Cisco UCS Manager B シリーズ トラブルシューティング ガイド
偏向のない言語
この製品のマニュアルセットは、偏向のない言語を使用するように配慮されています。このマニュアルセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザーインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブランゲージに対する取り組みの詳細は、こちらをご覧ください。
翻訳について
このドキュメントは、米国シスコ発行ドキュメントの参考和訳です。リンク情報につきましては、日本語版掲載時点で、英語版にアップデートがあり、リンク先のページが移動/変更されている場合がありますことをご了承ください。あくまでも参考和訳となりますので、正式な内容については米国サイトのドキュメントを参照ください。
- Updated:
- 2017年6月27日
章のタイトル: サーバのハードウェア問題のトラブルシューティング
目次
- サーバのハードウェア問題のトラブルシューティング
- 診断ボタンと LED
- DIMM メモリの問題
- 既知の DIMM メモリに関する問題
- Cisco UCS Manager GUI で DIMM が正しくレポートされない
- BMC のリセットと DIMM エラーのクリア
- Cisco UCS Manager で有効なメモリが正しくレポートされない
- Cisco UCS Manager でメモリが誤って報告される
- 1 つの DIMM により、その他の DIMM が不良とマークされ POST が失敗する
- DIMM エラーのトラブルシューティング
- DIMM の正しい取り付け
- Cisco UCS Manager CLI を使用した DIMM エラーのトラブルシューティング
- Cisco UCS Manager GUI を使用した DIMM エラーのトラブルシューティング
- DIMM の低下エラーのトラブルシューティング
- 動作不能な DIMM エラーのトラブルシューティング
- DIMM の問題に関する推奨される解決策
- CPU の問題
- CLI を使用した CPU の問題のトラブルシューティング
- GUI を使用した CPU の問題のトラブルシューティング
- CPU の問題に関する推奨される解決策
- CPU CATERR の詳細
- ディスク ドライブと RAID に関する問題
- RAID コントローラ
- Quiet Boot のディセーブル化
- ROM ベースのコントローラ ユーティリティへのアクセス
- RAID コントローラと LSI ユーティリティのマニュアル
- UCS ソフトウェア バージョン 1.4(1) を使用した RAID クラスタの移動
- UCS ソフトウェア バージョン 1.4(2) 以降を使用した RAID クラスタの移動
- B200 M3 サーバ間での RAID クラスタの移動
- RAID クラスタ内の障害の発生したドライブの交換
- アダプタの問題
- アダプタに関する既知の問題
- CLI を使用したアダプタ エラーのトラブルシューティング
- GUI を使用したアダプタ エラーのトラブルシューティング
- アダプタの問題に関する推奨される解決策
- 電源の問題
- Cisco UCS B440 サーバの FET 障害のトラブルシューティング
- Cisco TAC に連絡するときに必要となる情報
- B シリーズ サーバの関連資料
この章の内容は、次のとおりです。
- 診断ボタンと LED
- DIMM メモリの問題
- CPU の問題
- ディスク ドライブと RAID に関する問題
- アダプタの問題
- 電源の問題
- Cisco TAC に連絡するときに必要となる情報
- B シリーズ サーバの関連資料
診断ボタンと LED
ブレードの起動時に、POST 診断によって CPU、DIMM、HDD、およびアダプタ カードがテストされます。 エラー通知がある場合は、Cisco UCS Manager に送信されます。 通知はシステム エラー ログ(SEL)または show tech-support コマンド出力で確認できます。 エラーが検出されると、障害が発生したコンポーネントの横にある LED がオレンジに点灯します。 実行時に、ブレード BIOS、コンポーネント ドライバ、および OS によってハードウェアの障害がモニタされます。 修正できないエラーまたは規定値を超える修正できるエラー(ホスト ECC エラーなど)が発生すると、ハードウェアのコンポーネントの診断 LED がオレンジに点灯します。
LED の状態は保存されます。 シャーシからブレードを取り外すと、LED の値は最大 10 分間継続されます。 マザーボードの LED 診断ボタンを押すと、コンポーネントに障害が発生していることを示す LED が最大 30 秒間点灯します。 シャーシにブレードを取り付け直して起動すると、LED の障害値がリセットされます。
DIMM 挿入エラーが検出されると、ブレードの検出に失敗する場合があり、エラーはサーバの POST 情報でレポートされます。 これらのエラーは、Cisco UCS Manager CLI または Cisco UCS Manager GUI で確認できます。 ブレード サーバに DIMM を取り付けるときは、特定のルールに従う必要があります。 このルールはブレード サーバのモデルによって異なります。 ルールについてはブレード サーバの各マニュアルを参照してください。
HDD ステータス LED は HDD の前面にあります。 CPU、DIMM、またはアダプタ カードで障害が発生すると、サーバ ヘルス LED は、軽微な障害ではオレンジに点灯し、重大な障害ではオレンジに点滅します。
DIMM メモリの問題
DIMM メモリに問題が発生すると、サーバの起動に失敗したり、サーバがその能力以下で動作したりする場合があります。 DIMM の問題が疑われる場合は、次の内容を検討します。
- システムでサポートされる DIMM は、シスコによりテストされ、シスコの基準を満たし、シスコにより販売される DIMM のみです。 サードパーティ製の DIMM はサポートされません。このような DIMM が存在する場合、これらの DIMM をシスコが販売する DIMM に交換してから、問題のトラブルシューティングを続行してください。
- 不具合がある DIMM が、使用しているサーバのモデルでサポートされているかどうかを確認します。 サーバの取り付けおよびサービス ノートを参照して、サーバ、CPU、および DIMM を正しく組み合わせて使用しているかどうかを確認します。
