Cisco Unified Communications Domain Manager 10.6(x)/11.5(x)/12.5(x)
This topic describes about the reports, error messages, and troubleshooting.
Health Report
On sign-in, the system displays a health report indicating the status of the system before displaying the CLI user prompt. This health report shows the following:
host: AS01, role: webproxy,application,database, LOAD: 2.74
date: 2014-08-28 13:44:42 +00:00, up: 6 days, 5:23
network: 172.29.42.100, ntp: 196.26.5.10
HEALTH: NOT MONITORED
database: 20GB
DATABASE TRANSACTION SIZE: 21.75GB
DATABASE TRANSACTION COUNT: 500003
Failed logins: 1 since Thu Aug 28 13:44:47 2014 from atlantic.biz
mail - local mail management keys - ssh/sftp credentials
network - network management backup - manage backups
voss - voss management tools log - manage system logs
notify - notifications control database - database management
diag - system diagnostic tools schedule - scheduling commands
snmp - snmp configuration system - system administration
cluster - cluster management user - manage users
web - web server management drives - manage disk drives
security - security update tools app - manage applications
template - template pack creator
platform@development:~$
On sign-in, the system displays a health report indicating the status of the system before displaying the CLI user prompt. This health report shows the following:
host: AS01, role: webproxy,application,database, LOAD: 2.74
date: 2014-08-28 13:44:42 +00:00, up: 6 days, 5:23
network: 172.29.42.100, ntp: 196.26.5.10
HEALTH: NOT MONITORED
database: 20GB
DATABASE TRANSACTION SIZE: 21.75GB
DATABASE TRANSACTION COUNT: 500003
Failed logins: 1 since Thu Aug 28 13:44:47 2014 from atlantic.biz
mail - local mail management keys - ssh/sftp credentials
network - network management backup - manage backups
voss - voss management tools log - manage system logs
notify - notifications control database - database management
diag - system diagnostic tools schedule - scheduling commands
snmp - snmp configuration system - system administration
cluster - cluster management user - manage users
web - web server management drives - manage disk drives
security - security update tools app - manage applications
template - template pack creator
platform@development:~$
Logs
The system maintains a comprehensive list of logs under /var/log:
-
The platform/ directory has logs pertaining to the general platform.
-
apps.log contains application and process control logging.
-
db.log contains database logs spawned by system transactions.
-
backup.log contains all logging pertaining to backups.
-
cluster.log contains all control-level management of the cluster.
-
config.log contains information relating to the platform-level configuration.
-
execute.log contains low-level information about command execution.
-
notifications.log contains information relating to SNMP notifications.
-
reports.log contains information relating to system reports. Refer to the Scheduling section on how to create a report.
-
security.log contains low-level information relating to security updates.
-
ui.log contains higher-level information relating to UI commands being executed.
-
wsgi.log contains information relating to API-level commands via the WSGI server.
-
-
The provision/ directory contains logs relating to provisioning. Every module provision is logged to component log files.
-
The health/ directory contains health logs. The health logs are stored automatically every half hour, or whenever health is run, and are of the format health/summary_report-<date>-<time>.
-
The process/ directory contains process logs instrumental in debugging particular processes. All the output from each process is logged to an individual file process/<application>.<process>.log.
-
The install/ directory contains logs detailing the install process.
-
The mongodb/ directory contains logs relating to the Database function.
-
The nginx/ directory contains logs relating to the WebProxy function.
-
The voss-deviceapi/ directory contains logs relating to the Application function.
log list [<search_string>] is used to display a list of logs, optionally matching search_string. For example:
platform@clusternode:~$ log list alternatives.log
selfservice/alternatives.log
voss-deviceapi/alternatives.log
nginx/alternatives.log
mongodb/alternatives.log
alternatives.log
Once a filename is known, the particular log can be viewed with log view <logfile>, or watched (Unix terminology: tail –f) using log follow <logfile>, for example log view process/mongodb.router.log. When the log file is viewed, it can be searched for a particular regular expression using / as with the normal less command.
Log entries have key-value pairs. The keys are as follows:
-
hostname - the hostname of the server
-
level - debug level
-
message - the actual log message
-
name - module where log occurred
-
parent process id - Linux process parent id
-
process id - Linux process id
-
request uuid - identifier to group all logs generated in a request
-
username - user that generated the log
-
user hierarchy - users that generated the log’s hierarchy
-
txn_id - transaction uuid
-
txn_seq_id - transaction ID as seen in the GUI
-
toplevel_txn_seq_id - top level transaction ID
The attempts to auto-complete the prefix if it uniquely identifies a file, for example:
log view process/nginx
Single or multiple logfiles can be sent to a URI destination using log send <URI> <logfile> and log send <URI> <prefix> respectively. The URI must match the URI description detailed under the Networking section. An example of an email URI is mailto:user@server.com. Log files newer than a certain date can be sent using log sendnewer <yyyy-mm-dd> <URI>. If the remote URI destination requires a password, it prompts for the password. A passwordless scp session can be enabled by generating keys locally with key generate, and then sending the local keyset to the remote destination with key send user@<hostname>.
When using log send to a scp and sftp destination, no port should be specified.
All email communication requires notify emailrelay to be configured with the IP address of your mail relay.
Use log collect to collect logs into an archive file. System and database logs can be collected. Mandatory and optional parameters are available to refine the log collection.
The syntax is:
log collect start_time <start-time> output [logs|db|all] end_time <end-time> [limit]
-
The start_time and output parameters are mandatory.
-
The start_time and end_time format is +%Y-%m-%d_%H:%M:%S, for example, 2016-01-10_00:00:00.
-
The output options are:
-
db: collect database logs. By default, this includes transaction activity log records and the detail records of the content of transactions as seen on the GUI as the Log transaction list.
-
logs: collect system application log files from the /var/log directory. The start_time and end_time parameters don't affect the collection of system logs.
-
all:both database and system logs are collected
-
-
The limit option affects the database logs. It specifies that the detail records of transaction logs are not collected. This option is used if the collected logs are required for a task such as performance analysis and not for a task such as debugging.
Following is an example of the console input and output of the command:
$ log collect start_time 2016-01-10_00:00:00 output all
connected to: 127.0.0.1:27020
exported 240888 records
Output saved to media/logs.atlantic.2016-02-16_08-15-39.tar.gz
The log file archive format is logs.<hostname>.<timestamp>.tar.gz, where <timestamp> is the time that the collection was requested in the format %Y-%m-%d_%H-%M-%S. This file is created in the media/ directory.
The log file archive can then for example be fetched with scp.
The main log rotation scripts rotate the log files only when files exceed 100M or if the disk containing /var/log/ is over 80% full. This is checked once per day. The system attempts to keep five historic zipped files of each log. If the disk containing /var/log is over 90% full, files are purged to ensure that the system continues to function.
100M size logs:
-
mongodb/*.log
-
nginx/*.log
-
selfservice/*.log
-
voss-deviceapi/*.log
10M size logs:
-
other logs in /var/log/ and sub-directories are not specified above
Manually purge all the rotated log files and the log files exceeding 1GB using log purge.
