Status LEDs and Buttons
This section contains information for interpreting front, rear, and internal LED states.
Front-Panel LEDs
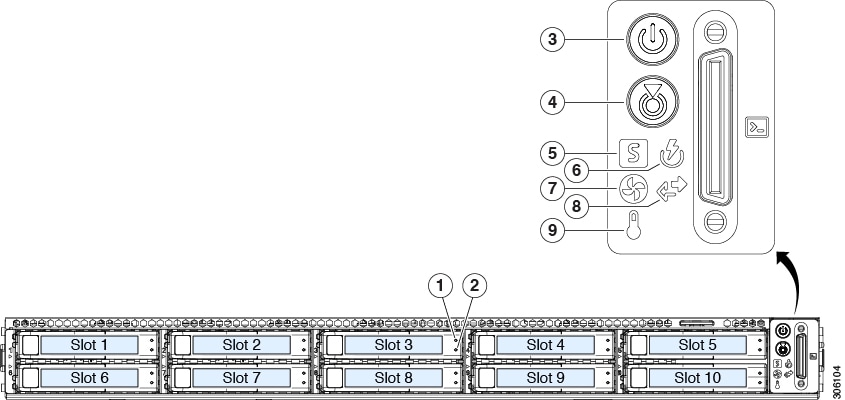
|
LED Name |
States |
|||
|
1 SAS |
SAS/SATA drive fault
|
|
||
|
2 SAS |
SAS/SATA drive activity LED |
|
||
|
1 NVMe |
NVMe SSD drive fault
|
|
||
|
2 NVMe |
NVMe SSD activity |
|
||
|
3 |
Power button/LED |
|
||
|
4 |
Unit identification |
|
||
|
5 |
System health |
|
||
|
6 |
Power supply status |
|
||
|
7 |
Fan status |
|
||
|
8 |
Network link activity |
|
||
|
9 |
Temperature status |
|
Rear-Panel LEDs

|
LED Name |
