Secure Web Applianceの遅延のトラブルシューティング
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
はじめに
このドキュメントでは、Cisco Secure Web Appliance(SWA)での高遅延、高ディスク、高CPU使用率に対処するためのトラブルシューティング手順について説明します。
前提条件
要件
次の項目に関する知識があることが推奨されます。
- Cisco SWAの管理
-
プロキシの導入方法(明示的および透過的)
- SWAコマンドラインインターフェイス(CLI)コマンド
使用するコンポーネント
このドキュメントの内容は、特定のソフトウェアやハードウェアのバージョンに限定されるものではありません。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、クリアな(デフォルト)設定で作業を開始しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
背景説明
シスコテクニカルサポートに連絡すると、SWAの発信および着信ネットワークアクティビティの詳細を提供するよう求められます。このアクティビティは、デバッグまたは検証の目的でトラフィックを収集するためにパケットキャプチャを実行することで監視できます。
SWAで高い遅延が発生する一般的な原因
一般的に、SWAの高遅延には主に3つのカテゴリがあります。
1. SWAのサイジングが不十分であるか、リソースが過負荷になっている
2. 複雑な構成
3. ネットワーク関連の遅延問題
SWAの高遅延の最も一般的な原因の1つは、ソリューションのサイジングが不十分であることです。適切なサイジングは、SWAシステムが現在のワークロードと予想されるワークロードを処理するのに十分なリソースを確保するために重要です。システムのサイズが小さいと、要求の効率的な処理に苦慮し、運用の遅延やパフォーマンスの低下を招く可能性があります。リソースの制約を避けるために、導入時には、ユーザ数、復号化の量、特定のスキャン要求などの要因を慎重に評価する必要があります。SWAの容量を組織のニーズに合わせることができないと、遅延が長引き、ユーザエクスペリエンスが低下する可能性があります。
複雑な設定では、各要求を多数の条件で処理する必要があるため、特に高負荷時に、SWAのパフォーマンスが低下し、遅延が発生する可能性があります。
ネットワーク関連の遅延は、SWA自体、Active Directory、DLP、DNSなどのサードパーティサービス、またはクライアント、SWA、アップストリームサーバ間のネットワーク遅延に起因する可能性があります。
SWAに送信された要求を分析し、上位ユーザと最もアクセスされたURLを特定することは、潜在的な誤動作を明らかにし、遅延の根本原因を特定するのに役立ちます。この情報は、パフォーマンス問題の診断、帯域幅消費の管理、システムの適切な使用の確保に非常に重要です。