The Mail Command
The system monitors a number of events. For more information, see Warnings and Notifications. The events can be signaled externally using email and snmp. However, a local copy of all events is maintained in the platform user's mailbox.
|
Command |
Description |
|---|---|
|
mail list |
Display a list of events stored in the mailbox. |
|
mail read all |
Read all mail. |
|
mail read <number> |
Read a specific mail message. |
|
mail del <number> |
Delete a specific mail message. |
|
mail del <from> <to> |
Delete a range of mail messages. |
|
mail del all |
Delete all mail messages. |
Mail events can accumulate over time. The system purges old events automatically, if the mailbox becomes full (more than 500 messages).
Diagnostic Tools
There is an extensive list of diagnostic tools available under the diag menu.
platform@development:~$ diag
USAGE:
------
diag disk - display diagnostics for disk usage
diag free - display diagnostics relating to free memory
diag health - display a health report
diag health report - save a health report as a logfile
diag iostat - IO subsystem statistics
diag iotop - IO metrics
diag largefiles - Find the largest files on your system no more than the top 10 items are display
diag mem - display memory diagnostics
diag monitor - update the system resource analysis. Use 'diag monitor list' to view the results
diag monitor list - display system resource analysis
diag nicstat - Network Interface Statistics
diag perf <commands> - Linux perf tools (try --help)
diag ping <host> - ping a remote host to test network reachability
diag proc - display a list of system processes
diag resolve <host> - resolve a hostname to IP address
diag tasks - display constant task listing
diag top - Process resource statistics
diag traceroute <host> - Discover the network path to <host>
diag unmttests - Run system unit tests
diag vmstat - Virtual Memory subsystem statistics
mail - local mail management keys - manage ssh / sftp credenti
network - network management backup - manage backups
voss - voss management tools log - manage system logs
cert - manage nginx certificates notify - notifications control
ssl schedule - scheduling commands
diag - system diagnostic tools system - system administration
snmp - snmp configuration user - manage users
drives - manage disk drives app - manage applications
security - security update toolsIn particular, the following are mostly used:
|
Command |
Description |
|---|---|
|
diag ping <host> |
Test network availability to a network host. |
|
diag resolve <hostname> |
Test DNS resolution of a hostname. |
|
diag free |
Display the memory usage. |
|
diag disk |
Display the disk usage. |
|
diag mem |
Display a more detailed memory usage by process. |
|
diag health |
Display a comprehensive health summary. |
|
diag top |
Display a single UNIX top summary. |
Diagnostic Troubleshooting
The health displayed on login normally includes sufficient information to determine that the system is either working, or experiencing a fault. More detailed health reports can be be displayed with diag health.
A rich set of SNMP and SMTP traps are described in the Notifications section which can be used to automate fault discovery.
Determine if all processes are running using app status. If a process is not running, investigate its log file with:
log view process/<application>.<process>
For example, checking processes:
platform@development:~$ app status
development v0.8.0 (2013-08-12 12:41)
voss-deviceapi v0.6.0 (2013-11-19 07:37)
|-voss-celerycam running
|-voss-queue_high_priority running
...
core_services v0.8.0 (2013-08-27 10:46)
|-wsgi running
|-logsizemon running
|-firewall running
|-mountall running
|-syslog running (completed)
|-timesync stopped (failed with error 1)
nginx v0.8.0 (2013-08-27 10:53)
|-nginx running
security v0.8.0 (2013-08-27 11:02)Followed by a log investigation for a stopped process:
platform@development:~$ log view process/core_services.timesync
2013-08-15 10:55:20.234932 is stopping from basic_stop
2013-08-15 10:55:20: core_services:timesync killed
successfully
2013-08-15 10:55:20: Apps.StatusGenerator core_services:timesync
returned 1 after 1 loops
App core_services:timesync is not running with status stopped
...
+ /usr/sbin/ntpdate 172.29.1.15
2014-02-04 09:27:31: Apps.StatusGenerator core_services:timesync
returned 0 after 1 loops
2014-02-04 09:27:31: WaitRunning core_services:timesync is reporting
return code 0
core_services:timesync:/opt/platform/apps/core_services/timesync
started
4 Feb 09:27:38 ntpdate[2766]: no server suitable for
synchronization found
+ echo 'Failed to contact server: 172.29.1.15 - retrying'
Failed to contact server: 172.29.1.15 - retrying
+ COUNTER=2
+ sleep 1
+ test 2 -lt 3
+ /usr/sbin/ntpdate 172.29.1.15
4 Feb 09:27:48 ntpdate[3197]: no server suitable for
synchronization found
+ echo 'Failed to contact server: 172.29.1.15 - retrying'
Failed to contact server: 172.29.1.15 - retrying
+ COUNTER=3
+ sleep 1
+ test 3 -lt 3
+ test 3 -eq 3
+ echo 'Timesync - could not contact server 172.29.1.15 after
three tries. Giving up'
Timesync - could not contact server 172.29.1.15 after
three tries. Giving up
+ exit 1The error message and return code being displayed in the browser is also invaluable in determining the cause of the problem.
The system resources can be inspected as follows:
-
diag disk displays the disk status
-
diag free and diag mem displays the memory status
-
diag top displays the CPU status
Warnings and Notifications
The system monitors a number of conditions and generate events as necessary.
Events are grouped into three categories:
-
Info messages that are informational, and do not require further attention
-
Warning notices that indicate that a recoverable event has occurred, and further action is not required.
-
Error notices that indicate a failure, and must be addressed.
