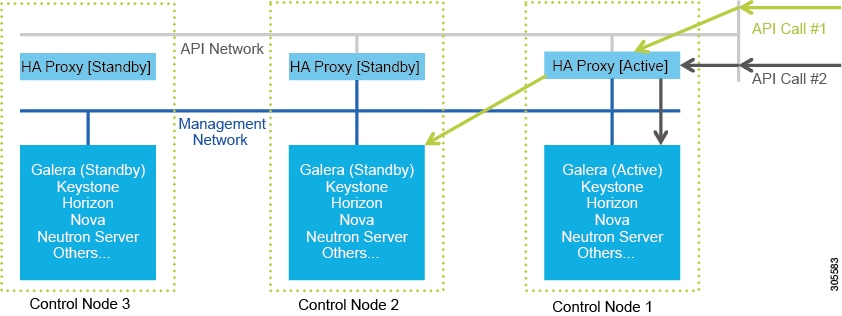
The Cisco NFVI uses OpenStack services running inside containers with HAProxy load balancing and providing high availability to API and management network messaging. Transport Layer Security (TLS) protects the API network from external users to the HAProxy. Cisco VIM installation also includes service assurance, OpenStack CloudPulse, built-in control, and data plane validation. Day two pod management allows you to add and remove both compute and Ceph nodes, and replace the controller nodes. The Cisco VIM installation embeds all necessary RHEL licenses as long as you use the Cisco VIM supported BOM and the corresponding release artifacts.
