
New and changed information
The following table provides an overview of the significant changes up to this current release. The table does not provide an exhaustive list of all changes or of the new features up to this release.
| Release Version | Feature | Description |
|---|---|---|
|
Nexus Dashboard 4.1.1 |
Improved navigation and workflow when detecting anomalies for Nexus Dashboard |
Beginning with Nexus Dashboard 4.1.1, the navigation and workflow when detecting anomalies for Nexus Dashboard have been enhanced. |
|
Nexus Dashboard 4.1.1 |
Ability to view platform and system alerts in global anomalies and advisories tables |
Beginning with Nexus Dashboard 4.1.1, an option to view platform and system alerts in the global Anomalies page and Advisories page of Nexus Dashboard has been introduced. For more information, see View platform and system alerts in global anomalies table and View platform and system alerts in global advisories table. |
|
Nexus Dashboard 4.1.1 |
Fix me option to resolve telemetry configuration anomalies |
Beginning with Nexus Dashboard 4.1.1, Nexus Dashboard includes Fix me option to resolve telemetry configuration anomalies and restore normal telemetry operations on affected switches. For more information, see Resolve telemetry configuration anomalies on switches. |
Anomalies
Nexus Dashboard proactively detects different types of anomalies across the network, analyzes the anomalies, and identifies remediation methods.
Nexus Dashboard collects and analyzes data from all nodes within the fabric, establishing a baseline to define "normal" behavior. Deviations from this baseline are flagged as anomalies. This allows you to focus on resolving issues rather than tracking them. Furthermore, the Nexus Dashboard can assess the anomaly’s impact and provide tailored recommendations based on its nature, thereby reducing the mean time to troubleshooting and resolution (MTTR). This helps in accelerated troubleshooting, enhanced operational efficiency, and effective remediation.
The Anomalies page displays the anomalies by level and category for your fabrics, based on the chosen time range.
-
The Anomaly level donut chart displays the total number of anomalies of Critical, Major, Minor, and Warning severities.
-
The Category list displays the number of anomalies grouped by various categories, such as Hardware, Capacity, Compliance, Connectivity, Configuration, Integrations, Active bugs, Telemetry configuration, and System.
About CRC Anomalies
CRC anomalies are raised based on the error count with respect to total packets received within 60 mins interval. If the number of CRC Error counter reached 5% of Total Packets Received - the anomaly severity is set to Warning. If the error rate crosses 7% the severity becomes Major. If the error rate crosses 10% the severity becomes Critical.
Understanding anomaly correlation
The anomaly correlation functionality identifies cause-and-effect relationships between various anomalies within a specific time frame. It examines attributes such as device, interface, and protocols to pinpoint the root cause anomaly. This root cause anomaly acts as the primary issue that triggers the secondary anomalies, known as correlated anomalies. This approach helps in pinpointing the root cause, enabling efficient resolution of related issues.
Root cause anomalies
A root cause anomaly is an anomaly that causes other anomalies, which are referred to as correlated anomalies. Resolving the root cause anomaly should resolve the correlated anomalies.
Correlated anomalies
A correlated anomaly occurs because another anomaly, known as the root cause anomaly, triggers it. Resolving the root cause automatically resolves the correlated anomalies, without needing to take further action for them.
Nexus Dashboard release 4.1.1 introduces anomaly correlation with route events for NX-OS switches. Route correlation for ACI fabrics is not supported in this release.
-
Admin shut event (Parent) and AM Route Delete event (Child)
-
Interface Down (Parent) and AM Route Delete event (Child)
-
OSPF Neighbor Lost (Parent) and OSPF Route Delete event (Child)
-
AM/OSPF Route Delete event (Parent) and BGP Neighbor down (Child)
-
BGP Neighbor Down (Parent) and BGP Route Delete event (Child)
-
Route Delete event (Parent) to Service Endpoint Traffic Score Unhealthy (Forward drop)
-
Route Delete event (Parent) to Endpoint Traffic Score Unhealthy (Forward drop)

AM route refers to a route learned through the Adjacency Manager.
Uncorrelated anomalies
An uncorrelated anomaly neither causes correlated anomalies nor results from a root cause anomaly. Therefore, it does not affect any other anomalies. You must resolve each uncorrelated anomaly individually.
An uncorrelated anomaly can also be an anomaly that Nexus Dashboard does not yet evaluate for correlated anomalies. Nexus Dashboard will be able to evaluate these anomalies for correlated anomalies in a future release.
Anomaly levels
Anomalies are classified into the following levels based on their severity and impact.
-
Critical — Anomalies are shown as critical when the network is down. Some of the examples include:
-
When connectivity to a given prefix or endpoint is lost
-
When a fabric or switch is not operational.
-
-
Major — Anomalies are shown as major when connectivity to a given prefix or endpoint could be compromised. An example includes:
-
Overlapping IP addresses or subnets
-
-
Minor — Anomalies are classified as minor when they represent less severe issues that do not immediately impact network connectivity but may require attention. Examples include:
-
Interface errors or packet drops below threshold
-
Non-critical hardware component warnings
-
-
Warning — Anomalies are shown as warnings when there are best practice violations or when components such as power supply units (PSUs) are non-redundant.
Anomaly properties
You can configure these properties on an anomaly.
-
Assign a user
-
Add tags
-
Add a comment
-
Set verification status
-
Acknowledge an anomaly so that the acknowledged anomalies are not displayed in the Anomalies table
For more information, see Configure anomaly properties.
You can acknowledge anomalies in these ways.
-
Manually acknowledge an anomaly. See Configure anomaly properties.
-
Manually acknowledge multiple anomalies. See Analyze anomalies.
-
Use anomaly rules to automatically acknowledge anomalies matching anomaly rules. See Create anomaly rules.
Navigate to the Anomalies
You can view anomalies in Nexus Dashboard at different levels such as across all fabrics, for a specific fabric, for a specific switch, or for system-wide anomalies. Use the following methods to access anomaly information.
-
To view all anomalies across all fabrics, you can navigate to Analyze > Anomalies.
This displays all anomalies detected across all fabrics in your environment.
-
Follow these steps to view the anomalies for a single fabric.
-
Navigate to Home > Overview.
-
Choose online fabrics or snapshot fabrics from the drop-down list.
-
Click the Anomaly level card.
-
In the Anomalies page, click Analyze Anomalies to view detailed information for the selected fabric.
-
-
You can also view the anomalies for a single fabric in the Fabrics Overview page.
-
Navigate to Manage > Fabrics.
-
Choose an appropriate fabric.
The Fabrics Overview page displays.
-
Click the Anomalies tab to view anomalies specific to that fabric.
-
Follow these steps to view the anomalies for a single switch in the Inventory page.
-
Navigate to Manage > Inventory.
-
Choose online fabrics or snapshot fabrics from the drop-down list.
-
Choose a switch.
The Switch Overview page displays.
-
Click the Anomalies tab.
Follow these steps to view the system anomalies.
-
Navigate to Admin > System Status.
-
Click the Anomalies tab.
Analyze anomalies
Follow these steps to analyze anomalies.
-
From the drop-down list, choose Grouped, Ungrouped, or Root events.
-
The Ungrouped view displays the individual anomalies raised for your fabrics.
-
The Grouped view displays the aggregated view of the anomalies based on the anomaly type.
-
The Root events table displays root events that cause dependent anomalies. You can view root events until Nexus Dashboard deletes them, which happens only after it deletes all the associated dependent anomalies.
-
-
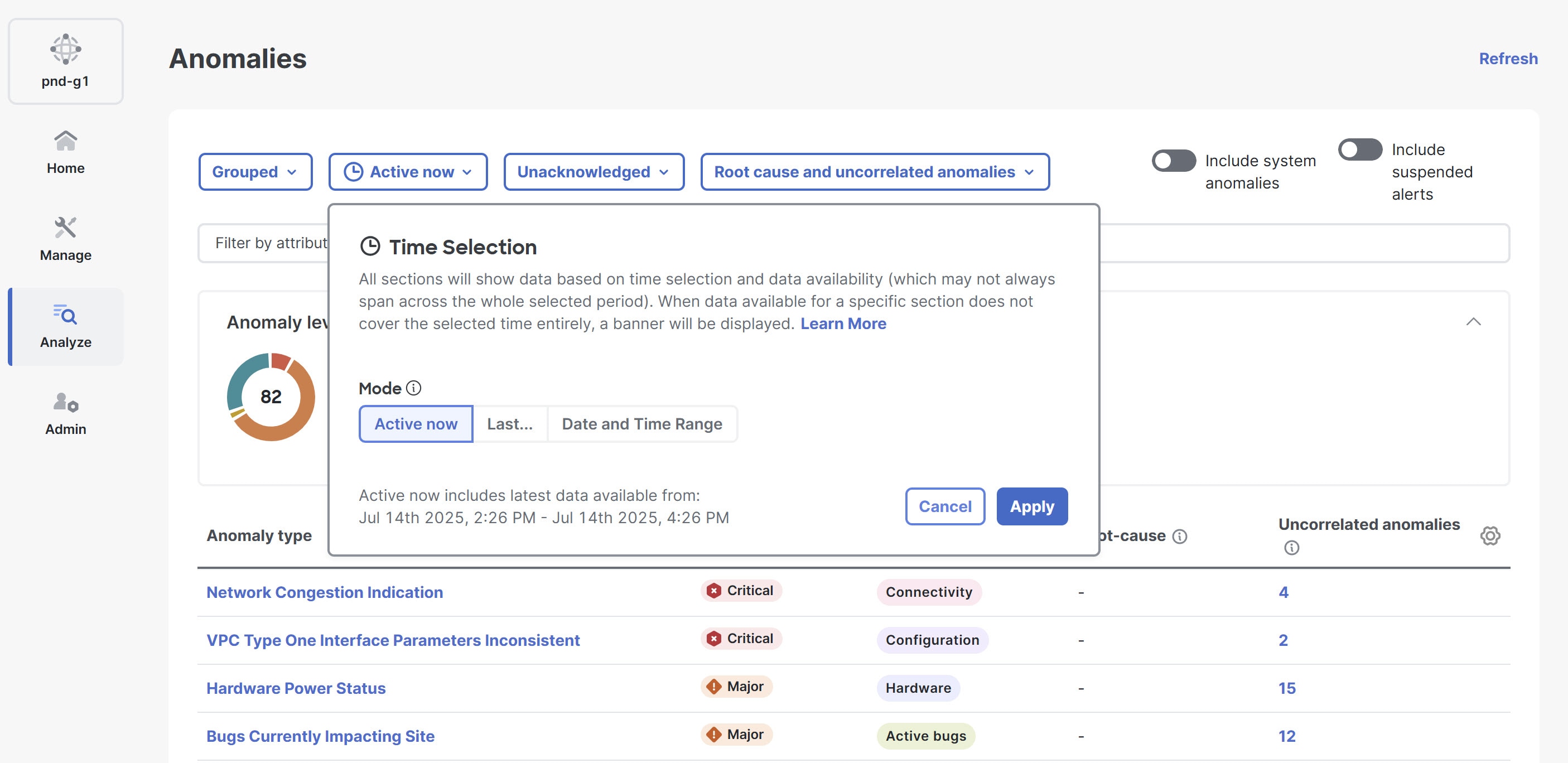
Go to Active now > Time Selection, to choose the date and time range. By default, Active now is chosen. You can customize the date and time range to determine the data displayed in the Anomalies table.