The following conditions are monitored:
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Backups |
Backup failed |
Error Corrective action
|
|
Backups |
Backup successful |
Info |
|
Backups |
Backup restored successfully |
Info |
|
Backups |
Backup restore failed |
Error Corrective action
|
|
Backups |
Last successful backup more than 2 days ago |
Error Corrective action
|
|
Backups |
Backups are running regularly |
Info |
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Logs |
Forcing log rotation as disk usage is high |
Info |
|
Logs |
Autopurging logs due to excessive disk usage |
Warn |
|
Logs |
Log files larger than 1GB found in /var/log |
Error. : Corrective action |
|
Logs |
Normal log rotation is running |
Info |
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Disk usage |
Disk full |
Error Corrective action
|
|
Disk usage |
Disk usage greater than 80% |
Warn |
|
Disk usage |
Disk latency excessive (slow) |
Error Corrective action Monitor hardware performance using hardware specific tools such as Vsphere. |
|
Disk usage |
Disk latency returned to normal |
Info |
|
Disk usage |
Disk /var/log greater than 80% |
Error Corrective actions Purge logs with log purge. |
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Mailbox |
Mailbox full, > 500 messages, autoarchiving |
Info |
|
Mailbox |
Messages reduced < 200 |
Info |
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Notifications |
Email not configured for notifications |
Warn Corrective action Configure email address and mail relay. |
|
Notifications |
Email is configured for notifications |
Info |
|
Notifications |
SNMP trap failed to be sent |
Error Corrective action |
|
Notifications |
Test notification sent |
Info |
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Health reports |
Error sending health report through email |
Error |
|
Health reports |
Health reports successfully sent through email |
Info |
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Cluster |
One or more nodes down in the cluster |
Error Corrective action Check cluster status and restart node as necessary. |
|
Cluster |
No hosts defined in the cluster |
Error Corrective action Check cluster list and add nodes as necessary. |
|
Cluster |
All nodes in the cluster running |
Info |
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Network |
Network failure |
Error Corrective actions Check network cables, firewalling, routing and hardware. |
|
Network |
Network failure resolved |
Info |
|
Network |
NTP server is not configured |
Error Corrective action Ensure that the NTP server is set correctly with network ntp |
|
Network |
NTP server is configured |
Info |
|
Network |
NTP offset exceeds 1 second |
Warn Corrective action Check that the NTP server is correctly configured with network ntp and the NTP server is reachable and functioning correctly. |
|
Network |
NTP offset returns to normal |
Info |
|
Network |
DNS server is not configured |
Warn |
|
Network |
DNS server is now configured |
Info |
|
Network |
No DNS domain configured |
Warn |
|
Network |
DNS domain is configured |
Info |
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Applications |
Failed to start service |
Error Corrective action Check the application status with app status; service log with log view process/<application>.<process> |
|
Applications |
Services started successfully |
Info |
|
Aplications |
Upgrade failed |
Error Corrective action
|
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Security |
Security updates available |
Warn Required action: Run security update |
|
Security |
Security updates applied |
Info |
|
Condition |
Message type |
Detail and Action |
|---|---|---|
|
Resource usage |
High memory usage |
Error Corrective action
|
|
Resource usage |
Memory usage returned to normal |
Info |
|
Resource usage |
CPU has high utilization |
Warn |
|
Resource usage |
Extremely high CPU utilization |
Error. : ; Corrective action
|
|
Resource usage |
CPU utilization returned to normal |
Info |
SNMP CPU load notifications are set using:
snmp load <1min load> <5min load> <15min load>
If the threshold is exceeded, a notification is sent. For a server with 2 CPUs, it is recommended that this setting be:
snmp load 8 4 2
This means that notifications are sent if the 2-CPU system load averages over the last 1, 5, and 15 minutes reach these values.
The system can be configured to forward warnings and notifications to various destinations, including:
-
Local email
-
Remote email addresses
-
Remote SNMP destinations
The notification destinations can be displayed with notify list. The destinations for each event level can be set with notify add info|warn|error <destination-URI> Refer to the Network URI Specification topic for a detailed description of URIs. Note that email notifications require the mail relay to be set with notify emailrelay <relayhost>. A test event can be generated with notify test info|warn|error to test the notification delivery mechanism.
Examples:
-
notify add info mailto:sysadmin@mycompany.com
-
notify add error snmp://public@mysnmpserver.com
In addition to external email and SNMP alerts, the system also records various events to a local mailbox.
Error Messages
The following tables provide a reference to the error codes in the system.
To inspect application log messages from the command line, set the debug level on, and view the app log.
voss set_debug 1
log view voss-deviceapi/app.logThe message strings are shown in template format: references to specific properties are shown as placeholders that are represented by {}.
The HTTP Code is 400 unless specified otherwise.
|
Default Error Code |
Message |
HTTP Code |
|---|---|---|
|
0 |
Invalid Exception |
|
System Error Code |
Message |
HTTP Code |
|---|---|---|
|
0000 |
Error, Mongo service not started |
|
|
0001 |
Error, Server too busy |
|
|
0002 |
Error, Celery service not started |
|
Python Internal Error Code |
Message |
HTTP Code |
|---|---|---|
|
1000 |
Cannot import Python model name {} |
404 |
|
1001 |
Python Type error |
|
Database Error Code |
Message |
HTTP Code |
|---|---|---|
|
2000 |
Cannot setup Mongo DB collection {} |
|
|
2001 |
Find failed with spec={}, fields={}, skip={}, limit={}, sort_by={}, err={} |
|
|
2002 |
Find one failed with spec={}, fields={}, err={} |
|
|
2003 |
Get archive history failed with spec={}, fields={}, skip={}, limit={}, err={} |
|
|
2004 |
Remove failed with spec={}, err={} |
|
|
2005 |
Find and modify failed with spec={}, modify={}, err={} |
|
|
2006 |
Find and modify failed with spec={}, modify={}, err={} |
|
|
2007 |
Count failed for {} |
|
|
2008 |
Find failed with spec={}, fields={}, err={} |
|
|
2100 |
Error, Cannot connect to RESOURCE database collection |
|
|
2101 |
Error, Cannot connect to DATA database collection |
|
|
2102 |
Error, Cannot connect to ARCHIVE database collection |
|
|
2104 |
Bulk insert failed, err={} |
400 |
|
2999 |
Unhandled Database Error |
|
API Error Code |
Message |
HTTP Code |
|---|---|---|
|
3000 |
Hierarchy context may not be None, please select Hierarchy |
|
|
3001 |
Error, Incorrect request format |
|
|
3002 |
Error, Unhandled method for URL |
|
|
3003 |
Invalid import file specified. {} |
|
|
3004 |
Invalid export URL specified. {} |
|
|
3005 |
Error, Invalid list view sort key [{}]. Valid options are {} |
|
|
3006 |
Error, Invalid list direction [{}]. Valid options are {} |
|
|
3007 |
Error, No schema available during list view |
|
|
3008 |
Provisioning Workflow error [{}] |
|
|
3009 |
Nothing to export |
|
|
3010 |
List delete failed, error [{}] |
|
|
3011 |
List size not allowed, requested [{}], maximum [{}] |
|
|
3012 |
List sort by hierarchy path not allowed |
|
|
3013 |
Function not implemented |
|
|
3014 |
Attribute field name required |
|
|
3015 |
Hierarchy path [{}] not found. |
|
|
3016 |
Model type list [{}] not found. |
|
|
3017 |
Bulk update failed, error [{}]. |
