冗長性
コンポーネントの障害に対処するために冗長性が追加されたコンポーネントを以下に示します。
-
x86 コンピューティング ハードウェア:x86 コンピューティング ハードウェアの冗長性を参照してください。
-
ネットワークファブリック:ネットワークファブリックの冗長性を参照してください。
-
物理 NIC/インターフェイス:物理 NIC またはインターフェイスの冗長性を参照してください。
-
NFVIS 仮想化インフラストラクチャ:NFVIS、仮想化インフラストラクチャの冗長性を参照してください。
-
サービスチェーン/VNF:サービスチェーンまたは VNF の冗長性を参照してください。
-
Cisco Colo Manager:Cisco Colo Manager のリカバリを参照してください。
ネットワークファブリックの冗長性
ネットワークファブリック:ハードウェアスイッチの冗長性機能は、ネットワークファブリックの障害を処理するために使用されます。スイッチに障害が発生した場合、スタンバイスイッチが、障害が発生したスイッチを通過するトラフィックを引き継ぐようにします。
x86 コンピューティング ハードウェアの冗長性
x86 コンピューティング ハードウェア:x86 コンピューティング ハードウェアで使用されるプロセッサ、ストレージなどのハードウェアコンポーネントが故障し、完全な Cisco Cloud Services Platform(CSP)システム障害につながる可能性があります。Cisco vBond オーケストレータは、管理インターフェイスを介して ICMP ping を使用して、x86 コンピューティング プラットフォームの正常性を継続的に監視します。システム障害では、オーケストレータはデバイスの状態と、影響を受けるサービスチェーンと VM を表示します。サービスチェーンを立ち上げるために必要なアクションを実行します。『Cisco SD-WAN Cloud onRamp for Colocation ソリューションデバイスのモニタリング』を参照してください。VNF(仮想ネットワーク機能)の動作状態に応じて、十分なリソースが利用可能な場合は、VM を別の CSP で起動する必要があります。このアクションにより、VNF は Day-N 構成を保持できます。VNF ディスクがローカルストレージを使用している場合、サービスグループ全体を、オーケストレータに保存されている Day-0 構成を使用して別の CSP デバイスで再スピンする必要があります。
物理 NIC またはインターフェイスの冗長性
物理 NIC またはインターフェイス:物理 NIC(PNIC)またはインターフェイスまたはケーブルに障害が発生したり、切断されたりすると、これらのインターフェイスを使用している VNF が影響を受けます。VNF が OVS ネットワークを使用している場合、リンクの冗長性を実現するためにポートチャネル構成が使用されます。VNF が OVS ネットワークを使用していて、VNF に HA インスタンスがある場合、そのインスタンスはすでに別の CSP で起動されています。フェールオーバーは、2 番目の CSP 上のこの VNF に対して発生します。2 番目の VNF インスタンスがない場合は、障害が発生した VNF を含むサービスチェーンを削除して再インスタンス化する必要があります。
NFVIS、仮想化インフラストラクチャの冗長性
Cisco NFVIS 仮想化インフラストラクチャ:NFVIS ソフトウェアレイヤで複数のタイプの障害が発生する可能性があります。CSP の重要なコンポーネントの 1 つがクラッシュしたり、ホストの Linux カーネルがパニックになったり、重要なコンポーネントの 1 つが応答しなくなったりする可能性があります。重大なコンポーネント障害が発生した場合、NFVIS ソフトウェアは netconf 通知を生成します。オーケストレータはこれらの通知を使用して、vManage ダッシュボードに障害を表示します。Cisco CSP または Cisco NFVIS がクラッシュするか、制御接続がダウンすると、オーケストレータはデバイスの到達可能性がダウンしていることを示します。ネットワークの問題(ある場合)を解決するか、CSP デバイスをリブートします。デバイスが回復しない場合は、CSP デバイスの削除に進む必要があります。