- 不具合がある DIMM がスロットに確実に装着されていることを確認します。 DIMM を取り外してからもう一度装着します。
- すべての Cisco サーバには必須または推奨の DIMM 取り付け順序があります。 サーバの取り付けおよびサービス ノートを参照して、所定のサーバ タイプに対して DIMM を適切に追加していることを確認します。
- 多くの DIMM は、2 枚のペアで販売されています。 これらは、2 枚を対にして同時に追加することを想定しています。 このペアを個別に使用すると、メモリの問題が発生する可能性があります。
- 交換用の DIMM の最大速度が以前に取り付けられていたメモリの速度より遅い場合、サーバ内のすべての DIMM の速度が低下するか、場合によっては完全に動作しなくなります。 サーバ内の DIMM はすべて同じタイプである必要があります。
- DIMM の数およびサイズは、サーバ内のすべての CPU について同一である必要があります。 DIMM の構成に不一致があると、システムのパフォーマンスが低下する場合があります。
Cisco UCS Manager GUI で DIMM が正しくレポートされない
Cisco UCS Manager CLI には障害が表示されなくても、Cisco UCS Manager GUI では誤って「inoperable memory」がレポートされる場合があります。 この問題は、Cisco UCS Manager Release1.0(1e) の実行時に発生する可能性があります。
Cisco UCS Manager Release1.0(2d) またはそれ以降のリリースにアップグレードしてください。 アップグレードできない場合は、メモリに問題がないことを確認して、次の CLI コマンドを順番に入力してください(ここで、x はシャーシ番号、y はサーバ番号、z はメモリ アレイ ID 番号です)。
BMC のリセットと DIMM エラーのクリア
Cisco UCS Manager で、修正可能な DIMM エラーによって DIMM が「低下状態」として報告されますが、DIMM はブレード上の OS で引き続き使用可能な状態です。
この問題を修正するには、次のコマンドを使用して BMC から SEL ログをクリアした後、影響を受けるブレードの BMC をリブートするか、または単にシャーシからブレード サーバを取り外して装着し直します。
次に、サーバ x/y 上の BMC から SEL ログをリセットする例を示します。
SAM-FCS-A# scope server x/y UCS-A /chassis/server # scope bmc UCS-A /chassis/server/bmc # reset UCS-A /chassis/server/bmc* # commit-buffer
Cisco UCS Manager で有効なメモリが正しくレポートされない
Cisco UCS Manager Release 1.0(1e) の実行時に、Cisco UCS Manager は SMBIOS テーブルを正しく読み取らず、このテーブルの読み取りを行うためにサーバのリブートが必要となる場合があります。
Cisco UCS Manager Release 1.2(0) 以降のリリースにアップグレードしてください。
Cisco UCS Manager でメモリが誤って報告される
メモリ アレイに、システム ボード上の物理実装より多くのソケットが表示されます。
Cisco UCS Manager Release 1.0(2j) 以降にアップグレードしてください。
1 つの DIMM により、その他の DIMM が不良とマークされ POST が失敗する
サーバが起動サイクルを完了せず、FSM が 54% で止まります。
Cisco UCS Manager Release 1.2.(1b) 以降のリリースにアップグレードします。
DIMM の正しい取り付け
DIMM が正しく取り付けられていることを確認します。
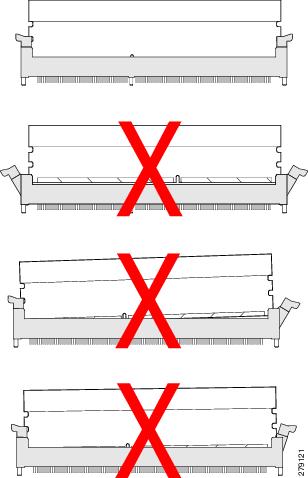
次の図に示す最初の例では、DIMM が正常に挿入され、固定されています。 少量のほこりによっていずれかの接点が塞がれていない限り、この DIMM は正常に機能します。 2 番目の例は、DIMM の向きがスロットのキーの向きと合っていない場合を示しています。 DIMM はこの方向に挿入することはできないため、スロットに合うように向きを変える必要があります。 3 番目の例では、DIMM の左側は正しく装着され、ラッチがしっかりとかかっていますが、右側はスロットにわずかに接触しているだけで、ラッチが DIMM のノッチに固定されていません。 4 番目の例では、左側はしっかりと挿入されて固定されていますが、右側は挿入が不完全で、ラッチがしっかりと固定されていません。
Cisco UCS Manager CLI を使用した DIMM エラーのトラブルシューティング
Cisco UCS Manager CLI でメモリ情報を確認して、発生する可能性のある DIMM エラーを識別します。
次に、Cisco UCS Manager CLI を使用してメモリ情報を確認する例を示します。
UCS-A# scope server 1/5
UCS-A /chassis/server # show memory detail
Server 1/5:
Array 1:
CPU ID: 1
Current Capacity (GB): 393216
Error Correction: Undisc
Max Capacity (GB): 393216
Max Devices: 48
Populated: 48
DIMMS:
ID 1:
Location: DIMM_A0
Presence: Equipped
Overall Status: Operable
Operability: Operable
Visibility: Yes
Product Name: 8GB DDR3-1333MHz RDIMM/PC3-10600/dual rank 2Gb DRAM
PID: N01-M308GB2
VID: V01
Vendor: 0xCE00
Vendor Description: Samsung Electronics, Inc.
Vendor Part Number: M393B1K70BH1-CH9
Vendor Serial (SN): 0x46185EC2
HW Revision: 0
Form Factor: Dimm
Type: Other
Capacity (MB): 8192
Clock: 1067
Latency: 0.900000
Width: 64
.
.
.