|
|
3018 |
Bulk operation {} failed, error [{}]. |
|
|
3019 |
Schemas of data being imported have cyclic foreign keys {}. |
|
|
3027 |
The current filter caused a long running request. Please add more filter fields, use Case Sensitive or change the criteria types to one of {}. |
400 |
|
3999 |
Unhandled API Error |
|
Resource Error Code |
Message |
HTTP Code |
|---|---|---|
|
4000 |
Error, Cannot delete Resource while children exist {} |
|
|
4001 |
Error, Duplicate Resource Found. {} |
|
|
4002 |
Resource Not Found {} |
404 |
|
4003 |
Failed to save {}. {} |
|
|
4004 |
Failed to save {}. {} |
|
|
4005 |
Model Type cannot be None when adding a new Resource |
|
|
4006 |
Resource Parent {} not found |
|
|
4007 |
Resource Meta structure corrupt for {} |
|
|
4008 |
Cannot create a Resource without a Parent Hierarchy |
|
|
4009 |
Failed to save {}. {} |
|
|
4010 |
Cannot find Resource relation {} |
|
|
4011 |
Cannot find target device for model type {} in current hierarchy context |
|
|
4012 |
Cannot find summary attr [{}] in schema root |
|
|
4013 |
Cannot perform operation, model {} already has one or more instances |
|
|
4014 |
Cannot perform operation, resource is part of domain model {} |
|
|
4015 |
Resource Meta structure corrupt. {} |
|
|
4016 |
Badly-formed schema; properties missing for data type object |
|
|
4017 |
Cannot perform operation, model {} is already referenced by one or more resources: {} |
|
|
4018 |
Failed to execute {}. {} |
|
|
4019 |
One or more errors occurred during import |
|
|
4020 |
Transaction resource failed with errors {} |
|
|
4021 |
Resources are not of the same type |
|
|
4022 |
Model type for Resources not found |
|
|
4023 |
Cannot move Hierarchy Node {} to {} |
|
|
4024 |
Resource move failed with error {} |
400 |
|
4025 |
Invalid business key {}, expected {} |
|
|
4026 |
Cascade delete failed with error {} |
400 |
|
4999 |
Unhandled Resource Error |
|
Model Error Code |
Message |
HTTP Code |
|---|---|---|
|
5000 |
[{}] Child model exists; ({}) |
|
|
5001 |
[{}] Model already exists; ({}) |
|
|
5002 |
[{}] One or more data sync errors occurred; ({}) |
|
|
5003 |
[{}] The helper cannot instantiate a model it does not recognize; ({}) |
|
|
5004 |
[{}] The specified resource could not be found; ({}) |
404 |
|
5005 |
[{}] A single model instance was expected but more than one was found; ({}) |
404 |
|
5006 |
[{}] Attempt to modify a read-only model failed; ({}) |
|
|
5007 |
[{}] Attempt to modify a read-only model field failed; ({}) |
|
|
5008 |
[{}] Data does not conform to schema; {} |
|
|
5009 |
[{}] Badly-formed schema; ({}) |
|
|
5010 |
[{}] Error manipulating schema; ({}) |
|
|
5011 |
[{}] Error generating schema; ({}) |
|
|
5008 |
[{}] Invalid foreign key to {} for business keys {} |
|
|
5017 |
[{}] Operation not supported; ({}) |
405 |
|
5018 |
Unable to determine workflow for operation {} |
|
|
5019 |
Workflow {} not found |
|
|
5020 |
Workflow operation {} clashes with an existing model attribute/method |
|
|
5021 |
Unable to execute provisioning workflow for {}, error {} |
|
|
5022 |
Unable to compile data for provisioning workflow for {}, error {} |
|
|
5022 |
[{}] Authentication error; ({}) |
401 |
|
5023 |
[{}] Connection timeout error after ({}) seconds |
|
|
5024 |
[{}] Connection error; ({}) |
|
|
5051 |
New password must have {} characters different from old password. |
400 |
|
5052 |
User cannot change their password more than once within {} day(s). Please contact your administrator. |
400 |
|
5053 |
Password does not meet minimum length required. |
400 |
|
5998 |
{1} |
|
|
5999 |
[{}] Unexpected error; ({}) |
|
Macro Error Code |
Message |
HTTP Code |
|---|---|---|
|
6000 |
Template must be a dictionary - got {} |
|
|
6001 |
No hierarchy supplied |
|
|
6002 |
Invalid macro specified: {} |
|
|
6003 |
Macro lookup of {} failed at hierarchy {} |
|
|
6004 |
Macro lookup of {} returned multiple values {} at hierarchy {} |
|
|
6005 |
Macro lookup of {} failed when fetching from {} at hierarchy {} |
|
|
6006 |
Macro lookup failed for field {} in context {} |
|
|
6007 |
Macro lookup failed for field {} in context {}, type str or int expected not type dict {} |
|
|
6008 |
Macro function {} not found |
|
|
6009 |
Macro function arguments error - {} |
|
|
6010 |
Macro function error - {} |
|
|
6011 |
Unexpected business key format - {} |
|
|
6018 |
Incorrect hierarchy direction, {}. Allowed: {}. |
|
|
6999 |
Error, |
|
Workflow Error Code |
Message |
HTTP Code |
|---|---|---|
|
7000 |
Workflow not found |
|
|
7001 |
Maximum workflow recursion depth exceeded |
|
|
7002 |
Invalid workflow script identifier {} |
|
|
7003 |
Specified workflow script name {} not found |
|
|
7004 |
Error looking up workflow script names against API |
|
|
7005 |
Invalid workflow action |
|
|
7006 |
Workflow {} at step {} failed. {} |
|
|
7007 |
Advanced Find Options invalid - Resource not found with options {} |
|
|
7008 |
{} |
|
|
7999 |
Error, |
|
Script Error Code |
Message |
HTTP Code |
|---|---|---|
|
8000 |
Script not found |
|
|
8002 |
Syntax error on line {} |
|
|
8003 |
Could not connect to {} |
|
|
8004 |
Authentication failed {} |
|
|
8999 |
Error, |
|
Schema Error Code |
Message |
HTTP Code |
|---|---|---|
|
9000 |
Unhandled schema property error: [{}] |
|
|
9999 |
Error, |
|
Bulk Loader Error Code |
Message |
HTTP Code |
|---|---|---|
|
10012 |
‘{user}’ is not permitted access to resources at ‘{hierarchy}’. |
403 |
|
10021 |
Action ‘{action}’ not allowed. |
400 |
|
10050 |
Cannot enforce data type ‘{data_type}’ on ‘{data}’. Row data:{row_data} |
400 |
|
10006 |
Both parallel and serial are not allowed in ‘{worksheet}’. |
400 |
|
10047 |
Malformed entity header ‘{header}’ in cell ‘{cell}’ worksheet ‘{sheet}’. |
400 |
|
10045 |
Malformed fields{message}: {fields}. |
400 |
|
10007 |
Differing parallel_transaction_limit values are not allowed in ‘{worksheet}’. |
400 |
|
10004 |
{success} out of {total} items loaded successfully. |
400 |
|
10000 |
File Upload Error for filename : ({}) |
400 |
|
10005 |
Resource data was not found in worksheet ‘{worksheet}’. |
400 |
|
10052 |
The specified meta_prefix ‘{meta_prefix}’ in sheet ‘{sheet_name}’ is in-valid. |
400 |
|
10041 |
No search fields specified in row. |
400 |
|
10011 |
Hierarchy not specified for row with data; ({}) |
400 |
|
10003 |
General Error; ({}) |
400 |
|
10044 |
Malformed search fields: {fields}. |
400 |
|
10043 |
Resource not found. Search fields ‘{search}’. |
400 |
|
10001 |
File Encoding Error : ({}) |
400 |
|
10010 |
Data does not conform to schema; ({}) |
400 |
|
10008 |
Invalid value of ‘{limit}’ for parallel_transaction_limit header in ‘{worksheet}’,should be left blank or a number between 1 and 100(inclusive). |
400 |
|
10042 |
More than one resource found. Search fields ‘{search}’. |
400 |
|
10020 |
Hierarchy ‘{hierarchy}’ was not found. |
400 |
|
10051 |
An internal error occurred while processing workbook ‘{filename}’{note} |
400 |
|
10046 |
Cannot find meta actions for specified resource instance. |
400 |
|
10002 |
Only valid Excel xlsx files are accepted |
400 |
|
10030 |
User ‘{username}’ is not allowed to {operation} {model_type}. |
403 |
|
10022 |
Action ‘{action}’ not allowed for model ‘{model}’. |
400 |
|
10040 |
Fields do not exist in {model}: {fields}. |
400 |
|
10061 |
No match for device ‘{device}’. |
400 |
|
Data Import Error Code |
Message |
HTTP Code |
|---|---|---|
|
11000 |
Multiple json files {} found in zip archive root; only 1 expected |
|
|
11999 |
Error, |
|
Test Connection Error Code |
Message |
HTTP Code |
|---|---|---|
|
12000 |
Please specify the model type of the device connection parameters |
|
|
12999 |
Error, |
Cisco Unified Communications Domain Manager Version Information
To find detailed information about your version of Cisco Unified Communications Domain Manager:
-
Log in as hcsadmin administrator.
