ここでは、4G CUPS ユーザープレーンの 1:1 冗長性機能の仕組みについて簡単に説明します。
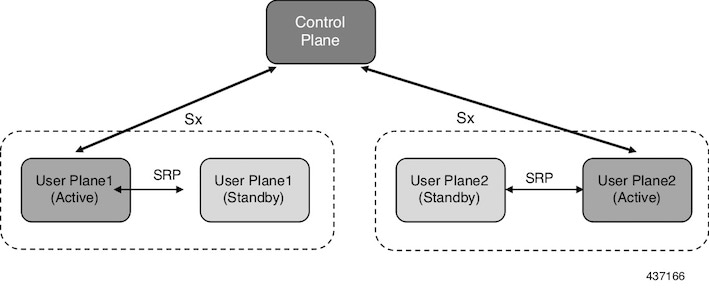
4G CUPS 展開では、次の図に示すように、ICSR フレームワーク インフラストラクチャを活用して UP ノードのチェックポインティングとスイッチオーバーを実現します。アクティブ UP は、UP 間でプロビジョニングされたサービス冗長性プロトコル(SRP)リンクを介して専用のスタンバイ
UP と通信します。
図 1. SRP を使用した UP の 1:1 冗長性
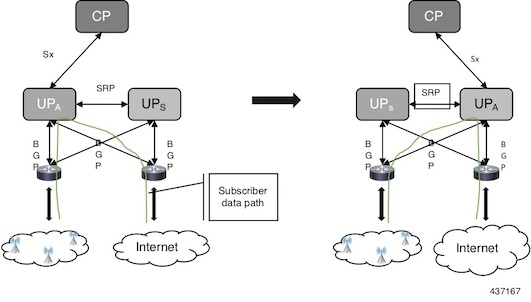
コントロールプレーン(CP)ノードには、UP グループ設定で使用可能なスタンバイ UP 情報がありません。このため、UP の冗長性設定と UP 間のスイッチオーバーイベントは CP には認識されません。
アクティブ UP は、UP で設定された Sx インターフェイスアドレスを介して CP と通信します。スタンバイ UP は、スイッチオーバーイベント中にアクティブに移行する際に、同じ Sx インターフェイスアドレスを引き継ぎます。これは、Sx
インターフェイスが SRP によってアクティブ化され、既存の設定方法に準拠していることを意味します。したがって、UP スイッチオーバーは CP に対して透過的です。
図 2. UP の 1:1 冗長性スイッチオーバー
1:1 の冗長性に完全に準拠するため、CUPS 環境の SRP ベースの ICSR に対する次の依存関係に対応します。
PFD 設定の同期
Sx 関連付けチェックポイント
Sx リンクのモニタリング
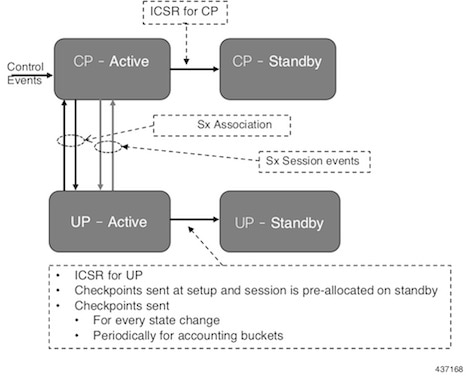
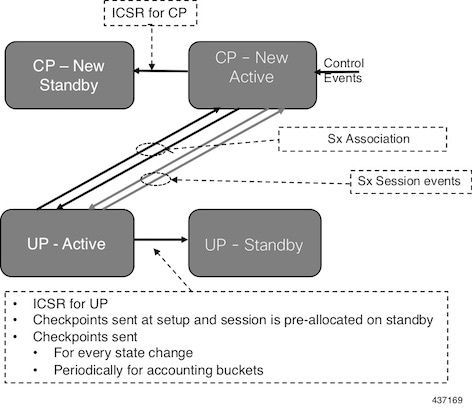
上記の依存関係に加えて、UP は UP ノードに固有のデータ収集およびチェックポイント手順を実装します。たとえば、IP プールチャンクのチェックポインティングなどです。UP は、これらの手順を既存の ICSR チェックポインティング フレームワークに統合します。
図 3. UP の 1:1 冗長性設定時の CP-CP ICSR(CP スイッチオーバー前)
図 4. UP の 1:1 冗長性設定時の CP-CP ICSR(CP スイッチオーバー後)
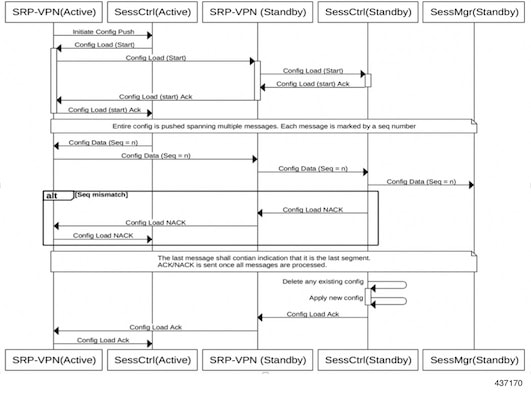
PFD 設定の同期 CP ノードは、パケットフロー記述(PFD)メッセージを介して UP 設定をプッシュします。UP の Sx IP アドレスはアクティブ UP およびスタンバイ UP を介して SRP によってアクティブ化されるため、CP はアクティブ UP からスタンバイ
UP に PFD 設定を送信します。
SRP VPN マネージャが UP 間のトランスポートを提供し、アクティブ UP のセッションコントローラが設定のプッシュをアンカーします。次の図にイベントのシーケンスを示します。
図 5. PFD 設定の同期
アクティブ UP とスタンバイ UP 間の BFD モニター
BFD は、アクティブ UP とスタンバイ UP 間の SRP リンクをモニターして、迅速な障害検出とスイッチオーバーを実現します。スタンバイ UP がこのリンクで BFD 障害を検出すると、アクティブ UP を引き継ぎます。
BFD リンクは、シングルホップまたはマルチホップが可能です。
(注)
アクティブ UP とスタンバイ UP 間の BFD モニターを設定するには、「アクティブ UP とスタンバイ UP 間の BFD モニタリングの設定」を参照してください。
マルチホップ BFD モニタリングの設定例
プライマリ UP:
config
context srp
bfd-protocol
bfd multihop-peer 209.165.200.225 interval 50 min_rx 50 multiplier 20
#exit
service-redundancy-protocol
monitor bfd context srp 209.165.200.225 chassis-to-chassis
peer-ip-address 209.165.200.225
bind address 209.165.200.227
#exit
interface srp
ip address 209.165.200.227 255.255.255.224
#exit
ip route static multihop bfd bfd1 209.165.200.227 209.165.200.225
ip route 192.168.210.0 255.255.255.224 209.165.200.228 srp
#exit
end
バックアップ UP:
config
context srp
bfd-protocol