SWA遅延のトラブルシューティングツール
システムのステータス
SWAの現在のリソース消費を確認するには、次の手順を使用します。
ステップ 1:SWAのグラフィカルユーザインターフェイス(GUI)にアクセスします。
ステップ 2:Reporting > System Information > System Statusの順に選択します。
ステップ 3:システムパフォーマンスを評価するには、次の重要なメトリックを確認します。
- CPU使用率(%):現在のCPU負荷を示します。
- RAM使用率(%):メモリ使用率を反映
- Reporting/Logging Usage (%):レポートとロギングに使用されているディスク領域の割合が表示されます。
- システム稼働時間:システムが再起動なしで実行された合計時間を表示します
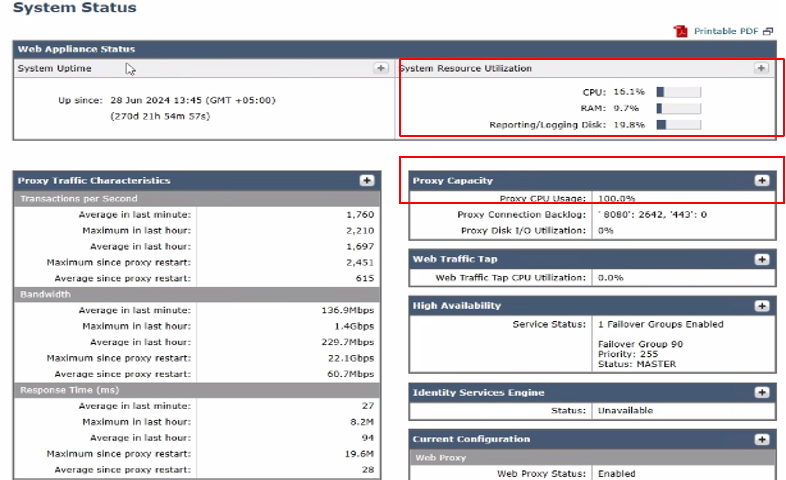 イメージ – システムステータス
イメージ – システムステータス
このページには、RAM、CPU、およびディスクの使用状況の現在のステータスの概要が表示されます。時間の経過に伴うリソースの使用状況を表示するには、SWA GUIからReportingに移動し、System Capacityを選択します。
システム容量
SWAのSystem Capacityページには、指定した時間範囲におけるリソース使用率とパフォーマンスメトリックの包括的なビューが表示されます。このページには、システム動作の監視と分析に役立つ詳細なグラフが表示されます。これにより、最適なパフォーマンスを確保し、潜在的なボトルネックを特定できます。
[System Capacity]ページで使用可能なグラフとメトリックは次のとおりです。
- Overall CPU Usage:合計CPU使用率を表示し、システムパフォーマンスの概要を示します。
- 機能別のCPU使用率:次のような特定の機能に基づいてCPU使用率を分類します。
- Webプロキシ
- Logging
- レポート
- マカフィー
- ソフォス
- ウェブルート
- アクセプタブルユースとレピュテーション
3. 応答時間/遅延(ミリ秒):応答時間を追跡して、要求の処理における遅延を特定します。
4. Transactions Per Second: SWAによって処理されているトランザクションの1秒あたりの数が表示されます。
5. Connections Out:確立されている発信接続の数を監視します。
6. アウト帯域幅(バイト):使用されているアウトバウンド帯域幅の量を測定します。
7. プロキシ・バッファ・メモリー(%):プロキシ・プロセスが使用するメモリーの割合が表示されます。