サービスチェーンまたは VNF の冗長性
|
機能名 |
リリース情報 |
説明 |
|---|---|---|
|
スイッチ冗長性のための HA VNF NIC の配置 |
Cisco SD-WAN リリース 20.5.1 Cisco vManage リリース 20.5.1 |
この機能は、サービスチェーンの最適な配置を提供するため、スイッチの冗長性を考慮しながら、リソースの使用率を最大化します。HA プライマリおよびセカンダリインスタンスの VNIC は、代替 CSP インターフェイスに配置され、スイッチレベルでの冗長性を実現します。 |
|
HA VNF NIC 配置の変更 |
Cisco SD-WAN リリース 20.6.1 Cisco vManage リリース 20.6.1 |
このリリースでは、冗長スイッチインターフェイスに接続されている CSP デバイスの物理 NIC 上のプライマリおよびセカンダリ VNF VNIC の配置が変更されています。 |
サービスチェーンまたは VNF:ファイアウォールなどのコロケーション サービス チェーン内の一部の VNF は、スタンバイ VNF を使用してステートフルな冗長性機能をサポートしている可能性がありますが、Cisco CSR1000V などの VNF はステートフルな冗長性をサポートしていない可能性があります。Cisco SD-WAN Cloud onRamp for Colocation ソリューションは、VNF に依存して VNF の高可用性を実現します。サービスチェーンレベルでの HA サポートは利用できません。VNF がステートフル HA をサポートしている場合、障害を検出してスイッチオーバーを実行します。VNF をホストしている CSP デバイスが機能し、すべての NIC またはインターフェイス接続が機能している場合、以前にアクティブだった VNF がダウンし、スタンバイ VNF としてリブートすることが前提です。VNF が動作していない場合、VNF の HA はその時点から機能していないため、問題を修正する必要があります。
VNF が HA をサポートしていない場合、VNF 内で重要なプロセスが失敗し、そのような VNF で使用できる HA サポートがない場合、VNF はリブートすると想定されます。
スイッチ冗長性のための高可用性 VNF NIC の配置
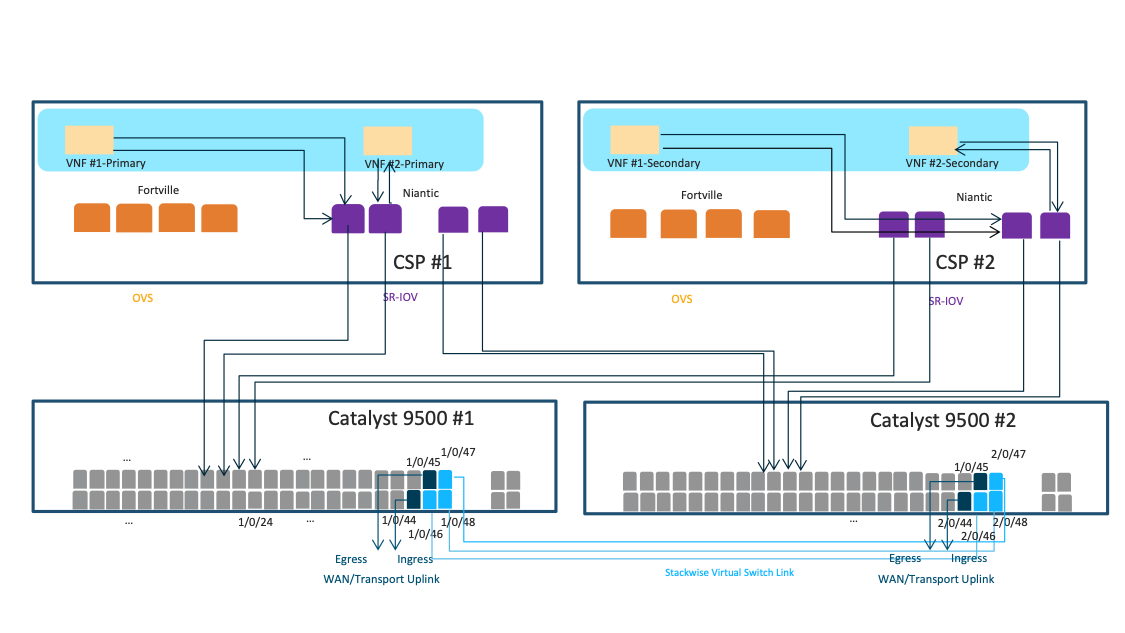
Cisco SD-WAN Cloud onRamp for Colocation Release 20.5.1 以降、サービスチェーン内のネットワークサービスは、スイッチに障害が発生しても中断することなくトラフィックを転送します。HA 仮想インスタンスの仮想 NIC(VNIC)は、プライマリ HA インスタンスがあるスイッチとは異なるスイッチに配置されるため、トラフィックフローは中断されません。たとえば、スイッチ 1 に接続されている CSP1 の物理 NIC にプライマリ VNF が配置されている場合、スイッチ 2 に接続されている CSP2 の物理 NIC にセカンダリ VNF が配置されます。
次の図は、次のことを示しています。
-
このソリューションは、VNF #1 と VNF #2 のプライマリインスタンスを、スイッチ #1 に接続されている CSP #1 の SR-IOV ポートにプロビジョニングします。
-
VNF1 と VNF2 のセカンダリインスタンスは、スイッチ 2 に接続されている CSP2 の SR-IOV ポートに配置されます。
-
スイッチ #1 に障害が発生した場合、トラフィックは 2 番目のスイッチを使用して、1 番目の VNF と 2 番目の VNF のスイッチ #2 から引き続き流れます。
スイッチ冗長化のための HA VNF NIC に関する注意事項
-
この機能は、VNF が SR-IOV インターフェイスを使用し、スイッチへのデュアルホーミングがサポートされていないシングルテナントクラスタにのみ適用されます。マルチテナントクラスタでは、ポートチャネルの一部である OVS インターフェイスがすでに使用されていて、スイッチにデュアルホーム接続されるため、この機能は必要ありません。
