Cisco VSM Operations Manager High Availability Troubleshooting Guide
Available Languages
Table of Contents
Cisco VSM Operations Manager High Availability Troubleshooting Guide
Known Limitations in VSOM-HA Functionality
Deleting VSOM-HA Manually from CLI
The HA Configuration Job Does Not Complete
Determining if a Database Replication Error Occurred
Manually Running the restoreDBReplication.sh Script in case of MYSQL Errors
Detecting if the Database Crashed
Network Connectivity Loss Results in a Split Brain Scenario
Troubleshooting Errors During a Force Failover
Summary of Force Failover Errors and Workarounds
Resolving a “Server Unreachable” Error During Force Failover
Force Failover During a Software Upgrade on the Secondary Server
Unmanaged Split Brain Scenario
Useful Command Line Tools for HA Troubleshooting
Cisco VSM Operations Manager High Availability Troubleshooting Guide
Review the following information for workarounds and solutions to Cisco Video Surveillance Operations Manager high availability (HA) issues:
- Requirements
- Known Limitations in VSOM-HA Functionality
- Deleting VSOM-HA Manually from CLI
- Database Replication Failures
- File Replication Failures
- Network Connectivity Loss Results in a Split Brain Scenario
- Troubleshooting Errors During a Force Failover
–![]() Summary of Force Failover Errors and Workarounds
Summary of Force Failover Errors and Workarounds
–![]() Resolving a “Server Unreachable” Error During Force Failover
Resolving a “Server Unreachable” Error During Force Failover
–![]() Force Failover During a Software Upgrade on the Secondary Server
Force Failover During a Software Upgrade on the Secondary Server
- Virtual IP Login Failure
- Unmanaged Split Brain Scenario
- Useful Command Line Tools for HA Troubleshooting

Note![]() For more information including configuration and management instructions, see the “Operations Manager High Availability” section of the Cisco Video Surveillance Operations Manager User Guide.
For more information including configuration and management instructions, see the “Operations Manager High Availability” section of the Cisco Video Surveillance Operations Manager User Guide.
Requirements
Before you configure Operations Manager HA, verify that the following requirements are met.
Note![]() The VSOM High Availability configuration page appears only if the server is a stand-alone Operations Manager and is running a supported OS (such as RHEL 6.4).
The VSOM High Availability configuration page appears only if the server is a stand-alone Operations Manager and is running a supported OS (such as RHEL 6.4).
To configure Operations Manager HA, admins must belong to a User Group with permissions for Servers & Encoders. See the Cisco Video Surveillance Operations Manager User Guide for more information. |
|
Two standalone physical or virtual servers must be installed on the network. – – Note Any data on the server used as the Secondary server will be deleted and replaced with the data from the Primary server. |
|
We recommend two CPS-UCS-2RU-K9 servers for best performance. |
|
Additional server requirements and recommendations:
|
|
|
|
– – – Note End-users should always use the virtual IP address to access the Operations Manager since it will still work even in a failover occurs. Users should never use the server Ethernet port (NIC) address since connectivity can be lost if the server is unreachable. |
|
Security certificate requirements: By default, all Cisco VSM server include a self-signed certificate. Using the self-signed certificate on the Operations Manager server causes a security warning to appear when users log in the Operation Manager. To avoid this, you can create and install a web server certificate for the Operations Manager servers. The certificate must point to the HA virtual IP address and be installed on both Operations Manager servers (Primary and Secondary) used in the HA configuration.
|
|
Network Time Protocol (NTP) server: All servers must be configured with the same NTP configuration to ensure the time settings are accurate and identical. See the “NTP Information” section of the Cisco Video Surveillance Operations Manager User Guide for more information. |
|




Known Limitations in VSOM-HA Functionality
While using the VSOM-HA functionality, the following issues may occur causing inaccessibility to VSOM or the system to be in Critical Alert state. If so, disable VSOM-HA functionality.
Deleting VSOM-HA Manually from CLI
User is unable to delete VSOM-HA from VSOM-UI and needs to delete VSOM-HA manually from CLI.
Perform the steps below on the primary VSOM.