bfd multihop-peer 209.165.200.227 interval 50 min_rx 50 multiplier 20
#exit
service-redundancy-protocol
monitor bfd context srp 209.165.200.227 chassis-to-chassis
peer-ip-address 209.165.200.227
bind address 209.165.200.225
#exit
interface srp
ip address 209.165.200.225 255.255.255.224
#exit
ip route static multihop bfd bfd1 209.165.200.225 209.165.200.227
ip route 192.168.209.0 255.255.255.224 209.165.200.226 srp
#exit
End
プライマリ UP とバックアップ UP 間のルータ:
config
context one
interface one
ip address 209.165.200.228 255.255.255.224
#exit
interface two
ip address 209.165.200.226 255.255.255.224
#exit
#exit
end
シングルホップ BFD モニタリングの設定例
プライマリ UP:
config
context srp
bfd-protocol
#exit
service-redundancy-protocol
monitor bfd context srp 255.255.255.230 chassis-to-chassis
peer-ip-address 255.255.255.230
bind address 209.165.200.227
#exit
interface srp
ip address 209.165.200.227 255.255.255.224
bfd interval 50 min_rx 50 multiplier 10
#exit
ip route static bfd srp 255.255.255.230
#exit
end
バックアップ UP:
config
context srp
bfd-protocol
#exit
service-redundancy-protocol
monitor bfd context srp 209.165.200.227 chassis-to-chassis
peer-ip-address 209.165.200.227
bind address 255.255.255.230
#exit
interface srp
ip address 255.255.255.230 255.255.255.224
bfd interval 50 min_rx 50 multiplier 10
#exit
ip route static bfd srp 209.165.200.227
#exit
end
VPP モニター
VPP サブシステムに障害が発生すると、SRP VPP モニターはスタンバイ UP へのスイッチオーバーを開始します。
(注)
VPP モニターを設定するには、「アクティブ UP およびスタンバイ UP での VPP モニターの設定」を参照してください。
Sx 関連付けチェックポイント
アクティブ UP が設定済み CP ノードへの Sx 関連付けを開始すると必ず、スタンバイ UP がこのデータのチェックポイントを生成します。これにより、UP スイッチオーバー後も関連付け情報が保持されます。
Sx ハートビートメッセージが送信され、アクティブ UP は連続した UP スイッチオーバー後であっても応答する必要があります。
Sx モニター
UP と CP 間の Sx インターフェイスのモニタリングは重要です。Sx ハートビート機能を有効にすることは、モニター障害の検出に役立つため不可欠です。
(注)
アクティブ UP の Sx インターフェイスは障害を検出し、SRP VPN マネージャに通知して、スタンバイ UP による引き継ぎに向けた UP スイッチオーバーイベントがトリガーされるようにします。
CP Sx ハートビートタイムアウトが、UP Sx ハートビートタイムアウトと UP ICSR スイッチオーバー時間の合計よりも大きくなるようにすることが重要です。これは、UP Sx モニター障害が原因で、UP スイッチオーバー中に CP が
Sx パス障害を検出しないようにするためです。
コントロールプレーンのハートビートタイムアウトの防止
UP ICSR スイッチオーバー中に CP ハートビートがタイムアウトする可能性はわずかながらあります。これを軽減するには、次の手順を実行します。
CP から UP への Sx ハートビートを削除します。
