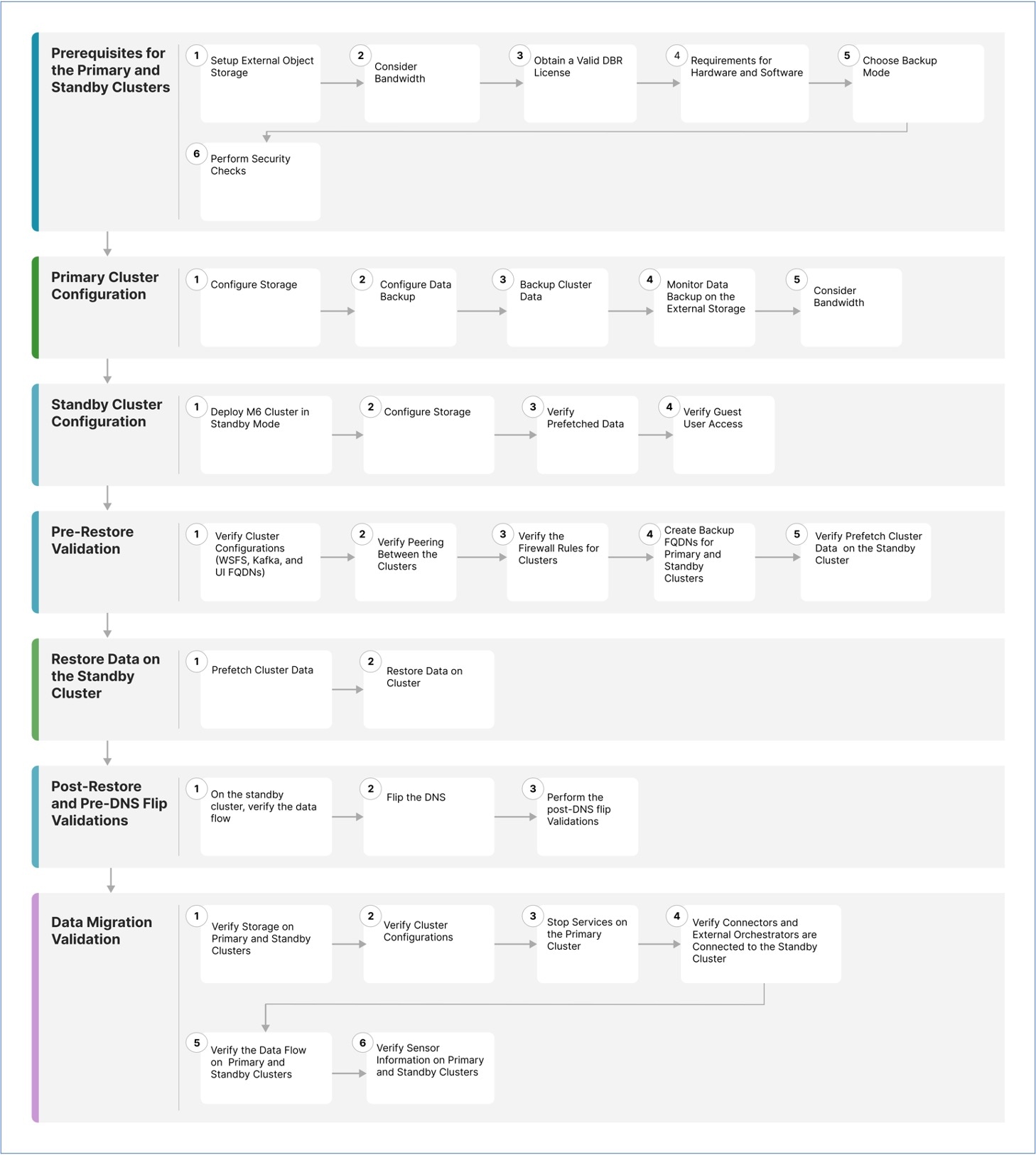
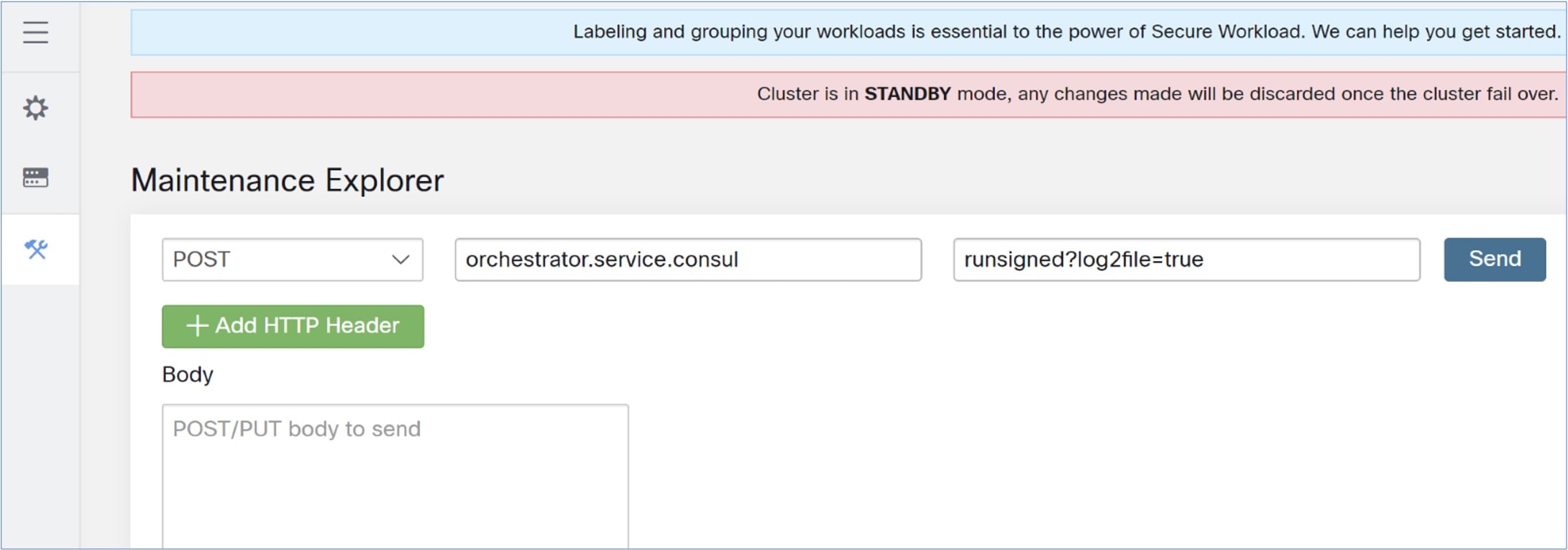
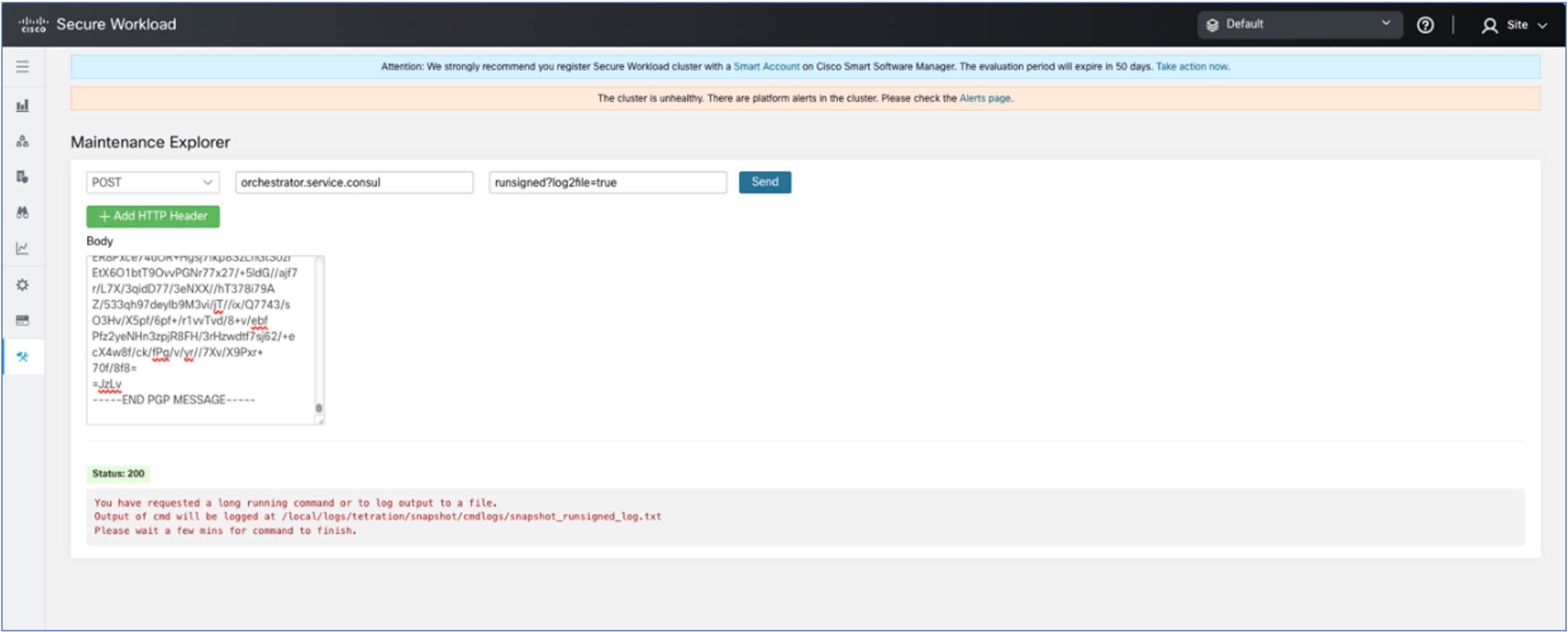