The Anomalies page displays the anomalies by level and category for your fabrics, based on the chosen time range.
-
The Anomaly level donut chart displays the total number of anomalies of Critical, Major, Minor, and Warning severities.
-
The Category list displays the number of anomalies grouped by various categories, such as Hardware, Capacity, Compliance, Connectivity, Configuration, Integrations, Active bugs, Telemetry configuration, and System.

-
For snapshot fabrics, the anomalies shown represent all detected anomalies across all snapshots, not just those from the latest snapshot.
-
-
If you want to include system anomalies in the Anomalies table, click the Include system anomalies toggle button. Note that the System category appears in the Category list only when you enable the Include system anomalies toggle button.
For more information, see View platform and system alerts in global anomalies table.
-
If you want to include suspended alerts, click the Include suspended alerts toggle button.
For more information, see Alerts suspend mode for anomalies and advisories.
-
Use the filter field to filter the anomalies. You can filter affected objects such as interface, VRF instance, EPG, or BD and view the associated anomalies.
-
When you view the ungrouped anomalies, you can use the drop-down list next to the filter field to filter for unacknowledged or acknowledged anomalies. The default is Unacknowledged.
-
You can use the drop-down list next to the unacknowledged and acknowledged anomalies drop-down list to filter by root cause and uncorrelated anomalies, root cause anomalies only, uncorrelated anomalies only, or all anomaly types. The default is All anomaly types.
For more information about the filters, see Anomaly filters.
-
-
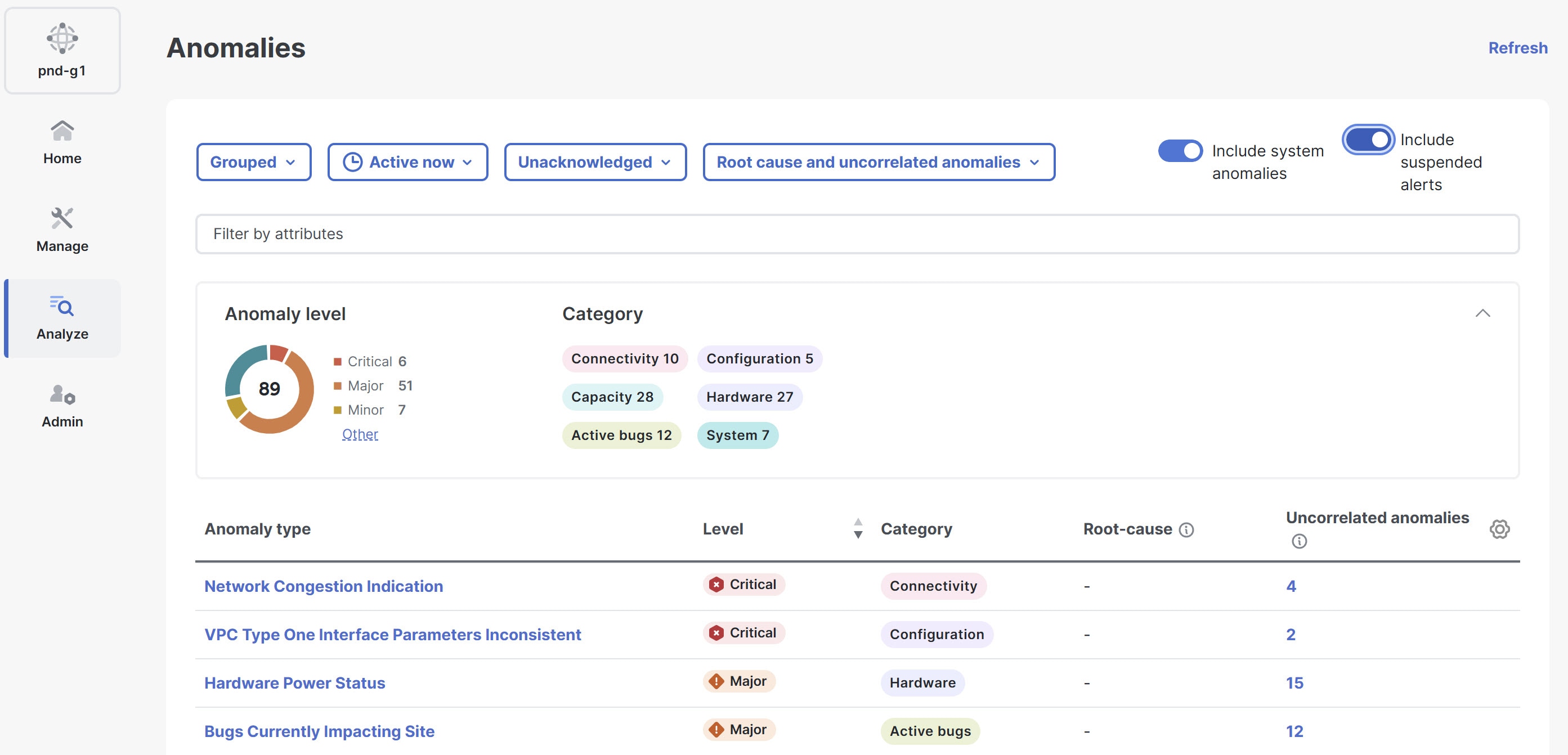
The Anomalies table displays the filtered anomalies. By default, the anomalies are sorted by level. Click the column heading to sort the anomalies in the table.
When you view the ungrouped anomalies and configure the table to display the Status column, the status appears as either Active or Cleared. An Active status means the anomaly is present in your network, while a Cleared status means the anomaly is no longer present.
-
Click the gear icon to configure which columns display in the Anomalies table.
By default, the columns Anomaly type, Level, Category, Root-cause, and Uncorrelated anomalies are displayed for grouped anomalies. The Root-cause column shows how many anomalies in that group are root cause anomalies.
By default, the columns What’s wrong, Level, Category, Fabric, Detection time, and Correlated anomalies/events are displayed for ungrouped anomalies.
-
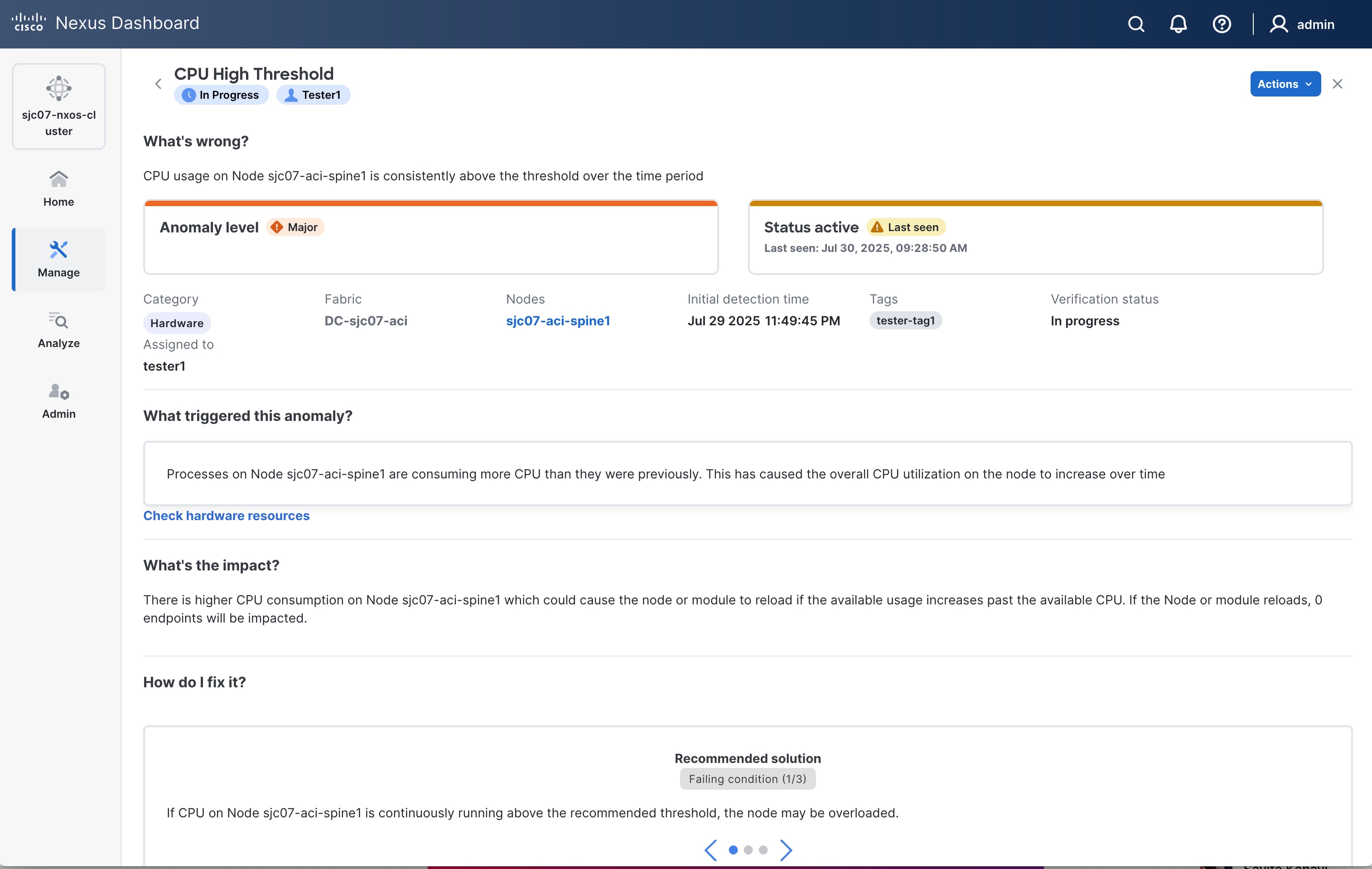
Click an anomaly to view more information.
