Overview
The Common Execution Environment (CEE) is a software solution developed for monitoring mobile and cable applications that are deployed on the Subscriber Microservices Infrastructure (SMI). The CEE captures information (key metrics) from the applications in a centralized way for engineers to debug and troubleshoot.
The CEE is the common set of tools that are installed for all the applications. It comes equipped with a dedicated Ops Center, which provides the user interface (Command Line Interface) and APIs for managing the monitoring tools. There is only one CEE available for each cluster.
The CEE includes the following components:
-
CEE Ops Center - The CEE Ops Center allows users to configure and install the CEE. The CEE Ops Center contains the following components:
-
Metrics Collection - It includes functions such as reporting from Prometheus, alerting and Bulk statistics and so on.
-
Metrics Visualization - The metrics are displayed to the end users through a Grafana dashboard. The dashboard displays the key metrics such as CPU usage, memory, and disk input and output (I/O) utilization of each application deployed on the SMI. Use cases include:
-
Import custom Grafana dashboard from a GIT repository.
For more information, refer Grafana section.
-
-
Bulk Statistics - Configures application specific statistics, which are collected through the Gather TAC feature. The Bulk Statistics are automatically generated based on the user requirements at repeated intervals. Use cases include:
-
Generate query for current PDU per 4G session.
-
Generate query for current PDU per 4G IPv6 session.
-
View bulk statistics.
For more information, refer to the Configuring Bulk Statistics section.
-
-
Metrics Global Query - Thanos - a set of software components for metric system - provides the ability to perform global queries across multiple clusters. Use cases include:
-
In cable environment with multiple Kubernetes clusters, where instances of Prometheus collect metrics specific to cluster, a global Prometheus instance (set up as a part of an application Ops Center) is used as focal point to gather data and respond to queries for metrics from all Prometheus pods.
For more information, refer Cluster Monitoring section.
-
-
Alerting - Enables you to monitor applications, containers or nodes by setting up alert rules. The CEE uses the Prometheus Alert Manager for generating alerts. Use cases include:
-
Monitor the success rate of SMF session creation by configuring Prometheus alert rule to report if session creation is less than threshold.
-
Configure Prometheus alert rule to report if pod has restarted.
-
Alerts addon: If snmp-trapper is configured, alert is also sent as SNMP Trap to the receiving agent.
-
View active alerts.
-
View alerts history.
For more information, refer to the Configuring Alerts section.
-
-
Log Monitoring - The Kubetail utility in the CEE Ops Center allows end users to monitor the logs of an application in real time.
-
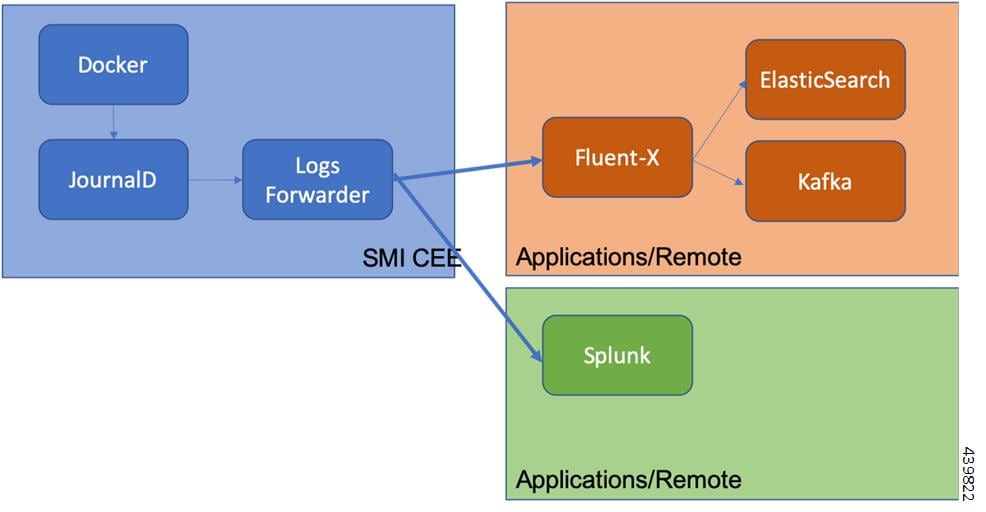
Log Forwarding - The Log Forwarding function collects and forwards all the logs to any of the third-party applications present in the customer infrastructure. Use cases include:
-
Configure log forwarding to an external Splunk server.
-
Configure log forwarding to an external Fluent-D or Fluent-Bit instance, where logs can be streamed to supporting application such as ElasticSearch.
For more information, refer Log Forwarding section.
-
-
Gather TAC - The Gather TAC function is used for creating log files at specified intervals of time. The logs are collected based on the pods that are deployed on the Kubernetes cluster. Use cases include:
-
When a Network Function (NF) exhibits some issues, the log collection can be configured to include data and statistics for the system and pods in a specific namespace within the last few hours.
-
For more information, refer Gather TAC section.
-


 icon on the left pane.
icon on the left pane.
 tab.
tab.
 Feedback
Feedback