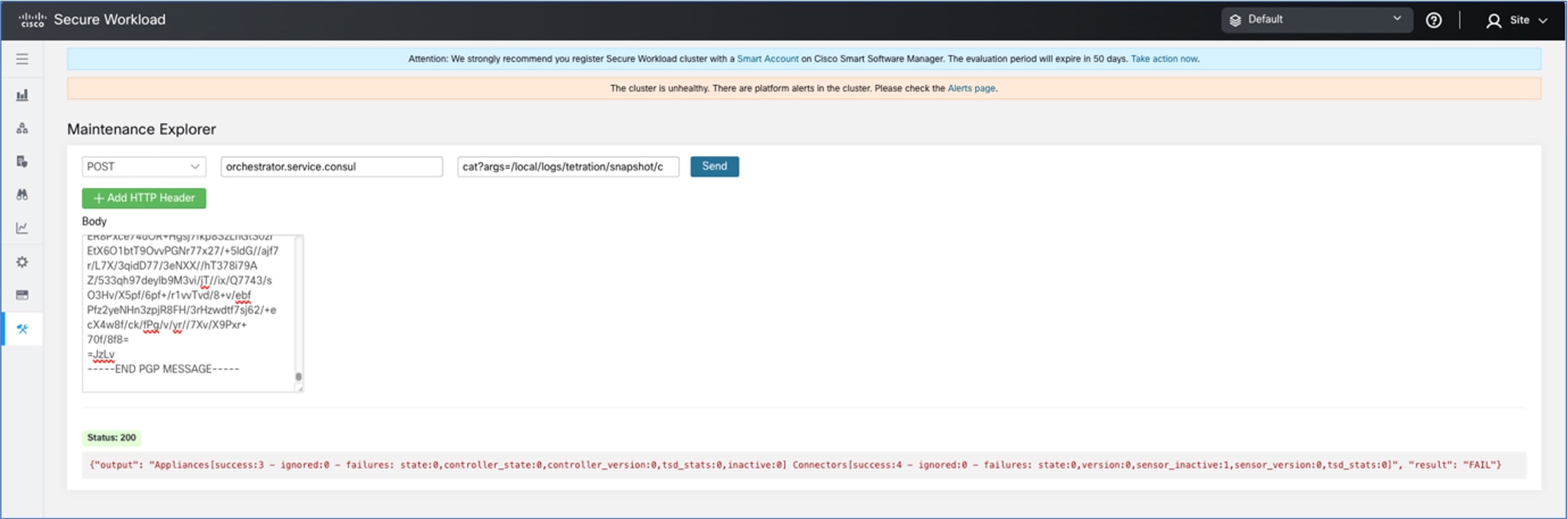
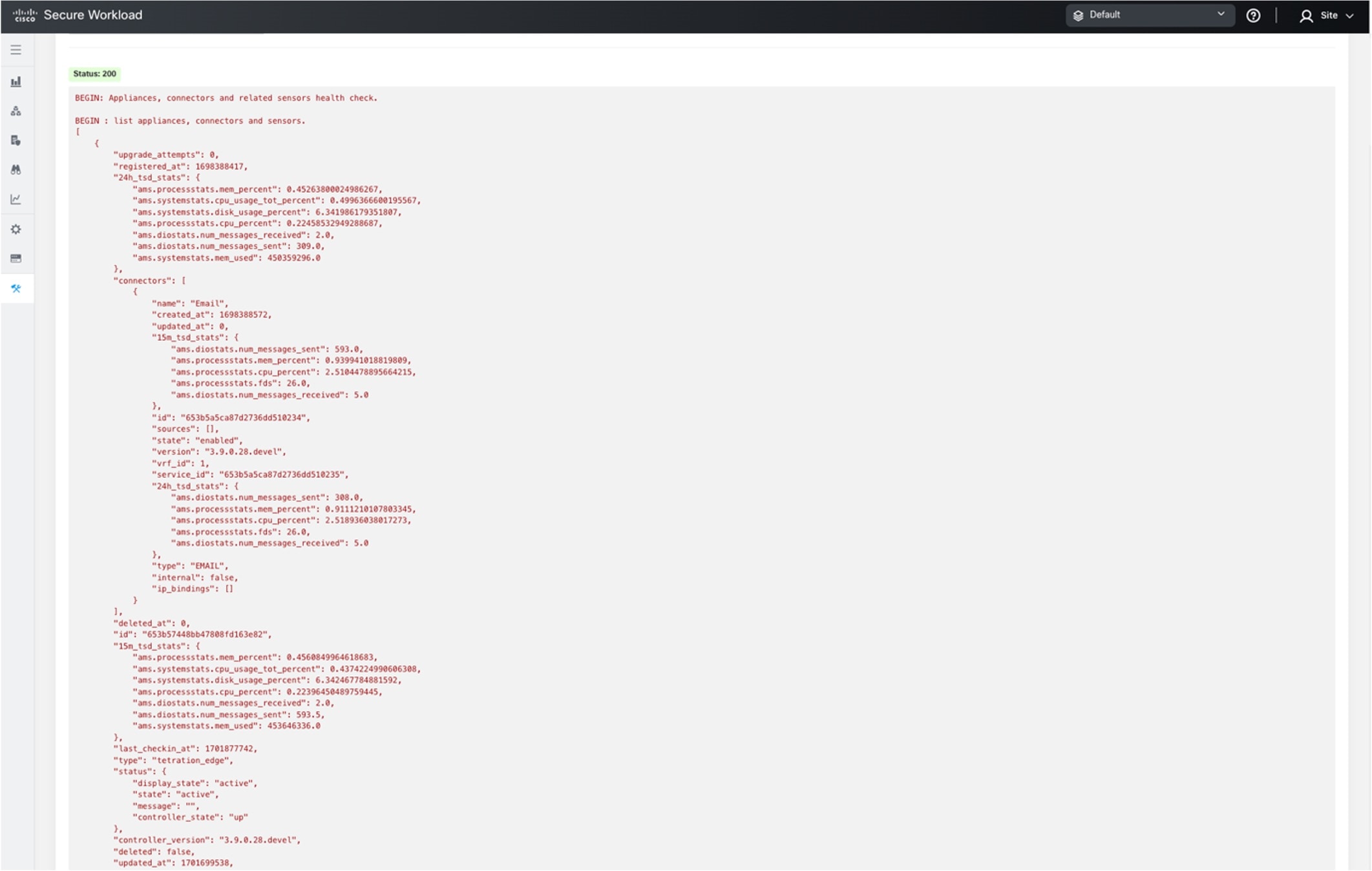
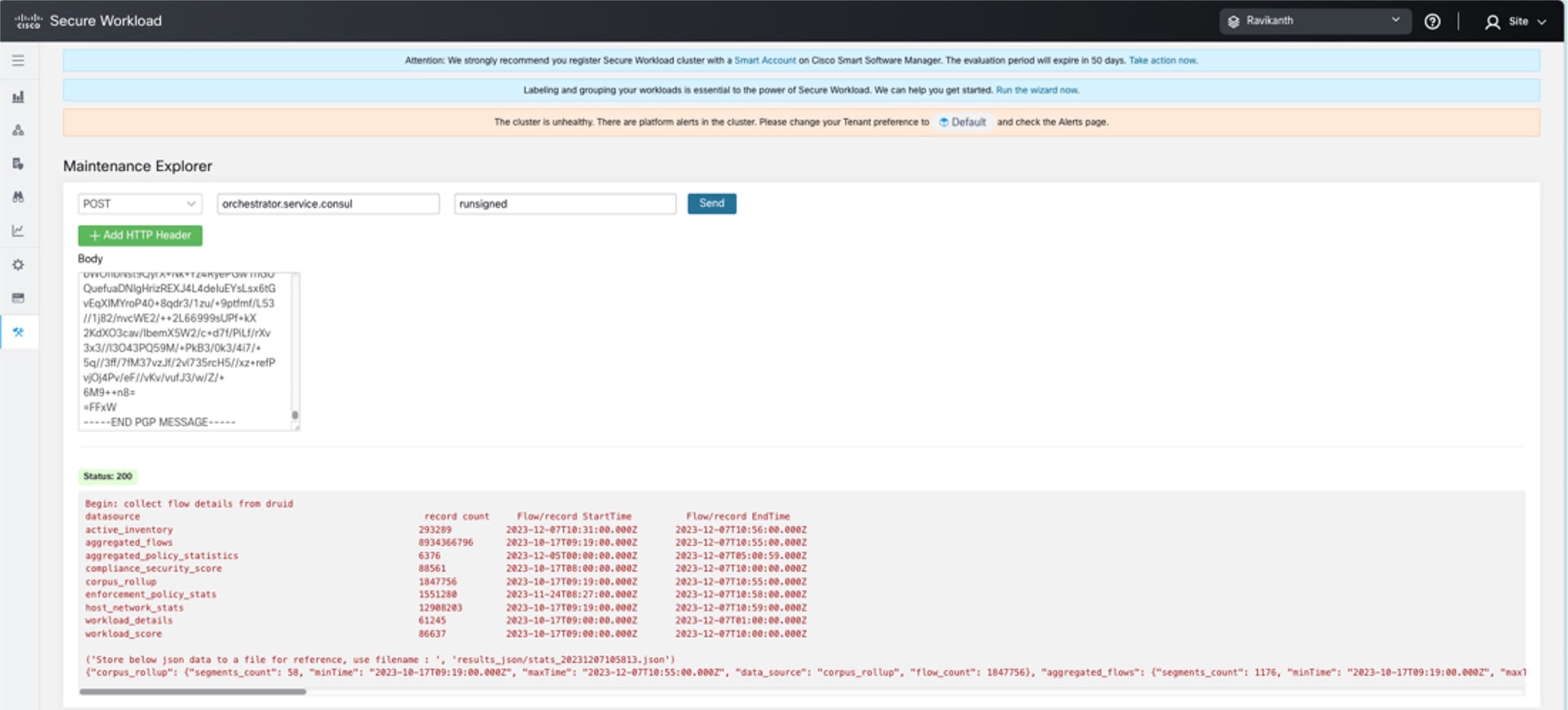