The Anomaly Name page displays these details.
-
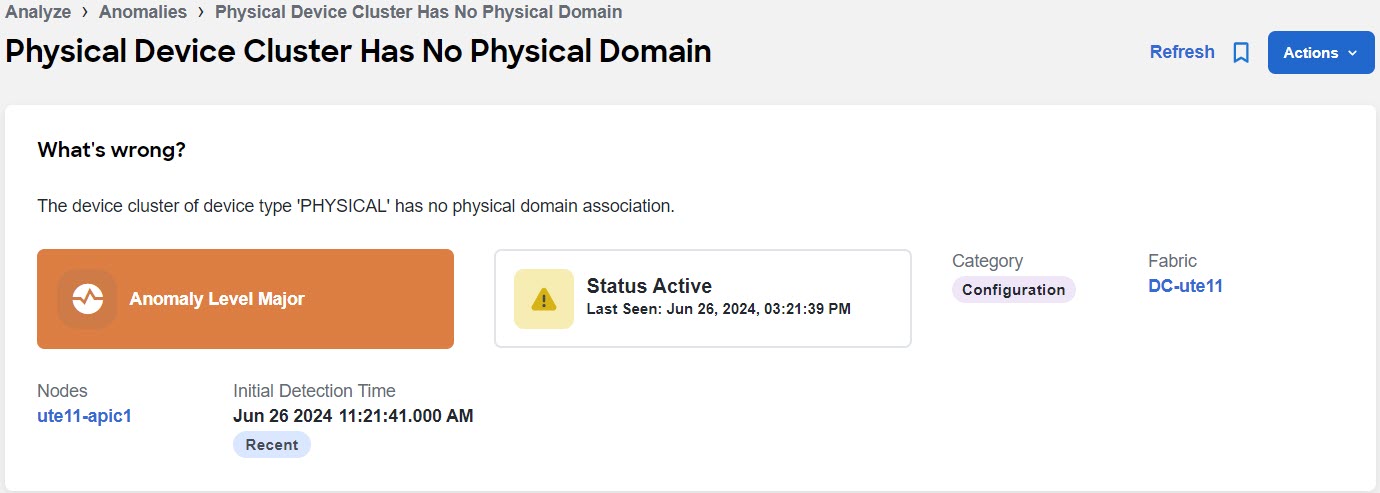
What’s wrong? — provides a problem description with the specific affected objects.
-
What triggered this anomaly? — provides the primary source of the anomaly, including a link that you can click to see information about it. This area includes a graph that shows the root cause anomaly and all correlated anomalies. You can click an anomaly in the graph to get more information about that anomaly. The controls at the lower right of the area enable you to zoom the graph in or out and view the topology legend. This area appears only for correlated anomalies.
-
What’s the impact? — explains the potential impact if the problem is not fixed. If the anomaly is a root cause, it also shows the number of correlated anomalies. You can click this number to view a table listing those correlated anomalies.
For root cause anomalies, this area includes a graph that shows the root cause anomaly and all correlated anomalies. You can click an anomaly in the graph to get more information about that anomaly. The controls at the lower right of the area enable you to zoom the graph in or out and view the topology legend.
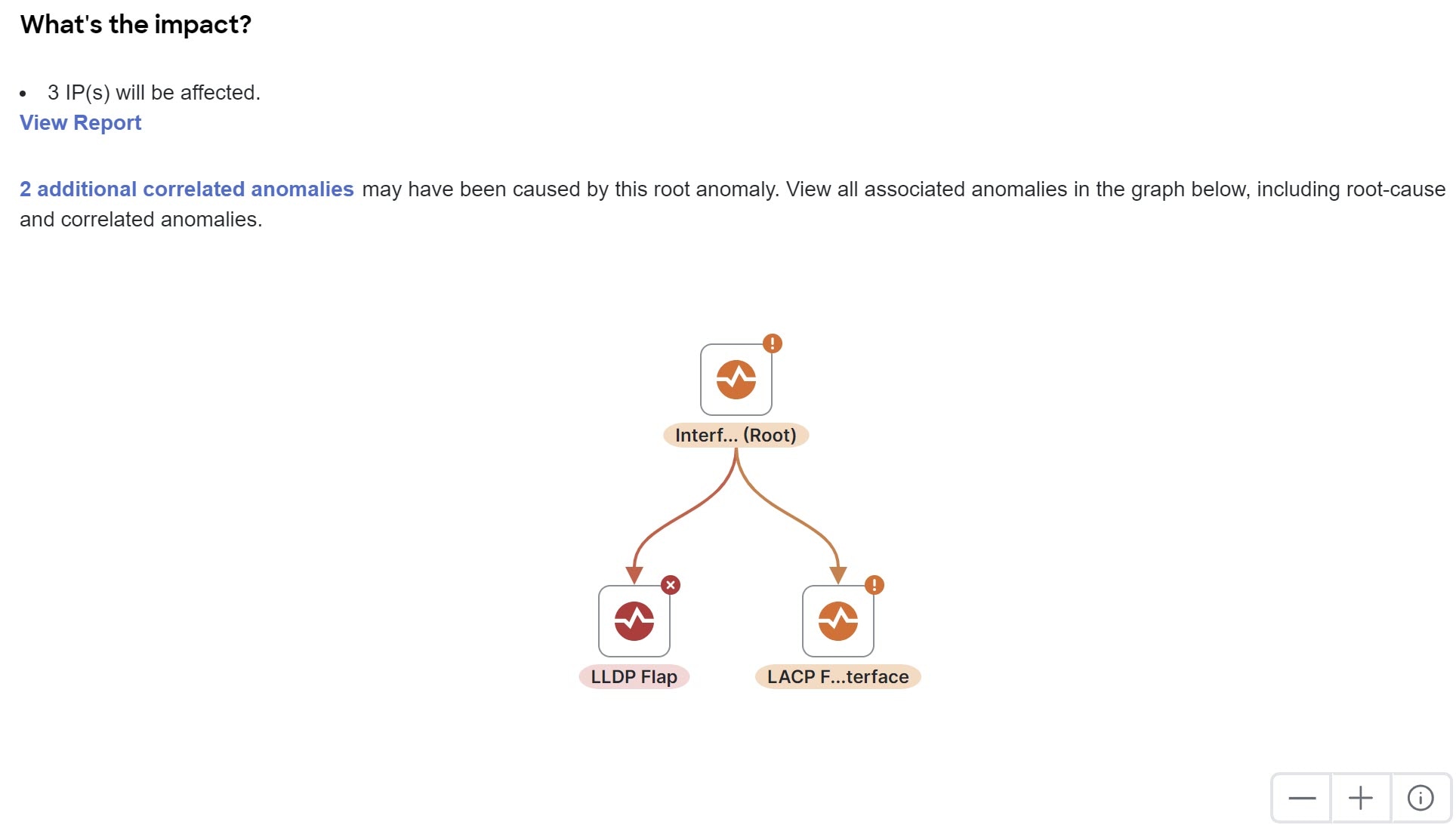
When you view the correlated anomalies page and you configure the table to display the Status column, the status can be Active, Cleared, or Deleted. The Active status indicates that the anomaly is present in your network. The Cleared status indicates that the anomaly is not present in your network anymore. The Deleted status indicates that the system deleted the anomaly from the anomalies database due to being aged out, but the anomaly is not yet deleted from this page because some of its correlated anomalies still exist.
-
How do I fix it? — provides prescriptive recommendations.
-
-
From the drop-down list in the Anomalies page, choose Ungrouped.
-
Choose anomalies from the Anomalies table and click Acknowledge anomalies to acknowledge the anomalies.
-
You can also click an anomaly, then click the ellipses (…) next to each anomaly, and choose Acknowledge anomaly from the drop-down list.
By default, all the unacknowledged anomalies are displayed in the Anomalies table. After you acknowledge an anomaly, choose Acknowledged from the drop-down list to view all the acknowledged anomalies.