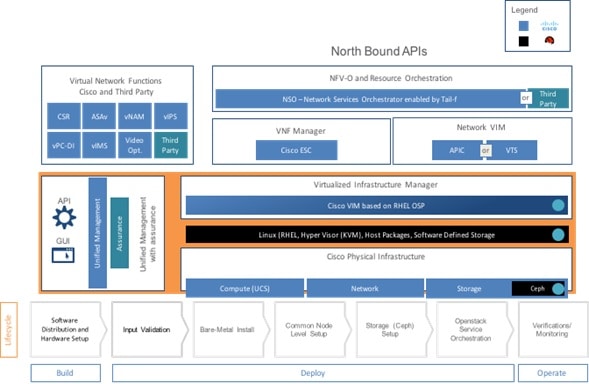
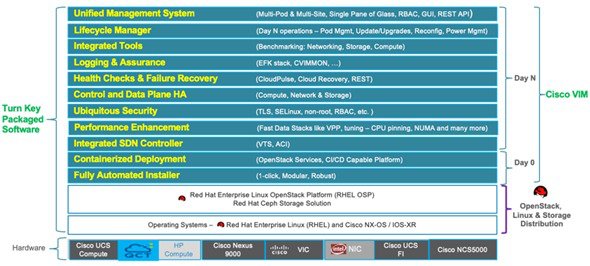
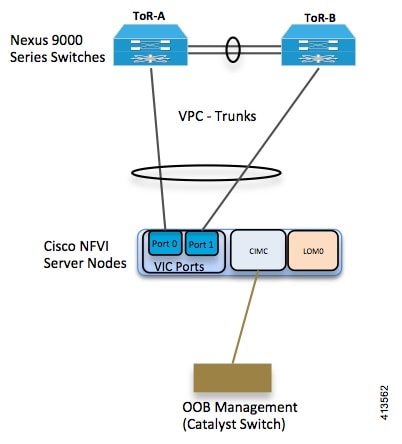
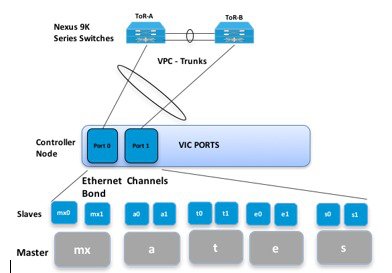
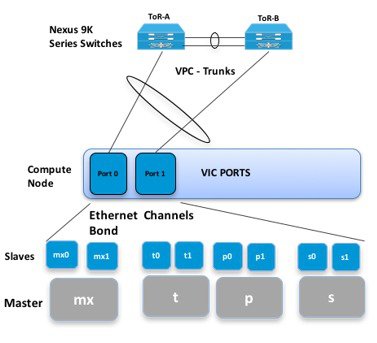
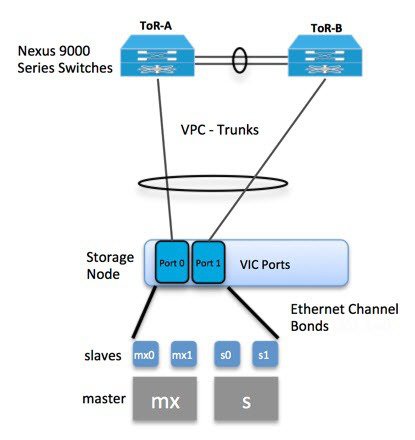
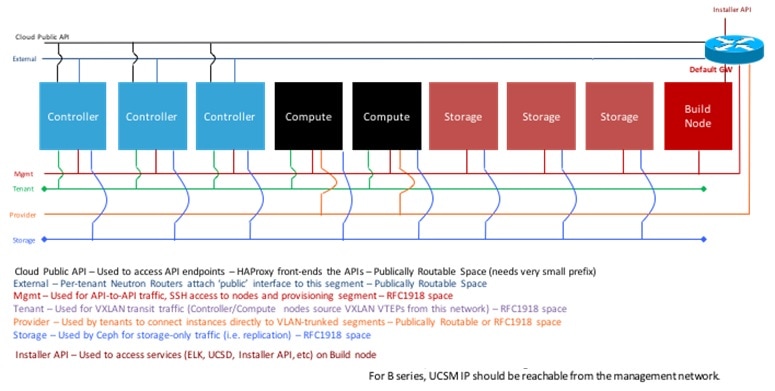
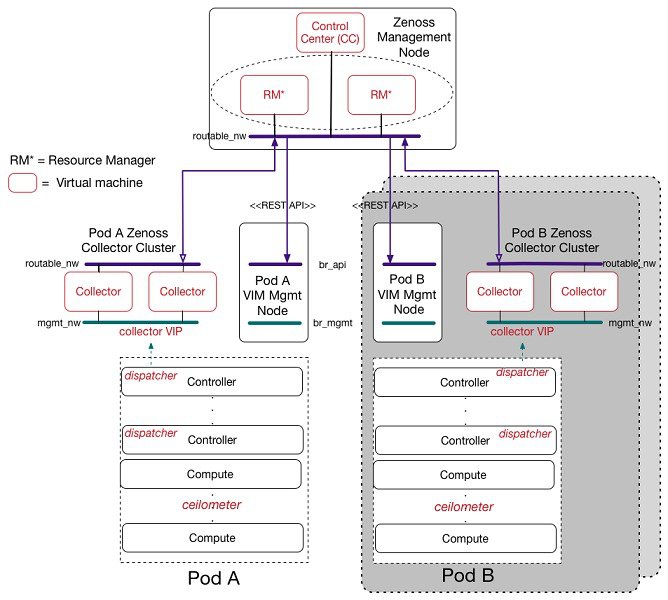
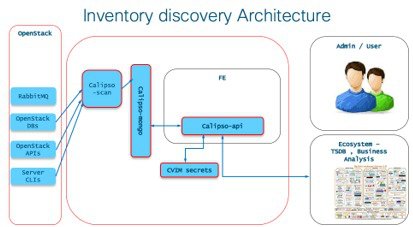
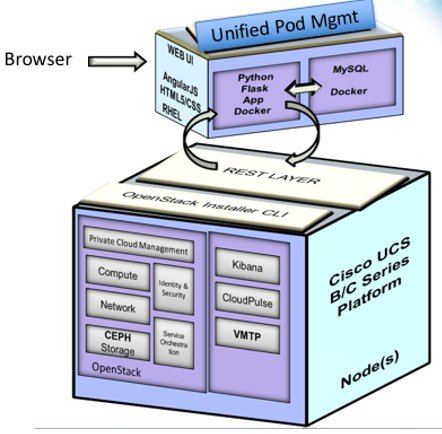
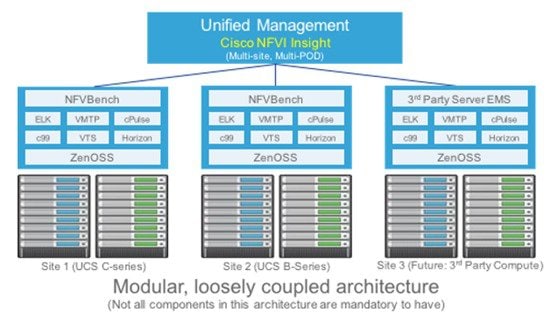
The following illustration shows a detailed view of the Cisco NFVI architecture and the Cisco NFVI installation flow.