Step 1![]() Update vsomservice table, set NULL for haConfig_OBJECTID for every related row.
Update vsomservice table, set NULL for haConfig_OBJECTID for every related row.
/usr/BWhttpd/vsom_be/db/mysql/bin/mysql--defaults-file=/usr/BWhttpd/vsom_be/db/db.cnf vsom -e "UPDATE vsomservice SET haConfig_OBJECTID=NULL;
Step 2![]() Set SYSTEM_CREATED to false in 'server' table for secondary VSOM server.
Set SYSTEM_CREATED to false in 'server' table for secondary VSOM server.
/usr/BWhttpd/vsom_be/db/mysql/bin/mysql--defaults-file=/usr/BWhttpd/vsom_be/db/db.cnf vsom - e "UPDATE server SET system_created=false where name='<secondary_server>';"
Step 3![]() Delete all rows from haserverstate table.
Delete all rows from haserverstate table.
/usr/BWhttpd/vsom_be/db/mysql/bin/mysql--defaults-file=/usr/BWhttpd/vsom_be/db/db.cnf vsom -e "DELETE FROM haserverstate;"
Step 4![]() Delete all rows from haconfig table.
Delete all rows from haconfig table.
/usr/BWhttpd/vsom_be/db/mysql/bin/mysql--defaults-file=/usr/BWhttpd/vsom_be/db/db.cnf vsom -e "DELETE FROM haconfig;"
Step 5![]() Delete all rows from hasplitbrainserver table.
Delete all rows from hasplitbrainserver table.
/usr/BWhttpd/vsom_be/db/mysql/bin/mysql--defaults-file=/usr/BWhttpd/vsom_be/db/db.cnf vsom-e "DELETE FROM hasplitbrainserver;"
Step 6![]() Delete /root/.ssh/known_hosts file.
Delete /root/.ssh/known_hosts file.
Step 7![]() Stop the pacemaker service.
Stop the pacemaker service.
sudo service pacemaker stop (On RHEL 6 system)
sudo systemctl stop pacemaker (On RHEL 7 system)
Perform the steps below on the secondary VSOM.
Step 1![]() Stop the pacemaker service.
Stop the pacemaker service.
sudo service pacemaker stop (On RHEL 6 system)
sudo systemctl stop pacemaker (On RHEL 7 system)
Step 2![]() Stop the VSM software and rebuild VSOM database by performing the steps below:
Stop the VSM software and rebuild VSOM database by performing the steps below:
a.![]() Remove the VSOM database files, everything in /usr/BWhttpd/vsom_be/db/mysql/data/ but leave the data/ directory.
Remove the VSOM database files, everything in /usr/BWhttpd/vsom_be/db/mysql/data/ but leave the data/ directory.
# rm –rf /usr/BWhttpd/vsom_be/db/mysql/data/*
b.![]() Start the VSOM database to create the default database.
Start the VSOM database to create the default database.
# /usr/BWhttpd/bin/init_vsom_mysql start
c.![]() Create a new Operations Manager database and CDAF database to restore its configuration.
Create a new Operations Manager database and CDAF database to restore its configuration.
# /usr/BWhttpd/vsom_be/db/database_create.sh
# /usr/BWhttpd/cdaf_be/db/database_create.sh
Perform the steps below on the VSOM-UI.
Step 1![]() Login in to the Primary VSOM-UI and delete the Secondary VSOM from the server tab.
Login in to the Primary VSOM-UI and delete the Secondary VSOM from the server tab.
Now, the environment has only a standalone VSOM. VSOM-HA can be enabled back from primary VSOM-UI, if customer requires High Availability environment.
Note![]() Whenever VSOM-HA is enabled or “Replace HA” is performed, DB and file replication between the Primary and Secondary starts. This takes time to complete, depending on the number of devices configured and other parameters.
Whenever VSOM-HA is enabled or “Replace HA” is performed, DB and file replication between the Primary and Secondary starts. This takes time to complete, depending on the number of devices configured and other parameters.