このダッシュボードで、リソースの使用率が高くなっている兆候がないかメトリックを確認します。
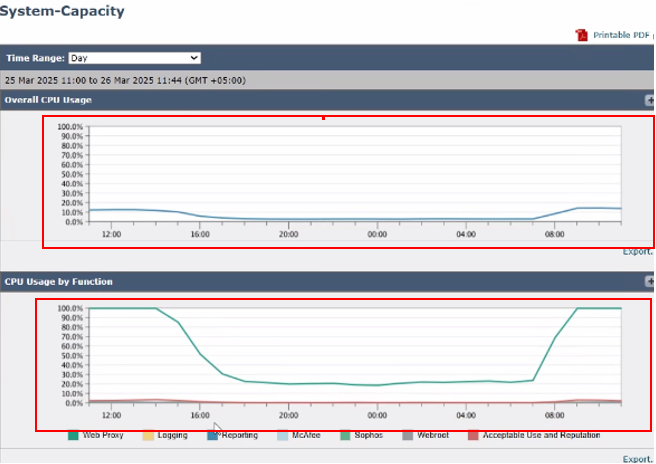 イメージ – システム容量
イメージ – システム容量
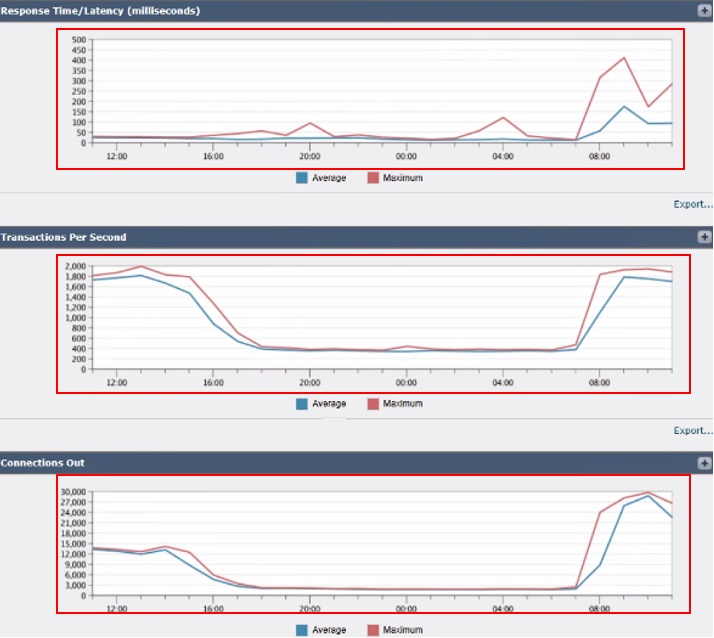 イメージ:1秒あたりのSWAトランザクション数および発信接続数
イメージ:1秒あたりのSWAトランザクション数および発信接続数
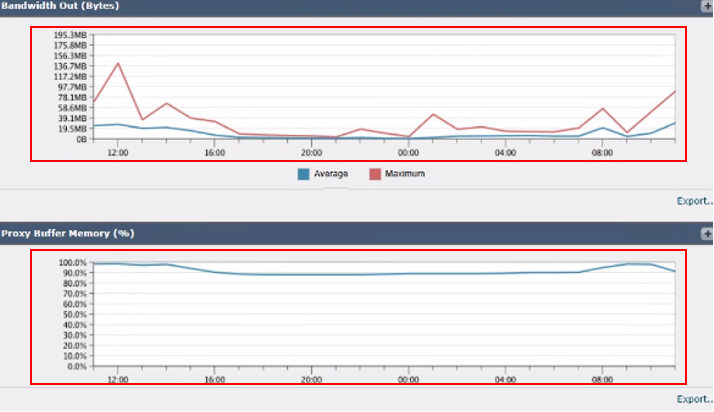 イメージ – SWAメモリ使用量
イメージ – SWAメモリ使用量
上位の通知先の分析
上位の宛先を分析するには、SWA GUIに移動し、Reportingに移動して、Websitesを選択します。上位のHTTP/HTTPS Webサイトのリストを確認し、トラフィックの多いドメインや頻繁にアクセスされるドメインを特定します。
調査結果に基づいて、Microsoft Updates、Adobe、Office365、オンラインミーティングプラットフォームなどの一般的なURLをバイパスするか、除外することを検討してください。このアプローチにより、SWA上のトラフィックが減少し、遅延が減少し、プロキシ処理の負荷が軽減されます。
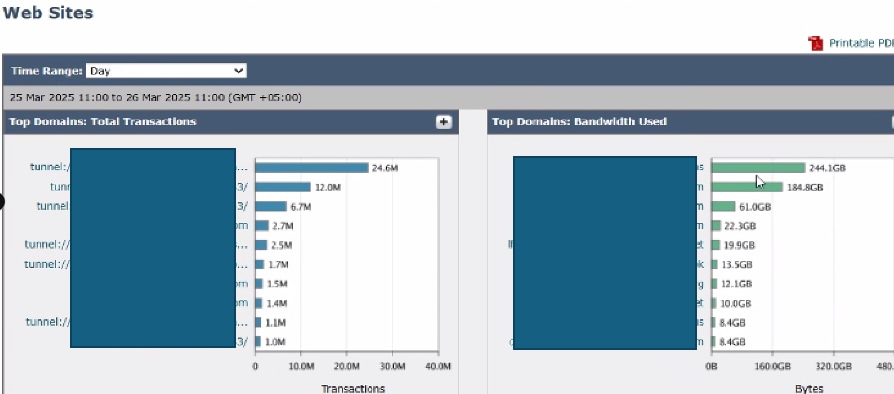 イメージ:SWAの上位Webサイトダッシュボード
イメージ:SWAの上位Webサイトダッシュボード
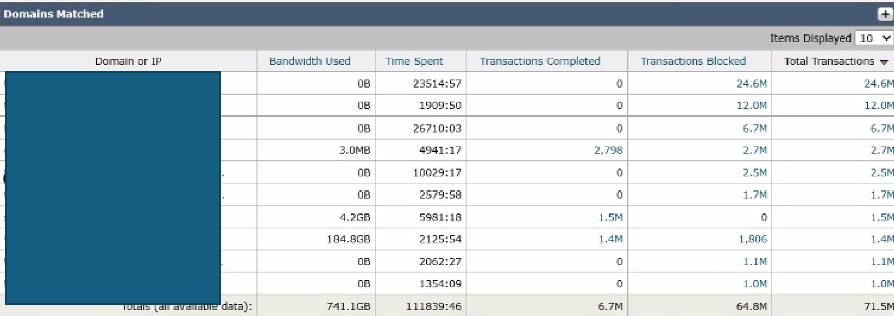 イメージ:SWA Top Domainsダッシュボード
イメージ:SWA Top Domainsダッシュボード
上位ユーザの分析
過剰なトラフィックの潜在的な発信元を識別するには、ReportingからSWA GUIに移動して、Usersを選択します。
リストを確認して、SWAへのトランザクション数が最も多いユーザを特定します。さらに、SWAへのトランザクション数が最も多く、最大帯域幅を消費しているユーザマシンを確認します。
この分析は、重大なトラフィック負荷の原因となるユーザまたはデバイスを特定するのに役立ち、対象を絞ったアクションによってシステム全体の負荷を軽減できます。
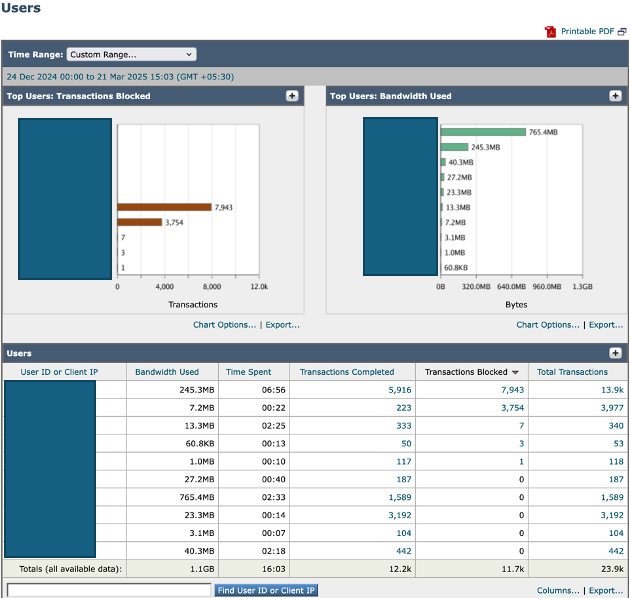 Image-SWAのトップユーザダッシュボード
Image-SWAのトップユーザダッシュボード
SHDログ
SHD_logを確認すると、ユーザーからSWAへのセッション数(CliConn)、SWAからインターネットへのセッション数(SrvConn)、平均要求数(Req)などのパフォーマンス・メトリックの一部を分析できます。
SHDログの詳細については、「SHDログによるセキュアWebアプライアンスのパフォーマンスのトラブルシューティング」のリンクを参照してください。