Overview of Cluster to Cluster Migration
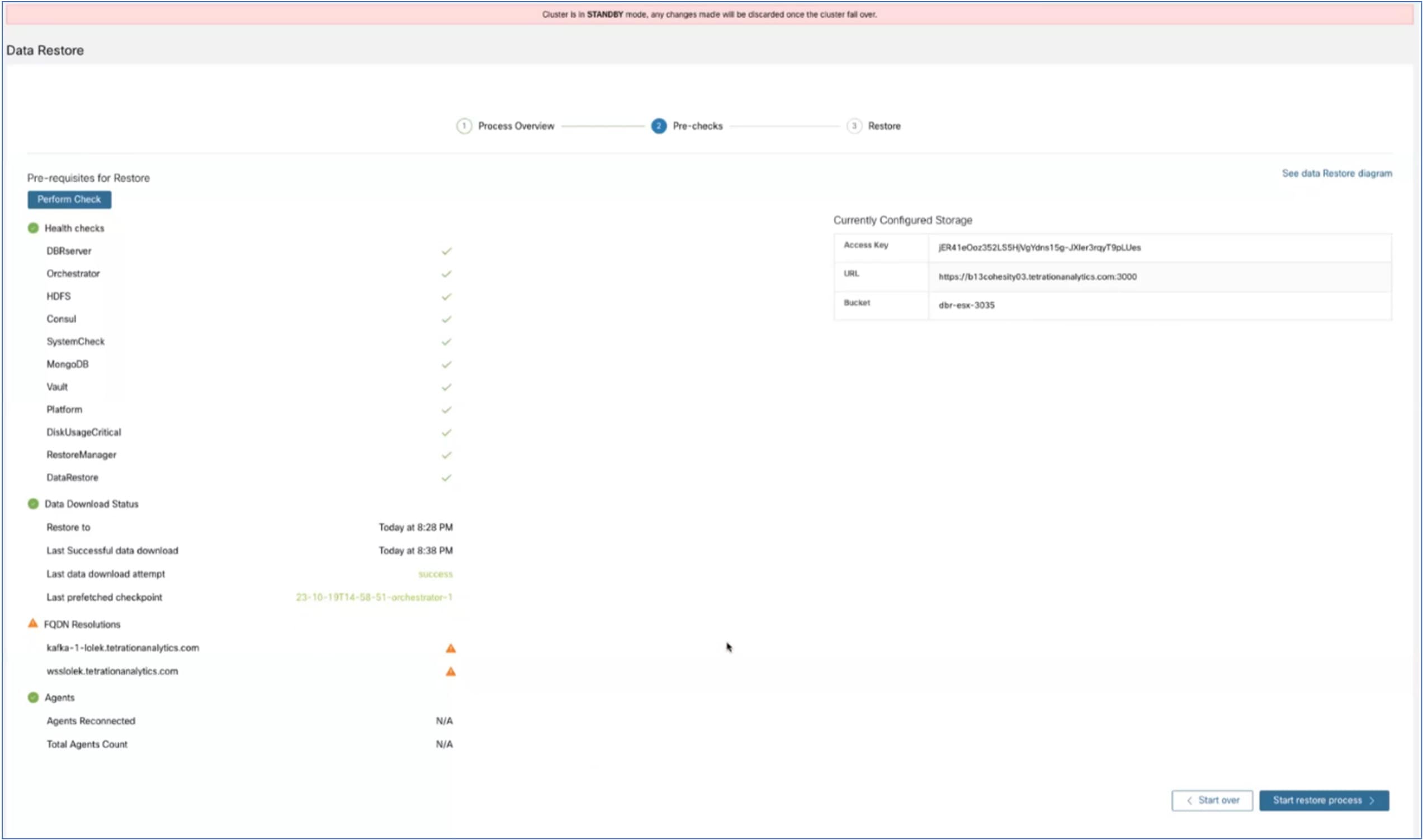
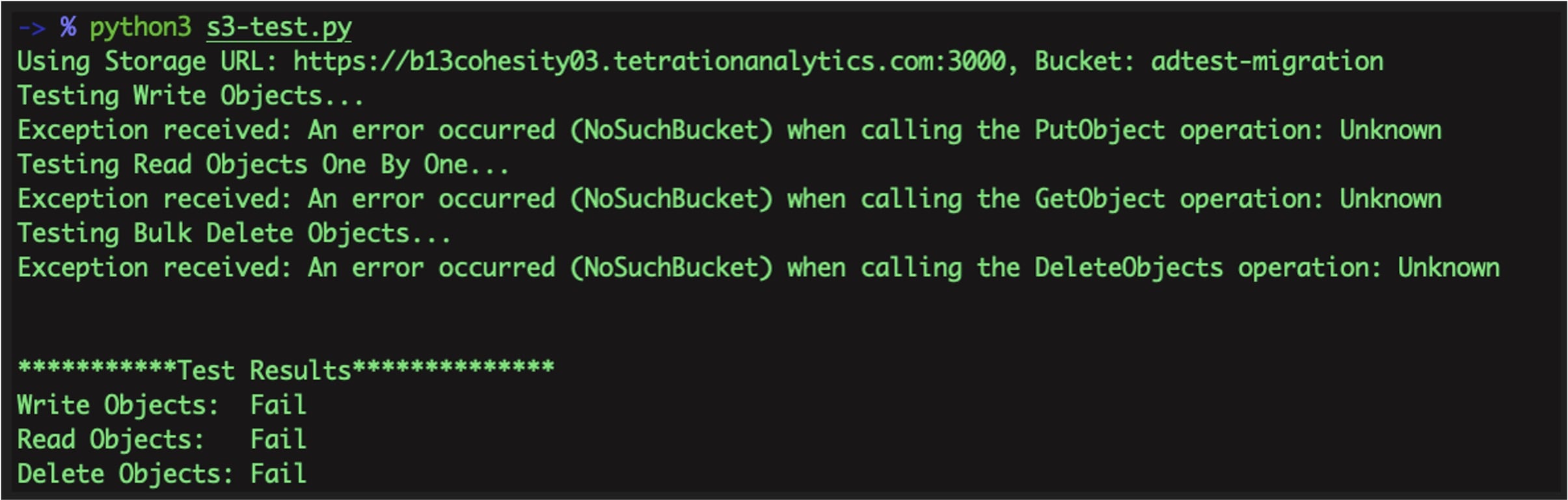