-
Select .
-
Click the HcsBase version.
The following information is displayed:
Field
Description
Name
Always HcsBase
Release
The Cisco Unified Communications Domain Manager release
Version
The version of the template file.
Previous Version
The previous version of the template file, if the template has been upgraded or reinstalled.
Build Number
Cisco's build number associated with this load
Branch
Development branch
View
Development view
Build Time
Build Time associated with this load
Author
Always Cisco HCS Base
Deployment Mode
HCM Standard
Platform Version
Matches the installed OVA file version or the version of the latest Cisco Unified Communications Domain Manager upgrade ISO file. The platform version is not displayed if an HCM-F device has not been configured in Cisco Unified Communications Domain Manager.
-
To export the detailed version information, select .
Single Sign On (SSO)
Troubleshooting Self-Provisioning
Getting Started
Inspect transactions and user management logs:
-
Check Transactions:
-
Check User Management logs:
-
Check configurations
When Cisco Unified Communications Domain Manager is using LDAP for user management and new users synced with LDAP are not pushed to Cisco Unified Communications Manager confirm Auto Push Users is checked in .
When users are pushed to the call manager with an incorrect Primary Extension and Self Service ID check that the Line Mask is correct under . Line Mask should exist for each site.
Troubleshooting Specific Failures
Line is not created
-
Ensure that the Directory Number Inventory exists and the number is not in use.
-
If the line mask is applicable, check the following
-
Ensure that the ULT has a site-specific partition
-
Ensure that the Line Mask is configured
-
Ensure that the User Profile is configured and set in the Site Defaults
-
Ensure that the user's attribute value is valid and that the mask is applicable
-
-
For setting the Self-Service Id, check the following - Ensure Site Defaults default line partition is set - Check Quick Add Group configuration
Users are not in correct sites
Check that filters for each site exist in Manage Filters under User Management.
Users are not getting correct User Profile
Check that the correct User Profile is populated under Default User Profile in .
Quick Add subscriber not getting correct User Profile in Cisco Unified Communications Call Manager
Check that the correct Quick Add Group is selected for Quick Add Subscriber. If correct Quick Add Group is selected, open the Quick Add Subscriber Group and check that the correct template is selected for Default Cisco Unified Communications Manager User Template.
Users are unable to log in to Self Service page
Check that the users are LDAP Authenticated Users. Only the LDAP Authenticated Users can log into the Self Service page.
AD LDS LDAP Synced Users Login Failure
If the LDAP Username is not correctly mapped when defining the LDAP Sync, users synced from an AD LDS LDAP server cannot log in to Cisco Unified Communications Domain Manager. Use this procedure to correct the problem.
Procedure
| Step 1 |
Login as provider administrator. |
| Step 2 |
Set the hierarchy path the customer node where the LDAP server is configured. |
| Step 3 |
Purge the LDAP synced users.
|
| Step 4 |
Delete the LDAP Sync with incorrect mapping.
|
| Step 5 |
Readd the LDAP Sync with the correct mapping.
|
| Step 6 |
Sync the users from LDAP.
|
| Step 7 |
Log in as an LDAP synced user with username@hierarchy. Example: |
Unable to Configure UC Applications 10.5(2)
- Symptom:
-
When you try to configure a 10.5(2) UC App in Cisco Unified Communications Domain Manager, 10.5 is not available as the UC App Version.
- Resolution:
-
Ensure that HCM-F has been upgraded to 10.6(2), and that the HCM-F device on Cisco Unified Communications Domain Manager has the version set to v10_6.
Transactions
Transaction Logging and Audit
Activity on the system results in transactions that are recorded. The Transaction menu provides auditing information for each transaction.
The recorded information includes:
-
Transaction ID - Identifier of the transaction
-
Action - The type of action that is recorded in the transaction, for instance Execute, Create, Modify, Data Import, and so on.
-
Resource - the affected resource of the transaction, including the model type (for example, data or User), and its hierarchy.
-
Username - Of the user who initiated the transaction.
-
Submitted Time, Started Time, and Completed Time - The date and time of the progress of the transaction.
-
Rolled Back - Indicates whether the transaction was rolled back or not.
-
Status - for running transactions, this is In Progress; for completed transactions there are three scenarios:
-
Fail
-
Success
-
Success with Async failure
-
-
Detail - A brief description of the processed transaction.
-
Duration - The duration of the selected transaction. If there are subtransactions, this parent transaction duration is the total duration of the transaction. This includes the total duration of import transactions that carry out provisioning workflows asynchronously.
-
Submitter hostname - The hostname of the application node that scheduled the transaction. On a clustered system, this can differ from the Processor hostname.
-
Processor hostname - The hostname of the application node that processed the transaction (this value is only set once the transaction is processed). On a clustered system, this can differ from the Submitter hostname.
The Unified CDM GUI displays the transaction details upon selection of transaction in the list view.
When a transaction is selected, the Base tab shows details of the columns of the transaction list view. The button bar on the detail list view shows Help and Refresh buttons if the transaction is still running. If the transaction is running, click the Refresh button to update the Progress field.
If you want to cancel a transaction while it is running, click the Cancel button. A pop-up confirmation dialog is displayed. Click Yesto cancel, or No to cancel the request. If a transaction, with subtransactions, is cancelled, the subtransaction currently in progress completes. This subtransaction and all preceding subtransactions rolls-back to their previous states. Bulk load transactions do not follow this behavior. Each bulk load subtransaction is seen as a main transaction, and only the ‘in progress’ subtransaction rolls back to its previous state.
The Replay button is available if the transaction is complete. A transaction can be replayed if necessary, for example if a transaction failed because a target system service was not running. The replay of the transaction can then be used instead of reentering data on a GUI form.
The Edit and Replay button is also available for completed transactions. This is similar to the Replay button, but allows you to first change the previously submitted form before the transaction is resubmitted.
The button is available for transactions, that did not originate from bulk loads, wizards, or pop-up forms.
The bulk loader does not support Replay; and Edit and Replay functionalities because the bulk load files are not stored by default. The bulk loader extracts data from the spreadsheets and then performs the necessary actions. The only time a bulk load file is stored in the database is when the bulk load is scheduled. In this case, the bulk loader keeps the file until it triggers the scheduler to execute the actions in the file. When the data is extracted from the file, it is deleted.
When using Edit and Replay for a failed Quick Add Subscriber transaction, the user information fields do not automatically update when changing the Username field:
-
Entitlement Profile
-
Firstname
-
Lastname
-
Email
-
Jabber Device
These are edited manually.
Selecting the button opens the original input form that resulted in the transaction. The form also contains the original data that was posted. This data can be edited and the form can be submitted to replay the transaction. This functionality can therefore be used, for example, to edit a failed transaction or to modify data of a successful transaction.
