Deploy, manage, and optimize your computing resources across hybrid cloud environments faster than you can say "whoa."
All of your apps, none of the complexity
Adopt modern, adaptable computing infrastructure engineered to simplify IT and innovate at the speed of software.
Be ready for tomorrow
Embrace change with confidence knowing your systems and operations can adapt to any application and those yet to come.
Enjoy flexibility and choice
It's time for new ways of working, with an open platform and cloud-agnostic approach. Speed up service delivery, automate repetitive tasks, and harness computing infrastructure that's flexible, not fixed.
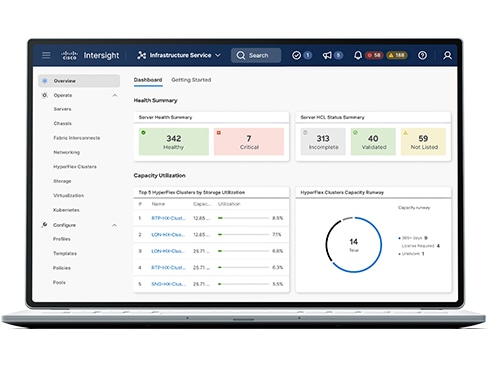
Operate in concert
Give IT ops the instruments to perform in harmony with intelligent visualization, optimization, and orchestration to bring your teams, tools, infrastructure, and apps together.
Explore the portfolio
Servers
Find modular, blade, rack, and storage servers for all your data center needs.
Accelerate your hybrid cloud journey with expert-led Cisco webinars, where you'll learn how to improve your business using the latest trends and product innovations.