UCS-A /chassis/server # show memory-array detail
Memory Array:
ID: 1
Current Capacity (GB): 384
Max Capacity (GB): 384
Populated: 48
Max Devices: 48
Error Correction: Undisc
Product Name:
PID:
VID:
Vendor:
Serial (SN):
HW Revision: 0
Threshold Status: N/A
Power State: N/A
Thermal Status: N/A
Voltage Status: N/A
UCS-A /chassis/server # scope memory-array 1
UCS-A /chassis/server/memory-array # show stats
Memory Array Env Stats:
Time Collected: 2011-09-27T20:15:52.858
Monitored Object: sys/chassis-1/blade-5/board/memarray-1/array-env-stats
Suspect: No
Input Current (A): 62.400002
Thresholded: 0
Memory Error Stats:
Time Collected: 2011-09-27T20:15:43.821
Monitored Object: sys/chassis-1/blade-5/board/memarray-1/mem-1/error-stats
Suspect: No
Address Parity Errors: 0
Mismatch Errors: 0
Ecc Multibit Errors: 0
Ecc Singlebit Errors: 0
Thresholded: 0
Time Collected: 2011-09-27T20:15:43.821
Monitored Object: sys/chassis-1/blade-5/board/memarray-1/mem-2/error-stats
Suspect: No
Address Parity Errors: 0
Mismatch Errors: 0
Ecc Multibit Errors: 0
Ecc Singlebit Errors: 0
Thresholded: 0
Time Collected: 2011-09-27T20:15:43.821
Monitored Object: sys/chassis-1/blade-5/board/memarray-1/mem-3/error-stats
Suspect: No
Address Parity Errors: 0
Mismatch Errors: 0
Ecc Multibit Errors: 0
Ecc Singlebit Errors: 0
Thresholded: 0
.
.
.
UCS-A /chassis/server/memory-array #
Cisco UCS Manager GUI を使用した DIMM エラーのトラブルシューティング
Cisco UCS Manager GUI を使用して、発生している DIMM エラーの種類を特定できます。
DIMM の低下エラーのトラブルシューティング
修正可能なエラーのある DIMM はディセーブルにならず、OS で利用できます。 合計メモリと実効メモリは同じです(メモリのミラーリングが考慮されます)。 これらの修正可能なエラーは、Cisco UCS Manager において、低下としてレポートされます。
前述の情報に一致する修正可能なエラーがレポートされている場合、その問題は、ブレード サーバを装着し直したり、リセットしたりするのではなく、BMC をリセットすることによって修正できます。 次の Cisco UCS Manager CLI コマンドを使用します。
 (注) |
BMC のリセットは、ブレード上で実行されている OS に影響を及ぼしません。 |
次の例では、BMC をリセットする方法を示します。
UCS1-A# scope server x/y UCS1-A /chassis/server # scope bmc UCS1-A /chassis/server/bmc # reset UCS1-A /chassis/server/bmc* # commit-buffer
動作不能な DIMM エラーのトラブルシューティング
修正不可能なエラーが発生している DIMM はディセーブルになり、そのメモリはサーバの OS から認識されません。 システムが稼働しているときに DIMM で障害が発生した場合、OS が予期せずクラッシュする可能性があります。 修正不可能な DIMM エラーの場合、DIMM は動作不能として Cisco UCS Manager に表示されます。 これらのエラーは、ソフトウェアでは修正できません。 不良 DIMM を特定して取り外すと、サーバをブートできます。 たとえば、1 つ以上の DIMM が不良であるために、BIOS で POST を渡せなくなります。
BIOS POST の障害が発生し、原因としてメモリの問題が疑われる状況で、その特定の DIMM スロットを識別できない場合は、次の手順を実行して、障害の発生している特定のパーツをさらに探し出します。
DIMM の問題に関する推奨される解決策
次の表に、DIMM の問題のトラブルシューティングを行うためのガイドラインおよび推奨される解決策を示します。
| 問題 |
推奨される解決策 |
|---|---|
| DIMM が認識されない。 |
DIMM が、アクティブ CPU をサポートするスロットに装着されていることを確認します。 DIMM が Cisco 製品であることを確認します。 サードパーティ製のメモリは Cisco UCS ではサポートされていません。 |
| DIMM がスロットに合わない。 |
DIMM がそのサーバ モデルでサポートされていることを確認します。 スロットに対して DIMM の向きが正しいことを確認します。 DIMM とそのスロットにはキーが付いており、2 方向のうちのいずれか一方でのみ固定できます。 |
| DIMM が SEL、POST、または LED で不良としてレポートされるか、または Cisco UCS Manager で動作不能としてレポートされる。 |
DIMM がそのサーバ モデルでサポートされていることを確認します。 DIMM が、そのサーバ モデルの装着規則に従ってスロットに装着されていることを確認します。 DIMM がスロットにしっかりと装着されていることを確認します。 アダプタが確実に接触するように装着し直し、POST を再度実行します。 DIMM を、正常に機能することがわかっているスロットに取り付けて、DIMM に問題があることを確認します。 正常に機能することがわかっている DIMM をスロットに取り付けて、DIMM のスロットが損傷していないことを確認します。 Cisco UCS Manager Release 1.2.(1b) 以降のリリースにアップグレードします。 BMC をリセットします。 |