States |
|
|
1 |
1-Gb/10-Gb Ethernet link speed (on both LAN1 and LAN2) |
|
|
2 |
1-Gb/10-Gb Ethernet link status (on both LAN1 and LAN2) |
|
|
3 |
1-Gb Ethernet dedicated management link speed |
|
|
4 |
1-Gb Ethernet dedicated management link status |
|
|
5 |
Rear unit identification |
|
|
6 |
Power supply status (one LED each power supply unit) |
AC power supplies:
|
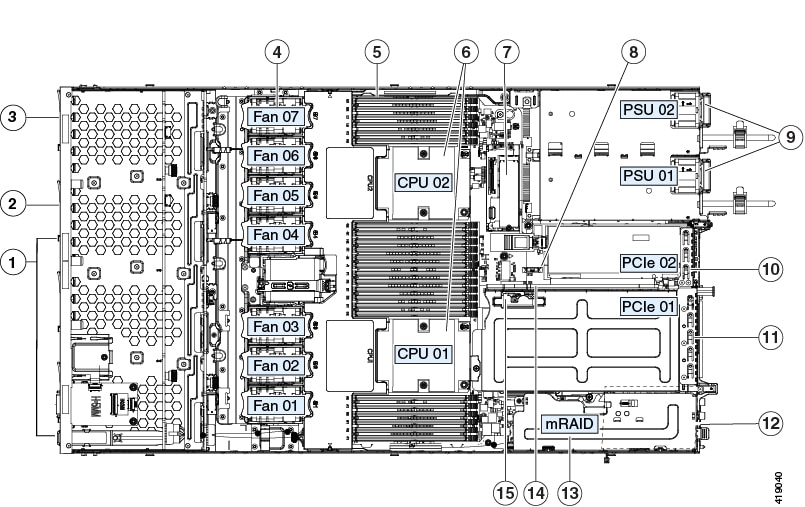
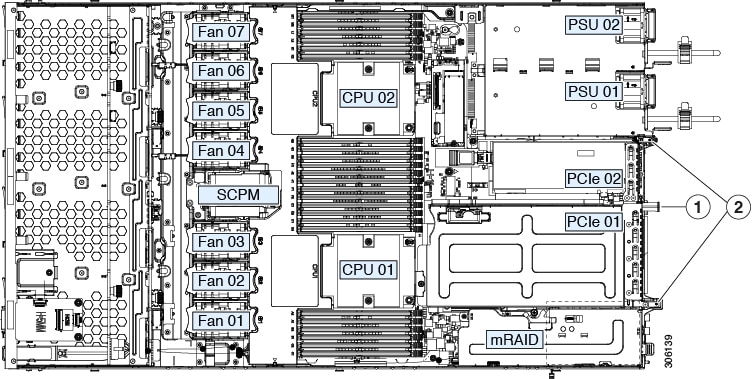
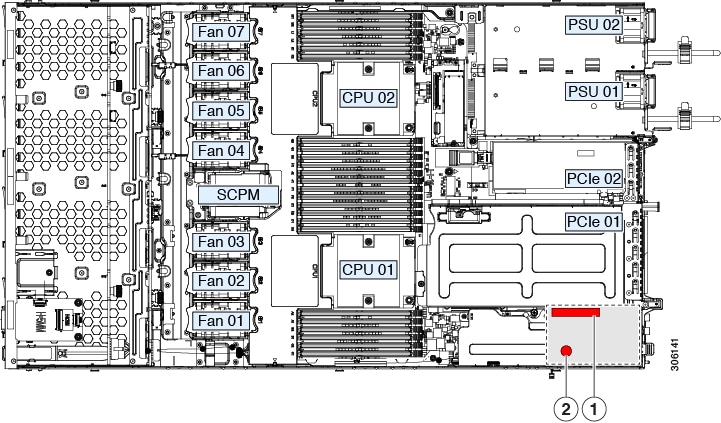
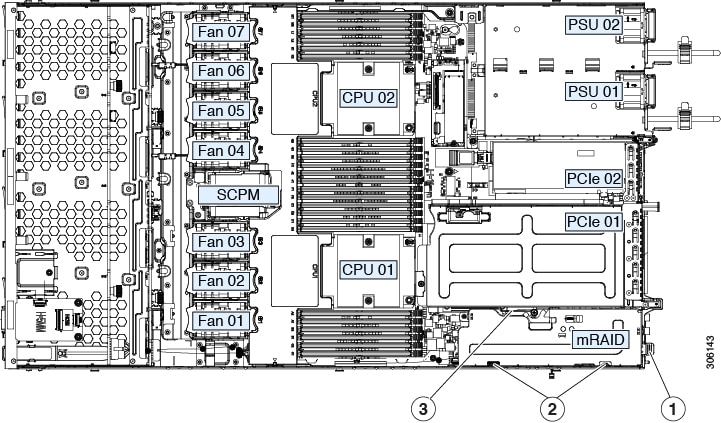
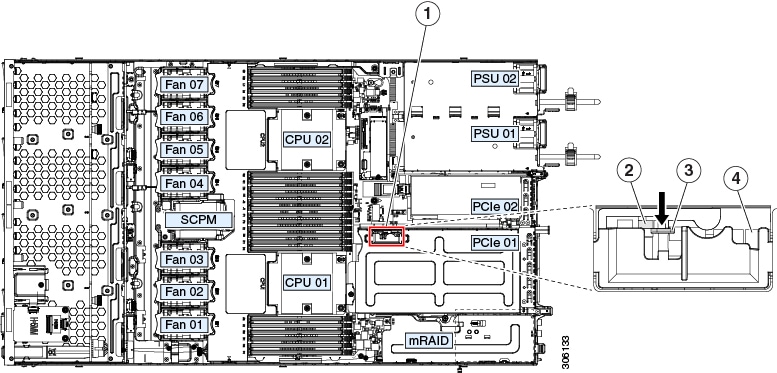