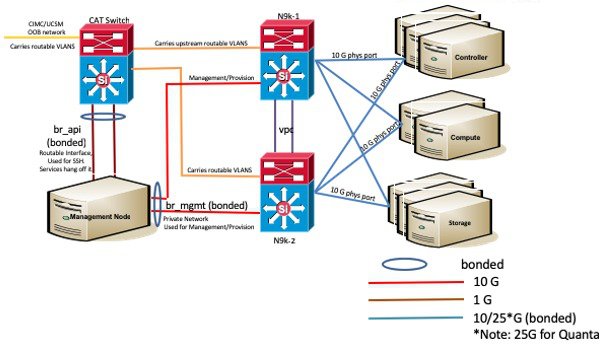
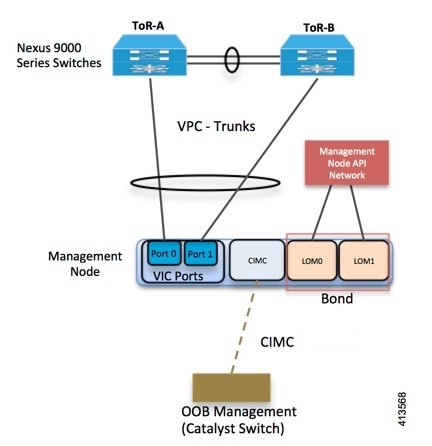
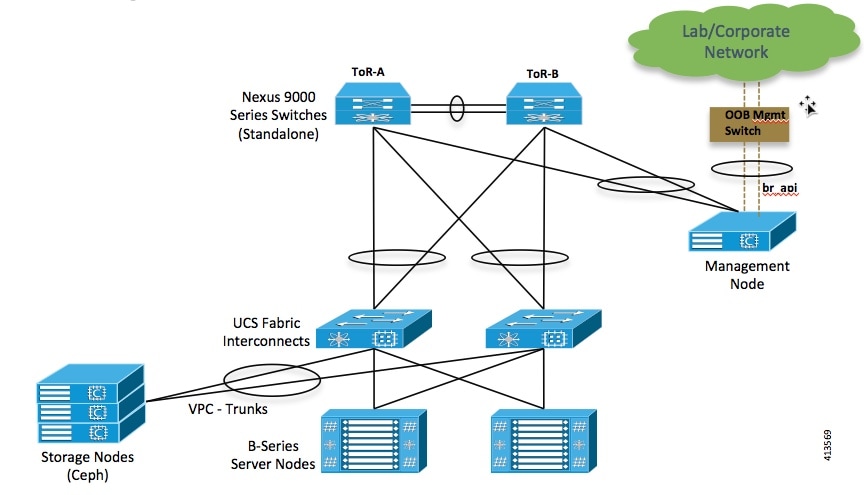