SHDログで確認する主なパラメータは次のとおりです。
- ClientConns:アクティブなクライアント接続数
- ServerConns:アクティブなサーバー接続の数
- ProxLd:プロキシ処理の平均負荷
- CPULL:CPU全体の平均負荷
- RAMUTIL:RAM使用率
- 遅延:平均サービス時間(1分)
- DiskUtil:ディスク使用率とI/Oパフォーマンス
この例と同様に、1秒あたり約1,600個のリクエストがあるため、プロキシプロセスの負荷が高くなります。
Wed Mar 26 11:09:30 2025 Info: Status: CPULd 16.3 DskUtil 19.9 RAMUtil 9.3 Reqs 1661 Band 152966 Latency 4245 CacheHit 3 CliConn 27180 SrvConn 24356 MemBuf 93 SwpPgOut 222877 ProxLd 100 Wbrs_WucLd 0.0 LogLd 0.0 RptLd 0.0 WebrootLd 0.0 SophosLd 0.0 McafeeLd 0.0 WTTLd 0.0 AMPLd 0.0
Wed Mar 26 11:10:31 2025 Info: Status: CPULd 13.6 DskUtil 19.9 RAMUtil 9.5 Reqs 1699 Band 107048 Latency 5724 CacheHit 2 CliConn 26921 SrvConn 24164 MemBuf 93 SwpPgOut 222877 ProxLd 99 Wbrs_WucLd 0.0 LogLd 0.0 RptLd 9.0 WebrootLd 0.0 SophosLd 0.0 McafeeLd 0.0 WTTLd 0.0 AMPLd 0.0
Wed Mar 26 11:11:31 2025 Info: Status: CPULd 15.0 DskUtil 19.9 RAMUtil 9.5 Reqs 1669 Band 178803 Latency 4871 CacheHit 1 CliConn 26676 SrvConn 23922 MemBuf 93 SwpPgOut 222877 ProxLd 100 Wbrs_WucLd 11.2 LogLd 0.0 RptLd 0.0 WebrootLd 0.0 SophosLd 0.0 McafeeLd 0.0 WTTLd 0.0 AMPLd 0.0
Wed Mar 26 11:12:31 2025 Info: Status: CPULd 17.6 DskUtil 19.9 RAMUtil 9.2 Reqs 1785 Band 143721 Latency 4349 CacheHit 1 CliConn 25929 SrvConn 23256 MemBuf 92 SwpPgOut 222877 ProxLd 99 Wbrs_WucLd 0.0 LogLd 3.6 RptLd 0.0 WebrootLd 0.0 SophosLd 0.0 McafeeLd 0.0 WTTLd 0.0 AMPLd 0.0 アクセスログを使用した遅延問題のトラブルシューティング