| DIMM が GUI または CLI で低下としてレポートされるか、または予期した速度よりも遅い。 |
BMC をリセットします。 シャーシ内のブレード サーバを装着し直します。 すべての DIMM が同じ速度で実行できることを確認します。 高速な DIMM を使用していたシステムに速度の遅い DIMM が追加されると、サーバ上のすべての DIMM の実行速度が遅くなります。 |
| DIMM が過熱としてレポートされる。 |
DIMM がスロットにしっかりと装着されていることを確認します。 アダプタが確実に接触するように装着し直し、POST を再度実行します。 空気が設計どおりに流れるように、空の HDD ベイ、サーバ スロット、電源装置ベイのすべてでブランキング カバーが使用されていることを確認します。 空気が設計どおりに流れるように、サーバ エア バッフルが取り付けられていることを確認します。 空気が設計どおりに流れるように、必要な CPU エア ブロッカが取り付けられていることを確認します。 (B440 サーバでは、未使用の CPU スロットに対してエア ブロッカが使用されます)。 |
CPU の問題
すべての Cisco UCS サーバは、1 ~ 2 基または 1 ~ 4 基の CPU をサポートしています。 1 基の CPU に問題が発生すると、サーバのブート失敗、非常に低速な動作、または重大なデータ損失やデータ破損の原因となり得ます。 CPU の問題が疑われる場合は、次の内容を検討します。
- サーバ内のすべての CPU は、同じタイプである必要があり、同じ速度で動作し、同数および同じサイズの DIMM を使用している必要があります。
- 新しく CPU を交換またはアップグレードした場合は、その CPU がサーバに対して互換性があり、その CPU をサポートしている BIOS がインストールされていることを確認します。 サポートされる Cisco モデルおよび製品 ID については、サーバのマニュアルを参照してください。 シスコ提供の CPU のみを使用してください。 BIOS バージョンの情報は、ソフトウェア リリースのリリース ノートで確認できます。
- CPU を交換する際は、ヒートシンクを確実に接着し、放熱を行ってください。 CPU が加熱すると、Cisco UCS Manager で障害メッセージが表示されます。 また、CPU の損傷を防ぐためにパフォーマンスが低下する場合があります。
- CPU の過熱が疑われる場合は、シャーシ内のすべてのサーバのバッフルおよびエア フローを確認します。 隣接サーバのエア フロー問題により、別のサーバの CPU 冷却が不十分になる可能性があります。
- CPU 速度とメモリ速度は一致している必要があります。 一致しない場合、サーバは 2 つの速度のうちの遅い方の速度で動作します。
- 1 基の CPU に障害が発生した場合、残りのアクティブな CPU は、障害が発生した CPU に割り当てられているメモリにはアクセスできません。
CLI を使用した CPU の問題のトラブルシューティング
Cisco UCS Manager CLI を使用して CPU 情報を確認できます。
| コマンドまたはアクション | 目的 | |
|---|---|---|
| ステップ 1 | UCS-A# scope server x/y | サーバ モードを開始します。 |
| ステップ 2 | UCS-A# show cpu | サーバの CPU 情報が表示されます。 |
| ステップ 3 | UCS-A# show bios | サーバの BIOS 情報が表示されます。 |
| ステップ 4 | UCS-A# show cimc | サーバの CIMC 情報が表示されます。 |
次に、サーバ 1/5 の CPU、BIOS、および CIMC に関する情報を表示する例を示します。
jane-A# scope server 1/5
UCS-A /chassis/server # show cpu
CPU:
ID Presence Architecture Socket Cores Speed (GHz)
--- -------------------- ----------------- ------ ----------- -----------
1 Equipped Xeon CPU1 6 3.333000
2 Equipped Xeon CPU2 6 3.333000
UCS-A /chassis/server # show bios
Bios Firmware:
Server Model Vendor Running-Vers Package-Vers
------- ---------- ----------------- ------------ ------------
1/5 N20-B6625-2 Cisco Systems, In S5500.1.3.1c.0.052020102031
UCS-A /chassis/server # show cimc
CIMC:
PID Serial (SN) HW Revision
---------------- ---------------- -----------
N20-B6625-2 QCI140200D4 0
UCS-A /chassis/server #
GUI を使用した CPU の問題のトラブルシューティング
Cisco UCS Manager GUI を使用して、発生している CPU エラーのタイプを判別できます。
| ステップ 1 | ナビゲーション ペインで、正しいシャーシを展開し、サーバを選択します。 |
| ステップ 2 |
[Inventory] ウィンドウの [CPU] タブをクリックします。 そのサーバの CPU エラーが表示されます。 |
CPU の問題に関する推奨される解決策
次の表に、CPU の問題のトラブルシューティングに役立つガイドラインおよび推奨される解決策を示します。
| 問題 |
推奨される解決策 |
|---|---|
| CPU がスロットに合わない。 |
CPU がそのサーバ モデルでサポートされていることを確認します。 スロットに対して CPU の向きが正しいことを確認します。 DIMM とそのスロットにはキーが付いており、2 方向のうちのいずれか一方でのみ固定できます。 |
| DIMM が SEL、POST、または LED で不良としてレポートされるか、または Cisco UCS Manager で動作不能としてレポートされる。 |
DIMM がそのサーバ モデルでサポートされていることを確認します。 DIMM が、そのサーバ モデルの装着規則に従ってスロットに装着されていることを確認します。 DIMM がスロットにしっかりと装着されていることを確認します。 アダプタが確実に接触するように装着し直し、POST を再度実行します。 DIMM を、正常に機能することがわかっているスロットに取り付けて、DIMM に問題があることを確認します。 正常に機能することがわかっている DIMM をスロットに取り付けて、DIMM のスロットが損傷していないことを確認します。 Cisco UCS Manager Release 1.2.(1b) 以降のリリースにアップグレードします。 BMC をリセットします。 |