Since GUI Rules apply to a form from a specific hierarchy, the Edit and Replay functionality is only used from the same hierarchy as the original transaction was executed.
The Logs section on the Transaction base tab displays Message and Severity details of transactions that are performed by . For example, if the Severity has the status of error, the Message section can be expanded to inspect the error, and optionally copy it and send it to Support. If a workflow is inspected, a separate log entry provides details of each step with a log message as Step n, starting with Step 0.
The Resource tab, which has content for transaction types where a resource changed, displays the additional information, depending on the transaction type:
-
Hierarchy - The point in the hierarchy at which the transaction occurred.
-
Model Type - For example, data or User.
-
Current State - if available, click the Entity link to inspect the instance on the GUI form.
The Back button on the button bar can be used to navigate to the previous screen; for example, from the parent transaction screen to the list view of all transactions.
View a Transaction
You can only view transactions that are relevant to your specific hierarchy level. For instance, if you are logged into the system as a Customer Administrator, you can view all transactions that were performed at the customer for which you are the administrator. This includes transactions that were performed at any of the sites that belong to the customer. If you are logged in as a Site Administrator, you can view only the transactions that were performed at your specific site. Follow the steps on the GUI.
Procedure
| Step 1 |
Log in as the sysadmin administrator. |
| Step 2 |
Click . The Transaction list view is displayed. The Transaction list view shows transactions in progress or executed. This is indicated in the Status column of the list. For completed transactions, the Success column indicates if the transaction was successful. The Description column provides additional details on the transaction, if available. |
| Step 3 |
Click an individual transaction (if required) to show a detailed view of the transaction. |
| Step 4 |
If there are subtransactions, click the Link in the Sub Transactions list to show its details. |
Transaction Choices
A URL endpoint and parameter is available to list the transaction actions as they are shown in the transaction log.
-
The API call to get the list of transaction actions use the parameter and value: field=action, for example: GET api/tool/Transaction/choices/? field=action& hierarchy=[hierarchy]& format=jsonThe output shows the list of transaction actions: [ { "value": "Auto Migrate Base Customer Dat", "title": "Auto Migrate Base Customer Dat" }, { "value": "Auto Migrate Base Provider", "title": "Auto Migrate Base Provider" }, { "value": "Auto Migrate Base Site Dat", "title": "Auto Migrate Base Site Dat" }, { "value": "Auto Migrate Dial Plan", "title": "Auto Migrate Dial Plan" }, { "value": "Auto Migrate Feature Subscriber Phone Cft", "title": "Auto Migrate Feature Subscriber Phone Cft" }, { "value": "Auto Migrate Hotdial Data", "title": "Auto Migrate Hotdial Data" }, { "value": "Auto Migrate Init Ippbx", "title": "Auto Migrate Init Ippbx" }, { "value": "Auto Migrate Internal Number Inventory", "title": "Auto Migrate Internal Number Inventory" },
Transaction Details
The Detail column of the list of transactions in the transaction log user interface shows information according to the type of entity and the operation carried out by the transaction.
The rules listed below are considered when creating a transaction filter and specifying the value of the filter text.
| Action | Entity | Comment |
|---|---|---|
|
Create, Update, Clone, and Delete |
All models | Detail contains the name on the model. |
| Execute |
DataSync, Workflow, Event, Scheduler |
Detail contains the instance name. |
|
Bulk operations on Modify, Delete, Move |
All models |
|
| Data Import | All models | Detail shows only the imported filename. |
|
Device Import |
All devices | Detail shows hostname or device address. |
| All operations | All models |
The following attribute values are considered first for inclusion in the Detail column: country_name, DialPlanName, name, ip, host, address, description, username, type, entity_id, userid, pattern, RoleCurrent. Otherwise, the first string field in the view or in the left model of the relation is shown. |
 Note |
The contents of the Detail column of transaction lists are not localized. |
Transaction Filters
In addition to the filter parameters that can be applied to transactions as indicated in the topic on API Parameters, transactions in particular can be filtered by the following values:
-
For the URL parameter filter_field:
-
Transaction ID: id
-
Start or end submitted time: submitted_time
-
The transaction message: message
-
-
Use URL paramter to list subtransactions and value subtransactions=true. By default, subtransactions are not listed, in other words, the value is false.
-
To carry out a filter on subtransactions of a parent transaction, the /sub-transactions/endpoint is added to the GET request:
/api/tool/Transaction/[parent-pkid]/sub-transactions/ -
To carry out a filter on transaction logs of a parent transaction, the /logs/ endpoint is added to the GET request:
/api/tool/Transaction/[parent-pkid]/log/The transaction filters do not apply to logs.
The parameters can have the filter_condition values:
-
eq (equals)
-
ne (not equals)
-
gt (greater than)
-
gte (greater than or equals)
-
lt (less than)
-
lte (less than or equals)
The date-time is a filter_text value for filter_field=submitted_time.
The format is YYYY-MMDDTHH: MM:SS.f, where:
-
“T” is the time separator and the character is added.
-
“Z” indicates UTC time and the character is added.
-
“f” represents the decimal fraction of a second and the character is not added. The specification of the decimal fraction is optional.
Transaction Behavior
The transaction engine for ensures that configuration changes are made efficiently and reliably.
If a transaction failure or error occurs, Unified CDM lets you roll transactions back to a state preceding the failed transaction.
For example, where a workflow step fails, all successful steps before a failed step are rolled back.
Transactions are hierarchical and have parent-child relationships with other transactions. Subtransactions are always executed sequentially and synchronously. In other words, the child transactions of a workflow parent transaction are executed one after another.
Transaction behavior is different for the following actions in the system:
-
API
The API supports executing transactions in both synchronous and asynchronous modes. When executed in synchronous mode, the API responds only after the transaction is completed. When executed asynchronously, the API responds immediately with a transaction ID so that the progress and status of the transaction can be polled.
-
Bulk Loaders
With bulk loading, the load of each row on a sheet is a separate transaction. These transactions are run in series. There is no rollback of rows that have loaded successfully before or after a failed transaction (a failed row on a sheet). Multiple bulk load sheets can be loaded in parallel.
-
Data Import
One transaction is created for each record in the import file. If a transaction fails, the import continues and does not roll back the preceding successful transactions.
-
Data Sync
A data sync transaction contains subtransactions that record each device model operation that takes place during a data sync action, for example add, update and delete.
-
Events
Events are triggered as part of data sync operations or as triggers on operations performed on certain model types. The provisioning workflow executed when the event triggers is executed as a new parent transaction. Transaction failures with the workflow executed after an event do not affect the original transaction that triggered the event.
All transactions are placed on a queue before they are run. Parent transactions can run concurrently, but their subtransactions run serially. Parent transactions are prioritized so that user input, such as adding on a GUI form, is prioritized over a running import or bulk load process.
The following diagram shows an example transaction flow and also the relationship between parent and child transaction queues and workers.
