
Simplify at scale
Deploy, manage, and optimize your computing resources across hybrid cloud environments faster than you can say "whoa."
Explore the portfolio
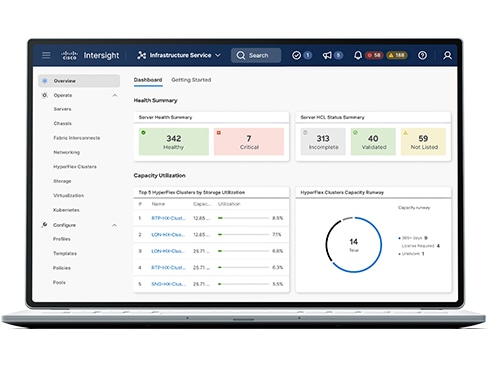
Deploy, manage, and optimize your computing resources across hybrid cloud environments faster than you can say "whoa."