| DIMM が GUI または CLI で低下としてレポートされる。 |
BMC をリセットします。 シャーシ内のブレード サーバを装着し直します。 すべての DIMM が同じ速度で実行されていることを確認します。 高速な DIMM が装着されているシステムに速度の遅い DIMM が追加されると、サーバ上のすべての DIMM の実行速度が遅くなります。 |
| DIMM が過熱としてレポートされる。 |
DIMM がスロットにしっかりと装着されていることを確認します。 アダプタが確実に接触するように装着し直し、POST を再度実行します。 空気が設計どおりに流れるように、空の HDD ベイ、サーバ スロット、電源装置ベイのすべてでブランキング カバーが使用されていることを確認します。 空気が設計どおりに流れるように、サーバ エア バッフルが取り付けられていることを確認します。 |
CPU CATERR の詳細
システム イベント ログ(SEL)には、プロセッサの壊滅的なエラー(CATERR)センサーに関連するイベントが含まれます。 CATERR メッセージは障害を示し、一方 CATERR_N メッセージはセンサーが障害状態にないことを示しています。
CATERR_N メッセージは、予測障害がデアサートされたことを示す no-fault ビットのアサーションを示しています。 no-fault ビットがオンの場合、障害が存在しないことを示しています。
センサーが初期化されるときに、BMC はセンサーが初期状態の SEL イベントを送出し、センサーがアクティブになるタイミングやセンサーの状態をモニタするサーバ管理ソフトウェアとの同期状態を維持します。 多くの場合、センサーの初期読み取りでは、予測障害がデアサートされ、CATERR_N メッセージが送信されます。
これらのイベントは、no-fault ビットがオフになり(デアサート)、fault ビット(予測障害のアサーション)がオンになったことを示しています。
障害状態から障害なし状態への遷移は、多くの場合重複するため、通常はログに記録されません。これは、この状態遷移が、エラーではない状態または誤検出の場合を示すためです。 これらのメッセージは、センサーが値を読み取り、センサーの no-failure ビットがオンであることを示しています。 管理ソフトウェアとの同期を行うために、初期のセンサー状態の読み取り値がログに記録されます。
ディスク ドライブと RAID に関する問題
ディスク ドライブまたは RAID コントローラに問題が発生すると、サーバの起動に失敗したり、重大なデータ損失またはデータ破損が生じる可能性ががあります。 ドライブの問題が疑われる場合は、次の内容を検討します。
- OS ツールを定期的に使用して、ドライブの問題(不良セクターなど)を検出および修正します。 Cisco UCS Manager では、サーバの OS と同じように効果的にドライブの問題を修正することはできません。
- 各ディスク ドライブに装備されているアクティビティ LED により、ドライブに対する未処理の I/O 処理が示されます。また、ドライブに障害が検出されると、ヘルス LED がオレンジに点灯します。 ドライブの障害は、BIOS POST で検出できます。 SEL メッセージには、これらの問題を見つけるのに役立つ重要な情報が含まれている場合があります。
- ディスク ドライブは、システム シャーシからブレードを取り外さなくてもサーバから取り外すことができる唯一の主要コンポーネントです。
- ディスク ドライブには、さまざまな容量のものがあります。 ドライブに空き容量がない、またはドライブに OS で解決できない問題が存在するためにディスク ドライブのパフォーマンスが低下した場合、ドライブの内容をバックアップして、より大容量のハード ドライブまたは新しいハード ドライブを取り付ける必要があります。
- RAID コントローラ
- Quiet Boot のディセーブル化
- ROM ベースのコントローラ ユーティリティへのアクセス
- RAID コントローラと LSI ユーティリティのマニュアル
- UCS ソフトウェア バージョン 1.4(1) を使用した RAID クラスタの移動
- UCS ソフトウェア バージョン 1.4(2) 以降を使用した RAID クラスタの移動
- B200 M3 サーバ間での RAID クラスタの移動
- RAID クラスタ内の障害の発生したドライブの交換
RAID コントローラ
- Cisco UCS B200 および B250 サーバでは、LSI 1064E コントローラがマザーボードに搭載されています。 このコントローラは、最大 2 台の SAS ドライブまたは SATA ドライブに対して RAID 0 および 1 をサポートします。 このコントローラは、RAID を設定する前に Cisco UCS Manager でイネーブルにしておく必要があります。 すべての RAID オプションを Cisco UCS Manager から設定できます。
- Cisco UCS B440 サーバには、LSI MegaRAID コントローラ(サーバによってモデルは異なる)が搭載されています。 インストールされたライセンス キーに応じて、これらのコントローラは、最大 4 台の SAS ドライブまたは SATA ドライブに対する RAID 0、1、5、6、および 10 のサポートを提供します。
- Cisco B200 M3 サーバでは、LSI SAS 2004 RAID コントローラがマザーボードに搭載されています。 このコントローラは、最大 2 台の SAS ドライブまたは SATA ドライブに対して RAID 0 および 1 をサポートします。
(注) |
RAID クラスタをサーバ間で移動させる必要がある場合は、そのクラスタの新旧両方のサーバで同じ LSI コントローラが使用されている必要があります。 たとえば、LSI 1064E を搭載したサーバから LSI MegaRAID を搭載したサーバへの移行はサポートされていません。 |
サーバで使用されているオプションについての記録がない場合は、Quiet Boot 機能をディセーブルにし、システムのブート時に表示されるメッセージから読み取ります。 搭載されている RAID コントローラのモデルに関する情報は、冗長ブート機能の一部として表示されます。 それらのコントローラの構成ユーティリティを起動するため、Ctrl を押した状態で H を押すように求めるプロンプトが表示されます。
Quiet Boot のディセーブル化
Quiet Boot 機能がディセーブルになっている場合、ブートアップ時にコントローラの情報と、オプションの ROM ベースの LSI ユーティリティのプロンプトが表示されます。 この機能をディセーブルにするには、次の手順を実行します。
ROM ベースのコントローラ ユーティリティへのアクセス