The HA Configuration Job Does Not Complete
While configuring Operations Manager HA or replacing the HA Secondary server, the sub job that updates the Secondary server may not complete and cause the job to remain in Pending/Running state.
This can happen if the Secondary server is in any of the following states:
- The Secondary server is being rebooted.
- The Secondary server was recently rebooted but is not fully up.
- The Secondary server has a Pending or In-progress job. This can be any job but examples include synchronization, device configuration, or template configuration.
To clear the job and complete the HA configuration, do one or more of the following:
Step 1![]() Verify that there are no configuration or other tasks being performed on the Secondary server, and that the Secondary server does not have any Pending jobs.
Verify that there are no configuration or other tasks being performed on the Secondary server, and that the Secondary server does not have any Pending jobs.
a.![]() Login to the Secondary server Operations Manager interface.
Login to the Secondary server Operations Manager interface.
b.![]() Click System Settings > Jobs.
Click System Settings > Jobs.
c.![]() Verify that there are no Pending jobs in the Secondary server.
Verify that there are no Pending jobs in the Secondary server.
Step 2![]() Restart the services on the Primary server:
Restart the services on the Primary server:
a.![]() Log in the Primary server Management Console interface.
Log in the Primary server Management Console interface.
b.![]() Click Restart Services at the top right corner of the page.
Click Restart Services at the top right corner of the page.
c.![]() Follow the on-screen prompts and wait for the operation to complete (the login screen will reappear when services are fully restarted).
Follow the on-screen prompts and wait for the operation to complete (the login screen will reappear when services are fully restarted).
See the Cisco Video Surveillance Management Console Administration Guide for more information.
Step 3![]() Verify that the HA job is cleared on the Primary server.
Verify that the HA job is cleared on the Primary server.
a.![]() Login to the Primary server Operations Manager interface.
Login to the Primary server Operations Manager interface.
b.![]() Click System Settings > Jobs.
Click System Settings > Jobs.
c.![]() Verify that the previously stuck Operations Manager HA job is marked Failed.
Verify that the previously stuck Operations Manager HA job is marked Failed.
Step 4![]() Replace the HA configuration:
Replace the HA configuration:
a.![]() Select System Settings > Servers.
Select System Settings > Servers.
b.![]() Select the Primary server from the list.
Select the Primary server from the list.
c.![]() Select the VSOM High Availability tab.
Select the VSOM High Availability tab.
d.![]() Click the pencil icon in the top right to turn maintenance mode ON.
Click the pencil icon in the top right to turn maintenance mode ON.
–![]() The icon is grey
The icon is grey  when maintenance mode is ON.
when maintenance mode is ON.
e.![]() Select Device Settings > Replace HA Configuration.
Select Device Settings > Replace HA Configuration.
f.![]() Click OK and wait for the job to complete.
Click OK and wait for the job to complete.
See the Cisco Video Surveillance Operations Manager User Guide for more information.
Step 5![]() Log in to the Operations Manager using the virtual IP address or hostname to verify that the HA setup was successful.
Log in to the Operations Manager using the virtual IP address or hostname to verify that the HA setup was successful.
Database Replication Failures
Some events on either server in an HA configuration can cause database replication failures, where the data on the Primary server is different than the data on the Secondary server.
Events that can cause this include server reboots, power failures, database crashes, or a database going down on either of the participating servers.
Refer to the following topics for information to determine the cause of the failure and recover the database.
Determining if a Database Replication Error Occurred
To detect if a database replication issue occurred, run the following command. If the fields LAST_SQL_ERRNO or LAST_SQL_ERROR fields have a value in the response, the database replication is stuck (the query is in the response).
For example, the replication errors in the following output are shown in red:
For example, complete this procedure to detect which database replication query is stuck in the following error:
Could not execute Delete_rows event on table vsom.issue; Can't find record in 'issue', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's Primary log vsom-mysql-bin.000001, end_log_pos 23237993’
Step 1![]() Decrypt the binary error log file.
Decrypt the binary error log file.
Step 2![]() Look in the Primary log file for the end_log_pos entry in the Example Output.
Look in the Primary log file for the end_log_pos entry in the Example Output.
