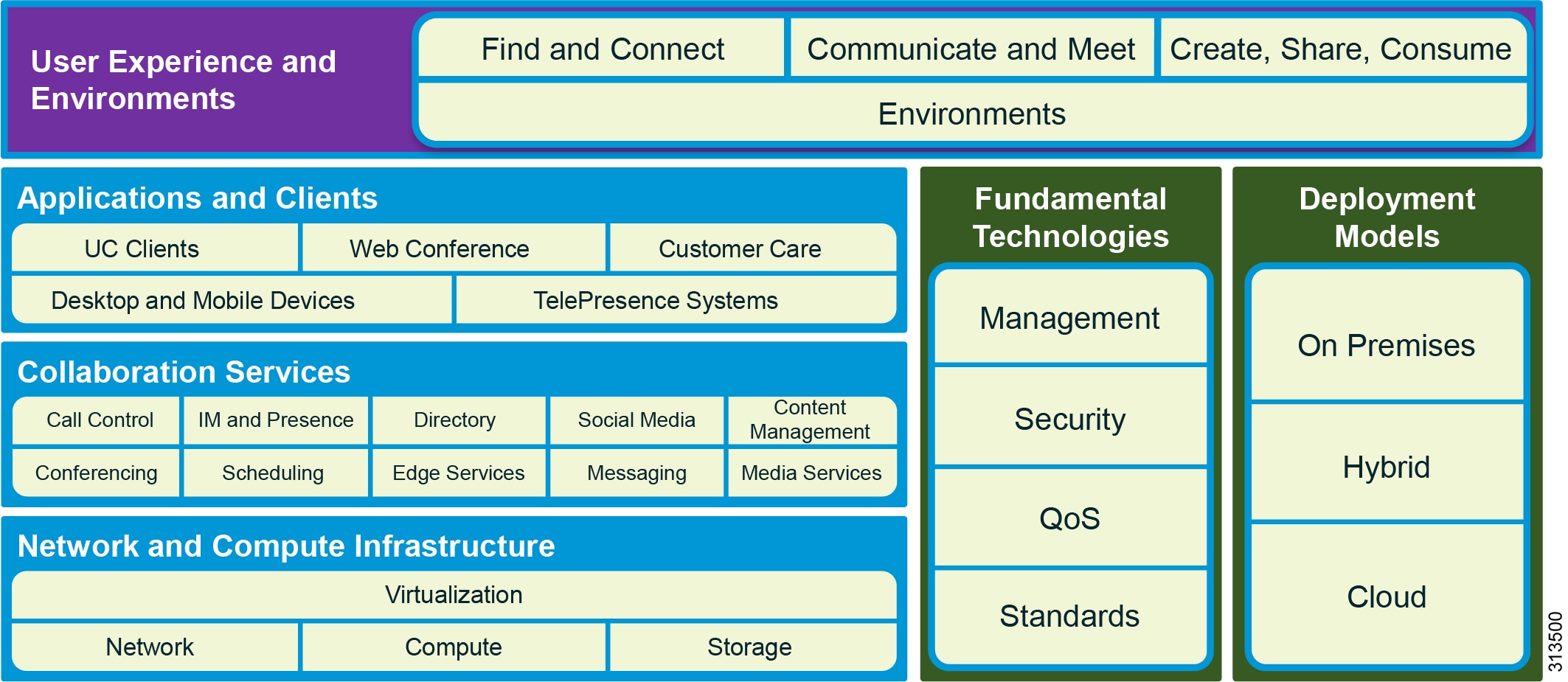
Architectural Overview
Cisco Hosted Collaboration Solution (HCS) provides industry-leading cloud collaboration services. The HCS data center design is based upon Cisco’s Virtualized Multi-Tenant Data Center (VMDC), later renamed to Virtual Multiservice Data Center, reference architecture. This architecture provides a framework for building fabric-based infrastructure using the Cisco Unified Computing System (UCS) platform as well as an Integrated Compute Stack (ICS). It is based upon traditional three-tier and two-tier data center architectures that brought forth a modular design to deliver networking, computing, and storage resources and services. The combined UCS and ICS form the basic data center building blocks called Points of Delivery (PoD). The PoD serves as a blueprint for the incremental build-out of the Cloud data center in a structured fashion. When resource utilization in a PoD reaches a pre-determined threshold (such as 70 to 80%), you can simply migrate to higher capacity resources (Aggregation or Services devices) or deploy a new PoD.
Starting in HCS 9.2(1) the three-tier, separate core model, was removed which allowed a significant increase in tenant (per customer) capacity. All references to an HCS PoD assumes this collapsed core model. HCS has two PoD architectures; Large PoD and Small PoD. The significant difference between the two is the aggregation switched used. A Large PoD leverages a Nexus 7000 series or Nexus 9500 series switch while a Small PoD leverages a Nexus 5600 series or Nexus 9300 series switch.
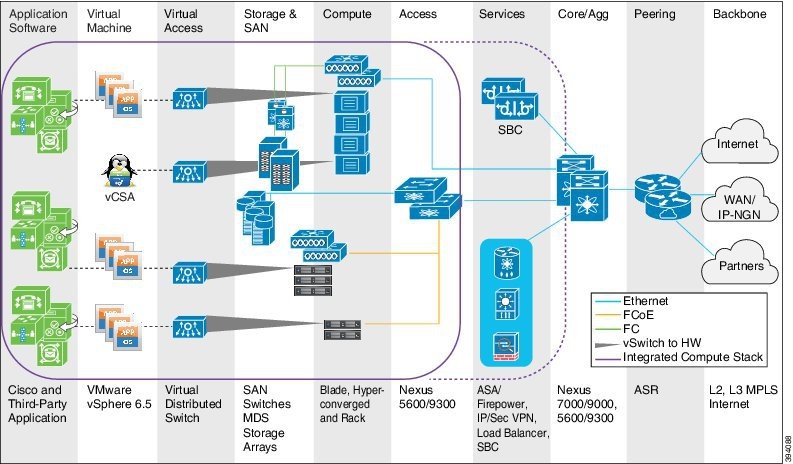
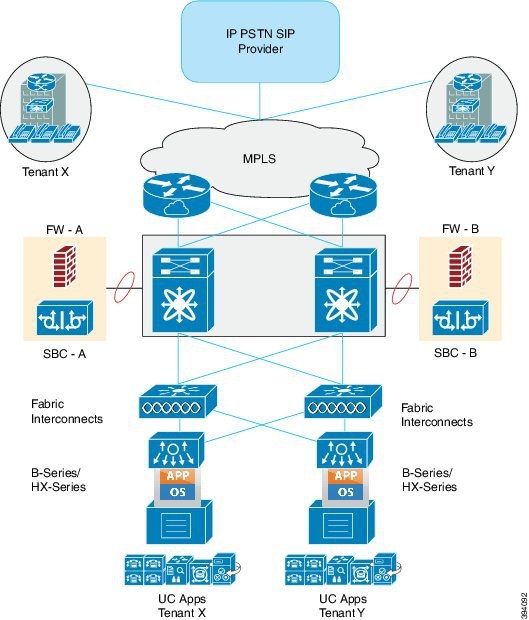
Today HCS may be deployed within a Cisco Powered Infrastructure as a Service (IaaS) model that not only includes VMDC but also Cisco Application Centric Infrastructure Fabric (ACI) designs. It also supports a Cisco Powered Hybrid Cloud model based exclusively upon ACI. The one caveat is that all HCS deployments required VMware vSphere as the cloud computing virtualization platform.
The focus of this document is around either HCS PoD deployment models based on VMDC and does not address ACI deployments.

 Feedback
Feedback