ハード ドライブの RAID 設定を変更するには、ホスト OS の上にインストールされたホストベースのユーティリティを使用します。 また、サーバ上にインストールされている LSI オプションの ROM ベースのユーティリティを使用することもできます。
RAID コントローラと LSI ユーティリティのマニュアル
UCS ソフトウェア バージョン 1.4(1) を使用した RAID クラスタの移動
別のサーバ上で作成された RAID クラスタを認識するようにサーバを設定できます。 この手順は、M1 バージョンのサーバを M2 バージョンのサーバにアップグレードする際に役立ちます。 また、RAID クラスタ上のデータをサーバ間で移動させなければならなくなったときにも使用できます。
(注) |
クラスタの新旧両方のサーバが同じ LSI コントローラ内に存在している必要があります。 たとえば、LSI 1064E を搭載したサーバから LSI MegaRAID を搭載したサーバへの移行はサポートされていません。 |
移動元と移動先の両方のサーバのサービス プロファイルが、まったく同じローカル ディスク設定ポリシーを持ち、正常に起動できることを確認します。
| ステップ 1 | RAID クラスタの移動元と移動先の両方のサーバを関連付けられている状態にします。 | ||
| ステップ 2 |
両方のサーバをシャットダウンします。
|
||
| ステップ 3 | サーバの電源がオフになったら、アレイ内のドライブを移動先のサーバに物理的に移します。 サーバを変更しても、ドライブは同じスロットのままにする場合は、元のサーバのスロットに新しいサーバを挿入します。 | ||
| ステップ 4 | KVM ドングルを接続します。 | ||
| ステップ 5 | モニタ、キーボード、およびマウスを移動先サーバに接続します。 | ||
| ステップ 6 |
サーバの前面にある電源スイッチを使用して、移動先サーバを起動します。 必要ならば、Quiet Boot 機能をディセーブルにし、再起動します (Quiet Boot のディセーブル化 を参照)。 |
||
| ステップ 7 | LSI Configuration Utility バナーが表示されるのを待ちます。 | ||
| ステップ 8 | LSI Configuration Utility を起動するために、Ctrl+C を押します。 | ||
| ステップ 9 |
[SAS Adapter List] 画面から、サーバ内で使用される SAS アダプタを選択します。 使用されている RAID コントローラを確認するには、RAID コントローラを参照してください。 |
||
| ステップ 10 |
[RAID Properties] を選択します。 [View Array] 画面が表示されます。 |
||
| ステップ 11 |
[Manage Array] を選択します。 [Manage Array] 画面が表示されます。 |
||
| ステップ 12 |
[Activate Array] を選択します。 アクティベーションが完了すると、RAID ステータスが [Optimal] に変化します。 |
||
| ステップ 13 | [Manage Array] 画面で、[Synchronize Array] を選択します。 | ||
| ステップ 14 |
ミラー同期化が完了するまで待ちます(表示されている経過表示バーを監視します)。
|
||
| ステップ 15 | ミラー同期化が完了したら、Esc キーを数回押して画面を順番に戻り(一度に 1 つ)、LSI Configuration Utility を終了します。 | ||
| ステップ 16 | [reboot] オプションを選択して、変更を完了します。 |
UCS ソフトウェア バージョン 1.4(2) 以降を使用した RAID クラスタの移動
別のサーバ上で作成された RAID アレイを認識するようにサーバを設定できます。 この手順は、M1 バージョンのサーバを M2 バージョンのサーバにアップグレードする際に役立ちます。 また、RAID アレイ上のデータをサーバ間で移動させなければならなくなったときにも使用できます。
(注) |
クラスタの新旧両方のサーバが同じ LSI コントローラ ファミリ内に存在している必要があります。 たとえば、LSI 1064 を搭載したサーバから LSI MegaRAID を搭載したサーバへの移行はサポートされていません。 |
移動元と移動先の両方のサーバのサービス プロファイルが、まったく同じローカル ディスク設定ポリシーを持ち、正常に起動できることを確認します。
B200 M3 サーバ間での RAID クラスタの移動
別のサーバ上で作成された RAID クラスタを認識するようにサーバを設定できます。 また、RAID クラスタ上のデータをサーバ間で移動させなければならなくなったときにも使用できます。
移動元と移動先の両方のサーバのサービス プロファイルが、まったく同じローカル ディスク設定ポリシーを持ち、正常に起動できることを確認します。
| ステップ 1 |
移動元サーバのオペレーティング システムをそのオペレーティング システム内からシャットダウンします。 先に進む前に、OS が完全にシャットダウンし、自動で再起動していないことを確認します。 |
| ステップ 2 | B200M3 サーバに現在適用されているサービス プロファイルの関連付けを解除します。 |
| ステップ 3 |
アレイ内のドライブを移動先のサーバに物理的に移します。 サーバを変更する場合は、新しいサーバでも元のサーバと同じスロットにドライブを装着する必要があります。 |
| ステップ 4 | 前に使用していたのと同じ論理ドライブ設定ポリシーが維持されるように、サービス プロファイルを新しいブレードに再関連付けします。 |
| ステップ 5 | 各サーバの前面にある電源スイッチを押して、サーバの電源をオンにします。 |
| ステップ 6 | 新しいサーバへの KVM 接続を開き、Storage Web BIOS Utility が起動するのを待ちます。 |
| ステップ 7 | この Web BIOS ユーティリティのプロンプトに従って、RAID LUN を「移行」します。 |
RAID クラスタ内の障害の発生したドライブの交換
RAID ボリュームを作成する際は、業界の標準的なプラクティスに従って、容量が同じドライブを使用することを推奨します。 容量の異なるドライブを使用すると、最も容量の小さいドライブで使用可能な容量が、RAID ボリュームを編成するすべてのドライブで使用されることになります。
障害の発生した HDD または SSD を、同じサイズ、モデル、メーカーのドライブと交換します。 稼働中のシステムで HDD を交換する前に、UCS Manager でサービス プロファイルを確認し、新しいハードウェア設定が、サービス プロファイルで設定されているパラメータの範囲内になることを確認します。
| ステップ 1 | KVM ドングルを、障害の発生したドライブを搭載しているサーバに接続します。 | ||