SWAを介してトラフィックをプロキシする際に遅延の問題が発生すると、アクセスログが、考えられる根本原因を特定するための貴重なツールとして機能します。トラブルシューティングの取り組みを強化するために、既存のアクセスログ設定を変更するか、新しいアクセスログを作成することができます。カスタム・フィールドにパフォーマンス・パラメータを含めることにより、遅延の要因をより詳細に把握し、より効果的な分析と解決を可能にします。
パフォーマンスパラメータと設定手順の詳細については、「アクセスログでのパフォーマンスパラメータの設定」を参照してください。
SWAでログを収集するための詳細なガイドは次のとおりです。セキュアWebアプライアンス(WSA)のログへのアクセス
遅延の原因は、クライアントとSWAの間、SWA内部プロセス内、またはSWAとWebサーバの間で遅延が発生したかどうかを判断するのに役立つ主要なパラメータを調べることによって分析できます。考慮すべき重要な指標には、DNS解決、認証時間、サーバやクライアントの応答時間など、ネットワークベースのサービスがあります。さらに、AMP、Sophos、AVCなどのスキャンエンジンによる遅延を評価して、全体的な遅延への影響を特定する必要があります。
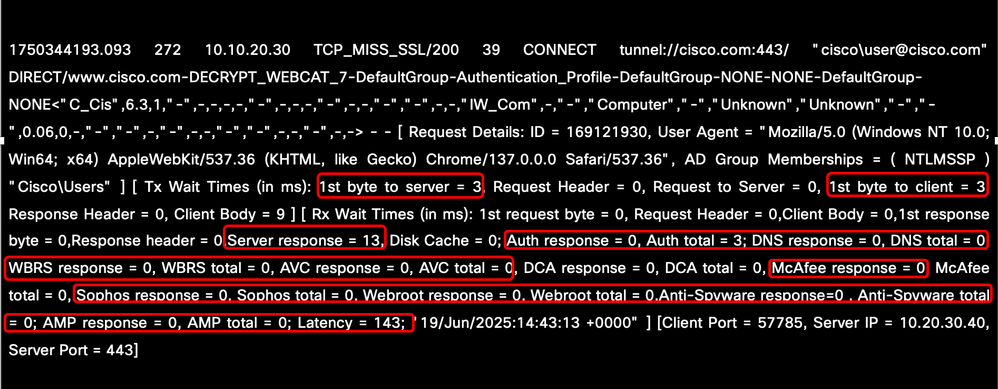 イメージ:AccessLogのパフォーマンスパラメータ
イメージ:AccessLogのパフォーマンスパラメータ
高認証時間
認証の応答時間が長い場合、TACが認証の遅延をより適切かつ迅速にトラブルシューティングするためには、次の情報が必要です。
-
現在のSWA設定
-
デバッグモードまたはトレースモードでの認証ログ
-
パケットキャプチャ
-
クライアントマシン。
-
SWA(レルム設定で設定されたすべてのアクティブなディレクトリへのクライアントトラフィックとSWAトラフィックをキャプチャするフィルタを使用)
-
-
アクセスログにカスタムフィールド%mと%gの両方があり、認証メカニズムとグループを識別していることを確認してください
-
問題の再現中にクライアントからHARファイルを取得
- CLIからのtestauthconfigコマンドの出力
次の例は、認証に関連する高い遅延時間を示しています。
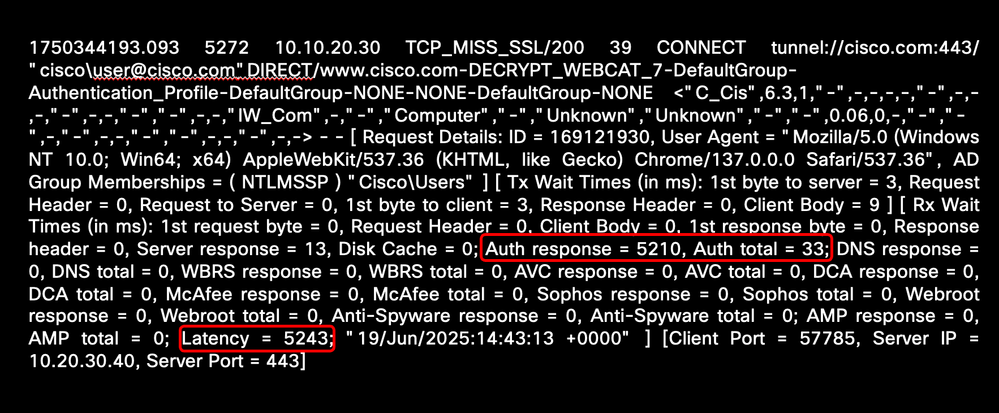 画像 – 認証遅延が大きい場合の例
画像 – 認証遅延が大きい場合の例
高いDNS時間
DNS応答時間が長い場合、TACがDNS遅延の問題をトラブルシューティングするには、次の情報が必要です。
