Logging and Monitoring in Cisco NFVI
Cisco VIM uses a combination of open source tools to collect and monitor the Cisco OpenStack services including Elasticsearch, Fluentd, and the Kibana dashboard (EFK).
In VIM, we have moved our platform to use Fluentd, instead of logstash. However, to maintain backwards compatibility, the code, and documentation refers to ELK, instead of EFK at various places. In VIM, these two acronyms are interchangeable, however it refers to the presence of EFK in the offering. OpenStack services that followed by EFK include:
-
MariaDB—A relational database management system which is based on MySQL. All the OpenStack components store their data in MariaDB.
-
HAProxy—HAProxy is a free open source software that provides a high-availability load balancer, and proxy server for TCP and HTTP-based applications that spreads requests across multiple servers.
-
Keystone—Keystone is an OpenStack project that provides identity, token, catalog, and policy services for use specifically by projects in the OpenStack.
-
Glance—An OpenStack project that allows you to upload and discover data assets that are meant for use with other services.
-
Neutron—An OpenStack project that provides the network connectivity between interface devices, such as vNICs, managed by other OpenStack services, such as Nova.
-
Nova—An OpenStack project that is designed to provide massively scalable, on demand, self-service access to compute resources.
-
HTTP—The Apache HTTP server Project, an effort to develop and maintain an open-source HTTP server.
-
Cinder—An OpenStack block storage service that is designed to present storage resources to the users that are consumed by the OpenStack compute project (Nova).
-
Memcached—A general purpose distributed memory caching system.
-
CloudPulse—Is an OpenStack tool that checks the health of the cloud. CloudPulse includes operator and end-point tests.
-
Heat—The main OpenStack Orchestration program. Heat implements an orchestration engine to launch multiple composite cloud applications that is based on text file templates.
-
Other OpenStack services—RabbitMQ, Ceph, Open vSwitch, Linux bridge, Neutron VTS (optional), and others.
-
VMTP—Integrated control and data plane log for testing the cloud.
-
NFVBench—Network performance benchmarking tool.
A Fluentd container resides on each control, compute, and storage nodes. They forward log to the Fluentd-aggr server residing on the management node.
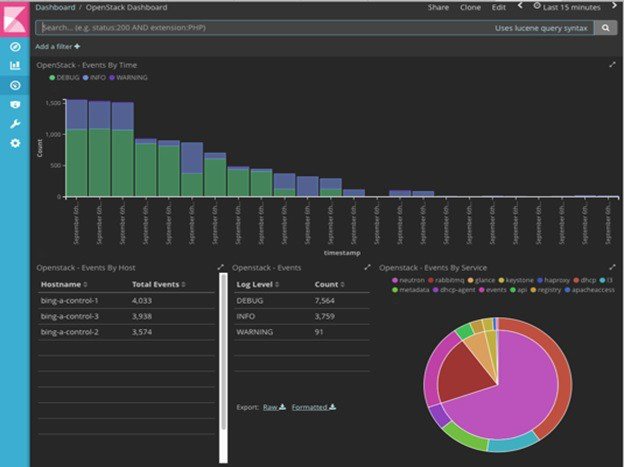
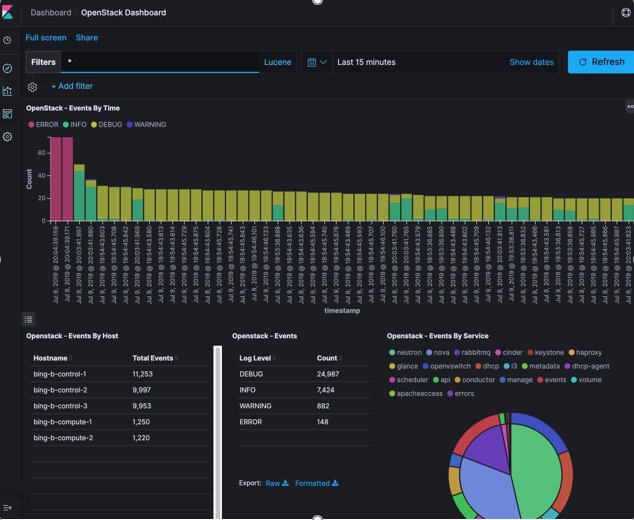
The following figure shows a high-level schematic of the Fluent service assurance architecture.