| ステップ 2 | モニタ、キーボード、およびマウスを移動先サーバに接続します。 | ||
| ステップ 3 |
障害の発生したドライブを物理的に交換します。 必要に応じて、お使いのサーバ モデルのサービス ノートを参照します。 通常、ほとんどのモデルで同様の手順になります。 |
||
| ステップ 4 |
サーバの前面にある電源スイッチを使用して、サーバを起動します。 必要ならば、Quiet Boot 機能をディセーブルにし、再起動します (Quiet Boot のディセーブル化 を参照)。 |
||
| ステップ 5 | LSI Configuration Utility バナーが表示されるのを待ちます。 | ||
| ステップ 6 | LSI Configuration Utility を起動するために、Ctrl+C を押します。 | ||
| ステップ 7 |
[SAS Adapter List] 画面から、サーバ内で使用される SAS アダプタを選択します。 使用されている RAID コントローラを確認するには、RAID コントローラを参照してください。 |
||
| ステップ 8 |
[RAID Properties] を選択します。 [View Array] 画面が表示されます。 |
||
| ステップ 9 |
[Manage Array] を選択します。 [Manage Array] 画面が表示されます。 |
||
| ステップ 10 |
[Activate Array] を選択します。 アクティベーションが完了すると、RAID ステータスが [Optimal] に変化します。 |
||
| ステップ 11 | [Manage Array] 画面で、[Synchronize Array] を選択します。 | ||
| ステップ 12 |
ミラー同期化が完了するまで待ちます(表示されている経過表示バーを監視します)。
|
||
| ステップ 13 | ミラー同期化が完了したら、Esc キーを数回押して画面を順番に戻り(一度に 1 つ)、LSI Configuration Utility を終了します。 | ||
| ステップ 14 | [reboot] オプションを選択して、変更を完了します。 |
アダプタの問題
- そのシスコのアダプタが正規品であるかどうかを確認します。
- 使用しているソフトウェア リリースで、そのアダプタ タイプがサポートされているかどうかを確認します。 Cisco UCS Manager のリリース ノートにある内部的な依存性の表には、すべてのアダプタに対する、最小および推奨ソフトウェア バージョンが示されています。
- アダプタに適したファームウェアがサーバにロードされているかどうかを確認します。 リリース バージョン 1.0(1) ~ 2.0 では、Cisco UCS Manager のバージョンとアダプタ ファームウェアのバージョンが一致する必要があります。 Cisco UCS ソフトウェアとファームウェアをアップデートするには、インストール環境に適した Cisco UCS のアップグレードのドキュメントを参照してください。
- ソフトウェア バージョンのアップデートが完全でなく、ファームウェア バージョンが Cisco UCS Manager のバージョンに一致しなくなった場合は、インストール環境に適した Cisco UCS Manager の設定ガイドに従い、アダプタ ファームウェアをアップデートします。
- 2 枚の Cisco UCS M81KR 仮想インターフェイス カードを、ESX 4.0 を実行する Cisco UCS B250 拡張メモリ ブレード サーバに装着する場合、パッチ 5(ESX4.0u1p5)以降のリリースの ESX 4.0 にアップグレードする必要があります。
- あるアダプタ タイプから別のアダプタ タイプに移行する場合は、新しいアダプタ タイプのドライバを入手できることを確認します。 新しいアダプタ タイプに合わせてサービス プロファイルをアップデートします。 そのアダプタ タイプに適したサービスを設定します。
-
デュアル アダプタを使用する場合は、サポートされる組み合わせにいくつかの制限があることに注意してください。 次の組み合わせがサポートされます。
サーバ
同一タイプのデュアル カード
混合タイプのデュアル カード
Cisco UCS B250
すべて
M71KR-Q または -E + M81KR M72KR-Q または -E + M81KR
Cisco UCS B440
82598KR-CI を除くすべて
M72KR-Q または -E + M81KR
アダプタに関する既知の問題
アダプタに関しては、既知の問題および未解決のバグが複数存在します。 これらの問題は、リリース ノートで指摘されています。 リリース ノートは、Cisco UCS B-Series Servers Documentation Roadmap から入手できます。
特に、バグ CSCtd32884 および CSC71310 は、従来から継続している既知の条件であり、サーバ内のアダプタのタイプによって、サポートされる最大伝送単位(MTU)が影響を受けます。 ネットワーク MTU が最大値を超えた場合、次のアダプタでパケットがドロップする可能性があります。
CLI を使用したアダプタ エラーのトラブルシューティング
アダプタでネットワーク リンクを 1 つも確立できなかった場合、サーバ正面のリンク LED がオフになります。 1 つ以上のリンクがアクティブになっている場合は、緑色になります。 アダプタ エラーは、マザーボード上の LED で報告されます。 診断ボタンと LEDを参照してください。
次の手順を使用して、CLI でアダプタの状態情報を確認できます。
| コマンドまたはアクション | 目的 | |
|---|---|---|
| ステップ 1 | UCS-A# scope server chassis-id/server-id | |
| ステップ 2 | UCS-A /chassis/server #show adapter [detail] |
次に、シャーシ ID 1、サーバ ID 5 のアダプタの詳細を表示する例を示します。
UCS-A# scope server 1/5
UCS-A /chassis/server # show adapter detail
Adapter:
Id: 2
Product Name: Cisco UCS 82598KR-CI
PID: N20-AI0002
VID: V01
Vendor: Cisco Systems Inc
Serial: QCI132300GG
Revision: 0
Mfg Date: 2009-06-13T00:00:00.000
Slot: N/A
Overall Status: Operable
Conn Path: A,B
Conn Status: Unknown
Managing Instance: B
Product Description: PCI Express Dual Port 10 Gigabit Ethernet Server Adapter
UCS-A /chassis/server #