-
Resolve telemetry configuration anomalies on switches
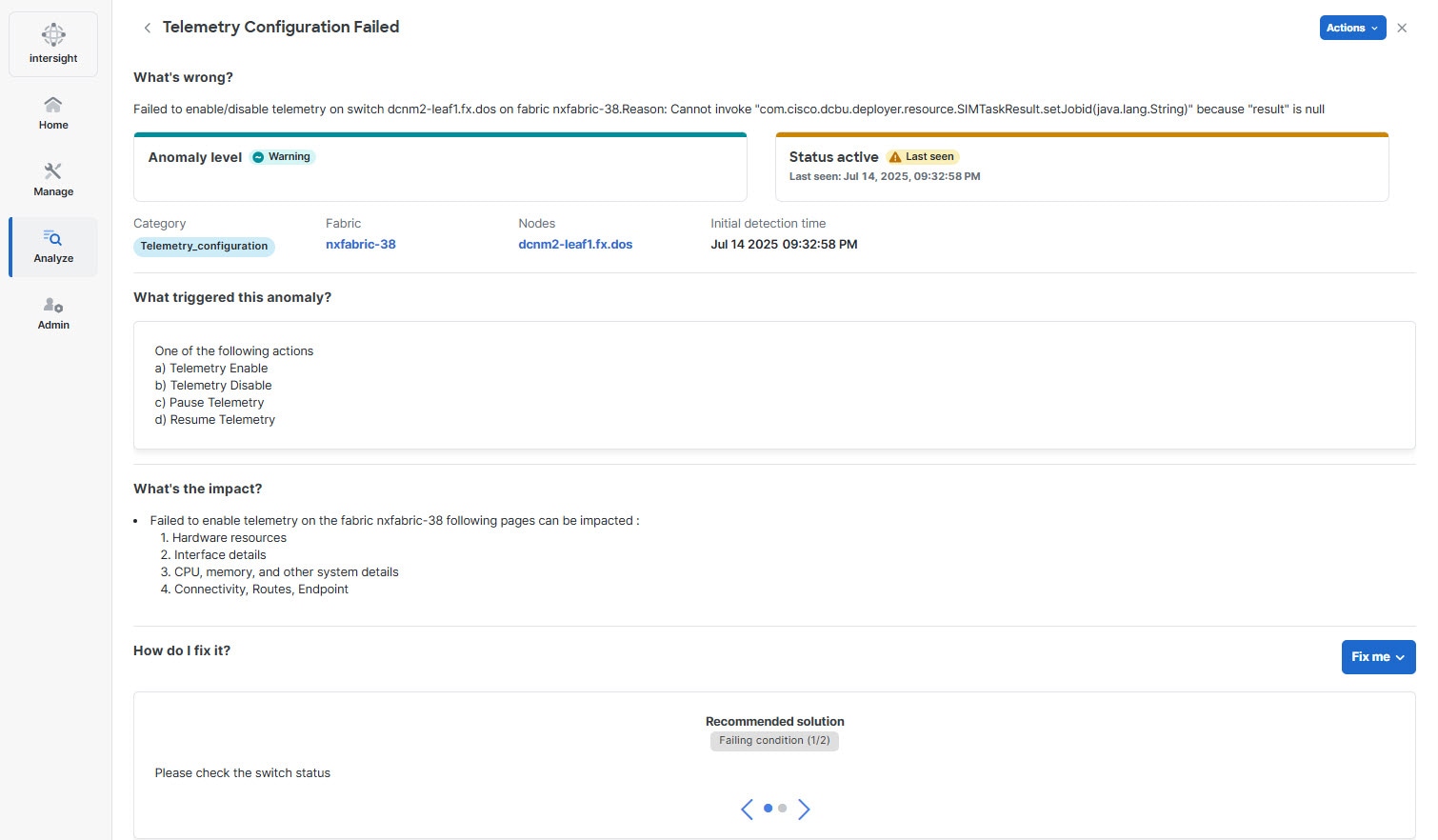
Policy gateway anomalies are categorized under Telemetry configuration. If telemetry configuration fails on a switch, you can resolve the issue using the Fix me option available in the How do I fix it? section in the Telemetry Configuration Failed page. This option helps to systematically resolve telemetry configuration anomalies and restore normal telemetry operations on affected switches.
Follow these steps to resolve the telemetry configuration anomalies.
-
In the Anomalies table, click a Telemetry configuration anomaly.
The Telemetry Configuration Failed page displays.
-
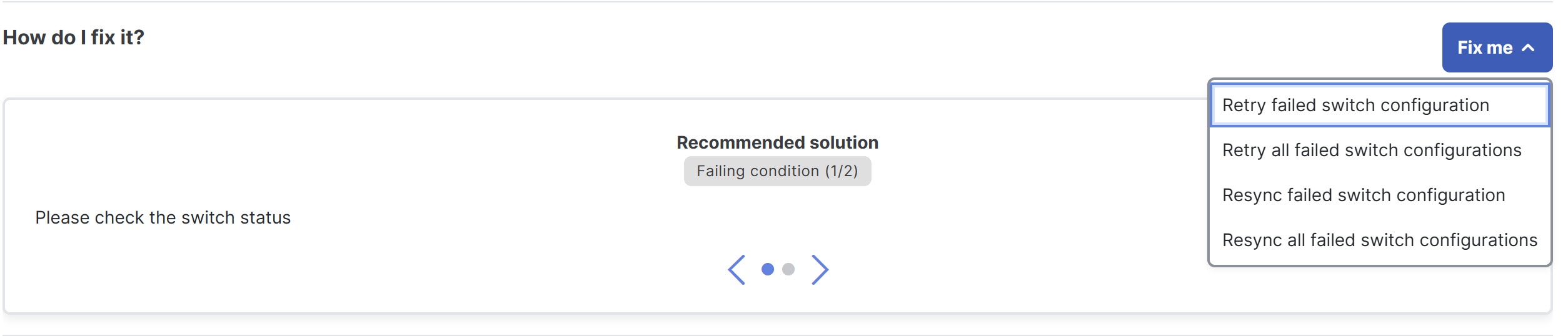
In the How do I fix it? section, click the Fix me drop-down list.
You can view these options.
Field Description Retry failed switch configuration
Attempts to re-apply the configuration only on switches where the telemetry configuration previously failed.
Retry all failed switch configuration
Attempts to re-apply the configuration on all switches that have failed telemetry configuration. This option does not remove any stale or failed configurations on the affected switches, it only attempts to reconfigure the telemetry configurations on the failed switches.
Resync failed switch configuration
Synchronizes and re-applies the telemetry configuration on switches with failed configurations to ensure consistency. This option is ideal for issues related to flow collection, traffic analytics, and flow rules configuration anomalies.
Resync all failed switch configuration
Synchronizes and re-applies telemetry configurations on all switches with any failed telemetry configuration.
-
Choose one of these options from the Fix me drop-down list to resolve telemetry configuration anomalies.
View platform and system alerts in global anomalies table
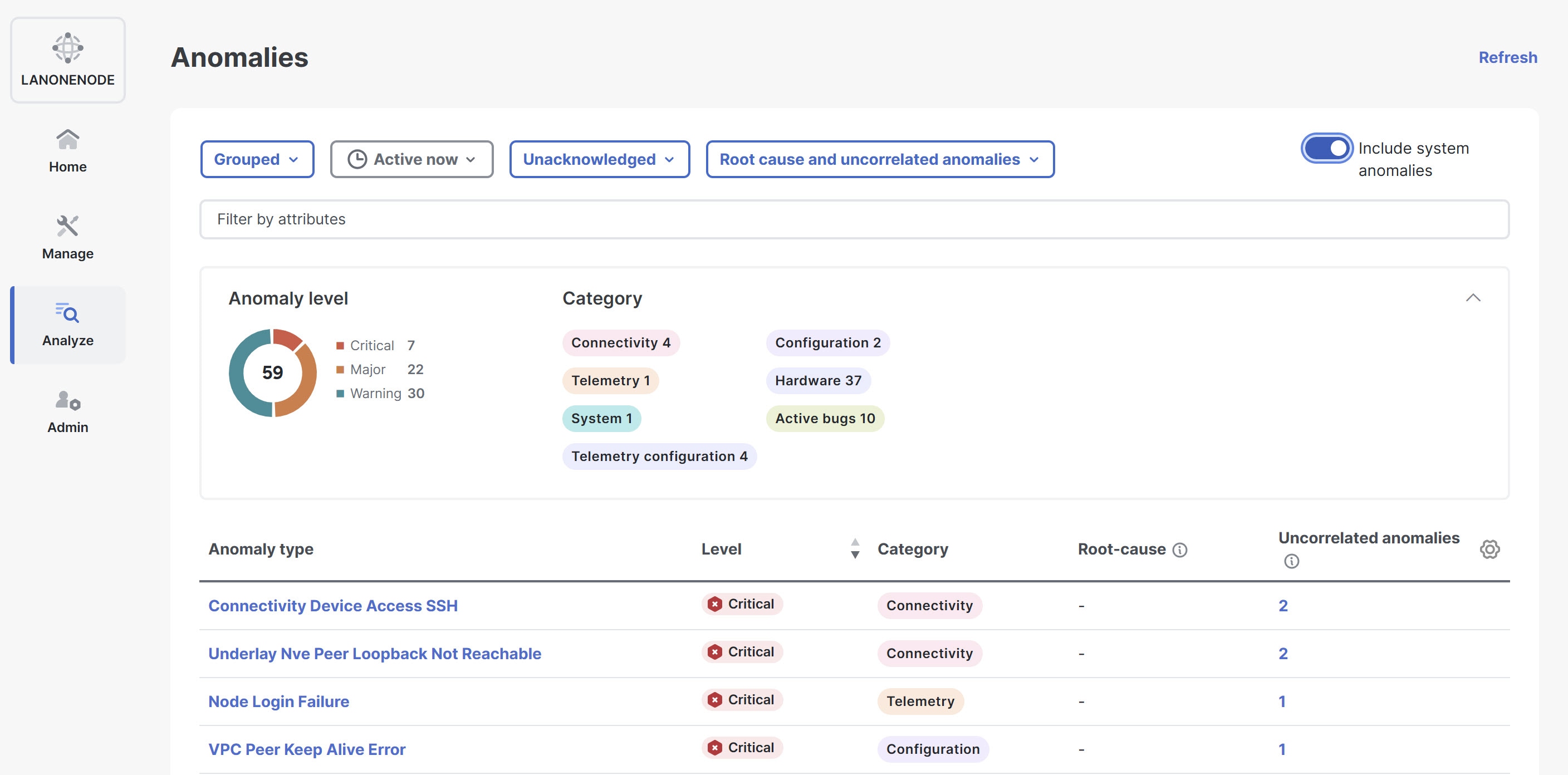
Anomalies that affect a Nexus Dashboard cluster but are not necessarily associated with a fabric are referred to as system anomalies. These anomalies can include issues such as hardware malfunctions, capacity constraints, compliance violations, connectivity disruptions, configuration errors, and active bugs. Enabling system anomalies allows you to identify the root cause, improve network health, and enhance operational efficiency.
Follow these steps to include system-related anomalies.
-
Navigate to Analyze > Anomalies.
The Anomalies page displays.
-
Click the Include system anomalies toggle button in the top-right corner, to include system-related anomalies in the Anomalies table.
Once enabled, the System category appears under anomalies by category in the Anomalies page.