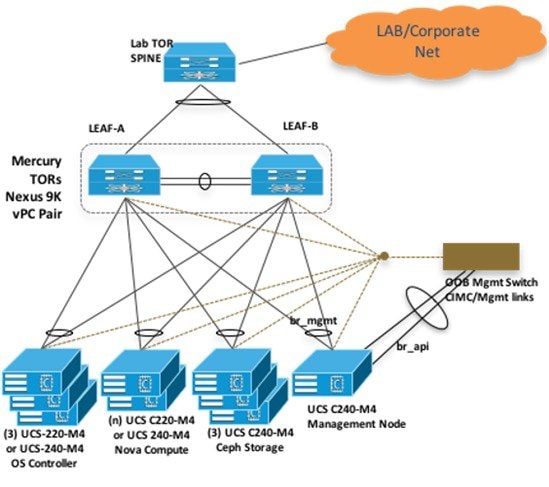



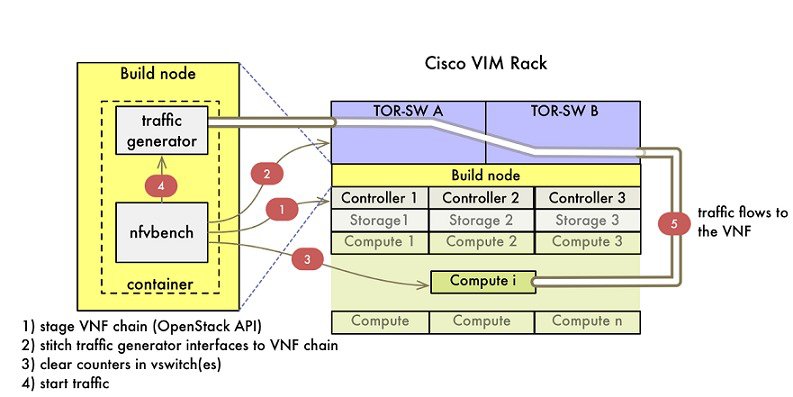





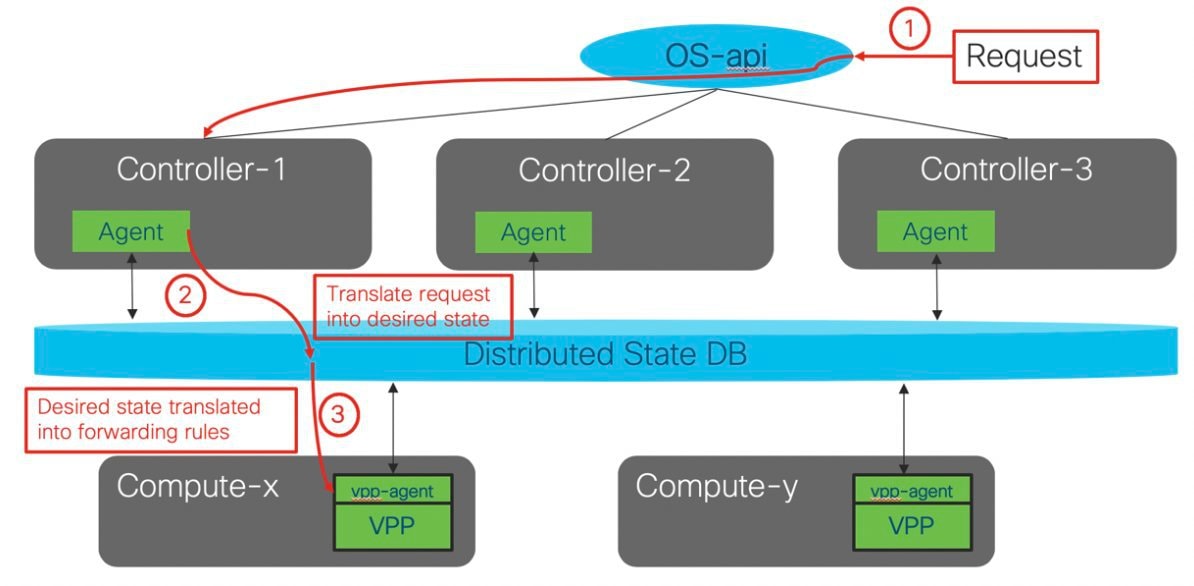