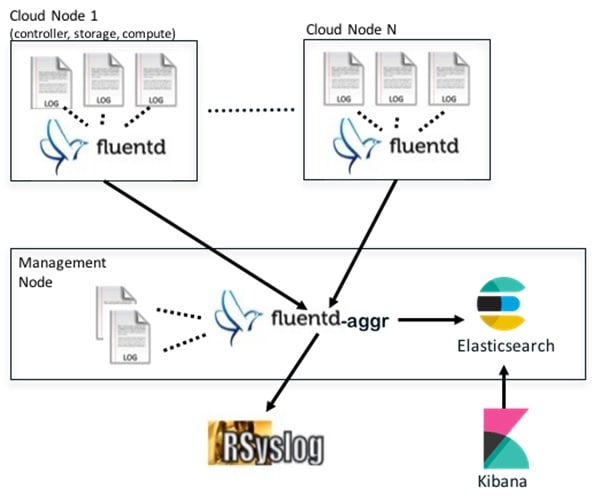
The EFK flow includes:
- Fluentd extracts the relevant data from the logs and tags them so that Kibana can use it later to display useful information about those logs.
- Fluentd sends the logs from all the compute, controller, and storage nodes to the Fluentd-aggr server on the management node.
- Fluentd-aggr in the management node sends the structured logs into the Elasticsearch database.
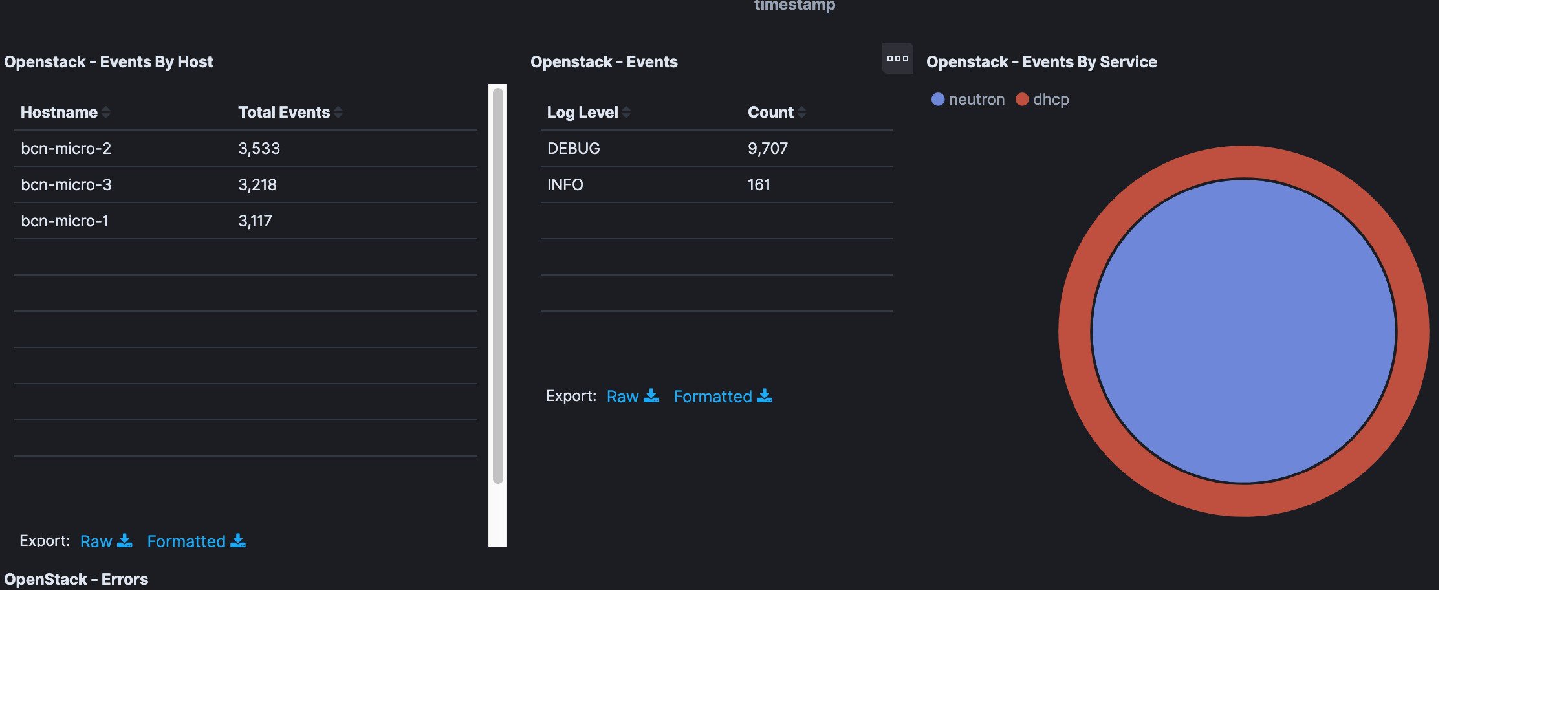
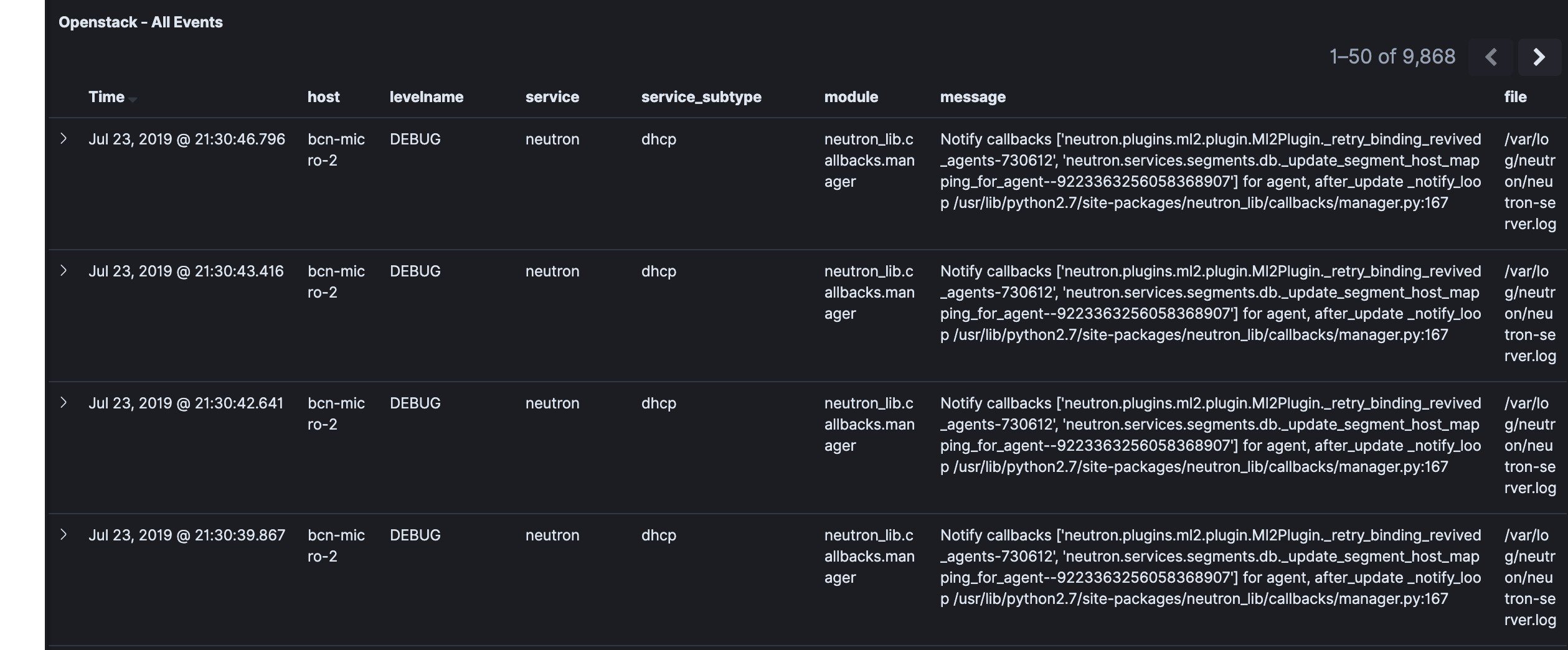
- Elasticsearch stores the data, indexes it, and supports fast queries against a large amount of log data.