-
現在のSWA設定
-
トレースモードのシステムログ
- DNSサーバのIPアドレス
-
パケットキャプチャ
-
クライアントマシン
-
SWA(DNSサーバのIPアドレスによるフィルタリング)
-
-
アクセスログのカスタムフィールドに%:<dと%:>dの両方が含まれていることを確認します
-
問題の再現中にクライアントからHARファイルを取得
DNSの設定とトラブルシューティングの詳細については、「Troubleshoot Secure Web Appliance DNS Service」のリンクを参照してください。
次の例は、DNS名前解決に関連する長い遅延時間を示しています。
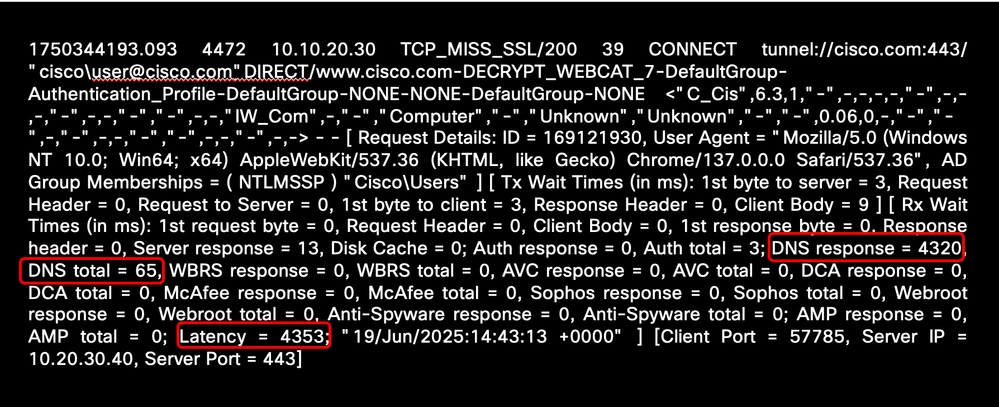 画像 – 高いDNS解決遅延の例
画像 – 高いDNS解決遅延の例
高いスキャンエンジン時間
Webレピュテーションスコア(WBRS)、Application and Visibility Control(AVC)、およびマルウェアスキャンエンジンの応答時間が長い場合、TACがスキャンエンジンの応答時間が長い問題をトラブルシューティングするには、次の情報が必要です。
-
現在のSWA設定。
-
応答時間の長いエンジンに応じて、ログレベルをdebugに変更します。
次の例は、Sophosエンジンに関連する高い遅延時間を示しています。
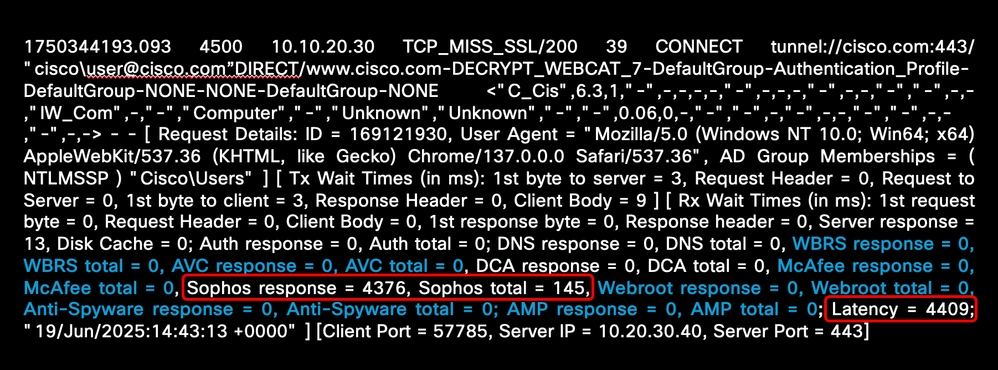 イメージ – マルウェアスキャンエンジンの高遅延
イメージ – マルウェアスキャンエンジンの高遅延
スキャンエンジンの応答が高い場合は、即時に回復するために、次の手順に従ってCLIからスキャンサービスを再開できます。
ステップ 1: diagnosticと入力してEnterキーを押します(これは隠しコマンドであり、正確なコマンドを入力する必要があります)。
ステップ 2: SERVICESを選択します。
ステップ 3:WBRSサービスを再起動するには、WBRSを選択します。それ以外の場合は、ステップ6に進みます。
ステップ 4:RESTARTを選択します。
ステップ 5:引き続きEnterキーを押してウィザードを終了します。
手順 6:マルウェアスキャンエンジンを再起動する場合は、ANTIVIRUSを選択します。
手順 7:スキャナを選択します。
ステップ 8:RESTARTを選択します。
ステップ 9: 引き続きEnterキーを押してウィザードを終了します。

警告:内部サービスを再起動すると、サービスが中断されます。この作業は、稼働時間外に行うか、注意して行うことを推奨します。
パケットキャプチャを接続する際のベストプラクティス
パケットキャプチャの実行中に、この情報を収集してCisco TACと共有してください。
- クライアントのIPアドレス.