Step 3![]() Enter the following command on the Primary log file on the Secondary server.
Enter the following command on the Primary log file on the Secondary server.
For example, if an HA deployment includes server 50 and server 51, and the issue was seen on server 51, go to the Secondary server 50 and enter the following command on the Primary log file. In the example error message above it is vsom-mysql-bin.000001 :
–![]() Notice that the command was storing the parsed output in the
Notice that the command was storing the parsed output in the /tmp/error_log.sql file.
–![]() Open the parsed log file
Open the parsed log file error_log.sql and search for log position seen in above error 23237993.
–![]() Check the query seen at the log position which gives the ASCII format of the original query that is being executed and is stuck.
Check the query seen at the log position which gives the ASCII format of the original query that is being executed and is stuck.
Manually Running the restoreDBReplication.sh Script in case of MYSQL Errors
Using the restoreDBReplication.sh script will correct a DB replication issue only if replication failed because of MySQL error 1032,1062 or 1517. If the script is executed in case of MySQL error other than 1032, 1062 or 1517, there will not be any adverse effect on the system. There may be downtime of the application because the script will stop tomcat service during execution. The script will work on VSM 7.11 and later.
Note![]() The script must be executed on the Primary server using the following script location:
The script must be executed on the Primary server using the following script location:
/usr/BWhttpd/vsom_be/ha/restoreDBReplication.sh
restoreDBReplication.sh [-m masterIp] [-s slaveIp] [-p slave root password]
Once executed on the Primary server, Primary server will trigger the same execution on the Secondary server. The script executes the following:
- Puts pacemaker in MaintenanceMode
- Stops tomcat service
- Takes DB dump if DB replication is not running.
- Takes backup of current MySQL DB config file. Location of current MySQL DB config file:
/usr/BWhttpd/vsom_be/db/mysql/my.cnf
my_original.cnf : It is created to restore original configuration.
my_temp.cnf : It is a modified file which contains changes to skip specified MySQL errors.
- Copy my_temp.cnf to /usr/BWhttpd/vsom_be/db/mysql/my.cnf and restart vsom mysql service.
- Once execution is done, restore original DB configuration from my_original.cnf and restart vsom mysql service.
Once Primary is done with execution, it will wait for Secondary server to finish execution. When both Primary and Secondary servers are done with execution, below steps will be performed:
Step 1![]() Release pacemaker MaintenanceMode on Primary.
Release pacemaker MaintenanceMode on Primary.
Step 2![]() Start tomcat on Primary.
Start tomcat on Primary.
Step 3![]() Release pacemaker MaintenanceMode on Secondary.
Release pacemaker MaintenanceMode on Secondary.
Step 4![]() Start tomcat on Secondary.
Start tomcat on Secondary.
Important Files and Locations on Primary Server:
- Execution of the script will be logged in a file: /usr/BWhttpd/tomcat/logs/vsom_be/restore_db_replication.log<UTCTIMESTAMP>_DB.dmp
- MySQL DB config backup file: /usr/BWhttpd/vsom_be/ha/my_original.cnf
- Primary DB replication status file: /usr/BWhttpd/vsom_be/ha/replicationStatus.txt
- Secondary DB replication status file: /usr/BWhttpd/vsom_be/ha/slaveReplicationStatus.txt
Important Files and Locations on Secondary Server:
- Execution of the script will be logged in a file: /usr/BWhttpd/tomcat/logs/vsom_be/restore_db_replication.log<UTCTIMESTAMP>_DB.dmp
- MySQL DB config backup file: /usr/BWhttpd/vsom_be/ha/my_original.cnf
Note![]() After running the script, if DB Replication is still not running either on Primary or Secondary server, do the following:
After running the script, if DB Replication is still not running either on Primary or Secondary server, do the following:
1. Restore DB using DB dump–taken during script execution. This is available here:
Q: When the script starts, if DB replication is currently running, does it exit with an error?
A: If DB replication is currently running, script will exit with message “DB replication is already running. There is no need to restore DB replication. Hence exiting...”
Q: What if someone kills the script Ctrl-C or reboots the server, how does someone recover the system?