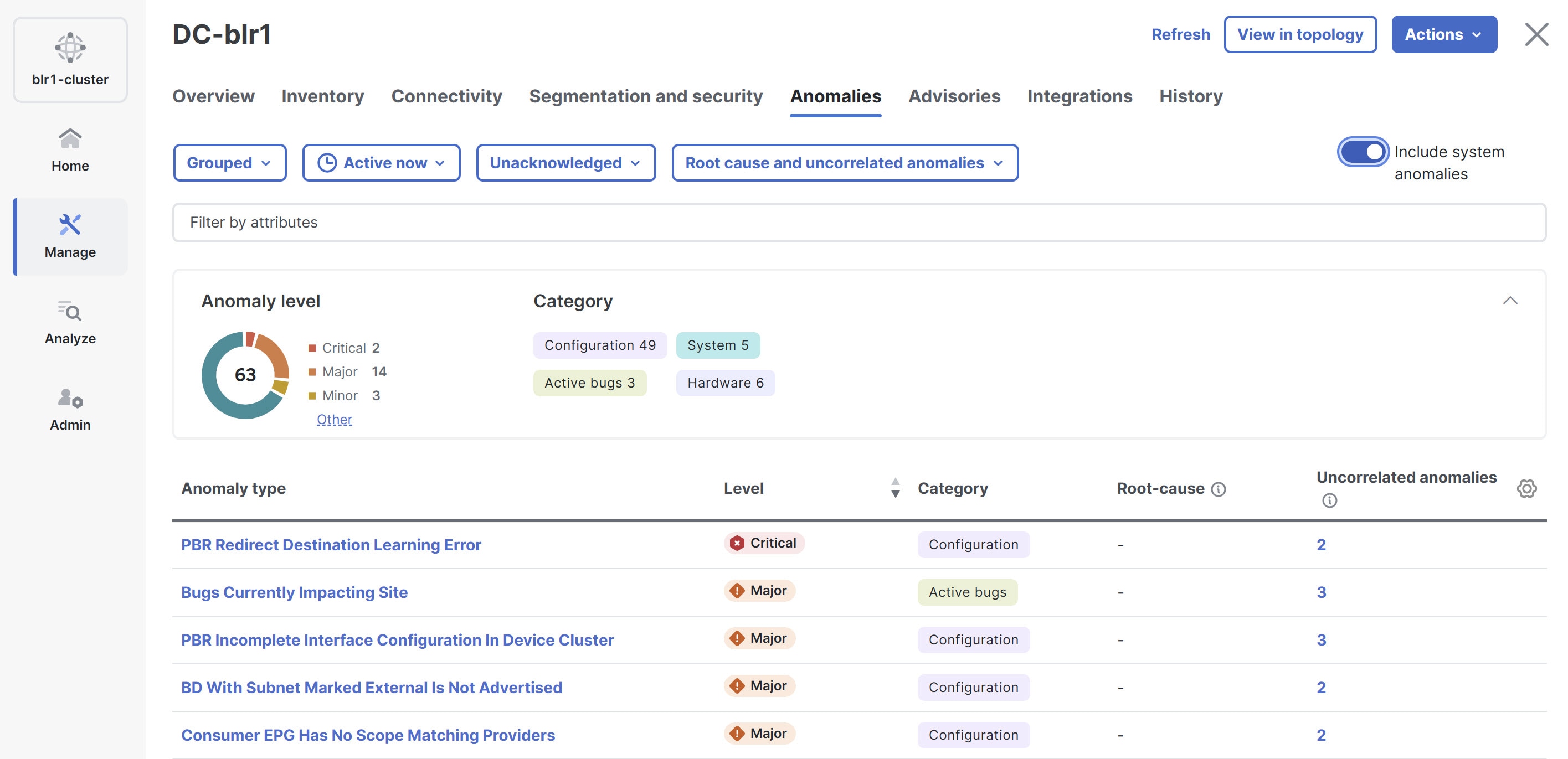
Follow these steps to include system-related anomalies at fabric level.
-
Navigate to Manage > Fabrics.
-
In the Fabrics page, choose the appropriate fabric.
The Fabric Overview page displays.
-
In the Fabric Overview page, click the Anomalies tab.
-
Click the Include system anomalies toggle button in the top-right corner, to include system-related anomalies in the Anomalies table.
Once enabled, the System category appears in the anomalies by category card in the Anomalies page.
System anomaly notification
When an active system anomaly impacts the cluster health, a notification alert appears on the Notifications bell icon located in the common navigation bar at the top of the page. Click the notification bell icon to open the Notifications pane. In the Notifications pane, click View system anomalies. Nexus Dashboard redirects you to the System Status page, where you can review the full list of current and past system anomalies in the Anomalies table.
Nexus Dashboard will not display a notification alert if the cluster health is not affected.
Guidelines and limitations for anomalies
-
In the following scenarios, anomalies are not displayed in the Anomalies page.
-
Anomalies that belong to the category "System" are not displayed in the Anomalies page by default.
-
When there is any collection or login failure, in the Admin > System Settings > System Status Details page, Assurance status is displayed as Healthy. At the same time, in the Admin > System Settings > System Issues page, anomalies related to any collection or login failure are not displayed.
To view the anomalies, perform the following steps:
-
To view these anomalies, Navigate to Analyze > Anomalies.
-
Select Online Fabrics from the drop-down list.
-
Select Ungrouped from the All Anomalies drop-down list.
-
Use the search bar to filter on category == system. All system anomalies are displayed in the anomalies table.
-
-
-
For any fabric, the data is purged in either of the following scenarios:
-
After the thirty day retention period
-
When the storage threshold is reached
As a result, the anomalies and advisories for that fabric are not displayed. You have to rerun the analysis to view the anomalies and advisories.
-
-
In Nexus Dashboard, invalid and stale alarms are periodically cleared every 24 hours.
-
When you upgrade a device, there may be instances where traps are not sent or received by the Nexus Dashboard, resulting in anomalies not being raised or cleared."
Configure anomaly properties
Use the following procedure to configure properties on an anomaly.
-
Navigate to Analyze > Anomalies.
-
Choose Online fabrics or Snapshot fabrics from the drop-down menu.
-
From the Anomalies drop-down menu, choose Ungrouped.
The Ungrouped view displays the individual anomalies raised for your fabrics.
-
From the Time Selection dialog, choose the desired mode, then click Apply. The default is Active Now.
-
For Last…, you must also choose a period.
-
For Date and Time Range, you must also choose the range.
-
-
Click an anomaly from the table and then choose a property from the Actions menu.
-
Choose Acknowledge Anomaly to acknowledge an anomaly. By default all the unacknowledged anomalies are displayed in the anomalies table. After you acknowledge an anomaly, choose Acknowledged from the drop-down list to view all the acknowledged anomalies.
-
Choose Verification Status to set a user defined status such a New, In Progress, or Closed to an anomaly. Choose a status from the drop-down list and click Save.
-
Choose Assigned To to assign an anomaly to an user. Enter the username and click Save.
-
Choose Comment to assign a comment to an anomaly. Enter a comment and click Save.
-
Choose Manage Tags to add user-defined tags to an anomaly. Enter the tag name and click Save. You can enter multiple tags. After entering the tag name, press Enter.
-
-
To acknowledge multiple anomalies, select the anomalies. Click Acknowledge anomalies.
-
To view the the properties assigned to an anomaly, click an anomaly to view the Anomaly page. In the Anomaly page, properties such as Verification Status, Acknowledge, and Assigned To are displayed. To view comments and tags assigned to an anomaly, from the Actions menu, choose Comment or Manage Tags.
Anomaly filters
The filter field allows you to filter the table of anomalies when viewing the ungrouped anomalies, or filter the table of anomaly types when viewing the grouped anomalies.
In the Anomalies page, you can use the following filters to refine entries in the table:
-
Anomaly Type - Display anomalies with a specific type.
-
Assigned To - (Ungrouped, only) Display anomalies assigned to a specific user.
-
BD - Display anomalies with a specific bridge domain.
-
Category - Display anomalies from a specific category.
-
Check code - (Ungrouped, only) Display anomalies with a specific check code.
-
Cleared Time - (Ungrouped, only) Display anomalies with a specific cleared time.
-
Comment - (Ungrouped, only) Display anomalies with a specific comment.
-
Detection Time - (Ungrouped, only) Display anomalies with a specific detection time.
-
EPG - Display anomalies with a specific EPG.
-
Fabric - (Ungrouped, only) Display anomalies for a specific fabric.
-
Interface - Display anomalies with a specific interface.
-
IP address - (Ungrouped, only) Display anomalies with a specific IP address.
-
Last Seen Time - (Ungrouped, only) Display anomalies with a specific last seen time. Last Seen Time indicates the time the anomaly was updated while under active status. If the status of the anomaly is not cleared, then the anomaly is active.
-
Level - Display anomalies of a specific level.
-
MAC address - Display anomalies with a MAC address.
-
Nodes - Display anomalies for specific nodes.
-
Status - Displays anomalies that have the specified status.
-
Tags - (Ungrouped, only) Display anomalies with a specific tag.
-
VPC - Display anomalies with a specific virtual port channel (vPC).
-
VRF - (Ungrouped, only) Display anomalies with a specific virtual routing and forwarding (VRF) instance.
-
Verification Status - (Ungrouped, only) Display anomalies with a specific verification status.
-
What’s Wrong - (Ungrouped, only) Displays anomalies of a specific affected object.
As a secondary filter refinement, use the following operators:
-
== - With the initial filter type, this operator, and a subsequent value, returns an exact match. This operator is available for all filters.
-
!= - With the initial filter type, this operator, and a subsequent value, returns all that do not have the same value. This operator is available for most filters.
-
contains - With the initial filter type, this operator, and a subsequent value, returns all that contain the value. This operator is available for some filters.
-
!contains - With the initial filter type, this operator, and a subsequent value, returns all that do not contain the value. This operator is available for some filters.
Filtering for acknowledged or unacknowledged anomalies
This drop-down menu next to the filter field enables you to filter the anomalies the unackowledged or ackowledged status. Choose Acknowledged to filter out unackowledged anomalies. Choose Unacknowledged to filter out ackowledged anomalies.
Filtering for root cause and uncorrelated anomalies
This drop-down menu near to the filter field enables you to filter for root cause and uncorrelated anomalies, which filters the table of anomalies accordingly.