-
ソリューションの配置アルゴリズムは、上で指定された冗長要件に基づいてサービスチェーンを自動的に配置します。手動構成は必要ありません。
-
Cisco vManage を以前のリリースからリリース 20.5.1 にアップグレードする場合、HA VNF NIC 冗長性機能を使用するときに次の点が適用されます。
-
作成する新しいサービスグループの場合、代替スイッチに接続する CSP インターフェイスでの HA 仮想インスタンスの VNIC の配置は自動的に行われます。
-
既存のサービスグループの場合、サービスグループをクラスタから切り離してから、クラスタに再接続して、サービスチェーンのスイッチの冗長性を実現します。
-
-
出力ポートを配置するときに、ソリューションは最初に入力 VNF ポートをホストするのと同じ CSP ポートに出力ポートを配置しようとします。CSP ポートに十分な帯域幅がない場合、ソリューションは、同じスイッチに接続されている同じ CSP デバイスの追加ポートに出力ポートを配置しようとします。
Cisco SD-WAN Cloud onRamp for Colocation Release 20.6.1 以降、ソリューションは最大 10 Gbps の帯域幅のサービスチェーンをサポートします。必要な帯域幅が 5 Gbps を超え、10 Gbps 以下である場合、VNF の入力および出力 VNIC の配置は、同じ CSP デバイスの異なる CSP ポートにある可能性があります。
スイッチの冗長性のために HA VNF NIC の配置を使用するための推奨事項
-
すべてのサービスチェーンリソースを最大容量まで使用できるように、できるだけ多くのサービスチェーンを設計し、これらのチェーンをプロビジョニングします。これにより、コロケーション ソリューションは、各ポートに未使用の帯域幅を残すことなく、VM の帯域幅を完全に連続した順序で利用できます。
-
高帯域幅のサービスチェーンをコロケーションクラスタに接続し、続いて低帯域幅のサービスチェーンを接続します。リソースを最適に使用するには、可用性の高いサービスチェーンをコロケーションクラスタに接続し、その後にスタンドアロン サービス チェーンを接続します。
Cisco Colo Manager のリカバリ
Cisco Colo Manager のリカバリ:Cisco Colo Manager は、Cloud OnRamp for Colocation 内の CSP デバイスで起動されます。Cisco vManage は、DTLS トンネルを持つ CSP を選択して Cisco Colo Manager を起動します。次のシナリオでは、Cisco Colo Manager のリカバリフローが必要です。
Cisco Colo Manager をホストしている CSP が返品許可(RMA)プロセスの対象と見なされ、この CSP を削除した後にクラスタ内に少なくとも 2 つの他の CSP デバイスがある場合、新しい Cisco Colo Manager は、既存の 2 つの CSP デバイスのうちのいずれかの Cisco vManage によって新しい構成のプッシュ中に自動的に起動されます。
 (注) |
RMA プロセスの対象と見なされた CSP デバイスの電源を切るか、CSP デバイスで工場出荷時のデフォルトリセットを実行する必要があります。このタスクにより、クラスタ内に Cisco Colo Manager が 1 つだけあることが保証されます。 |
(注) |
Cisco Colo Manager が実行されているホストは再起動またはリブートできます。Cisco Colo Manager はすべての構成データと運用データをそのまま使用する必要があるため、このアクションはリカバリシナリオではありません。 |
クラスタが正常にアクティブ化された後、Cisco Colo Manager が異常になった場合は、Cisco Colo Manager の問題のトラブルシューティングを参照してください。
 フィードバック
フィードバック