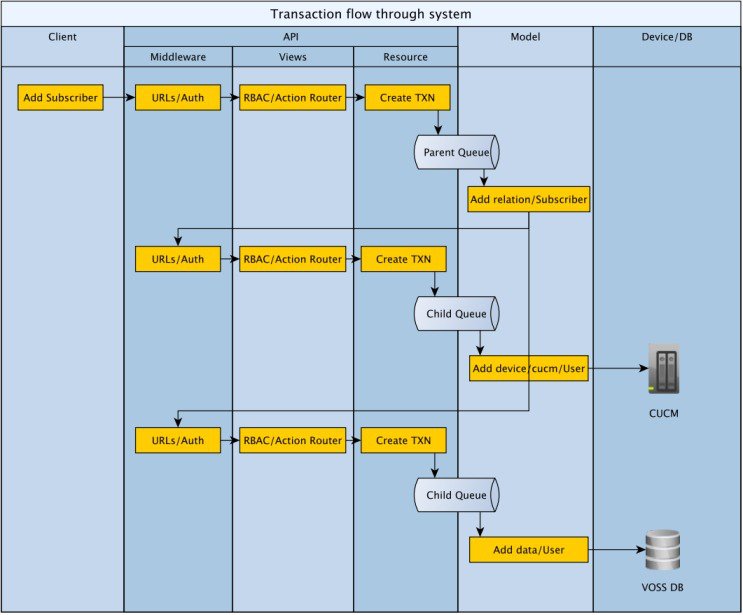
Cluster Failure Scenarios
Cluster Failure Scenarios
The status of the cluster can be displayed from the command line on any node using the command:
cluster status
The system can automatically signal email and SNMP events if a node is found to be down.
Refer to the diagrams in the section on deployments.
- Loss of an Application Role
-
The Web Proxy keeps directing traffic to alternate application role servers. There is no downtime.
- Loss of a Web Proxy
-
Communication with the lost Web Proxy fails, unless some another load balancing infrastructure is in place (DNS, external load balancer, VIP technology). The node can be installed as a HA pair so that the VMware infrastructure restores the node if it fails. Downtime takes place while updating the DNS entry or returning the Web Proxy to service. For continued service, traffic can be directed to an alternate Web Proxy or directly to an Application node if available. Traffic can be directed manually (in other words, network elements must be configured to forward traffic to the alternate Web Proxy).
-
Primary Unified Node (UN1) database weight = 40
-
Secondary Unified Node (UN2) database weight = 30
-
Secondary Unified Node (UN3) database weight = 20
-
Secondary Unified Node (UN4) database weight = 10
The Unified CDM system automatically assigns Voting Members to the Unified Nodes that are based on their DB weights noted previously for four Unified Nodes:
-
Primary Unified Node (UN1) Voting Members = 2
-
Secondary Unified Node (UN2) Voting Members = 2
-
Secondary Unified Node (UN3) Voting Members = 2
-
Secondary Unified Node (UN4 ) Voting Members = 1
In the sections that follows, it is assumed that the service provider has assigned the recommended database (DB) weights, for six Unified Nodes in active/standby setup, as follows:
-
Primary Unified Node (UN1) database weight = 60
-
Secondary Unified Node (UN2) database weight = 50
-
Secondary Unified Node (UN3) database weight = 40
-
Secondary Unified Node (UN4) database weight = 30
-
Secondary Unified Node (UN5) database weight = 20
-
Secondary Unified Node (UN6) database weight = 10
The Unified CDM system automatically assigns Voting Members to the Unified Nodes based on their DB weights noted previously for Six Unified Nodes:
-
Primary Unified Node (UN1) Voting Members = 2
-
Secondary Unified Node (UN2) Voting Members = 1
-
Secondary Unified Node (UN3) Voting Members = 1
-
Secondary Unified Node (UN4) Voting Members = 1
-
Secondary Unified Node (UN5) Voting Members = 1
-
Secondary Unified Node (UN6) Voting Members = 1
The relative size of the database weights determines the hierarchy of the nodes in a failure scenario. The Unified Node (UN) with the highest database weight is the Primary.
The number of Voting Members is used to establish a quorum, and is the basis for the behavior of the system in a multinode failure scenario. There are a total of seven Voting Members, the default value in a four node system is (2 + 2 +2 +1) and default value in a six node system is (2+1+1+1+1+1).
The subsequent tables illustrate the behavior of the system in various failure scenarios. In all cases where a UN has failed, it is assumed that the entire node (and therefore the database function referenced earlier in this section) is out of service. Any in-flight transactions on nodes that failed are lost.
|
UN1 State [Voting Members = 2] (Primary) |
UN2 State [Voting Members = 2] |
UN3 State [Voting Members = 2] |
UN4 State [Voting Members = 1] |
System Status under Scenario |
|---|---|---|---|---|
|
In Service |
In Service |
In Service |
In Service |
System is functioning normally. |
|
In Service |
In Service |
In Service |
Fail |
System continues functioning normally. |
|
In Service |
In Service |
Fail |
In Service |
System continues functioning normally. |
|
In Service |
Fail |
In Service |
In Service |
System continues functioning normally. |
|
Fail |
In Service |
In Service |
In Service |
Some downtime occurs. System automatically fails over to UN2. |
|
UN1 State [Voting Members = 2] (Primary) |
UN2 State [Voting Members = 2] |
UN3 State [Voting Members = 2] |
UN4 State [Voting Members = 1] |
Voting Members in Service |
System Status under Scenario |
|---|---|---|---|---|---|
|
In Service |
In Service |
In Service |
In Service |
7 |
System is functioning normally. |
|
Fail |
Fail |
In Service |
In Service |
3 |
Manual Intervention is required to restore service. |
|
In Service |
In Service |
Fail |
Fail |
4 |
System continues functioning normally. |
|
In Service |
Fail |
Fail |
In Service |
3 |
Manual Intervention is required to restore service. |
|
In Service |
Fail |
In Service |
Fail |
4 |
System continues functioning normally. |
In all the scenarios, whenever 50% or more (greater than or equal to four) Voting Members are in service, the system remains in service. Manual steps are required to restore the cluster.
- Loss of a Database role
-
If the primary Database service is lost, the system automatically reverts to the secondary Database. The primary and secondary database nodes can be configured with the command-line interface using database weight<ip><weight>. For example, the primary can be configured with a weight of 40, and the secondary with a weight of 30. If both the primary and the secondary Database servers are lost, the remaining Database servers vote to elect a new primary Database server. There is downtime (no more than a few seconds) during election and failover, with a possible loss of data in transit (a single transaction). The GUI web-frontend transaction status can be queried to determine if any transactions failed. The downtime for a Primary to Secondary failover is less and the risk of data loss likewise reduced. A full election (with higher downtime and risk) is therefore limited only to cases of severe outages where it is unavoidable. Although any values can be used, for 4 database nodes the weights: 40, 30, 20, 10 is recommended.
- Loss of a site
-
Unified and Database nodes have database roles. The status of the roles can be displayed using cluster status. If 50% or more of the database roles are down, then there is insufficient availability for the cluster to function as is. Either additional role servers must be added, or the nodes with down roles must be removed from the cluster and the cluster is reprovisioned. If there is insufficient (less than 50% means that the system is down) Database role availability, manual intervention is required to reprovision the system – downtime depends on the size of the cluster. Refer to the Operations Guide for details on DR Failover. Database role availability can be increased by adding Database roles, providing greater probability of automatic failover. To delete a failed node, and replace it with a new one if database primary is for example lost: The node can be deleted using cluster del <ip>. Extra nodes can be deployed and added to the cluster with cluster add <ip>. The database weights can be adjusted using database weight <ip> <weight>. Finally, the cluster can be reprovisioned with cluster provision.
