About ACL Contract Permit and Deny Logs
To log and/or monitor the traffic flow for a contract rule, you can enable and view the logging of packets or flows that were allowed to be sent because of contract permit rules or the logging of packets or flows that were dropped because of:
-
Taboo contract deny rules
-
ACL contract permit and deny logging in the ACI fabric is only supported on Nexus 9000 Series switches with names that end in EX or FX, and all later models. For example, N9K-C93180LC-EX or N9K-C9336C-FX.
-
Using log directive on filters in management contracts is not supported. Setting the log directive will cause zoning-rule deployment failure.
For information on standard and taboo contracts and subjects, see Cisco Application Centric Infrastructure Fundamentals and Cisco APIC Basic Configuration Guide.

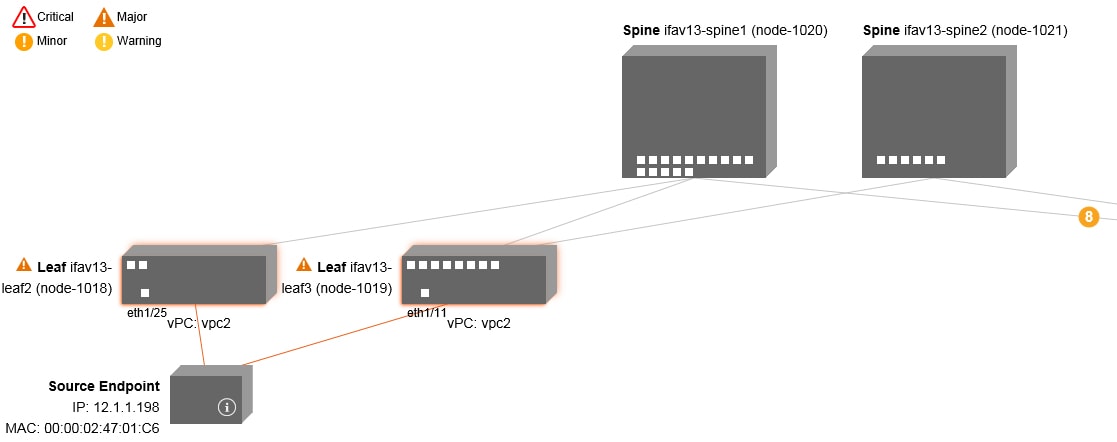
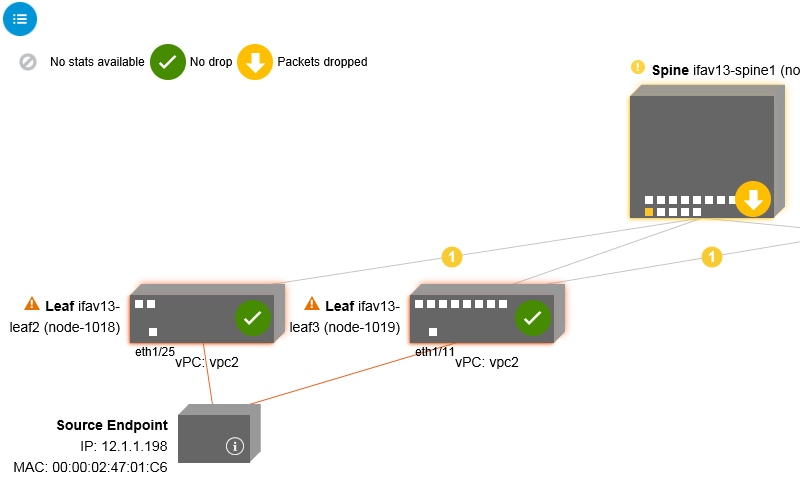
 ) icon. You can also see which EPGs are being referred to.
) icon. You can also see which EPGs are being referred to.
 Feedback
Feedback