上記が不可能な場合は、CP から UP への Sx ハートビートに複数の再試行タイムアウトを設けるようにします。また、この再試行回数が UP Sx ハートビートタイムアウトと UP ICSR スイッチオーバー時間の合計よりも大きくなるようにします。
次に例を示します。
A = CP ハートビート間隔(sx-protocol Heartbeat interval )
B = CP ハートビートの最大再送信回数(sx-protocol Heartbeat max-retransmissions )
C = CP ハートビート再送信タイムアウト(sx-protocol Heartbeat retransmission-timeout )
D = UP ハートビート間隔(sx-protocol Heartbeat interval )
E = UP ハートビートの最大再送信回数(sx-protocol Heartbeat max-retransmissions )
F = UP ハートビート再送信タイムアウト(sx-protocol Heartbeat max-retransmissions )
G = スイッチオーバー時間(BGP ルートコンバージェンス時間を含む)
したがって、Sx モニター障害スイッチオーバーを成功させるための式は次のようになります。
B * C > D + ( E * F ) + G
値の例:
CP:
A: sx-protocol heartbeat interval 60
B:sx-protocol heartbeat max-retransmissions 10
C:sx-protocol heartbeat retransmission-timeout 10
UP:
D: sx-protocol heartbeat interval 30
E: sx-protocol heartbeat max-retransmissions 3
F: sx-protocol heartbeat retransmission-timeout 3
BGP:
G:ルートコンバージェンス時間の例 = 30 秒
したがって、B * C > D + ( E * F ) + G
=> 10 * 10 > 30 + ( 3 * 3 ) + 30
=> 100 > 69
B の最大値は 15 で、C の最大値は 20 です。したがって、Sx モニター障害検出と UP スイッチオーバー( D +( E * F )+ G )を設定して、15 * 20 = 300 秒(5 分)の最大遅延に耐えられるようにします。
BGP ルートコンバージェンス時間(G)を最小限に抑えるには、BFD フェールオーバーを使用して BGP を実行します。
Sx モニターを設定するには、「アクティブ UP およびスタンバイ UP での Sx モニタリングの設定」を参照してください。
スタンバイ UP 自体に CP との独立した接続はありません。アクティブ UP の Sx コンテキストがスタンバイ UP に複製され、SRP スイッチオーバー時のテイクオーバーの準備が整います。これは、Sx モニター障害のためにアクティブ UP
がスタンバイに切り替わった場合、新しいスタンバイは UP から CP へのリンクが機能しているかどうかを把握できないことを意味します。新しいアクティブ UP での Sx モニター障害が原因で、新しいスタンバイ UP が再びアクティブ状態にスイッチバックされないようにするには、新たな
monitor sx disallow-switchover-on-peer-monitor-fail
Sx モニタリング障害が原因でシャーシがスタンバイになった後、Sx UP チェックポイントが新しいアクティブ UP から受信されても、Sx 障害ステータスはリセットされません。これは、前回のスイッチオーバーを引き起こしたそもそもの原因が Sx
モニター障害であった場合に、Sx モニター障害によって、再び新しいアクティブの計画外のスイッチバックが起こるのを防ぐためです。これにより、CP のダウン時に、連続したピンポン方式のスイッチオーバーが起こるのを防ぎます。Sx モニター障害ステータスは、ネットワーク接続が正常であるという確信が得られたら、オペレータが手動でリセットする必要があります。リセットするには、スタンバイシャーシで新しい
srp reset-sx-fail
BGP モニター
次の図に示すように、UP(Gi 側と Gn 側の両方)からネクストホップルータの BGP ピアモニターとピアグループモニターを設定します。これは既存の ICSR 設定です。BGP は、迅速な BGP ピア障害の検出のため、BFD によるサポートと併せて実行できます。
図 6. BGP ピアグループと回送
BGP モニタリングを設定し、BPG モニタリング障害にフラグを設定するには、BGP モニタリング障害のフラグ付け を参照してください。
UP セッションチェックポイント
アクティブシャーシは、次のシナリオで、UP データのコレクションをチェックポイントとしてピアスタンバイシャーシに送信します。