The console output below shows examples of these commands.
The cluster status:
platform@cpt-bld2-cluster-01:~$ cluster status
Data Centre: jhb
application : cpt-bld2-cluster-04[172.29.21.243]
cpt-bld2-cluster-03[172.29.21.242]
webproxy : cpt-bld2-cluster-06[172.29.21.245]
cpt-bld2-cluster-04[172.29.21.243]
cpt-bld2-cluster-03[172.29.21.242]
database : cpt-bld2-cluster-04[172.29.21.243]
cpt-bld2-cluster-03[172.29.21.242]
Data Centre: cpt
application : cpt-bld2-cluster-02[172.29.21.241]
cpt-bld2-cluster-01[172.29.21.240] (services down)
webproxy : cpt-bld2-cluster-05[172.29.21.244]
cpt-bld2-cluster-02[172.29.21.241]
cpt-bld2-cluster-01[172.29.21.240] (services down)
database : cpt-bld2-cluster-02[172.29.21.241]
cpt-bld2-cluster-01[172.29.21.240] (services down)Deleting a node:
platform@cpt-bld2-cluster-01:~$ cluster del 172.29.21.245
You are about to delete a host from the cluster. Do you wish to continue? y
Cluster successfully deleted node 172.29.21.245
Please run 'cluster provision' to reprovision the services in the cluster
Please note that the remote host may still be part of the database clustering
and should either be shut down or reprovisioned as a single node BEFORE this
cluster is reprovisioned
You have new mail in /var/mail/platformAdding a node:
platform@cpt-bld2-cluster-01:~$ cluster add 172.29.21.245
Cluster successfully invited node 172.29.21.245
Please run 'cluster provision' to provision the services in the clusterDatabase weights: listing and adding
platform@DC30-UN1:~$ database weight list
172.16.30.101:
weight: 40
172.16.30.102:
weight: 30
172.16.40.203:
weight: 20
172.16.40.204:
weight: 10
platform@DC30-UN1:~$ database weight add 172.16.30.101 40
172.16.30.101:
weight: 40
172.16.30.102:
weight: 30
172.16.40.203:
weight: 20
172.16.40.204:
weight: 10
Troubleshooting Installation
Fixing Keyboard Repeat Problems on vSphere
On VMware vSphere, there are known issues with key repeat problems which can sometimes cause problems while entering the password on the console during OVA deployment over slow-speed links.
This is documented in the http://kb.vmware.com/ on the VMware Knowledge Base as follows:
Procedure
| Step 1 |
Power off the virtual machine |
| Step 2 |
Right-click the virtual machine and select Edit Settings. |
| Step 3 |
Click . |
| Step 4 |
Click Add Row. |
| Step 5 |
Under Name, enter keyboard.typematicMinDelay. In the Value field, enter 2000000. |
| Step 6 |
Click OK. |
| Step 7 |
Power on the virtual machine. |
Troubleshooting User Issues
Unlock a Locked Out User
If a user is locked out because a credential policy violation, an administrator responsible for the user can unlock the user account.
Procedure
| Step 1 |
Log in as provider, reseller, or customer admin. |
| Step 2 |
Select . |
| Step 3 |
Click the user whose account you want to unlock. |
| Step 4 |
Click the Account Information tab. |
| Step 5 |
Uncheck the Locked check-box. |
| Step 6 |
Click Save. |
Unlock a Locked Out Administrator
If an administrator is locked out because a credential policy violation, an administrator at a hierarchy node above the locked out administrator can unlock the administrator account.
Procedure
| Step 1 |
Log in as provider, reseller, or customer admin, depending on the location of the locked out administrator. |
| Step 2 |
Select . |
| Step 3 |
Click the administrator whose account you want to unlock. |
| Step 4 |
Click the Account Information tab. |
| Step 5 |
Uncheck the Locked check box. |
| Step 6 |
Click Save. |
Credential Policies Rate Limiting
uses two types of failed login attempt rate limiting. These use a token bucket algorithm.
-
Per-user rate limiting
-
Per-source rate limiting
Failed Login Attempt Per-user Rate Limiting
Per-user failed login attempt rate limiting works as follows:
-
One token is added to the username-specific bucket at the interval specified in Reset failed Login Count per User (minutes).
-
The bucket can hold at most the number of tokens as specified in Failed Login Count per User. If the token is added when the bucket is full, it is discarded.
-
When a login attempt is made with an incorrect password, one token is removed from the bucket. When the last token is removed from the bucket, the rate limiting threshold is reached and the user account is locked for the number of minutes specified in Lock Duration (minutes).
-
Rate limiting is done for both existing and nonexistent system users.
-
The system user triggers a transaction, when an existing user account is locked. Example detail: Password retry limit reached. Locking account with the username "customer".
-
When an account is locked, subsequent login requests (regardless of whether the password is correct or not) from the GUI receives the following message: Too many failed login attempts for this user account. Try again later.
-
A locked account is automatically unlocked on the first login request after the number of minutes specified in Lock Duration (minutes) has lapsed. Account unlocking triggers a transaction as the "system" user. Example detail: Automatic account lockout duration lapsed. Unlocking the account with username "customer".
-
Per-user rate limiting can be disabled by checking the Disable Failed Login Limiting per User check-box.
Failed Login Attempt Per-source Rate Limiting
Per-source rate limiting process is similar to the per-user variant and works as follows:
-
One token is added to the source-specific bucket at the interval that is specified in Reset Failed Login Count per User (minutes).
-
The bucket can hold at most the number of tokens as specified in Failed Login Count per-source. If a token is added when the bucket is full, it is discarded.
-
When a login attempt is made with an incorrect password, one token is removed from the bucket. When the last token is removed from the bucket, the rate limiting threshold is reached and subsequent login requests from the source IP address are locked out for the number of minutes specified in Lock Duration (minutes).
-
No transactions are triggered when per-source rate limits triggered, since there is no associated resource.
-
When a source IP address is locked out, subsequent login requests (regardless of whether the password is correct or not) from the given IP address through the GUI receives the following message: Too many failed login attempts from the computer. Try again later.
-
A locked out source IP address is automatically unlocked on the first login request after the number of minutes specified in Lock Duration (minutes) has lapsed.
-
Per-source rate limiting can be disabled by checking the Disable Failed Login Limiting per-source check box.
Reset Your Own Password
You can reset your password only if you have already provided answers to the security questions created by your administrator.
If you forget your password while attempting to log in to :
-
Enter your username in the Username field on the Log in screen.
-
Click the Forgot Password? hyperlink that is located below the Log in button.
-
Enter your username again.
-
Click Reset my password.
-
Click in each security question field and type the correct answer.
-
Click in the New Password field and type your new password.
-
Click in the Repeat Password field and retype your new password.
-
Click Reset my Password. Your password is changed.
-
Click the Login hyperlink if you want to attempt to log in again.


 Feedback
Feedback