- アクセスしようとしたURL。
- クライアントPCとSWAから、そのURLに対して解決されたIPアドレス。
- ユーザエクスペリエンス(ページが読み込まれなかったり、部分的に読み込まれたりする、エラーメッセージが表示された場合は、スクリーンショットを撮ってください)
- テストのタイムスタンプ。
- クライアントマシン上の他のすべてのブラウザとアプリケーションを閉じます。Webサイトにアクセスし、メモ帳でログをキャプチャして、成功/失敗を1回試行して、シスコサポートと共有します。
SWAでパケットキャプチャを実行する方法の詳細については、「コンテンツセキュリティアプライアンスでのパケットキャプチャの設定」のリンクを参照してください。
設定の複雑さ
高遅延と低パフォーマンスの別の一般的な原因は、設定の複雑さです。これは、SWAが過剰な数の条件、プロファイル、およびポリシーで設定されている場合に発生します。このような複雑な処理は、応答時間を大幅に増加させ、プロキシプロセスに大きな負荷を与える可能性があります。この問題は、トラフィックがピーク時間帯に最も高くなる傾向にあります。
設定を最適化するためのヒントを次に示します。
- HTTPS復号化の制限:セキュリティポリシーに不可欠なトラフィックのみを復号化します。セキュリティを維持しながら、可能な限り処理のオーバーヘッドを削減します。
- ポリシーの優先順位付けによる効率化:最も頻繁に使用するポリシーをポリシーリストの一番上に配置します。これにより、最も要求の厳しいトラフィックを最初に処理することで、処理の高速化を実現します。
- ポリシー設計の合理化:ポリシーの数を可能な限り最小限に抑えることで、ポリシーを簡素化します。これにより、不要な処理が減り、システム全体のパフォーマンスが向上します。
- アンチマルウェアおよびアンチウイルススキャンの最適化:スキャン設定でアンチマルウェアおよびアンチウイルスプロセスを確認します。これらはCPUに負荷がかかるため、微調整を行うとセキュリティを損なうことなくリソース消費を大幅に削減できます。
- 軽量の正規表現の使用:複雑な正規表現やリソースを大量に消費する正規表現を避けます。ドット(.)や星(*)などの文字を適切にエスケープして、処理の負担を軽減し、非効率を防ぎます。
SWAのベストプラクティスの詳細については、「セキュアWebアプライアンスのベストプラクティスの使用」を参照してください。
CLI コマンド
バージョン
versionコマンドを使用して、ハードウェア割り当て(仮想SWAの場合)とRAIDステータス(物理SWAの場合)を確認します。 ハードウェア構成を確認します。CPUコア、メモリ、およびハードディスクの数が予想どおりに割り当てられていることを確認します。 仮想モデルでは、RAIDステータスは「不明」と表示されます。物理アプライアンスでRAIDステータスが「機能縮退」または「障害」の場合は、Cisco TACに連絡してバックエンドからのディスクステータスを確認してください。
誤動作を引き起こす可能性があるSWAへの割り当てCPUの追加割り当ての例を次に示します。
SWA Lab> version
Current Version
===============
Product: Cisco S100V Secure Web Appliance
Model: S100V
BIOS: 6.00
CPUs: 3 expected, 4 allocated
Memory: 8192 MB expected, 8192 MB allocated
Hard disk: 200 GB, or 250 GB expected; 200 GB allocated
RAID: NA
RAID Status: Optimal
アラートの表示
根本原因を示す可能性があるSWAネットワーク関連のアラートメッセージを確認するには、displayalertsコマンドを使用します。
この例では、IPアドレス10.10.10.10のDNSサーバが応答しておらず、「The File Reputation service is not reachable」というメッセージがネットワーク接続の問題を示している可能性があります。
SWA LAB> displayalerts
Date and Time Stamp Description
--------------------------------------------------------------------------------
26 Mar 2025 11:20:07 +0500 The File Reputation service is not reachable.
26 Mar 2025 11:20:07 +0500 Critical: Reached maximum failures querying DNS server 10.10.10.10
26 Mar 2025 11:20:07 +0500 Critical: Reached maximum failures querying DNS server 10.10.10.10
26 Mar 2025 10:16:18 +0500 Warning: Communication with the File Reputation service has been established. プロセス_ステータス
SWA内部サービスのプロセスおよびメモリの使用量を表示するには、process_statusコマンドを使用します。
トラフィックプロキシを処理するメインプロセスであるProxプロセスの使用率が、数分間継続して100 %を超える場合、プロセスに高い負荷が続いていることを示します。ただし、Proxまたは他のプロセスでCPU使用率が一時的に一時的に上昇することは正常であり、予期されています。
SWA LAB> process_status
USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND
root 11 2805.4 0.0 0 512 - RNL 28Jun24 11863204:12.63 idle
root 71189 102.0 19.5 6670700 6478032 - R 23Feb25 18076:32.80 prox
root 91880 99.0 0.6 369564 214832 - R 28Jun24 58854:51.78 counterd
root 91267 76.0 0.9 379804 292324 - R 28Jun24 59371:01.26 counterd
root 12 25.9 0.0 0 1600 - WL 28Jun24 30899:57.88 intr
root 46955 25.0 0.2 91260 59336 - S 23Jan25 7547:02.96 wbnpd
root 95056 23.0 11.2 5369332 3710348 - I 28Jun24 31719:23.99 java
root 93190 12.0 1.4 3118384 456088 - S 01:15 29:57.05 beakerd
root 64579 11.0 0.2 101336 71204 - S 6Aug24 12074:55.55 coeuslogd
ステータスの詳細