A: If someone kills the script Ctrl-C or reboots the server, use Replace HA config to recover the system.
Q: Should I clean up the DB dump if everything was OK?
A: Yes. Currently, script does not clean DB dump. It may be required to restore/look at the DB at some point in the future, if critical data is lost.
Detecting if the Database Crashed
To determine if the database crashed, verify the /usr/BWhttpd/vsom_be/mysql.log and look for errors such as the following (in red):
2014-11-06 13:46:40 2859 [ERROR] Error reading packet from server: Lost connection to MySQL server during query ( server_errno=2013)
2014-11-06 13:46:40 2859 [Note] Slave I/O thread killed while reading event
2014-11-06 13:46:40 2859 [Note] Slave I/O thread exiting, read up to log 'vsom-mysql-bin.000023', position 580246
2014-10-24 15:34:39 13859 [Note] InnoDB: Initializing buffer pool, size = 64.0M
2014-10-24 15:34:39 13859 [Note] InnoDB: Completed initialization of buffer pool
2014-10-24 15:34:39 13859 [Note] InnoDB: Highest supported file format is Barracuda.
2014-10-24 15:34:39 13859 [Note] InnoDB: The log sequence numbers 46653980 and 46653980 in ibdata files do not match the log sequence number 197868345 in the ib_logfiles!
2014-10-24 15:34:39 13859 [Note] InnoDB: Database was not shutdown normally!
Recovering the Database
If a Database Replication Error Occurred
If the SQL that was stuck is of no significance, log in to the Operations Manager using the virtual IP address, and then select Replace HA Configuration. This process clears the replication error by replacing the Secondary data with the Primary data.
Step 1![]() Restart Cisco services using the following commands:
Restart Cisco services using the following commands:
Step 2![]() Ensure the database is fully up, by checking Cisco service status:
Ensure the database is fully up, by checking Cisco service status:
Step 3![]() If the VSOM database service is still not coming up, check the
If the VSOM database service is still not coming up, check the /usr/BWhttpd/vsom_be/mysql.log :
- If the log states that the slave thread was killed, fix the issue by logging into the Operations Manager using the virtual IP address, and then select Replace HA Configuration.
- if the ibdata files do not match the log sequence number, force recover the database as recommended by Oracle Support team in this link and restart Cisco services: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html
Step 4![]() If all services are up and running, a database replication issue occurred. Recover the database by logging into the Operations Manager using the virtual IP address, and then select Replace HA Configuration.
If all services are up and running, a database replication issue occurred. Recover the database by logging into the Operations Manager using the virtual IP address, and then select Replace HA Configuration.
File Replication Failures
If a database or file replication issue is displayed in the server Status page, double-click the alert to view the events that describe why file replication is failing. The following can cause these errors:
The localadmin password for the Secondary server is not valid. For example, the password was changed on the Secondary server but was not updated on the VSOM HA Configuration page.
Step 1![]() Log in to the Operations Manager using the virtual IP address / hostname.
Log in to the Operations Manager using the virtual IP address / hostname.
Step 2![]() Click the pencil icon in the top right to turn maintenance mode ON.
Click the pencil icon in the top right to turn maintenance mode ON.
 when maintenance mode is ON.
when maintenance mode is ON.
Step 3![]() Select System Settings > Servers.
Select System Settings > Servers.
Step 4![]() Select the Primary server from the list.
Select the Primary server from the list.
Step 5![]() Select the VSOM High Availability tab.
Select the VSOM High Availability tab.
Step 6![]() Enter the new Secondary server password.
Enter the new Secondary server password.
The Remote Host Identification (Hostkeys) for the Secondary Server Changed
The Hostkeys for the Secondary server can change if the server IP address is changed when the server is reinstalled or replaced. If this occurs:
Step 1![]() Log in to the Primary server using an SSH client.
Log in to the Primary server using an SSH client.
Step 2![]() SSH to the Secondary server to verify that the following error is displayed. For example:
SSH to the Secondary server to verify that the following error is displayed. For example:
[root@psbu-server-qaha]# ssh localadmin@psbu-server-qa2
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you right now (man-in-the-middle attack)!