新しいコールのセットアップ時
コールの状態が変化するたびに
アカウンティングバケット用に定期的に
これらのチェックポイントを受信すると、スタンバイシャーシはデータに基づいて動作し、コールレベルまたはノード/インスタンスレベルで必要な情報を更新します。
VPN IP プールのチェックポイント
PFD 設定メッセージとともに、CP は IP プール割り当てを各 UP に送信します。VPN マネージャは、UP でこのメッセージを受信し、SRP が設定されている場合、スタンバイ UP で同じ情報を使ってチェックポイントを生成します。
IP プール情報は、SRP VPNMGR の再起動中、および SRP リンクのダウンおよびアップシナリオ中にも送信されます。
スイッチオーバーの前に、スタンバイに IP プール情報が存在することを検証することが重要です。IP プール情報が存在しない場合、ルートアドバタイズメントができないため、トラフィックは UP に到達しません。
外部監査と PFD 設定監査のインタラクション
アクティブ UP は、外部監査と PFD 設定監査のインタラクションを実行します。セッションマネージャが PFD 設定監査の開始通知と完了通知を受け取ります。PFD 設定監査の進行中は、セッションマネージャは外部監査を開始しません。外部監査の進行中に
PFD 設定監査の開始通知が届いた場合、セッションマネージャは PFD 設定監査の完了後に外部監査を再開するようにフラグを立てます。PFD 監査の進行中に外部監査が発生しても目的を達成できないため、外部監査の再開が必要です。
ユーザープレーンのゼロアカウンティング損失
アカウンティングデータ/課金情報の損失が 18 秒より小さくなるよう、ゼロアカウンティング損失機能がユーザープレーン(UP)に実装されます。この時間は、アクティブ UP からスタンバイ UP へのデフォルトチェックポイント時間、または設定されるアカウンティング
チェックポイント時間のデフォルトチェックポイント時間です。
UP でのこの変更は、Gz、Gy、VoGx、および RADIUS URR をサポートするためです。ゼロアカウンティング損失/URR データカウンタ損失では、計画的スイッチオーバーのみがサポートされます。この機能は、現行の ICSR フレームワークや、チェックポイントの生成およびリカバリ方法には影響しません。
Sx 使用状況レポートは、シャーシが [pending active] 状態から [Active] になるまでブロックされます。
UP セッション回復のための早期 PDU リカバリ
早期 PDU リカバリ機能は、これまでのセッションリカバリ機能が抱えていた、リカバリ対象として選択された CRR に優先順位付けが行われないという制限を克服します。これまでは、すべての CRR が AAAMgr から取得され、コールが順番に回復されていました。すべての
CRR を取得するのにかかる時間が、セッションリカバリ中に認識される遅延の主な要因でした。障害が発生した際に、セッションマネージャに多数のセッションがあると、遅延が非常に長くなることがありました。また、コールのリカバリに特定の順序がないため、アクティブセッションよりも前にアイドルセッションが回復されることもありました。
(注)
早期 PDU リカバリ機能は、最大 5% のセッションを回復できます。
リカバリ中のセッションの優先順位付け
このリリース以前は、セッションリカバリ機能はリカバリ対象として選択されたセッションに優先順位を付けず、コールリカバリリスト内のすべてのコールをループ処理し、セッションリカバリがトリガーされると順番に回復していました。
リカバリにおけるセッションの優先順位付けの一環として、優先コールのみを対象に別途スキップリストを保持します。該当するレコードがループ処理によらず、AAAMgr からすぐに送信できるようにするためです。その結果、優先コールの迅速なリカバリとデータ停止時間の短縮につながります。
ユーザープレーンには、優先セッションと通常セッションの 2 種類のセッションがあります。セッションが優先セッションかどうかは、コントロールプレーンから受信したメッセージの優先順位フラグに基づいて判別され、優先セッションがまず回復され、その後に通常のコールが続きます。
これらの優先セッションは、早期 PDU 処理でも優先されます。通常コールの早期 PDU リカバリは、すべての優先セッションのリカバリが完了してはじめて開始されます。
クリティカルフラッシュ(GR)の場合、まず優先セッションのチェックポイントが送信され、その後に通常のコールが送信されます。スイッチオーバー中は、すべてのコール(通常コールと優先コールの両方)のデータが許可されます。
(注)
コントロールプレーンがすべてのコールに優先順位フラグを設定します。ユーザープレーンは、コントロールプレーンから受信した優先コールの詳細を、セッションの優先順位付け機能に使用します。



 フィードバック
フィードバック