You can choose the following filters:
-
Root Cause and Uncorrelated Anomalies - The table displays root cause anomalies and uncorrelated anomalies, but not correlated anomalies. This is the default value because it shows only the anomalies that you must manually resolve. If you resolve the root cause anomalies, then the correlated anomalies also get resolved. Because of this, it is not as important for you to see the correlated anomalies.
-
Root Cause Anomalies Only - The table displays only root cause anomalies.
-
Uncorrelated Anomalies - The table displays only uncorrelated anomalies.
-
All Anomaly Types - The table displays all anomalies.
Determine the primary affected object for an anomaly
To filter for anomalies using a combination of affected object filters, such as IP address, MAC address, interface, VPC, EPG, and VRF, all the provided filter objects should be a primary affected object for any given anomaly. The filter will not return results if the query contains non-primary affected objects.
Follow these steps to determine the primary affected object for a particular anomaly.
-
To determine the primary affected object for a particular anomaly, navigate to Analyze > Anomalies.
-
If you want determine the object from the ungrouped anomalies, choose Ungrouped from the drop-down menu.
-
If you want determine the object from the grouped anomalies, choose Grouped from the drop-down menu, then click the desired anomaly type in the table.
-
Choose an anomaly from the Anomalies table.
-
In the What’s the impact? area, the primary affected objects are highlighted in bold.
Global rules
Global rules
Global rules page enables you to see which anomaly levels are enabled for the different anomaly categories. You can also customize the thresholds that determine whether an anomaly is assigned the warning, major, or critical level.
Customize anomaly level thresholds
Follow these steps to customize anomaly level thresholds.
-
Navigate to Manage > Anomaly and Compliance Rules > Global Rules.
-
Locate the row with the anomaly category that you want to customize, then click the entry in the Status column on that row.
These are the anomaly categories that you can customize in Global Rules - the threshold customizations that are available differ for each of the anomaly categories:
Capacity
This information applies if Capacity is the entry in the Anomaly Category column and you click the entry in the Status column on that row.
-
In the Customize thresholds for capacity anomalies table, find the anomaly whose thresholds you want to customize and click the edit (pencil) icon.
The Customize thresholds for capacity anomalies table can have multiple pages. If necessary, use the page controls at the bottom of the table to find the desired anomaly.
-
Enter the desired percent for each anomaly level, then click the green check mark.
After you customize the thresholds, Nexus Dashboard recalculates the anomaly levels of existing anomalies, which takes approximately 30 minutes to complete.
You can click Reset to reset the values to their default or X to cancel the edit.
-
The values can be from 0 to 100. A value of 0 indicates Nexus Dashboard will not raise any anomalies for that severity. If you enter 0 for all of the severities, Nexus Dashboard suppresses the anomaly completely.
-
The value for Warning must be lower than the value for Major, and the value for Major must be lower than the value for Critical.
-
The value defined for Major sets the upper end limit of the range defined for Warning, and the value defined for Critical sets the upper end limit of the range defined for Major.
-
Hardware
This information applies if Hardware is the entry in the Anomaly Category column and you click the entry in the Status column on that row.
In the Customize Hardware page, choose the appropriate category:
Fabric Management
The Fabric Management Anomaly Thresholds option under Hardware is available for NX-OS fabrics only.
-
In the Fabric Management Anomaly Thresholds table, find the anomaly whose thresholds you want to customize and click the edit (pencil) icon.
The Fabric Management Anomaly Thresholds table can have multiple pages. If necessary, use the page controls at the bottom of the table to find the desired anomaly.
-
In the Warning, Minor, Major, and Critical columns, enter the desired percent for each anomaly level, then click the green check mark.
-
The values can be from 0 to 100. A value of 0 indicates Nexus Dashboard will not raise any anomalies for that severity. If you enter 0 for all of the severities, Nexus Dashboard suppresses the anomaly completely.
-
The value for Warning must be lower than the value for Minor, the value for Minor must be lower than the value for Major, and the value for Major must be lower than the value for Critical.
-
The value defined for Minor sets the upper end limit of the range defined for Warning, the value defined for Major sets the upper end limit of the range defined for Minor, and the value defined for Critical sets the upper end limit of the range defined for Major.
-
-
In the Forwarding column, determine if you want to enable forwarding using email, SNMP, or all, or leave the option set at None if you do not want to enable forwarding.
After you customize the thresholds, Nexus Dashboard recalculates the anomaly levels of existing anomalies, which takes approximately 30 minutes to complete.
You can click Reset to reset the values to their default or X to cancel the edit.
-
To enable notifications for the CPU, memory, power usage, or temperature anomaly types, locate the appropriate row and toggle the button in the Enable column to the on position.
Toggle the button in the Enable column back to the off position to disable the appropriate notification.
Telemetry
-
In the Customize thresholds for capacity anomalies table, find the anomaly whose thresholds you want to customize and click the edit (pencil) icon.
The Customize thresholds for capacity anomalies table can have multiple pages. If necessary, use the page controls at the bottom of the table to find the desired anomaly.
-
Enter the desired percent for each anomaly level, then click the green check mark.
After you customize the thresholds, Nexus Dashboard recalculates the anomaly levels of existing anomalies, which takes approximately 30 minutes to complete.
You can click Reset to reset the values to their default or X to cancel the edit.
-
The values can be from 0 to 100. A value of 0 indicates Nexus Dashboard will not raise any anomalies for that severity. If you enter 0 for all of the severities, Nexus Dashboard suppresses the anomaly completely.
-
The value for Warning must be lower than the value for Major, and the value for Major must be lower than the value for Critical.
-
The value defined for Major sets the upper end limit of the range defined for Warning, and the value defined for Critical sets the upper end limit of the range defined for Major.
-
Connectivity
These areas are available under Connectivity:
Fabric Management Anomaly Thresholds
The Fabric Management Anomaly Thresholds option under Connectivity is available for NX-OS fabrics only.
-
In the Fabric Management Anomaly Thresholds table, find the anomaly whose thresholds you want to customize and click the edit (pencil) icon.
The Fabric Management Anomaly Thresholds table can have multiple pages. If necessary, use the page controls at the bottom of the table to find the desired anomaly.
-
In the Warning, Minor, Major, and Critical columns, enter the desired percent for each anomaly level, then click the green check mark.
-
The values can be from 0 to 100. A value of 0 indicates Nexus Dashboard will not raise any anomalies for that severity. If you enter 0 for all of the severities, Nexus Dashboard suppresses the anomaly completely.
-
The value for Warning must be lower than the value for Minor, the value for Minor must be lower than the value for Major, and the value for Major must be lower than the value for Critical.
-
The value defined for Minor sets the upper end limit of the range defined for Warning, the value defined for Major sets the upper end limit of the range defined for Minor, and the value defined for Critical sets the upper end limit of the range defined for Major.
-
-
In the Forwarding column, determine if you want to enable forwarding using email, SNMP, or all, or leave the option set at None if you do not want to enable forwarding.
After you customize the thresholds, Nexus Dashboard recalculates the anomaly levels of existing anomalies, which takes approximately 30 minutes to complete.
You can click Reset to reset the values to their default or X to cancel the edit.
-
To enable notifications for any of the anomaly types available under Fabric Management Anomaly Thresholds, locate the appropriate row and toggle the button in the Enable column to the on position.
Toggle the button in the Enable column back to the off position to disable the appropriate notification.
Interface Anomaly Option
-
In the Interface Anomaly Option table, find the anomaly whose thresholds you want to customize and click the edit (pencil) icon.
The Interface Anomaly Option table can have multiple pages. If necessary, use the page controls at the bottom of the table to find the desired anomaly.
The Edit Interface Anomaly Option page appears.
-
In the Edit Interface Anomaly Option page, make the appropriate choices for the interface anomaly option:
-
Toggle the button in the Enable field to the on position to enable this option, or in the off position to disable this option.
-
In the Forwarding field, determine if you want to enable forwarding using email, SNMP, or all, or leave the option set at None if you do not want to enable forwarding.
-
In the Severity field, determine if you want to set the severity threshold at Minor, Major, Warning, or Critical.
-
Click Save to save the configured interface anomaly option.
After you customize the thresholds, Nexus Dashboard recalculates the anomaly levels of existing anomalies, which takes approximately 30 minutes to complete.
-
Syslog Rules
Syslog Alarm Policy defines a pair of Syslog messages formats; one which raises the alarm, and one which clears the alarm.
-
To add a syslog rule, click Add Syslog Rule.
The Add Syslog Rule page appears.
-
Enter the necessary information to add a syslog rule.
Field Description Identifier
Specify the identifier portions of the raise and clear messages.
Syslog Raise
Define the format of a syslog raise message. The syntax is as follows: Facility-Severity-Type: Message
Syslog Clear
Define the format of a syslog clear message. The syntax is as follows: Facility-Severity-Type: Message
Policy Name
Specify the name for this policy. It must be unique.
Policy Details
Specify a brief description for this policy.
Forwarding
Determine if you want to enable forwarding using email, SNMP, or all, or leave the option set at None if you do not want to enable forwarding
Severity
Determine if you want to set the severity threshold at Minor, Major, Warning, or Critical.
What is wrong
Enter text that describes what went wrong.
What triggered it
Enter text that describes what went triggered the alarm.
What’s the impact
Enter text that describes what the impact is.
How do I fix it?
Enter text that describes how to fix the issue.
-
Determine how you want to proceed after entering the information for the syslog rule.
-
Click Save and Add New to save the information for this syslog rule and to add another syslog rule
-
Click Save to save the information for this syslog rule and exit the page
-
Click Cancel to exit out of the page without saving
-
Anomaly rules
Anomaly rules
Anomaly rules feature enables you to acknowledge all new detected anomalies that match the criteria and adjust the anomaly score accordingly. You can also match an alert against an anomaly rule using the match criteria.
It also allows you to customize an anomaly by adding a custom message that will be displayed when an anomaly is raised based on the anomaly rule.
-
An anomaly rule contains the match criteria required to match an anomaly against the rule and the action that should be applied on the matched anomaly.
-
An anomaly rule can contain multiple match criteria.
-
You can use attributes such as severity, category, event name, and object match rule, to define the match criteria for the anomaly rule.
-
A match criteria can contain one attribute or multiple attributes.
-
If a match criteria contains multiple attributes, then the anomalies containing all the attributes will be matched. The AND operator will apply to the attributes.