It is also possible that the RSA host key has just been changed.
The fingerprint for the RSA key sent by the remote host is
d3:b5:e3:0d:fc:0b:ab:6a:c6:c4:b2:3e:17:21:7b:c9.
Please contact your system administrator.
Add correct host key in /root/.ssh/known_hosts to get rid of this message.
Offending key in /root/.ssh/known_hosts:8
RSA host key for psbu-server-qa2 has changed and you have requested strict checking.
Step 3![]() If this message appears, edit the known hosts using the following command:
If this message appears, edit the known hosts using the following command:
Step 4![]() Delete the host key entry of the Secondary server and save the changes.
Delete the host key entry of the Secondary server and save the changes.
Step 5![]() Verify that the database or file replication error is resolved. Wait at least one minute since health monitoring jobs are updated each minute.
Verify that the database or file replication error is resolved. Wait at least one minute since health monitoring jobs are updated each minute.
a.![]() Log in to the Operations Manager using the virtual IP address / hostname.
Log in to the Operations Manager using the virtual IP address / hostname.
b.![]() Select System Settings > Servers.
Select System Settings > Servers.
c.![]() Select the Primary server from the list.
Select the Primary server from the list.
e.![]() Verify that the issue is clear.
Verify that the issue is clear.
Network Connectivity Loss Results in a Split Brain Scenario
If communication between the Primary and Secondary servers is lost, both servers will try to independently assume the Primary role. This is called a “Split Brain” scenario.
Cisco VSM will automatically detect a Split Brain scenario and direct all traffic to the server that was Primary at the time of communication loss. The Secondary server is put in standby and a Health alert is sent.
Note![]() This recovery process requires that at least one Media Server be added to the HA “Split Brain Configuration. See the “Operations Manager High Availability” section of the Cisco Video Surveillance Operations Manager User Guide.
This recovery process requires that at least one Media Server be added to the HA “Split Brain Configuration. See the “Operations Manager High Availability” section of the Cisco Video Surveillance Operations Manager User Guide.
Since there can be a delay up to 90 seconds for the issue to be detected, users may still be able to log in to the wrong server. During this time, it is possible that user traffic will go to both servers.
If this occurs, refer to the “Operations Manager High Availability” section of the Cisco Video Surveillance Operations Manager User Guide for more information.
Troubleshooting Errors During a Force Failover
If a force failover does not complete or encounters errors, review the following information and workarounds.
Summary of Force Failover Errors and Workarounds
Resolving a “Server Unreachable” Error During Force Failover |
|
Force Failover During a Software Upgrade on the Secondary Server |
|
Check the Secondary server’s Status tab to see if the server is reachable. |
|
Go to the Secondary server Status > Status History tab to see if there is a issue “HA Functionality is not available at this time.Pacemaker service is not running”. To resolve the issue select Device Settings > Replace HA Configuration to bring up the pacemaker service on the Secondary server. |
|
To resolve this, go to Server > VSOM High Availability and select Device Settings > Clear Split Brain Issues. See Cisco Video Surveillance Operations Manager User Guide. |
Resolving a “Server Unreachable” Error During Force Failover
If the default self-signed certificates are used on the Primary and Secondary servers, a “Server unreachable” error may occur when performing a force failover (Figure 1-1).
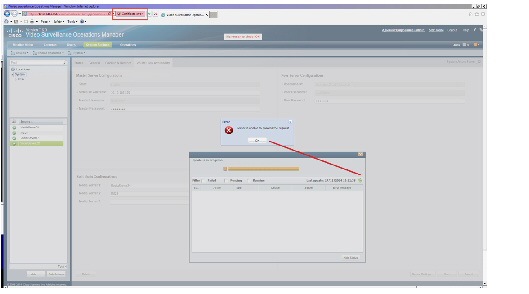
To temporarily address this issue, refresh the browser page to remove the error and continue.
To resolve the issue, obtain and install a signed certificate issued by a Certification Authority.
1.![]() Obtain a signed certificate by a Certification Authority. This certificate should contain the host name mapped to the virtual IP. For example: vsom-server3.