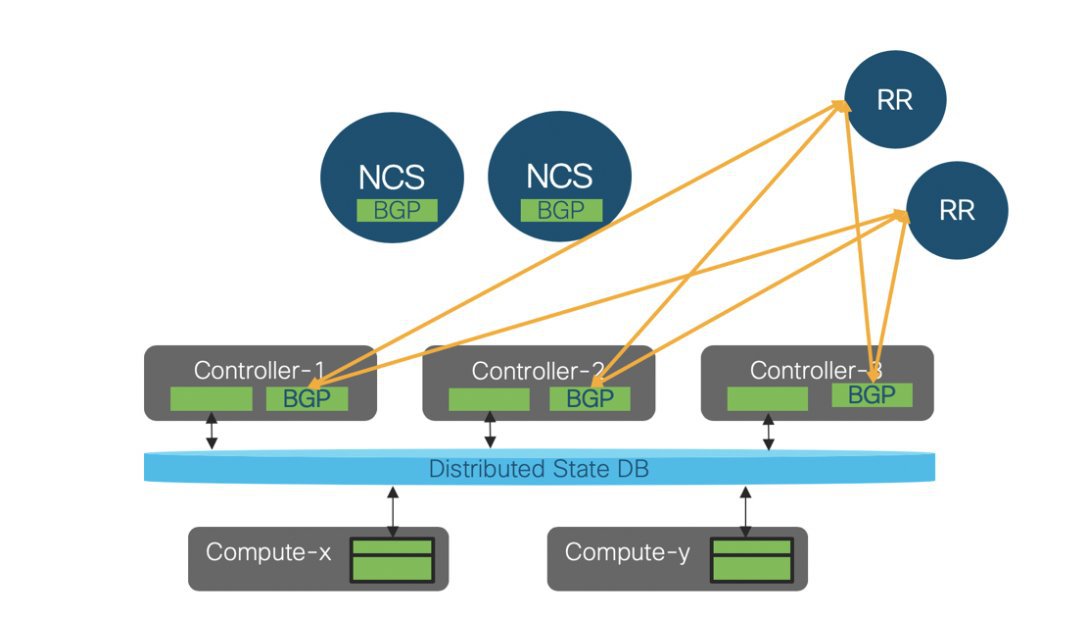
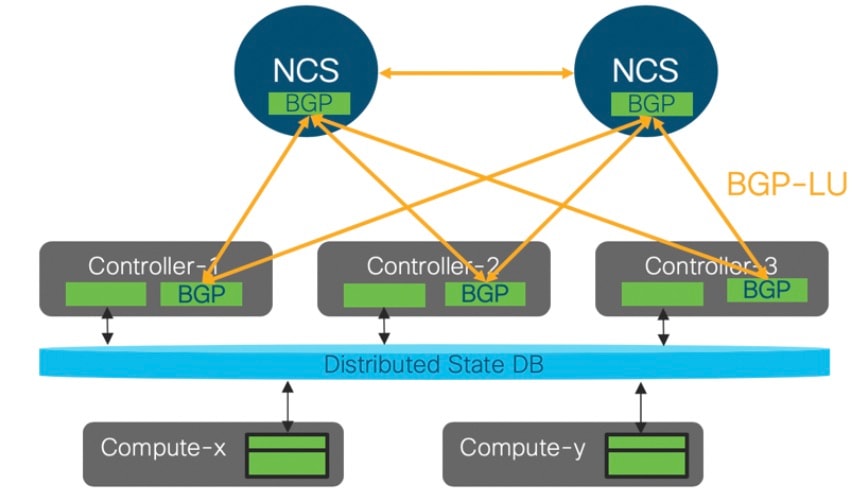
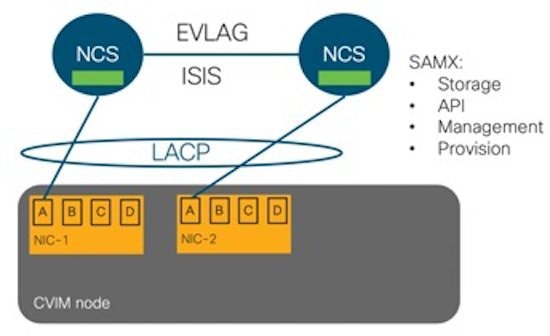
 Feedback
Feedback