GUI を使用したアダプタ エラーのトラブルシューティング
アダプタでネットワーク リンクを 1 つも確立できなかった場合、サーバ正面のリンク LED がオフになります。 1 つ以上のリンクがアクティブになっている場合は、緑色になります。 アダプタ エラーは、マザーボード上の LED で報告されます。 「診断ボタンと LED」(P.6-1)を参照してください。
次の手順を使用して、発生しているアダプタ エラーの種類を特定します。
| ステップ 1 | ナビゲーション ペインでシャーシを展開し、目的のサーバを選択します。 |
| ステップ 2 |
[Inventory] ウィンドウで、[Interface Cards] タブを選択します。 そのサーバのアダプタ エラーが画面に表示されます。 |
アダプタの問題に関する推奨される解決策
次の表に、アダプタの問題のトラブルシューティングに役立つガイドラインおよび推奨される解決策を示します。
問題 |
推奨される解決策 |
|---|---|
アダプタが SEL、POST、または LED で不良としてレポートされるか、または Cisco UCS Manager で動作不能としてレポートされる。 |
アダプタがそのサーバ モデルでサポートされていることを確認します。 使用中の Cisco UCS Manager のバージョンで動作するのに必要なファームウェア バージョンが、アダプタに組み込まれていることを確認します。 アダプタが、マザーボードのスロットおよびミッドプレーンの接点にしっかりと装着されていることを確認します。 アダプタが確実に接触するように装着し直し、サーバを再度取り付けてから、POST を再度実行します。 アダプタを、正常に機能することがわかっており、同じ種類のアダプタを使用しているサーバに取り付けて、アダプタに問題があることを確認します。 |
アダプタが GUI または CLI で低下としてレポートされる。 |
シャーシ内のブレード サーバを装着し直します。 |
アダプタが過熱としてレポートされる。 |
アダプタがスロットにしっかりと装着されていることを確認します。 アダプタが確実に接触するように装着し直し、POST を再度実行します。 空気が設計どおりに流れるように、空の HDD ベイ、サーバ スロット、電源装置ベイのすべてでブランキング カバーが使用されていることを確認します。 空気が設計どおりに流れるように、サーバ エア バッフルが取り付けられていることを確認します。 |
電源の問題
サーバのオンボード電源システムの問題が原因で、警告なしでサーバがシャットダウンしたり、電源オンに失敗したり、検出プロセスに失敗したりする場合があります。
Cisco UCS B440 サーバの FET 障害のトラブルシューティング
Cisco UCS B440 サーバの電源部における電界効果トランジスタ(FET)の障害によって、サーバのシャットダウン、電源投入の障害、または検出プロセスの障害が発生する場合があります。 サーバによって障害が検出された場合は、前面パネルの電源ボタンを使用しても、サーバの電源をオンにできません。
FET 障害が発生しているかどうかを判断するには、次の手順を実行します。
| ステップ 1 | 「障害」の項(P.1 ~ 2)の手順を使用し、レポートされた障害で障害コード F0806、「Compute Board Power Fail.」の有無を確認します。この障害によって、サーバの全体的なステータスが Inoperable になります。 |
| ステップ 2 |
システム イベント ログ(SEL)で、この例に示すタイプの電源システム障害の有無を確認します。
58f | 06/28/2011 22:00:19 | BMC | Power supply POWER_SYS_FLT #0xdb | Predictive Failure deasserted | Asserted |
| ステップ 3 |
ファブリック インターコネクトの CLI から、障害が発生したサーバの CIMC にアクセスし、connect cimc chassis/server と入力することによって、障害センサーを表示します。 例: 次の例では、シャーシ 1、サーバ 5 の CIMC に接続する方法を示します。 Fabric Interconnect-A# connect cimc 1/5 Trying 127.5.1.1... Connected to 127.5.1.1. Escape character is '^]'. CIMC Debug Firmware Utility Shell [ help ]# sensors fault HDD0_INFO | 0x0 | discrete | 0x2181| na | na | na | na | na | na HDD1_INFO | 0x0 | discrete | 0x2181| na | na | na | na | na | na . .[lines removed for readability] . LED_RTC_BATT_FLT | 0x0 | discrete | 0x2180| na | na | na | na | na | na POWER_SYS_FLT | 0x0 | discrete | 0x0280| na | na | na | na | na | na [ sensors fault]# POWER_SYS_FLT センサーで 0x0280 が示されている場合は、FET 障害があります。 通常動作においては、このセンサーでは 0x0180 が示されます。 |
| ステップ 4 |
FET 障害が発生したと判断した場合は、次の手順を実行します。
|
Cisco TAC に連絡するときに必要となる情報
問題を切り分けてコンポーネントを特定できない場合は、次の質問について検討してください。 これらの質問は、Cisco Technical Assistance Center(TAC)に連絡するときに役立ちます。
- 問題が発生する前は、ブレードは動作していましたか。 サービス プロファイルが関連付けられた状態でブレードが実行中に問題が発生しましたか。
- これは新しく挿入したブレードですか。
- このブレードは、現地で組み立てられたものですか。それともシスコから組み立てられた状態で到着したものですか。
- メモリを装着し直しましたか。
- ブレードの電源は切れていましたか、またはブレードをスロット間で移動しましたか。
- Cisco UCS Manager を最近アップグレードしましたか。 アップグレードした場合は、BIOS もアップグレードしましたか。
Cisco UCS の問題に関して Cisco TAC に連絡するときは、Cisco UCS Manager および問題が発生しているシャーシから tech-support 出力を取得することが重要です。 詳細については、テクニカル サポート ファイルを参照してください。
B シリーズ サーバの関連資料
個別のサーバ モデルについては、『Cisco UCS Blade Server Installation and Service Notes』を参照してください。