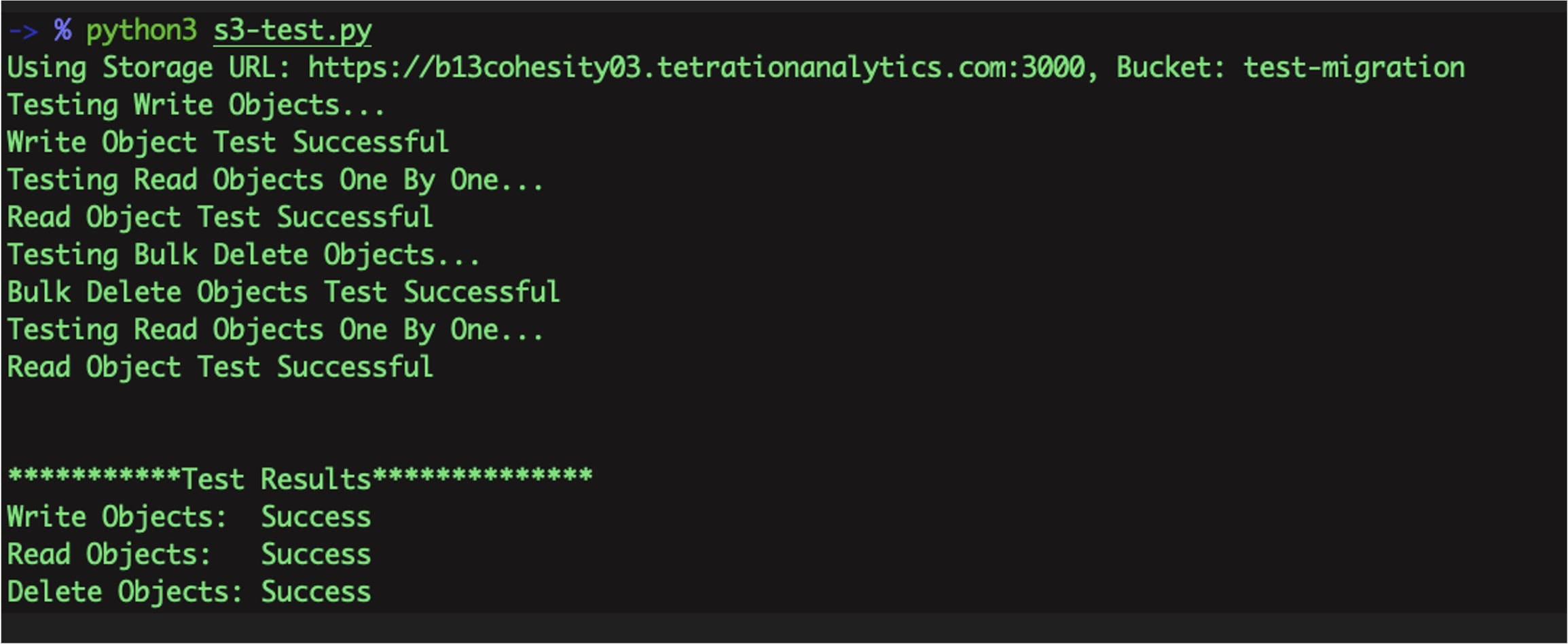
When transferring data from a primary cluster to a standby cluster in Secure Workload, it is recommended to use the data backup and restore (DBR) method. DBR involves copying the data from the primary cluster to an S3-compatible storage and then restoring the same data to the standby cluster from the storage. You can choose either the "lean mode" or "full mode" backup, depending on your specific migration needs.