status detailコマンドでは、システムリソースの使用状況、ネットワークトラフィックのメトリック、および接続統計情報の要約がリアルタイムで表示されます。この情報には、SWAの健全性とパフォーマンス全体が反映されます。GUIのSystem Statusビューをミラーリングし、迅速な監視とトラブルシューティングを実現します。
SWA LAB> Status detail
Status as of: Wed Mar 26 11:51:27 2025 PKT
Up since: Fri Jun 28 13:45:43 2024 PKT (270d 22h 5m 43s)
System Resource Utilization:
CPU 16.0%
RAM 10.3%
Reporting/Logging Disk 19.8%
Transactions per Second:
Average in last minute 1745
Maximum in last hour 2210
Average in last hour 1708
Maximum since proxy restart 2451
Average since proxy restart 615
Bandwidth (Mbps):
Average in last minute 149.699
Maximum in last hour 1356.387
Average in last hour 229.634
Maximum since proxy restart 22075.244
Average since proxy restart 60.689
Response Time (ms):
Average in last minute 99
Maximum in last hour 8194128
Average in last hour 87
Maximum since proxy restart 19608632
Average since proxy restart 28
Cache Hit Rate:
Average in last minute 3
Maximum in last hour 6
Average in last hour 2
Maximum since proxy restart 89
Average since proxy restart 2
Connections:
Idle client connections 3481
Idle server connections 754
Total client connections 21866
Total server connections 19049
SSLJobs:
In queue Avg in last minute 0
Average in last minute 12050
SSLInfo Average in last min 0
Network Events:
Average in last minute 16.0
Maximum in last minute 171
Network events in last min 151918
Ipチェック
ipcheckコマンドは、ハードウェア仕様、ディスク使用率、ネットワークインターフェイス、インストールされているソフトウェアキー、バージョンの詳細など、Secure Web Applianceの詳細なシステム情報を表示し、アプライアンスの現在の状態を包括的に示します。
SWA LAB > ipcheck
Ipcheck Rev 1
Date Fri Mar 21 16:34:56 2025
Model S100V
Platform vmware (VMware Virtual Platform)
Secure Web Appliance Version Version: 15.2.1-011
Build Date 2024-10-03
Install Date 2025-02-13 17:49:24
Burn-in Date Unknown
BIOS Version 6.00
RAID Version NA
RAID Status Unknown
RAID Type NA
RAID Chunk Unknown
BMC Version NA
Disk 0 200GB VMware Virtual disk 1.0 at mpt0 bus 0 scbus2 target 0 lun 0
Disk Total 200GB
Root 4GB 64%
Nextroot 4GB 65%
Var 400MB 38%
Log 130GB 24%
DB 2GB 0%
Swap 8GB
Proxy Cache 50GB
RAM Total 8192M
速度
rateコマンドを使用すると、接続レートおよび10秒ごとの1秒あたりの要求数が表示されます(TCPセッションの場合)。
SWA LAB> rate
Press Ctrl-C to stop.
%proxy reqs client server %bw disk disk
CPU /sec hits blocks misses kb/sec kb/sec saved wrs rds
100.00 1800 17 16352 1626 178551 178551 0.0 2366 0
100.00 1813 18 16453 1659 226301 224952 0.6 3008 0
99.00 1799 10 16338 1645 206234 206234 0.0 3430 1
高遅延のためのログ収集
アクセスログからの応答時間が長い、またはSHDログからのプロセス負荷が高い状況が発生しているかによって異なります。さらにトラブルシューティングを進めるには、対応するログサブスクリプションをDebugに変更することを推奨します。
警告:ログレベルをデバッグまたはトレースに設定すると、リソースの使用量が増加し、ログファイルがすぐにローテーションまたは上書きされる可能性があります。
|
アクセスログフィールド |
SHDログフィールド |
対応するログサブスクリプション |
|
認証応答、認証合計 |
— |
authlogs(認証) |
|
DNS応答、DNS合計 |
— |
system_logs(デフォルト) |
|
WBRS応答、WBRS合計 |
Wbrs_WucLd |
Cisco TACへの問い合わせ |
|
AVC応答、AVC合計 |
— |
avc_logs |
|
McAfee応答、McAfee合計 |
McafeeLd |
mcafee_logs |
|
Sophos応答、Sophos合計 |
SophosLd |
sophos_logs |
|
Webroot応答、Webroot合計 |
WebrootLd |
webrootログ |
|
AMP応答、AMP合計 |
AMPLd |
amp_logs |
関連情報
SHDログを使用した安全なWebアプライアンスのパフォーマンスのトラブルシューティング
コンテンツセキュリティアプライアンスでのパケットキャプチャの設定
更新履歴
| 改定 | 発行日 | コメント |
|---|---|---|
1.0 |
26-Jun-2025
|
初版 |
シスコ エンジニア提供
- マジェシュBテクニカルコンサルティングエンジニア
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)