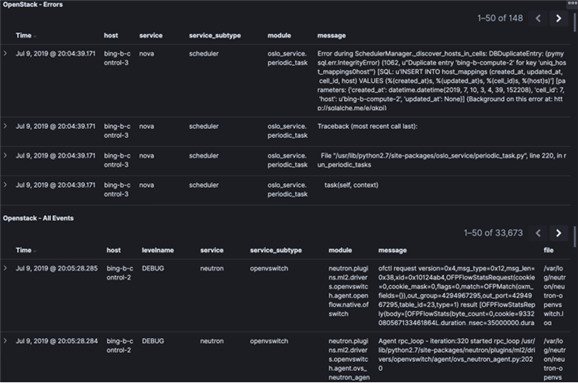
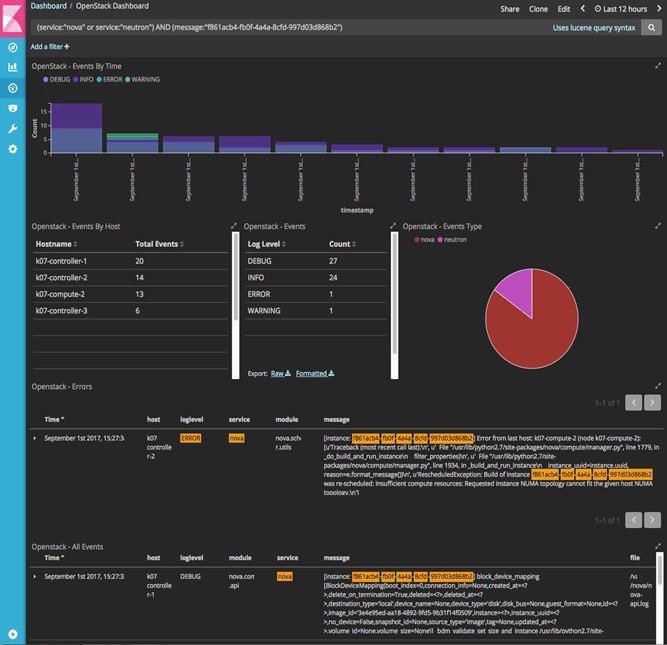
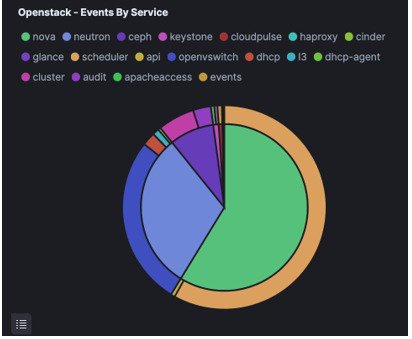
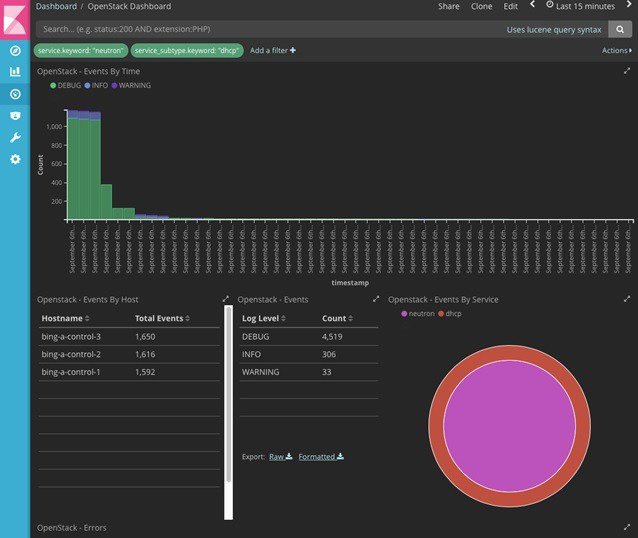
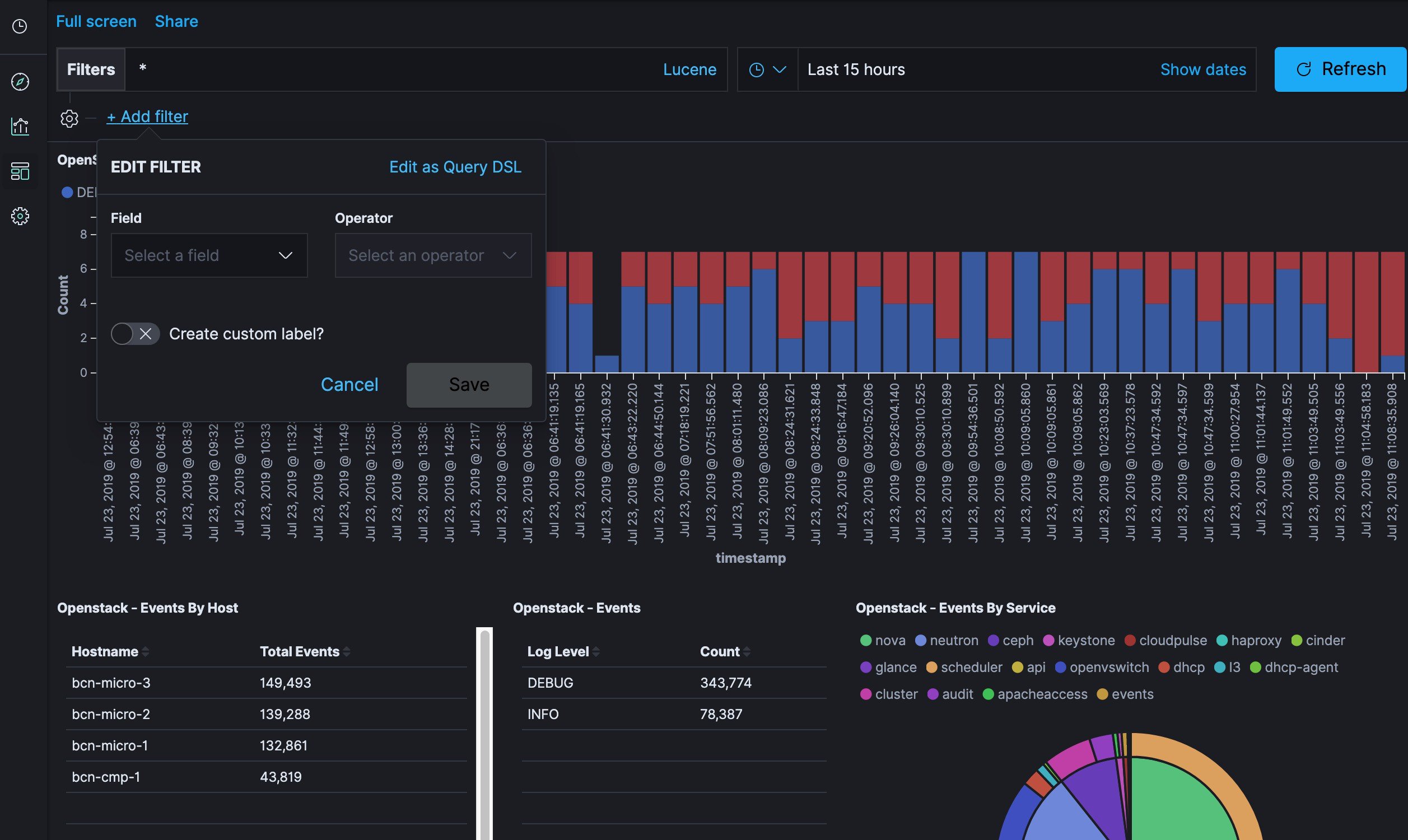
- Kibana visualizes the data that is stored in Elasticsearch using a custom dashboard. You can also add filters to the data to visualize interesting fragments of the log data.




 Feedback
Feedback