Obtain a signed certificate by a Certification Authority. This certificate should contain the host name mapped to the virtual IP. For example: vsom-server3.
2.![]() Install the certificate on both the Primary and Secondary servers using the Cisco Video Surveillance Management Console. For example vsom-server1 and vsom-server2.
Install the certificate on both the Primary and Secondary servers using the Cisco Video Surveillance Management Console. For example vsom-server1 and vsom-server2.
3.![]() Wait for the services to be restarted.
Wait for the services to be restarted.
4.![]() Log in again to the Operation Manager using the virtual IP address. The certificate error should not appear.
Log in again to the Operation Manager using the virtual IP address. The certificate error should not appear.
For more information, see the following:
- Requirements
- Cisco Video Surveillance Operations Manager User Guide
- Cisco Video Surveillance Management Console Administration Guide —for instructions to install the certificate.
Force Failover During a Software Upgrade on the Secondary Server
If you perform a force failover while a software upgrade is in process on the Secondary server (for example, the Secondary server has not fully initialized after the upgrade), the virtual IP address/hostname can be lost.
If this happens, error messages may appear when a user attempts to log in using the Operations Manager virtual IP address. Messages include: “Invalid access, server is in standby mode” or “”Must login with Virtual IP [IP address] to access system”. This is because both the Primary and Secondary servers are in standby state.
To resolve this issue, you must manually release standby mode on the original Primary server.
Step 1![]() To determine the Primary server, query the following database with the following SQL from either server:
To determine the Primary server, query the following database with the following SQL from either server:
select peerserverip from haconfig where state = 2
Step 2![]() Log in to the Primary server from the command prompt.
Log in to the Primary server from the command prompt.
Step 3![]() This provides the node name of the server.
This provides the node name of the server.
Step 4![]() Release standby mode using the following command:
Release standby mode using the following command:
crm_standby -D -N server-name [node name collected from above command]
For example: crm_standby -D -N vsm-server
Step 5![]() After releasing the Standby mode, the server should automatically acquire the virtual IP address.
After releasing the Standby mode, the server should automatically acquire the virtual IP address.
Step 6![]() Log back in to the Operations Manager using the virtual IP address or hostname.
Log back in to the Operations Manager using the virtual IP address or hostname.
Step 7![]() Go to the Primary server and select Force Fail Over to proceed with rest of the software upgrade process.
Go to the Primary server and select Force Fail Over to proceed with rest of the software upgrade process.
Virtual IP Login Failure
If users are not able to login using the virtual IP address or hostname, do the following:
–![]() Check the status by entering service pacemaker status on both the servers.
Check the status by entering service pacemaker status on both the servers.
–![]() Run the command crm_mon -1 to list node status information on both the servers.
Run the command crm_mon -1 to list node status information on both the servers.
–![]() Enter the command ifconfig on both servers. If either server returns NO eth0:0 or eth1:0, then neither server acquired the virtual IP address.
Enter the command ifconfig on both servers. If either server returns NO eth0:0 or eth1:0, then neither server acquired the virtual IP address.
If a software upgrade was not being performed, log in to the Primary server using the server’s actual IP/Hostname and select Replace HA Configuration. Otherwise, try one of the following:
If a force fail over was issued before a software upgrade was complete, see Force Failover During a Software Upgrade on the Secondary Server.
Step 1![]() If the pacemaker is down, restart the pacemaker service using the command:
If the pacemaker is down, restart the pacemaker service using the command:
Step 2![]() If the pacemaker does not come up clean, run the script:
If the pacemaker does not come up clean, run the script:
/usr/BWhttpd/vsom_be/ha/recoverPacemaker.sh
Step 3![]() Restart the pacemaker service:
Restart the pacemaker service:
Unmanaged Split Brain Scenario
If network connectivity is lost between the Primary and Secondary server, both servers can assume the Primary role and acquire the virtual IP address.
If connectivity is restored between the servers, user traffic can be sent to both servers.
This scenario can be caused by the following:
- The Primary server is disconnected from the rest of the world, but the Secondary server can see all other servers (including the Media Servers used for HA storage).