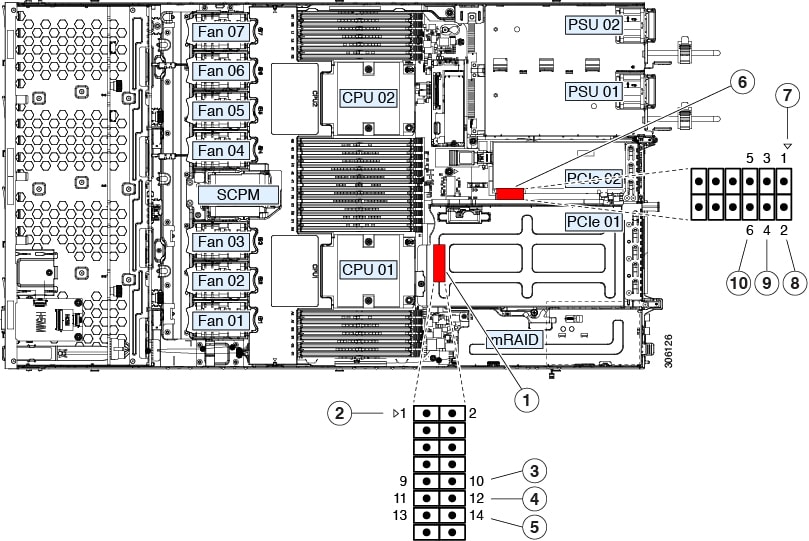
Internal Diagnostic LEDs
The server has internal fault LEDs for CPUs, DIMMs, and fan modules.
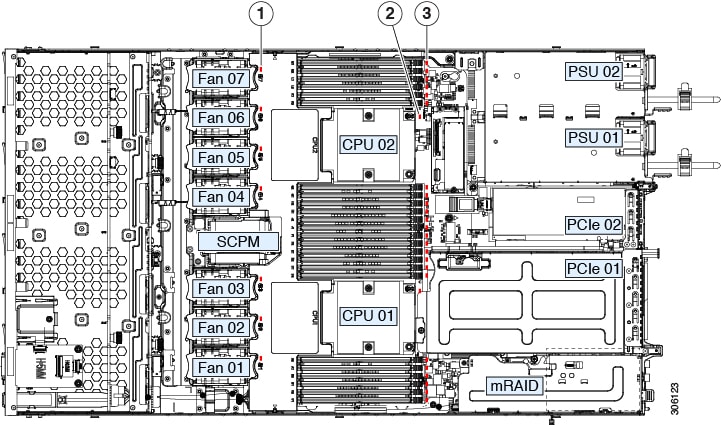
|
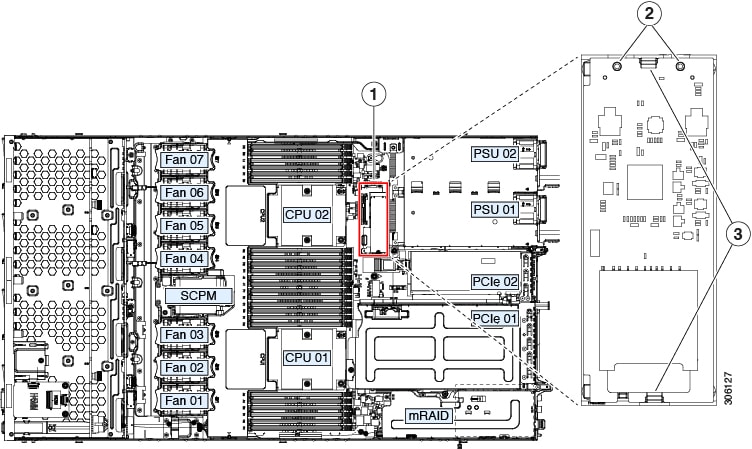
1 |
Fan module fault LEDs (one behind each fan connector on the motherboard)
|
3 |
DIMM fault LEDs (one behind each DIMM socket on the motherboard) These LEDs operate only when the server is in standby power mode.
|
|
2 |
CPU fault LEDs (one behind each CPU socket on the motherboard). These LEDs operate only when the server is in standby power mode.
|
- |







 Feedback
Feedback