-
If a match criteria contains multiple affected object match rules, then the anomalies containing all of the affected object match rules will be matched.
-
-
If an anomaly rule contains multiple match criteria, then the anomalies containing the union of the match criteria will be matched. Any anomalies that match any criteria will apply to the rule. The OR operator will apply to the criteria.
-
Anomaly Rules using Match Criteria with Object Match Rule will only support the Equals to regex criteria.
-
An Anomaly rule can be enabled only if it contains at least one match criteria.
-
Anomaly rules are not supported for advisories.
-
If you created multiple anomaly rules, all rules that match get applied.
-
If you specified multiple attributes in an anomaly rule, the conditions of each attribute must be met for the rule to apply.
-
If you specified multiple conditions for an attribute, any of the conditions must be met for the attribute to evaluate as true.
-
If you specified multiple match criteria within an affected object, each criteria must be met.
Guidelines and limitations
-
Deleting or disabling an anomaly rule containing either Acknowledge or Customize Anomaly action will not delete or disable the anomaly rule from active anomalies. The anomaly rule will not be applied to any new instance of the anomaly only.
-
When you edit an anomaly rule containing either Acknowledge or Customize Anomaly action, the updates are not applied to active anomalies. The anomaly rule updates will be applied to any new instance of the anomaly only.
-
If an anomaly rule contains both Acknowledge and Customize Anomaly action, and you edit the anomaly rule by removing either the Acknowledge and Customize Anomaly action, then the updates are not applied to active anomalies.
-
When you delete or disable an anomaly rule containing Customize Anomaly action, the recommendations are still displayed in the How do I fix it area.
-
You can only manually unacknowledge anomalies, including those that are automatically acknowledged by an anomaly rule. You cannot automatically unacknowledge these anomalies by disabling or deleting the anomaly rules.
-
If you manually unacknowledge an anomaly that was previously acknowledged by an anomaly rule, re-applying the same anomaly rule (even with the Apply to existing active anomalies option checked) may not re-acknowledge that specific anomaly. In such cases, you need to manually acknowledge it.
-
When you configure an anomaly rule with both Acknowledge and Customize anomaly actions, and check the Apply to existing active anomalies checkbox, the rule may not acknowledge active anomalies that were previously manually unacknowledged. However, the custom message action is applied to all existing active anomalies.
For example, if you set a rule to acknowledge and add a custom message to
L3 QoS TCAM Threshold Exceededanomalies, the custom message appears on all the 8 existing anomalies. However, the rule acknowledges only 2 out of 8 anomalies, if the other 6 anomalies are unacknowledged manually earlier. -
Maximum anomaly rules supported across all fabrics is 500.
-
In the following scenario, you cannot use an alert rule to automatically acknowledge existing active anomalies matching the match criteria by selecting the Apply to existing active anomalies check-box in the Create Anomaly Rule page.
If a streaming anomaly is raised before the alert rule is created, then it can take up to 6 hours for the rule to come into effect.
-
An anomaly is raised before the alert rule is created and there are no further updates to the anomaly after the alert rule is created.
In this scenario, you can manually acknowledge the anomalies. See Configure anomaly properties.
-
-
After upgrading to this release, some anomaly rules may be updated or deleted. You can manually add these rules after the upgrade based on the new categories and severity.
-
Anomaly rules using match criteria with an object match rule or code rule does not apply to anomalies with the one of the following categories: Active Bugs, Capacity, Hardware, Integrations, or Connectivity.
Create anomaly rules
-
Navigate to Manage > Anomaly and Compliance Rules > Anomaly Rules.
-
Click Create Anomaly Rule.
-
Complete the following fields for General.
-
In the Name field, enter the name.
-
In the Description field, enter the description.
-
Choose the state to enable the rule to be active.
-
Click Next.
-
-
Complete the following fields for Settings.
-
Click Add Criteria to define the match criteria for the anomaly rule.
-
From the Fabric drop-down list, select the fabric. Only the match criteria for the fabric running the analysis will be selected and matched with the alerts to perform the action.
-
Select the attributes for the match criteria. You can use category, event title, object match rule, code rule, and severity to define the attribute for the match criteria. Select category and event title from the drop-down list.
-
Click Add Object Match Rule to define the primary affected objects for the match criteria.
-
Click Add Code Rule to define the check code for the match criteria.
-
Select severity from the drop-down list.
-
Click Save.
-
-
Complete the following fields for Actions.
-
Use toggle to choose Acknowledge.
-
Check Apply to existing active anomalies check-box to apply the anomaly rule to existing instance of the anomalies matching the alert anomaly. Uncheck the check-box to apply the anomaly rule to match to new instance of anomalies.
-
-
Use toggle to choose Customize Anomaly.
-
Enter the recommendations to be displayed in the anomaly rule. You can create multiple rules based on different matching criteria to have more than one customized recommendation displayed in the anomaly rule. In the Anomaly page, the recommendations are displayed in the How do I fix it? area.
-
Check Apply to existing active anomalies check-box to apply the anomaly rule to existing instance of the anomalies matching the anomaly rule. Uncheck the check-box to apply the anomaly rule to match to new instance of anomalies.
-
-
-
In the Summary, review your selections and click Add Anomaly Rule. The new anomaly rule is displayed in the Anomaly Rule table.
Manage anomaly rules
-
Navigate to Manage > Anomaly and Compliance Rules > Anomaly Rules. The anomaly rules are displayed in the Anomaly Rule table.
-
Use the search bar to filter the rules based on Name, Actions, and State.
-
Select an anomaly rule and click Edit Rule to edit.
-
Select an anomaly rule and click Delete Rule to delete the rule from the system.
-
Select an anomaly rule and click ellipsis icon. Click Enable to enable the rule. If the state is enabled, the rule will be applied in the next analysis. Before enabling an anomaly rule make sure that at least one match criteria is present in the anomaly rule.
-
Select an anomaly rule and click ellipsis icon. Click Disable to disable the rule. If the state is disabled, the rule will not be applied during the next analysis.
Advisories
Advisories
Nexus Dashboard identifies field notices, software and hardware end-of-life and end-of-sale announcements, as well as PSIRTs that can potentially impact the network fabrics that it is monitoring, and generate advisories. Advisories provides recommendations to keep your network under support and running in optimal conditions.
Advisories in Nexus Dashboard provide details of relevant impact from field notices, PSIRTs, EoL/EoS of hardware and software, and best practices. You can view the advisories by level and category for a particular fabric based on the selected time range.
When Advisories identifies field notices that can potentially impact the network fabrics that it is monitoring, Nexus Dashboard validates the serial number of the devices in the fabrics against a list of affected device serial numbers in each field notice. If a serial number is not included in a field notice, Nexus Dashboard excludes that field notice. For Advisories to validate the device serial numbers, Nexus Dashboard must have an Internet connection and be connected to and registered to Cisco Intersight. Without such connectivity, Advisories cannot validate the serial numbers, which can result in Advisories incorrectly including field notices that do not apply. Not all field notices include serial number validation.
Click a particular advisory to view information such as What’s wrong, What’s the impact, and How do I fix it.
Advisories enable you to stay current with
-
new software and hardware availability
-
hardware and software EoS and EoL announcements and lead time for upgrades
-
PSIRTs and field notices, which helps you stay secure and compliant, and
-
instant visibility into applicable bugs.
Advisories are classified into three levels: critical, major, and warning.
-
Critical: Advisories are shown as critical when there are unsupported infrastructure and the severity of the bugs associated with notices is Severity1. Some of the examples include:
-
When switches in a fabric are running under End-of-Life conditions. When a critical (Severity1) field notice or PSIRT has been issued for a switch or software version currently running in your network.
-
-
Major: Advisories are shown as major when the severity of the bugs associated with notices is Severity2. Some of the examples include:
-
When a critical (Severity2) field notice or PSIRT has been issued for a switch or software version currently running in your network.
-
-
Warning: Advisories are shown as warning when there is support for potentially at risk infrastructure and the severity of the bugs associated with notices is Severity3. Some of the examples include:
-
When switches in a fabric are approaching end-of-life conditions. When a Severity3 field notice or PSIRT has been issued for a switch or software version currently running in your network.
-
Navigate to the Advisories
You can view advisories in Nexus Dashboard at different levels such as across all fabrics, for a specific fabric, for a specific switch, or for system-wide advisories. Use the following methods to access advisory information.
-
To view all advisories across all fabrics, you can navigate to Analyze > Advisories.
This displays all advisories detected across all fabrics in your environment.
-
Follow these steps to view the advisories for a single fabric.
-
Navigate to Home > Overview.
-
Choose online fabrics or snapshot fabrics from the drop-down list.
-
Click the Advisory level card.
-
In the Advisories page, click Analyze Advisories to view detailed information for the selected fabric.
-
-
You can also view the advisories for a single fabric in the Fabrics Overview page.
-
Navigate to Manage > Fabrics.
-
Choose an appropriate fabric.
The Fabrics Overview page displays.
-
Click the Advisories tab to view advisories specific to that fabric.
-
Follow these steps to view the advisories for a single switch in the Inventory page.
-
Navigate to Manage > Inventory.
-
Choose online fabrics or snapshot fabrics from the drop-down list.
-
Choose a switch.
The Switch Overview page displays.
-
Click the Advisories tab.
Follow these steps to view the system advisories.
-
Navigate to Admin > System Status.
-
Click the Advisories tab.
Analyze advisories
-
Click the Date and Time selector to select the time range.
-
Use the search bar to filter the advisories.
-
The Advisories table displays the filtered advisories. The advisories are sorted by Level by default. Click the column heading to sort the advisories in the table.
-
Click the gear icon to configure the columns in the Advisories table. By default, the columns Title, Level, Category, and Fabric are displayed.
-
Click an advisory to view the additional details such as What’s wrong?, What’s the impact?, and How do I fix it?.
-
Choose advisories from the Advisories table and click Acknowledge Advisories to acknowledge advisories.
You can also click an advisory in the Advisory page and choose Acknowledge Advisory from the Actions drop-down list.
By default all the unacknowledged Advisories are displayed in the advisories table. Once you acknowledge an advisory, choose Acknowledged from the drop-down list to view all the acknowledged advisories.