- The Primary server has communication with all servers except the Secondary server, and the Secondary server loses network communication with the rest of the world.
- No Media Servers are configured for HA storage, so the system cannot resolve the split brain.
- Media Servers are configured for HA storage but the connectivity issue was shorter than a minute.
If an unmanaged split brain scenario occurs, the virtual IP address is configured on both servers. Enter the ifconfig command on both servers to view the IP address on each server and verify that both servers are using the virtual IP address.
For example, if the Eth0 interface was used, the virtual IP address is displayed under the eth0:0 entry. If the eth1 interface was used for HA configuration, the virtual IP address is displayed under eth1:0.
After network connectivity between the Operation Manager HA servers is restored, log in to the Operation Manager browser-based interface to replace the HA configuration.
Step 1![]() Log in to the Operation Manager for either server using the physical IP address.
Log in to the Operation Manager for either server using the physical IP address.
Step 2![]() Select Device Settings > Replace HA Configuration.
Select Device Settings > Replace HA Configuration.
Step 3![]() If the issue is still not resolved, delete the HA Configuration and reconfigure Operation Manager HA:
If the issue is still not resolved, delete the HA Configuration and reconfigure Operation Manager HA:
a.![]() Delete the HA Configuration.
Delete the HA Configuration.
b.![]() Re-configure Operations Manager HA.
Re-configure Operations Manager HA.
See the Cisco Video Surveillance Operations Manager User Guide for more information.
The following alternative method can also be performed to manually resolve the issues.
Step 1![]() Enter the command ifconfig on both servers to determine if both servers are configured with the virtual IP address.
Enter the command ifconfig on both servers to determine if both servers are configured with the virtual IP address.
Step 2![]() Verify that the Cisco service is up on both servers.
Verify that the Cisco service is up on both servers.
Step 3![]() Bring the Cisco service back up on both servers, if necessary.
Bring the Cisco service back up on both servers, if necessary.
Step 4![]() Stop the pacemaker service on both servers.
Stop the pacemaker service on both servers.
Step 5![]() Start the pacemaker service on the original Primary server.
Start the pacemaker service on the original Primary server.
Step 6![]() When the pacemaker service starts, enter the command ifconfig to verify it has the virtual IP address.
When the pacemaker service starts, enter the command ifconfig to verify it has the virtual IP address.
Step 7![]() Log in to the Operation Manager using the virtual IP address or hostname.
Log in to the Operation Manager using the virtual IP address or hostname.
Step 8![]() View the server status.
View the server status.
Step 9![]() If the database replication issue is not automatically released, go to the VSOM High Availability tab and select Device Settings > Replace HA Configuration.
If the database replication issue is not automatically released, go to the VSOM High Availability tab and select Device Settings > Replace HA Configuration.
Related Documentation
See the following locations for the most current information and documentation:
HA Configuration, Management and Monitoring
See the “Operations Manager High Availability” section of the Cisco Video Surveillance Operations Manager User Guide for more information.
Cisco Video Surveillance 7 Documentation Roadmap
Descriptions and links to Cisco Video Surveillance documentation, server and storage platform documentation, and other related documentation.
http://www.cisco.com/go/physicalsecurity/vsm/roadmap
Cisco Physical Security Product Information:
www.cisco.com/go/physicalsecurity/
Cisco Video Surveillance Manager Documentation Website
www.cisco.com/go/physicalsecurity/vsm/docs
Cisco and the Cisco logo are trademarks or registered trademarks of Cisco and/or its affiliates in the U.S. and other countries. To view a list of Cisco trademarks, go to this URL: www.cisco.com/go/trademarks. Third-party trademarks mentioned are the property of their respective owners. The use of the word partner does not imply a partnership relationship between Cisco and any other company. (1721R)
Any Internet Protocol (IP) addresses and phone numbers used in this document are not intended to be actual addresses and phone numbers. Any examples, command display output, network topology diagrams, and other figures included in the document are shown for illustrative purposes only. Any use of actual IP addresses or phone numbers in illustrative content is unintentional and coincidental.
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)