For more information on lean or full backup mode, see the Data Backup and Restore (DBR) section in the Cisco Secure Workload User Guide.
 Note |
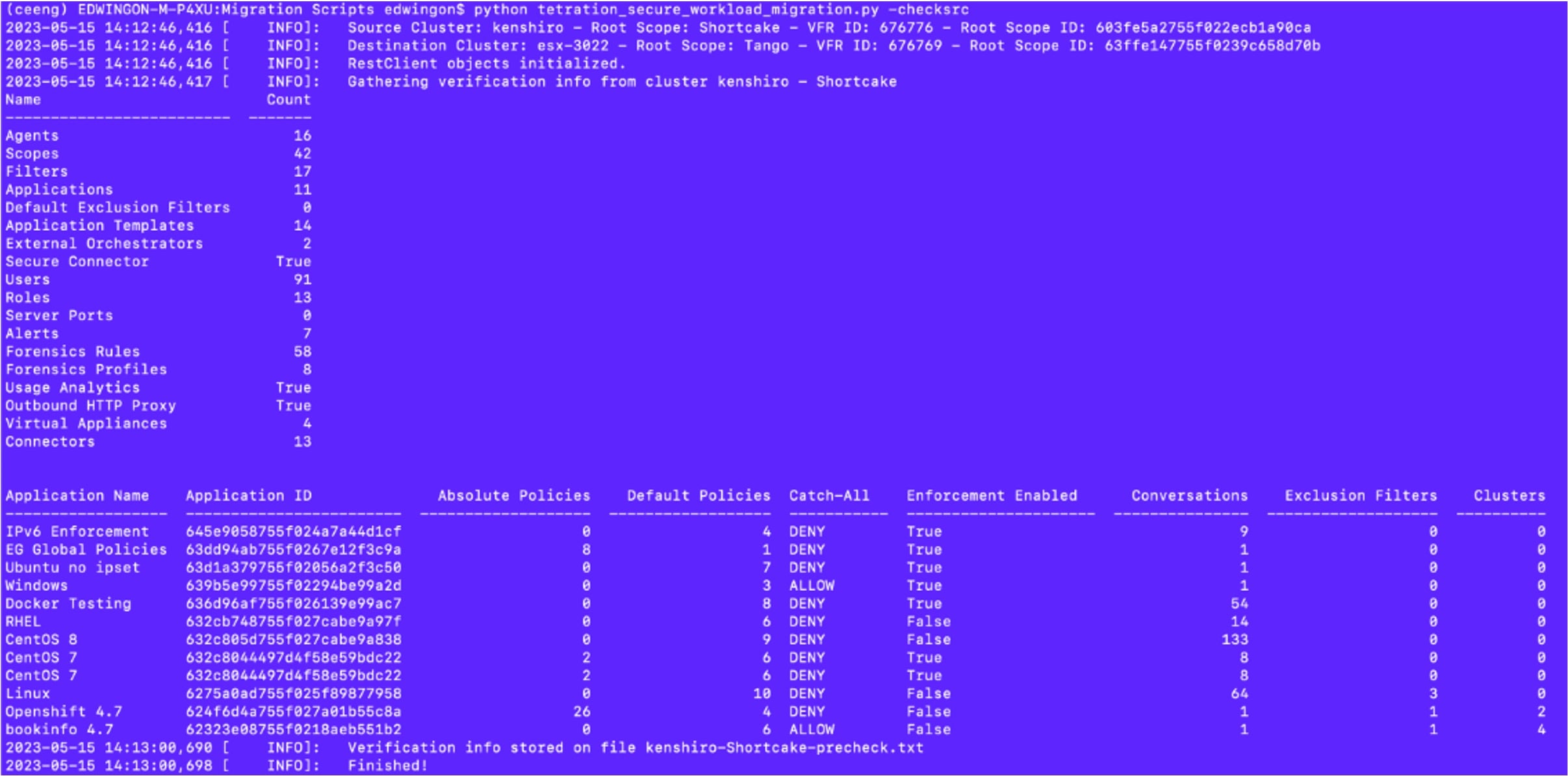
The primary cluster in this guide is either M4 or M5, while M6 is referred to as the standby cluster. |




 Feedback
Feedback