View platform and system alerts in global advisories table
System advisories allow you to view information about updates, issues, or required actions related to a system, application, or network. These advisories ensure that you are aware of critical information that might impact the system’s performance, security, or operation.
Follow these steps to include system-related advisories.
-
Navigate to Analyze > Advisories.
The Advisories page displays.
-
Click the Include system advisories toggle button in the top-right corner, to include system-related advisories in the Advisories table.
Once enabled, the System category appears under advisories by category in the Advisories page.
System advisory notification
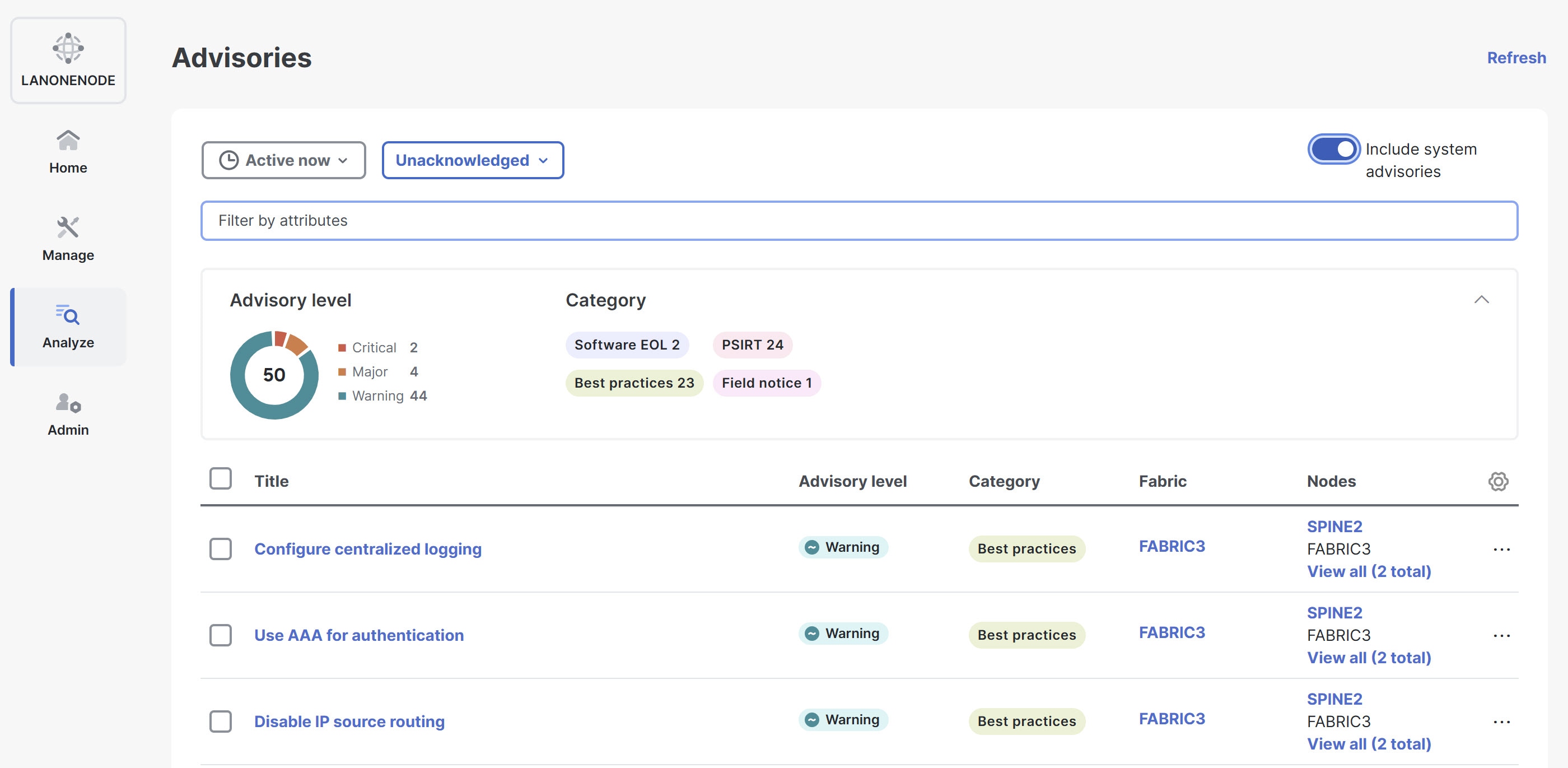
When there is an active system advisory, a notification alert appears on the Notifications bell icon located in the common navigation bar at the top of the page. Click the notification bell icon to open the Notifications pane. In the Notifications pane, click View system advisories. Nexus Dashboard redirects you to the System Status page, where you can review the full list of current and past system advisories in the Advisories table.
Advisory filters
The search bar allows you to filters the advisories. In the Advisories page, you can use the following filters to refine the displayed advisories:
-
Title - Display advisories with a specific title.
-
Advisory Level - Display advisories of a specific level.
-
Detection Time - Display advisories with a specific detection time.
-
Last Seen time - Display only advisories with a specific last seen time. Last Seen Time indicates the time advisory was updated while under active status. If the status of the advisory is not cleared, then the advisory is active.
-
Category - Display advisories from a specific category.
-
Fabric - Display advisories for a specific fabric.
-
Nodes - Display advisories for specific nodes.
-
What’s wrong? - Display advisories of a specific affected object.
As a secondary filter refinement, use the following operators:
-
==- with the initial filter type, this operator, and a subsequent value, returns an exact match. -
!=- with the initial filter type, this operator, and a subsequent value, returns all that do not have the same value. -
contains- with the initial filter type, this operator, and a subsequent value, returns all that contain the value. -
!contains- with the initial filter type, this operator, and a subsequent value, returns all that do not contain the value.
Metadata support
Nexus Dashboard uses metadata bundles to detect new bugs, PSIRTs, Field Notices, and End of Life Notices. Metadata packages are constantly updated by us and posted to the Cisco Intersight Cloud after validation. Nexus Dashboard connects to the Cisco Intersight Cloud through a device connector that is embedded in the Nexus Dashboard platform and that pulls periodically updated metadata packages. With metadata support for air-gap environment, if Nexus Dashboard is not connected to Cisco Intersight Cloud, you can manually upload the latest metadata to Nexus Dashboard in a secure and trusted way. You can download the bundle updates from the Cisco DC App Center.
Navigate to Admin > System Settings > Metadata to view the metadata version.
-
In the General area, the Metadata Version is displayed.
-
In the Update Metadata Version area, you can upload metadata for air-gapped environments.
Metadata support for an air-gap environment
With metadata support for air-gap environment, if Nexus Dashboard is not connected to Cisco secure cloud, you can upload the latest metadata to Nexus Dashboard periodically in a secure and trusted way.
You can download the encrypted metadata file from the Cisco DC App Center and upload it to Nexus Dashboard to get decrypted updates on exposure to Bugs, PSIRTs, Defects, Field Notices, and End of Life Notices.
Update metadata version
Use this procedure to update the latest metadata version in an Air-Gap or offline environment.
-
Log in to Cisco DC App Center.
-
From the User drop-down menu, select My Account.
-
Click Config Files Requests tab.
-
Click Request Config File.
-
From the Choose App ID drop-down list, select Nexus Dashboard.
-
Verify the minimum supported app version and click Request.
It takes approximately 15 minutes for the request to be completed. In the Config Files Request page, the generated file is displayed in the table below.
-
Select the file and click Download to download the file locally.

-
Log in to Nexus Dashboard.
-
Navigate to Admin > System Settings > Metadata to view the metadata version.
-
In the Update Metadata Version area, upload the file you have downloaded from the Cisco DC App Center.
-
Click Begin Upload to upload the latest metadata.
Copyright
THE SPECIFICATIONS AND INFORMATION REGARDING THE PRODUCTS IN THIS MANUAL ARE SUBJECT TO CHANGE WITHOUT NOTICE. ALL STATEMENTS, INFORMATION, AND RECOMMENDATIONS IN THIS MANUAL ARE BELIEVED TO BE ACCURATE BUT ARE PRESENTED WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. USERS MUST TAKE FULL RESPONSIBILITY FOR THEIR APPLICATION OF ANY PRODUCTS.
THE SOFTWARE LICENSE AND LIMITED WARRANTY FOR THE ACCOMPANYING PRODUCT ARE SET FORTH IN THE INFORMATION PACKET THAT SHIPPED WITH THE PRODUCT AND ARE INCORPORATED HEREIN BY THIS REFERENCE. IF YOU ARE UNABLE TO LOCATE THE SOFTWARE LICENSE OR LIMITED WARRANTY, CONTACT YOUR CISCO REPRESENTATIVE FOR A COPY.
The Cisco implementation of TCP header compression is an adaptation of a program developed by the University of California, Berkeley (UCB) as part of UCB’s public domain version of the UNIX operating system. All rights reserved. Copyright © 1981, Regents of the University of California.
NOTWITHSTANDING ANY OTHER WARRANTY HEREIN, ALL DOCUMENT FILES AND SOFTWARE OF THESE SUPPLIERS ARE PROVIDED “AS IS" WITH ALL FAULTS. CISCO AND THE ABOVE-NAMED SUPPLIERS DISCLAIM ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING, WITHOUT LIMITATION, THOSE OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE.
IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THIS MANUAL, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
Any Internet Protocol (IP) addresses and phone numbers used in this document are not intended to be actual addresses and phone numbers. Any examples, command display output, network topology diagrams, and other figures included in the document are shown for illustrative purposes only. Any use of actual IP addresses or phone numbers in illustrative content is unintentional and coincidental.
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product.
Cisco and the Cisco logo are trademarks or registered trademarks of Cisco and/or its affiliates in the U.S. and other countries. To view a list of Cisco trademarks, go to this URL: https://www.cisco.com/go/trademarks. Third-party trademarks mentioned are the property of their respective owners. The use of the word partner does not imply a partnership relationship between Cisco and any other company. (1110R)
© 2017-2025 Cisco Systems, Inc. All rights reserved.
Americas Headquarters
Cisco Systems, Inc.
170 West Tasman Drive
San Jose, CA 95134-1706
USA
http://www.cisco.com
Tel: 408 526-4000
800 553-NETS (6387)
Fax: 408 527-0883